React源码分析
宏观包结构
基础包结构
1、react
react 基础包, 只提供定义 react 组件(ReactElement)的必要函数, 一般来说需要和渲染器(react-dom,react-native)一同使用. 在编写react应用的代码时, 大部分都是调用此包的 api.
2、react-dom
react 渲染器之一, 是 react 与 web 平台连接的桥梁(可以在浏览器和 nodejs 环境中使用), 将react-reconciler中的运行结果输出到 web 界面上. 在编写react应用的代码时,大多数场景下, 能用到此包的就是一个入口函数ReactDOM.render(<App/>, document.getElementById('root')), 其余使用的 api, 基本是react包提供的.
3、react-reconciler
react 得以运行的核心包(综合协调react-dom,react,scheduler各包之间的调用与配合).
管理 react 应用状态的输入和结果的输出. 将输入信号最终转换成输出信号传递给渲染器.
-
接受输入(scheduleUpdateOnFiber), 将fiber树生成逻辑封装到一个回调函数中(涉及fiber树形结构, fiber.updateQueue队列, 调和算法等),
-
把此回调函数(performSyncWorkOnRoot或performConcurrentWorkOnRoot)送入scheduler进行调度
-
scheduler会控制回调函数执行的时机, 回调函数执行完成后得到全新的 fiber 树
-
再调用渲染器(如react-dom, react-native等)将 fiber 树形结构最终反映到界面上
4、scheduler
调度机制的核心实现, 控制由react-reconciler送入的回调函数的执行时机, 在concurrent模式下可以实现任务分片. 在编写react应用的代码时, 同样几乎不会直接用到此包提供的 api.
-
核心任务就是执行回调(回调函数由react-reconciler提供)
-
通过控制回调函数的执行时机, 来达到任务分片的目的, 实现可中断渲染(concurrent模式下才有此特性)
宏观总览
架构分层
为了便于理解, 可将 react 应用整体结构分为接口层(api)和内核层(core)2 个部分
1、接口层(api)
react包, 平时在开发过程中使用的绝大部分api均来自此包(不是所有). 在react启动之后, 正常可以改变渲染的基本操作有 3 个.
-
class 组件中使用setState()
-
function 组件里面使用 hook,并发起dispatchAction去改变 hook 对象
-
改变 context(其实也需要setState或dispatchAction的辅助才能改变)
以上setState和dispatchAction都由react包直接暴露. 所以要想 react 工作, 基本上是调用react包的 api 去与其他包进行交互.
2、内核层(core)
整个内核部分, 由 3 部分构成:
a、调度器
scheduler包, 核心职责只有 1 个, 就是执行回调.
-
把react-reconciler提供的回调函数, 包装到一个任务对象中.
-
在内部维护一个任务队列, 优先级高的排在最前面.
-
循环消费任务队列, 直到队列清空.
b、构造器
react-reconciler包, 有 3 个核心职责:
-
装载渲染器, 渲染器必须实现HostConfig协议(如: react-dom), 保证在需要的时候, 能够正确调用渲染器的 api, 生成实际节点(如: dom节点).
-
接收react-dom包(初次render)和react包(后续更新setState)发起的更新请求.
-
将fiber树的构造过程包装在一个回调函数中, 并将此回调函数传入到scheduler包等待调度.
c、渲染器
react-dom包, 有 2 个核心职责:
-
引导react应用的启动(通过ReactDOM.render).
-
实现HostConfig协议(源码在 ReactDOMHostConfig.js 中), 能够将react-reconciler包构造出来的fiber树表现出来, 生成 dom 节点(浏览器中), 生成字符串(ssr).
注意:
-
此处分层的标准并非官方说法, 因为官方没有架构分层这样的术语.
-
本文只是为了深入理解 react, 在官方标准之外, 对其进行分解和剖析, 方便我们理解 react 架构.
内核关系
现将内核 3 个包的主要职责和调用关系, 绘制到一张概览图上:
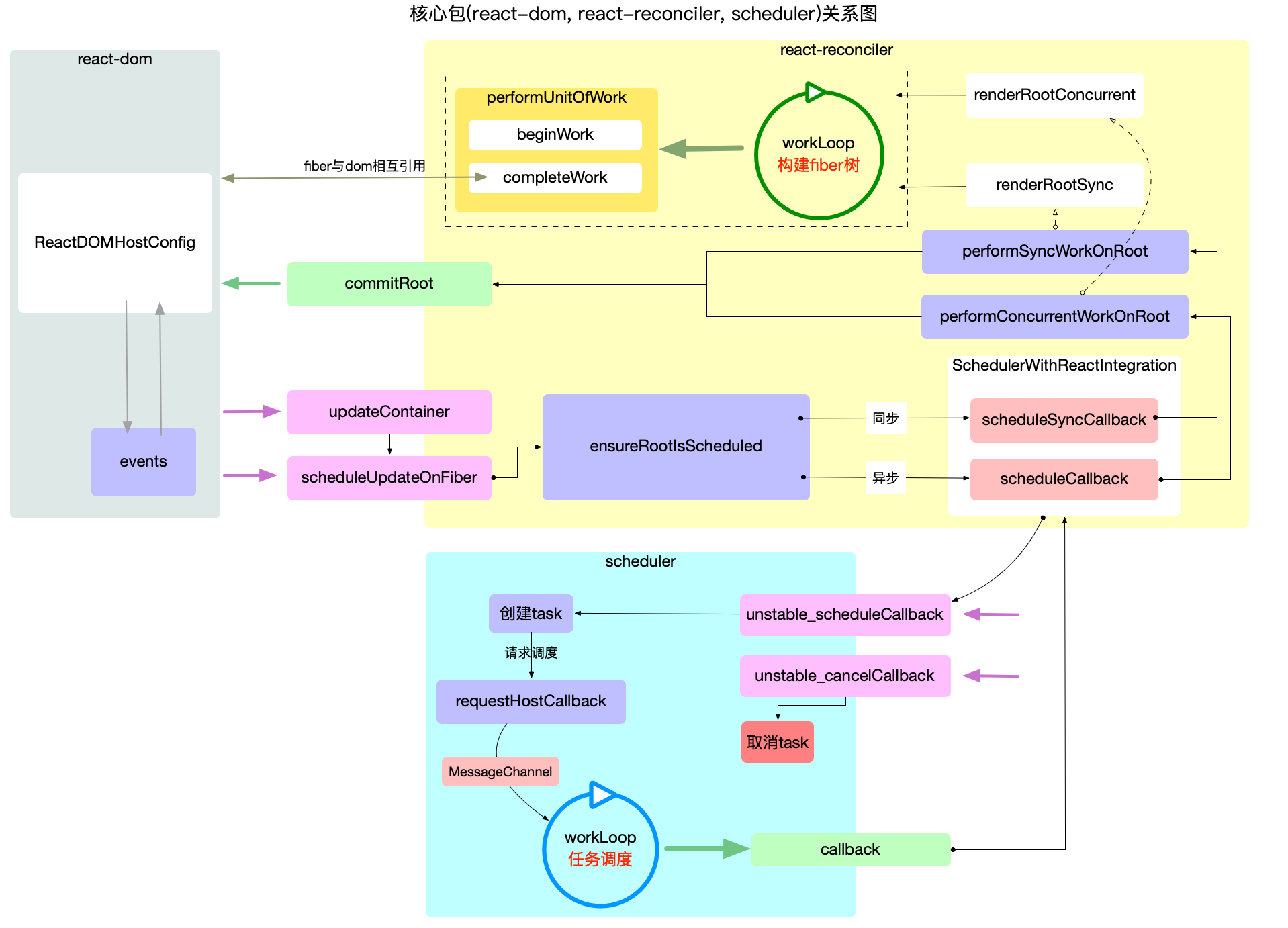
注意:
-
红色方块代表入口函数, 绿色方块代表出口函数.
-
package 之间的调用脉络就是通过板块间的入口和出口函数连接起来的.
通过此概览图, 基本可以表述 react 内核层的宏观结构. 后面的章节, 会按照此图的思路深入到对应的模块逐一解读.
两大工作循环
在前文(React 应用的宏观包结构)中, 介绍了react核心包之间的依赖和调用关系, 并绘制出了概览图. 在概览图中, 可以看到有两个大的循环, 它们分别位于scheduler和react-reconciler包中:
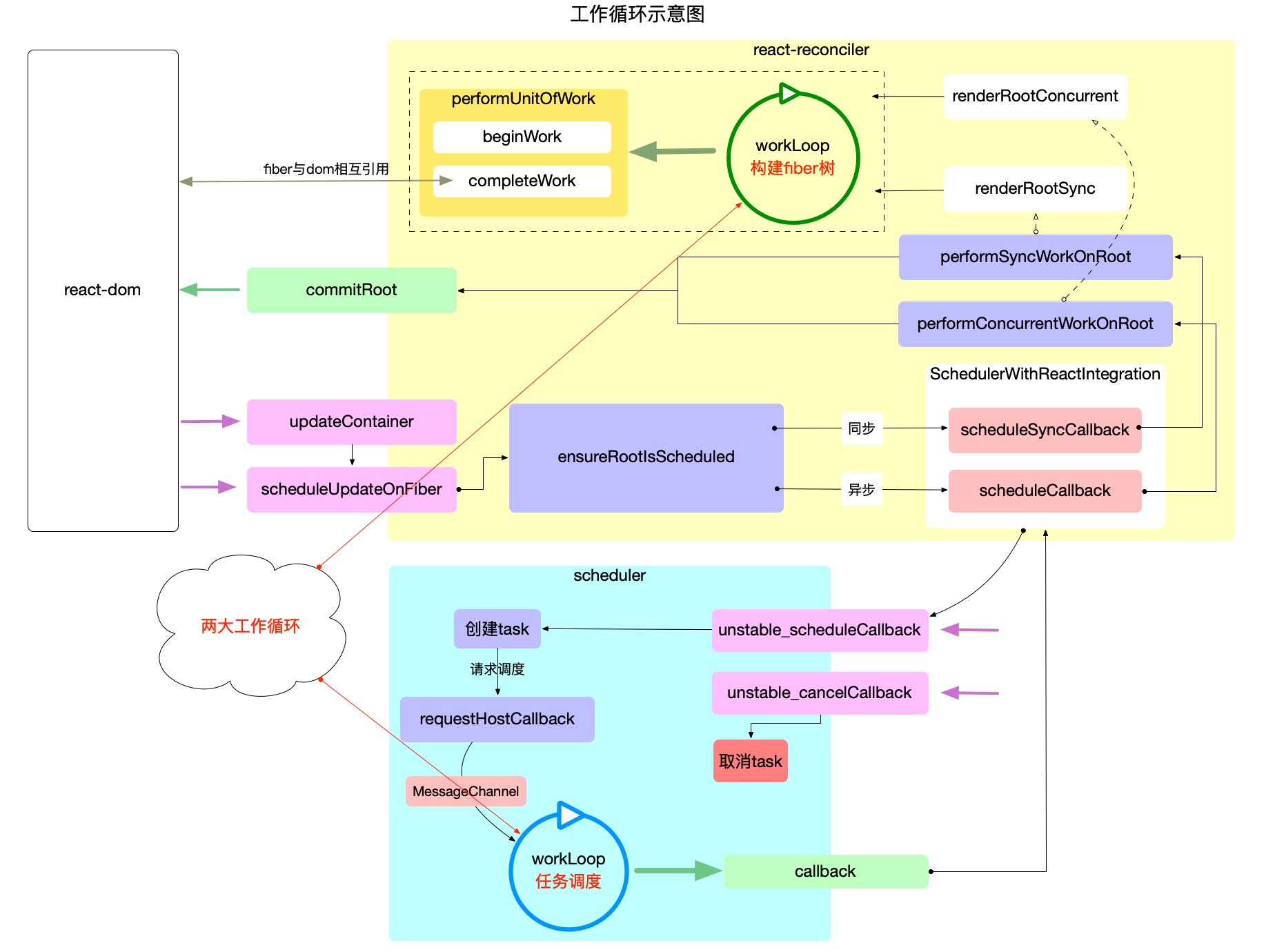
本文将这两个循环分别表述为任务调度循环和fiber构造循环. 接下来从宏观角度阐述这两大循环的作用, 以及它们之间的区别和联系. 更深入的源码分析分别在scheduler 调度机制和fiber 树构造章节中详细解读.
1、任务调度循环
源码位于Scheduler.js, 它是react应用得以运行的保证, 它需要循环调用, 控制所有任务(task)的调度.
2、fiber构造循环
源码位于ReactFiberWorkLoop.js, 控制 fiber 树的构造, 整个过程是一个深度优先遍历.
这两个循环对应的 js 源码不同于其他闭包(运行时就是闭包), 其中定义的全局变量, 不仅是该作用域的私有变量, 更用于控制react应用的执行过程.
区别与联系
区别
-
任务调度循环是以二叉堆为数据结构(详见react 算法之堆排序), 循环执行堆的顶点, 直到堆被清空.
-
任务调度循环的逻辑偏向宏观, 它调度的是每一个任务(task), 而不关心这个任务具体是干什么的(甚至可以将Scheduler包脱离react使用), 具体任务其实就是执行回调函数performSyncWorkOnRoot或performConcurrentWorkOnRoot.
-
fiber构造循环是以树为数据结构, 从上至下执行深度优先遍历(详见react 算法之深度优先遍历).
-
fiber构造循环的逻辑偏向具体实现, 它只是任务(task)的一部分(如performSyncWorkOnRoot包括: fiber树的构造, DOM渲染, 调度检测), 只负责fiber树的构造.
联系
- fiber构造循环是任务调度循环中的任务(task)的一部分. 它们是从属关系, 每个任务都会重新构造一个fiber树.
主干逻辑
通过上文的描述, 两大循环的分工可以总结为: 大循环(任务调度循环)负责调度task, 小循环(fiber 构造循环)负责实现task .
react 运行的主干逻辑, 即将输入转换为输出的核心步骤, 实际上就是围绕这两大工作循环进行展开.
结合上文的宏观概览图(展示核心包之间的调用关系), 可以将 react 运行的主干逻辑进行概括:
1、输入: 将每一次更新(如: 新增, 删除, 修改节点之后)视为一次更新需求(目的是要更新DOM节点).
2、注册调度任务: react-reconciler收到更新需求之后, 并不会立即构造fiber树, 而是去调度中心scheduler注册一个新任务task, 即把更新需求转换成一个task.
3、执行调度任务(输出): 调度中心scheduler通过任务调度循环来执行task(task的执行过程又回到了react-reconciler包中).
-
fiber构造循环是task的实现环节之一, 循环完成之后会构造出最新的 fiber 树.
-
commitRoot是task的实现环节之二, 把最新的 fiber 树最终渲染到页面上, task完成.
主干逻辑就是输入到输出这一条链路, 为了更好的性能(如批量更新, 可中断渲染等功能), react在输入到输出的链路上做了很多优化策略, 比如本文讲述的任务调度循环和fiber构造循环相互配合就可以实现可中断渲染.
高频对象
在 React 应用中, 有很多特定的对象或数据结构. 了解这些内部的设计, 可以更容易理解 react 运行原理. 本章主要列举从 react 启动到渲染过程出现频率较高, 影响范围较大的对象, 它们贯穿整个 react 运行时.
其他过程的重要对象:
-
如事件对象(位于react-dom/events保障 react 应用能够响应 ui 交互), 在事件机制章节中详细解读.
-
如ReactContext, ReactProvider, ReactConsumer对象, 在 context 机制章节中详细解读.
react 包
在React 应用的宏观包结构中介绍过, 此包定义 react 组件(ReactElement)的必要函数, 提供一些操作ReactElement对象的 api.
所以这个包的核心需要理解ReactElement对象, 假设有如下入口函数:
// 入口函数
ReactDOM.render(<App />, document.getElementById('root'));
可以简单的认为, 包括<App/>及其所有子节点都是ReactElement对象(在 render 之后才会生成子节点, 后文详细解读), 每个ReactElement对象的区别在于 type 不同.
ReactElement 对象
所有采用jsx语法书写的节点, 都会被编译器转换, 最终会以React.createElement(…)的方式, 创建出来一个与之对应的ReactElement对象.
ReactElement对象的数据结构如下:
export type ReactElement = {|
// 用于辨别ReactElement对象
$$typeof: any,
// 内部属性
type: any, // 表明其种类
key: any,
ref: any,
props: any,
// ReactFiber 记录创建本对象的Fiber节点, 还未与Fiber树关联之前, 该属性为null
_owner: any,
// __DEV__ dev环境下的一些额外信息, 如文件路径, 文件名, 行列信息等
_store: {validated: boolean, ...},
_self: React$Element<any>,
_shadowChildren: any,
_source: Source,
|};
需要特别注意 2 个属性:
1、key属性在reconciler阶段会用到, 目前只需要知道所有的ReactElement对象都有 key 属性(且其默认值是 null, 这点十分重要, 在 diff 算法中会使用到).
2、type属性决定了节点的种类:
-
它的值可以是字符串(代表div,span等 dom 节点), 函数(代表function, class等节点), 或者 react 内部定义的节点类型(portal,context,fragment等)
-
在reconciler阶段, 会根据 type 执行不同的逻辑(在 fiber 构建阶段详细解读).
-
如 type 是一个字符串类型, 则直接使用.
-
如 type 是一个ReactComponent类型, 则会调用其 render 方法获取子节点.
-
如 type 是一个function类型,则会调用该方法获取子节点
-
…
-
在v17.0.2中, 定义了 20 种内部节点类型. 根据运行时环境不同, 分别采用 16 进制的字面量和Symbol进行表示.
ReactComponent对象
对于ReactElement来讲, ReactComponent仅仅是诸多type类型中的一种.
对于开发者来讲, ReactComponent使用非常高频(在状态组件章节中详细解读), 在本节只是先证明它只是一种特殊的ReactElement.
这里用一个简单的示例, 通过查看编译后的代码来说明
class App extends React.Component {
render() {
return (
<div className="app">
<header>header</header>
<Content />
<footer>footer</footer>
</div>
);
}
}
class Content extends React.Component {
render() {
return (
<React.Fragment>
<p>1</p>
<p>2</p>
<p>3</p>
</React.Fragment>
);
}
}
export default App;
编译之后的代码(此处只编译了 jsx 语法, 并没有将 class 语法编译成 es5 中的 function), 可以更直观的看出调用逻辑.
createElement函数的第一个参数将作为创建ReactElement的type. 可以看到Content这个变量被编译器命名为App_Content, 并作为第一个参数(引用传递), 传入了createElement.
class App_App extends react_default.a.Component {
render() {
return /*#__PURE__*/ react_default.a.createElement(
'div',
{
className: 'app',
} /*#__PURE__*/,
react_default.a.createElement('header', null, 'header') /*#__PURE__*/,
// 此处直接将Content传入, 是一个指针传递
react_default.a.createElement(App_Content, null) /*#__PURE__*/,
react_default.a.createElement('footer', null, 'footer'),
);
}
}
class App_Content extends react_default.a.Component {
render() {
return /*#__PURE__*/ react_default.a.createElement(
react_default.a.Fragment,
null /*#__PURE__*/,
react_default.a.createElement('p', null, '1'),
/*#__PURE__*/
react_default.a.createElement('p', null, '2'),
/*#__PURE__*/
react_default.a.createElement('p', null, '3'),
);
}
}
上述示例演示了ReactComponent是诸多ReactElement种类中的一种情况, 但是由于ReactComponent是 class 类型, 自有它的特殊性(可对照源码, 更容易理解).
1、ReactComponent是 class 类型, 继承父类Component, 拥有特殊的方法(setState,forceUpdate)和特殊的属性(context,updater等).
2、在reconciler阶段, 会依据ReactElement对象的特征, 生成对应的 fiber 节点. 当识别到ReactElement对象是 class 类型的时候, 会触发ReactComponent对象的生命周期, 并调用其 render方法, 生成ReactElement子节点.
其他ReactElement
上文介绍了第一种特殊的ReactElement(class类型的组件), 除此之外function类型的组件也需要深入了解, 因为Hook只能在function类型的组件中使用.
如果在function类型的组件中没有使用Hook(如: useState, useEffect等), 在reconciler阶段所有有关Hook的处理都会略过, 最后调用该function拿到子节点ReactElement.
如果使用了Hook, 逻辑就相对复杂, 涉及到Hook创建和状态保存(有关 Hook 的原理部分, 在 Hook 原理章节中详细解读). 此处只需要了解function类型的组件和class类型的组件一样, 是诸多ReactElement形式中的一种.
ReactElement内存结构
通过前文对ReactElement的介绍, 可以比较容易的画出<App/>这个ReactElement对象在内存中的结构(reconciler阶段完成之后才会形成完整的结构).
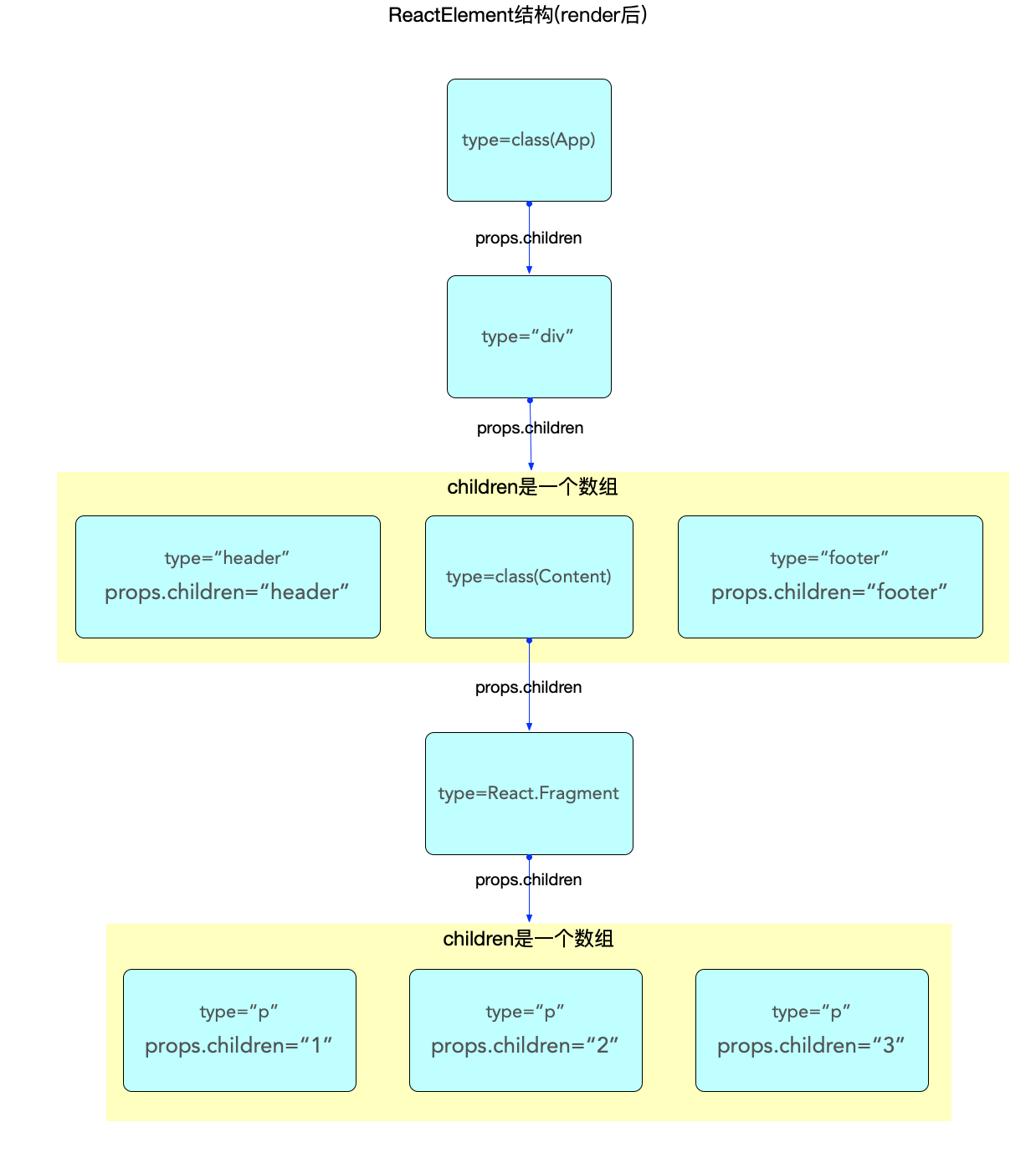
注意:
-
class和function类型的组件,其子节点是在 render 之后(reconciler阶段)才生成的. 此处只是单独表示ReactElement的数据结构.
-
父级对象和子级对象之间是通过props.children属性进行关联的(与 fiber 树不同).
-
ReactElement虽然不能算是一个严格的树, 也不能算是一个严格的链表. 它的生成过程是自顶向下的, 是所有组件节点的总和.
-
ReactElement树(暂且用树来表述)和fiber树是以props.children为单位先后交替生成的(在 fiber 树构建章节详细解读), 当ReactElement树构造完毕, fiber 树也随后构造完毕.
-
reconciler阶段会根据ReactElement的类型生成对应的fiber节点(不是一一对应, 比如Fragment类型的组件在生成fiber节点的时候会略过).
react-reconciler 包
在宏观结构中介绍过, react-reconciler包是react应用的中枢, 连接渲染器(react-dom)和调度中心(scheduler), 同时自身也负责 fiber 树的构造.
对于此包的深入分析, 放在fiber 树构建, reconciler 工作空间等章节中.
此处先要知道fiber是核心, react 体系的渲染和更新都要以 fiber 作为数据模型, 如果不能理解 fiber, 也无法深入理解 react.
本章先预览一下此包中与fiber对象关联度较高的对象.
Fiber 对象
先看数据结构, 其 type 类型的定义在ReactInternalTypes.js中:
// 一个Fiber对象代表一个即将渲染或者已经渲染的组件(ReactElement), 一个组件可能对应两个fiber(current和WorkInProgress)
// 单个属性的解释在后文(在注释中无法添加超链接)
export type Fiber = {|
tag: WorkTag,
key: null | string,
elementType: any,
type: any,
stateNode: any,
return: Fiber | null,
child: Fiber | null,
sibling: Fiber | null,
index: number,
ref:
| null
| (((handle: mixed) => void) & { _stringRef: ?string, ... })
| RefObject,
pendingProps: any, // 从`ReactElement`对象传入的 props. 用于和`fiber.memoizedProps`比较可以得出属性是否变动
memoizedProps: any, // 上一次生成子节点时用到的属性, 生成子节点之后保持在内存中
updateQueue: mixed, // 存储state更新的队列, 当前节点的state改动之后, 都会创建一个update对象添加到这个队列中.
memoizedState: any, // 用于输出的state, 最终渲染所使用的state
dependencies: Dependencies | null, // 该fiber节点所依赖的(contexts, events)等
mode: TypeOfMode, // 二进制位Bitfield,继承至父节点,影响本fiber节点及其子树中所有节点. 与react应用的运行模式有关(有ConcurrentMode, BlockingMode, NoMode等选项).
// Effect 副作用相关
flags: Flags, // 标志位
subtreeFlags: Flags, //替代16.x版本中的 firstEffect, nextEffect. 当设置了 enableNewReconciler=true才会启用
deletions: Array<Fiber> | null, // 存储将要被删除的子节点. 当设置了 enableNewReconciler=true才会启用
nextEffect: Fiber | null, // 单向链表, 指向下一个有副作用的fiber节点
firstEffect: Fiber | null, // 指向副作用链表中的第一个fiber节点
lastEffect: Fiber | null, // 指向副作用链表中的最后一个fiber节点
// 优先级相关
lanes: Lanes, // 本fiber节点的优先级
childLanes: Lanes, // 子节点的优先级
alternate: Fiber | null, // 指向内存中的另一个fiber, 每个被更新过fiber节点在内存中都是成对出现(current和workInProgress)
// 性能统计相关(开启enableProfilerTimer后才会统计)
// react-dev-tool会根据这些时间统计来评估性能
actualDuration?: number, // 本次更新过程, 本节点以及子树所消耗的总时间
actualStartTime?: number, // 标记本fiber节点开始构建的时间
selfBaseDuration?: number, // 用于最近一次生成本fiber节点所消耗的时间
treeBaseDuration?: number, // 生成子树所消耗的时间的总和
|};
属性解释:
-
fiber.tag: 表示 fiber 类型, 根据ReactElement组件的 type 进行生成, 在 react 内部共定义了25 种 tag.
-
fiber.key: 和ReactElement组件的 key 一致.
-
fiber.elementType: 一般来讲和ReactElement组件的 type 一致
-
fiber.type: 一般来讲和fiber.elementType一致. 一些特殊情形下, 比如在开发环境下为了兼容热更新(HotReloading), 会对function, class, ForwardRef类型的ReactElement做一定的处理, 这种情况会区别于fiber.elementType, 具体赋值关系可以查看源文件.
-
fiber.stateNode: 与fiber关联的局部状态节点(比如: HostComponent类型指向与fiber节点对应的 dom 节点; 根节点fiber.stateNode指向的是FiberRoot; class 类型节点其stateNode指向的是 class 实例).
-
fiber.return: 指向父节点.
-
fiber.child: 指向第一个子节点.
- fiber.sibling: 指向下一个兄弟节点.
-
fiber.index: fiber 在兄弟节点中的索引, 如果是单节点默认为 0.
-
fiber.ref: 指向在ReactElement组件上设置的 ref(string类型的ref除外, 这种类型的ref已经不推荐使用, reconciler阶段会将string类型的ref转换成一个function类型).
-
fiber.pendingProps: 输入属性, 从ReactElement对象传入的 props. 用于和fiber.memoizedProps比较可以得出属性是否变动.
-
fiber.memoizedProps: 上一次生成子节点时用到的属性, 生成子节点之后保持在内存中. 向下生成子节点之前叫做pendingProps, 生成子节点之后会把pendingProps赋值给memoizedProps用于下一次比较.pendingProps和memoizedProps比较可以得出属性是否变动.
-
fiber.updateQueue: 存储update更新对象的队列, 每一次发起更新, 都需要在该队列上创建一个update对象.
-
fiber.memoizedState: 上一次生成子节点之后保持在内存中的局部状态.
-
fiber.dependencies: 该 fiber 节点所依赖的(contexts, events)等, 在context机制章节详细说明.
-
fiber.mode: 二进制位 Bitfield,继承至父节点,影响本 fiber 节点及其子树中所有节点. 与 react 应用的运行模式有关(有 ConcurrentMode, BlockingMode, NoMode 等选项).
-
fiber.flags: 标志位, 副作用标记(在 16.x 版本中叫做effectTag, 相应pr), 在ReactFiberFlags.js中定义了所有的标志位. reconciler阶段会将所有拥有flags标记的节点添加到副作用链表中, 等待 commit 阶段的处理.
-
fiber.subtreeFlags: 替代 16.x 版本中的 firstEffect, nextEffect. 默认未开启, 当设置了enableNewReconciler=true 才会启用, 本系列只跟踪稳定版的代码, 未来版本不会深入解读, 使用示例见源码.
-
fiber.deletions: 存储将要被删除的子节点. 默认未开启, 当设置了enableNewReconciler=true 才会启用, 本系列只跟踪稳定版的代码, 未来版本不会深入解读, 使用示例见源码.
-
fiber.nextEffect: 单向链表, 指向下一个有副作用的 fiber 节点.
-
fiber.firstEffect: 指向副作用链表中的第一个 fiber 节点.
-
fiber.lastEffect: 指向副作用链表中的最后一个 fiber 节点.
-
fiber.lanes: 本 fiber 节点所属的优先级, 创建 * fiber 的时候设置.
-
fiber.childLanes: 子节点所属的优先级.
- fiber.alternate: 指向内存中的另一个 fiber, 每个被更新过 fiber 节点在内存中都是成对出现(current 和 workInProgress)
通过以上 25 个属性的解释, 对fiber对象有一个初步的认识.
最后绘制一颗 fiber 树与上文中的ReactElement树对照起来:
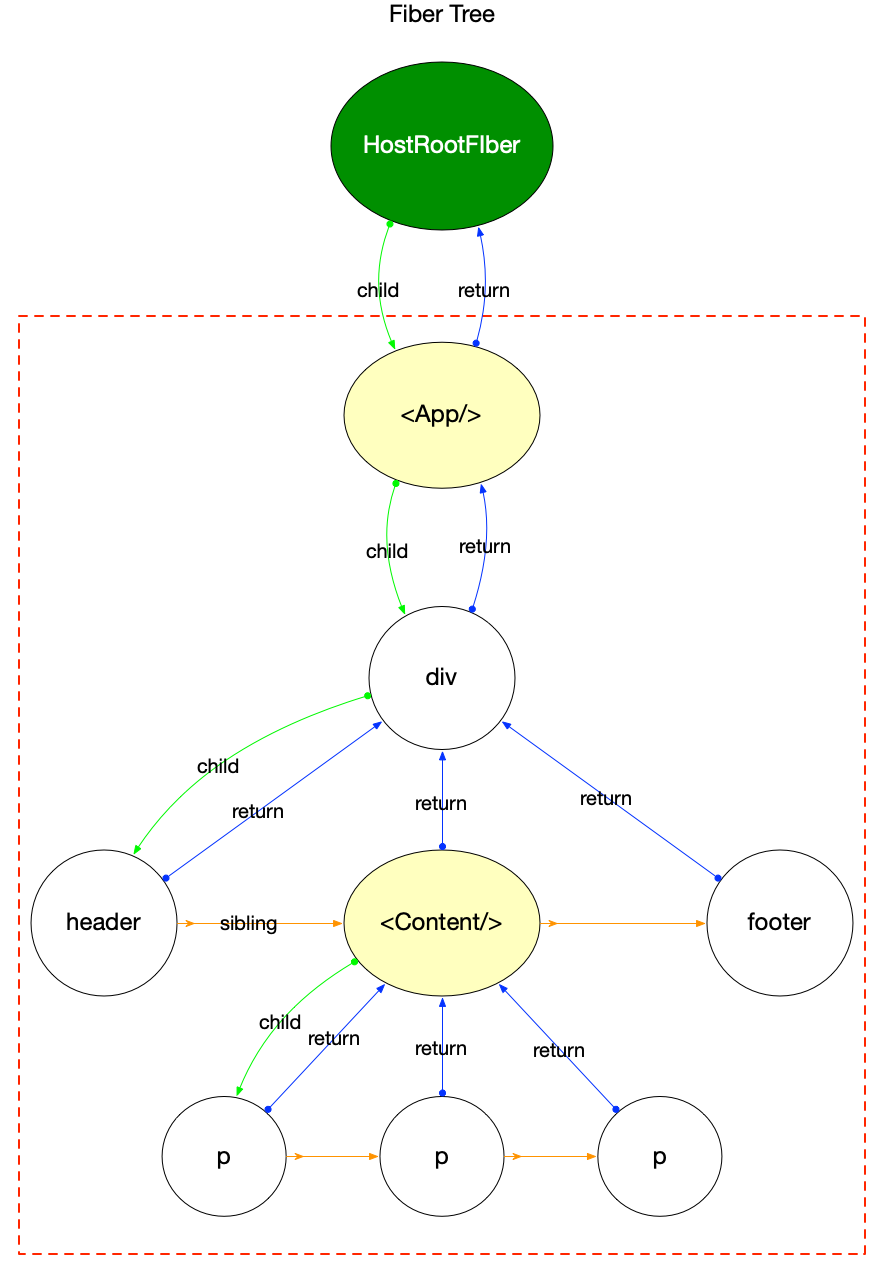
注意:
-
这里的fiber树只是为了和上文中的ReactElement树对照, 所以只用观察红色虚线框内的节点. 根节点HostRootFiber在react 应用的启动模式章节中详细解读.
-
其中
<App/>,<Content/>为ClassComponent类型的fiber节点, 其余节点都是普通HostComponent类型节点. -
<Content/>的子节点在ReactElement树中是React.Fragment, 但是在fiber树中React.Fragment并没有与之对应的fiber节点(reconciler阶段对此类型节点做了单独处理, 所以ReactElement节点和fiber节点不是一对一匹配).
Update 与 UpdateQueue 对象
在fiber对象中有一个属性fiber.updateQueue, 是一个链式队列(即使用链表实现的队列存储结构), 后文会根据场景表述成链表或队列.
首先观察Update对象的数据结构(对照源码):
export type Update<State> = {|
eventTime: number, // 发起update事件的时间(17.0.2中作为临时字段, 即将移出)
lane: Lane, // update所属的优先级
tag: 0 | 1 | 2 | 3, //
payload: any, // 载荷, 根据场景可以设置成一个回调函数或者对象
callback: (() => mixed) | null, // 回调函数
next: Update<State> | null, // 指向链表中的下一个, 由于UpdateQueue是一个环形链表, 最后一个update.next指向第一个update对象
|};
// =============== UpdateQueue ==============
type SharedQueue<State> = {|
pending: Update<State> | null,
|};
export type UpdateQueue<State> = {|
baseState: State,
firstBaseUpdate: Update<State> | null,
lastBaseUpdate: Update<State> | null,
shared: SharedQueue<State>,
effects: Array<Update<State>> | null,
|};
属性解释:
1、UpdateQueue
-
baseState: 表示此队列的基础 state
-
firstBaseUpdate: 指向基础队列的队首
-
lastBaseUpdate: 指向基础队列的队尾
-
shared: 共享队列
-
effects: 用于保存有callback回调函数的 update 对象, 在commit之后, 会依次调用这里的回调函数.
2、SharedQueue
- pending: 指向即将输入的update队列. 在class组件中调用setState()之后, 会将新的 update 对象添加到这个队列中来.
3、Update
-
eventTime: 发起update事件的时间(17.0.2 中作为临时字段, 即将移出)
-
lane: update所属的优先级
-
tag: 表示update种类, 共 4 种. UpdateState,ReplaceState,ForceUpdate,CaptureUpdate
-
payload: 载荷, update对象真正需要更新的数据, 可以设置成一个回调函数或者对象.
-
callback: 回调函数. commit完成之后会调用.
-
next: 指向链表中的下一个, 由于UpdateQueue是一个环形链表, 最后一个update.next指向第一个update对象.
updateQueue是fiber对象的一个属性, 所以不能脱离fiber存在. 它们之间数据结构和引用关系如下:
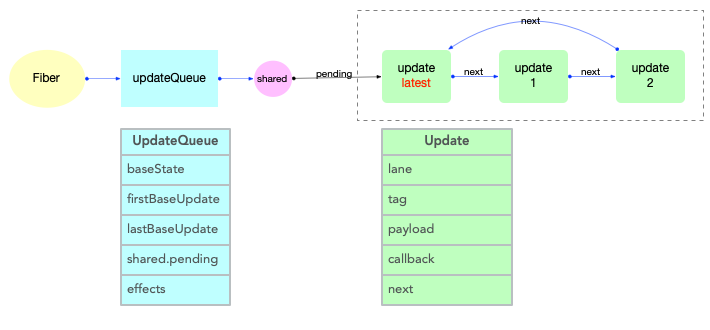
注意:
- 此处只是展示数据结构和引用关系.对于updateQueue在更新阶段的实际作用和运行逻辑, 会在状态组件(class 与 function)章节中详细解读.
Hook 对象
Hook用于function组件中, 能够保持function组件的状态(与class组件中的state在性质上是相同的, 都是为了保持组件的状态).在react@16.8以后, 官方开始推荐使用Hook语法, 常用的 api 有useState,useEffect,useCallback等, 官方一共定义了14 种Hook类型.
这些 api 背后都会创建一个Hook对象, 先观察Hook对象的数据结构:
export type Hook = {|
memoizedState: any,
baseState: any,
baseQueue: Update<any, any> | null,
queue: UpdateQueue<any, any> | null,
next: Hook | null,
|};
type Update<S, A> = {|
lane: Lane,
action: A,
eagerReducer: ((S, A) => S) | null,
eagerState: S | null,
next: Update<S, A>,
priority?: ReactPriorityLevel,
|};
type UpdateQueue<S, A> = {|
pending: Update<S, A> | null,
dispatch: ((A) => mixed) | null,
lastRenderedReducer: ((S, A) => S) | null,
lastRenderedState: S | null,
|};
属性解释:
1、Hook
-
memoizedState: 内存状态, 用于输出成最终的fiber树
-
baseState: 基础状态, 当Hook.queue更新过后, baseState也会更新.
-
baseQueue: 基础状态队列, 在reconciler阶段会辅助状态合并.
-
queue: 指向一个Update队列
-
next: 指向该function组件的下一个Hook对象, 使得多个Hook之间也构成了一个链表.
2、Hook.queue和 Hook.baseQueue(即UpdateQueue和Update)是为了保证Hook对象能够顺利更新, 与上文fiber.updateQueue中的UpdateQueue和Update是不一样的(且它们在不同的文件), 其逻辑会在状态组件(class 与 function)章节中详细解读.
Hook与fiber的关系:
在fiber对象中有一个属性fiber.memoizedState指向fiber节点的内存状态. 在function类型的组件中, fiber.memoizedState就指向Hook队列(Hook队列保存了function类型的组件状态).
所以Hook也不能脱离fiber而存在, 它们之间的引用关系如下:
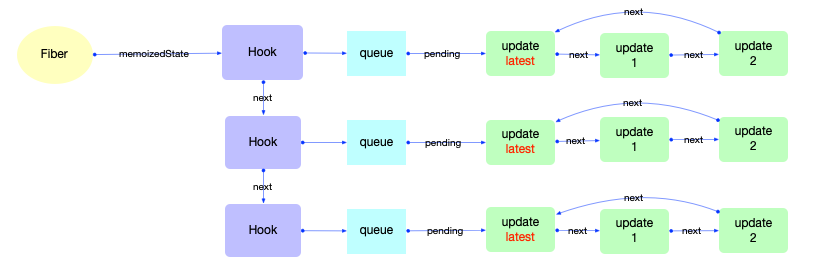
注意:
此处只是展示数据结构和引用关系.对于Hook在运行时的实际作用和逻辑, 会在状态组件(class 与 function)章节中详细解读.
scheduler 包
如宏观结构中所介绍, scheduler包负责调度, 在内部维护一个任务队列(taskQueue). 这个队列是一个最小堆数组(详见React 算法之堆排序), 其中存储了 task 对象.
Task 对象
scheduler包中, 没有为 task 对象定义 type, 其定义是直接在 js 代码中:
var newTask = {
id: taskIdCounter++,
callback,
priorityLevel,
startTime,
expirationTime,
sortIndex: -1,
};
属性解释:
-
id: 唯一标识
-
callback: task 最核心的字段, 指向react-reconciler包所提供的回调函数.
-
priorityLevel: 优先级
-
startTime: 一个时间戳,代表 task 的开始时间(创建时间 + 延时时间).
-
expirationTime: 过期时间.
-
sortIndex: 控制 task 在队列中的次序, 值越小的越靠前.
注意task中没有next属性, 它不是一个链表, 其顺序是通过堆排序来实现的(小顶堆数组, 始终保证数组中的第一个task对象优先级最高).
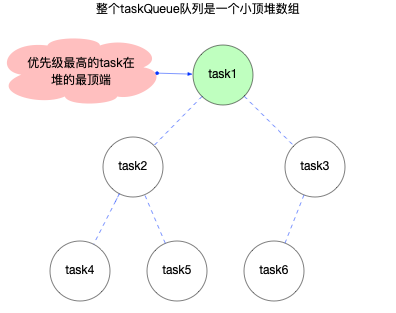
启动过程
在前文reconciler 运作流程把reconciler的流程归结成 4 个步骤.
本章节主要讲解react应用程序的启动过程, 位于react-dom包, 衔接reconciler 运作流程中的输入步骤.
在正式分析源码之前, 先了解一下react应用的启动模式:
在当前稳定版react@17.0.2源码中, 有 3 种启动方式. 先引出官网上对于这 3 种模式的介绍, 其基本说明如下:
1、legacy 模式: ReactDOM.render(<App />, rootNode). 这是当前 React app 使用的方式. 这个模式可能不支持这些新功能(concurrent 支持的所有功能).
// LegacyRoot
ReactDOM.render(<App />, document.getElementById('root'), (dom) => {}); // 支持callback回调, 参数是一个dom对象
2、Blocking 模式: ReactDOM.createBlockingRoot(rootNode).render(<App />). 目前正在实验中, 它仅提供了 concurrent 模式的小部分功能, 作为迁移到 concurrent 模式的第一个步骤.
// BlockingRoot
// 1. 创建ReactDOMRoot对象
const reactDOMBlockingRoot = ReactDOM.createBlockingRoot(
document.getElementById('root'),
);
// 2. 调用render
reactDOMBlockingRoot.render(<App />); // 不支持回调
3、Concurrent 模式: ReactDOM.createRoot(rootNode).render(<App />). 目前在实验中, 未来稳定之后,打算作为 React 的默认开发模式. 这个模式开启了所有的新功能.
// ConcurrentRoot
// 1. 创建ReactDOMRoot对象
const reactDOMRoot = ReactDOM.createRoot(document.getElementById('root'));
// 2. 调用render
reactDOMRoot.render(<App />); // 不支持回调
注意: 虽然17.0.2的源码中有createRoot和createBlockingRoot方法(如果自行构建, 会默认构建experimental版本), 但是稳定版的构建入口排除掉了这两个 api, 所以实际在npm i react-dom安装17.0.2稳定版后, 不能使用该 api.如果要想体验非legacy模式, 需要显示安装 alpha 版本(或自行构建).
启动流程
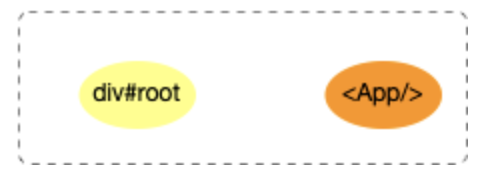
在调用入口函数之前,reactElement(<App/>)和 DOM 对象div#root之间没有关联, 用图片表示如下:
创建全局对象
无论Legacy, Concurrent或Blocking模式, react 在初始化时, 都会创建 3 个全局对象
1、ReactDOM(Blocking)Root对象
属于react-dom包, 该对象暴露有render,unmount方法, 通过调用该实例的render方法, 可以引导 react 应用的启动.
2、fiberRoot对象
属于react-reconciler包, 作为react-reconciler在运行过程中的全局上下文, 保存 fiber 构建过程中所依赖的全局状态.
其大部分实例变量用来存储fiber 构造循环(详见两大工作循环)过程的各种状态.react 应用内部, 可以根据这些实例变量的值, 控制执行逻辑.
3、HostRootFiber对象
属于react-reconciler包, 这是 react 应用中的第一个 Fiber 对象, 是 Fiber 树的根节点, 节点的类型是HostRoot.
这 3 个对象是 react 体系得以运行的基本保障, 一经创建大多数场景不会再销毁(除非卸载整个应用root.unmount()).
这一过程是从react-dom包发起, 内部调用了react-reconciler包, 核心流程图如下(其中红色标注了 3 个对象的创建时机).
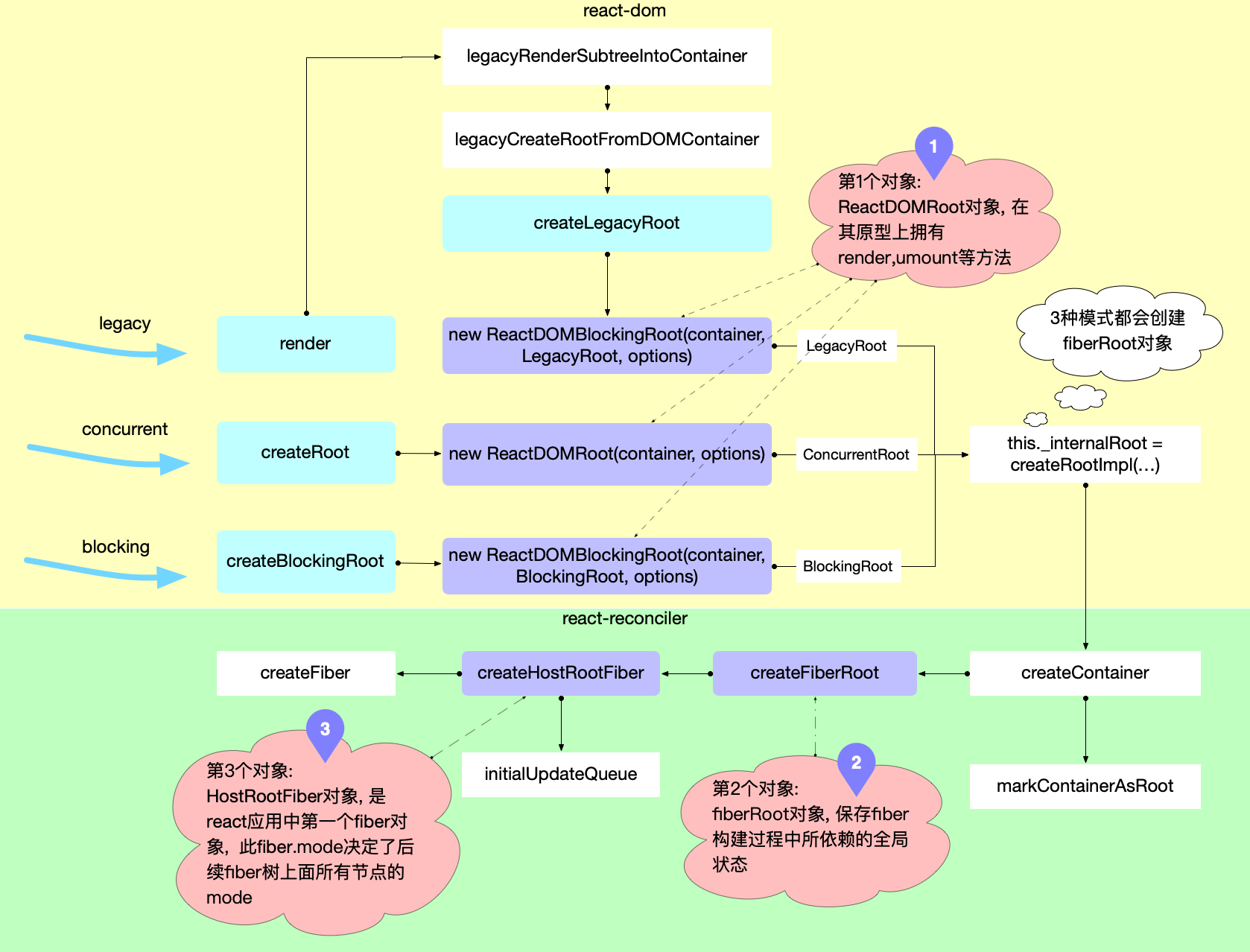
下面逐一解释这 3 个对象的创建过程.
创建 ReactDOM(Blocking)Root 对象
由于 3 种模式启动的 api 有所不同, 所以从源码上追踪, 也对应了 3 种方式. 最终都 new 一个ReactDOMRoot或ReactDOMBlockingRoot的实例, 需要创建过程中RootTag参数, 3 种模式各不相同. 该RootTag的类型决定了整个 react 应用是否支持可中断渲染(后文有解释).
下面根据 3 种 mode 下的启动函数逐一分析.
legacy 模式
legacy模式表面上是直接调用ReactDOM.render, 跟踪ReactDOM.render后续调用legacyRenderSubtreeIntoContainer(源码链接)
function legacyRenderSubtreeIntoContainer(
parentComponent: ?React$Component<any, any>,
children: ReactNodeList,
container: Container,
forceHydrate: boolean,
callback: ?Function,
) {
let root: RootType = (container._reactRootContainer: any);
let fiberRoot;
if (!root) {
// 初次调用, root还未初始化, 会进入此分支
//1. 创建ReactDOMRoot对象, 初始化react应用环境
root = container._reactRootContainer = legacyCreateRootFromDOMContainer(
container,
forceHydrate,
);
fiberRoot = root._internalRoot;
if (typeof callback === 'function') {
const originalCallback = callback;
callback = function () {
// instance最终指向 children(入参: 如<App/>)生成的dom节点
const instance = getPublicRootInstance(fiberRoot);
originalCallback.call(instance);
};
}
// 2. 更新容器
unbatchedUpdates(() => {
updateContainer(children, fiberRoot, parentComponent, callback);
});
} else {
// root已经初始化, 二次调用render会进入
// 1. 获取FiberRoot对象
fiberRoot = root._internalRoot;
if (typeof callback === 'function') {
const originalCallback = callback;
callback = function () {
const instance = getPublicRootInstance(fiberRoot);
originalCallback.call(instance);
};
}
// 2. 调用更新
updateContainer(children, fiberRoot, parentComponent, callback);
}
return getPublicRootInstance(fiberRoot);
}
继续跟踪legacyCreateRootFromDOMContainer. 最后调用new ReactDOMBlockingRoot(container, LegacyRoot, options);
function legacyCreateRootFromDOMContainer(
container: Container,
forceHydrate: boolean,
): RootType {
const shouldHydrate =
forceHydrate || shouldHydrateDueToLegacyHeuristic(container);
return createLegacyRoot(
container,
shouldHydrate
? {
hydrate: true,
}
: undefined,
);
}
export function createLegacyRoot(
container: Container,
options?: RootOptions,
): RootType {
return new ReactDOMBlockingRoot(container, LegacyRoot, options); // 注意这里的LegacyRoot是固定的, 并不是外界传入的
}
通过以上分析,legacy模式下调用ReactDOM.render有 2 个核心步骤:
1、创建ReactDOMBlockingRoot实例(在 Concurrent 模式和 Blocking 模式中详细分析该类), 初始化 react 应用环境.
2、调用updateContainer进行更新.
Concurrent 模式和 Blocking 模式
Concurrent模式和Blocking模式从调用方式上直接可以看出
1、分别调用ReactDOM.createRoot和ReactDOM.createBlockingRoot创建ReactDOMRoot和ReactDOMBlockingRoot实例
2、调用ReactDOMRoot和ReactDOMBlockingRoot实例的render方法
export function createRoot(
container: Container,
options?: RootOptions,
): RootType {
return new ReactDOMRoot(container, options);
}
export function createBlockingRoot(
container: Container,
options?: RootOptions,
): RootType {
return new ReactDOMBlockingRoot(container, BlockingRoot, options); // 注意第2个参数BlockingRoot是固定写死的
}
继续查看ReactDOMRoot和ReactDOMBlockingRoot对象
function ReactDOMRoot(container: Container, options: void | RootOptions) {
// 创建一个fiberRoot对象, 并将其挂载到this._internalRoot之上
this._internalRoot = createRootImpl(container, ConcurrentRoot, options);
}
function ReactDOMBlockingRoot(
container: Container,
tag: RootTag,
options: void | RootOptions,
) {
// 创建一个fiberRoot对象, 并将其挂载到this._internalRoot之上
this._internalRoot = createRootImpl(container, tag, options);
}
ReactDOMRoot.prototype.render = ReactDOMBlockingRoot.prototype.render =
function (children: ReactNodeList): void {
const root = this._internalRoot;
// 执行更新
updateContainer(children, root, null, null);
};
ReactDOMRoot.prototype.unmount = ReactDOMBlockingRoot.prototype.unmount =
function (): void {
const root = this._internalRoot;
const container = root.containerInfo;
// 执行更新
updateContainer(null, root, null, () => {
unmarkContainerAsRoot(container);
});
};
ReactDOMRoot和ReactDOMBlockingRoot有相同的特性
1、调用createRootImpl创建fiberRoot对象, 并将其挂载到this._internalRoot上.
2、原型上有render和unmount方法, 且内部都会调用updateContainer进行更新.
创建 fiberRoot 对象
无论哪种模式下, 在ReactDOM(Blocking)Root的创建过程中, 都会调用一个相同的函数createRootImpl, 查看后续的函数调用, 最后会创建fiberRoot 对象(在这个过程中, 特别注意RootTag的传递过程):
// 注意: 3种模式下的tag是各不相同(分别是ConcurrentRoot,BlockingRoot,LegacyRoot).
this._internalRoot = createRootImpl(container, tag, options);
function createRootImpl(
container: Container,
tag: RootTag,
options: void | RootOptions,
) {
// ... 省略部分源码(有关hydrate服务端渲染等, 暂时用不上)
// 1. 创建fiberRoot
const root = createContainer(container, tag, hydrate, hydrationCallbacks); // 注意RootTag的传递
// 2. 标记dom对象, 把dom和fiber对象关联起来
markContainerAsRoot(root.current, container);
// ...省略部分无关代码
return root;
}
export function createContainer(
containerInfo: Container,
tag: RootTag,
hydrate: boolean,
hydrationCallbacks: null | SuspenseHydrationCallbacks,
): OpaqueRoot {
// 创建fiberRoot对象
return createFiberRoot(containerInfo, tag, hydrate, hydrationCallbacks); // 注意RootTag的传递
}
创建 HostRootFiber 对象
在createFiberRoot中, 创建了react应用的首个fiber对象, 称为HostRootFiber(fiber.tag = HostRoot)
export function createFiberRoot(
containerInfo: any,
tag: RootTag,
hydrate: boolean,
hydrationCallbacks: null | SuspenseHydrationCallbacks,
): FiberRoot {
// 创建fiberRoot对象, 注意RootTag的传递
const root: FiberRoot = (new FiberRootNode(containerInfo, tag, hydrate): any);
// 1. 这里创建了`react`应用的首个`fiber`对象, 称为`HostRootFiber`
const uninitializedFiber = createHostRootFiber(tag);
root.current = uninitializedFiber;
uninitializedFiber.stateNode = root;
// 2. 初始化HostRootFiber的updateQueue
initializeUpdateQueue(uninitializedFiber);
return root;
}
在创建HostRootFiber时, 其中fiber.mode属性, 会与 3 种RootTag(ConcurrentRoot,BlockingRoot,LegacyRoot)关联起来.
export function createHostRootFiber(tag: RootTag): Fiber {
let mode;
if (tag === ConcurrentRoot) {
mode = ConcurrentMode | BlockingMode | StrictMode;
} else if (tag === BlockingRoot) {
mode = BlockingMode | StrictMode;
} else {
mode = NoMode;
}
return createFiber(HostRoot, null, null, mode); // 注意这里设置的mode属性是由RootTag决定的
}
注意:fiber树中所有节点的mode都会和HostRootFiber.mode一致(新建的 fiber 节点, 其 mode 来源于父节点),所以HostRootFiber.mode非常重要, 它决定了以后整个 fiber 树构建过程.
运行到这里, 3 个对象创建成功, react应用的初始化完毕.
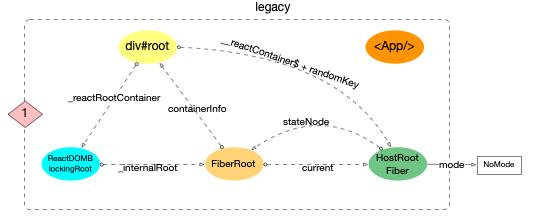
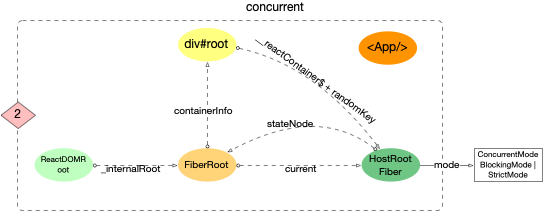
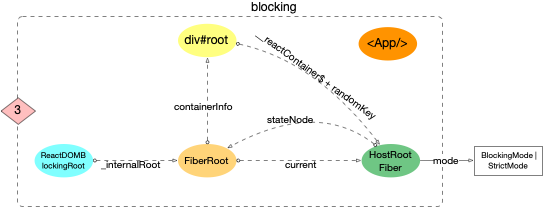
将此刻内存中各个对象的引用情况表示出来:
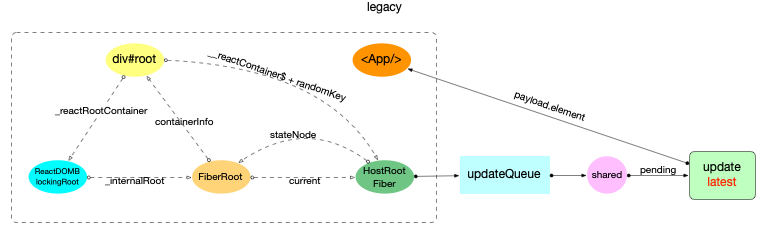
legacy
concurrent
blocking
注意:
1、3 种模式下,HostRootFiber.mode是不一致的
2、legacy 下, div#root和ReactDOMBlockingRoot之间通过_reactRootContainer关联. 其他模式是没有关联的
3、此时reactElement(<App/>)还是独立在外的, 还没有和目前创建的 3 个全局对象关联起来
调用更新入口
legacy
回到legacyRenderSubtreeIntoContainer函数中有:
// 2. 更新容器
unbatchedUpdates(() => {
updateContainer(children, fiberRoot, parentComponent, callback);
});
concurrent 和 blocking
在ReactDOM(Blocking)Root原型上有render方法
ReactDOMRoot.prototype.render = ReactDOMBlockingRoot.prototype.render =
function (children: ReactNodeList): void {
const root = this._internalRoot;
// 执行更新
updateContainer(children, root, null, null);
};
相同点:
1、3 种模式在调用更新时都会执行updateContainer. updateContainer函数串联了react-dom与react-reconciler, 之后的逻辑进入了react-reconciler包.
不同点:
1、legacy下的更新会先调用unbatchedUpdates, 更改执行上下文为LegacyUnbatchedContext, 之后调用updateContainer进行更新.
2、concurrent和blocking不会更改执行上下文, 直接调用updateContainer进行更新.
继续跟踪updateContainer函数
export function updateContainer(
element: ReactNodeList,
container: OpaqueRoot,
parentComponent: ?React$Component<any, any>,
callback: ?Function,
): Lane {
const current = container.current;
// 1. 获取当前时间戳, 计算本次更新的优先级
const eventTime = requestEventTime();
const lane = requestUpdateLane(current);
// 2. 设置fiber.updateQueue
const update = createUpdate(eventTime, lane);
update.payload = { element };
callback = callback === undefined ? null : callback;
if (callback !== null) {
update.callback = callback;
}
enqueueUpdate(current, update);
// 3. 进入reconciler运作流程中的`输入`环节
scheduleUpdateOnFiber(current, lane, eventTime);
return lane;
}
updateContainer函数位于react-reconciler包中, 它串联了react-dom与react-reconciler. 此处暂时不深入分析updateContainer函数的具体功能, 需要关注其最后调用了scheduleUpdateOnFiber.
在前文reconciler 运作流程中, 重点分析过scheduleUpdateOnFiber是输入阶段的入口函数.
所以到此为止, 通过调用react-dom包的api(如: ReactDOM.render), react内部经过一系列运转, 完成了初始化, 并且进入了reconciler 运作流程的第一个阶段.
可中断渲染
react 中最广为人知的可中断渲染(render 可以中断, 部分生命周期函数有可能执行多次, UNSAFE_componentWillMount,UNSAFE_componentWillReceiveProps)只有在HostRootFiber.mode === ConcurrentRoot | BlockingRoot才会开启. 如果使用的是legacy, 即通过ReactDOM.render(<App/>, dom)这种方式启动时HostRootFiber.mode = NoMode, 这种情况下无论是首次 render 还是后续 update 都只会进入同步工作循环, reconciliation没有机会中断, 所以生命周期函数只会调用一次.
对于可中断渲染的宣传最早来自2017 年 Lin Clark 的演讲. 演讲中阐述了未来 react 会应用 fiber 架构, reconciliation可中断等(13:15 秒). 在v16.1.0中应用了 fiber.
在最新稳定版v17.0.2中, 可中断渲染虽然实现, 但是并没有在稳定版暴露出 api. 只能安装 alpha 版本才能体验该特性.
但是不少开发人员认为稳定版本的react已经是可中断渲染(其实是有误区的), 大概率也是受到了各类宣传文章的影响. 前端大环境还是比较浮躁的, 在当下, 更需要静下心来学习.
reconciler 运作流程
通过前文宏观包结构和两大工作循环中的介绍, 对react-reconciler包有一定了解.
此处先归纳一下react-reconciler包的主要作用, 将主要功能分为 4 个方面:
1、输入: 暴露api函数(如: scheduleUpdateOnFiber), 供给其他包(如react包)调用.
2、注册调度任务: 与调度中心(scheduler包)交互, 注册调度任务task, 等待任务回调.
3、执行任务回调: 在内存中构造出fiber树, 同时与与渲染器(react-dom)交互, 在内存中创建出与fiber对应的DOM节点.
4、输出: 与渲染器(react-dom)交互, 渲染DOM节点.
以上功能源码都集中在ReactFiberWorkLoop.js中. 现在将这些功能(从输入到输出)串联起来, 用下图表示:
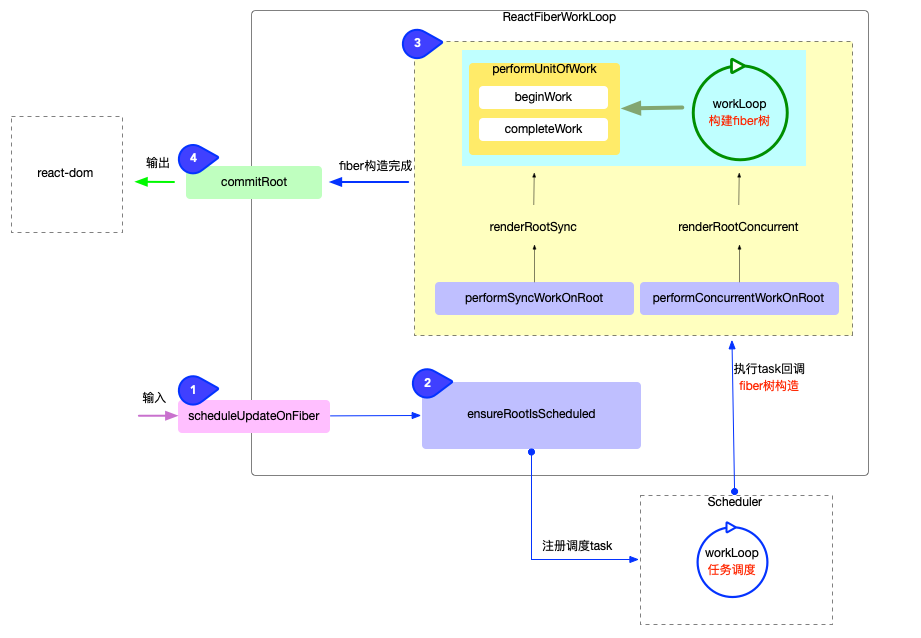
图中的1,2,3,4步骤可以反映react-reconciler包从输入到输出的运作流程,这是一个固定流程, 每一次更新都会运行.
图中只列举了最核心的函数调用关系(其中的每一步都有各自的实现细节, 会在后续的章节中逐一展开). 将上述 4 个步骤逐一分解, 了解它们的主要逻辑.
输入
在ReactFiberWorkLoop.js中, 承接输入的函数只有scheduleUpdateOnFiber源码地址. 在react-reconciler对外暴露的 api 函数中, 只要涉及到需要改变 fiber 的操作(无论是首次渲染或后续更新操作), 最后都会间接调用scheduleUpdateOnFiber, 所以scheduleUpdateOnFiber函数是输入链路中的必经之路.
// 唯一接收输入信号的函数
export function scheduleUpdateOnFiber(
fiber: Fiber,
lane: Lane,
eventTime: number,
) {
// ... 省略部分无关代码
const root = markUpdateLaneFromFiberToRoot(fiber, lane);
if (lane === SyncLane) {
if (
(executionContext & LegacyUnbatchedContext) !== NoContext &&
(executionContext & (RenderContext | CommitContext)) === NoContext
) {
// 直接进行`fiber构造`
performSyncWorkOnRoot(root);
} else {
// 注册调度任务, 经过`Scheduler`包的调度, 间接进行`fiber构造`
ensureRootIsScheduled(root, eventTime);
}
} else {
// 注册调度任务, 经过`Scheduler`包的调度, 间接进行`fiber构造`
ensureRootIsScheduled(root, eventTime);
}
}
逻辑进入到scheduleUpdateOnFiber之后, 后面有 2 种可能:
1、不经过调度, 直接进行fiber构造.
2、注册调度任务, 经过Scheduler包的调度, 间接进行fiber构造.
注册调度任务
与输入环节紧密相连, scheduleUpdateOnFiber函数之后, 立即进入ensureRootIsScheduled函数:
// ... 省略部分无关代码
function ensureRootIsScheduled(root: FiberRoot, currentTime: number) {
// 前半部分: 判断是否需要注册新的调度
const existingCallbackNode = root.callbackNode;
const nextLanes = getNextLanes(
root,
root === workInProgressRoot ? workInProgressRootRenderLanes : NoLanes,
);
const newCallbackPriority = returnNextLanesPriority();
if (nextLanes === NoLanes) {
return;
}
if (existingCallbackNode !== null) {
const existingCallbackPriority = root.callbackPriority;
if (existingCallbackPriority === newCallbackPriority) {
return;
}
cancelCallback(existingCallbackNode);
}
// 后半部分: 注册调度任务
let newCallbackNode;
if (newCallbackPriority === SyncLanePriority) {
newCallbackNode = scheduleSyncCallback(
performSyncWorkOnRoot.bind(null, root),
);
} else if (newCallbackPriority === SyncBatchedLanePriority) {
newCallbackNode = scheduleCallback(
ImmediateSchedulerPriority,
performSyncWorkOnRoot.bind(null, root),
);
} else {
const schedulerPriorityLevel =
lanePriorityToSchedulerPriority(newCallbackPriority);
newCallbackNode = scheduleCallback(
schedulerPriorityLevel,
performConcurrentWorkOnRoot.bind(null, root),
);
}
root.callbackPriority = newCallbackPriority;
root.callbackNode = newCallbackNode;
}
ensureRootIsScheduled的逻辑很清晰, 分为 2 部分:
1、前半部分: 判断是否需要注册新的调度(如果无需新的调度, 会退出函数)
2、后半部分: 注册调度任务
-
performSyncWorkOnRoot或performConcurrentWorkOnRoot被封装到了任务回调(scheduleCallback)中
-
等待调度中心执行任务, 任务运行其实就是执行performSyncWorkOnRoot或performConcurrentWorkOnRoot
执行任务回调
任务回调, 实际上就是执行performSyncWorkOnRoot或performConcurrentWorkOnRoot. 简单看一下它们的源码(在fiber树构造章节再深入分析), 将主要逻辑剥离出来, 单个函数的代码量并不多.
performSyncWorkOnRoot:
// ... 省略部分无关代码
function performSyncWorkOnRoot(root) {
let lanes;
let exitStatus;
lanes = getNextLanes(root, NoLanes);
// 1. fiber树构造
exitStatus = renderRootSync(root, lanes);
// 2. 异常处理: 有可能fiber构造过程中出现异常
if (root.tag !== LegacyRoot && exitStatus === RootErrored) {
// ...
}
// 3. 输出: 渲染fiber树
const finishedWork: Fiber = (root.current.alternate: any);
root.finishedWork = finishedWork;
root.finishedLanes = lanes;
commitRoot(root);
// 退出前再次检测, 是否还有其他更新, 是否需要发起新调度
ensureRootIsScheduled(root, now());
return null;
}
performSyncWorkOnRoot的逻辑很清晰, 分为 3 部分:
1、fiber 树构造
2、异常处理: 有可能 fiber 构造过程中出现异常
3、调用输出
performConcurrentWorkOnRoot:
// ... 省略部分无关代码
function performConcurrentWorkOnRoot(root) {
const originalCallbackNode = root.callbackNode;
// 1. 刷新pending状态的effects, 有可能某些effect会取消本次任务
const didFlushPassiveEffects = flushPassiveEffects();
if (didFlushPassiveEffects) {
if (root.callbackNode !== originalCallbackNode) {
// 任务被取消, 退出调用
return null;
} else {
// Current task was not canceled. Continue.
}
}
// 2. 获取本次渲染的优先级
let lanes = getNextLanes(
root,
root === workInProgressRoot ? workInProgressRootRenderLanes : NoLanes,
);
// 3. 构造fiber树
let exitStatus = renderRootConcurrent(root, lanes);
if (
includesSomeLane(
workInProgressRootIncludedLanes,
workInProgressRootUpdatedLanes,
)
) {
// 如果在render过程中产生了新的update, 且新update的优先级与最初render的优先级有交集
// 那么最初render无效, 丢弃最初render的结果, 等待下一次调度
prepareFreshStack(root, NoLanes);
} else if (exitStatus !== RootIncomplete) {
// 4. 异常处理: 有可能fiber构造过程中出现异常
if (exitStatus === RootErrored) {
// ...
}.
const finishedWork: Fiber = (root.current.alternate: any);
root.finishedWork = finishedWork;
root.finishedLanes = lanes;
// 5. 输出: 渲染fiber树
finishConcurrentRender(root, exitStatus, lanes);
}
// 退出前再次检测, 是否还有其他更新, 是否需要发起新调度
ensureRootIsScheduled(root, now());
if (root.callbackNode === originalCallbackNode) {
// 渲染被阻断, 返回一个新的performConcurrentWorkOnRoot函数, 等待下一次调用
return performConcurrentWorkOnRoot.bind(null, root);
}
return null;
}
performConcurrentWorkOnRoot的逻辑与performSyncWorkOnRoot的不同之处在于, 对于可中断渲染的支持:
1、调用performConcurrentWorkOnRoot函数时, 首先检查是否处于render过程中, 是否需要恢复上一次渲染.
2、如果本次渲染被中断, 最后返回一个新的 performConcurrentWorkOnRoot 函数, 等待下一次调用.
输出
commitRoot:
// ... 省略部分无关代码
function commitRootImpl(root, renderPriorityLevel) {
// 设置局部变量
const finishedWork = root.finishedWork;
const lanes = root.finishedLanes;
// 清空FiberRoot对象上的属性
root.finishedWork = null;
root.finishedLanes = NoLanes;
root.callbackNode = null;
// 提交阶段
let firstEffect = finishedWork.firstEffect;
if (firstEffect !== null) {
const prevExecutionContext = executionContext;
executionContext |= CommitContext;
// 阶段1: dom突变之前
nextEffect = firstEffect;
do {
commitBeforeMutationEffects();
} while (nextEffect !== null);
// 阶段2: dom突变, 界面发生改变
nextEffect = firstEffect;
do {
commitMutationEffects(root, renderPriorityLevel);
} while (nextEffect !== null);
root.current = finishedWork;
// 阶段3: layout阶段, 调用生命周期componentDidUpdate和回调函数等
nextEffect = firstEffect;
do {
commitLayoutEffects(root, lanes);
} while (nextEffect !== null);
nextEffect = null;
executionContext = prevExecutionContext;
}
ensureRootIsScheduled(root, now());
return null;
}
在输出阶段,commitRoot的实现逻辑是在commitRootImpl函数中, 其主要逻辑是处理副作用队列, 将最新的 fiber 树结构反映到 DOM 上.
核心逻辑分为 3 个步骤:
1、commitBeforeMutationEffects
dom 变更之前, 主要处理副作用队列中带有Snapshot,Passive标记的fiber节点.
2、commitMutationEffects
dom 变更, 界面得到更新. 主要处理副作用队列中带有Placement, Update, Deletion, Hydrating标记的fiber节点.
3、commitLayoutEffects
dom 变更后, 主要处理副作用队列中带有Update | Callback标记的fiber节点.
优先级管理
React是一个声明式, 高效且灵活的用于构建用户界面的 JavaScript 库. React 团队一直致力于实现高效渲染, 其可中断渲染,时间切片(time slicing),异步渲染(suspense)等特性, 在源码中得以实现都依赖于优先级管理.
在React@17.0.2源码中, 一共有2套优先级体系和1套转换体系, 在深入分析之前, 再次回顾一下(reconciler 运作流程):
React内部对于优先级的管理, 贯穿运作流程的 4 个阶段(从输入到输出), 根据其功能的不同, 可以分为 3 种类型:
1、fiber优先级(LanePriority): 位于react-reconciler包, 也就是Lane(车道模型).
2、调度优先级(SchedulerPriority): 位于scheduler包.
3、优先级等级(ReactPriorityLevel) : 位于react-reconciler包中的SchedulerWithReactIntegration.js, 负责上述 2 套优先级体系的转换.
Lane (车道模型)
英文单词lane翻译成中文表示”车道, 航道”的意思, 所以很多文章都将Lanes模型称为车道模型
Lane模型的源码在ReactFiberLane.js, 源码中大量使用了位运算(有关位运算的讲解, 可以参考React 算法之位运算).
首先引入作者对Lane的解释, 这里简单概括如下:
1、Lane类型被定义为二进制变量, 利用了位掩码的特性, 在频繁运算的时候占用内存少, 计算速度快.
Lane和Lanes就是单数和复数的关系, 代表单个任务的定义为Lane, 代表多个任务的定义为Lanes
2、Lane是对于expirationTime的重构, 以前使用expirationTime表示的字段, 都改为了lane
renderExpirationtime -> renderLanes
update.expirationTime -> update.lane
fiber.expirationTime -> fiber.lanes
fiber.childExpirationTime -> fiber.childLanes
root.firstPendingTime and root.lastPendingTime -> fiber.pendingLanes
3、使用Lanes模型相比expirationTime模型的优势:
a、Lanes把任务优先级从批量任务中分离出来, 可以更方便的判断单个任务与批量任务的优先级是否重叠.
// 判断: 单task与batchTask的优先级是否重叠
//1. 通过expirationTime判断
const isTaskIncludedInBatch = priorityOfTask >= priorityOfBatch;
//2. 通过Lanes判断
const isTaskIncludedInBatch = (task & batchOfTasks) !== 0;
// 当同时处理一组任务, 该组内有多个任务, 且每个任务的优先级不一致
// 1. 如果通过expirationTime判断. 需要维护一个范围(在Lane重构之前, 源码中就是这样比较的)
const isTaskIncludedInBatch =
taskPriority <= highestPriorityInRange &&
taskPriority >= lowestPriorityInRange;
//2. 通过Lanes判断
const isTaskIncludedInBatch = (task & batchOfTasks) !== 0;
b、Lanes使用单个 32 位二进制变量即可代表多个不同的任务, 也就是说一个变量即可代表一个组(group), 如果要在一个 group 中分离出单个 task, 非常容易.
在expirationTime模型设计之初, react 体系中还没有Suspense 异步渲染的概念. 现在有如下场景: 有 3 个任务, 其优先级 A > B > C, 正常来讲只需要按照优先级顺序执行就可以了. 但是现在情况变了: A 和 C 任务是CPU密集型, 而 B 是IO密集型(Suspense 会调用远程 api, 算是 IO 任务), 即 A(cpu) > B(IO) > C(cpu). 此时的需求需要将任务B从 group 中分离出来, 先处理 cpu 任务A和C.
// 从group中删除或增加task
//1. 通过expirationTime实现
// 0) 维护一个链表, 按照单个task的优先级顺序进行插入
// 1) 删除单个task(从链表中删除一个元素)
task.prev.next = task.next;
// 2) 增加单个task(需要对比当前task的优先级, 插入到链表正确的位置上)
let current = queue;
while (task.expirationTime >= current.expirationTime) {
current = current.next;
}
task.next = current.next;
current.next = task;
// 3) 比较task是否在group中
const isTaskIncludedInBatch =
taskPriority <= highestPriorityInRange &&
taskPriority >= lowestPriorityInRange;
// 2. 通过Lanes实现
// 1) 删除单个task
batchOfTasks &= ~task;
// 2) 增加单个task
batchOfTasks |= task;
// 3) 比较task是否在group中
const isTaskIncludedInBatch = (task & batchOfTasks) !== 0;
通过上述伪代码, 可以看到Lanes的优越性, 运用起来代码量少, 简洁高效.
4、Lanes是一个不透明的类型, 只能在ReactFiberLane.js这个模块中维护. 如果要在其他文件中使用, 只能通过ReactFiberLane.js中提供的工具函数来使用.
分析车道模型的源码(ReactFiberLane.js中), 可以得到如下结论:
1、可以使用的比特位一共有 31 位(为什么? 可以参考React 算法之位运算中的说明).
2、共定义了18 种车道(Lane/Lanes)变量, 每一个变量占有 1 个或多个比特位, 分别定义为Lane和Lanes类型.
3、每一种车道(Lane/Lanes)都有对应的优先级, 所以源码中定义了 18 种优先级(LanePriority).
4、占有低位比特位的Lane变量对应的优先级越高
-
最高优先级为SyncLanePriority对应的车道为SyncLane = 0b0000000000000000000000000000001.
-
最低优先级为OffscreenLanePriority对应的车道为OffscreenLane = 0b1000000000000000000000000000000.
优先级区别和联系
在源码中, 3 种优先级位于不同的 js 文件, 是相互独立的.
注意:
-
LanePriority和SchedulerPriority从命名上看, 它们代表的是优先级
-
ReactPriorityLevel从命名上看, 它代表的是等级而不是优先级, 它用于衡量LanePriority和SchedulerPriority的等级.
LanePriority
LanePriority: 属于react-reconciler包, 定义于ReactFiberLane.js(见源码).
export const SyncLanePriority: LanePriority = 15;
export const SyncBatchedLanePriority: LanePriority = 14;
const InputDiscreteHydrationLanePriority: LanePriority = 13;
export const InputDiscreteLanePriority: LanePriority = 12;
// .....
const OffscreenLanePriority: LanePriority = 1;
export const NoLanePriority: LanePriority = 0;
与fiber构造过程相关的优先级(如fiber.updateQueue,fiber.lanes)都使用LanePriority.
由于本节重点介绍优先级体系以及它们的转换关系, 关于Lane(车道模型)在fiber树构造时的具体使用, 在fiber 树构造章节详细解读.
SchedulerPriority
SchedulerPriority, 属于scheduler包, 定义于SchedulerPriorities.js中(见源码).
export const NoPriority = 0;
export const ImmediatePriority = 1;
export const UserBlockingPriority = 2;
export const NormalPriority = 3;
export const LowPriority = 4;
export const IdlePriority = 5;
与scheduler调度中心相关的优先级使用SchedulerPriority.
ReactPriorityLevel
reactPriorityLevel, 属于react-reconciler包, 定义于SchedulerWithReactIntegration.js中(见源码).
export const ImmediatePriority: ReactPriorityLevel = 99;
export const UserBlockingPriority: ReactPriorityLevel = 98;
export const NormalPriority: ReactPriorityLevel = 97;
export const LowPriority: ReactPriorityLevel = 96;
export const IdlePriority: ReactPriorityLevel = 95;
// NoPriority is the absence of priority. Also React-only.
export const NoPriority: ReactPriorityLevel = 90;
LanePriority与SchedulerPriority通过ReactPriorityLevel进行转换
转换关系
为了能协同调度中心(scheduler包)和 fiber 树构造(react-reconciler包)中对优先级的使用, 则需要转换SchedulerPriority和LanePriority, 转换的桥梁正是ReactPriorityLevel.
在SchedulerWithReactIntegration.js中, 可以互转SchedulerPriority 和 ReactPriorityLevel:
// 把 SchedulerPriority 转换成 ReactPriorityLevel
export function getCurrentPriorityLevel(): ReactPriorityLevel {
switch (Scheduler_getCurrentPriorityLevel()) {
case Scheduler_ImmediatePriority:
return ImmediatePriority;
case Scheduler_UserBlockingPriority:
return UserBlockingPriority;
case Scheduler_NormalPriority:
return NormalPriority;
case Scheduler_LowPriority:
return LowPriority;
case Scheduler_IdlePriority:
return IdlePriority;
default:
invariant(false, 'Unknown priority level.');
}
}
// 把 ReactPriorityLevel 转换成 SchedulerPriority
function reactPriorityToSchedulerPriority(reactPriorityLevel) {
switch (reactPriorityLevel) {
case ImmediatePriority:
return Scheduler_ImmediatePriority;
case UserBlockingPriority:
return Scheduler_UserBlockingPriority;
case NormalPriority:
return Scheduler_NormalPriority;
case LowPriority:
return Scheduler_LowPriority;
case IdlePriority:
return Scheduler_IdlePriority;
default:
invariant(false, 'Unknown priority level.');
}
}
在ReactFiberLane.js中, 可以互转LanePriority 和 ReactPriorityLevel:
export function schedulerPriorityToLanePriority(
schedulerPriorityLevel: ReactPriorityLevel,
): LanePriority {
switch (schedulerPriorityLevel) {
case ImmediateSchedulerPriority:
return SyncLanePriority;
// ... 省略部分代码
default:
return NoLanePriority;
}
}
export function lanePriorityToSchedulerPriority(
lanePriority: LanePriority,
): ReactPriorityLevel {
switch (lanePriority) {
case SyncLanePriority:
case SyncBatchedLanePriority:
return ImmediateSchedulerPriority;
// ... 省略部分代码
default:
invariant(
false,
'Invalid update priority: %s. This is a bug in React.',
lanePriority,
);
}
}
通过reconciler 运作流程中的归纳, reconciler从输入到输出一共经历了 4 个阶段, 在每个阶段中都会涉及到与优先级相关的处理. 正是通过优先级的灵活运用, React实现了可中断渲染,时间切片(time slicing),异步渲染(suspense)等特性.
在理解了优先级的基本思路之后, 接下来就正式进入 react 源码分析中的硬核部分(scheduler 调度原理和fiber树构造)
调度原理
在 React 运行时中, 调度中心(位于scheduler包), 是整个 React 运行时的中枢(其实是心脏), 所以理解scheduler调度, 就基本把握了 React 的命门.
在深入分析之前, 建议回顾一下往期与scheduler相关的文章(这 3 篇文章不长, 共 10 分钟能浏览完):
1、React 工作循环: 从宏观的角度介绍 React 体系中两个重要的循环, 其中任务调度循环就是本文的主角.
2、reconciler 运作流程: 从宏观的角度介绍了react-reconciler包的核心作用, 并把reconciler分为了 4 个阶段. 其中第 2 个阶段注册调度任务串联了scheduler包和react-reconciler包, 其实就是任务调度循环中的一个任务(task).
3、React 中的优先级管理: 介绍了 React 体系中的 3 中优先级的管理, 列出了源码中react-reconciler与scheduler包中关于优先级的转换思路. 其中SchedulerPriority控制任务调度循环中循环的顺序.
了解上述基础知识之后, 再谈scheduler原理, 其实就是在大的框架下去添加实现细节, 相对较为容易. 下面就正式进入主题.
内核
调度中心最核心的代码, 在SchedulerHostConfig.default.js中.
该 js 文件一共导出了 8 个函数, 最核心的逻辑, 就集中在了这 8 个函数中 :
export let requestHostCallback; // 请求及时回调: port.postMessage
export let cancelHostCallback; // 取消及时回调: scheduledHostCallback = null
export let requestHostTimeout; // 请求延时回调: setTimeout
export let cancelHostTimeout; // 取消延时回调: cancelTimeout
export let shouldYieldToHost; // 是否让出主线程(currentTime >= deadline && needsPaint): 让浏览器能够执行更高优先级的任务(如ui绘制, 用户输入等)
export let requestPaint; // 请求绘制: 设置 needsPaint = true
export let getCurrentTime; // 获取当前时间
export let forceFrameRate; // 强制设置 yieldInterval (让出主线程的周期). 这个函数虽然存在, 但是从源码来看, 几乎没有用到
我们知道 react 可以在 nodejs 环境中使用, 所以在不同的 js 执行环境中, 这些函数的实现会有区别. 下面基于普通浏览器环境, 对这 8 个函数逐一分析 :
1、调度相关
请求或取消调度
-
requestHostCallback
-
cancelHostCallback
-
requestHostTimeout
-
cancelHostTimeout
这 4 个函数源码很简洁, 非常好理解, 它们的目的就是请求执行(或取消)回调函数. 现在重点介绍其中的及时回调(延时回调的 2 个函数暂时属于保留 api, 17.0.2 版本其实没有用上)
// 接收 MessageChannel 消息
const performWorkUntilDeadline = () => {
// ...省略无关代码
if (scheduledHostCallback !== null) {
const currentTime = getCurrentTime();
// 更新deadline
deadline = currentTime + yieldInterval;
// 执行callback
scheduledHostCallback(hasTimeRemaining, currentTime);
} else {
isMessageLoopRunning = false;
}
};
const channel = new MessageChannel();
const port = channel.port2;
channel.port1.onmessage = performWorkUntilDeadline;
// 请求回调
requestHostCallback = function (callback) {
// 1. 保存callback
scheduledHostCallback = callback;
if (!isMessageLoopRunning) {
isMessageLoopRunning = true;
// 2. 通过 MessageChannel 发送消息
port.postMessage(null);
}
};
// 取消回调
cancelHostCallback = function () {
scheduledHostCallback = null;
};
很明显, 请求回调之后scheduledHostCallback = callback, 然后通过MessageChannel发消息的方式触发performWorkUntilDeadline函数, 最后执行回调scheduledHostCallback.
此处需要注意: MessageChannel在浏览器事件循环中属于宏任务, 所以调度中心永远是异步执行回调函数.
2、时间切片(time slicing)相关
执行时间分割, 让出主线程(把控制权归还浏览器, 浏览器可以处理用户输入, UI 绘制等紧急任务).
-
getCurrentTime: 获取当前时间
-
shouldYieldToHost: 是否让出主线程
-
requestPaint: 请求绘制
-
forceFrameRate: 强制设置 yieldInterval(从源码中的引用来看, 算一个保留函数, 其他地方没有用到)
const localPerformance = performance;
// 获取当前时间
getCurrentTime = () => localPerformance.now();
// 时间切片周期, 默认是5ms(如果一个task运行超过该周期, 下一个task执行之前, 会把控制权归还浏览器)
let yieldInterval = 5;
let deadline = 0;
const maxYieldInterval = 300;
let needsPaint = false;
const scheduling = navigator.scheduling;
// 是否让出主线程
shouldYieldToHost = function () {
const currentTime = getCurrentTime();
if (currentTime >= deadline) {
if (needsPaint || scheduling.isInputPending()) {
// There is either a pending paint or a pending input.
return true;
}
// There's no pending input. Only yield if we've reached the max
// yield interval.
return currentTime >= maxYieldInterval; // 在持续运行的react应用中, currentTime肯定大于300ms, 这个判断只在初始化过程中才有可能返回false
} else {
// There's still time left in the frame.
return false;
}
};
// 请求绘制
requestPaint = function () {
needsPaint = true;
};
// 设置时间切片的周期
forceFrameRate = function (fps) {
if (fps < 0 || fps > 125) {
// Using console['error'] to evade Babel and ESLint
console['error'](
'forceFrameRate takes a positive int between 0 and 125, ' +
'forcing frame rates higher than 125 fps is not supported',
);
return;
}
if (fps > 0) {
yieldInterval = Math.floor(1000 / fps);
} else {
// reset the framerate
yieldInterval = 5;
}
};
这 4 个函数代码都很简洁, 其功能在注释中都有解释.
注意shouldYieldToHost的判定条件:
-
currentTime >= deadline: 只有时间超过deadline之后才会让出主线程(其中deadline = currentTime + yieldInterval).
-
yieldInterval默认是5ms, 只能通过forceFrameRate函数来修改(事实上在 v17.0.2 源码中, 并没有使用到该函数).
-
如果一个task运行时间超过5ms, 下一个task执行之前, 会把控制权归还浏览器.
-
-
navigator.scheduling.isInputPending(): 这 facebook 官方贡献给 Chromium 的 api, 现在已经列入 W3C 标准(具体解释), 用于判断是否有输入事件(包括: input 框输入事件, 点击事件等).
介绍完这 8 个内部函数, 最后浏览一下完整回调的实现performWorkUntilDeadline(逻辑很清晰, 在注释中解释):
const performWorkUntilDeadline = () => {
if (scheduledHostCallback !== null) {
const currentTime = getCurrentTime(); // 1. 获取当前时间
deadline = currentTime + yieldInterval; // 2. 设置deadline
const hasTimeRemaining = true;
try {
// 3. 执行回调, 返回是否有还有剩余任务
const hasMoreWork = scheduledHostCallback(hasTimeRemaining, currentTime);
if (!hasMoreWork) {
// 没有剩余任务, 退出
isMessageLoopRunning = false;
scheduledHostCallback = null;
} else {
port.postMessage(null); // 有剩余任务, 发起新的调度
}
} catch (error) {
port.postMessage(null); // 如有异常, 重新发起调度
throw error;
}
} else {
isMessageLoopRunning = false;
}
needsPaint = false; // 重置开关
};
分析到这里, 可以得到调度中心的内核实现图:
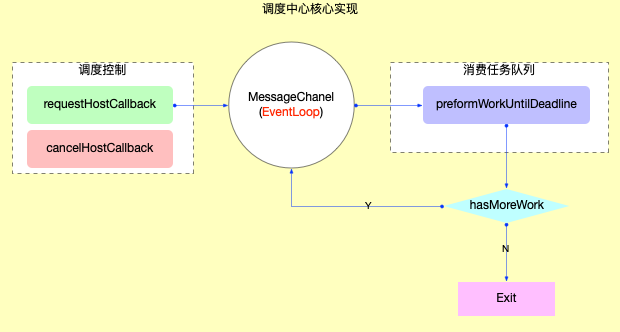
说明: 这个流程图很简单, 源码量也很少(总共不到 80 行), 但是它代表了scheduler的核心, 所以精华其实并不一定需要很多代码.
任务队列管理
通过上文的分析, 我们已经知道请求和取消调度的实现原理. 调度的目的是为了消费任务, 接下来就具体分析任务队列是如何管理与实现的.
在Scheduler.js中, 维护了一个taskQueue, 任务队列管理就是围绕这个taskQueue展开.
// Tasks are stored on a min heap
var taskQueue = [];
var timerQueue = [];
注意:
-
taskQueue是一个小顶堆数组, 关于堆排序的详细解释, 可以查看React 算法之堆排序.
-
源码中除了taskQueue队列之外还有一个timerQueue队列. 这个队列是预留给延时任务使用的, 在 react@17.0.2 版本里面, 从源码中的引用来看, 算一个保留功能, 没有用到.
创建任务
在unstable_scheduleCallback函数中(源码链接):
// 省略部分无关代码
function unstable_scheduleCallback(priorityLevel, callback, options) {
// 1. 获取当前时间
var currentTime = getCurrentTime();
var startTime;
if (typeof options === 'object' && options !== null) {
// 从函数调用关系来看, 在v17.0.2中,所有调用 unstable_scheduleCallback 都未传入options
// 所以省略延时任务相关的代码
} else {
startTime = currentTime;
}
// 2. 根据传入的优先级, 设置任务的过期时间 expirationTime
var timeout;
switch (priorityLevel) {
case ImmediatePriority:
timeout = IMMEDIATE_PRIORITY_TIMEOUT;
break;
case UserBlockingPriority:
timeout = USER_BLOCKING_PRIORITY_TIMEOUT;
break;
case IdlePriority:
timeout = IDLE_PRIORITY_TIMEOUT;
break;
case LowPriority:
timeout = LOW_PRIORITY_TIMEOUT;
break;
case NormalPriority:
default:
timeout = NORMAL_PRIORITY_TIMEOUT;
break;
}
var expirationTime = startTime + timeout;
// 3. 创建新任务
var newTask = {
id: taskIdCounter++,
callback,
priorityLevel,
startTime,
expirationTime,
sortIndex: -1,
};
if (startTime > currentTime) {
// 省略无关代码 v17.0.2中不会使用
} else {
newTask.sortIndex = expirationTime;
// 4. 加入任务队列
push(taskQueue, newTask);
// 5. 请求调度
if (!isHostCallbackScheduled && !isPerformingWork) {
isHostCallbackScheduled = true;
requestHostCallback(flushWork);
}
}
return newTask;
}
逻辑很清晰(在注释中已标明), 重点分析task对象的各个属性:
var newTask = {
id: taskIdCounter++, // id: 一个自增编号
callback, // callback: 传入的回调函数
priorityLevel, // priorityLevel: 优先级等级
startTime, // startTime: 创建task时的当前时间
expirationTime, // expirationTime: task的过期时间, 优先级越高 expirationTime = startTime + timeout 越小
sortIndex: -1,
};
newTask.sortIndex = expirationTime; // sortIndex: 排序索引, 全等于过期时间. 保证过期时间越小, 越紧急的任务排在最前面
消费任务
创建任务之后, 最后请求调度requestHostCallback(flushWork)(创建任务源码中的第 5 步), flushWork函数作为参数被传入调度中心内核等待回调. requestHostCallback函数在上文调度内核中已经介绍过了, 在调度中心中, 只需下一个事件循环就会执行回调, 最终执行flushWork.
// 省略无关代码
function flushWork(hasTimeRemaining, initialTime) {
// 1. 做好全局标记, 表示现在已经进入调度阶段
isHostCallbackScheduled = false;
isPerformingWork = true;
const previousPriorityLevel = currentPriorityLevel;
try {
// 2. 循环消费队列
return workLoop(hasTimeRemaining, initialTime);
} finally {
// 3. 还原全局标记
currentTask = null;
currentPriorityLevel = previousPriorityLevel;
isPerformingWork = false;
}
}
flushWork中调用了workLoop. 队列消费的主要逻辑是在workLoop函数中, 这就是React 工作循环一文中提到的任务调度循环.
// 省略部分无关代码
function workLoop(hasTimeRemaining, initialTime) {
let currentTime = initialTime; // 保存当前时间, 用于判断任务是否过期
currentTask = peek(taskQueue); // 获取队列中的第一个任务
while (currentTask !== null) {
if (
currentTask.expirationTime > currentTime &&
(!hasTimeRemaining || shouldYieldToHost())
) {
// 虽然currentTask没有过期, 但是执行时间超过了限制(毕竟只有5ms, shouldYieldToHost()返回true). 停止继续执行, 让出主线程
break;
}
const callback = currentTask.callback;
if (typeof callback === 'function') {
currentTask.callback = null;
currentPriorityLevel = currentTask.priorityLevel;
const didUserCallbackTimeout = currentTask.expirationTime <= currentTime;
// 执行回调
const continuationCallback = callback(didUserCallbackTimeout);
currentTime = getCurrentTime();
// 回调完成, 判断是否还有连续(派生)回调
if (typeof continuationCallback === 'function') {
// 产生了连续回调(如fiber树太大, 出现了中断渲染), 保留currentTask
currentTask.callback = continuationCallback;
} else {
// 把currentTask移出队列
if (currentTask === peek(taskQueue)) {
pop(taskQueue);
}
}
} else {
// 如果任务被取消(这时currentTask.callback = null), 将其移出队列
pop(taskQueue);
}
// 更新currentTask
currentTask = peek(taskQueue);
}
if (currentTask !== null) {
return true; // 如果task队列没有清空, 返回true. 等待调度中心下一次回调
} else {
return false; // task队列已经清空, 返回false.
}
}
workLoop就是一个大循环, 虽然代码也不多, 但是非常精髓, 在此处实现了时间切片(time slicing)和fiber树的可中断渲染. 这 2 大特性的实现, 都集中于这个while循环.
每一次while循环的退出就是一个时间切片, 深入分析while循环的退出条件:
1、队列被完全清空: 这种情况就是很正常的情况, 一气呵成, 没有遇到任何阻碍.
2、执行超时: 在消费taskQueue时, 在执行task.callback之前, 都会检测是否超时, 所以超时检测是以task为单位.
-
如果某个task.callback执行时间太长(如: fiber树很大, 或逻辑很重)也会造成超时
-
所以在执行task.callback过程中, 也需要一种机制检测是否超时, 如果超时了就立刻暂停task.callback的执行.
时间切片原理
消费任务队列的过程中, 可以消费1~n个 task, 甚至清空整个 queue. 但是在每一次具体执行task.callback之前都要进行超时检测, 如果超时可以立即退出循环并等待下一次调用.
可中断渲染原理
在时间切片的基础之上, 如果单个task.callback执行时间就很长(假设 200ms). 就需要task.callback自己能够检测是否超时, 所以在 fiber 树构造过程中, 每构造完成一个单元, 都会检测一次超时(源码链接), 如遇超时就退出fiber树构造循环, 并返回一个新的回调函数(就是此处的continuationCallback)并等待下一次回调继续未完成的fiber树构造.
节流防抖
通过上文的分析, 已经覆盖了scheduler包中的核心原理. 现在再次回到react-reconciler包中, 在调度过程中的关键路径中, 我们还需要理解一些细节.
在reconciler 运作流程中总结的 4 个阶段中, 注册调度任务属于第 2 个阶段, 核心逻辑位于ensureRootIsScheduled函数中. 现在我们已经理解了调度原理, 再次分析ensureRootIsScheduled(源码地址):
// ... 省略部分无关代码
function ensureRootIsScheduled(root: FiberRoot, currentTime: number) {
// 前半部分: 判断是否需要注册新的调度
const existingCallbackNode = root.callbackNode;
const nextLanes = getNextLanes(
root,
root === workInProgressRoot ? workInProgressRootRenderLanes : NoLanes,
);
const newCallbackPriority = returnNextLanesPriority();
if (nextLanes === NoLanes) {
return;
}
// 节流防抖
if (existingCallbackNode !== null) {
const existingCallbackPriority = root.callbackPriority;
if (existingCallbackPriority === newCallbackPriority) {
return;
}
cancelCallback(existingCallbackNode);
}
// 后半部分: 注册调度任务 省略代码...
// 更新标记
root.callbackPriority = newCallbackPriority;
root.callbackNode = newCallbackNode;
}
正常情况下, ensureRootIsScheduled函数会与scheduler包通信, 最后注册一个task并等待回调.
1、在task注册完成之后, 会设置fiberRoot对象上的属性(fiberRoot是 react 运行时中的重要全局对象, 可参考React 应用的启动过程), 代表现在已经处于调度进行中
2、再次进入ensureRootIsScheduled时(比如连续 2 次setState, 第 2 次setState同样会触发reconciler运作流程中的调度阶段), 如果发现处于调度中, 则需要一些节流和防抖措施, 进而保证调度性能.
-
节流(判断条件: existingCallbackPriority === newCallbackPriority, 新旧更新的优先级相同, 如连续多次执行setState), 则无需注册新task(继续沿用上一个优先级相同的task), 直接退出调用.
-
防抖(判断条件: existingCallbackPriority !== newCallbackPriority, 新旧更新的优先级不同), 则取消旧task, 重新注册新task.
本节主要分析了scheduler包中调度原理, 也就是React两大工作循环中的任务调度循环. 并介绍了时间切片和可中断渲染等特性在任务调度循环中的实现. scheduler包是React运行时的心脏, 为了提升调度性能, 注册task之前, 在react-reconciler包中做了节流和防抖等措施.
fiber 树构造(基础准备)
在 React 运行时中, fiber树构造位于react-reconciler包.
在正式解读fiber树构造之前, 再次回顾一下reconciler 运作流程的 4 个阶段:
1、输入阶段: 衔接react-dom包, 承接fiber更新请求(可以参考React 应用的启动过程).
2、注册调度任务: 与调度中心(scheduler包)交互, 注册调度任务task, 等待任务回调(可以参考React 调度原理(scheduler)).
3、执行任务回调: 在内存中构造出fiber树和DOM对象, 也是fiber 树构造的重点内容.
4、输出: 与渲染器(react-dom)交互, 渲染DOM节点.
fiber树构造处于上述第 3 个阶段, 可以通过不同的视角来理解fiber树构造在React运行时中所处的位置:
-
从scheduler调度中心的角度来看, 它是任务队列taskQueue中的一个具体的任务回调(task.callback).
-
从React 工作循环的角度来看, 它属于fiber树构造循环.
由于fiber 树构造源码量比较大, 本系列根据React运行的内存状态, 分为 2 种情况来说明:
1、初次创建: 在React应用首次启动时, 界面还没有渲染, 此时并不会进入对比过程, 相当于直接构造一棵全新的树.
2、对比更新: React应用启动后, 界面已经渲染. 如果再次发生更新, 创建新fiber之前需要和旧fiber进行对比. 最后构造的 fiber 树有可能是全新的, 也可能是部分更新的.
无论是初次创建还是对比更新, 基础概念都是通用的, 本节将介绍这些基础知识, 为正式进入fiber树构造做准备.
ReactElement, Fiber, DOM 三者的关系
在React 应用中的高频对象一文中, 已经介绍了ReactElement和Fiber对象的数据结构. 这里我们梳理出ReactElement, Fiber, DOM这 3 种对象的关系
1、ReactElement 对象(type 定义在shared 包中)
- 所有采用jsx语法书写的节点, 都会被编译器转换, 最终会以React.createElement(…)的方式, 创建出来一个与之对应的ReactElement对象
2、fiber 对象(type 类型的定义在ReactInternalTypes.js中)
- fiber对象是通过ReactElement对象进行创建的, 多个fiber对象构成了一棵fiber树, fiber树是构造DOM树的数据模型, fiber树的任何改动, 最后都体现到DOM树.
3、DOM 对象: 文档对象模型
-
DOM将文档解析为一个由节点和对象(包含属性和方法的对象)组成的结构集合, 也就是常说的DOM树.
-
JavaScript可以访问和操作存储在 DOM 中的内容, 也就是操作DOM对象, 进而触发 UI 渲染.
它们之间的关系反映了我们书写的 JSX 代码到 DOM 节点的转换过程:
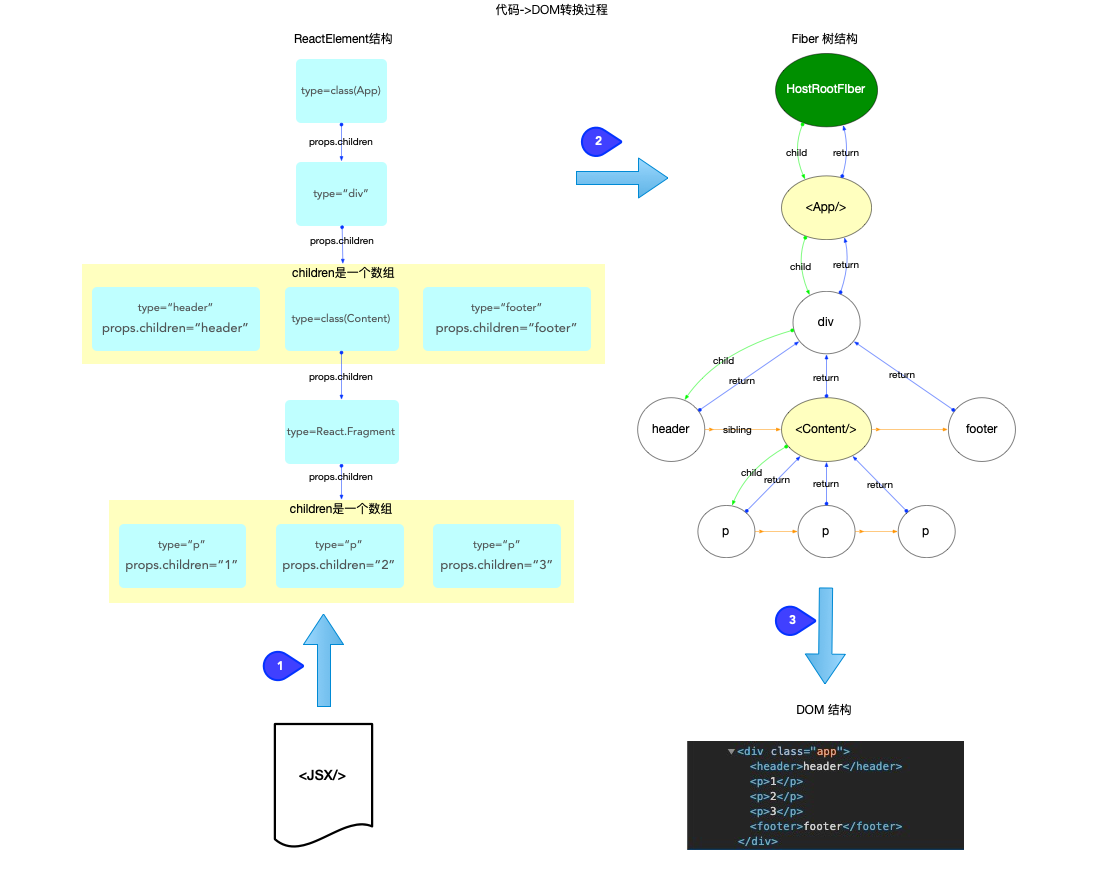
注意:
-
开发人员能够控制的是JSX, 也就是ReactElement对象.
-
fiber树是通过ReactElement生成的, 如果脱离了ReactElement,fiber树也无从谈起. 所以是ReactElement树(不是严格的树结构, 为了方便也称为树)驱动fiber树.
-
fiber树是DOM树的数据模型, fiber树驱动DOM树
开发人员通过编程只能控制ReactElement树的结构, ReactElement树驱动fiber树, fiber树再驱动DOM树, 最后展现到页面上. 所以fiber树的构造过程, 实际上就是ReactElement对象到fiber对象的转换过程.
全局变量
从React 工作循环的角度来看, 整个构造过程被包裹在fiber树构造循环中(对应源码位于ReactFiberWorkLoop.js).
在React运行时, ReactFiberWorkLoop.js闭包中的全局变量会随着fiber树构造循环的进行而变化, 现在查看其中重要的全局变量(源码链接):
// 当前React的执行栈(执行上下文)
let executionContext: ExecutionContext = NoContext;
// 当前root节点
let workInProgressRoot: FiberRoot | null = null;
// 正在处理中的fiber节点
let workInProgress: Fiber | null = null;
// 正在渲染的车道(复数)
let workInProgressRootRenderLanes: Lanes = NoLanes;
// 包含所有子节点的优先级, 是workInProgressRootRenderLanes的超集
// 大多数情况下: 在工作循环整体层面会使用workInProgressRootRenderLanes, 在begin/complete阶段层面会使用 subtreeRenderLanes
let subtreeRenderLanes: Lanes = NoLanes;
// 一个栈结构: 专门存储当前节点的 subtreeRenderLanes
const subtreeRenderLanesCursor: StackCursor<Lanes> = createCursor(NoLanes);
// fiber构造完后, root节点的状态: completed, errored, suspended等
let workInProgressRootExitStatus: RootExitStatus = RootIncomplete;
// 重大错误
let workInProgressRootFatalError: mixed = null;
// 整个render期间所使用到的所有lanes
let workInProgressRootIncludedLanes: Lanes = NoLanes;
// 在render期间被跳过(由于优先级不够)的lanes: 只包括未处理的updates, 不包括被复用的fiber节点
let workInProgressRootSkippedLanes: Lanes = NoLanes;
// 在render期间被修改过的lanes
let workInProgressRootUpdatedLanes: Lanes = NoLanes;
// 防止无限循环和嵌套更新
const NESTED_UPDATE_LIMIT = 50;
let nestedUpdateCount: number = 0;
let rootWithNestedUpdates: FiberRoot | null = null;
const NESTED_PASSIVE_UPDATE_LIMIT = 50;
let nestedPassiveUpdateCount: number = 0;
// 发起更新的时间
let currentEventTime: number = NoTimestamp;
let currentEventWipLanes: Lanes = NoLanes;
let currentEventPendingLanes: Lanes = NoLanes;
在源码中, 大部分变量都带有英文注释(读者可自行查阅), 此处只列举了fiber树构造循环中最核心的变量
执行上下文
在全局变量中有executionContext, 代表渲染期间的执行栈(或叫做执行上下文), 它也是一个二进制表示的变量, 通过位运算进行操作(参考React 算法之位运算). 在源码中一共定义了 8 种执行栈:
type ExecutionContext = number;
export const NoContext = /* */ 0b0000000;
const BatchedContext = /* */ 0b0000001;
const EventContext = /* */ 0b0000010;
const DiscreteEventContext = /* */ 0b0000100;
const LegacyUnbatchedContext = /* */ 0b0001000;
const RenderContext = /* */ 0b0010000;
const CommitContext = /* */ 0b0100000;
上文回顾了reconciler 运作流程的 4 个阶段, 这 4 个阶段只是一个整体划分. 如果具体到每一次更新, 是有差异的. 比如说: Legacy模式下的首次更新, 不会经过调度中心(第 2 阶段),而是直接进入fiber树构造(第 3 阶段).
事实上正是executionContext在操控reconciler 运作流程(源码体现在scheduleUpdateOnFiber 函数).
export function scheduleUpdateOnFiber(
fiber: Fiber,
lane: Lane,
eventTime: number,
) {
if (lane === SyncLane) {
// legacy或blocking模式
if (
(executionContext & LegacyUnbatchedContext) !== NoContext &&
(executionContext & (RenderContext | CommitContext)) === NoContext
) {
performSyncWorkOnRoot(root);
} else {
// 后续的更新
// 进入第2阶段, 注册调度任务
ensureRootIsScheduled(root, eventTime);
if (executionContext === NoContext) {
// 如果执行上下文为空, 会取消调度任务, 手动执行回调
// 进入第3阶段, 进行fiber树构造
flushSyncCallbackQueue();
}
}
} else {
// concurrent模式
// 无论是否初次更新, 都正常进入第2阶段, 注册调度任务
ensureRootIsScheduled(root, eventTime);
}
}
在 render 过程中, 每一个阶段都会改变executionContext(render 之前, 会设置executionContext |= RenderContext; commit 之前, 会设置executionContext |= CommitContext), 假设在render过程中再次发起更新(如在UNSAFE_componentWillReceiveProps生命周期中调用setState)则可通过executionContext来判断当前的render状态.
双缓冲技术(double buffering)
在全局变量中有workInProgress, 还有不少以workInProgress来命名的变量. workInProgress的应用实际上就是React的双缓冲技术(double buffering).
在上文我们梳理了ReactElement, Fiber, DOM三者的关系, fiber树的构造过程, 就是把ReactElement转换成fiber树的过程. 在这个过程中, 内存里会同时存在 2 棵fiber树:
-
其一: 代表当前界面的fiber树(已经被展示出来, 挂载到fiberRoot.current上). 如果是初次构造(初始化渲染), 页面还没有渲染, 此时界面对应的 fiber 树为空(fiberRoot.current = null).
-
其二: 正在构造的fiber树(即将展示出来, 挂载到HostRootFiber.alternate上, 正在构造的节点称为workInProgress). 当构造完成之后, 重新渲染页面, 最后切换fiberRoot.current = workInProgress, 使得fiberRoot.current重新指向代表当前界面的fiber树.
此处涉及到 2 个全局对象fiberRoot和HostRootFiber, 在React 应用的启动过程中有详细的说明.
用图来表述double buffering的概念如下:
1、构造过程中, fiberRoot.current指向当前界面对应的fiber树.
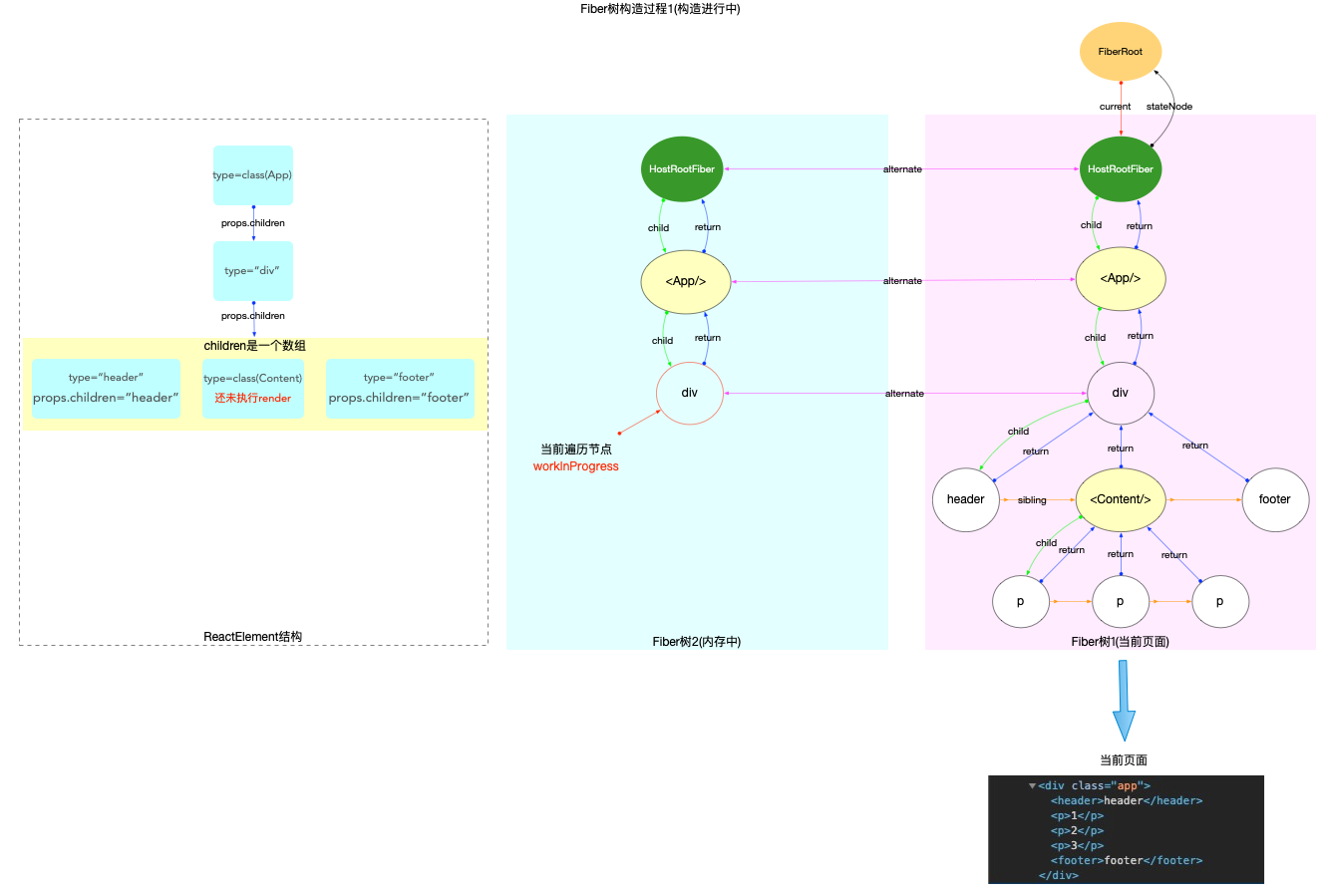
2、构造完成并渲染, 切换fiberRoot.current指针, 使其继续指向当前界面对应的fiber树(原来代表界面的 fiber 树, 变成了内存中).
优先级
在全局变量中有不少变量都以 Lanes 命名(如workInProgressRootRenderLanes,subtreeRenderLanes其作用见上文注释), 它们都与优先级相关.
在前文React 中的优先级管理中, 我们介绍了React中有 3 套优先级体系, 并了解了它们之间的关联. 现在fiber树构造过程中, 将要深入分析车道模型Lane的具体应用.
在整个react-reconciler包中, Lane的应用可以分为 3 个方面:
update优先级
在React 应用中的高频对象一文中, 介绍过update对象, 它是一个环形链表. 对于单个update对象来讲, update.lane代表它的优先级, 称之为update优先级.
观察其构造函数(源码链接),其优先级是由外界传入.
export function createUpdate(eventTime: number, lane: Lane): Update<*> {
const update: Update<*> = {
eventTime,
lane,
tag: UpdateState,
payload: null,
callback: null,
next: null,
};
return update;
}
在React体系中, 有 2 种情况会创建update对象:
1、应用初始化: 在react-reconciler包中的updateContainer函数中(源码)
export function updateContainer(
element: ReactNodeList,
container: OpaqueRoot,
parentComponent: ?React$Component<any, any>,
callback: ?Function,
): Lane {
const current = container.current;
const eventTime = requestEventTime();
const lane = requestUpdateLane(current); // 根据当前时间, 创建一个update优先级
const update = createUpdate(eventTime, lane); // lane被用于创建update对象
update.payload = { element };
enqueueUpdate(current, update);
scheduleUpdateOnFiber(current, lane, eventTime);
return lane;
}
2、发起组件更新: 假设在 class 组件中调用setState(源码)
const classComponentUpdater = {
isMounted,
enqueueSetState(inst, payload, callback) {
const fiber = getInstance(inst);
const eventTime = requestEventTime(); // 根据当前时间, 创建一个update优先级
const lane = requestUpdateLane(fiber); // lane被用于创建update对象
const update = createUpdate(eventTime, lane);
update.payload = payload;
enqueueUpdate(fiber, update);
scheduleUpdateOnFiber(fiber, lane, eventTime);
},
};
可以看到, 无论是应用初始化或者发起组件更新, 创建update.lane的逻辑都是一样的, 都是根据当前时间, 创建一个 update 优先级.
requestUpdateLane
export function requestUpdateLane(fiber: Fiber): Lane {
// Special cases
const mode = fiber.mode;
if ((mode & BlockingMode) === NoMode) {
// legacy 模式
return (SyncLane: Lane);
} else if ((mode & ConcurrentMode) === NoMode) {
// blocking模式
return getCurrentPriorityLevel() === ImmediateSchedulerPriority
? (SyncLane: Lane)
: (SyncBatchedLane: Lane);
}
// concurrent模式
if (currentEventWipLanes === NoLanes) {
currentEventWipLanes = workInProgressRootIncludedLanes;
}
const isTransition = requestCurrentTransition() !== NoTransition;
if (isTransition) {
// 特殊情况, 处于suspense过程中
if (currentEventPendingLanes !== NoLanes) {
currentEventPendingLanes =
mostRecentlyUpdatedRoot !== null
? mostRecentlyUpdatedRoot.pendingLanes
: NoLanes;
}
return findTransitionLane(currentEventWipLanes, currentEventPendingLanes);
}
// 正常情况, 获取调度优先级
const schedulerPriority = getCurrentPriorityLevel();
let lane;
if (
(executionContext & DiscreteEventContext) !== NoContext &&
schedulerPriority === UserBlockingSchedulerPriority
) {
// executionContext 存在输入事件. 且调度优先级是用户阻塞性质
lane = findUpdateLane(InputDiscreteLanePriority, currentEventWipLanes);
} else {
// 调度优先级转换为车道模型
const schedulerLanePriority =
schedulerPriorityToLanePriority(schedulerPriority);
lane = findUpdateLane(schedulerLanePriority, currentEventWipLanes);
}
return lane;
}
可以看到requestUpdateLane的作用是返回一个合适的 update 优先级.
1、legacy 模式: 返回SyncLane
2、blocking 模式: 返回SyncLane
3、concurrent 模式:
-
正常情况下, 根据当前的调度优先级来生成一个lane.
-
特殊情况下(处于 suspense 过程中), 会优先选择TransitionLanes通道中的空闲通道(如果所有TransitionLanes通道都被占用, 就取最高优先级. 源码).
最后通过scheduleUpdateOnFiber(current, lane, eventTime);函数, 把update.lane正式带入到了输入阶段.
scheduleUpdateOnFiber是输入阶段的必经函数, 在本系列的文章中已经多次提到, 此处以update.lane的视角分析:
export function scheduleUpdateOnFiber(
fiber: Fiber,
lane: Lane,
eventTime: number,
) {
if (lane === SyncLane) {
// legacy或blocking模式
if (
(executionContext & LegacyUnbatchedContext) !== NoContext &&
(executionContext & (RenderContext | CommitContext)) === NoContext
) {
performSyncWorkOnRoot(root);
} else {
ensureRootIsScheduled(root, eventTime); // 注册回调任务
if (executionContext === NoContext) {
flushSyncCallbackQueue(); // 取消schedule调度 ,主动刷新回调队列,
}
}
} else {
// concurrent模式
ensureRootIsScheduled(root, eventTime);
}
}
当lane === SyncLane也就是 legacy 或 blocking 模式中, 注册完回调任务之后(ensureRootIsScheduled(root, eventTime)), 如果执行上下文为空, 会取消 schedule 调度, 主动刷新回调队列flushSyncCallbackQueue().
这里包含了一个热点问题(setState到底是同步还是异步)的标准答案:
-
如果逻辑进入flushSyncCallbackQueue(executionContext === NoContext), 则会主动取消调度, 并刷新回调, 立即进入fiber树构造过程. 当执行setState下一行代码时, fiber树已经重新渲染了, 故setState体现为同步.
-
正常情况下, 不会取消schedule调度. 由于schedule调度是通过MessageChannel触发(宏任务), 故体现为异步.
渲染优先级
这是一个全局概念, 每一次render之前, 首先要确定本次render的优先级. 具体对应到源码如下:
// ...省略无关代码
function performSyncWorkOnRoot(root) {
let lanes;
let exitStatus;
// 获取本次`render`的优先级
lanes = getNextLanes(root, lanes);
exitStatus = renderRootSync(root, lanes);
}
// ...省略无关代码
function performConcurrentWorkOnRoot(root) {
// 获取本次`render`的优先级
let lanes = getNextLanes(
root,
root === workInProgressRoot ? workInProgressRootRenderLanes : NoLanes,
);
if (lanes === NoLanes) {
return null;
}
let exitStatus = renderRootConcurrent(root, lanes);
}
可以看到, 无论是Legacy还是Concurrent模式, 在正式render之前, 都会调用getNextLanes获取一个优先级(源码链接).
// ...省略部分代码
export function getNextLanes(root: FiberRoot, wipLanes: Lanes): Lanes {
// 1. check是否有等待中的lanes
const pendingLanes = root.pendingLanes;
if (pendingLanes === NoLanes) {
return_highestLanePriority = NoLanePriority;
return NoLanes;
}
let nextLanes = NoLanes;
let nextLanePriority = NoLanePriority;
const expiredLanes = root.expiredLanes;
const suspendedLanes = root.suspendedLanes;
const pingedLanes = root.pingedLanes;
// 2. check是否有已过期的lanes
if (expiredLanes !== NoLanes) {
nextLanes = expiredLanes;
nextLanePriority = return_highestLanePriority = SyncLanePriority;
} else {
const nonIdlePendingLanes = pendingLanes & NonIdleLanes;
if (nonIdlePendingLanes !== NoLanes) {
// 非Idle任务 ...
} else {
// Idle任务 ...
}
}
if (nextLanes === NoLanes) {
return NoLanes;
}
return nextLanes;
}
getNextLanes会根据fiberRoot对象上的属性(expiredLanes, suspendedLanes, pingedLanes等), 确定出当前最紧急的lanes.
此处返回的lanes会作为全局渲染的优先级, 用于fiber树构造过程中. 针对fiber对象或update对象, 只要它们的优先级(如: fiber.lanes和update.lane)比渲染优先级低, 都将会被忽略.
fiber优先级
在React 应用中的高频对象一文中, 介绍过fiber对象的数据结构. 其中有 2 个属性与优先级相关:
1、fiber.lanes: 代表本节点的优先级
2、fiber.childLanes: 代表子节点的优先级
从FiberNode的构造函数中可以看出, fiber.lanes和fiber.childLanes的初始值都为NoLanes, 在fiber树构造过程中, 使用全局的渲染优先级(renderLanes)和fiber.lanes判断fiber节点是否更新(源码地址).
-
如果全局的渲染优先级renderLanes不包括fiber.lanes, 证明该fiber节点没有更新, 可以复用.
-
如果不能复用, 进入创建阶段.
function beginWork(
current: Fiber | null,
workInProgress: Fiber,
renderLanes: Lanes,
): Fiber | null {
const updateLanes = workInProgress.lanes;
if (current !== null) {
const oldProps = current.memoizedProps;
const newProps = workInProgress.pendingProps;
if (
oldProps !== newProps ||
hasLegacyContextChanged() ||
// Force a re-render if the implementation changed due to hot reload:
(__DEV__ ? workInProgress.type !== current.type : false)
) {
didReceiveUpdate = true;
} else if (!includesSomeLane(renderLanes, updateLanes)) {
didReceiveUpdate = false;
// 本`fiber`节点的没有更新, 可以复用, 进入bailout逻辑
return bailoutOnAlreadyFinishedWork(current, workInProgress, renderLanes);
}
}
// 不能复用, 创建新的fiber节点
workInProgress.lanes = NoLanes; // 重置优先级为 NoLanes
switch (workInProgress.tag) {
case ClassComponent: {
const Component = workInProgress.type;
const unresolvedProps = workInProgress.pendingProps;
const resolvedProps =
workInProgress.elementType === Component
? unresolvedProps
: resolveDefaultProps(Component, unresolvedProps);
return updateClassComponent(
current,
workInProgress,
Component,
resolvedProps,
// 正常情况下渲染优先级会被用于fiber树的构造过程
renderLanes,
);
}
}
}
栈帧管理
在React源码中, 每一次执行fiber树构造(也就是调用performSyncWorkOnRoot或者performConcurrentWorkOnRoot函数)的过程, 都需要一些全局变量来保存状态. 在上文中已经介绍最核心的全局变量.
如果从单个变量来看, 它们就是一个个的全局变量. 如果将这些全局变量组合起来, 它们代表了当前fiber树构造的活动记录. 通过这一组全局变量, 可以还原fiber树构造过程(比如时间切片的实现过程(参考React 调度原理), fiber树构造过程被打断之后需要还原进度, 全靠这一组全局变量). 所以每次fiber树构造是一个独立的过程, 需要独立的一组全局变量, 在React内部把这一个独立的过程封装为一个栈帧stack(简单来说就是每次构造都需要独立的空间. 对于栈帧的深入理解, 请读者自行参考其他资料).
所以在进行fiber树构造之前, 如果不需要恢复上一次构造进度, 都会刷新栈帧(源码在prepareFreshStack 函数)
function renderRootConcurrent(root: FiberRoot, lanes: Lanes) {
const prevExecutionContext = executionContext;
executionContext |= RenderContext;
const prevDispatcher = pushDispatcher();
// 如果fiberRoot变动, 或者update.lane变动, 都会刷新栈帧, 丢弃上一次渲染进度
if (workInProgressRoot !== root || workInProgressRootRenderLanes !== lanes) {
resetRenderTimer();
// 刷新栈帧
prepareFreshStack(root, lanes);
startWorkOnPendingInteractions(root, lanes);
}
}
/**
刷新栈帧: 重置 FiberRoot上的全局属性 和 `fiber树构造`循环过程中的全局变量
*/
function prepareFreshStack(root: FiberRoot, lanes: Lanes) {
// 重置FiberRoot对象上的属性
root.finishedWork = null;
root.finishedLanes = NoLanes;
const timeoutHandle = root.timeoutHandle;
if (timeoutHandle !== noTimeout) {
root.timeoutHandle = noTimeout;
cancelTimeout(timeoutHandle);
}
if (workInProgress !== null) {
let interruptedWork = workInProgress.return;
while (interruptedWork !== null) {
unwindInterruptedWork(interruptedWork);
interruptedWork = interruptedWork.return;
}
}
// 重置全局变量
workInProgressRoot = root;
workInProgress = createWorkInProgress(root.current, null); // 给HostRootFiber对象创建一个alternate, 并将其设置成全局 workInProgress
workInProgressRootRenderLanes =
subtreeRenderLanes =
workInProgressRootIncludedLanes =
lanes;
workInProgressRootExitStatus = RootIncomplete;
workInProgressRootFatalError = null;
workInProgressRootSkippedLanes = NoLanes;
workInProgressRootUpdatedLanes = NoLanes;
workInProgressRootPingedLanes = NoLanes;
}
注意其中的createWorkInProgress(root.current, null), 其参数root.current即HostRootFiber, 作用是给HostRootFiber创建一个alternate副本.workInProgress指针指向这个副本(即workInProgress = HostRootFiber.alternate), 在上文double buffering中分析过, HostRootFiber.alternate是正在构造的fiber树的根节点.
本节是fiber树构造的准备篇, 首先在宏观上从不同的视角(任务调度循环, fiber树构造循环)介绍了fiber树构造在React体系中所处的位置, 然后深入react-reconciler包分析fiber树构造过程中需要使用到的全局变量, 并解读了双缓冲技术和优先级(车道模型)的使用, 最后解释栈帧管理的实现细节. 有了这些基础知识, fiber树构造的具体实现过程会更加简单清晰.
fiber 树构造(初次创建)
本节的内容完全建立在前文fiber 树构造(基础准备)中介绍的基础知识之上, 其中总结了fiber 树构造的 2 种情况:
1、初次创建: 在React应用首次启动时, 界面还没有渲染, 此时并不会进入对比过程, 相当于直接构造一棵全新的树.
2、对比更新: React应用启动后, 界面已经渲染. 如果再次发生更新, 创建新fiber之前需要和旧fiber进行对比. 最后构造的 fiber 树有可能是全新的, 也可能是部分更新的.
本节只讨论初次创建这种情况, 为了控制篇幅(本节直击核心源码, 不再介绍基础知识, 可参照fiber 树构造(基础准备))并突出fiber 树构造过程, 后文会在Legacy模式下进行分析(因为只讨论fiber树构造原理, Concurrent模式与Legacy没有区别).
本节示例代码如下(codesandbox 地址):
class App extends React.Component {
componentDidMount() {
console.log(`App Mount`);
console.log(`App 组件对应的fiber节点: `, this._reactInternals);
}
render() {
return (
<div className="app">
<header>header</header>
<Content />
</div>
);
}
}
class Content extends React.Component {
componentDidMount() {
console.log(`Content Mount`);
console.log(`Content 组件对应的fiber节点: `, this._reactInternals);
}
render() {
return (
<React.Fragment>
<p>1</p>
<p>2</p>
</React.Fragment>
);
}
}
export default App;
启动阶段
在前文React 应用的启动过程中分析了 3 种启动模式的差异, 在进入react-reconciler包之前(调用updateContainer之前), 内存状态图如下:
根据这个结构, 可以在控制台中打出当前页面对应的fiber树(用于观察其结构):
document.getElementById('root')._reactRootContainer._internalRoot.current;
然后进入react-reconciler包调用updateContainer 函数:
// ... 省略了部分代码
export function updateContainer(
element: ReactNodeList,
container: OpaqueRoot,
parentComponent: ?React$Component<any, any>,
callback: ?Function,
): Lane {
// 获取当前时间戳
const current = container.current;
const eventTime = requestEventTime();
// 1. 创建一个优先级变量(车道模型)
const lane = requestUpdateLane(current);
// 2. 根据车道优先级, 创建update对象, 并加入fiber.updateQueue.pending队列
const update = createUpdate(eventTime, lane);
update.payload = { element };
callback = callback === undefined ? null : callback;
if (callback !== null) {
update.callback = callback;
}
enqueueUpdate(current, update);
// 3. 进入reconciler运作流程中的`输入`环节
scheduleUpdateOnFiber(current, lane, eventTime);
return lane;
}
由于update对象的创建, 此时的内存结构如下:
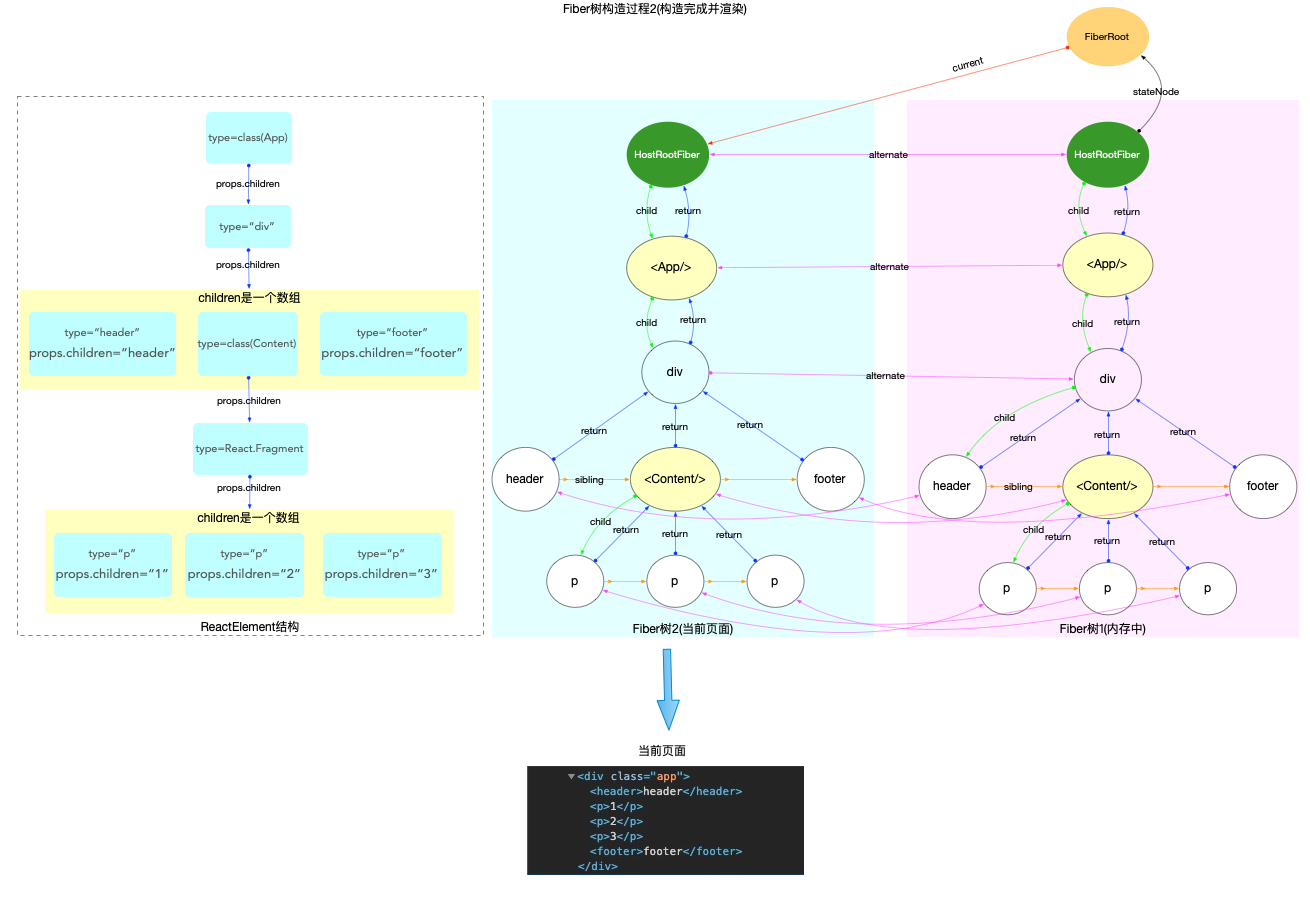
注意: 最初的ReactElement对象<App/>被挂载到HostRootFiber.updateQueue.shared.pending.payload.element中, 后文fiber树构造过程中会再次变动.
构造阶段
为了突出构造过程,排除干扰,先把内存状态图中的FiberRoot和HostRootFiber单独提出来(后文在此基础上添加):
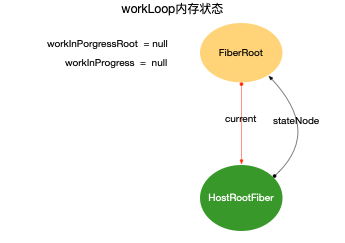
在scheduleUpdateOnFiber 函数中:
// ...省略部分代码
export function scheduleUpdateOnFiber(
fiber: Fiber,
lane: Lane,
eventTime: number,
) {
// 标记优先级
const root = markUpdateLaneFromFiberToRoot(fiber, lane);
if (lane === SyncLane) {
if (
(executionContext & LegacyUnbatchedContext) !== NoContext &&
(executionContext & (RenderContext | CommitContext)) === NoContext
) {
// 首次渲染, 直接进行`fiber构造`
performSyncWorkOnRoot(root);
}
// ...
}
}
可以看到, 在Legacy模式下且首次渲染时, 有 2 个函数markUpdateLaneFromFiberToRoot和performSyncWorkOnRoot.
其中markUpdateLaneFromFiberToRoot(fiber, lane)函数在fiber树构造(对比更新)中才会发挥作用, 因为在初次创建时并没有与当前页面所对应的fiber树, 所以核心代码并没有执行, 最后直接返回了FiberRoot对象.
performSyncWorkOnRoot看起来源码很多, 初次创建中真正用到的就 2 个函数:
function performSyncWorkOnRoot(root) {
let lanes;
let exitStatus;
if (
root === workInProgressRoot &&
includesSomeLane(root.expiredLanes, workInProgressRootRenderLanes)
) {
// 初次构造时(因为root=fiberRoot, workInProgressRoot=null), 所以不会进入
} else {
// 1. 获取本次render的优先级, 初次构造返回 NoLanes
lanes = getNextLanes(root, NoLanes);
// 2. 从root节点开始, 至上而下更新
exitStatus = renderRootSync(root, lanes);
}
// 将最新的fiber树挂载到root.finishedWork节点上
const finishedWork: Fiber = (root.current.alternate: any);
root.finishedWork = finishedWork;
root.finishedLanes = lanes;
// 进入commit阶段
commitRoot(root);
// ...后面的内容本节不讨论
}
其中getNextLanes返回本次 render 的渲染优先级(详见fiber 树构造(基础准备)中优先级相关小节)
renderRootSync
function renderRootSync(root: FiberRoot, lanes: Lanes) {
const prevExecutionContext = executionContext;
executionContext |= RenderContext;
// 如果fiberRoot变动, 或者update.lane变动, 都会刷新栈帧, 丢弃上一次渲染进度
if (workInProgressRoot !== root || workInProgressRootRenderLanes !== lanes) {
// 刷新栈帧, legacy模式下都会进入
prepareFreshStack(root, lanes);
}
do {
try {
workLoopSync();
break;
} catch (thrownValue) {
handleError(root, thrownValue);
}
} while (true);
executionContext = prevExecutionContext;
// 重置全局变量, 表明render结束
workInProgressRoot = null;
workInProgressRootRenderLanes = NoLanes;
return workInProgressRootExitStatus;
}
在renderRootSync中, 在执行fiber树构造前(workLoopSync)会先刷新栈帧prepareFreshStack(参考fiber 树构造(基础准备)).在这里创建了HostRootFiber.alternate, 重置全局变量workInProgress和workInProgressRoot等.
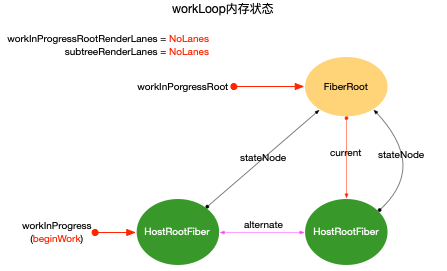
逻辑来到workLoopSync, 虽然本节在Legacy模式下进行讨论, 此处还是对比一下workLoopConcurrent
function workLoopSync() {
while (workInProgress !== null) {
performUnitOfWork(workInProgress);
}
}
function workLoopConcurrent() {
// Perform work until Scheduler asks us to yield
while (workInProgress !== null && !shouldYield()) {
performUnitOfWork(workInProgress);
}
}
可以看到workLoopConcurrent相比于Sync, 会多一个停顿机制, 这个机制实现了时间切片和可中断渲染(参考React 调度原理)
结合performUnitOfWork函数(源码地址)
// ... 省略部分无关代码
function performUnitOfWork(unitOfWork: Fiber): void {
// unitOfWork就是被传入的workInProgress
const current = unitOfWork.alternate;
let next;
next = beginWork(current, unitOfWork, subtreeRenderLanes);
unitOfWork.memoizedProps = unitOfWork.pendingProps;
if (next === null) {
// 如果没有派生出新的节点, 则进入completeWork阶段, 传入的是当前unitOfWork
completeUnitOfWork(unitOfWork);
} else {
workInProgress = next;
}
}
可以明显的看出, 整个fiber树构造是一个深度优先遍历(可参考React 算法之深度优先遍历), 其中有 2 个重要的变量workInProgress和current(可参考前文fiber 树构造(基础准备)中介绍的双缓冲技术):
-
workInProgress和current都视为指针
-
workInProgress指向当前正在构造的fiber节点
-
current = workInProgress.alternate(即fiber.alternate), 指向当前页面正在使用的fiber节点. 初次构造时, 页面还未渲染, 此时current = null.
在深度优先遍历中, 每个fiber节点都会经历 2 个阶段:
1、探寻阶段 beginWork
2、回溯阶段 completeWork
这 2 个阶段共同完成了每一个fiber节点的创建, 所有fiber节点则构成了fiber树.
探寻阶段 beginWork
beginWork(current, unitOfWork, subtreeRenderLanes)针对所有的 Fiber 类型, 其中的每一个 case 处理一种 Fiber 类型. updateXXX函数(如: updateHostRoot, updateClassComponent 等)的主要逻辑:
1、根据 ReactElement对象创建所有的fiber节点, 最终构造出fiber树形结构(设置return和sibling指针)
2、设置fiber.flags(二进制形式变量, 用来标记 fiber节点 的增,删,改状态, 等待completeWork阶段处理)
3、设置fiber.stateNode局部状态(如Class类型节点: fiber.stateNode=new Class())
function beginWork(
current: Fiber | null,
workInProgress: Fiber,
renderLanes: Lanes,
): Fiber | null {
const updateLanes = workInProgress.lanes;
if (current !== null) {
// update逻辑, 首次render不会进入
} else {
didReceiveUpdate = false;
}
// 1. 设置workInProgress优先级为NoLanes(最高优先级)
workInProgress.lanes = NoLanes;
// 2. 根据workInProgress节点的类型, 用不同的方法派生出子节点
switch (
workInProgress.tag // 只保留了本例使用到的case
) {
case ClassComponent: {
const Component = workInProgress.type;
const unresolvedProps = workInProgress.pendingProps;
const resolvedProps =
workInProgress.elementType === Component
? unresolvedProps
: resolveDefaultProps(Component, unresolvedProps);
return updateClassComponent(
current,
workInProgress,
Component,
resolvedProps,
renderLanes,
);
}
case HostRoot:
return updateHostRoot(current, workInProgress, renderLanes);
case HostComponent:
return updateHostComponent(current, workInProgress, renderLanes);
case HostText:
return updateHostText(current, workInProgress);
case Fragment:
return updateFragment(current, workInProgress, renderLanes);
}
}
updateXXX函数(如: updateHostRoot, updateClassComponent 等)虽然 case 较多, 但是主要逻辑可以概括为 3 个步骤:
1、根据fiber.pendingProps, fiber.updateQueue等输入数据状态, 计算fiber.memoizedState作为输出状态
2、获取下级ReactElement对象
-
class 类型的 fiber 节点
-
构建React.Component实例
-
把新实例挂载到fiber.stateNode上
-
执行render之前的生命周期函数
-
执行render方法, 获取下级reactElement
-
根据实际情况, 设置fiber.flags
-
-
function 类型的 fiber 节点
-
执行 function, 获取下级reactElement
-
根据实际情况, 设置fiber.flags
-
-
HostComponent 类型(如: div, span, button 等)的 fiber 节点
-
pendingProps.children作为下级reactElement
-
如果下级节点是文本节点,则设置下级节点为 null. 准备进入completeUnitOfWork阶段
-
根据实际情况, 设置fiber.flags
-
-
其他类型…
3、根据ReactElement对象, 调用reconcileChildren生成Fiber子节点(只生成次级子节点)
- 根据实际情况, 设置fiber.flags
不同的updateXXX函数处理的fiber节点类型不同, 总的目的是为了向下生成子节点. 在这个过程中把一些需要持久化的数据挂载到fiber节点上(如fiber.stateNode,fiber.memoizedState等); 把fiber节点的特殊操作设置到fiber.flags(如:节点ref,class组件的生命周期,function组件的hook,节点删除等).
这里列出updateHostRoot, updateHostComponent的代码, 对于其他常用 case 的分析(如class类型, function类型), 在状态组件章节中进行探讨.
fiber树的根节点是HostRootFiber节点, 所以第一次进入beginWork会调用updateHostRoot(current, workInProgress, renderLanes)
// 省略与本节无关代码
function updateHostRoot(current, workInProgress, renderLanes) {
// 1. 状态计算, 更新整合到 workInProgress.memoizedState中来
const updateQueue = workInProgress.updateQueue;
const nextProps = workInProgress.pendingProps;
const prevState = workInProgress.memoizedState;
const prevChildren = prevState !== null ? prevState.element : null;
cloneUpdateQueue(current, workInProgress);
// 遍历updateQueue.shared.pending, 提取有足够优先级的update对象, 计算出最终的状态 workInProgress.memoizedState
processUpdateQueue(workInProgress, nextProps, null, renderLanes);
const nextState = workInProgress.memoizedState;
// 2. 获取下级`ReactElement`对象
const nextChildren = nextState.element;
const root: FiberRoot = workInProgress.stateNode;
if (root.hydrate && enterHydrationState(workInProgress)) {
// ...服务端渲染相关, 此处省略
} else {
// 3. 根据`ReactElement`对象, 调用`reconcileChildren`生成`Fiber`子节点(只生成`次级子节点`)
reconcileChildren(current, workInProgress, nextChildren, renderLanes);
}
return workInProgress.child;
}
普通 DOM 标签类型的节点(如div,span,p),会进入updateHostComponent:
// ...省略部分无关代码
function updateHostComponent(
current: Fiber | null,
workInProgress: Fiber,
renderLanes: Lanes,
) {
// 1. 状态计算, 由于HostComponent是无状态组件, 所以只需要收集 nextProps即可, 它没有 memoizedState
const type = workInProgress.type;
const nextProps = workInProgress.pendingProps;
const prevProps = current !== null ? current.memoizedProps : null;
// 2. 获取下级`ReactElement`对象
let nextChildren = nextProps.children;
const isDirectTextChild = shouldSetTextContent(type, nextProps);
if (isDirectTextChild) {
// 如果子节点只有一个文本节点, 不用再创建一个HostText类型的fiber
nextChildren = null;
} else if (prevProps !== null && shouldSetTextContent(type, prevProps)) {
// 特殊操作需要设置fiber.flags
workInProgress.flags |= ContentReset;
}
// 特殊操作需要设置fiber.flags
markRef(current, workInProgress);
// 3. 根据`ReactElement`对象, 调用`reconcileChildren`生成`Fiber`子节点(只生成`次级子节点`)
reconcileChildren(current, workInProgress, nextChildren, renderLanes);
return workInProgress.child;
}
回溯阶段 completeWork
completeUnitOfWork(unitOfWork)(源码地址), 处理 beginWork 阶段已经创建出来的 fiber 节点, 核心逻辑:
1、调用completeWork
-
给fiber节点(tag=HostComponent, HostText)创建 DOM 实例, 设置fiber.stateNode局部状态(如tag=HostComponent, HostText节点: fiber.stateNode 指向这个 DOM 实例).
-
为 DOM 节点设置属性, 绑定事件(这里先说明有这个步骤, 详细的事件处理流程, 在合成事件原理中详细说明).
-
设置fiber.flags标记
2、把当前 fiber 对象的副作用队列(firstEffect和lastEffect)添加到父节点的副作用队列之后, 更新父节点的firstEffect和lastEffect指针.
3、识别beginWork阶段设置的fiber.flags, 判断当前 fiber 是否有副作用(增,删,改), 如果有, 需要将当前 fiber 加入到父节点的effects队列, 等待commit阶段处理.
function completeUnitOfWork(unitOfWork: Fiber): void {
let completedWork = unitOfWork;
// 外层循环控制并移动指针(`workInProgress`,`completedWork`等)
do {
const current = completedWork.alternate;
const returnFiber = completedWork.return;
if ((completedWork.flags & Incomplete) === NoFlags) {
let next;
// 1. 处理Fiber节点, 会调用渲染器(调用react-dom包, 关联Fiber节点和dom对象, 绑定事件等)
next = completeWork(current, completedWork, subtreeRenderLanes); // 处理单个节点
if (next !== null) {
// 如果派生出其他的子节点, 则回到`beginWork`阶段进行处理
workInProgress = next;
return;
}
// 重置子节点的优先级
resetChildLanes(completedWork);
if (
returnFiber !== null &&
(returnFiber.flags & Incomplete) === NoFlags
) {
// 2. 收集当前Fiber节点以及其子树的副作用effects
// 2.1 把子节点的副作用队列添加到父节点上
if (returnFiber.firstEffect === null) {
returnFiber.firstEffect = completedWork.firstEffect;
}
if (completedWork.lastEffect !== null) {
if (returnFiber.lastEffect !== null) {
returnFiber.lastEffect.nextEffect = completedWork.firstEffect;
}
returnFiber.lastEffect = completedWork.lastEffect;
}
// 2.2 如果当前fiber节点有副作用, 将其添加到子节点的副作用队列之后.
const flags = completedWork.flags;
if (flags > PerformedWork) {
// PerformedWork是提供给 React DevTools读取的, 所以略过PerformedWork
if (returnFiber.lastEffect !== null) {
returnFiber.lastEffect.nextEffect = completedWork;
} else {
returnFiber.firstEffect = completedWork;
}
returnFiber.lastEffect = completedWork;
}
}
} else {
// 异常处理, 本节不讨论
}
const siblingFiber = completedWork.sibling;
if (siblingFiber !== null) {
// 如果有兄弟节点, 返回之后再次进入`beginWork`阶段
workInProgress = siblingFiber;
return;
}
// 移动指针, 指向下一个节点
completedWork = returnFiber;
workInProgress = completedWork;
} while (completedWork !== null);
// 已回溯到根节点, 设置workInProgressRootExitStatus = RootCompleted
if (workInProgressRootExitStatus === RootIncomplete) {
workInProgressRootExitStatus = RootCompleted;
}
}
接下来分析fiber处理函数completeWork
function completeWork(
current: Fiber | null,
workInProgress: Fiber,
renderLanes: Lanes,
): Fiber | null {
const newProps = workInProgress.pendingProps;
switch (workInProgress.tag) {
case ClassComponent: {
// Class类型不做处理
return null;
}
case HostRoot: {
const fiberRoot = (workInProgress.stateNode: FiberRoot);
if (fiberRoot.pendingContext) {
fiberRoot.context = fiberRoot.pendingContext;
fiberRoot.pendingContext = null;
}
if (current === null || current.child === null) {
// 设置fiber.flags标记
workInProgress.flags |= Snapshot;
}
return null;
}
case HostComponent: {
popHostContext(workInProgress);
const rootContainerInstance = getRootHostContainer();
const type = workInProgress.type;
if (current !== null && workInProgress.stateNode != null) {
// update逻辑, 初次render不会进入
} else {
const currentHostContext = getHostContext();
// 1. 创建DOM对象
const instance = createInstance(
type,
newProps,
rootContainerInstance,
currentHostContext,
workInProgress,
);
// 2. 把子树中的DOM对象append到本节点的DOM对象之后
appendAllChildren(instance, workInProgress, false, false);
// 设置stateNode属性, 指向DOM对象
workInProgress.stateNode = instance;
if (
// 3. 设置DOM对象的属性, 绑定事件等
finalizeInitialChildren(
instance,
type,
newProps,
rootContainerInstance,
currentHostContext,
)
) {
// 设置fiber.flags标记(Update)
markUpdate(workInProgress);
}
if (workInProgress.ref !== null) {
// 设置fiber.flags标记(Ref)
markRef(workInProgress);
}
return null;
}
}
}
可以看到在满足条件的时候也会设置fiber.flags, 所以设置fiber.flags并非只在beginWork阶段.
过程图解
针对本节的示例代码, 将整个fiber树构造过程表示出来:
构造前:
在上文已经说明, 进入循环构造前会调用prepareFreshStack刷新栈帧, 在进入fiber树构造循环之前, 保持这这个初始化状态:
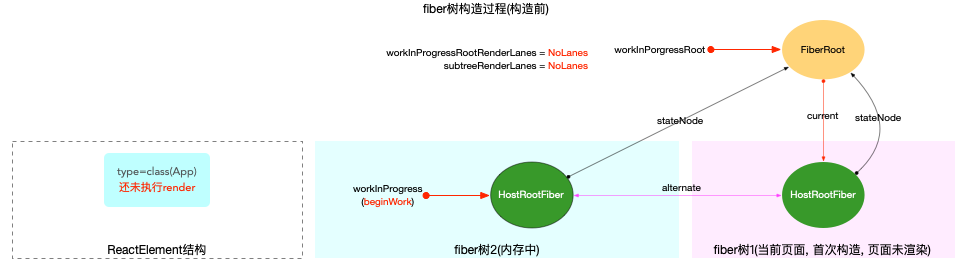
performUnitOfWork第 1 次调用(只执行beginWork):
-
执行前: workInProgress指针指向HostRootFiber.alternate对象, 此时current = workInProgress.alternate指向fiberRoot.current是非空的(初次构造, 只在根节点时, current非空).
-
执行过程: 调用updateHostRoot
- 在reconcileChildren阶段, 向下构造次级子节点
fiber(<App/>), 同时设置子节点(fiber(<App/>))fiber.flags |= Placement
- 在reconcileChildren阶段, 向下构造次级子节点
-
执行后: 返回下级节点
fiber(<App/>), 移动workInProgress指针指向子节点fiber(<App/>)
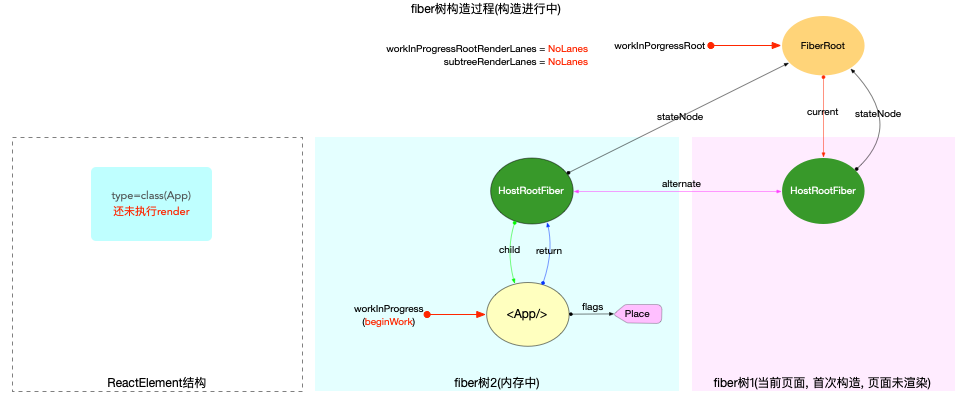
performUnitOfWork第 2 次调用(只执行beginWork):
-
执行前: workInProgress指针指向
fiber(<App/>)节点, 此时current = null -
执行过程: 调用updateClassComponent
-
本示例中, class 实例存在生命周期函数componentDidMount, 所以会设置
fiber(<App/>)节点workInProgress.flags |= Update -
另外也会为了React DevTools能够识别状态组件的执行进度, 会设置
workInProgress.flags |= PerformedWork(在commit阶段会排除这个flag, 此处只是列出workInProgress.flags的设置场景, 不讨论React DevTools) -
需要注意classInstance.render()在本步骤执行后, 虽然返回了render方法中所有的ReactElement对象, 但是随后reconcileChildren只构造次级子节点
-
在reconcileChildren阶段, 向下构造次级子节点div
-
-
执行后: 返回下级节点fiber(div), 移动workInProgress指针指向子节点fiber(div)
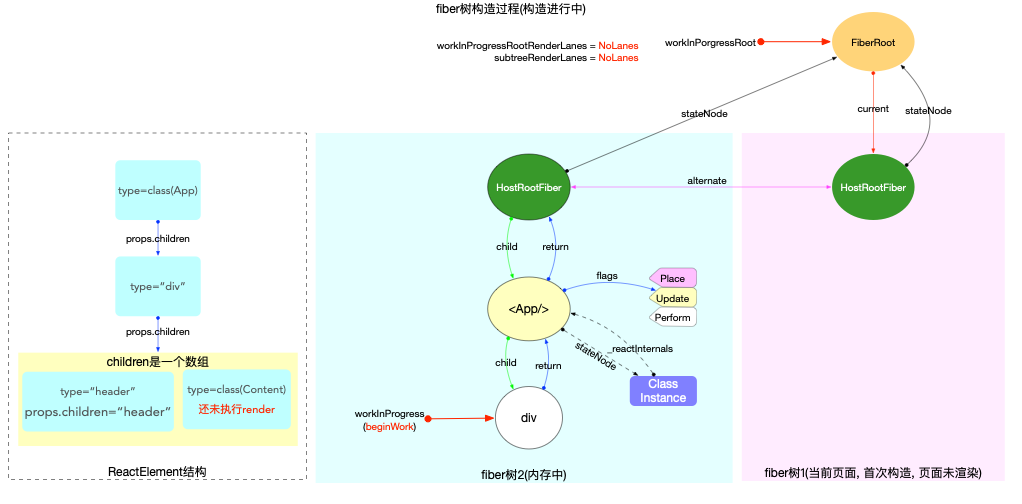
performUnitOfWork第 3 次调用(只执行beginWork):
-
执行前: workInProgress指针指向fiber(div)节点, 此时current = null
-
执行过程: 调用updateHostComponent
- 在reconcileChildren阶段, 向下构造次级子节点(本示例中, div有 2 个次级子节点)
-
执行后: 返回下级节点fiber(header), 移动workInProgress指针指向子节点fiber(header)
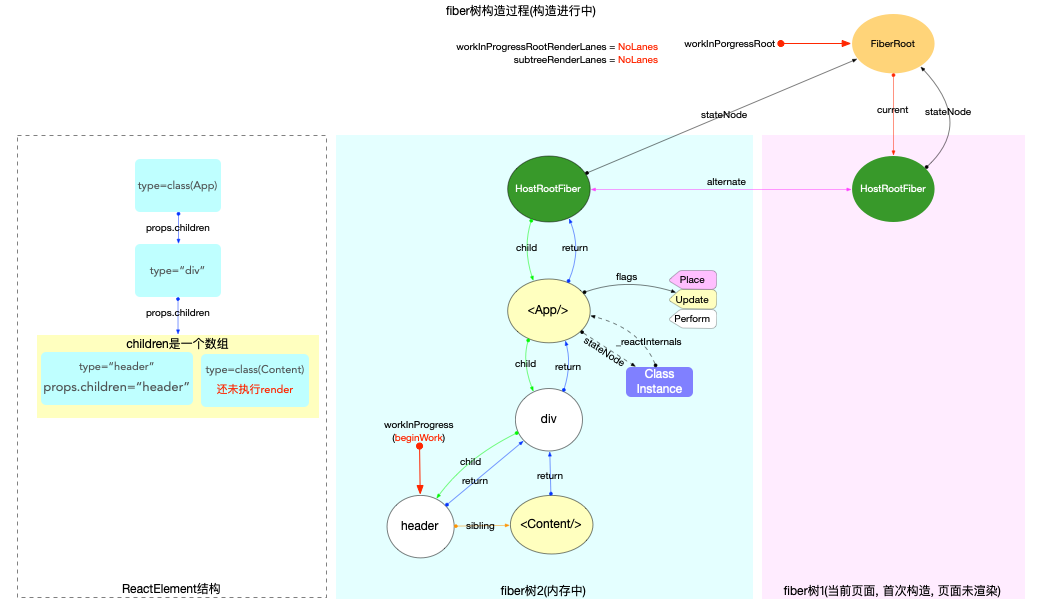
performUnitOfWork第 4 次调用(执行beginWork和completeUnitOfWork):
-
beginWork执行前: workInProgress指针指向fiber(header)节点, 此时current = null
-
beginWork执行过程: 调用updateHostComponent
-
本示例中header的子节点是一个直接文本节点,设置nextChildren = null(直接文本节点并不会被当成具体的fiber节点进行处理, 而是在宿主环境(父组件)中通过属性进行设置. 所以无需创建HostText类型的 fiber 节点, 同时节省了向下遍历开销.).
-
由于nextChildren = null, 经过reconcileChildren阶段处理后, 返回值也是null
-
-
beginWork执行后: 由于下级节点为null, 所以进入completeUnitOfWork(unitOfWork)函数, 传入的参数unitOfWork实际上就是workInProgress(此时指向fiber(header)节点)
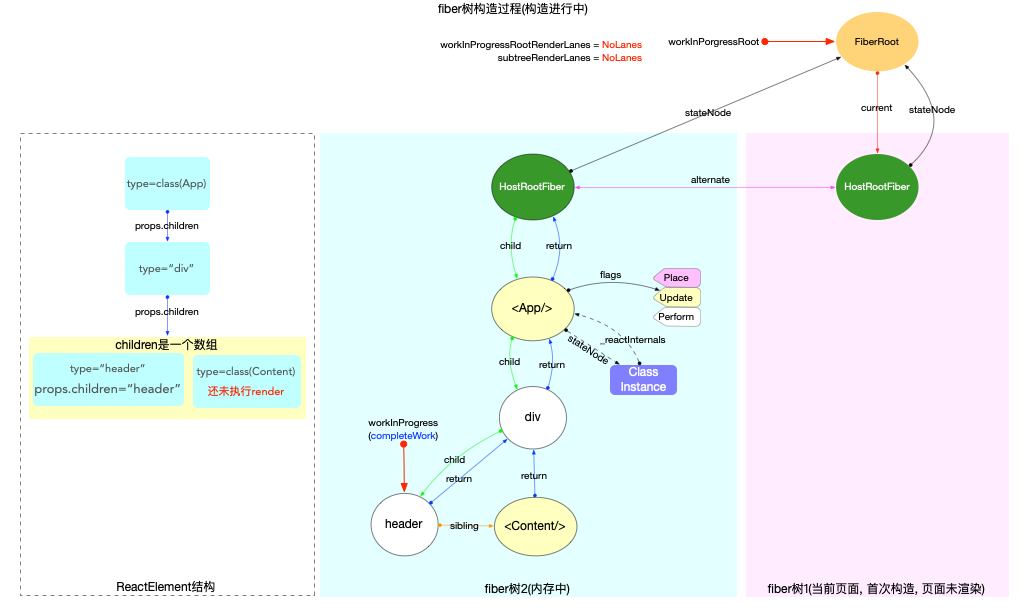
-
completeUnitOfWork执行前: workInProgress指针指向fiber(header)节点
-
completeUnitOfWork执行过程: 以fiber(header)为起点, 向上回溯
第 1 次循环:
1、执行completeWork函数
-
创建fiber(header)节点对应的DOM实例, 并append子节点的DOM实例
-
设置DOM属性, 绑定事件等(本示例中, 节点fiber(header)没有事件绑定)
2、上移副作用队列: 由于本节点fiber(header)没有副作用(fiber.flags = 0), 所以执行之后副作用队列没有实质变化(目前为空).
3、向上回溯: 由于还有兄弟节点, 把workInProgress指针指向下一个兄弟节点fiber(<Content/>), 退出completeUnitOfWork.
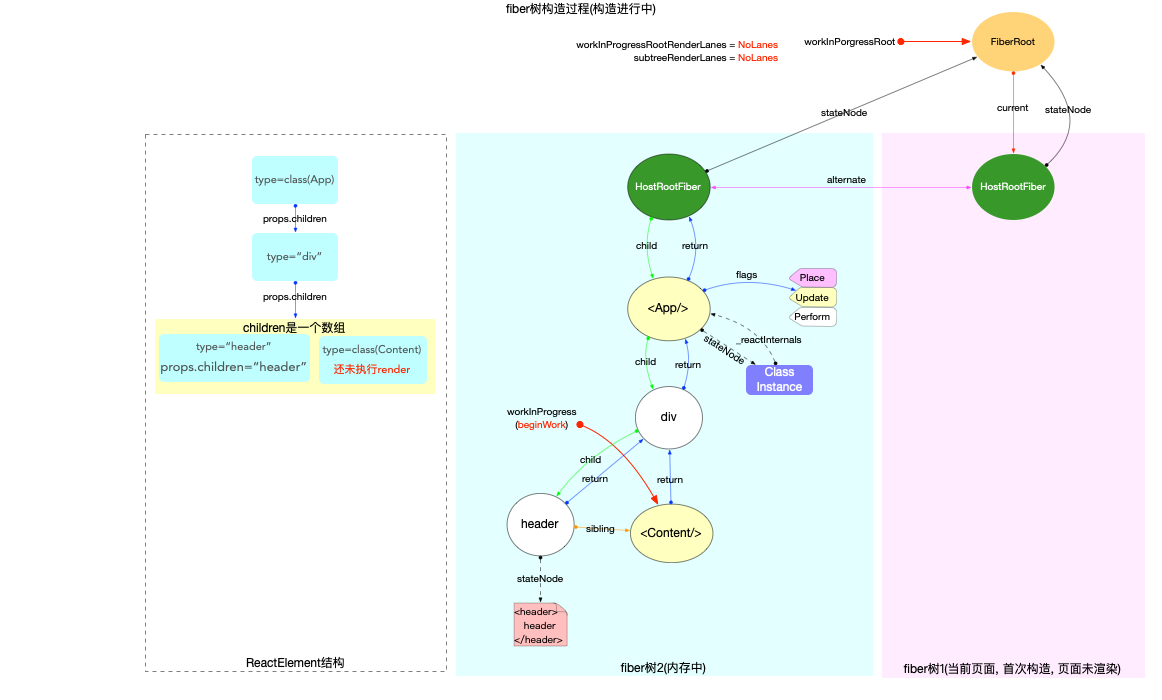
performUnitOfWork第 5 次调用(执行beginWork):
-
执行前:workInProgress指针指向
fiber(<Content/>)节点. -
执行过程: 这是一个class类型的节点, 与第 2 次调用逻辑一致.
-
执行后: 返回下级节点fiber(p), 移动workInProgress指针指向子节点fiber(p)
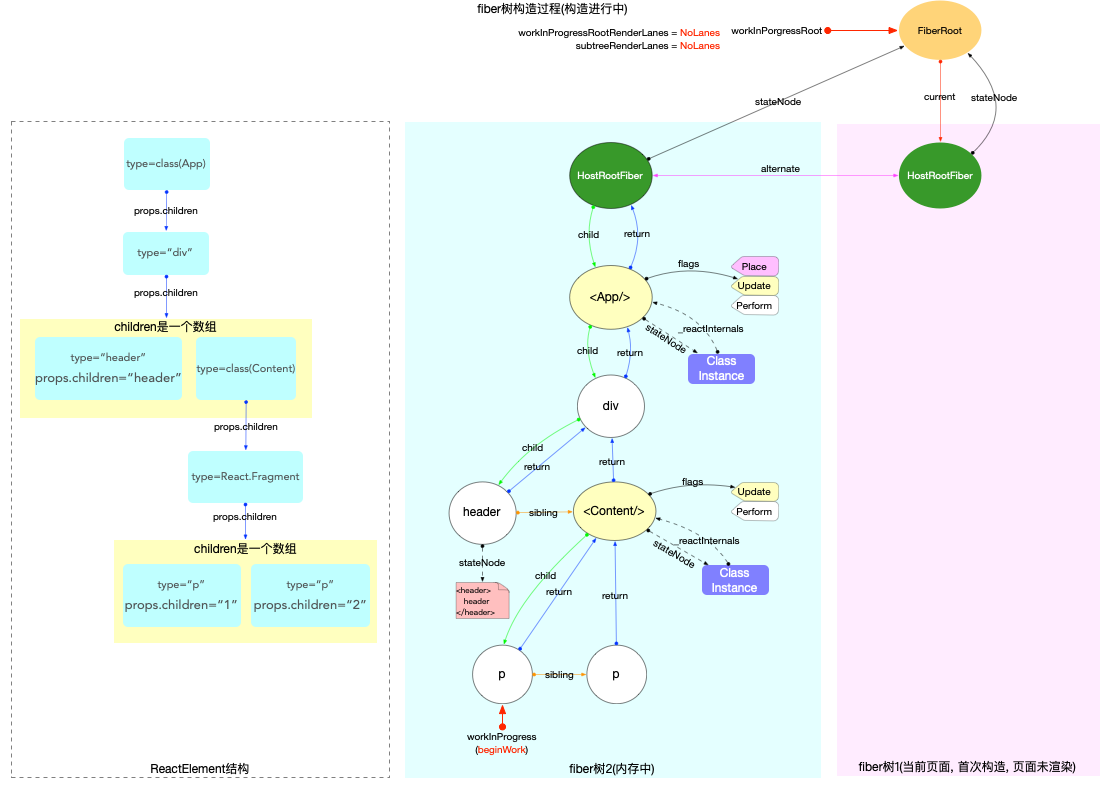
performUnitOfWork第 6 次调用(执行beginWork和completeUnitOfWork):与第 4 次调用中创建fiber(header)节点的逻辑一致. 先后会执行beginWork和completeUnitOfWork, 最后构造 DOM 实例, 并将把workInProgress指针指向下一个兄弟节点fiber(p).
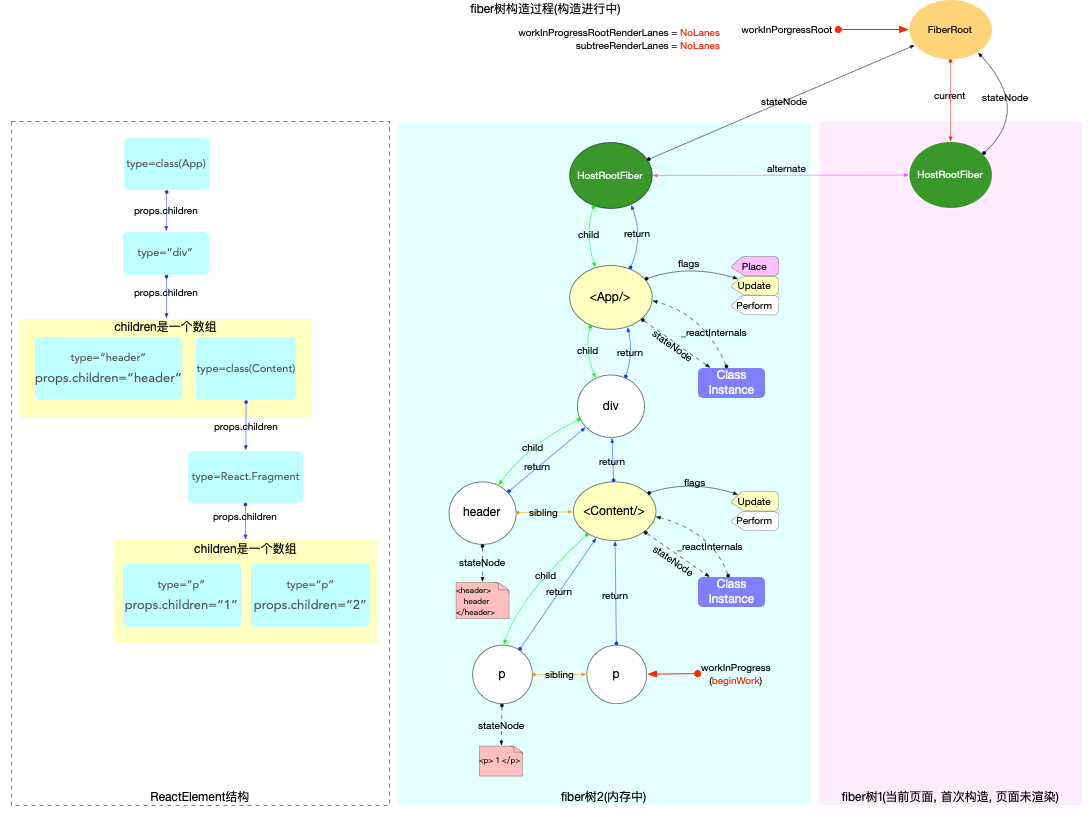
performUnitOfWork第 7 次调用(执行beginWork和completeUnitOfWork):
-
beginWork执行过程: 与上次调用中创建fiber(p)节点的逻辑一致
-
completeUnitOfWork执行过程: 以fiber(p)为起点, 向上回溯
第 1 次循环:
1、执行completeWork函数: 创建fiber(p)节点对应的DOM实例, 并append子树节点的DOM实例
2、上移副作用队列: 由于本节点fiber(p)没有副作用, 所以执行之后副作用队列没有实质变化(目前为空).
3、向上回溯: 由于没有兄弟节点, 把workInProgress指针指向父节点fiber(<Content/>)
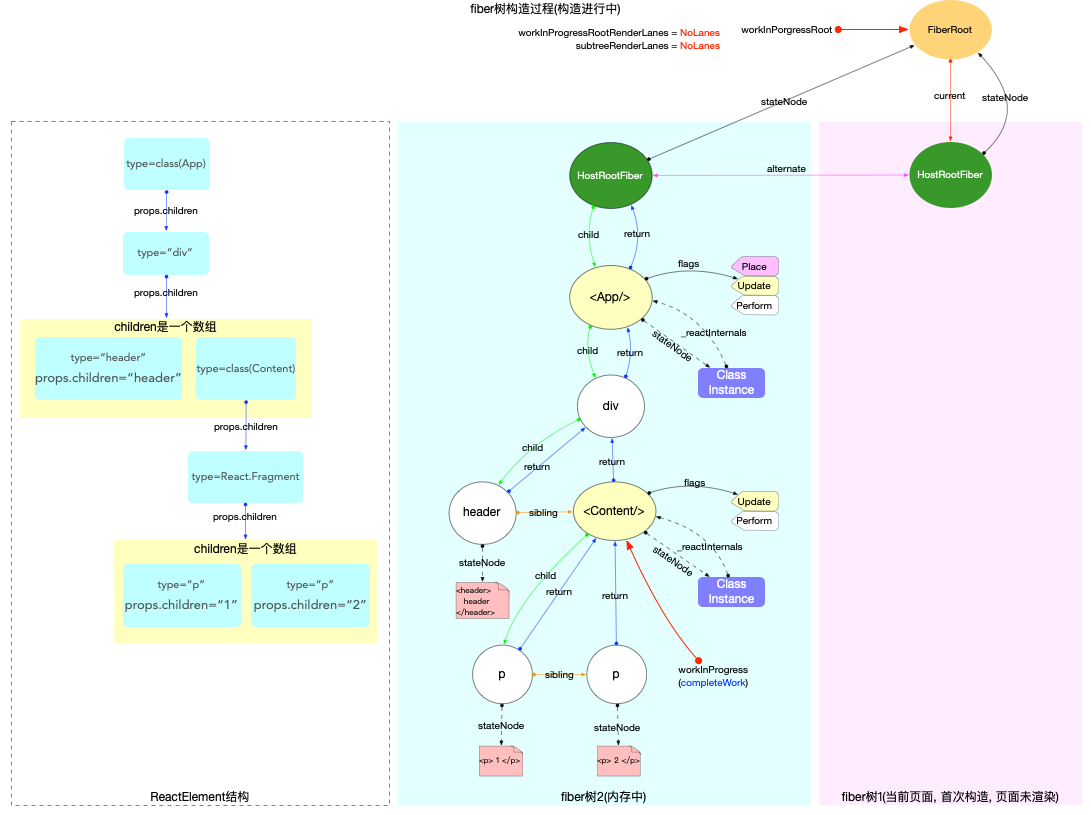
第 2 次循环:
1、执行completeWork函数: class 类型的节点不做处理
2、上移副作用队列:
- 本节点
fiber(<Content/>)的flags标志位有改动(completedWork.flags > PerformedWork), 将本节点添加到父节点(fiber(div))的副作用队列之后(firstEffect和lastEffect属性分别指向副作用队列的首部和尾部).
3、向上回溯: 把workInProgress指针指向父节点fiber(div)
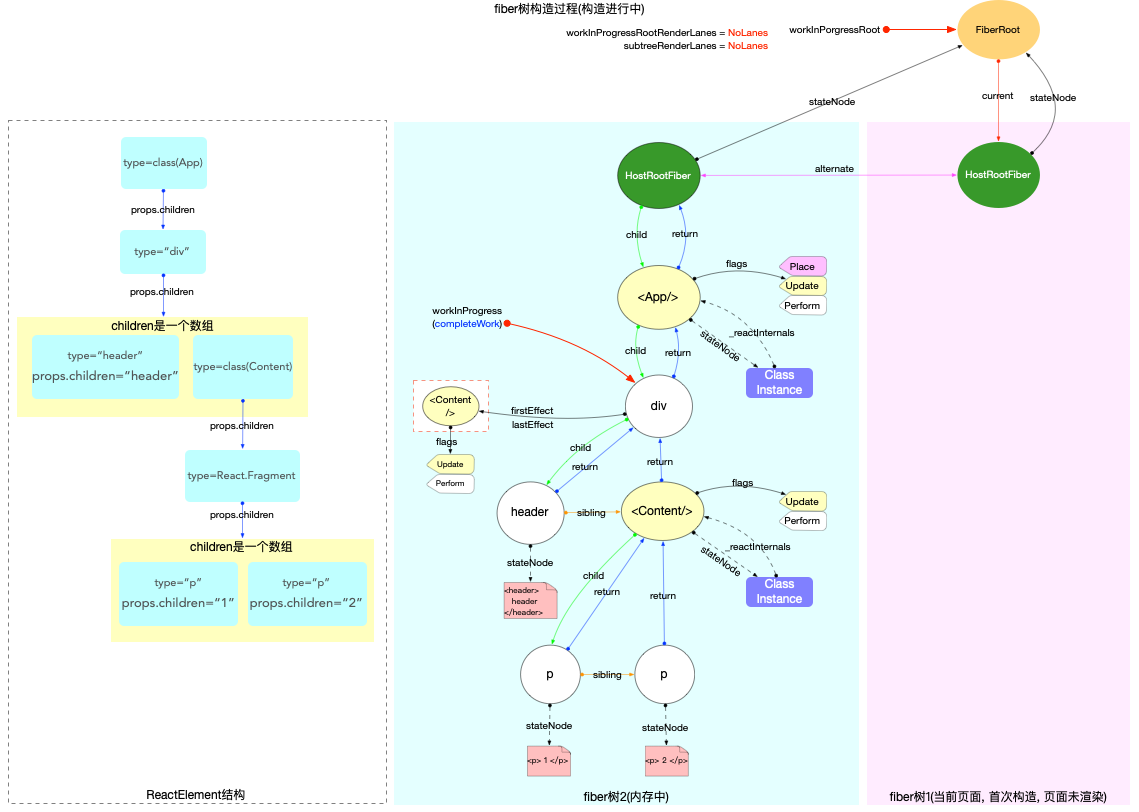
第 3 次循环:
1、执行completeWork函数: 创建fiber(div)节点对应的DOM实例, 并append子树节点的DOM实例
2、上移副作用队列:
- 本节点fiber(div)的副作用队列不为空, 将其拼接到父节点
fiber<App/>的副作用队列后面.
3、向上回溯: 把workInProgress指针指向父节点fiber(<App/>)
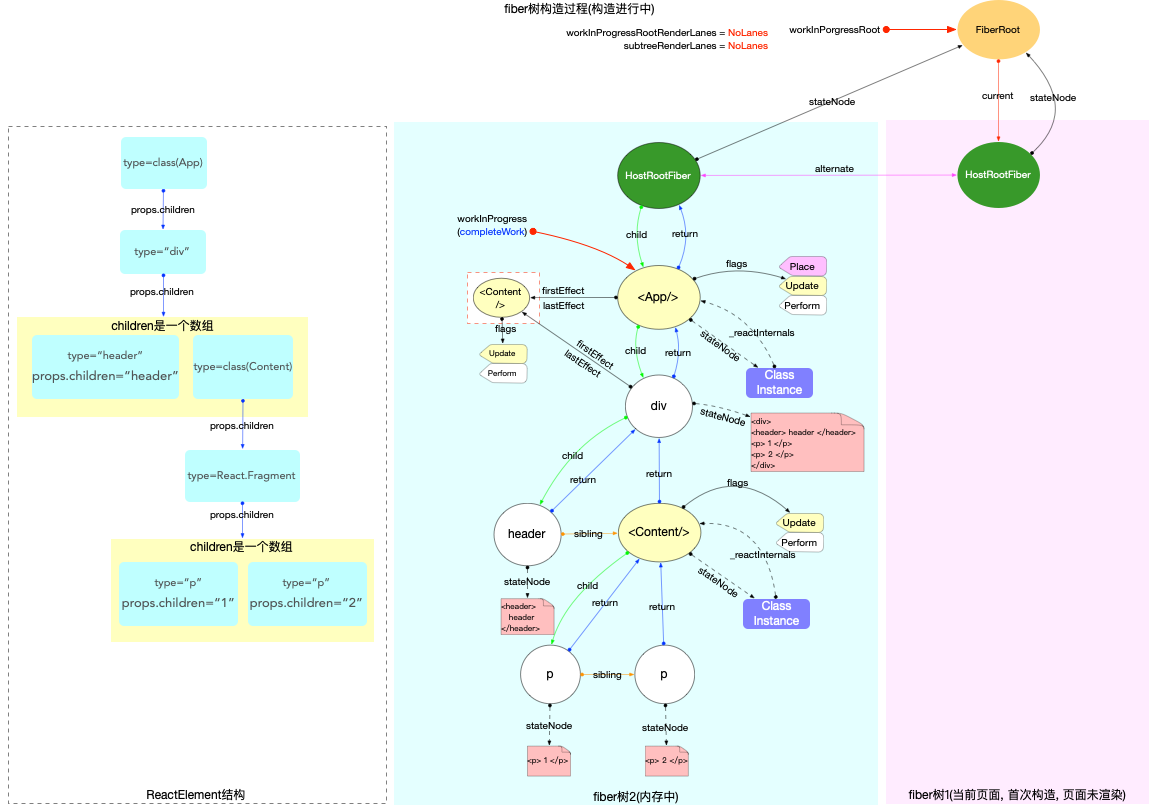
第 4 次循环:
1、执行completeWork函数: class 类型的节点不做处理
2、上移副作用队列:
-
本节点
fiber(<App/>)的副作用队列不为空, 将其拼接到父节点fiber(HostRootFiber)的副作用队列上. -
本节点
fiber(<App/>)的flags标志位有改动(completedWork.flags > PerformedWork), 将本节点添加到父节点fiber(HostRootFiber)的副作用队列之后. -
最后队列的顺序是子节点在前, 本节点在后
3、向上回溯: 把workInProgress指针指向父节点fiber(HostRootFiber)
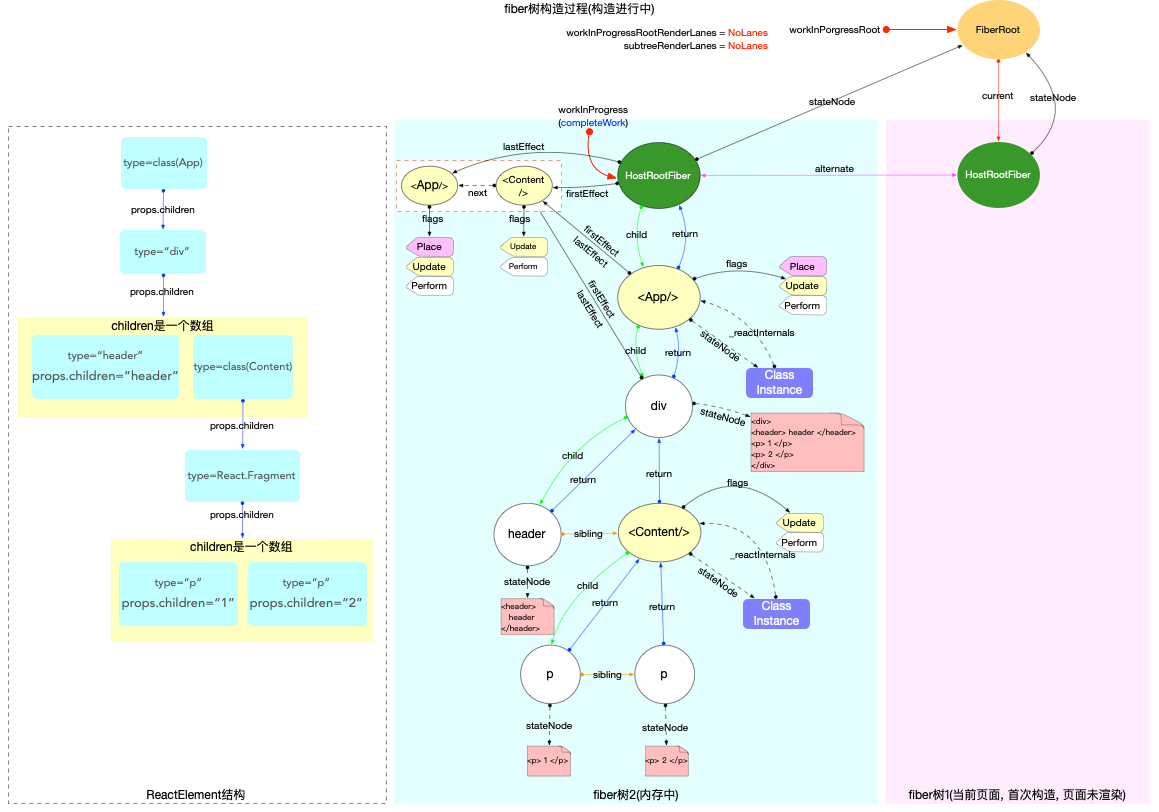
第 5 次循环:
1、执行completeWork函数: 对于HostRoot类型的节点, 初次构造时设置workInProgress.flags |= Snapshot
2、向上回溯: 由于父节点为空, 无需进入处理副作用队列的逻辑. 最后设置workInProgress=null, 并退出completeUnitOfWork
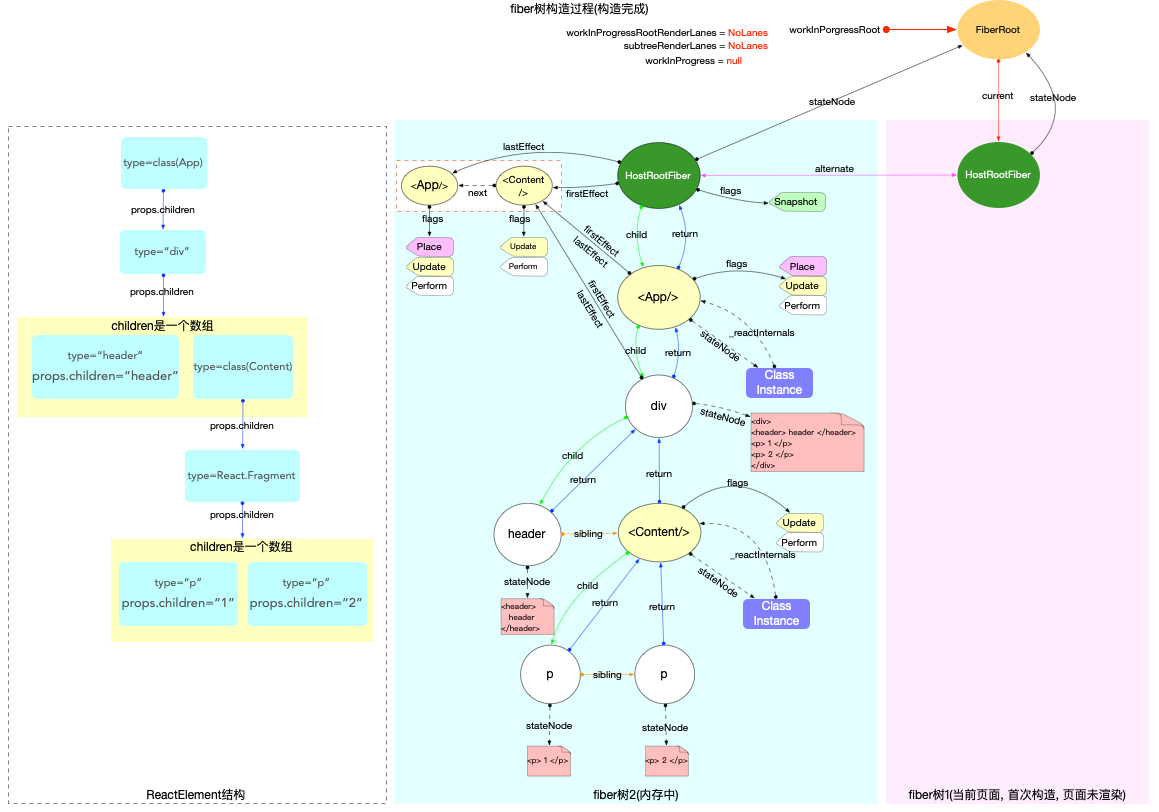
到此整个fiber树构造循环已经执行完毕, 拥有一棵完整的fiber树, 并且在fiber树的根节点上挂载了副作用队列, 副作用队列的顺序是层级越深子节点越靠前.
renderRootSync函数退出之前, 会重置workInProgressRoot = null, 表明没有正在进行中的render. 且把最新的fiber树挂载到fiberRoot.finishedWork上. 这时整个 fiber 树的内存结构如下(注意fiberRoot.finishedWork和fiberRoot.current指针,在commitRoot阶段会进行处理):
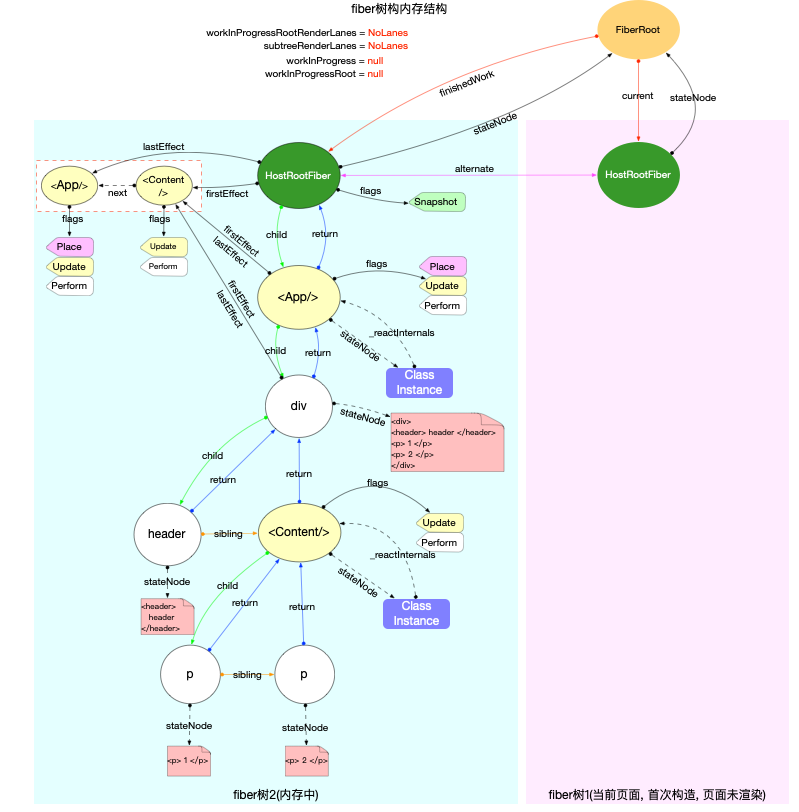
本节演示了初次创建fiber树的全部过程, 跟踪了创建过程中内存引用的变化情况. fiber树构造循环负责构造新的fiber树, 构造过程中同时标记fiber.flags, 最终把所有被标记的fiber节点收集到一个副作用队列中, 这个副作用队列被挂载到根节点上(HostRootFiber.alternate.firstEffect). 此时的fiber树和与之对应的DOM节点都还在内存当中, 等待commitRoot阶段进行渲染.
fiber 树构造(对比更新)
在前文fiber 树构造(初次创建)一文的介绍中, 演示了fiber树构造循环中逐步构造fiber树的过程. 由于是初次创建, 所以在构造过程中, 所有节点都是新建, 并没有复用旧节点.
本节讨论对比更新这种情况(在Legacy模式下进行分析). 在阅读本节之前, 最好对fiber 树构造(初次创建)有一些了解, 其中有很多相似逻辑不再重复叙述, 本节重点突出对比更新与初次创建的不同之处.
本节示例代码如下(codesandbox 地址):
import React from 'react';
class App extends React.Component {
state = {
list: ['A', 'B', 'C'],
};
onChange = () => {
this.setState({ list: ['C', 'A', 'X'] });
};
componentDidMount() {
console.log(`App Mount`);
}
render() {
return (
<>
<Header />
<button onClick={this.onChange}>change</button>
<div className="content">
{this.state.list.map((item) => (
<p key={item}>{item}</p>
))}
</div>
</>
);
}
}
class Header extends React.PureComponent {
render() {
return (
<>
<h1>title</h1>
<h2>title2</h2>
</>
);
}
}
export default App;
在初次渲染完成之后, 与fiber树相关的内存结构如下(后文以此图为基础, 演示对比更新过程):
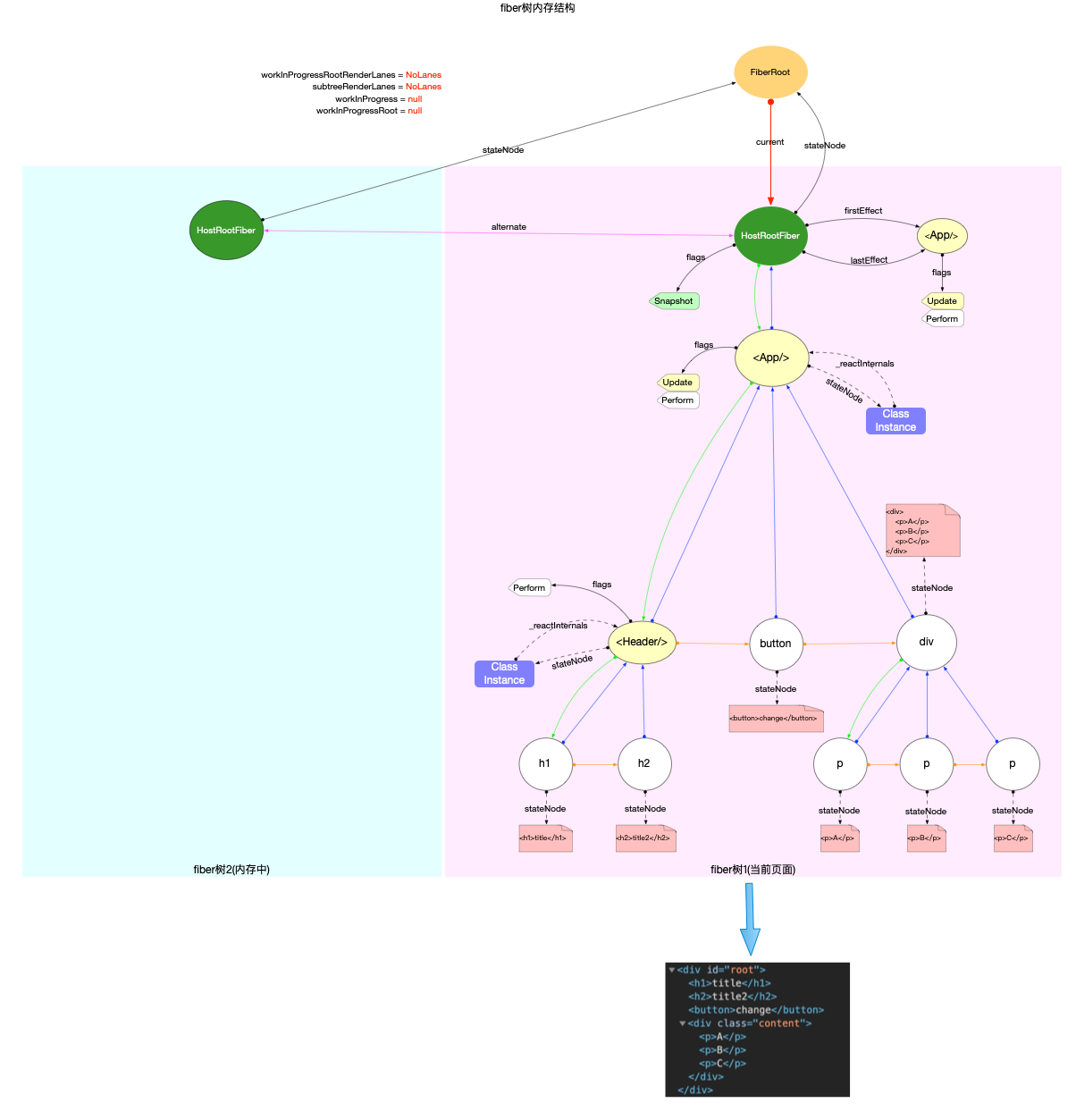
更新入口
前文reconciler 运作流程中总结的 4 个阶段(从输入到输出), 其中承接输入的函数只有scheduleUpdateOnFiber(源码地址).在react-reconciler对外暴露的 api 函数中, 只要涉及到需要改变 fiber 的操作(无论是首次渲染或对比更新), 最后都会间接调用scheduleUpdateOnFiber, scheduleUpdateOnFiber函数是输入链路中的必经之路.
3 种更新方式
如要主动发起更新, 有 3 种常见方式:
1、Class组件中调用setState.
2、Function组件中调用hook对象暴露出的dispatchAction.
3、在container节点上重复调用render(官网示例)
下面列出这 3 种更新方式的源码:
setState
在Component对象的原型上挂载有setState(源码链接):
Component.prototype.setState = function (partialState, callback) {
this.updater.enqueueSetState(this, partialState, callback, 'setState');
};
在fiber 树构造(初次创建)中的beginWork阶段, class 类型的组件初始化完成之后, this.updater对象如下(源码链接):
const classComponentUpdater = {
isMounted,
enqueueSetState(inst, payload, callback) {
// 1. 获取class实例对应的fiber节点
const fiber = getInstance(inst);
// 2. 创建update对象
const eventTime = requestEventTime();
const lane = requestUpdateLane(fiber); // 确定当前update对象的优先级
const update = createUpdate(eventTime, lane);
update.payload = payload;
if (callback !== undefined && callback !== null) {
update.callback = callback;
}
// 3. 将update对象添加到当前Fiber节点的updateQueue队列当中
enqueueUpdate(fiber, update);
// 4. 进入reconciler运作流程中的`输入`环节
scheduleUpdateOnFiber(fiber, lane, eventTime); // 传入的lane是update优先级
},
};
dispatchAction
此处只是为了对比dispatchAction和setState. 有关hook原理的深入分析, 在hook 原理章节中详细讨论.
在function类型组件中, 如果使用hook(useState), 则可以通过hook api暴露出的dispatchAction(源码链接)来更新
function dispatchAction<S, A>(
fiber: Fiber,
queue: UpdateQueue<S, A>,
action: A,
) {
// 1. 创建update对象
const eventTime = requestEventTime();
const lane = requestUpdateLane(fiber); // 确定当前update对象的优先级
const update: Update<S, A> = {
lane,
action,
eagerReducer: null,
eagerState: null,
next: (null: any),
};
// 2. 将update对象添加到当前Hook对象的updateQueue队列当中
const pending = queue.pending;
if (pending === null) {
update.next = update;
} else {
update.next = pending.next;
pending.next = update;
}
queue.pending = update;
// 3. 请求调度, 进入reconciler运作流程中的`输入`环节.
scheduleUpdateOnFiber(fiber, lane, eventTime); // 传入的lane是update优先级
}
重复调用 render
import ReactDOM from 'react-dom';
function tick() {
const element = (
<div>
<h1>Hello, world!</h1>
<h2>It is {new Date().toLocaleTimeString()}.</h2>
</div>
);
ReactDOM.render(element, document.getElementById('root'));
}
setInterval(tick, 1000);
对于重复render, 在React 应用的启动过程中已有说明, 调用路径包含updateContainer–>scheduleUpdateOnFiber
故无论从哪个入口进行更新, 最终都会进入scheduleUpdateOnFiber, 再次证明scheduleUpdateOnFiber是输入阶段的必经函数(参考reconciler 运作流程).
构造阶段
逻辑来到scheduleUpdateOnFiber函数:
// ...省略部分代码
export function scheduleUpdateOnFiber(
fiber: Fiber, // fiber表示被更新的节点
lane: Lane, // lane表示update优先级
eventTime: number,
) {
const root = markUpdateLaneFromFiberToRoot(fiber, lane);
if (lane === SyncLane) {
if (
(executionContext & LegacyUnbatchedContext) !== NoContext &&
(executionContext & (RenderContext | CommitContext)) === NoContext
) {
// 初次渲染
performSyncWorkOnRoot(root);
} else {
// 对比更新
ensureRootIsScheduled(root, eventTime);
}
}
mostRecentlyUpdatedRoot = root;
}
对比更新与初次渲染的不同点:
1、markUpdateLaneFromFiberToRoot函数, 只在对比更新阶段才发挥出它的作用, 它找出了fiber树中受到本次update影响的所有节点, 并设置这些节点的fiber.lanes或fiber.childLanes(在legacy模式下为SyncLane)以备fiber树构造阶段使用.
function markUpdateLaneFromFiberToRoot(
sourceFiber: Fiber, // sourceFiber表示被更新的节点
lane: Lane, // lane表示update优先级
): FiberRoot | null {
// 1. 将update优先级设置到sourceFiber.lanes
sourceFiber.lanes = mergeLanes(sourceFiber.lanes, lane);
let alternate = sourceFiber.alternate;
if (alternate !== null) {
// 同时设置sourceFiber.alternate的优先级
alternate.lanes = mergeLanes(alternate.lanes, lane);
}
// 2. 从sourceFiber开始, 向上遍历所有节点, 直到HostRoot. 设置沿途所有节点(包括alternate)的childLanes
let node = sourceFiber;
let parent = sourceFiber.return;
while (parent !== null) {
parent.childLanes = mergeLanes(parent.childLanes, lane);
alternate = parent.alternate;
if (alternate !== null) {
alternate.childLanes = mergeLanes(alternate.childLanes, lane);
}
node = parent;
parent = parent.return;
}
if (node.tag === HostRoot) {
const root: FiberRoot = node.stateNode;
return root;
} else {
return null;
}
}
markUpdateLaneFromFiberToRoot
下图表示了markUpdateLaneFromFiberToRoot的具体作用:
-
以sourceFiber为起点, 设置起点的fiber.lanes
-
从起点开始, 直到HostRootFiber, 设置父路径上所有节点(也包括fiber.alternate)的fiber.childLanes.
-
通过设置fiber.lanes和fiber.childLanes就可以辅助判断子树是否需要更新(在下文循环构造中详细说明).
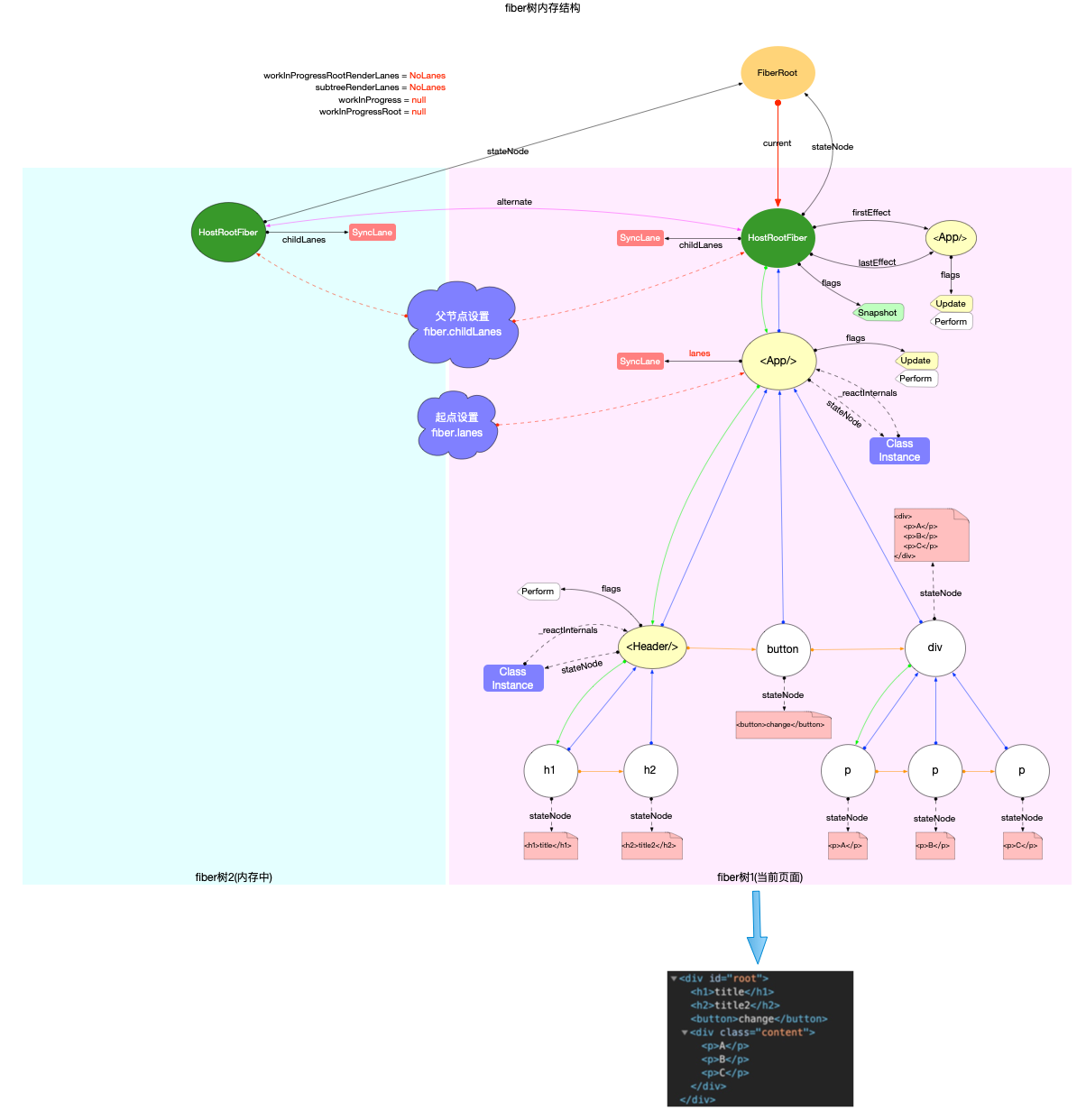
2、对比更新没有直接调用performSyncWorkOnRoot, 而是通过调度中心来处理, 由于本示例是在Legacy模式下进行, 最后会同步执行performSyncWorkOnRoot.(详细原理可以参考React 调度原理(scheduler)). 所以其调用链路performSyncWorkOnRoot—>renderRootSync—>workLoopSync与初次构造中的一致.
在renderRootSync中:
function renderRootSync(root: FiberRoot, lanes: Lanes) {
const prevExecutionContext = executionContext;
executionContext |= RenderContext;
// 如果fiberRoot变动, 或者update.lane变动, 都会刷新栈帧, 丢弃上一次渲染进度
if (workInProgressRoot !== root || workInProgressRootRenderLanes !== lanes) {
// 刷新栈帧, legacy模式下都会进入
prepareFreshStack(root, lanes);
}
do {
try {
workLoopSync();
break;
} catch (thrownValue) {
handleError(root, thrownValue);
}
} while (true);
executionContext = prevExecutionContext;
// 重置全局变量, 表明render结束
workInProgressRoot = null;
workInProgressRootRenderLanes = NoLanes;
return workInProgressRootExitStatus;
}
进入循环构造(workLoopSync)前, 会刷新栈帧(调用prepareFreshStack)(参考fiber 树构造(基础准备)中栈帧管理).
此时的内存结构如下:
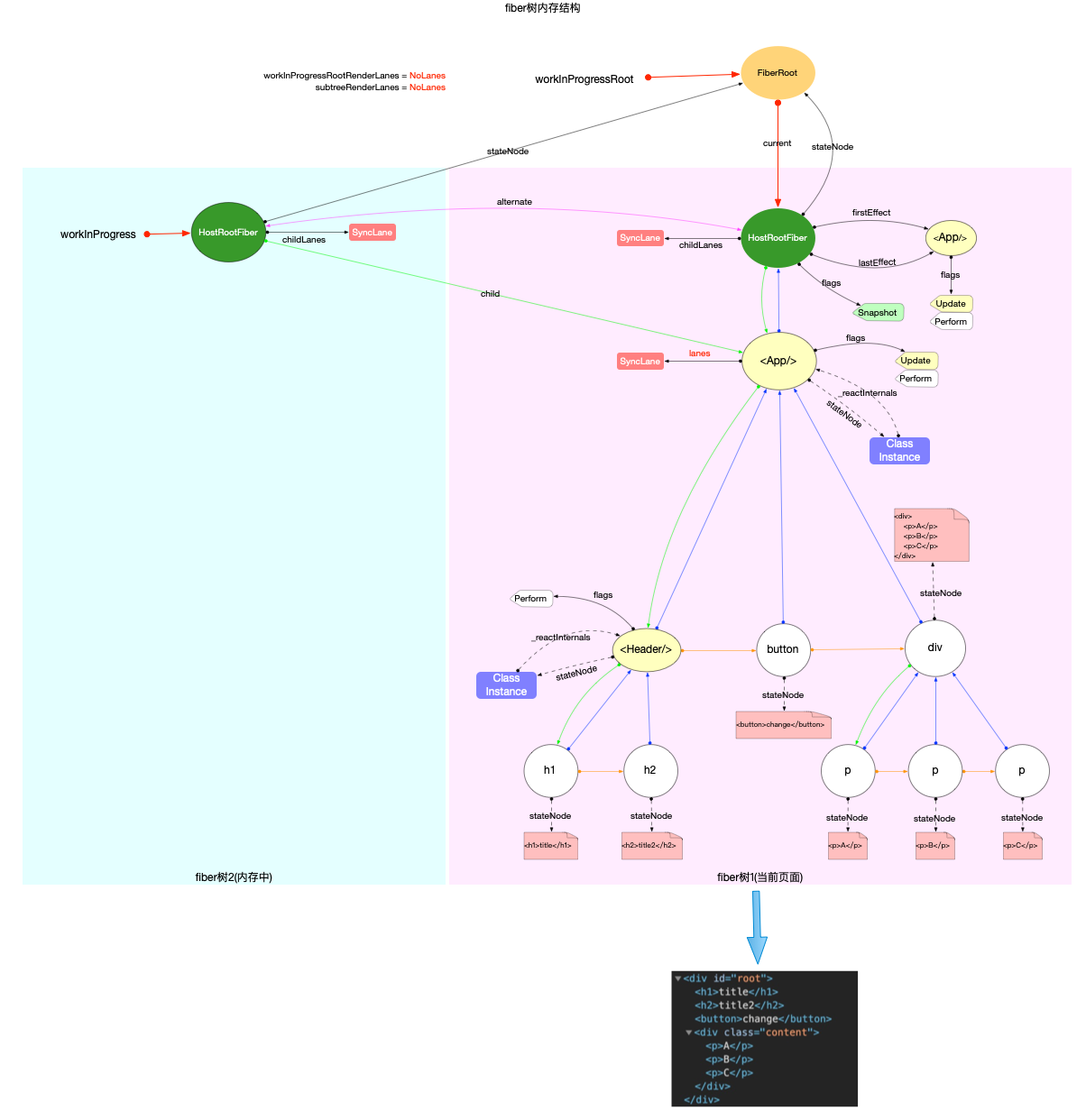
注意:
-
fiberRoot.current指向与当前页面对应的fiber树, workInProgress指向正在构造的fiber树.
-
刷新栈帧会调用createWorkInProgress(), 使得workInProgress.flags和workInProgress.effects都已经被重置. 且workInProgress.child = current.child. 所以在进入循环构造之前, HostRootFiber与HostRootFiber.alternate共用一个child(这里是
fiber(<App/>)).
回顾一下fiber 树构造(初次创建)中的介绍. 整个fiber树构造是一个深度优先遍历(可参考React 算法之深度优先遍历), 其中有 2 个重要的变量workInProgress和current(可参考fiber 树构造(基础准备)中介绍的双缓冲技术):
-
workInProgress和current都视为指针
-
workInProgress指向当前正在构造的fiber节点
-
current = workInProgress.alternate(即fiber.alternate), 指向当前页面正在使用的fiber节点.
在深度优先遍历中, 每个fiber节点都会经历 2 个阶段:
1、探寻阶段 beginWork
2、回溯阶段 completeWork
这 2 个阶段共同完成了每一个fiber节点的创建(或更新), 所有fiber节点则构成了fiber树.
function workLoopSync() {
while (workInProgress !== null) {
performUnitOfWork(workInProgress);
}
}
// ... 省略部分无关代码
function performUnitOfWork(unitOfWork: Fiber): void {
// unitOfWork就是被传入的workInProgress
const current = unitOfWork.alternate;
let next;
next = beginWork(current, unitOfWork, subtreeRenderLanes);
unitOfWork.memoizedProps = unitOfWork.pendingProps;
if (next === null) {
// 如果没有派生出新的节点, 则进入completeWork阶段, 传入的是当前unitOfWork
completeUnitOfWork(unitOfWork);
} else {
workInProgress = next;
}
}
注意: 在对比更新过程中current = unitOfWork.alternate;不为null, 后续的调用逻辑中会大量使用此处传入的current.
探寻阶段 beginWork
beginWork(current, unitOfWork, subtreeRenderLanes)(源码地址).
function beginWork(
current: Fiber | null,
workInProgress: Fiber,
renderLanes: Lanes,
): Fiber | null {
const updateLanes = workInProgress.lanes;
if (current !== null) {
// 进入对比
const oldProps = current.memoizedProps;
const newProps = workInProgress.pendingProps;
if (
oldProps !== newProps ||
hasLegacyContextChanged() ||
(__DEV__ ? workInProgress.type !== current.type : false)
) {
didReceiveUpdate = true;
} else if (!includesSomeLane(renderLanes, updateLanes)) {
// 当前渲染优先级renderLanes不包括fiber.lanes, 表明当前fiber节点无需更新
didReceiveUpdate = false;
switch (
workInProgress.tag
// switch 语句中包括 context相关逻辑, 本节暂不讨论(不影响分析fiber树构造)
) {
}
// 当前fiber节点无需更新, 调用bailoutOnAlreadyFinishedWork循环检测子节点是否需要更新
return bailoutOnAlreadyFinishedWork(current, workInProgress, renderLanes);
}
}
// 余下逻辑与初次创建共用
// 1. 设置workInProgress优先级为NoLanes(最高优先级)
workInProgress.lanes = NoLanes;
// 2. 根据workInProgress节点的类型, 用不同的方法派生出子节点
switch (
workInProgress.tag // 只列出部分case
) {
case ClassComponent: {
const Component = workInProgress.type;
const unresolvedProps = workInProgress.pendingProps;
const resolvedProps =
workInProgress.elementType === Component
? unresolvedProps
: resolveDefaultProps(Component, unresolvedProps);
return updateClassComponent(
current,
workInProgress,
Component,
resolvedProps,
renderLanes,
);
}
case HostRoot:
return updateHostRoot(current, workInProgress, renderLanes);
case HostComponent:
return updateHostComponent(current, workInProgress, renderLanes);
case HostText:
return updateHostText(current, workInProgress);
case Fragment:
return updateFragment(current, workInProgress, renderLanes);
}
}
bailout逻辑
bail out英文短语翻译为解救, 纾困, 在源码中, bailout用于判断子树节点是否完全复用, 如果可以复用, 则会略过 fiber 树构造.
与初次创建不同, 在对比更新过程中, 如果是老节点, 那么current !== null, 需要进行对比, 然后决定是否复用老节点及其子树(即bailout逻辑).
1、!includesSomeLane(renderLanes, updateLanes)这个判断分支, 包含了渲染优先级和update优先级的比较(详情可以回顾fiber 树构造(基础准备)中优先级相关解读), 如果当前节点无需更新, 则会进入bailout逻辑.
2、最后会调用bailoutOnAlreadyFinishedWork:
-
如果同时满足!includesSomeLane(renderLanes, workInProgress.childLanes), 表明该 fiber 节点及其子树都无需更新, 可直接进入回溯阶段(completeUnitOfWork)
-
如果不满足!includesSomeLane(renderLanes, workInProgress.childLanes), 意味着子节点需要更新, clone并返回子节点.
// 省略部分无关代码
function bailoutOnAlreadyFinishedWork(
current: Fiber | null,
workInProgress: Fiber,
renderLanes: Lanes,
): Fiber | null {
if (!includesSomeLane(renderLanes, workInProgress.childLanes)) {
// 渲染优先级不包括 workInProgress.childLanes, 表明子节点也无需更新. 返回null, 直接进入回溯阶段.
return null;
} else {
// 本fiber虽然不用更新, 但是子节点需要更新. clone并返回子节点
cloneChildFibers(current, workInProgress);
return workInProgress.child;
}
}
注意: cloneChildFibers内部调用createWorkInProgress, 在构造fiber节点时会优先复用workInProgress.alternate(不开辟新的内存空间), 否则才会创建新的fiber对象.
updateXXX函数
updateXXX函数(如: updateHostRoot, updateClassComponent 等)的主干逻辑与初次构造过程完全一致, 总的目的是为了向下生成子节点, 并在这个过程中调用reconcileChildren调和函数, 只要fiber节点有副作用, 就会把特殊操作设置到fiber.flags(如:节点ref,class组件的生命周期,function组件的hook,节点删除等).
对比更新过程的不同之处:
1、bailoutOnAlreadyFinishedWork
- 对比更新时如果遇到当前节点无需更新(如: class类型的节点且shouldComponentUpdate返回false), 会再次进入bailout逻辑.
2、reconcileChildren调和函数
-
调和函数是updateXXX函数中的一项重要逻辑, 它的作用是向下生成子节点, 并设置fiber.flags.
-
初次创建时fiber节点没有比较对象, 所以在向下生成子节点的时候没有任何多余的逻辑, 只管创建就行.
-
对比更新时需要把ReactElement对象与旧fiber对象进行比较, 来判断是否需要复用旧fiber对象.
注: 本节的重点是fiber树构造, 在对比更新过程中reconcileChildren()函数实现的diff算法十分重要, 但是它只是处于算法层面, 对于diff算法的实现,在React 算法之调和算法中单独分析.
本节只需要先了解调和函数目的:
1、给新增,移动,和删除节点设置fiber.flags(新增,移动: Placement, 删除: Deletion)
2、如果是需要删除的fiber, 除了自身打上Deletion之外, 还要将其添加到父节点的effects链表中(正常副作用队列的处理是在completeWork函数, 但是该节点(被删除)会脱离fiber树, 不会再进入completeWork阶段, 所以在beginWork阶段提前加入副作用队列).
回溯阶段 completeWork
completeUnitOfWork(unitOfWork)函数(源码地址)在初次创建和对比更新逻辑一致, 都是处理beginWork 阶段已经创建出来的 fiber 节点, 最后创建(更新)DOM 对象, 并上移副作用队列.
在这里我们重点关注completeWork函数中, current !== null的情况:
// ...省略无关代码
function completeWork(
current: Fiber | null,
workInProgress: Fiber,
renderLanes: Lanes,
): Fiber | null {
const newProps = workInProgress.pendingProps;
switch (workInProgress.tag) {
case HostComponent: {
// 非文本节点
popHostContext(workInProgress);
const rootContainerInstance = getRootHostContainer();
const type = workInProgress.type;
if (current !== null && workInProgress.stateNode != null) {
// 处理改动
updateHostComponent(
current,
workInProgress,
type,
newProps,
rootContainerInstance,
);
if (current.ref !== workInProgress.ref) {
markRef(workInProgress);
}
} else {
// ...省略无关代码
}
return null;
}
case HostText: {
// 文本节点
const newText = newProps;
if (current && workInProgress.stateNode != null) {
const oldText = current.memoizedProps;
// 处理改动
updateHostText(current, workInProgress, oldText, newText);
} else {
// ...省略无关代码
}
return null;
}
}
}
updateHostComponent = function (
current: Fiber,
workInProgress: Fiber,
type: Type,
newProps: Props,
rootContainerInstance: Container,
) {
const oldProps = current.memoizedProps;
if (oldProps === newProps) {
return;
}
const instance: Instance = workInProgress.stateNode;
const currentHostContext = getHostContext();
const updatePayload = prepareUpdate(
instance,
type,
oldProps,
newProps,
rootContainerInstance,
currentHostContext,
);
workInProgress.updateQueue = (updatePayload: any);
// 如果有属性变动, 设置fiber.flags |= Update, 等待`commit`阶段的处理
if (updatePayload) {
markUpdate(workInProgress);
}
};
updateHostText = function (
current: Fiber,
workInProgress: Fiber,
oldText: string,
newText: string,
) {
// 如果有属性变动, 设置fiber.flags |= Update, 等待`commit`阶段的处理
if (oldText !== newText) {
markUpdate(workInProgress);
}
};
可以看到在更新过程中, 如果 DOM 属性有变化, 不会再次新建 DOM 对象, 而是设置fiber.flags |= Update, 等待commit阶段处理(源码链接).
过程图解
针对本节的示例代码, 将整个fiber树构造过程表示出来:
构造前:
在上文已经说明, 进入循环构造前会调用prepareFreshStack刷新栈帧, 在进入fiber树构造循环之前, 保持这这个初始化状态:
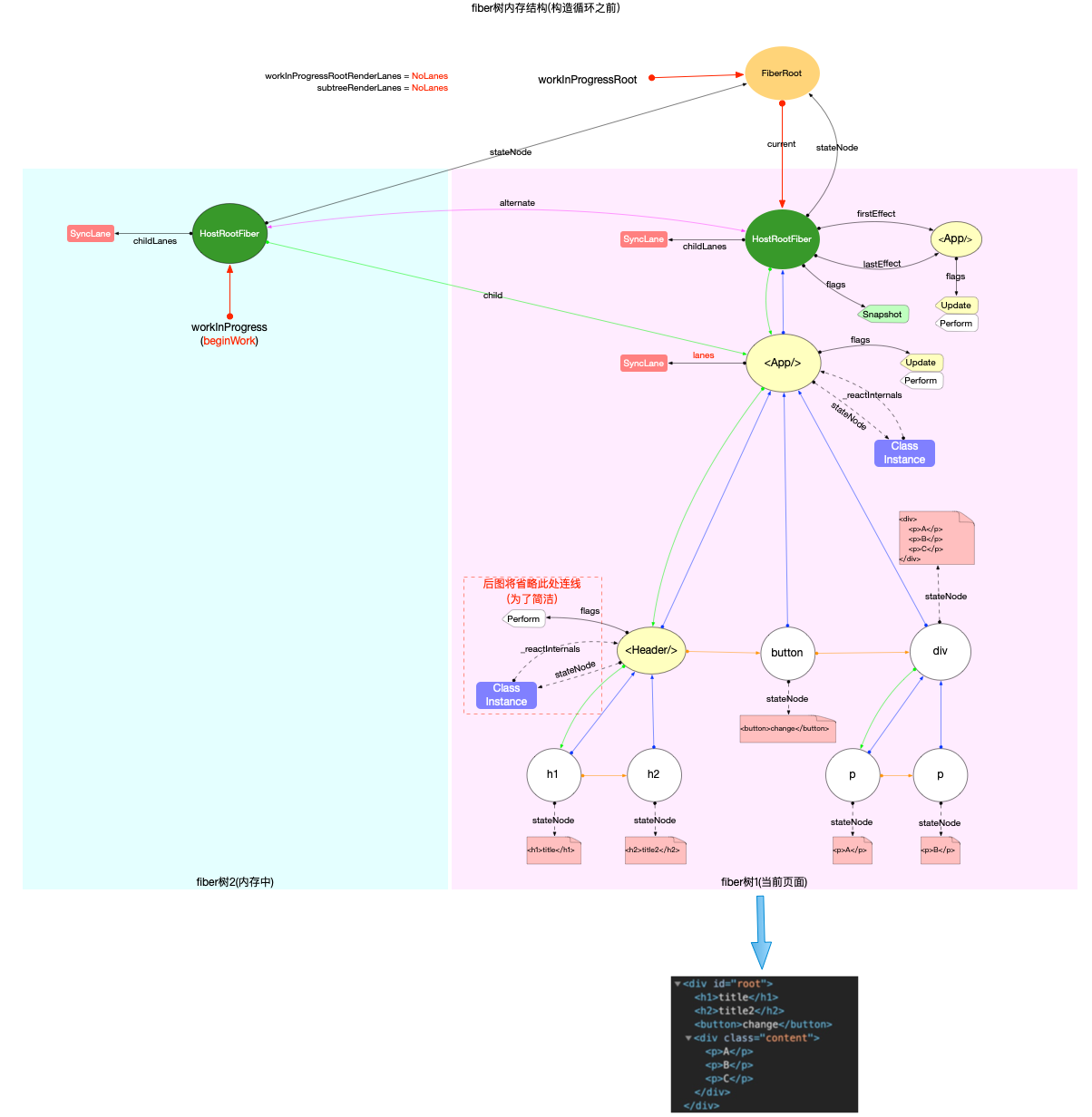
performUnitOfWork第 1 次调用(只执行beginWork):
-
执行前: workInProgress指向HostRootFiber.alternate对象, 此时current = workInProgress.alternate指向当前页面对应的fiber树.
-
执行过程:
-
因为current !== null且当前节点fiber.lanes不在渲染优先级范围内, 故进入bailoutOnAlreadyFinishedWork逻辑
-
又因为fiber.childLanes处于渲染优先级范围内, 证明child节点需要更新, 克隆workInProgress.child节点.
-
clone之后, 新fiber节点会丢弃旧fiber上的标志位(flags)和副作用(effects), 其他属性会继续保留.
-
-
执行后: 返回被clone的下级节点
fiber(<App/>), 移动workInProgress指向子节点fiber(<App/>)
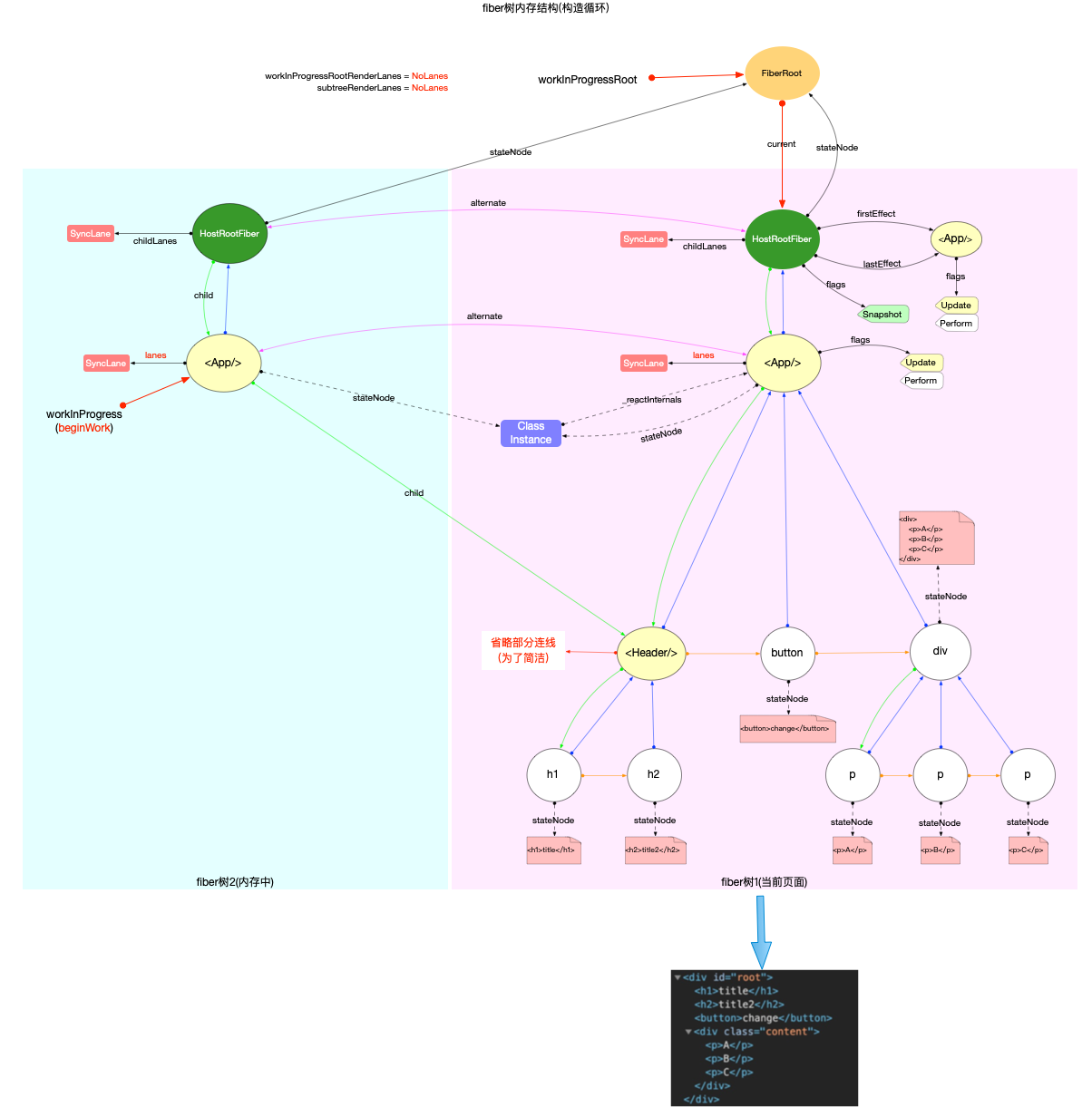
performUnitOfWork第 2 次调用(只执行beginWork):
-
执行前: workInProgress指向
fiber(<App/>)节点, 且current = workInProgress.alternate有值 -
执行过程:
-
当前节点fiber.lanes处于渲染优先级范围内, 会进入updateClassComponent()函数
-
在updateClassComponent()函数中, 调用reconcileChildren()生成下级子节点.
-
-
执行后: 返回下级节点
fiber(<Header/>), 移动workInProgress指向子节点fiber(<Header/>)
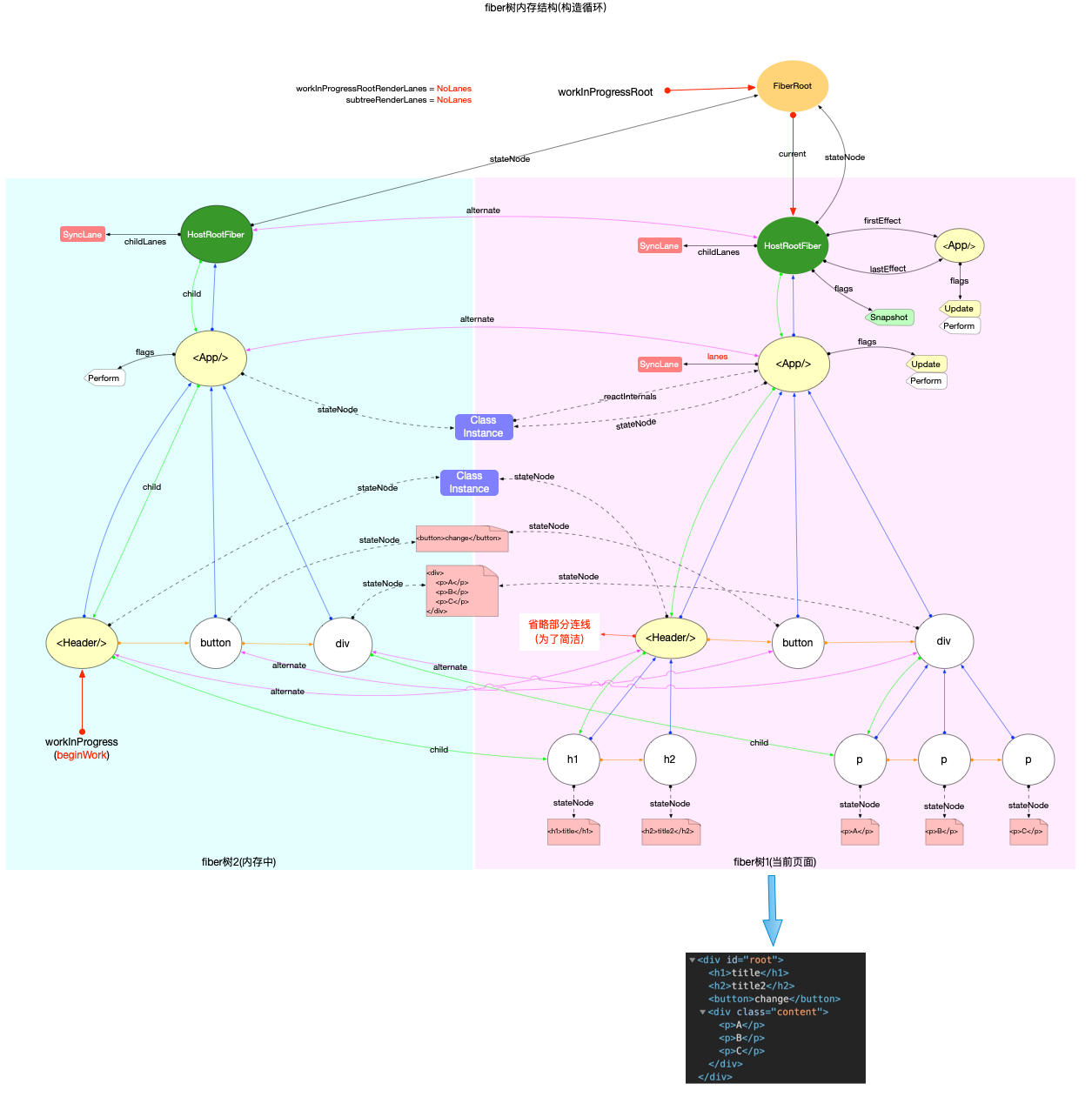
performUnitOfWork第 3 次调用(执行beginWork和completeUnitOfWork):
-
beginWork执行前: workInProgress指向
fiber(<Header/>), 且current = workInProgress.alternate有值 -
beginWork执行过程:
-
当前节点fiber.lanes处于渲染优先级范围内, 会进入updateClassComponent()函数
-
在updateClassComponent()函数中, 由于此组件是PureComponent, shouldComponentUpdate判定为false,故进入bailoutOnAlreadyFinishedWork逻辑.
-
又因为fiber.childLanes不在渲染优先级范围内, 证明child节点也不需要更新
-
-
beginWork执行后: 因为完全满足bailout逻辑, 返回null. 所以进入completeUnitOfWork(unitOfWork)函数, 传入的参数unitOfWork实际上就是workInProgress(此时指向
fiber(<Header/>))
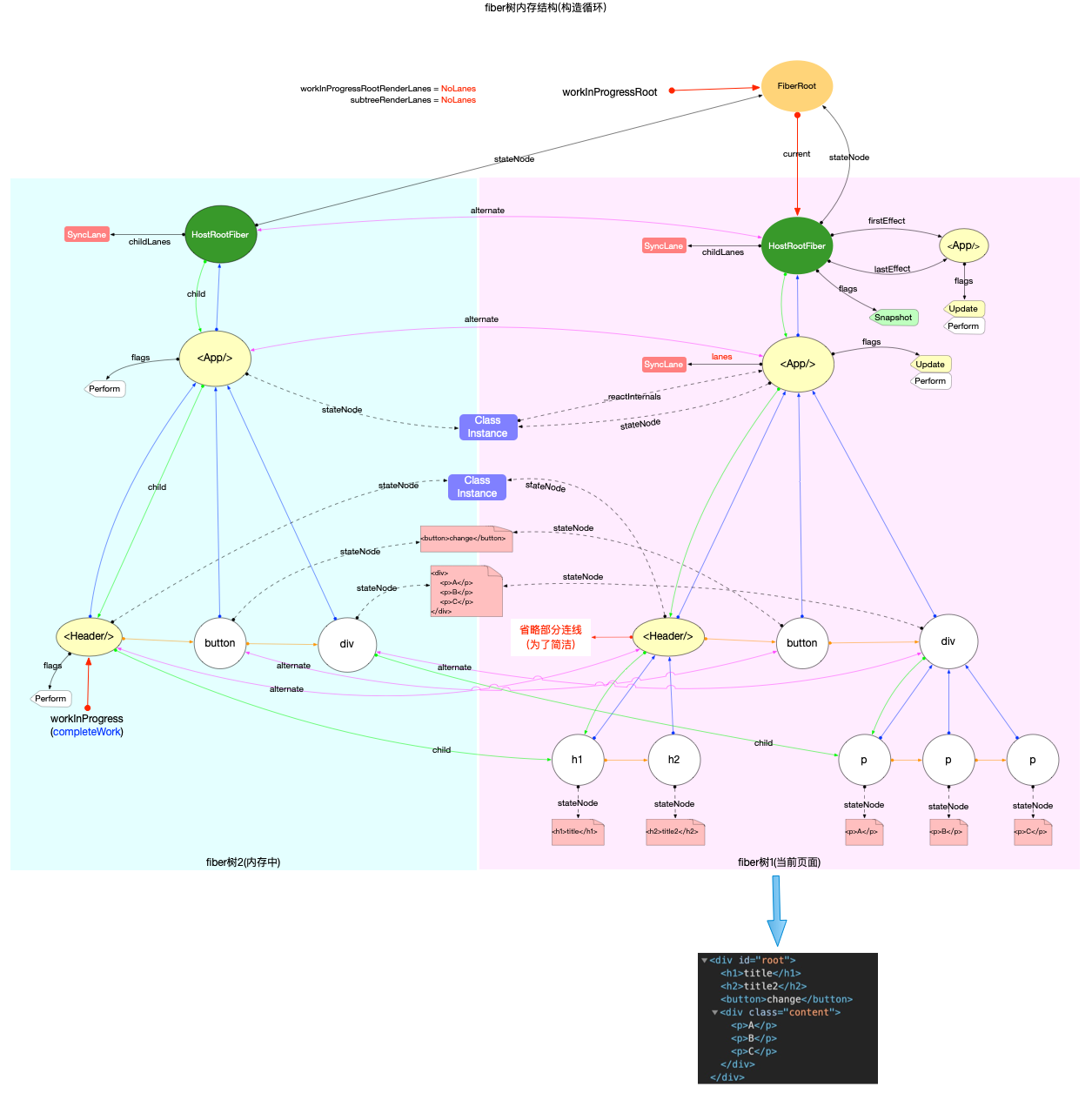
-
completeUnitOfWork执行前: workInProgress指向
fiber(<Header/>) -
completeUnitOfWork执行过程: 以
fiber(<Header/>)为起点, 向上回溯
completeUnitOfWork第 1 次循环:
1、执行completeWork函数: class类型的组件无需处理.
2、上移副作用队列: 由于本节点fiber(header)没有副作用(fiber.flags = 0), 所以执行之后副作用队列没有实质变化(目前为空).
3、向上回溯: 由于还有兄弟节点, 把workInProgress指向下一个兄弟节点fiber(button), 退出completeUnitOfWork.
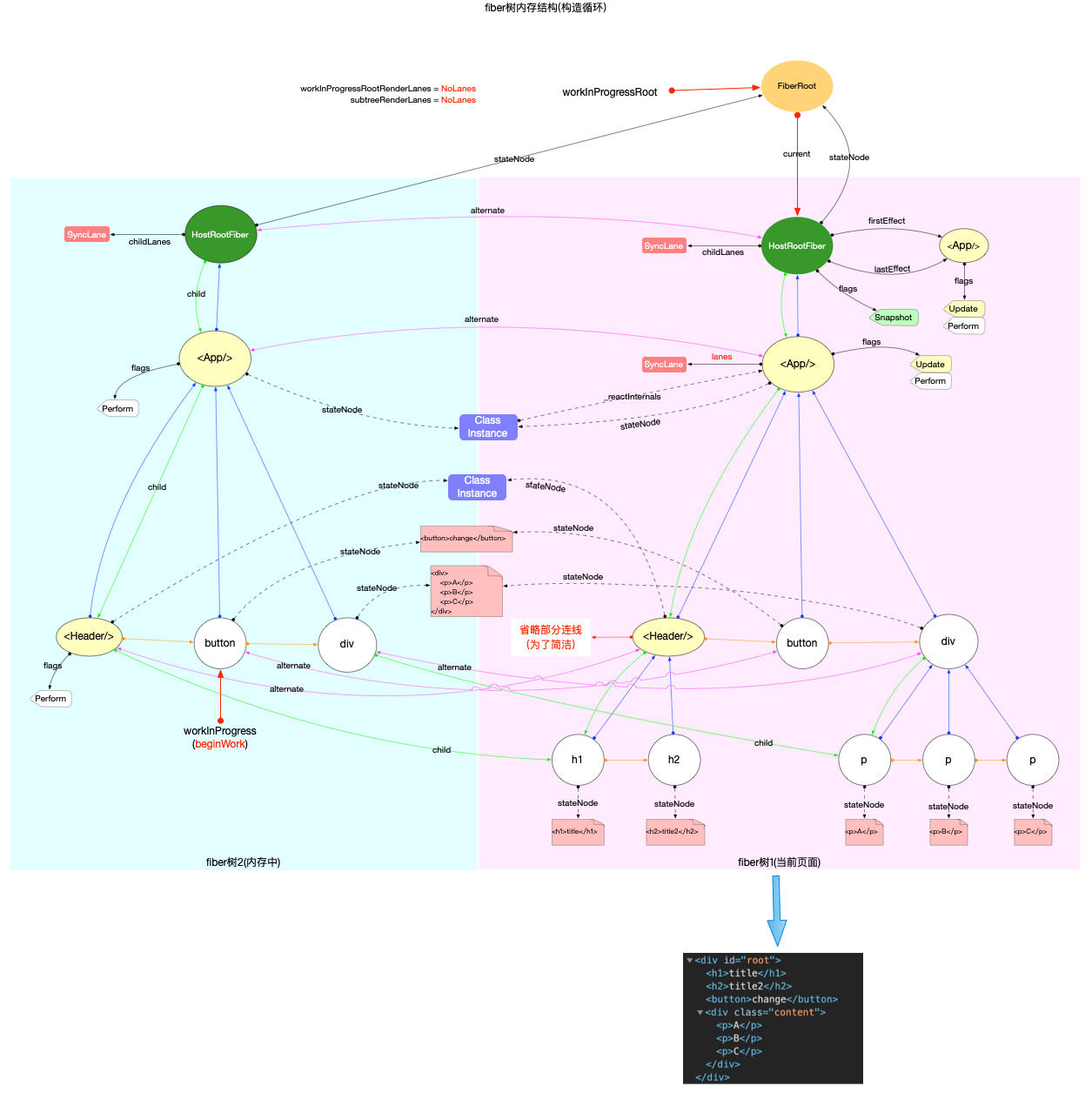
performUnitOfWork第 4 次调用(执行beginWork和completeUnitOfWork):
-
beginWork执行过程: 调用updateHostComponent
-
本示例中button的子节点是一个直接文本节点,设置nextChildren = null(源码注释的解释是不用在开辟内存去创建一个文本节点, 同时还能减少向下遍历).
-
由于nextChildren = null, 经过reconcileChildren阶段处理后, 返回值也是null
-
-
beginWork执行后: 由于下级节点为null, 所以进入completeUnitOfWork(unitOfWork)函数, 传入的参数unitOfWork实际上就是workInProgress(此时指向fiber(button)节点)
-
completeUnitOfWork执行过程: 以fiber(button)为起点, 向上回溯
completeUnitOfWork第 1 次循环:
1、执行completeWork函数
-
因为fiber(button).stateNode != null, 所以无需再次创建 DOM 对象. 只需要进一步调用updateHostComponent()记录 DOM 属性改动情况
-
在updateHostComponent()函数中, 又因为oldProps === newProps, 所以无需记录改动情况, 直接返回
2、上移副作用队列: 由于本节点fiber(button)没有副作用(fiber.flags = 0), 所以执行之后副作用队列没有实质变化(目前为空).
3、向上回溯: 由于还有兄弟节点, 把workInProgress指向下一个兄弟节点fiber(div), 退出completeUnitOfWork.
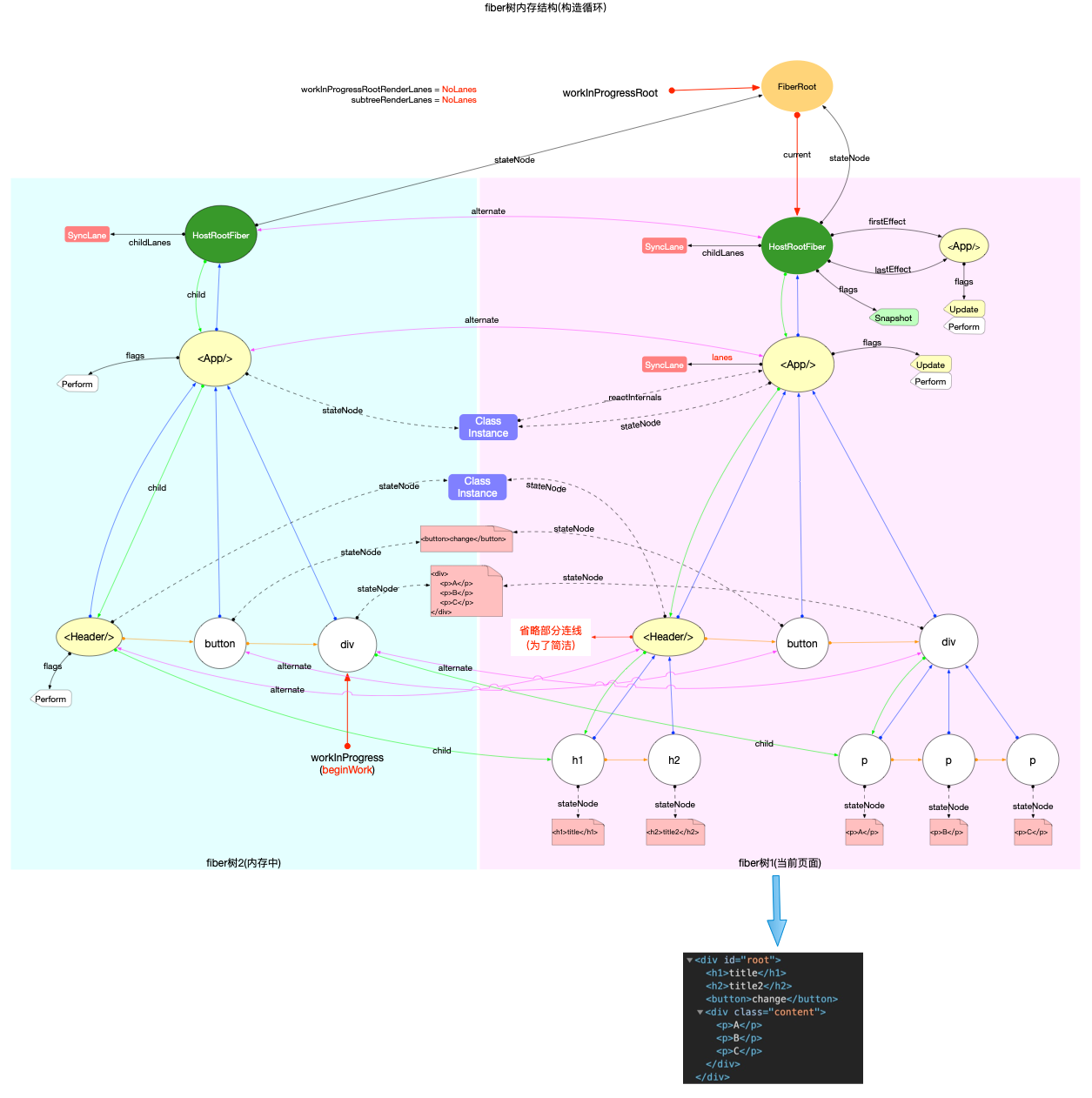
performUnitOfWork第 5 次调用(执行beginWork):
-
执行前: workInProgress指向fiber(div)节点, 且current = workInProgress.alternate有值
-
执行过程:
-
在updateHostComponent()函数中, 调用reconcileChildren()生成下级子节点.
-
需要注意的是, 下级子节点是一个可迭代数组, 会把fiber.child.sibling一起构造出来, 同时根据需要设置fiber.flags. 在本例中, 下级节点有被删除的情况, 被删除的节点会被添加到父节点的副作用队列中(具体实现方式请参考React 算法之调和算法).
-
-
执行后: 返回下级节点fiber(p), 移动workInProgress指向子节点fiber(p)
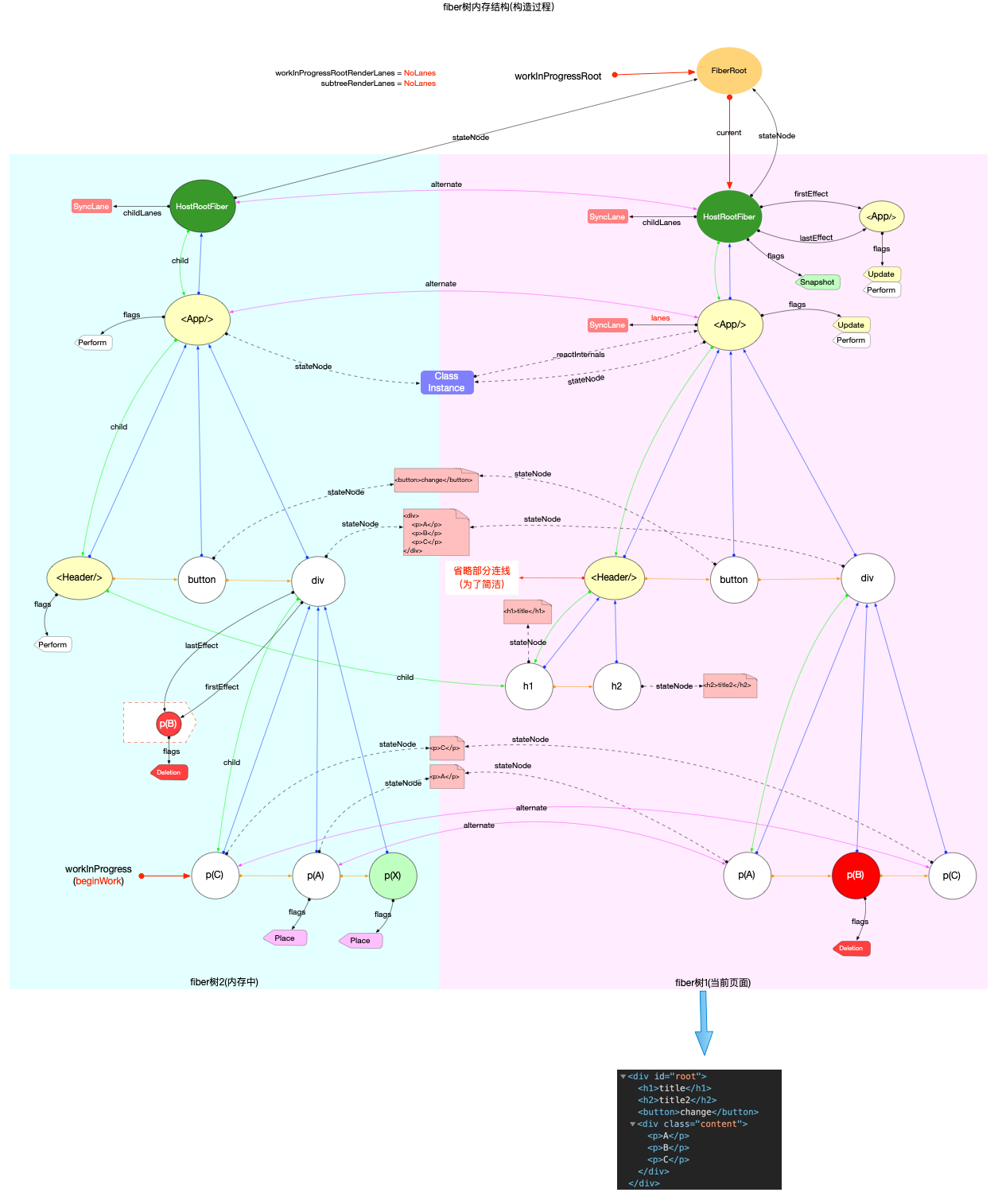
performUnitOfWork第 6 次调用(执行beginWork和completeUnitOfWork):
-
beginWork执行过程: 与第 4 次调用中构建fiber(button)的逻辑完全一致, 因为都是直接文本节点, reconcileChildren()返回的下级子节点为 null.
-
beginWork执行后: 由于下级节点为null, 所以进入completeUnitOfWork(unitOfWork)函数
-
completeUnitOfWork执行过程: 以fiber(p)为起点, 向上回溯
completeUnitOfWork第 1 次循环:
1、执行completeWork函数
- 因为fiber(p).stateNode != null, 所以无需再次创建 DOM 对象. 在updateHostComponent()函数中, 又因为节点属性没有变动, 所以无需打标记
2、上移副作用队列: 本节点fiber(p)没有副作用(fiber.flags = 0).
3、向上回溯: 由于还有兄弟节点, 把workInProgress指向下一个兄弟节点fiber(p), 退出completeUnitOfWork.
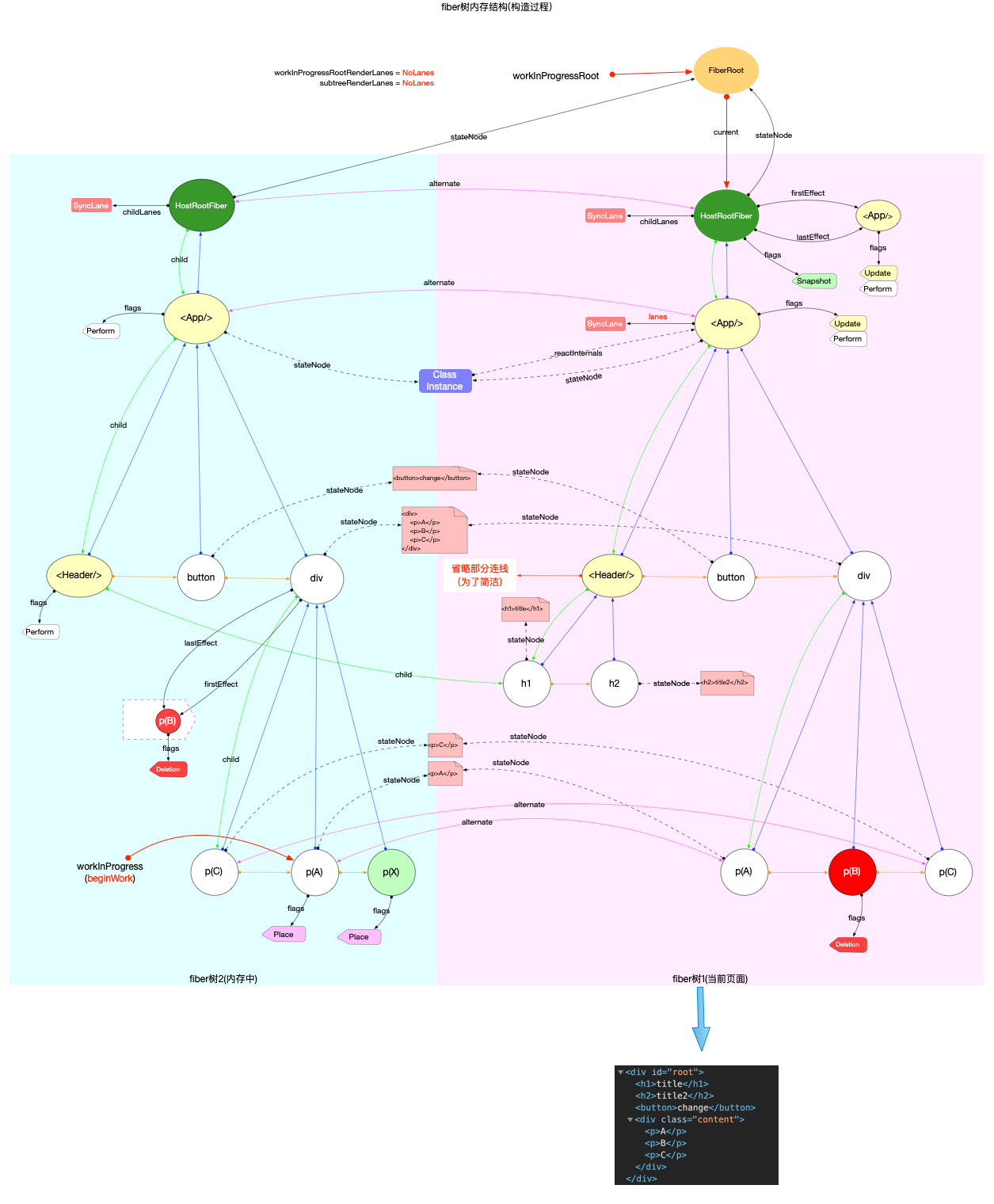
performUnitOfWork第 7 次调用(执行beginWork和completeUnitOfWork):
-
beginWork执行过程: 与第 4 次调用中构建fiber(button)的逻辑完全一致, 因为都是直接文本节点, reconcileChildren()返回的下级子节点为 null.
-
beginWork执行后: 由于下级节点为null, 所以进入completeUnitOfWork(unitOfWork)函数
-
completeUnitOfWork执行过程: 以fiber(p)为起点, 向上回溯
completeUnitOfWork第 1 次循环:
1、执行completeWork函数:
- 因为fiber(p).stateNode != null, 所以无需再次创建 DOM 对象. 在updateHostComponent()函数中, 又因为节点属性没有变动, 所以无需打标记
2、上移副作用队列: 本节点fiber(p)有副作用(fiber.flags = Placement), 需要将其添加到父节点的副作用队列之后.
3、向上回溯: 由于还有兄弟节点, 把workInProgress指向下一个兄弟节点fiber(p), 退出completeUnitOfWork.
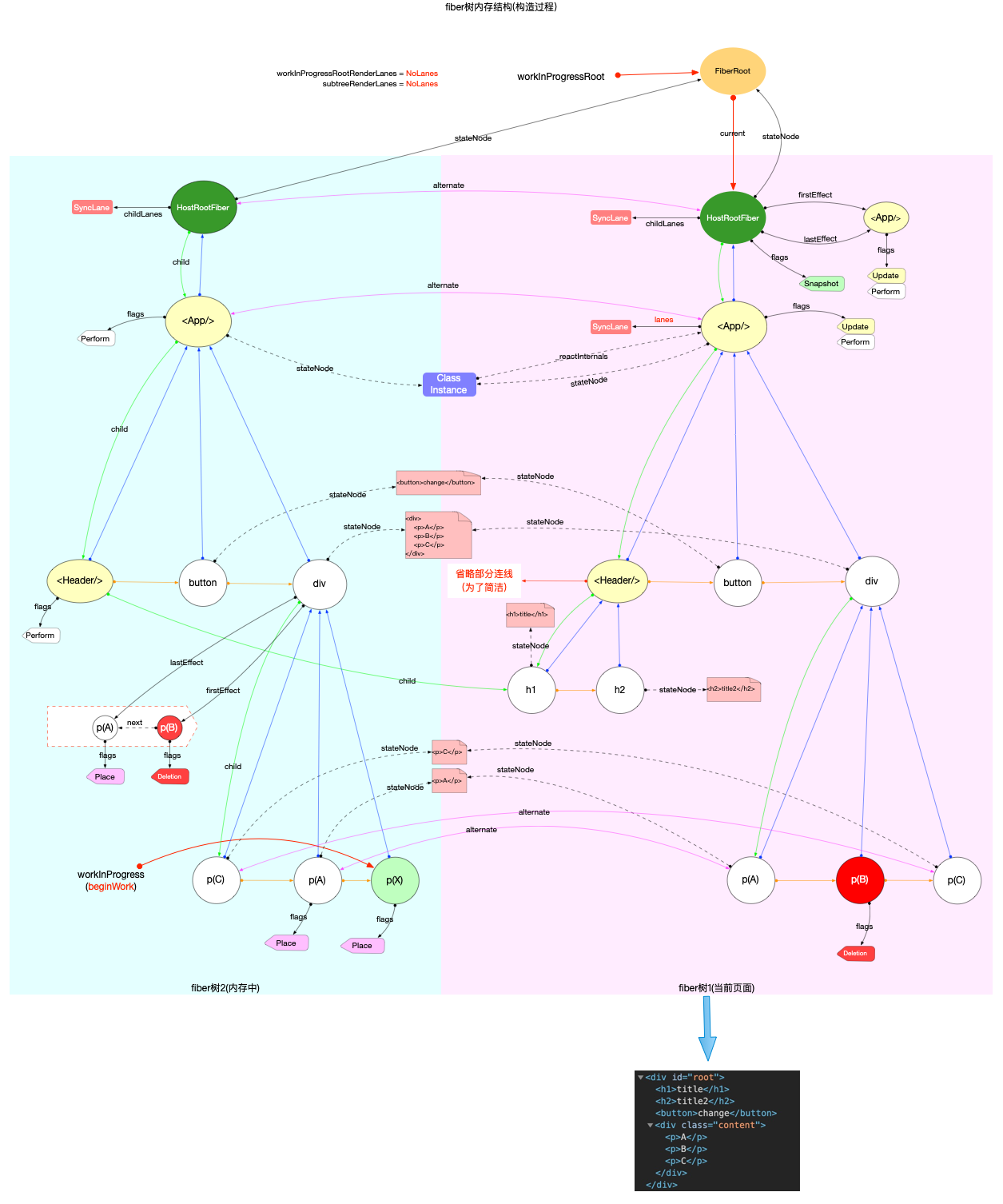
performUnitOfWork第 8 次调用(执行beginWork和completeUnitOfWork):
-
beginWork执行过程: 本节点fiber(p)是一个新增节点, 其current === null, 会进入updateHostComponent()函数. 因为是直接文本节点, reconcileChildren()返回的下级子节点为 null.
-
beginWork执行后: 由于下级节点为null, 所以进入completeUnitOfWork(unitOfWork)函数
-
completeUnitOfWork执行过程: 以fiber(p)为起点, 向上回溯
completeUnitOfWork第 1 次循环:
1、执行completeWork函数: 由于本节点是一个新增节点,且fiber(p).stateNode === null, 所以创建fiber(p)节点对应的DOM实例, 挂载到fiber.stateNode之上.
2、上移副作用队列: 本节点fiber(p)有副作用(fiber.flags = Placement), 需要将其添加到父节点的副作用队列之后.
3、向上回溯: 由于没有兄弟节点, 把workInProgress指针指向父节点fiber(div).
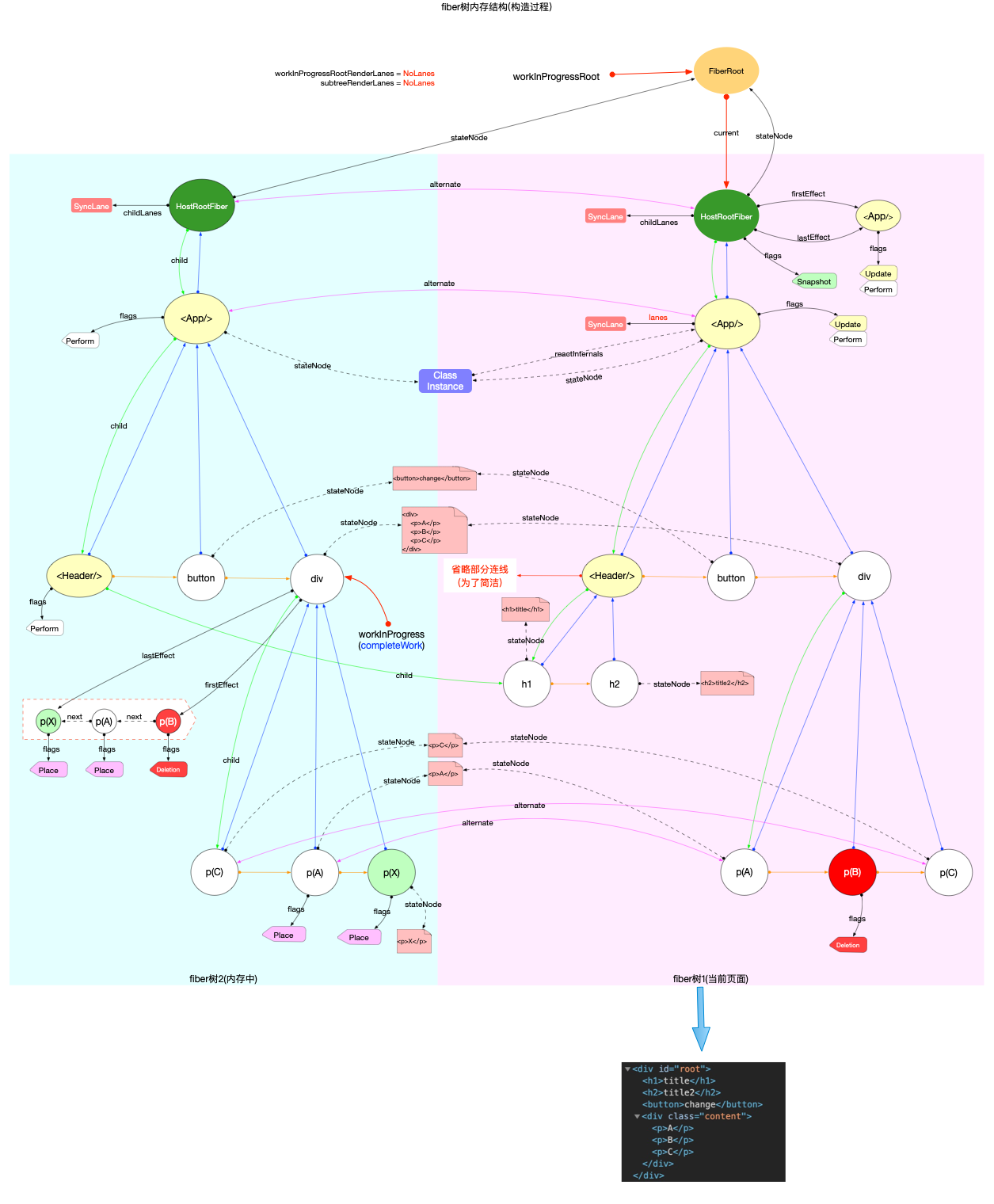
completeUnitOfWork第 2 次循环:
1、执行completeWork函数: 由于div组件没有属性变动, 故updateHostComponent()没有设置副作用标记
2、上移副作用队列: 本节点fiber(div)的副作用队列添加到父节点的副作用队列之后.
3、向上回溯: 由于没有兄弟节点, 把workInProgress指针指向父节点fiber(<App/>)
completeUnitOfWork第 3 次循环:
1、执行completeWork函数: class 类型的节点无需处理
2、上移副作用队列: 本节点fiber(<App/>)的副作用队列添加到父节点的副作用队列之后.
3、向上回溯: 由于没有兄弟节点, 把workInProgress指针指向父节点fiber(HostRootFiber)
completeUnitOfWork第 4 次循环:
1、执行completeWork函数: HostRoot类型的节点无需处理
2、向上回溯: 由于父节点为空, 无需进入处理副作用队列的逻辑. 最后设置workInProgress=null, 并退出completeUnitOfWork
3、重置fiber.childLanes
到此整个fiber树构造循环(对比更新)已经执行完毕, 拥有一棵新的fiber树, 并且在fiber树的根节点上挂载了副作用队列. renderRootSync函数退出之前, 会重置workInProgressRoot = null, 表明没有正在进行中的render. 且把最新的fiber树挂载到fiberRoot.finishedWork上. 这时整个 fiber 树的内存结构如下(注意fiberRoot.finishedWork和fiberRoot.current指针,在commitRoot阶段会进行处理):
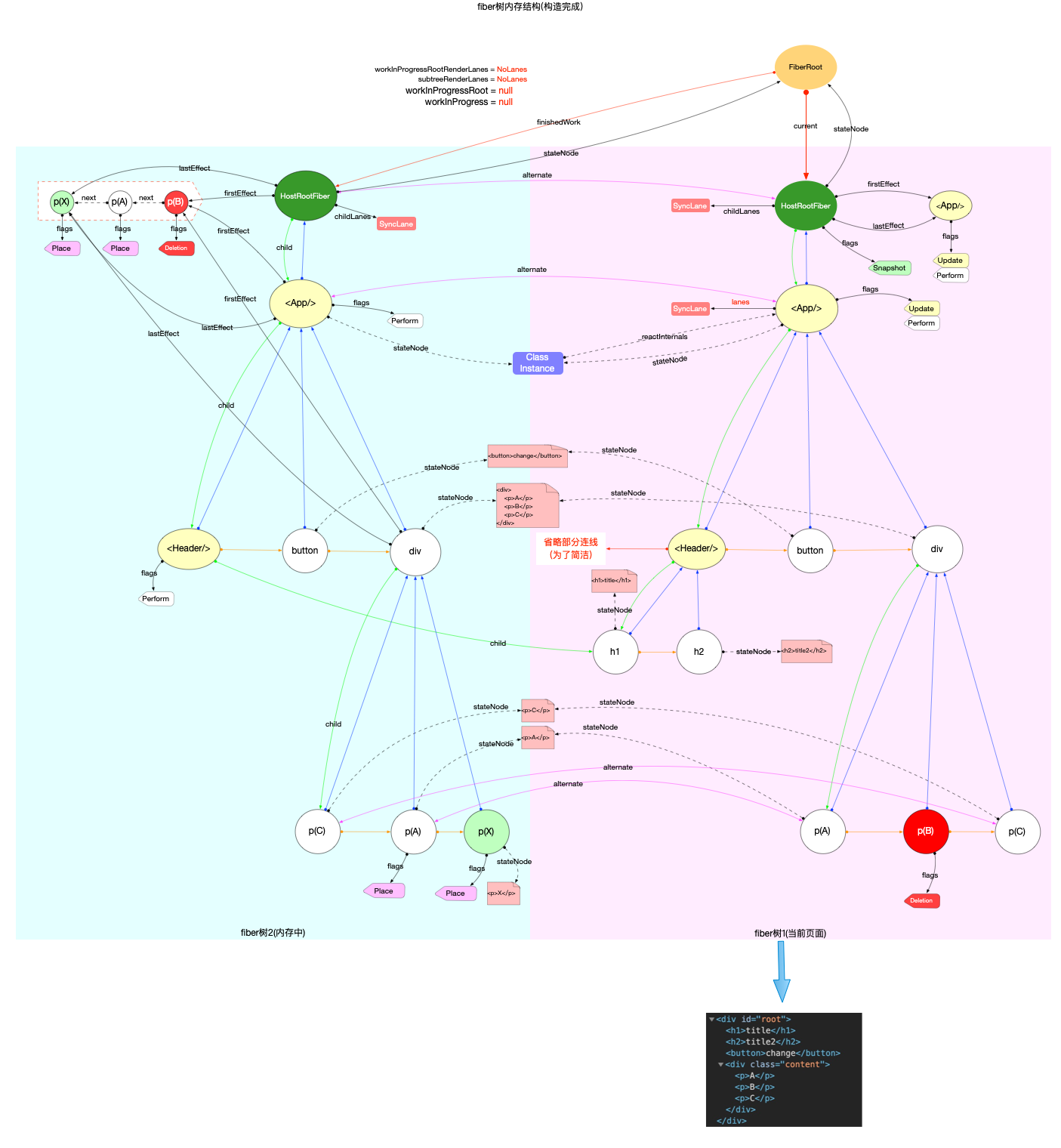
无论是初次构造或者是对比更新, 当fiber树构造完成之后, 余下的逻辑几乎一致, 在fiber 树渲染中继续讨论.
本节演示了更新阶段fiber树构造(对比更新)的全部过程, 跟踪了创建过程中内存引用的变化情况. 与初次构造最大的不同在于fiber节点是否可以复用, 其中bailout逻辑是fiber子树能否复用的判断依据.
fiber 树渲染
在正式分析fiber树渲染之前, 再次回顾一下reconciler 运作流程的 4 个阶段:
1、输入阶段: 衔接react-dom包, 承接fiber更新请求(参考React 应用的启动过程).
2、注册调度任务: 与调度中心(scheduler包)交互, 注册调度任务task, 等待任务回调(参考React 调度原理(scheduler)).
3、执行任务回调: 在内存中构造出fiber树和DOM对象(参考fiber 树构造(初次创建)和 fiber 树构造(对比更新)).
4、输出: 与渲染器(react-dom)交互, 渲染DOM节点.
本节分析其中的第 4 阶段(输出), fiber树渲染处于reconciler 运作流程这一流水线的最后一环, 或者说前面的步骤都是为了最后一步服务, 所以其重要性不言而喻.
前文已经介绍了fiber树构造, 现在分析fiber树渲染过程, 这个过程, 实际上是对fiber树的进一步处理.
fiber 树特点
通过前文fiber树构造的解读, 可以总结出fiber树的基本特点:
-
无论是首次构造或者是对比更新, 最终都会在内存中生成一棵用于渲染页面的fiber树(即fiberRoot.finishedWork).
-
这棵将要被渲染的fiber树有 2 个特点:
1、副作用队列挂载在根节点上(具体来讲是finishedWork.firstEffect)
2、代表最新页面的DOM对象挂载在fiber树中首个HostComponent类型的节点上(具体来讲DOM对象是挂载在fiber.stateNode属性上)
这里再次回顾前文使用过的 2 棵 fiber 树, 可以验证上述特点:
1、初次构造
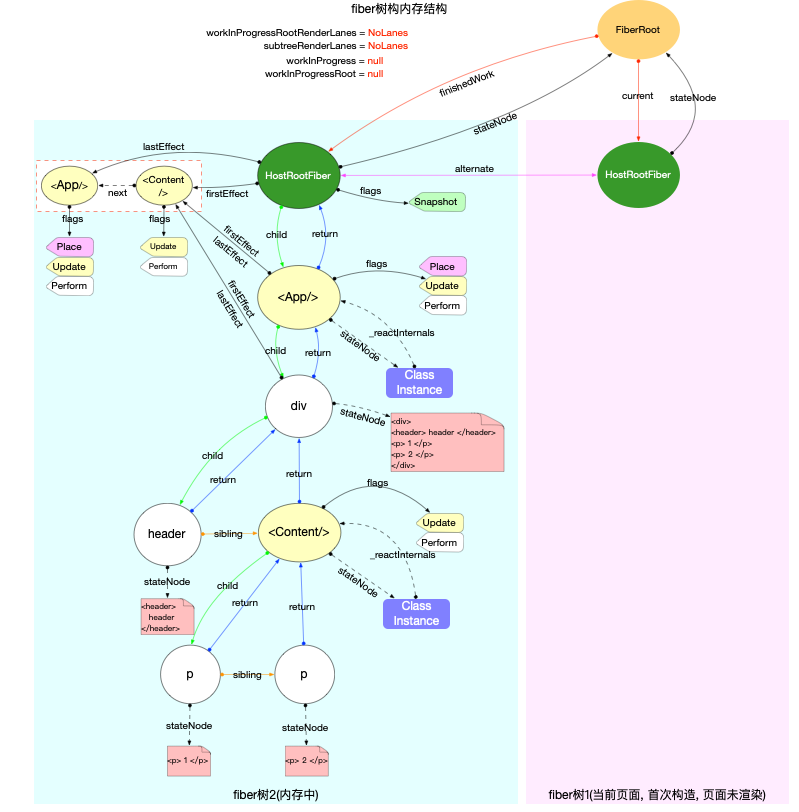
2、对比更新
commitRoot
整个渲染逻辑都在commitRoot 函数中:
function commitRoot(root) {
const renderPriorityLevel = getCurrentPriorityLevel();
runWithPriority(
ImmediateSchedulerPriority,
commitRootImpl.bind(null, root, renderPriorityLevel),
);
return null;
}
在commitRoot中同时使用到了渲染优先级和调度优先级, 有关优先级的讨论, 在前文已经做出了说明(参考React 中的优先级管理和fiber 树构造(基础准备)#优先级), 本节不再赘述. 最后的实现是通过commitRootImpl函数:
// ... 省略部分无关代码
function commitRootImpl(root, renderPriorityLevel) {
// ============ 渲染前: 准备 ============
const finishedWork = root.finishedWork;
const lanes = root.finishedLanes;
// 清空FiberRoot对象上的属性
root.finishedWork = null;
root.finishedLanes = NoLanes;
root.callbackNode = null;
if (root === workInProgressRoot) {
// 重置全局变量
workInProgressRoot = null;
workInProgress = null;
workInProgressRootRenderLanes = NoLanes;
}
// 再次更新副作用队列
let firstEffect;
if (finishedWork.flags > PerformedWork) {
// 默认情况下fiber节点的副作用队列是不包括自身的
// 如果根节点有副作用, 则将根节点添加到副作用队列的末尾
if (finishedWork.lastEffect !== null) {
finishedWork.lastEffect.nextEffect = finishedWork;
firstEffect = finishedWork.firstEffect;
} else {
firstEffect = finishedWork;
}
} else {
firstEffect = finishedWork.firstEffect;
}
// ============ 渲染 ============
let firstEffect = finishedWork.firstEffect;
if (firstEffect !== null) {
const prevExecutionContext = executionContext;
executionContext |= CommitContext;
// 阶段1: dom突变之前
nextEffect = firstEffect;
do {
commitBeforeMutationEffects();
} while (nextEffect !== null);
// 阶段2: dom突变, 界面发生改变
nextEffect = firstEffect;
do {
commitMutationEffects(root, renderPriorityLevel);
} while (nextEffect !== null);
// 恢复界面状态
resetAfterCommit(root.containerInfo);
// 切换current指针
root.current = finishedWork;
// 阶段3: layout阶段, 调用生命周期componentDidUpdate和回调函数等
nextEffect = firstEffect;
do {
commitLayoutEffects(root, lanes);
} while (nextEffect !== null);
nextEffect = null;
executionContext = prevExecutionContext;
}
// ============ 渲染后: 重置与清理 ============
if (rootDoesHavePassiveEffects) {
// 有被动作用(使用useEffect), 保存一些全局变量
} else {
// 分解副作用队列链表, 辅助垃圾回收
// 如果有被动作用(使用useEffect), 会把分解操作放在flushPassiveEffects函数中
nextEffect = firstEffect;
while (nextEffect !== null) {
const nextNextEffect = nextEffect.nextEffect;
nextEffect.nextEffect = null;
if (nextEffect.flags & Deletion) {
detachFiberAfterEffects(nextEffect);
}
nextEffect = nextNextEffect;
}
}
// 重置一些全局变量(省略这部分代码)...
// 下面代码用于检测是否有新的更新任务
// 比如在componentDidMount函数中, 再次调用setState()
// 1. 检测常规(异步)任务, 如果有则会发起异步调度(调度中心`scheduler`只能异步调用)
ensureRootIsScheduled(root, now());
// 2. 检测同步任务, 如果有则主动调用flushSyncCallbackQueue(无需再次等待scheduler调度), 再次进入fiber树构造循环
flushSyncCallbackQueue();
return null;
}
commitRootImpl函数中, 可以根据是否调用渲染, 把整个commitRootImpl分为 3 段(分别是渲染前, 渲染, 渲染后).
渲染前
为接下来正式渲染, 做一些准备工作. 主要包括:
1、设置全局状态(如: 更新fiberRoot上的属性)
2、重置全局变量(如: workInProgressRoot, workInProgress等)
3、再次更新副作用队列: 只针对根节点fiberRoot.finishedWork
-
默认情况下根节点的副作用队列是不包括自身的, 如果根节点有副作用, 则将根节点添加到副作用队列的末尾
-
注意只是延长了副作用队列, 但是fiberRoot.lastEffect指针并没有改变.
-
比如首次构造时, 根节点拥有Snapshot标记:
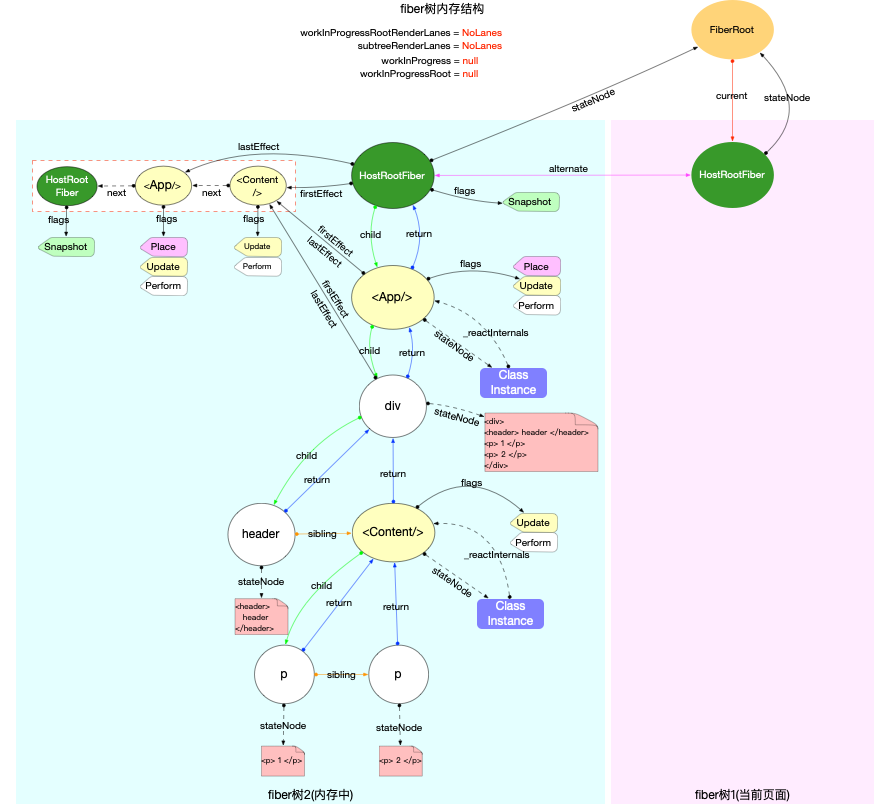
渲染
commitRootImpl函数中, 渲染阶段的主要逻辑是处理副作用队列, 将最新的 DOM 节点(已经在内存中, 只是还没渲染)渲染到界面上.
整个渲染过程被分为 3 个函数分布实现:
1、commitBeforeMutationEffects
- dom 变更之前, 处理副作用队列中带有Snapshot,Passive标记的fiber节点.
2、commitMutationEffects
- dom 变更, 界面得到更新. 处理副作用队列中带有Placement, Update, Deletion, Hydrating标记的fiber节点.
3、commitLayoutEffects
- dom 变更后, 处理副作用队列中带有
Update | Callback标记的fiber节点.
通过上述源码分析, 可以把commitRootImpl的职责概括为 2 个方面:
1、处理副作用队列. (步骤 1,2,3 都会处理, 只是处理节点的标识fiber.flags不同).
2、调用渲染器, 输出最终结果. (在步骤 2: commitMutationEffects中执行).
所以commitRootImpl是处理fiberRoot.finishedWork这棵即将被渲染的fiber树, 理论上无需关心这棵fiber树是如何产生的(可以是首次构造产生, 也可以是对比更新产生). 为了清晰简便, 在下文的所有图示都使用初次创建的fiber树结构来进行演示.
这 3 个函数处理的对象是副作用队列和DOM对象.
所以无论fiber树结构有多么复杂, 到了commitRoot阶段, 实际起作用的只有 2 个节点:
-
副作用队列所在节点: 根节点, 即HostRootFiber节点.
-
DOM对象所在节点: 从上至下首个HostComponent类型的fiber节点, 此节点fiber.stateNode实际上指向最新的 DOM 树.
下图为了清晰, 省略了一些无关引用, 只留下commitRoot阶段实际会用到的fiber节点:
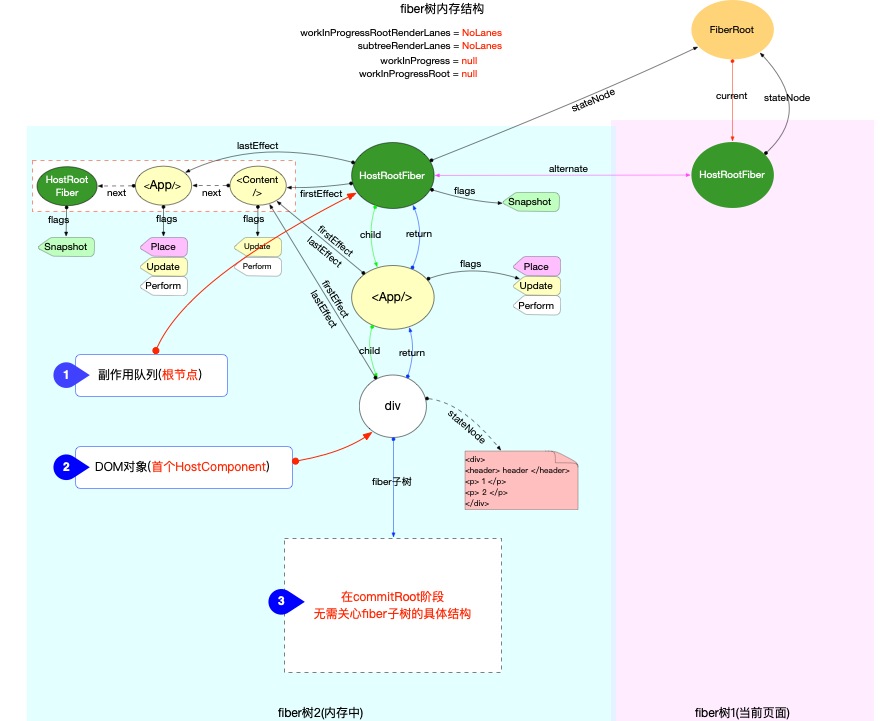
commitBeforeMutationEffects
第一阶段: dom 变更之前, 处理副作用队列中带有Snapshot,Passive标记的fiber节点.
// ... 省略部分无关代码
function commitBeforeMutationEffects() {
while (nextEffect !== null) {
const current = nextEffect.alternate;
const flags = nextEffect.flags;
// 处理`Snapshot`标记
if ((flags & Snapshot) !== NoFlags) {
commitBeforeMutationEffectOnFiber(current, nextEffect);
}
// 处理`Passive`标记
if ((flags & Passive) !== NoFlags) {
// Passive标记只在使用了hook, useEffect会出现. 所以此处是针对hook对象的处理
if (!rootDoesHavePassiveEffects) {
rootDoesHavePassiveEffects = true;
scheduleCallback(NormalSchedulerPriority, () => {
flushPassiveEffects();
return null;
});
}
}
nextEffect = nextEffect.nextEffect;
}
}
注意:commitBeforeMutationEffectOnFiber实际上对应了commitBeforeMutationLifeCycles函数,在导入时进行了重命名
1、处理Snapshot标记
function commitBeforeMutationLifeCycles(
current: Fiber | null,
finishedWork: Fiber,
): void {
switch (finishedWork.tag) {
case FunctionComponent:
case ForwardRef:
case SimpleMemoComponent:
case Block: {
return;
}
case ClassComponent: {
if (finishedWork.flags & Snapshot) {
if (current !== null) {
const prevProps = current.memoizedProps;
const prevState = current.memoizedState;
const instance = finishedWork.stateNode;
const snapshot = instance.getSnapshotBeforeUpdate(
finishedWork.elementType === finishedWork.type
? prevProps
: resolveDefaultProps(finishedWork.type, prevProps),
prevState,
);
instance.__reactInternalSnapshotBeforeUpdate = snapshot;
}
}
return;
}
case HostRoot: {
if (supportsMutation) {
if (finishedWork.flags & Snapshot) {
const root = finishedWork.stateNode;
clearContainer(root.containerInfo);
}
}
return;
}
case HostComponent:
case HostText:
case HostPortal:
case IncompleteClassComponent:
return;
}
}
从源码中可以看到, 与Snapshot标记相关的类型只有ClassComponent和HostRoot.
-
对于ClassComponent类型节点, 调用了instance.getSnapshotBeforeUpdate生命周期函数
-
对于HostRoot类型节点, 调用clearContainer清空了容器节点(即div#root这个 dom 节点).
2、处理Passive标记
Passive标记只会在使用了hook对象的function类型的节点上存在, 后续的执行过程在hook原理章节中详细说明. 此处我们需要了解在commitRoot的第一个阶段, 为了处理hook对象(如useEffect), 通过scheduleCallback单独注册了一个调度任务task, 等待调度中心scheduler处理.
注意: 通过调度中心scheduler调度的任务task均是通过MessageChannel触发, 都是异步执行(可参考React 调度原理(scheduler)).
小测试:
// 以下示例代码中的输出顺序为 1, 3, 4, 2
function Test() {
console.log(1);
useEffect(() => {
console.log(2);
});
console.log(3);
Promise.resolve(() => {
console.log(4);
});
return <div>test</div>;
}
commitMutationEffects
第二阶段: dom 变更, 界面得到更新. 处理副作用队列中带有ContentReset, Ref, Placement, Update, Deletion, Hydrating标记的fiber节点.
// ...省略部分无关代码
function commitMutationEffects(
root: FiberRoot,
renderPriorityLevel: ReactPriorityLevel,
) {
// 处理Ref
if (flags & Ref) {
const current = nextEffect.alternate;
if (current !== null) {
// 先清空ref, 在commitRoot的第三阶段(dom变更后), 再重新赋值
commitDetachRef(current);
}
}
// 处理DOM突变
while (nextEffect !== null) {
const flags = nextEffect.flags;
const primaryFlags = flags & (Placement | Update | Deletion | Hydrating);
switch (primaryFlags) {
case Placement: {
// 新增节点
commitPlacement(nextEffect);
nextEffect.flags &= ~Placement; // 注意Placement标记会被清除
break;
}
case PlacementAndUpdate: {
// Placement
commitPlacement(nextEffect);
nextEffect.flags &= ~Placement;
// Update
const current = nextEffect.alternate;
commitWork(current, nextEffect);
break;
}
case Update: {
// 更新节点
const current = nextEffect.alternate;
commitWork(current, nextEffect);
break;
}
case Deletion: {
// 删除节点
commitDeletion(root, nextEffect, renderPriorityLevel);
break;
}
}
nextEffect = nextEffect.nextEffect;
}
}
处理 DOM 突变:
1、新增: 函数调用栈 commitPlacement -> insertOrAppendPlacementNode -> appendChild
2、更新: 函数调用栈 commitWork -> commitUpdate
3、删除: 函数调用栈 commitDeletion -> removeChild
最终会调用appendChild, commitUpdate, removeChild这些react-dom包中的函数. 它们是HostConfig协议(源码在 ReactDOMHostConfig.js 中)中规定的标准函数, 在渲染器react-dom包中进行实现. 这些函数就是直接操作 DOM, 所以执行之后, 界面也会得到更新.
注意: commitMutationEffects执行之后, 在commitRootImpl函数中切换当前fiber树(root.current = finishedWork),保证fiberRoot.current指向代表当前界面的fiber树.
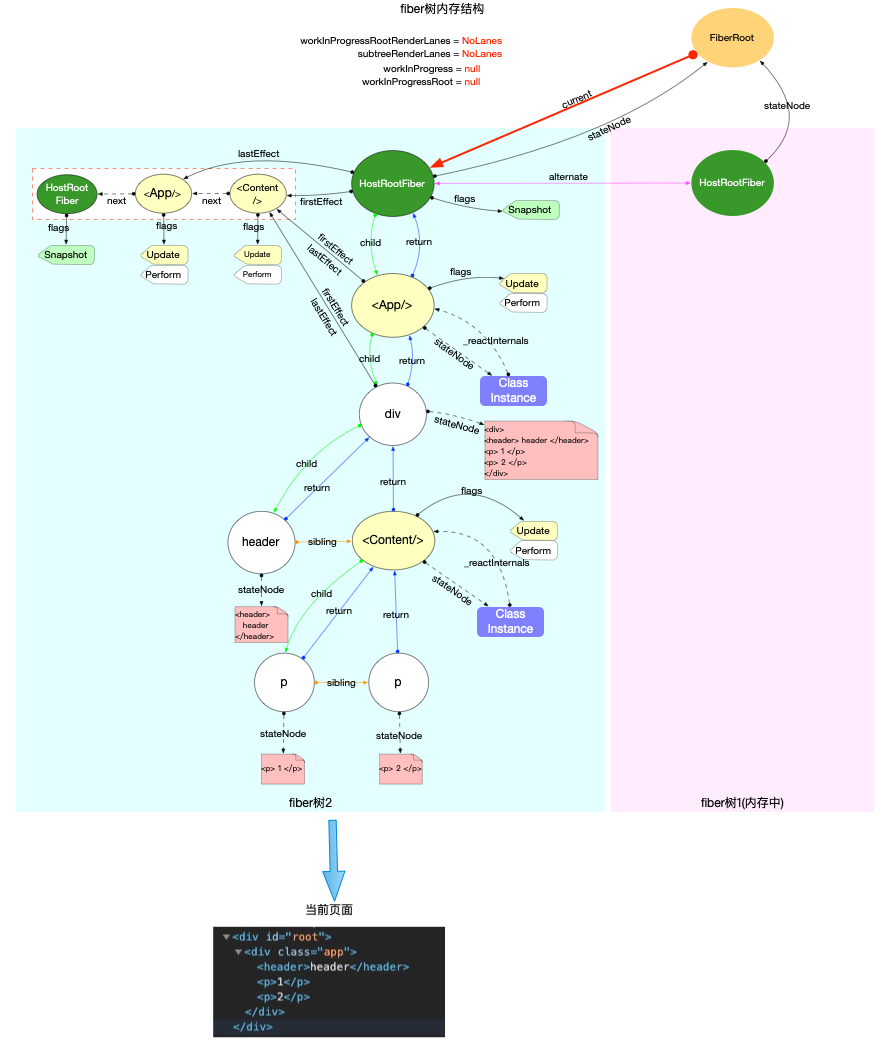
commitLayoutEffects
第三阶段: dom 变更后, 处理副作用队列中带有Update, Callback, Ref标记的fiber节点.
// ...省略部分无关代码
function commitLayoutEffects(root: FiberRoot, committedLanes: Lanes) {
while (nextEffect !== null) {
const flags = nextEffect.flags;
// 处理 Update和Callback标记
if (flags & (Update | Callback)) {
const current = nextEffect.alternate;
commitLayoutEffectOnFiber(root, current, nextEffect, committedLanes);
}
if (flags & Ref) {
// 重新设置ref
commitAttachRef(nextEffect);
}
nextEffect = nextEffect.nextEffect;
}
}
核心逻辑都在commitLayoutEffectOnFiber->commitLifeCycles函数中.
// ...省略部分无关代码
function commitLifeCycles(
finishedRoot: FiberRoot,
current: Fiber | null,
finishedWork: Fiber,
committedLanes: Lanes,
): void {
switch (finishedWork.tag) {
case ClassComponent: {
const instance = finishedWork.stateNode;
if (finishedWork.flags & Update) {
if (current === null) {
// 初次渲染: 调用 componentDidMount
instance.componentDidMount();
} else {
const prevProps =
finishedWork.elementType === finishedWork.type
? current.memoizedProps
: resolveDefaultProps(finishedWork.type, current.memoizedProps);
const prevState = current.memoizedState;
// 更新阶段: 调用 componentDidUpdate
instance.componentDidUpdate(
prevProps,
prevState,
instance.__reactInternalSnapshotBeforeUpdate,
);
}
}
const updateQueue: UpdateQueue<*> | null =
(finishedWork.updateQueue: any);
if (updateQueue !== null) {
// 处理update回调函数 如: this.setState({}, callback)
commitUpdateQueue(finishedWork, updateQueue, instance);
}
return;
}
case HostComponent: {
const instance: Instance = finishedWork.stateNode;
if (current === null && finishedWork.flags & Update) {
const type = finishedWork.type;
const props = finishedWork.memoizedProps;
// 设置focus等原生状态
commitMount(instance, type, props, finishedWork);
}
return;
}
}
}
在commitLifeCycles函数中:
-
对于ClassComponent节点, 调用生命周期函数componentDidMount或componentDidUpdate, 调用update.callback回调函数.
-
对于HostComponent节点, 如有Update标记, 需要设置一些原生状态(如: focus等)
渲染后
执行完上述步骤之后, 本次渲染任务就已经完成了. 在渲染完成后, 需要做一些重置和清理工作:
1、清除副作用队列
-
由于副作用队列是一个链表, 由于单个fiber对象的引用关系, 无法被gc回收.
-
将链表全部拆开, 当fiber对象不再使用的时候, 可以被gc回收.
![]()
2、检测更新
-
在整个渲染过程中, 有可能产生新的update(比如在componentDidMount函数中, 再次调用setState()).
-
如果是常规(异步)任务, 不用特殊处理, 调用ensureRootIsScheduled确保任务已经注册到调度中心即可.
-
如果是同步任务, 则主动调用flushSyncCallbackQueue(无需再次等待 scheduler 调度), 再次进入 fiber 树构造循环
// 清除副作用队列
if (rootDoesHavePassiveEffects) {
// 有被动作用(使用useEffect), 保存一些全局变量
} else {
// 分解副作用队列链表, 辅助垃圾回收.
// 如果有被动作用(使用useEffect), 会把分解操作放在flushPassiveEffects函数中
nextEffect = firstEffect;
while (nextEffect !== null) {
const nextNextEffect = nextEffect.nextEffect;
nextEffect.nextEffect = null;
if (nextEffect.flags & Deletion) {
detachFiberAfterEffects(nextEffect);
}
nextEffect = nextNextEffect;
}
}
// 重置一些全局变量(省略这部分代码)...
// 下面代码用于检测是否有新的更新任务
// 比如在componentDidMount函数中, 再次调用setState()
// 1. 检测常规(异步)任务, 如果有则会发起异步调度(调度中心`scheduler`只能异步调用)
ensureRootIsScheduled(root, now());
// 2. 检测同步任务, 如果有则主动调用flushSyncCallbackQueue(无需再次等待scheduler调度), 再次进入fiber树构造循环
flushSyncCallbackQueue();
本节分析了fiber 树渲染的处理过程, 从宏观上看fiber 树渲染位于reconciler 运作流程中的输出阶段, 是整个reconciler 运作流程的链路中最后一环(从输入到输出). 本节根据源码, 具体从渲染前, 渲染, 渲染后三个方面分解了commitRootImpl函数. 其中最核心的渲染逻辑又分为了 3 个函数, 这 3 个函数共同处理了有副作用fiber节点, 并通过渲染器react-dom把最新的 DOM 对象渲染到界面上.
状态与副作用
在前文我们已经分析了fiber树从构造到渲染的关键过程. 本节我们站在fiber对象的视角, 考虑一个具体的fiber节点如何影响最终的渲染.
回顾fiber 数据结构, 并结合前文fiber树构造系列的解读, 我们注意到fiber众多属性中, 有 2 类属性十分关键:
1、fiber节点的自身状态: 在renderRootSync[Concurrent]阶段, 为子节点提供确定的输入数据, 直接影响子节点的生成.
2、fiber节点的副作用: 在commitRoot阶段, 如果fiber被标记有副作用, 则副作用相关函数会被(同步/异步)调用.
export type Fiber = {|
// 1. fiber节点自身状态相关
pendingProps: any,
memoizedProps: any,
updateQueue: mixed,
memoizedState: any,
// 2. fiber节点副作用(Effect)相关
flags: Flags,
subtreeFlags: Flags, // v17.0.2未启用
deletions: Array<Fiber> | null, // v17.0.2未启用
nextEffect: Fiber | null,
firstEffect: Fiber | null,
lastEffect: Fiber | null,
|};
状态
与状态相关有 4 个属性:
1、fiber.pendingProps: 输入属性, 从ReactElement对象传入的 props. 它和fiber.memoizedProps比较可以得出属性是否变动.
2、fiber.memoizedProps: 上一次生成子节点时用到的属性, 生成子节点之后保持在内存中. 向下生成子节点之前叫做pendingProps, 生成子节点之后会把pendingProps赋值给memoizedProps用于下一次比较.pendingProps和memoizedProps比较可以得出属性是否变动.
3、fiber.updateQueue: 存储update更新对象的队列, 每一次发起更新, 都需要在该队列上创建一个update对象.
4、fiber.memoizedState: 上一次生成子节点之后保持在内存中的局部状态.
它们的作用只局限于fiber树构造阶段, 直接影响子节点的生成.
副作用
与副作用相关有 4 个属性:
1、fiber.flags: 标志位, 表明该fiber节点有副作用(在 v17.0.2 中共定义了28 种副作用).
2、fiber.nextEffect: 单向链表, 指向下一个副作用 fiber节点.
3、fiber.firstEffect: 单向链表, 指向第一个副作用 fiber 节点.
4、fiber.lastEffect: 单向链表, 指向最后一个副作用 fiber 节点.
通过前文fiber树构造我们知道, 单个fiber节点的副作用队列最后都会上移到根节点上. 所以在commitRoot阶段中, react提供了 3 种处理副作用的方式(详见fiber 树渲染).
另外, 副作用的设计可以理解为对状态功能不足的补充.
-
状态是一个静态的功能, 它只能为子节点提供数据源.
-
而副作用是一个动态功能, 由于它的调用时机是在fiber树渲染阶段, 故它拥有更多的能力, 能轻松获取突变前快照, 突变后的DOM节点等. 甚至通过调用api发起新的一轮fiber树构造, 进而改变更多的状态, 引发更多的副作用.
外部 api
fiber对象的这 2 类属性, 可以影响到渲染结果, 但是fiber结构始终是一个内核中的结构, 对于外部来讲是无感知的, 对于调用方来讲, 甚至都无需知道fiber结构的存在. 所以正常只有通过暴露api来直接或间接的修改这 2 类属性.
从react包暴露出的api来归纳, 只有 2 类组件支持修改:
本节只讨论使用api的目的是修改fiber的状态和副作用, 进而可以改变整个渲染结果. 本节先介绍 api 与状态和副作用的联系, 有关api的具体实现会在class组件,Hook原理章节中详细分析.
class 组件
class App extends React.Component {
constructor() {
this.state = {
// 初始状态
a: 1,
};
}
changeState = () => {
this.setState({ a: ++this.state.a }); // 进入reconciler流程
};
// 生命周期函数: 状态相关
static getDerivedStateFromProps(nextProps, prevState) {
console.log('getDerivedStateFromProps');
return prevState;
}
// 生命周期函数: 状态相关
shouldComponentUpdate(newProps, newState, nextContext) {
console.log('shouldComponentUpdate');
return true;
}
// 生命周期函数: 副作用相关 fiber.flags |= Update
componentDidMount() {
console.log('componentDidMount');
}
// 生命周期函数: 副作用相关 fiber.flags |= Snapshot
getSnapshotBeforeUpdate(prevProps, prevState) {
console.log('getSnapshotBeforeUpdate');
}
// 生命周期函数: 副作用相关 fiber.flags |= Update
componentDidUpdate() {
console.log('componentDidUpdate');
}
render() {
// 返回下级ReactElement对象
return <button onClick={this.changeState}>{this.state.a}</button>;
}
}
状态相关: fiber树构造阶段.
1、构造函数: constructor实例化时执行, 可以设置初始 state, 只执行一次.
2、生命周期: getDerivedStateFromProps在fiber树构造阶段(renderRootSync[Concurrent])执行, 可以修改 state(链接).
3、生命周期: shouldComponentUpdate在, fiber树构造阶段(renderRootSync[Concurrent])执行, 返回值决定是否执行 render(链接).
副作用相关: fiber树渲染阶段.
1、生命周期: getSnapshotBeforeUpdate在fiber树渲染阶段(commitRoot->commitBeforeMutationEffects->commitBeforeMutationEffectOnFiber)执行(链接).
2、生命周期: componentDidMount在fiber树渲染阶段(commitRoot->commitLayoutEffects->commitLayoutEffectOnFiber)执行(链接).
3、生命周期: componentDidUpdate在fiber树渲染阶段(commitRoot->commitLayoutEffects->commitLayoutEffectOnFiber)执行(链接).
可以看到, 官方api提供的class组件生命周期函数实际上也是围绕fiber树构造和fiber树渲染来提供的.
function 组件
注: function组件与class组件最大的不同是: class组件会实例化一个instance所以拥有独立的局部状态; 而function组件不会实例化, 它只是被直接调用, 故无法维护一份独立的局部状态, 只能依靠Hook对象间接实现局部状态(有关更多Hook实现细节, 在Hook原理章节中详细讨论).
在v17.0.2中共定义了14 种 Hook, 其中最常用的useState, useEffect, useLayoutEffect等
function App() {
// 状态相关: 初始状态
const [a, setA] = useState(1);
const changeState = () => {
setA(++a); // 进入reconciler流程
};
// 副作用相关: fiber.flags |= Update | Passive;
useEffect(() => {
console.log(`useEffect`);
}, []);
// 副作用相关: fiber.flags |= Update;
useLayoutEffect(() => {
console.log(`useLayoutEffect`);
}, []);
// 返回下级ReactElement对象
return <button onClick={changeState}>{a}</button>;
}
状态相关: fiber树构造阶段.
1、useState在fiber树构造阶段(renderRootSync[Concurrent])执行, 可以修改Hook.memoizedState.
副作用相关: fiber树渲染阶段.
1、useEffect在fiber树渲染阶段(commitRoot->commitBeforeMutationEffects->commitBeforeMutationEffectOnFiber)执行(注意是异步执行, 链接).
2、useLayoutEffect在fiber树渲染阶段(commitRoot->commitLayoutEffects->commitLayoutEffectOnFiber->commitHookEffectListMount)执行(同步执行, 链接).
细节与误区
这里有 2 个细节:
1、useEffect(function(){}, [])中的函数是异步执行, 因为它经过了调度中心(具体实现可以回顾调度原理).
2、useLayoutEffect和Class组件中的componentDidMount,componentDidUpdate从调用时机上来讲是等价的, 因为他们都在commitRoot->commitLayoutEffects函数中被调用.
误区: 虽然官网文档推荐尽可能使用标准的 useEffect 以避免阻塞视觉更新 , 所以很多开发者使用useEffect来代替componentDidMount,componentDidUpdate是不准确的, 如果完全类比, useLayoutEffect比useEffect更符合componentDidMount,componentDidUpdate的定义.
本节从fiber视角出发, 总结了fiber节点中可以影响最终渲染结果的 2 类属性(状态和副作用).并且归纳了class和function组件中, 直接或间接更改fiber属性的常用方式. 最后从fiber树构造和渲染的角度对class的生命周期函数与function的Hooks函数进行了比较.
Hook 原理(概览)
在前文状态与副作用中, 总结了class组件, function组件中通过api去改变fiber节点的状态和副作用. 其中对于function组件来讲, 其内部则需要依靠Hook来实现.
官方文档上专门用了一个版块来介绍Hook, 这里摘抄了几个比较关心的问题(其他FAQ请移步官网):
1、引入Hook的动机?
- 在组件之间复用状态逻辑很难; 复杂组件变得难以理解; 难以理解的 class. 为了解决这些实际开发痛点, 引入了Hook.
2、Hook 是什么? 什么时候会用 Hook?
-
Hook 是一个特殊的函数, 它可以让你“钩入” React 的特性. 如, useState 是允许你在 React 函数组件中添加 state 的 Hook.
-
如果你在编写函数组件并意识到需要向其添加一些 state, 以前的做法是必须将其转化为 class. 现在你可以在现有的函数组件中使用 Hook.
3、Hook 会因为在渲染时创建函数而变慢吗?
-
不会. 在现代浏览器中,闭包和类的原始性能只有在极端场景下才会有明显的差别. 除此之外,可以认为 Hook 的设计在某些方面更加高效:
-
Hook 避免了 class 需要的额外开支,像是创建类实例和在构造函数中绑定事件处理器的成本.
-
符合语言习惯的代码在使用 Hook 时不需要很深的组件树嵌套. 这个现象在使用高阶组件、render props、和 context 的代码库中非常普遍. 组件树小了, React 的工作量也随之减少.
-
所以Hook是React团队在大量实践后的产物, 更优雅的代替class, 且性能更高. 故从开发使用者的角度来讲, 应该拥抱Hook所带来的便利.
Hook 与 Fiber
通过官网文档的讲解, 能快速掌握Hook的使用. 再结合前文状态与副作用的介绍, 我们知道使用Hook最终也是为了控制fiber节点的状态和副作用. 从fiber视角, 状态和副作用相关的属性如下(这里不再解释单个属性的意义, 可以回顾状态与副作用):
export type Fiber = {|
// 1. fiber节点自身状态相关
pendingProps: any,
memoizedProps: any,
updateQueue: mixed,
memoizedState: any,
// 2. fiber节点副作用(Effect)相关
flags: Flags,
nextEffect: Fiber | null,
firstEffect: Fiber | null,
lastEffect: Fiber | null,
|};
使用Hook的任意一个api, 最后都是为了控制上述这几个fiber属性.
Hook 数据结构
在ReactFiberHooks中, 定义了Hook的数据结构:
type Update<S, A> = {|
lane: Lane,
action: A,
eagerReducer: ((S, A) => S) | null,
eagerState: S | null,
next: Update<S, A>,
priority?: ReactPriorityLevel,
|};
type UpdateQueue<S, A> = {|
pending: Update<S, A> | null,
dispatch: ((A) => mixed) | null,
lastRenderedReducer: ((S, A) => S) | null,
lastRenderedState: S | null,
|};
export type Hook = {|
memoizedState: any, // 当前状态
baseState: any, // 基状态
baseQueue: Update<any, any> | null, // 基队列
queue: UpdateQueue<any, any> | null, // 更新队列
next: Hook | null, // next指针
|};
从定义来看, Hook对象共有 5 个属性(有关这些属性的应用, 将在Hook 原理(状态)章节中具体分析.):
1、hook.memoizedState: 保持在内存中的局部状态.
2、hook.baseState: hook.baseQueue中所有update对象合并之后的状态.
3、hook.baseQueue: 存储update对象的环形链表, 只包括高于本次渲染优先级的update对象.
4、hook.queue: 存储update对象的环形链表, 包括所有优先级的update对象.
5、hook.next: next指针, 指向链表中的下一个hook.
所以Hook是一个链表, 单个Hook拥有自己的状态hook.memoizedState和自己的更新队列hook.queue(有关 Hook 状态的分析, 在Hook原理(状态)章节中解读).
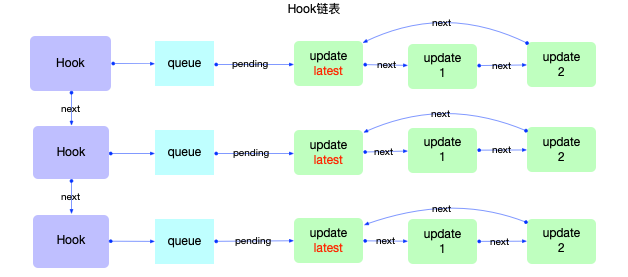
注意: 其中hook.queue与fiber.updateQueue虽然都是update环形链表, 尽管update对象的数据结构与处理方式都高度相似, 但是这 2 个队列中的update对象是完全独立的. hook.queue只作用于hook对象的状态维护, 切勿与fiber.updateQueue混淆.
Hook 分类
在v17.0.2中, 共定义了14 种 Hook
export type HookType =
| 'useState'
| 'useReducer'
| 'useContext'
| 'useRef'
| 'useEffect'
| 'useLayoutEffect'
| 'useCallback'
| 'useMemo'
| 'useImperativeHandle'
| 'useDebugValue'
| 'useDeferredValue'
| 'useTransition'
| 'useMutableSource'
| 'useOpaqueIdentifier';
官网上已经将其分为了 2 个类别, 状态Hook(State Hook), 和副作用Hook(Effect Hook).
这里我们可以结合前文状态与副作用, 从fiber的视角去理解状态Hook与副作用Hook的区别.
状态 Hook
狭义上讲, useState, useReducer可以在function组件添加内部的state, 且useState实际上是useReducer的简易封装, 是一个最特殊(简单)的useReducer. 所以将useState, useReducer称为状态Hook.
广义上讲, 只要能实现数据持久化且没有副作用的Hook, 均可以视为状态Hook, 所以还包括useContext, useRef, useCallback, useMemo等. 这类Hook内部没有使用useState/useReducer, 但是它们也能实现多次render时, 保持其初始值不变(即数据持久化)且没有任何副作用.
得益于双缓冲技术(double buffering), 在多次render时, 以fiber为载体, 保证复用同一个Hook对象, 进而实现数据持久化. 具体实现细节, 在Hook原理(状态)章节中讨论.
副作用 Hook
回到fiber视角, 状态Hook实现了状态持久化(等同于class组件维护fiber.memoizedState), 那么副作用Hook则会修改fiber.flags. (通过前文fiber树构造系列的解读, 我们知道在performUnitOfWork->completeWork阶段, 所有存在副作用的fiber节点, 都会被添加到父节点的副作用队列后, 最后在commitRoot阶段处理这些副作用节点.)
另外, 副作用Hook还提供了副作用回调(类似于class组件的生命周期回调), 比如:
// 使用useEffect时, 需要传入一个副作用回调函数.
// 在fiber树构造完成之后, commitRoot阶段会处理这些副作用回调
useEffect(() => {
console.log('这是一个副作用回调函数');
}, []);
在react内部, useEffect就是最标准的副作用Hook. 其他比如useLayoutEffect以及自定义Hook, 如果要实现副作用, 必须直接或间接的调用useEffect.
有关useEffect具体实现细节, 在Hook原理(副作用)章节中讨论.
组合 Hook
虽然官网并无组合Hook的说法, 但事实上大多数Hook(包括自定义Hook)都是由上述 2 种 Hook组合而成, 同时拥有这 2 种 Hook 的特性.
-
在react内部有useDeferredValue, useTransition, useMutableSource, useOpaqueIdentifier等.
-
平时开发中, 自定义Hook大部分都是组合 Hook.
比如官网上的自定义 Hook例子:
import { useState, useEffect } from 'react';
function useFriendStatus(friendID) {
// 1. 调用useState, 创建一个状态Hook
const [isOnline, setIsOnline] = useState(null);
// 2. 调用useEffect, 创建一个副作用Hook
useEffect(() => {
function handleStatusChange(status) {
setIsOnline(status.isOnline);
}
ChatAPI.subscribeToFriendStatus(friendID, handleStatusChange);
return () => {
ChatAPI.unsubscribeFromFriendStatus(friendID, handleStatusChange);
};
});
return isOnline;
}
调用 function 前
在调用function之前, react内部还需要提前做一些准备工作.
处理函数
从fiber树构造的视角来看, 不同的fiber类型, 只需要调用不同的处理函数返回fiber子节点. 所以在performUnitOfWork->beginWork函数中, 调用了多种处理函数. 从调用方来讲, 无需关心处理函数的内部实现(比如updateFunctionComponent内部使用了Hook对象, updateClassComponent内部使用了class实例).
本节讨论Hook, 所以列出其中的updateFunctionComponent函数:
// 只保留FunctionComponent相关:
function beginWork(
current: Fiber | null,
workInProgress: Fiber,
renderLanes: Lanes,
): Fiber | null {
const updateLanes = workInProgress.lanes;
switch (workInProgress.tag) {
case FunctionComponent: {
const Component = workInProgress.type;
const unresolvedProps = workInProgress.pendingProps;
const resolvedProps =
workInProgress.elementType === Component
? unresolvedProps
: resolveDefaultProps(Component, unresolvedProps);
return updateFunctionComponent(
current,
workInProgress,
Component,
resolvedProps,
renderLanes,
);
}
}
}
function updateFunctionComponent(
current,
workInProgress,
Component,
nextProps: any,
renderLanes,
) {
// ...省略无关代码
let context;
let nextChildren;
prepareToReadContext(workInProgress, renderLanes);
// 进入Hooks相关逻辑, 最后返回下级ReactElement对象
nextChildren = renderWithHooks(
current,
workInProgress,
Component,
nextProps,
context,
renderLanes,
);
// 进入reconcile函数, 生成下级fiber节点
reconcileChildren(current, workInProgress, nextChildren, renderLanes);
// 返回下级fiber节点
return workInProgress.child;
}
在updateFunctionComponent函数中调用了renderWithHooks(位于ReactFiberHooks) , 至此Fiber与Hook产生了关联.
全局变量
在分析renderWithHooks函数前, 有必要理解ReactFiberHooks头部定义的全局变量(源码中均有英文注释):
// 渲染优先级
let renderLanes: Lanes = NoLanes;
// 当前正在构造的fiber, 等同于 workInProgress, 为了和当前hook区分, 所以将其改名
let currentlyRenderingFiber: Fiber = (null: any);
// Hooks被存储在fiber.memoizedState 链表上
let currentHook: Hook | null = null; // currentHook = fiber(current).memoizedState
let workInProgressHook: Hook | null = null; // workInProgressHook = fiber(workInProgress).memoizedState
// 在function的执行过程中, 是否再次发起了更新. 只有function被完全执行之后才会重置.
// 当render异常时, 通过该变量可以决定是否清除render过程中的更新.
let didScheduleRenderPhaseUpdate: boolean = false;
// 在本次function的执行过程中, 是否再次发起了更新. 每一次调用function都会被重置
let didScheduleRenderPhaseUpdateDuringThisPass: boolean = false;
// 在本次function的执行过程中, 重新发起更新的最大次数
const RE_RENDER_LIMIT = 25;
每个变量的解释, 可以对照源码中的英文注释, 其中最重要的有:
1、currentlyRenderingFiber: 当前正在构造的 fiber, 等同于 workInProgress
2、currentHook 与 workInProgressHook: 分别指向current.memoizedState和workInProgress.memoizedState
注: 有关current和workInProgress的区别, 请回顾双缓冲技术(double buffering)
renderWithHooks 函数
renderWithHooks源码看似较长, 但是去除 dev 后保留主干, 逻辑十分清晰. 以调用function为分界点, 逻辑被分为 3 个部分:
// ...省略无关代码
export function renderWithHooks<Props, SecondArg>(
current: Fiber | null,
workInProgress: Fiber,
Component: (p: Props, arg: SecondArg) => any,
props: Props,
secondArg: SecondArg,
nextRenderLanes: Lanes,
): any {
// --------------- 1. 设置全局变量 -------------------
renderLanes = nextRenderLanes; // 当前渲染优先级
currentlyRenderingFiber = workInProgress; // 当前fiber节点, 也就是function组件对应的fiber节点
// 清除当前fiber的遗留状态
workInProgress.memoizedState = null;
workInProgress.updateQueue = null;
workInProgress.lanes = NoLanes;
// --------------- 2. 调用function,生成子级ReactElement对象 -------------------
// 指定dispatcher, 区分mount和update
ReactCurrentDispatcher.current =
current === null || current.memoizedState === null
? HooksDispatcherOnMount
: HooksDispatcherOnUpdate;
// 执行function函数, 其中进行分析Hooks的使用
let children = Component(props, secondArg);
// --------------- 3. 重置全局变量,并返回 -------------------
// 执行function之后, 还原被修改的全局变量, 不影响下一次调用
renderLanes = NoLanes;
currentlyRenderingFiber = (null: any);
currentHook = null;
workInProgressHook = null;
didScheduleRenderPhaseUpdate = false;
return children;
}
1、调用function前: 设置全局变量, 标记渲染优先级和当前fiber, 清除当前fiber的遗留状态.
2、调用function: 构造出Hooks链表, 最后生成子级ReactElement对象(children).
3、调用function后: 重置全局变量, 返回children.
- 为了保证不同的function节点在调用时renderWithHooks互不影响, 所以退出时重置全局变量.
调用 function
Hooks 构造
在function中, 如果使用了Hook api(如: useEffect, useState), 就会创建一个与之对应的Hook对象, 接下来重点分析这个创建过程.
有如下 demo:
export default function App() {
// 1. useState
const [a, setA] = useState(1);
// 2. useEffect
useEffect(() => {
console.log(`effect 1 created`);
});
// 3. useState
const [b] = useState(2);
// 4. useEffect
useEffect(() => {
console.log(`effect 2 created`);
});
return (
<>
<button onClick={() => setA(a + 1)}>{a}</button>
<button>{b}</button>
</>
);
}
在function组件中, 同时使用了状态Hook和副作用Hook.
初次渲染时, 逻辑执行到performUnitOfWork->beginWork->updateFunctionComponent->renderWithHooks前, 内存结构如下(本节重点是Hook, 有关fiber树构造过程可回顾前文):
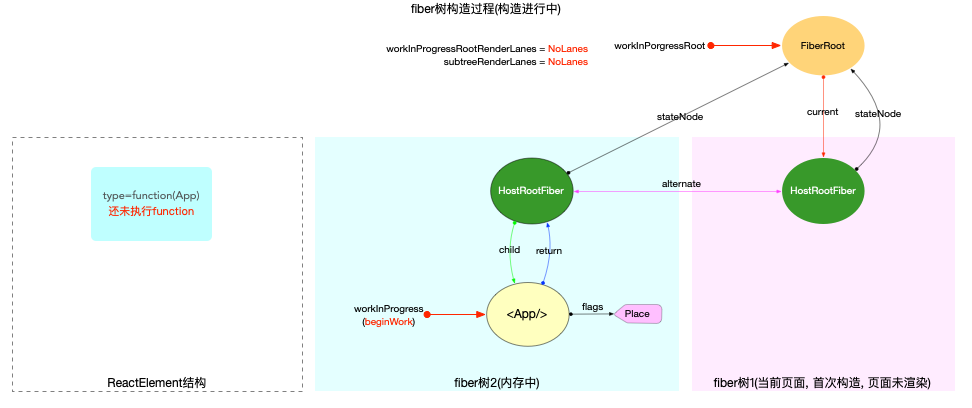
当执行renderWithHooks时, 开始调用function. 本例中, 在function内部, 共使用了 4 次Hook api, 依次调用useState, useEffect, useState, useEffect.
而useState, useEffect在fiber初次构造时分别对应mountState和mountEffect->mountEffectImpl
function mountState<S>(
initialState: (() => S) | S,
): [S, Dispatch<BasicStateAction<S>>] {
const hook = mountWorkInProgressHook();
// ...省略部分本节不讨论
return [hook.memoizedState, dispatch];
}
function mountEffectImpl(fiberFlags, hookFlags, create, deps): void {
const hook = mountWorkInProgressHook();
// ...省略部分本节不讨论
}
无论useState, useEffect, 内部都通过mountWorkInProgressHook创建一个 hook.
链表存储
而mountWorkInProgressHook非常简单:
function mountWorkInProgressHook(): Hook {
const hook: Hook = {
memoizedState: null,
baseState: null,
baseQueue: null,
queue: null,
next: null,
};
if (workInProgressHook === null) {
// 链表中首个hook
currentlyRenderingFiber.memoizedState = workInProgressHook = hook;
} else {
// 将hook添加到链表末尾
workInProgressHook = workInProgressHook.next = hook;
}
return workInProgressHook;
}
逻辑是创建Hook并挂载到fiber.memoizedState上, 多个Hook以链表结构保存.
本示例中, function调用之后则会创建 4 个hook, 这时的内存结构如下:
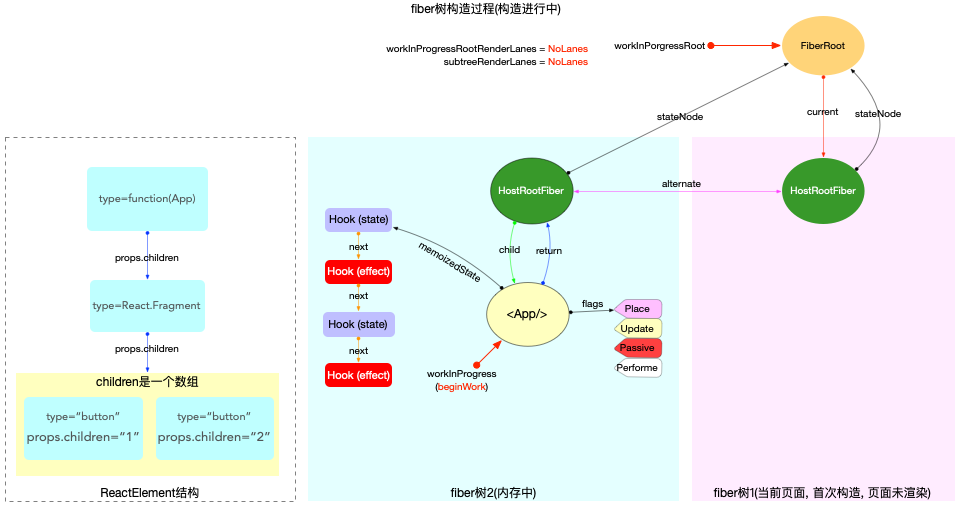
可以看到: 无论状态Hook或副作用Hook都按照调用顺序存储在fiber.memoizedState链表中.
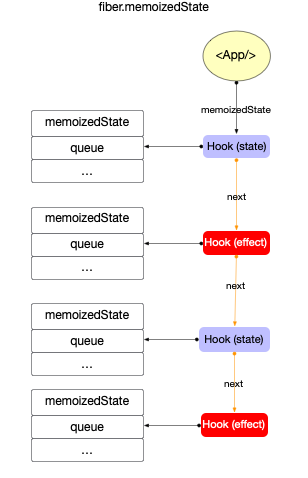
顺序克隆
fiber树构造(对比更新)阶段, 执行updateFunctionComponent->renderWithHooks时再次调用function, 调用function前的内存结构如下:
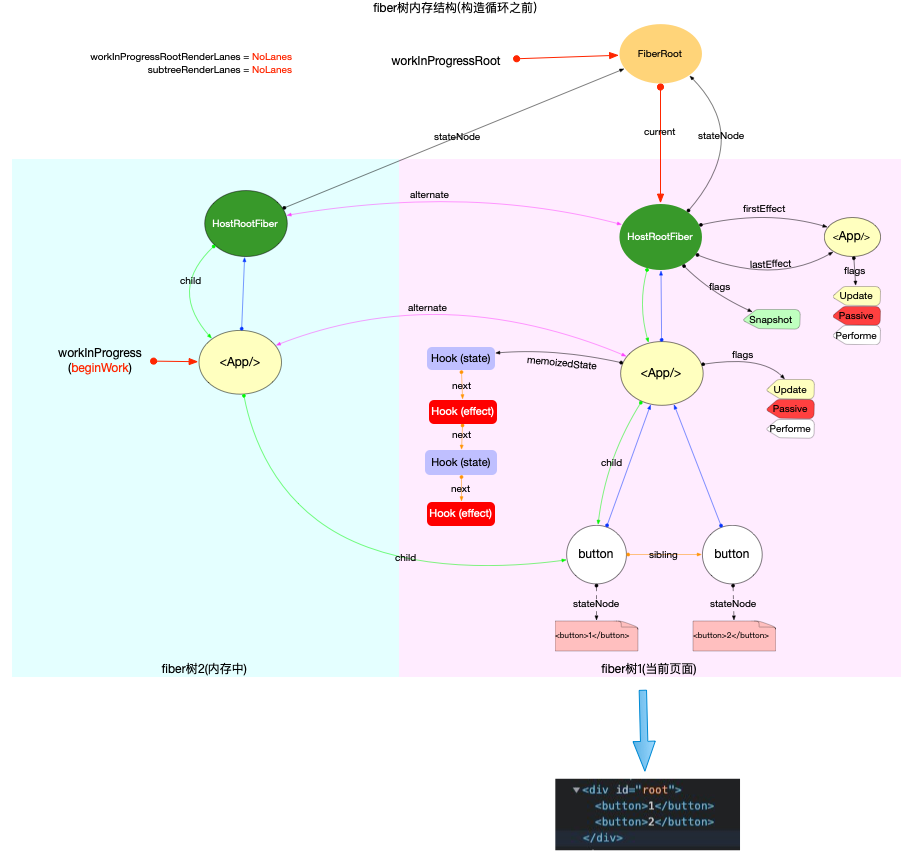
注意: 在renderWithHooks函数中已经设置了workInProgress.memoizedState = null, 等待调用function时重新设置.
接下来调用function, 同样依次调用useState, useEffect, useState, useEffect. 而useState, useEffect在fiber对比更新时分别对应updateState->updateReducer和updateEffect->updateEffectImpl
// ----- 状态Hook --------
function updateReducer<S, I, A>(
reducer: (S, A) => S,
initialArg: I,
init?: (I) => S,
): [S, Dispatch<A>] {
const hook = updateWorkInProgressHook();
// ...省略部分本节不讨论
}
// ----- 副作用Hook --------
function updateEffectImpl(fiberFlags, hookFlags, create, deps): void {
const hook = updateWorkInProgressHook();
// ...省略部分本节不讨论
}
无论useState, useEffect, 内部调用updateWorkInProgressHook获取一个 hook.
function updateWorkInProgressHook(): Hook {
// 1. 移动currentHook指针
let nextCurrentHook: null | Hook;
if (currentHook === null) {
const current = currentlyRenderingFiber.alternate;
if (current !== null) {
nextCurrentHook = current.memoizedState;
} else {
nextCurrentHook = null;
}
} else {
nextCurrentHook = currentHook.next;
}
// 2. 移动workInProgressHook指针
let nextWorkInProgressHook: null | Hook;
if (workInProgressHook === null) {
nextWorkInProgressHook = currentlyRenderingFiber.memoizedState;
} else {
nextWorkInProgressHook = workInProgressHook.next;
}
if (nextWorkInProgressHook !== null) {
// 渲染时更新: 本节不讨论
} else {
currentHook = nextCurrentHook;
// 3. 克隆currentHook作为新的workInProgressHook.
// 随后逻辑与mountWorkInProgressHook一致
const newHook: Hook = {
memoizedState: currentHook.memoizedState,
baseState: currentHook.baseState,
baseQueue: currentHook.baseQueue,
queue: currentHook.queue,
next: null, // 注意next指针是null
};
if (workInProgressHook === null) {
currentlyRenderingFiber.memoizedState = workInProgressHook = newHook;
} else {
workInProgressHook = workInProgressHook.next = newHook;
}
}
return workInProgressHook;
}
updateWorkInProgressHook函数逻辑简单: 目的是为了让currentHook和workInProgressHook两个指针同时向后移动.
1、由于renderWithHooks函数设置了workInProgress.memoizedState=null, 所以workInProgressHook初始值必然为null, 只能从currentHook克隆.
2、而从currentHook克隆而来的newHook.next=null, 进而导致workInProgressHook链表需要完全重建.
所以function执行完成之后, 有关Hook的内存结构如下:
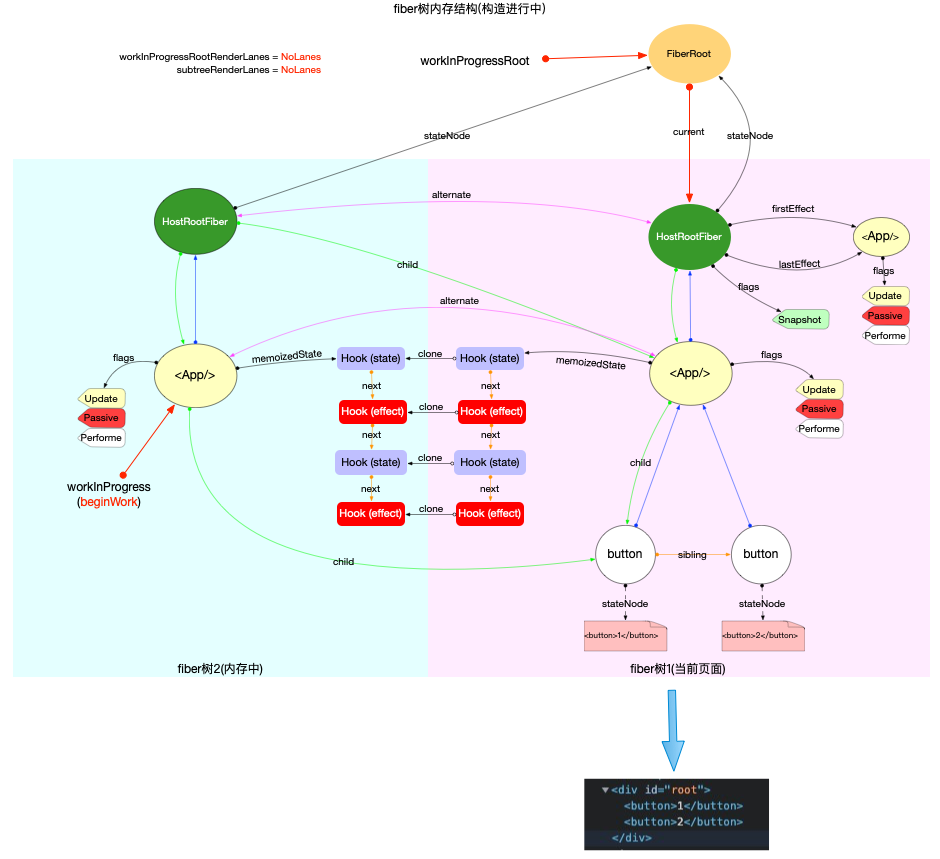
可以看到:
1、以双缓冲技术为基础, 将current.memoizedState按照顺序克隆到了workInProgress.memoizedState中.
2、Hook经过了一次克隆, 内部的属性(hook.memoizedState等)都没有变动, 所以其状态并不会丢失.
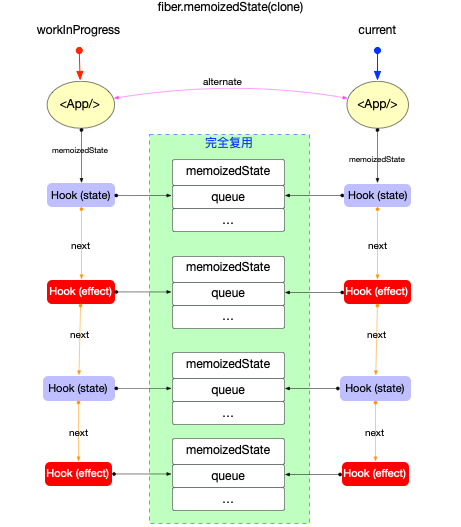
本节首先引入了官方文档上对于Hook的解释, 了解Hook的由来, 以及Hook相较于class的优势. 然后从fiber视角分析了fiber与hook的内在关系, 通过renderWithHooks函数, 把Hook链表挂载到了fiber.memoizedState之上. 利用fiber树内部的双缓冲技术, 实现了Hook从current到workInProgress转移, 进而实现了Hook状态的持久化.
Hook 原理(状态 Hook)
首先回顾一下前文Hook 原理(概览), 其主要内容有:
1、function类型的fiber节点, 它的处理函数是updateFunctionComponent, 其中再通过renderWithHooks调用function.
2、在function中, 通过Hook Api(如: useState, useEffect)创建Hook对象.
-
状态Hook实现了状态持久化(等同于class组件维护fiber.memoizedState).
-
副作用Hook则实现了维护fiber.flags,并提供副作用回调(类似于class组件的生命周期回调)
3、多个Hook对象构成一个链表结构, 并挂载到fiber.memoizedState之上.
4、fiber树更新阶段, 把current.memoizedState链表上的所有Hook按照顺序克隆到workInProgress.memoizedState上, 实现数据的持久化.
在此基础之上, 本节将深入分析状态Hook的特性和实现原理.
创建 Hook
在fiber初次构造阶段, useState对应源码mountState, useReducer对应源码mountReducer
mountState:
function mountState<S>(
initialState: (() => S) | S,
): [S, Dispatch<BasicStateAction<S>>] {
// 1. 创建hook
const hook = mountWorkInProgressHook();
if (typeof initialState === 'function') {
initialState = initialState();
}
// 2. 初始化hook的属性
// 2.1 设置 hook.memoizedState/hook.baseState
// 2.2 设置 hook.queue
hook.memoizedState = hook.baseState = initialState;
const queue = (hook.queue = {
pending: null,
dispatch: null,
// queue.lastRenderedReducer是内置函数
lastRenderedReducer: basicStateReducer,
lastRenderedState: (initialState: any),
});
// 2.3 设置 hook.dispatch
const dispatch: Dispatch<BasicStateAction<S>> = (queue.dispatch =
(dispatchAction.bind(null, currentlyRenderingFiber, queue): any));
// 3. 返回[当前状态, dispatch函数]
return [hook.memoizedState, dispatch];
}
mountReducer:
function mountReducer<S, I, A>(
reducer: (S, A) => S,
initialArg: I,
init?: (I) => S,
): [S, Dispatch<A>] {
// 1. 创建hook
const hook = mountWorkInProgressHook();
let initialState;
if (init !== undefined) {
initialState = init(initialArg);
} else {
initialState = ((initialArg: any): S);
}
// 2. 初始化hook的属性
// 2.1 设置 hook.memoizedState/hook.baseState
hook.memoizedState = hook.baseState = initialState;
// 2.2 设置 hook.queue
const queue = (hook.queue = {
pending: null,
dispatch: null,
// queue.lastRenderedReducer是由外传入
lastRenderedReducer: reducer,
lastRenderedState: (initialState: any),
});
// 2.3 设置 hook.dispatch
const dispatch: Dispatch<A> = (queue.dispatch = (dispatchAction.bind(
null,
currentlyRenderingFiber,
queue,
): any));
// 3. 返回[当前状态, dispatch函数]
return [hook.memoizedState, dispatch];
}
mountState和mountReducer逻辑简单: 主要负责创建hook, 初始化hook的属性, 最后返回[当前状态, dispatch函数].
唯一的不同点是hook.queue.lastRenderedReducer:
- mountState使用的是内置的basicStateReducer
function basicStateReducer<S>(state: S, action: BasicStateAction<S>): S {
return typeof action === 'function' ? action(state) : action;
}
- mountReducer使用的是外部传入自定义reducer
可见mountState是mountReducer的一种特殊情况, 即useState也是useReducer的一种特殊情况, 也是最简单的情况.
useState可以转换成useReducer:
const [state, dispatch] = useState({ count: 0 });
// 等价于
const [state, dispatch] = useReducer(
function basicStateReducer(state, action) {
return typeof action === 'function' ? action(state) : action;
},
{ count: 0 },
);
// 当需要更新state时, 有2种方式
dispatch({ count: 1 }); // 1.直接设置
dispatch((state) => ({ count: state.count + 1 })); // 2.通过回调函数设置
useReducer的官网示例:
const [state, dispatch] = useReducer(
function reducer(state, action) {
switch (action.type) {
case 'increment':
return { count: state.count + 1 };
case 'decrement':
return { count: state.count - 1 };
default:
throw new Error();
}
},
{ count: 0 },
);
// 当需要更新state时, 只有1种方式
dispatch({ type: 'decrement' });
可见, useState就是对useReducer的基本封装, 内置了一个特殊的reducer(后文不再区分useState, useReducer, 都以useState为例).创建hook之后返回值[hook.memoizedState, dispatch]中的dispatch实际上会调用reducer函数.
状态初始化
在useState(initialState)函数内部, 设置hook.memoizedState = hook.baseState = initialState;, 初始状态被同时保存到了hook.baseState,hook.memoizedState中.
1、hook.memoizedState: 当前状态
2、hook.baseState: 基础状态, 作为合并hook.baseQueue的初始值(下文介绍).
最后返回[hook.memoizedState, dispatch], 所以在function中使用的是hook.memoizedState.
状态更新
有如下代码:
export default function App() {
const [count, dispatch] = useState(0);
return (
<button
onClick={() => {
dispatch(1);
dispatch(3);
dispatch(2);
}}
>
{count}
</button>
);
}
初次渲染时count = 0, 这时hook对象的内存状态如下:
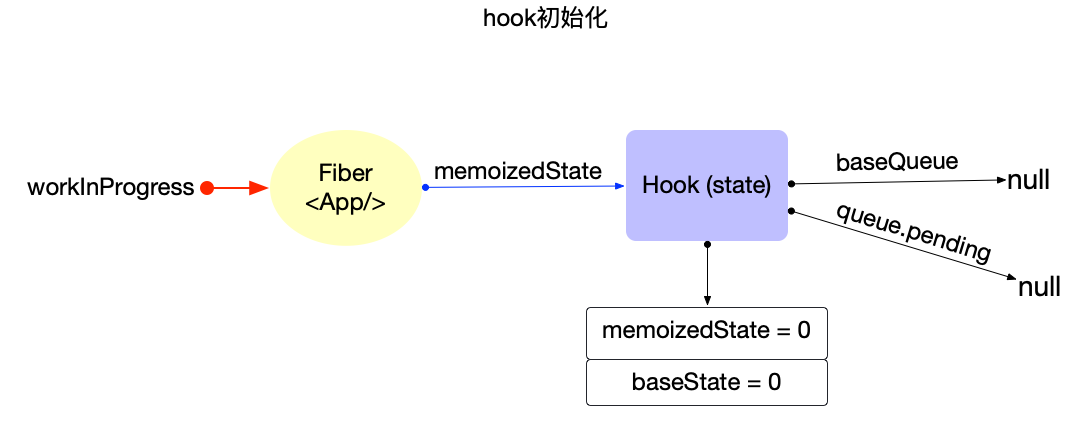
点击button, 通过dispatch函数进行更新, dispatch实际就是dispatchAction:
function dispatchAction<S, A>(
fiber: Fiber,
queue: UpdateQueue<S, A>,
action: A,
) {
// 1. 创建update对象
const eventTime = requestEventTime();
const lane = requestUpdateLane(fiber); // Legacy模式返回SyncLane
const update: Update<S, A> = {
lane,
action,
eagerReducer: null,
eagerState: null,
next: (null: any),
};
// 2. 将update对象添加到hook.queue.pending队列
const pending = queue.pending;
if (pending === null) {
// 首个update, 创建一个环形链表
update.next = update;
} else {
update.next = pending.next;
pending.next = update;
}
queue.pending = update;
const alternate = fiber.alternate;
if (
fiber === currentlyRenderingFiber ||
(alternate !== null && alternate === currentlyRenderingFiber)
) {
// 渲染时更新, 做好全局标记
didScheduleRenderPhaseUpdateDuringThisPass =
didScheduleRenderPhaseUpdate = true;
} else {
// ...省略性能优化部分, 下文介绍
// 3. 发起调度更新, 进入`reconciler 运作流程`中的输入阶段.
scheduleUpdateOnFiber(fiber, lane, eventTime);
}
}
逻辑十分清晰:
1、创建update对象, 其中update.lane代表优先级(可回顾fiber 树构造(基础准备)中的update优先级).
2、将update对象添加到hook.queue.pending环形链表.
-
环形链表的特征: 为了方便添加新元素和快速拿到队首元素(都是O(1)), 所以pending指针指向了链表中最后一个元素.
-
链表的使用方式可以参考React 算法之链表操作
3、发起调度更新: 调用scheduleUpdateOnFiber, 进入reconciler 运作流程中的输入阶段.
从调用scheduleUpdateOnFiber开始, 进入了react-reconciler包, 其中的所有逻辑可回顾reconciler 运作流程, 本节只讨论状态Hook相关逻辑.
注意: 本示例中虽然同时执行了 3 次 dispatch, 会请求 3 次调度, 由于调度中心的节流优化, 最后只会执行一次渲染
在fiber树构造(对比更新)过程中, 再次调用function, 这时useState对应的函数是updateState
function updateState<S>(
initialState: (() => S) | S,
): [S, Dispatch<BasicStateAction<S>>] {
return updateReducer(basicStateReducer, (initialState: any));
}
实际调用updateReducer.
在执行updateReducer之前, hook相关的内存结构如下:
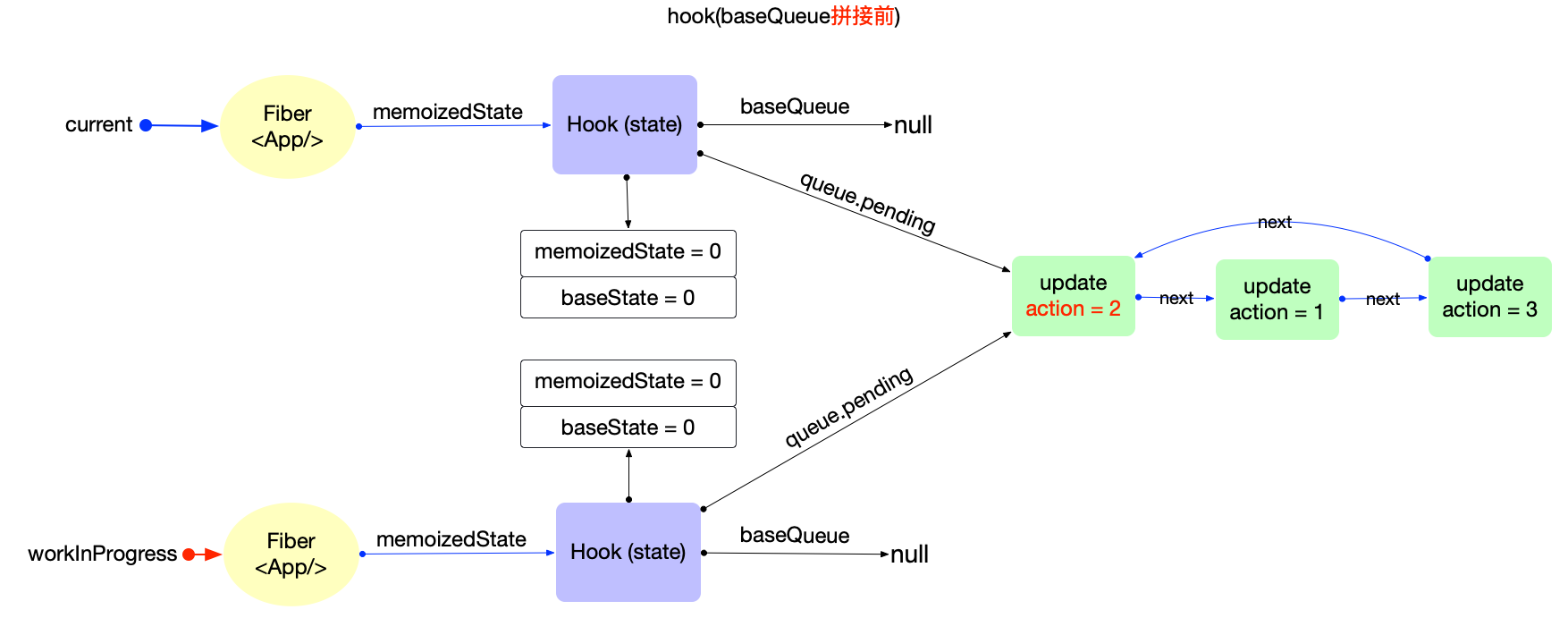
function updateReducer<S, I, A>(
reducer: (S, A) => S,
initialArg: I,
init?: (I) => S,
): [S, Dispatch<A>] {
// 1. 获取workInProgressHook对象
const hook = updateWorkInProgressHook();
const queue = hook.queue;
queue.lastRenderedReducer = reducer;
const current: Hook = (currentHook: any);
let baseQueue = current.baseQueue;
// 2. 链表拼接: 将 hook.queue.pending 拼接到 current.baseQueue
const pendingQueue = queue.pending;
if (pendingQueue !== null) {
if (baseQueue !== null) {
const baseFirst = baseQueue.next;
const pendingFirst = pendingQueue.next;
baseQueue.next = pendingFirst;
pendingQueue.next = baseFirst;
}
current.baseQueue = baseQueue = pendingQueue;
queue.pending = null;
}
// 3. 状态计算
if (baseQueue !== null) {
const first = baseQueue.next;
let newState = current.baseState;
let newBaseState = null;
let newBaseQueueFirst = null;
let newBaseQueueLast = null;
let update = first;
do {
const updateLane = update.lane;
// 3.1 优先级提取update
if (!isSubsetOfLanes(renderLanes, updateLane)) {
// 优先级不够: 加入到baseQueue中, 等待下一次render
const clone: Update<S, A> = {
lane: updateLane,
action: update.action,
eagerReducer: update.eagerReducer,
eagerState: update.eagerState,
next: (null: any),
};
if (newBaseQueueLast === null) {
newBaseQueueFirst = newBaseQueueLast = clone;
newBaseState = newState;
} else {
newBaseQueueLast = newBaseQueueLast.next = clone;
}
currentlyRenderingFiber.lanes = mergeLanes(
currentlyRenderingFiber.lanes,
updateLane,
);
markSkippedUpdateLanes(updateLane);
} else {
// 优先级足够: 状态合并
if (newBaseQueueLast !== null) {
// 更新baseQueue
const clone: Update<S, A> = {
lane: NoLane,
action: update.action,
eagerReducer: update.eagerReducer,
eagerState: update.eagerState,
next: (null: any),
};
newBaseQueueLast = newBaseQueueLast.next = clone;
}
if (update.eagerReducer === reducer) {
// 性能优化: 如果存在 update.eagerReducer, 直接使用update.eagerState.避免重复调用reducer
newState = ((update.eagerState: any): S);
} else {
const action = update.action;
// 调用reducer获取最新状态
newState = reducer(newState, action);
}
}
update = update.next;
} while (update !== null && update !== first);
// 3.2. 更新属性
if (newBaseQueueLast === null) {
newBaseState = newState;
} else {
newBaseQueueLast.next = (newBaseQueueFirst: any);
}
if (!is(newState, hook.memoizedState)) {
markWorkInProgressReceivedUpdate();
}
// 把计算之后的结果更新到workInProgressHook上
hook.memoizedState = newState;
hook.baseState = newBaseState;
hook.baseQueue = newBaseQueueLast;
queue.lastRenderedState = newState;
}
const dispatch: Dispatch<A> = (queue.dispatch: any);
return [hook.memoizedState, dispatch];
}
updateReducer函数, 代码相对较长, 但是逻辑分明:
1、调用updateWorkInProgressHook获取workInProgressHook对象
2、链表拼接: 将 hook.queue.pending 拼接到 current.baseQueue
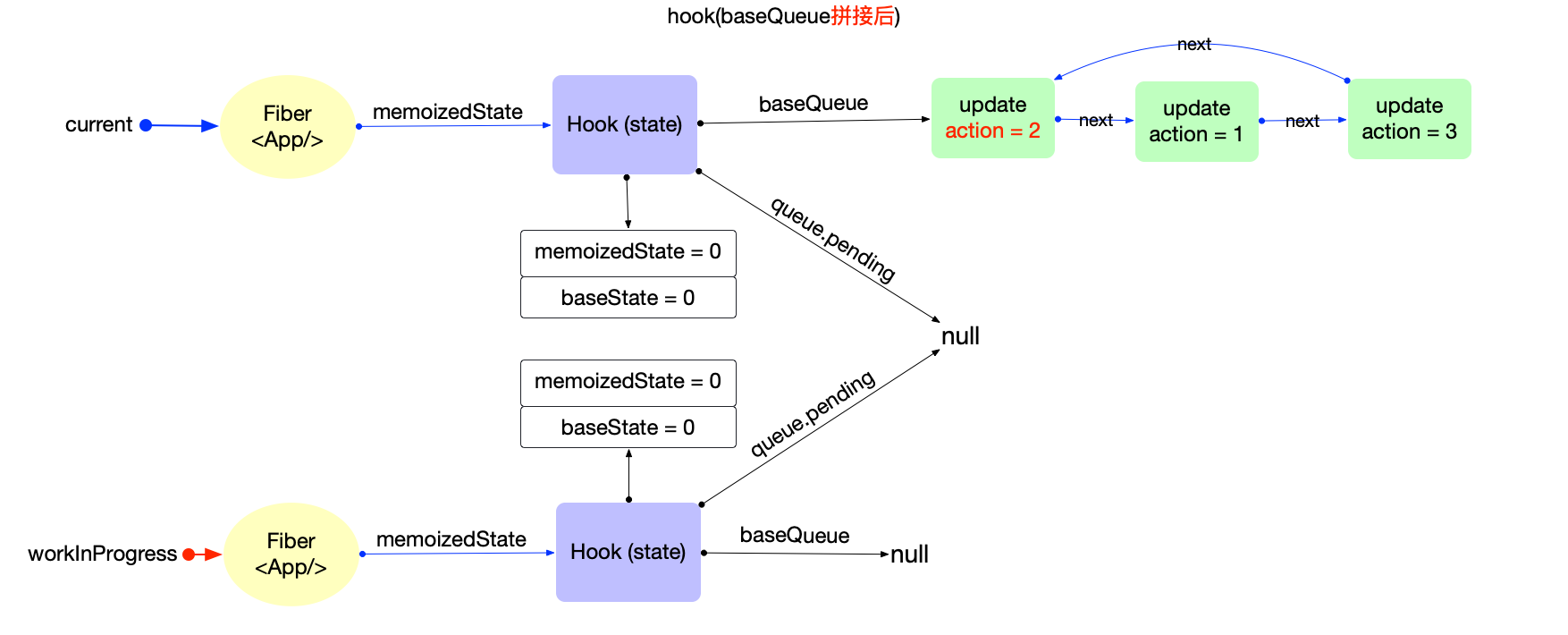
3、状态计算
-
update优先级不够: 加入到 baseQueue 中, 等待下一次 render
-
update优先级足够: 状态合并
-
更新属性
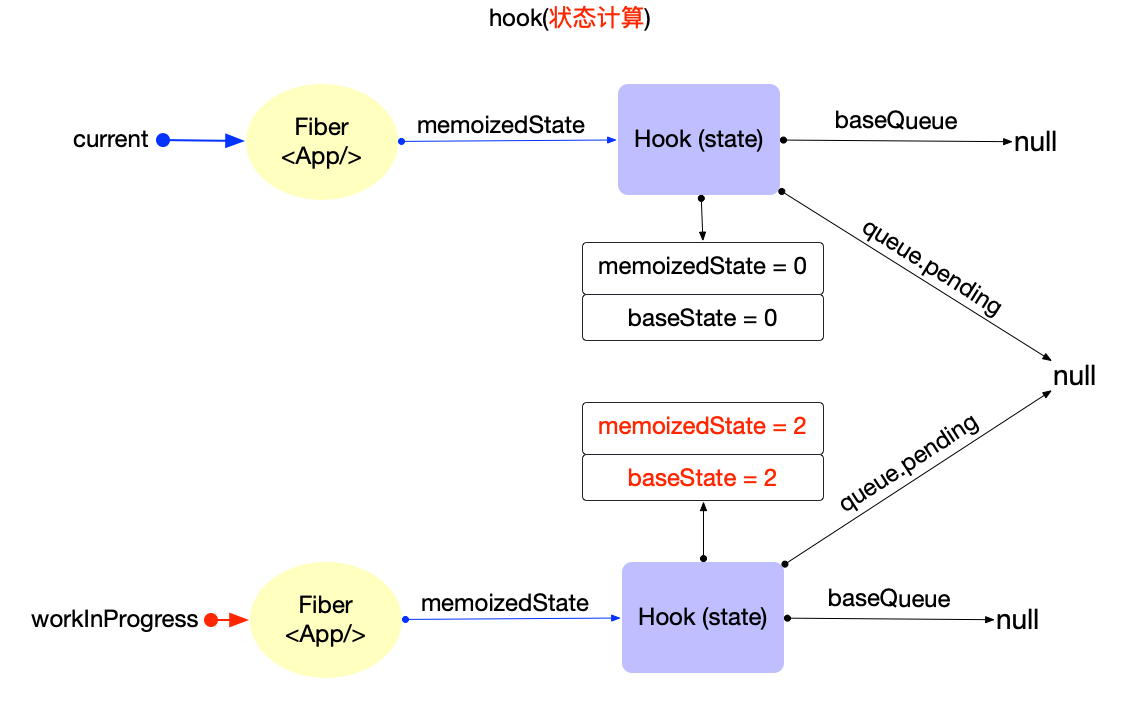
性能优化
dispatchAction函数中, 在调用scheduleUpdateOnFiber之前, 针对update对象做了性能优化.
1、queue.pending中只包含当前update时, 即当前update是queue.pending中的第一个update
2、直接调用queue.lastRenderedReducer,计算出update之后的 state, 记为eagerState
3、如果eagerState与currentState相同, 则直接退出, 不用发起调度更新.
4、已经被挂载到queue.pending上的update会在下一次render时再次合并.
function dispatchAction<S, A>(
fiber: Fiber,
queue: UpdateQueue<S, A>,
action: A,
) {
// ...省略无关代码 ...只保留性能优化部分代码:
// 下面这个if判断, 能保证当前创建的update, 是`queue.pending`中第一个`update`. 为什么? 发起更新之后fiber.lanes会被改动(可以回顾`fiber 树构造(对比更新)`章节), 如果`fiber.lanes && alternate.lanes`没有被改动, 自然就是首个update
if (
fiber.lanes === NoLanes &&
(alternate === null || alternate.lanes === NoLanes)
) {
const lastRenderedReducer = queue.lastRenderedReducer;
if (lastRenderedReducer !== null) {
let prevDispatcher;
const currentState: S = (queue.lastRenderedState: any);
const eagerState = lastRenderedReducer(currentState, action);
// 暂存`eagerReducer`和`eagerState`, 如果在render阶段reducer==update.eagerReducer, 则可以直接使用无需再次计算
update.eagerReducer = lastRenderedReducer;
update.eagerState = eagerState;
if (is(eagerState, currentState)) {
// 快速通道, eagerState与currentState相同, 无需调度更新
// 注: update已经被添加到了queue.pending, 并没有丢弃. 之后需要更新的时候, 此update还是会起作用
return;
}
}
}
// 发起调度更新, 进入`reconciler 运作流程`中的输入阶段.
scheduleUpdateOnFiber(fiber, lane, eventTime);
}
异步更新
上述示例都是为在Legacy模式下, 所以均为同步更新. 所以update对象会被全量合并,hook.baseQueue和hook.baseState并没有起到实质作用.
虽然在v17.x版本中, 并没有Concurrent模式的入口, 即将发布的v18.x版本将全面进入异步时代, 所以本节提前梳理一下update异步合并的逻辑. 同时加深hook.baseQueue和hook.baseState的理解.
假设有一个queue.pending链表, 其中update优先级不同, 绿色表示高优先级, 灰色表示低优先级, 红色表示最高优先级.
在执行updateReducer之前, hook.memoizedState有如下结构(其中update3, update4是低优先级):
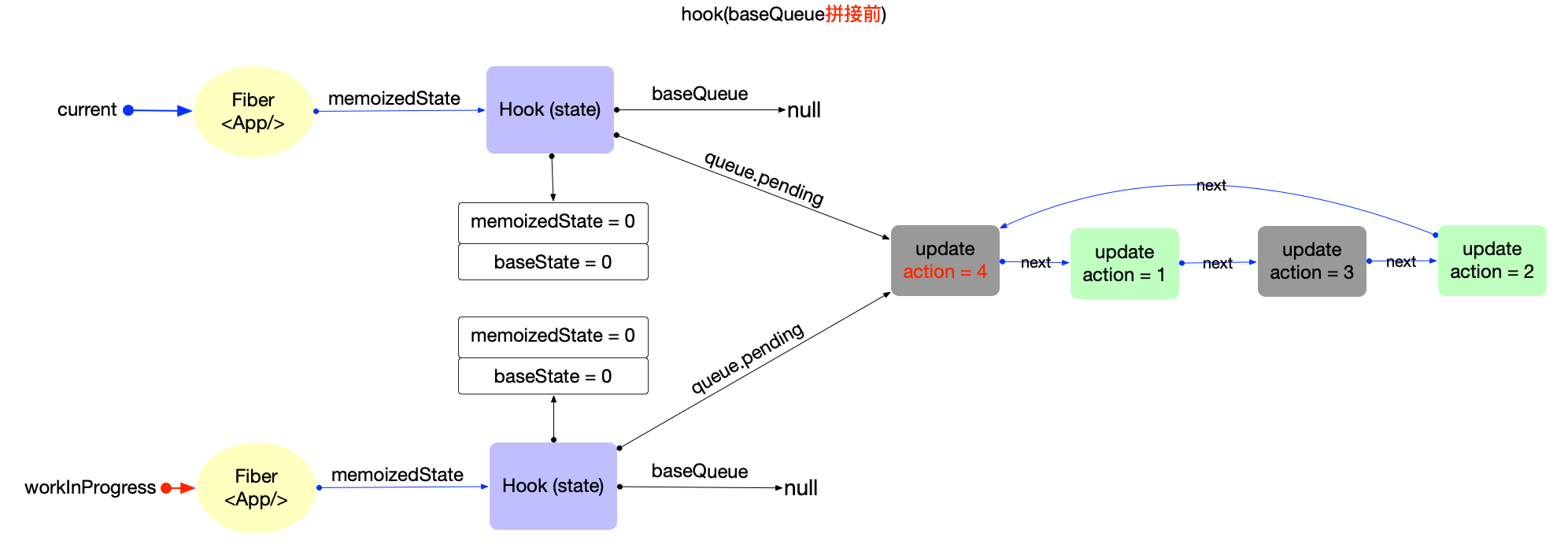
链表拼接:
和同步更新时一致, 直接把queue.pending拼接到current.baseQueue
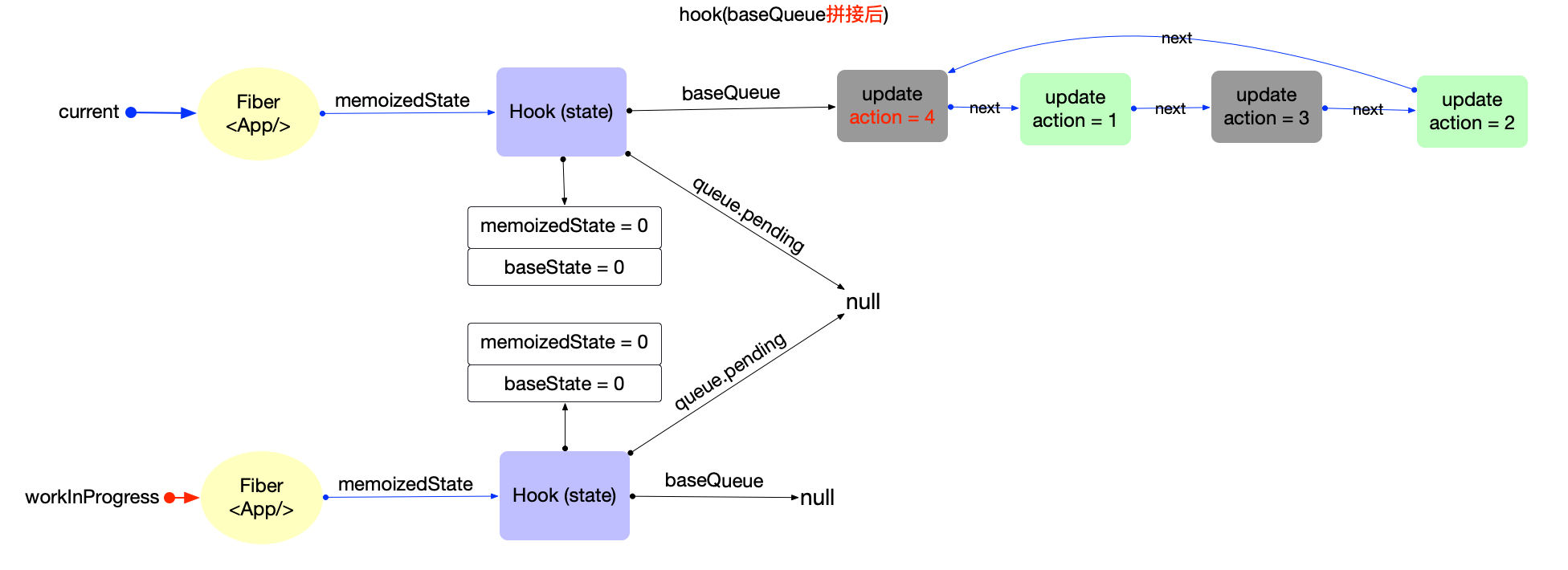
状态计算:
-
只会提取update1, update2这 2 个高优先级的update, 所以最后memoizedState=2
-
保留其余低优先级的update, 等待下一次render
-
从第一个低优先级update3开始, 随后的所有update都会被添加到baseQueue, 由于update2已经是高优先级, 会设置update2.lane=NoLane将优先级升级到最高(红色表示).
-
而baseState代表第一个低优先级update3之前的state, 在本例中, baseState=1
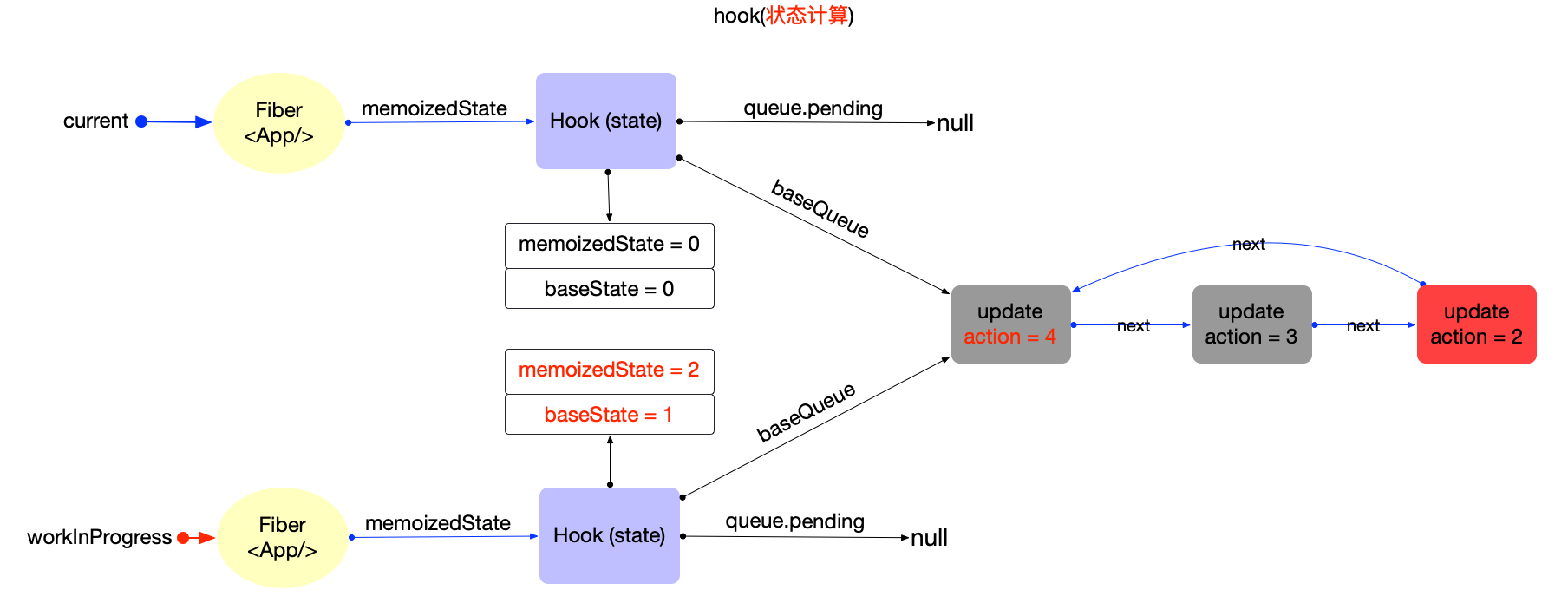
function节点被处理完后, 高优先级的update, 会率先被使用(memoizedState=2). 一段时间后, 低优先级update3, update4符合渲染, 这种情况下再次执行updateReducer重复之前的步骤.
链表拼接:
由于queue.pending = null, 故拼接前后没有实质变化
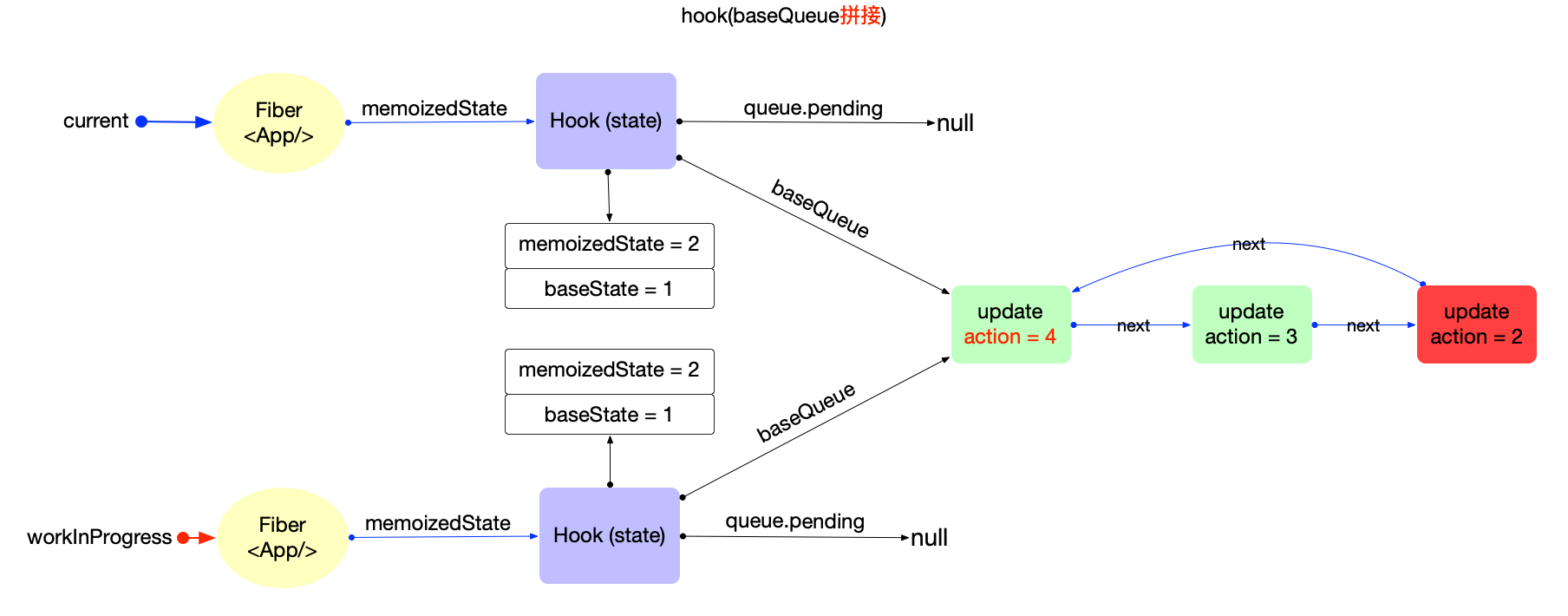
状态计算:
现在所有update.lane都符合渲染优先级, 所以最后的内存结构与同步更新一致(memoizedState=4,baseState=4).
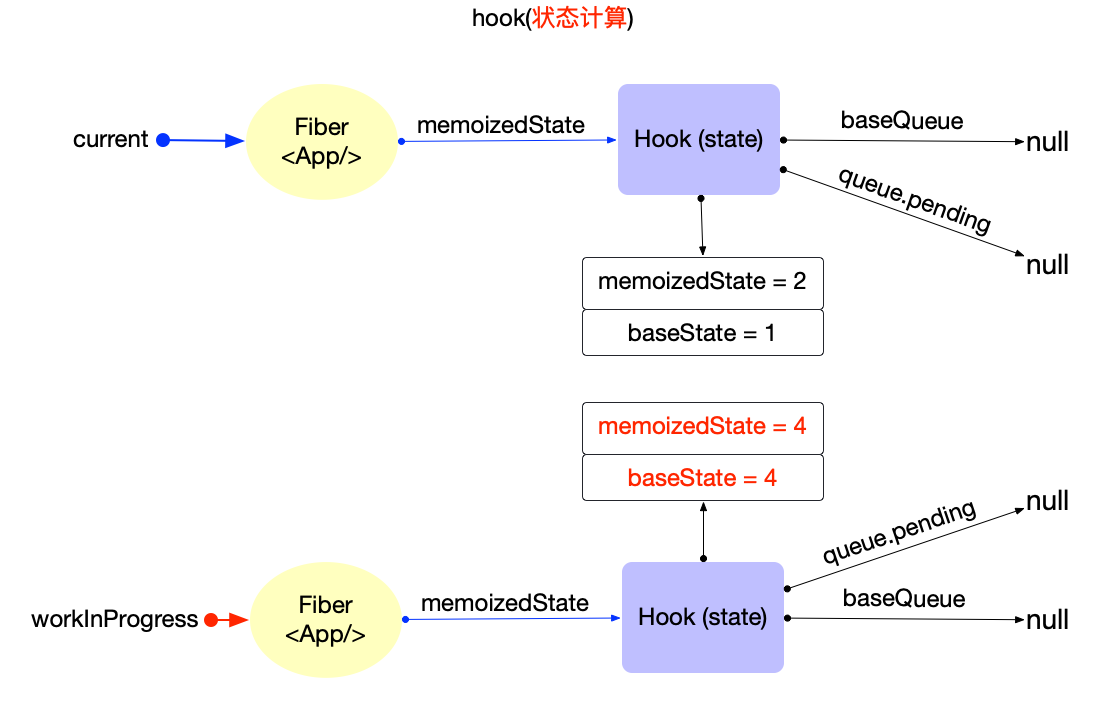
结论: 尽管update链表的优先级不同, 中间的render可能有多次, 但最终的更新结果等于update链表按顺序合并.
本节深入分析状态Hook即useState的内部原理, 从同步,异步更新理解了update对象的合并方式, 最终结果存储在hook.memoizedState供给function使用.
Hook 原理(副作用 Hook)
本节建立在前文Hook 原理(概览)和Hook 原理(状态 Hook)的基础之上, 重点讨论useEffect, useLayoutEffect等标准的副作用Hook.
创建 Hook
在fiber初次构造阶段, useEffect对应源码mountEffect, useLayoutEffect对应源码mountLayoutEffect
mountEffect:
function mountEffect(
create: () => (() => void) | void,
deps: Array<mixed> | void | null,
): void {
return mountEffectImpl(
UpdateEffect | PassiveEffect, // fiberFlags
HookPassive, // hookFlags
create,
deps,
);
}
mountLayoutEffect:
function mountLayoutEffect(
create: () => (() => void) | void,
deps: Array<mixed> | void | null,
): void {
return mountEffectImpl(
UpdateEffect, // fiberFlags
HookLayout, // hookFlags
create,
deps,
);
}
可见mountEffect和mountLayoutEffect内部都直接调用mountEffectImpl, 只是参数不同.
mountEffectImpl:
function mountEffectImpl(fiberFlags, hookFlags, create, deps): void {
// 1. 创建hook
const hook = mountWorkInProgressHook();
const nextDeps = deps === undefined ? null : deps;
// 2. 设置workInProgress的副作用标记
currentlyRenderingFiber.flags |= fiberFlags; // fiberFlags 被标记到workInProgress
// 2. 创建Effect, 挂载到hook.memoizedState上
hook.memoizedState = pushEffect(
HookHasEffect | hookFlags, // hookFlags用于创建effect
create,
undefined,
nextDeps,
);
}
mountEffectImpl逻辑:
1、创建hook
2、设置workInProgress的副作用标记: flags |= fiberFlags
3、创建effect(在pushEffect中), 挂载到hook.memoizedState上, 即 hook.memoizedState = effect
- 注意: 状态Hook中hook.memoizedState = state
创建 Effect
pushEffect:
function pushEffect(tag, create, destroy, deps) {
// 1. 创建effect对象
const effect: Effect = {
tag,
create,
destroy,
deps,
next: (null: any),
};
// 2. 把effect对象添加到环形链表末尾
let componentUpdateQueue: null | FunctionComponentUpdateQueue =
(currentlyRenderingFiber.updateQueue: any);
if (componentUpdateQueue === null) {
// 新建 workInProgress.updateQueue 用于挂载effect对象
componentUpdateQueue = createFunctionComponentUpdateQueue();
currentlyRenderingFiber.updateQueue = (componentUpdateQueue: any);
// updateQueue.lastEffect是一个环形链表
componentUpdateQueue.lastEffect = effect.next = effect;
} else {
const lastEffect = componentUpdateQueue.lastEffect;
if (lastEffect === null) {
componentUpdateQueue.lastEffect = effect.next = effect;
} else {
const firstEffect = lastEffect.next;
lastEffect.next = effect;
effect.next = firstEffect;
componentUpdateQueue.lastEffect = effect;
}
}
// 3. 返回effect
return effect;
}
pushEffect逻辑:
1、创建effect.
2、把effect对象添加到环形链表末尾.
3、返回effect.
effect的数据结构:
export type Effect = {|
tag: HookFlags,
create: () => (() => void) | void,
destroy: (() => void) | void,
deps: Array<mixed> | null,
next: Effect,
|};
- effect.tag: 使用位掩码形式, 代表effect的类型(源码).
export const NoFlags = /* */ 0b000;
export const HasEffect = /* */ 0b001; // 有副作用, 可以被触发
export const Layout = /* */ 0b010; // Layout, dom突变后同步触发
export const Passive = /* */ 0b100; // Passive, dom突变前异步触发
-
effect.create: 实际上就是通过useEffect()所传入的函数.
-
effect.deps: 依赖项, 如果依赖项变动, 会创建新的effect.
renderWithHooks执行完成后, 我们可以画出fiber,hook,effect三者的引用关系:
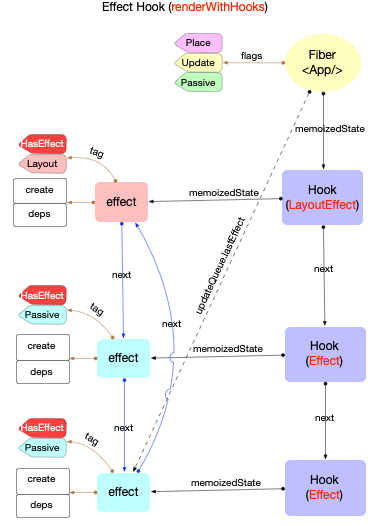
现在workInProgress.flags被打上了标记, 最后会在fiber树渲染阶段的commitRoot函数中处理. (这期间的所有过程可以回顾前文fiber树构造/fiber树渲染系列, 此处不再赘述)
useEffect & useLayoutEffect
站在fiber,hook,effect的视角, 无需关心这个hook是通过useEffect还是useLayoutEffect创建的. 只需要关心内部fiber.flags,effect.tag的状态.
所以useEffect与useLayoutEffect的区别如下:
1、fiber.flags不同
-
使用useEffect时:
fiber.flags = UpdateEffect | PassiveEffect. -
使用useLayoutEffect时: fiber.flags = UpdateEffect.
2、effect.tag不同
-
使用useEffect时:
effect.tag = HookHasEffect | HookPassive. -
使用useLayoutEffect时:
effect.tag = HookHasEffect | HookLayout.
处理 Effect 回调
完成fiber树构造后, 逻辑会进入渲染阶段. 通过fiber 树渲染中的介绍, 在commitRootImpl函数中, 整个渲染过程被 3 个函数分布实现:
-
commitBeforeMutationEffects
-
commitMutationEffects
-
commitLayoutEffects
这 3 个函数会处理fiber.flags, 也会根据情况处理fiber.updateQueue.lastEffect
commitBeforeMutationEffects
第一阶段: dom 变更之前, 处理副作用队列中带有Passive标记的fiber节点.
function commitBeforeMutationEffects() {
while (nextEffect !== null) {
// ...省略无关代码, 只保留Hook相关
// 处理`Passive`标记
const flags = nextEffect.flags;
if ((flags & Passive) !== NoFlags) {
if (!rootDoesHavePassiveEffects) {
rootDoesHavePassiveEffects = true;
scheduleCallback(NormalSchedulerPriority, () => {
flushPassiveEffects();
return null;
});
}
}
nextEffect = nextEffect.nextEffect;
}
}
注意: 由于flushPassiveEffects被包裹在scheduleCallback回调中, 由调度中心来处理, 且参数是NormalSchedulerPriority, 故这是一个异步回调(具体原理可以回顾React 调度原理(scheduler)).
由于scheduleCallback(NormalSchedulerPriority,callback)是异步的, flushPassiveEffects并不会立即执行. 此处先跳过flushPassiveEffects的分析, 继续跟进commitRoot.
commitMutationEffects
第二阶段: dom 变更, 界面得到更新.
function commitMutationEffects(
root: FiberRoot,
renderPriorityLevel: ReactPriorityLevel,
) {
// ...省略无关代码, 只保留Hook相关
while (nextEffect !== null) {
const flags = nextEffect.flags;
const primaryFlags = flags & (Placement | Update | Deletion | Hydrating);
switch (primaryFlags) {
case Update: {
// useEffect,useLayoutEffect都会设置Update标记
// 更新节点
const current = nextEffect.alternate;
commitWork(current, nextEffect);
break;
}
}
nextEffect = nextEffect.nextEffect;
}
}
function commitWork(current: Fiber | null, finishedWork: Fiber): void {
// ...省略无关代码, 只保留Hook相关
switch (finishedWork.tag) {
case FunctionComponent:
case ForwardRef:
case MemoComponent:
case SimpleMemoComponent:
case Block: {
// 在突变阶段调用销毁函数, 保证所有的effect.destroy函数都会在effect.create之前执行
commitHookEffectListUnmount(HookLayout | HookHasEffect, finishedWork);
return;
}
}
}
// 依次执行: effect.destroy
function commitHookEffectListUnmount(tag: number, finishedWork: Fiber) {
const updateQueue: FunctionComponentUpdateQueue | null =
(finishedWork.updateQueue: any);
const lastEffect = updateQueue !== null ? updateQueue.lastEffect : null;
if (lastEffect !== null) {
const firstEffect = lastEffect.next;
let effect = firstEffect;
do {
if ((effect.tag & tag) === tag) {
// 根据传入的tag过滤 effect链表.
const destroy = effect.destroy;
effect.destroy = undefined;
if (destroy !== undefined) {
destroy();
}
}
effect = effect.next;
} while (effect !== firstEffect);
}
}
调用关系: commitMutationEffects->commitWork->commitHookEffectListUnmount.
-
注意在调用
commitHookEffectListUnmount(HookLayout | HookHasEffect, finishedWork)时, 参数是HookLayout | HookHasEffect. -
而
HookLayout | HookHasEffect是通过useLayoutEffect创建的effect. 所以commitHookEffectListUnmount函数只能处理由useLayoutEffect()创建的effect. -
同步调用effect.destroy().
commitLayoutEffects
第三阶段: dom 变更后
function commitLayoutEffects(root: FiberRoot, committedLanes: Lanes) {
// ...省略无关代码, 只保留Hook相关
while (nextEffect !== null) {
const flags = nextEffect.flags;
if (flags & (Update | Callback)) {
// useEffect,useLayoutEffect都会设置Update标记
const current = nextEffect.alternate;
commitLayoutEffectOnFiber(root, current, nextEffect, committedLanes);
}
nextEffect = nextEffect.nextEffect;
}
}
function commitLifeCycles(
finishedRoot: FiberRoot,
current: Fiber | null,
finishedWork: Fiber,
committedLanes: Lanes,
): void {
// ...省略无关代码, 只保留Hook相关
switch (finishedWork.tag) {
case FunctionComponent:
case ForwardRef:
case SimpleMemoComponent:
case Block: {
// 在此之前commitMutationEffects函数中, effect.destroy已经被调用, 所以effect.destroy永远不会影响到effect.create
commitHookEffectListMount(HookLayout | HookHasEffect, finishedWork);
schedulePassiveEffects(finishedWork);
return;
}
}
}
function commitHookEffectListMount(tag: number, finishedWork: Fiber) {
const updateQueue: FunctionComponentUpdateQueue | null =
(finishedWork.updateQueue: any);
const lastEffect = updateQueue !== null ? updateQueue.lastEffect : null;
if (lastEffect !== null) {
const firstEffect = lastEffect.next;
let effect = firstEffect;
do {
if ((effect.tag & tag) === tag) {
const create = effect.create;
effect.destroy = create();
}
effect = effect.next;
} while (effect !== firstEffect);
}
}
1、调用关系: commitLayoutEffects->commitLayoutEffectOnFiber(commitLifeCycles)->commitHookEffectListMount.
-
注意在调用
commitHookEffectListMount(HookLayout | HookHasEffect, finishedWork)时, 参数是HookLayout | HookHasEffect,所以只处理由useLayoutEffect()创建的effect. -
调用effect.create()之后, 将返回值赋值到effect.destroy.
2、为flushPassiveEffects做准备
-
commitLifeCycles中的schedulePassiveEffects(finishedWork), 其形参finishedWork实际上指代当前正在被遍历的有副作用的fiber
-
schedulePassiveEffects比较简单, 就是把带有Passive标记的effect筛选出来(由useEffect创建), 添加到一个全局数组(pendingPassiveHookEffectsUnmount和pendingPassiveHookEffectsMount).
function schedulePassiveEffects(finishedWork: Fiber) {
// 1. 获取 fiber.updateQueue
const updateQueue: FunctionComponentUpdateQueue | null =
(finishedWork.updateQueue: any);
// 2. 获取 effect环形队列
const lastEffect = updateQueue !== null ? updateQueue.lastEffect : null;
if (lastEffect !== null) {
const firstEffect = lastEffect.next;
let effect = firstEffect;
do {
const { next, tag } = effect;
// 3. 筛选出由useEffect()创建的`effect`
if (
(tag & HookPassive) !== NoHookEffect &&
(tag & HookHasEffect) !== NoHookEffect
) {
// 把effect添加到全局数组, 等待`flushPassiveEffects`处理
enqueuePendingPassiveHookEffectUnmount(finishedWork, effect);
enqueuePendingPassiveHookEffectMount(finishedWork, effect);
}
effect = next;
} while (effect !== firstEffect);
}
}
export function enqueuePendingPassiveHookEffectUnmount(
fiber: Fiber,
effect: HookEffect,
): void {
// unmount effects 数组
pendingPassiveHookEffectsUnmount.push(effect, fiber);
}
export function enqueuePendingPassiveHookEffectMount(
fiber: Fiber,
effect: HookEffect,
): void {
// mount effects 数组
pendingPassiveHookEffectsMount.push(effect, fiber);
}
综上commitMutationEffects和commitLayoutEffects2 个函数, 带有Layout标记的effect(由useLayoutEffect创建), 已经得到了完整的回调处理(destroy和create已经被调用).
如下图:
其中第一个effect拥有Layout标记,会执行effect.destroy(); effect.destroy = effect.create()
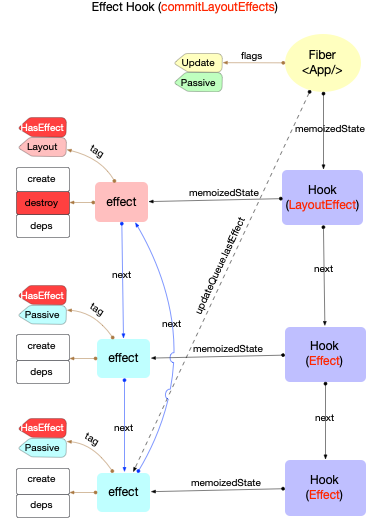
flushPassiveEffects
在上文commitBeforeMutationEffects阶段, 异步调用了flushPassiveEffects. 在这期间带有Passive标记的effect已经被添加到pendingPassiveHookEffectsUnmount和pendingPassiveHookEffectsMount全局数组中.
接下来flushPassiveEffects就可以脱离fiber节点, 直接访问effects
export function flushPassiveEffects(): boolean {
// Returns whether passive effects were flushed.
if (pendingPassiveEffectsRenderPriority !== NoSchedulerPriority) {
const priorityLevel =
pendingPassiveEffectsRenderPriority > NormalSchedulerPriority
? NormalSchedulerPriority
: pendingPassiveEffectsRenderPriority;
pendingPassiveEffectsRenderPriority = NoSchedulerPriority;
// `runWithPriority`设置Schedule中的调度优先级, 如果在flushPassiveEffectsImpl中处理effect时又发起了新的更新, 那么新的update.lane将会受到这个priorityLevel影响.
return runWithPriority(priorityLevel, flushPassiveEffectsImpl);
}
return false;
}
// ...省略无关代码, 只保留Hook相关
function flushPassiveEffectsImpl() {
if (rootWithPendingPassiveEffects === null) {
return false;
}
rootWithPendingPassiveEffects = null;
pendingPassiveEffectsLanes = NoLanes;
// 1. 执行 effect.destroy()
const unmountEffects = pendingPassiveHookEffectsUnmount;
pendingPassiveHookEffectsUnmount = [];
for (let i = 0; i < unmountEffects.length; i += 2) {
const effect = ((unmountEffects[i]: any): HookEffect);
const fiber = ((unmountEffects[i + 1]: any): Fiber);
const destroy = effect.destroy;
effect.destroy = undefined;
if (typeof destroy === 'function') {
destroy();
}
}
// 2. 执行新 effect.create(), 重新赋值到 effect.destroy
const mountEffects = pendingPassiveHookEffectsMount;
pendingPassiveHookEffectsMount = [];
for (let i = 0; i < mountEffects.length; i += 2) {
const effect = ((mountEffects[i]: any): HookEffect);
const fiber = ((mountEffects[i + 1]: any): Fiber);
effect.destroy = create();
}
}
其核心逻辑:
1、遍历pendingPassiveHookEffectsUnmount中的所有effect, 调用effect.destroy().
- 同时清空pendingPassiveHookEffectsUnmount
2、遍历pendingPassiveHookEffectsMount中的所有effect, 调用effect.create(), 并更新effect.destroy.
- 同时清空pendingPassiveHookEffectsMount
所以, 带有Passive标记的effect, 在flushPassiveEffects函数中得到了完整的回调处理.
如下图:
其中拥有Passive标记的effect, 都会执行effect.destroy(); effect.destroy = effect.create()
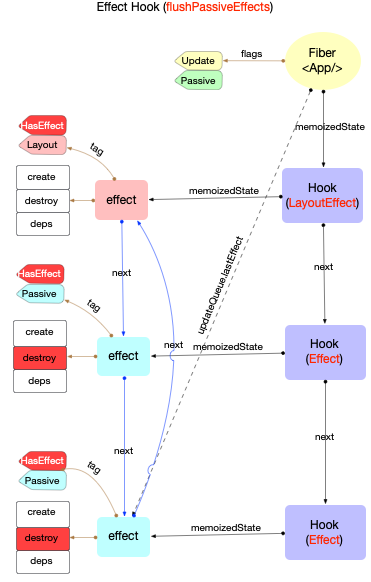
更新 Hook
假设在初次调用之后, 发起更新, 会再次执行function, 这时function中使用的useEffect, useLayoutEffect等api也会再次执行.
在更新过程中useEffect对应源码updateEffect, useLayoutEffect对应源码updateLayoutEffect.它们内部都会调用updateEffectImpl, 与初次创建时一样, 只是参数不同.
更新 Effect
updateEffectImpl:
function updateEffectImpl(fiberFlags, hookFlags, create, deps): void {
// 1. 获取当前hook
const hook = updateWorkInProgressHook();
const nextDeps = deps === undefined ? null : deps;
let destroy = undefined;
// 2. 分析依赖
if (currentHook !== null) {
const prevEffect = currentHook.memoizedState;
// 继续使用先前effect.destroy
destroy = prevEffect.destroy;
if (nextDeps !== null) {
const prevDeps = prevEffect.deps;
// 比较依赖是否变化
if (areHookInputsEqual(nextDeps, prevDeps)) {
// 2.1 如果依赖不变, 新建effect(tag不含HookHasEffect)
pushEffect(hookFlags, create, destroy, nextDeps);
return;
}
}
}
// 2.2 如果依赖改变, 更改fiber.flag, 新建effect
currentlyRenderingFiber.flags |= fiberFlags;
hook.memoizedState = pushEffect(
HookHasEffect | hookFlags,
create,
destroy,
nextDeps,
);
}
updateEffectImpl与mountEffectImpl逻辑有所不同: - 如果useEffect/useLayoutEffect的依赖不变, 新建的effect对象不带HasEffect标记.
注意: 无论依赖是否变化, 都复用之前的effect.destroy. 等待commitRoot阶段的调用(上文已经说明).
如下图:
-
图中第 1,2 个hook其deps没变, 故effect.tag中不会包含HookHasEffect.
-
图中第 3 个hook其deps改变, 故effect.tag中继续含有HookHasEffect.
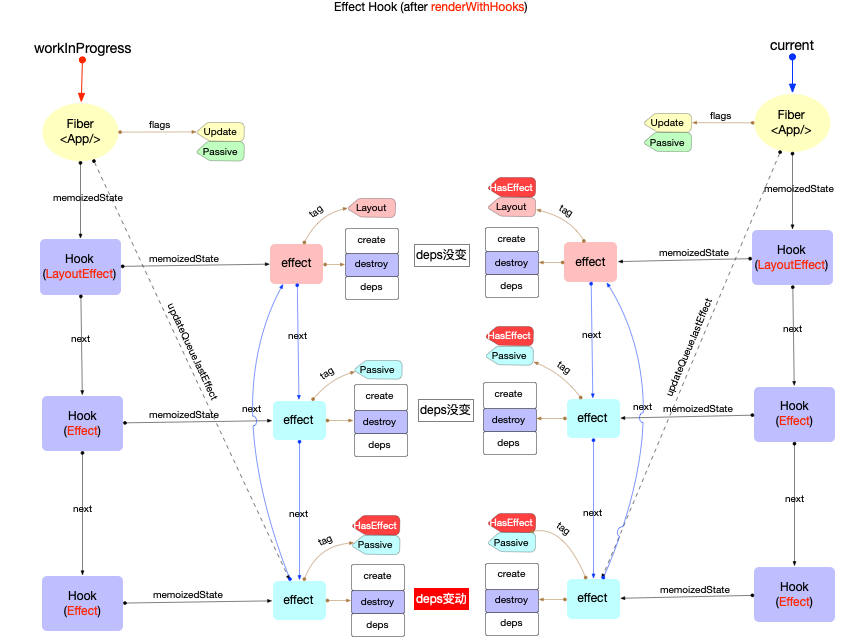
处理 Effect 回调
新的hook以及新的effect创建完成之后, 余下逻辑与初次渲染完全一致. 处理 Effect 回调时也会根据effect.tag进行判断: 只有effect.tag包含HookHasEffect时才会调用effect.destroy和effect.create()
组件销毁
当function组件被销毁时, fiber节点必然会被打上Deletion标记, 即fiber.flags |= Deletion. 带有Deletion标记的fiber在commitMutationEffects被处理:
// ...省略无关代码
function commitMutationEffects(
root: FiberRoot,
renderPriorityLevel: ReactPriorityLevel,
) {
while (nextEffect !== null) {
const primaryFlags = flags & (Placement | Update | Deletion | Hydrating);
switch (primaryFlags) {
case Deletion: {
commitDeletion(root, nextEffect, renderPriorityLevel);
break;
}
}
}
}
在commitDeletion函数之后, 继续调用unmountHostComponents->commitUnmount, 在commitUnmount中, 执行effect.destroy(), 结束整个闭环.
本节分析了副作用Hook从创建到销毁的全部过程, 在react内部, 依靠fiber.flags和effect.tag实现了对effect的精准识别. 在commitRoot阶段, 对不同类型的effect进行处理, 先后调用effect.destroy()和effect.create().
Context 原理
简单来讲, Context提供了一种直接访问祖先节点上的状态的方法, 避免了多级组件层层传递props.
有关Context的用法, 请直接查看官方文档, 本文将从fiber树构造的视角, 分析Context的实现原理.
创建 Context
根据官网示例, 通过React.createContext这个 api 来创建context对象. 在createContext中, 可以看到context对象的数据结构:
export function createContext<T>(
defaultValue: T,
calculateChangedBits: ?(a: T, b: T) => number,
): ReactContext<T> {
if (calculateChangedBits === undefined) {
calculateChangedBits = null;
}
const context: ReactContext<T> = {
$typeof: REACT_CONTEXT_TYPE,
_calculateChangedBits: calculateChangedBits,
// As a workaround to support multiple concurrent renderers, we categorize
// some renderers as primary and others as secondary. We only expect
// there to be two concurrent renderers at most: React Native (primary) and
// Fabric (secondary); React DOM (primary) and React ART (secondary).
// Secondary renderers store their context values on separate fields.
_currentValue: defaultValue,
_currentValue2: defaultValue,
_threadCount: 0,
Provider: (null: any),
Consumer: (null: any),
};
context.Provider = {
$typeof: REACT_PROVIDER_TYPE,
_context: context,
};
context.Consumer = context;
return context;
}
createContext核心逻辑:
-
其初始值保存在context._currentValue(同时保存到context._currentValue2. 英文注释已经解释, 保存 2 个 value 是为了支持多个渲染器并发渲染)
-
同时创建了context.Provider, context.Consumer2 个reactElement对象.
比如, 创建const MyContext = React.createContext(defaultValue);, 之后使用<MyContext.Provider value={/* 某个值 */}>声明一个ContextProvider类型的组件.
在fiber树渲染时, 在beginWork中ContextProvider类型的节点对应的处理函数是updateContextProvider:
function beginWork(
current: Fiber | null,
workInProgress: Fiber,
renderLanes: Lanes,
): Fiber | null {
const updateLanes = workInProgress.lanes;
workInProgress.lanes = NoLanes;
// ...省略无关代码
switch (workInProgress.tag) {
case ContextProvider:
return updateContextProvider(current, workInProgress, renderLanes);
case ContextConsumer:
return updateContextConsumer(current, workInProgress, renderLanes);
}
}
function updateContextProvider(
current: Fiber | null,
workInProgress: Fiber,
renderLanes: Lanes,
) {
// ...省略无关代码
const providerType: ReactProviderType<any> = workInProgress.type;
const context: ReactContext<any> = providerType._context;
const newProps = workInProgress.pendingProps;
const oldProps = workInProgress.memoizedProps;
// 接收新value
const newValue = newProps.value;
// 更新 ContextProvider._currentValue
pushProvider(workInProgress, newValue);
if (oldProps !== null) {
// ... 省略更新context的逻辑, 下文讨论
}
const newChildren = newProps.children;
reconcileChildren(current, workInProgress, newChildren, renderLanes);
return workInProgress.child;
}
updateContextProvider()在fiber初次创建时十分简单, 仅仅就是保存了pendingProps.value做为context的最新值, 之后这个最新的值用于供给消费.
context._currentValue 存储
注意updateContextProvider -> pushProvider中的pushProvider(workInProgress, newValue):
// ...省略无关代码
export function pushProvider<T>(providerFiber: Fiber, nextValue: T): void {
const context: ReactContext<T> = providerFiber.type._context;
push(valueCursor, context._currentValue, providerFiber);
context._currentValue = nextValue;
}
pushProvider实际上是一个存储函数, 利用栈的特性, 先把context._currentValue压栈, 之后更新context._currentValue = nextValue.
与pushProvider对应的还有popProvider, 同样利用栈的特性, 把栈中的值弹出, 还原到context._currentValue中.
本节重点分析Context Api在fiber树构造过程中的作用. 有关pushProvider/popProvider的具体实现过程(栈存储), 在React 算法之栈操作中有详细图解.
消费 Context
使用了MyContext.Provider组件之后, 在fiber树构造过程中, context 的值会被ContextProvider类型的fiber节点所更新. 在后续的过程中, 如何读取context._currentValue?
在react中, 共提供了 3 种方式可以消费Context:
1、使用MyContext.Consumer组件: 用于JSX. 如, <MyContext.Consumer>(value)=>{}</MyContext.Consumer>
- beginWork中, 对于ContextConsumer类型的节点, 对应的处理函数是updateContextConsumer
function updateContextConsumer(
current: Fiber | null,
workInProgress: Fiber,
renderLanes: Lanes,
) {
let context: ReactContext<any> = workInProgress.type;
const newProps = workInProgress.pendingProps;
const render = newProps.children;
// 读取context
prepareToReadContext(workInProgress, renderLanes);
const newValue = readContext(context, newProps.unstable_observedBits);
let newChildren;
// ...省略无关代码
}
2、使用useContext: 用于function中. 如, const value = useContext(MyContext)
-
进入updateFunctionComponent后, 会调用prepareToReadContext
-
无论是初次创建阶段, 还是更新阶段, useContext都直接调用了readContext
3、class组件中, 使用一个静态属性contextType: 用于class组件中获取context. 如, MyClass.contextType = MyContext;
-
进入updateClassComponent后, 会调用prepareToReadContext
-
无论constructClassInstance,mountClassInstance, updateClassInstance内部都调用context = readContext((contextType: any));
所以这 3 种方式只是react根据不同使用场景封装的api, 内部都会调用prepareToReadContext和readContext(contextType).
// ... 省略无关代码
export function prepareToReadContext(
workInProgress: Fiber,
renderLanes: Lanes,
): void {
// 1. 设置全局变量, 为readContext做准备
currentlyRenderingFiber = workInProgress;
lastContextDependency = null;
lastContextWithAllBitsObserved = null;
const dependencies = workInProgress.dependencies;
if (dependencies !== null) {
const firstContext = dependencies.firstContext;
if (firstContext !== null) {
if (includesSomeLane(dependencies.lanes, renderLanes)) {
// Context list has a pending update. Mark that this fiber performed work.
markWorkInProgressReceivedUpdate();
}
// Reset the work-in-progress list
dependencies.firstContext = null;
}
}
}
// ... 省略无关代码
export function readContext<T>(
context: ReactContext<T>,
observedBits: void | number | boolean,
): T {
const contextItem = {
context: ((context: any): ReactContext<mixed>),
observedBits: resolvedObservedBits,
next: null,
};
// 1. 构造一个contextItem, 加入到 workInProgress.dependencies链表之后
if (lastContextDependency === null) {
lastContextDependency = contextItem;
currentlyRenderingFiber.dependencies = {
lanes: NoLanes,
firstContext: contextItem,
responders: null,
};
} else {
lastContextDependency = lastContextDependency.next = contextItem;
}
// 2. 返回 currentValue
return isPrimaryRenderer ? context._currentValue : context._currentValue2;
}
核心逻辑:
1、prepareToReadContext: 设置currentlyRenderingFiber = workInProgress, 并重置lastContextDependency等全局变量.
2、readContext: 返回context._currentValue, 并构造一个contextItem添加到workInProgress.dependencies链表之后.
注意: 这个readContext并不是纯函数, 它还有一些副作用, 会更改workInProgress.dependencies, 其中contextItem.context保存了当前context的引用. 这个dependencies属性会在更新时使用, 用于判定是否依赖了ContextProvider中的值.
返回context._currentValue之后, 之后继续进行fiber树构造直到全部完成即可.
更新 Context
来到更新阶段, 同样进入updateContextConsumer
function updateContextProvider(
current: Fiber | null,
workInProgress: Fiber,
renderLanes: Lanes,
) {
const providerType: ReactProviderType<any> = workInProgress.type;
const context: ReactContext<any> = providerType._context;
const newProps = workInProgress.pendingProps;
const oldProps = workInProgress.memoizedProps;
const newValue = newProps.value;
pushProvider(workInProgress, newValue);
if (oldProps !== null) {
// 更新阶段进入
const oldValue = oldProps.value;
// 对比 newValue 和 oldValue
const changedBits = calculateChangedBits(context, newValue, oldValue);
if (changedBits === 0) {
// value没有变动, 进入 Bailout 逻辑
if (
oldProps.children === newProps.children &&
!hasLegacyContextChanged()
) {
return bailoutOnAlreadyFinishedWork(
current,
workInProgress,
renderLanes,
);
}
} else {
// value变动, 查找对应的consumers, 并使其能够被更新
propagateContextChange(workInProgress, context, changedBits, renderLanes);
}
}
// ... 省略无关代码
}
核心逻辑:
1、value没有改变, 直接进入Bailout(可以回顾fiber 树构造(对比更新)中对bailout的解释).
2、value改变, 调用propagateContextChange
propagateContextChange:
export function propagateContextChange(
workInProgress: Fiber,
context: ReactContext<mixed>,
changedBits: number,
renderLanes: Lanes,
): void {
let fiber = workInProgress.child;
if (fiber !== null) {
// Set the return pointer of the child to the work-in-progress fiber.
fiber.return = workInProgress;
}
while (fiber !== null) {
let nextFiber;
const list = fiber.dependencies;
if (list !== null) {
nextFiber = fiber.child;
let dependency = list.firstContext;
while (dependency !== null) {
// 检查 dependency中依赖的context
if (
dependency.context === context &&
(dependency.observedBits & changedBits) !== 0
) {
// 符合条件, 安排调度
if (fiber.tag === ClassComponent) {
// class 组件需要创建一个update对象, 添加到updateQueue队列
const update = createUpdate(
NoTimestamp,
pickArbitraryLane(renderLanes),
);
update.tag = ForceUpdate; // 注意ForceUpdate, 保证class组件一定执行render
enqueueUpdate(fiber, update);
}
fiber.lanes = mergeLanes(fiber.lanes, renderLanes);
const alternate = fiber.alternate;
if (alternate !== null) {
alternate.lanes = mergeLanes(alternate.lanes, renderLanes);
}
// 向上
scheduleWorkOnParentPath(fiber.return, renderLanes);
// 标记优先级
list.lanes = mergeLanes(list.lanes, renderLanes);
// 退出查找
break;
}
dependency = dependency.next;
}
}
// ...省略无关代码
// ...省略无关代码
fiber = nextFiber;
}
}
propagateContextChange源码比较长, 核心逻辑如下:
1、向下遍历: 从ContextProvider类型的节点开始, 向下查找所有fiber.dependencies依赖该context的节点(假设叫做consumer).
2、向上遍历: 从consumer节点开始, 向上遍历, 修改父路径上所有节点的fiber.childLanes属性, 表明其子节点有改动, 子节点会进入更新逻辑.
- 这一步通过调用scheduleWorkOnParentPath(fiber.return, renderLanes)实现.
export function scheduleWorkOnParentPath(
parent: Fiber | null,
renderLanes: Lanes,
) {
// Update the child lanes of all the ancestors, including the alternates.
let node = parent;
while (node !== null) {
const alternate = node.alternate;
if (!isSubsetOfLanes(node.childLanes, renderLanes)) {
node.childLanes = mergeLanes(node.childLanes, renderLanes);
if (alternate !== null) {
alternate.childLanes = mergeLanes(
alternate.childLanes,
renderLanes,
);
}
} else if (
alternate !== null &&
!isSubsetOfLanes(alternate.childLanes, renderLanes)
) {
alternate.childLanes = mergeLanes(alternate.childLanes, renderLanes);
} else {
// Neither alternate was updated, which means the rest of the
// ancestor path already has sufficient priority.
break;
}
node = node.return;
}
}
- scheduleWorkOnParentPath与markUpdateLaneFromFiberToRoot的作用相似, 具体可以回顾fiber 树构造(对比更新)
通过以上 2 个步骤, 保证了所有消费该context的子节点都会被重新构造, 进而保证了状态的一致性, 实现了context更新.
Context的实现思路还是比较清晰, 总体分为 2 步.
1、在消费状态时,ContextConsumer节点调用readContext(MyContext)获取最新状态.
2、在更新状态时, 由ContextProvider节点负责查找所有ContextConsumer节点, 并设置消费节点的父路径上所有节点的fiber.childLanes, 保证消费节点可以得到更新.
合成事件
从v17.0.0开始, React 不会再将事件处理添加到 document 上, 而是将事件处理添加到渲染 React 树的根 DOM 容器中.
引入官方提供的图片:
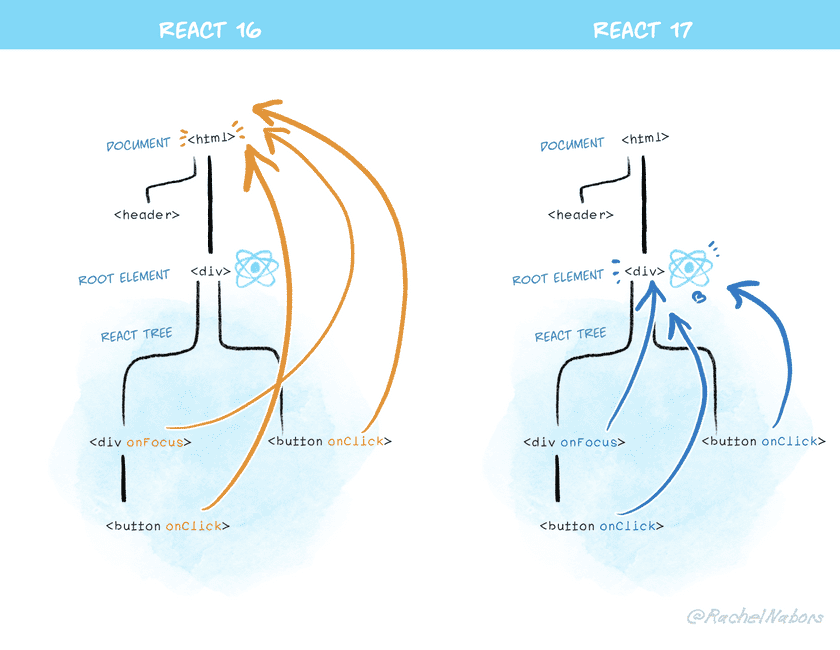
图中清晰的展示了v17.0.0的改动, 无论是在document还是根 DOM 容器上监听事件, 都可以归为事件委托(代理)(mdn).
注意: react的事件体系, 不是全部都通过事件委托来实现的. 有一些特殊情况, 是直接绑定到对应 DOM 元素上的(如:scroll, load), 它们都通过listenToNonDelegatedEvent函数进行绑定.
上述特殊事件最大的不同是监听的 DOM 元素不同, 除此之外, 其他地方的实现与正常事件大体一致.
本节讨论的是可以被根 DOM 容器代理的正常事件.
事件绑定
在前文React 应用的启动过程中介绍了React在启动时会创建全局对象, 其中在创建fiberRoot对象时, 调用createRootImpl:
function createRootImpl(
container: Container,
tag: RootTag,
options: void | RootOptions,
) {
// ... 省略无关代码
if (enableEagerRootListeners) {
const rootContainerElement =
container.nodeType === COMMENT_NODE ? container.parentNode : container;
listenToAllSupportedEvents(rootContainerElement);
}
// ... 省略无关代码
}
listenToAllSupportedEvents函数, 实际上完成了事件代理:
// ... 省略无关代码
export function listenToAllSupportedEvents(rootContainerElement: EventTarget) {
if (enableEagerRootListeners) {
// 1. 节流优化, 保证全局注册只被调用一次
if ((rootContainerElement: any)[listeningMarker]) {
return;
}
(rootContainerElement: any)[listeningMarker] = true;
// 2. 遍历allNativeEvents 监听冒泡和捕获阶段的事件
allNativeEvents.forEach((domEventName) => {
if (!nonDelegatedEvents.has(domEventName)) {
listenToNativeEvent(
domEventName,
false, // 冒泡阶段监听
((rootContainerElement: any): Element),
null,
);
}
listenToNativeEvent(
domEventName,
true, // 捕获阶段监听
((rootContainerElement: any): Element),
null,
);
});
}
}
核心逻辑:
1、节流优化, 保证全局注册只被调用一次.
2、遍历allNativeEvents, 调用listenToNativeEvent监听冒泡和捕获阶段的事件.
- allNativeEvents包括了大量的原生事件名称, 它是在DOMPluginEventSystem.js中被初始化
listenToNativeEvent:
// ... 省略无关代码
export function listenToNativeEvent(
domEventName: DOMEventName,
isCapturePhaseListener: boolean,
rootContainerElement: EventTarget,
targetElement: Element | null,
eventSystemFlags?: EventSystemFlags = 0,
): void {
let target = rootContainerElement;
const listenerSet = getEventListenerSet(target);
const listenerSetKey = getListenerSetKey(
domEventName,
isCapturePhaseListener,
);
// 利用set数据结构, 保证相同的事件类型只会被注册一次.
if (!listenerSet.has(listenerSetKey)) {
if (isCapturePhaseListener) {
eventSystemFlags |= IS_CAPTURE_PHASE;
}
// 注册事件监听
addTrappedEventListener(
target,
domEventName,
eventSystemFlags,
isCapturePhaseListener,
);
listenerSet.add(listenerSetKey);
}
}
addTrappedEventListener:
// ... 省略无关代码
function addTrappedEventListener(
targetContainer: EventTarget,
domEventName: DOMEventName,
eventSystemFlags: EventSystemFlags,
isCapturePhaseListener: boolean,
isDeferredListenerForLegacyFBSupport?: boolean,
) {
// 1. 构造listener
let listener = createEventListenerWrapperWithPriority(
targetContainer,
domEventName,
eventSystemFlags,
);
let unsubscribeListener;
// 2. 注册事件监听
if (isCapturePhaseListener) {
unsubscribeListener = addEventCaptureListener(
targetContainer,
domEventName,
listener,
);
} else {
unsubscribeListener = addEventBubbleListener(
targetContainer,
domEventName,
listener,
);
}
}
// 注册原生事件 冒泡
export function addEventBubbleListener(
target: EventTarget,
eventType: string,
listener: Function,
): Function {
target.addEventListener(eventType, listener, false);
return listener;
}
// 注册原生事件 捕获
export function addEventCaptureListener(
target: EventTarget,
eventType: string,
listener: Function,
): Function {
target.addEventListener(eventType, listener, true);
return listener;
}
从listenToAllSupportedEvents开始, 调用链路比较长, 最后调用addEventBubbleListener和addEventCaptureListener监听了原生事件.
原生 listener
在注册原生事件的过程中, 需要重点关注一下监听函数, 即listener函数. 它实现了把原生事件派发到react体系之内, 非常关键.
比如点击 DOM 触发原生事件, 原生事件最后会被派发到react内部的onClick函数. listener函数就是这个由外至内的关键环节.
listener是通过createEventListenerWrapperWithPriority函数产生:
export function createEventListenerWrapperWithPriority(
targetContainer: EventTarget,
domEventName: DOMEventName,
eventSystemFlags: EventSystemFlags,
): Function {
// 1. 根据优先级设置 listenerWrapper
const eventPriority = getEventPriorityForPluginSystem(domEventName);
let listenerWrapper;
switch (eventPriority) {
case DiscreteEvent:
listenerWrapper = dispatchDiscreteEvent;
break;
case UserBlockingEvent:
listenerWrapper = dispatchUserBlockingUpdate;
break;
case ContinuousEvent:
default:
listenerWrapper = dispatchEvent;
break;
}
// 2. 返回 listenerWrapper
return listenerWrapper.bind(
null,
domEventName,
eventSystemFlags,
targetContainer,
);
}
可以看到, 不同的domEventName调用getEventPriorityForPluginSystem后返回不同的优先级, 最终会有 3 种情况:
1、DiscreteEvent: 优先级最高, 包括click, keyDown, input等事件, 源码
- 对应的listener是dispatchDiscreteEvent
2、UserBlockingEvent: 优先级适中, 包括drag, scroll等事件, 源码
- 对应的listener是dispatchUserBlockingUpdate
3、ContinuousEvent: 优先级最低,包括animation, load等事件, 源码
- 对应的listener是dispatchEvent
这 3 种listener实际上都是对dispatchEvent的包装:
// ...省略无关代码
export function dispatchEvent(
domEventName: DOMEventName,
eventSystemFlags: EventSystemFlags,
targetContainer: EventTarget,
nativeEvent: AnyNativeEvent,
): void {
if (!_enabled) {
return;
}
const blockedOn = attemptToDispatchEvent(
domEventName,
eventSystemFlags,
targetContainer,
nativeEvent,
);
}
事件触发
当原生事件触发之后, 首先会进入到dispatchEvent这个回调函数. 而dispatchEvent函数是react事件体系中最关键的函数, 其调用链路较长, 核心步骤如图所示:
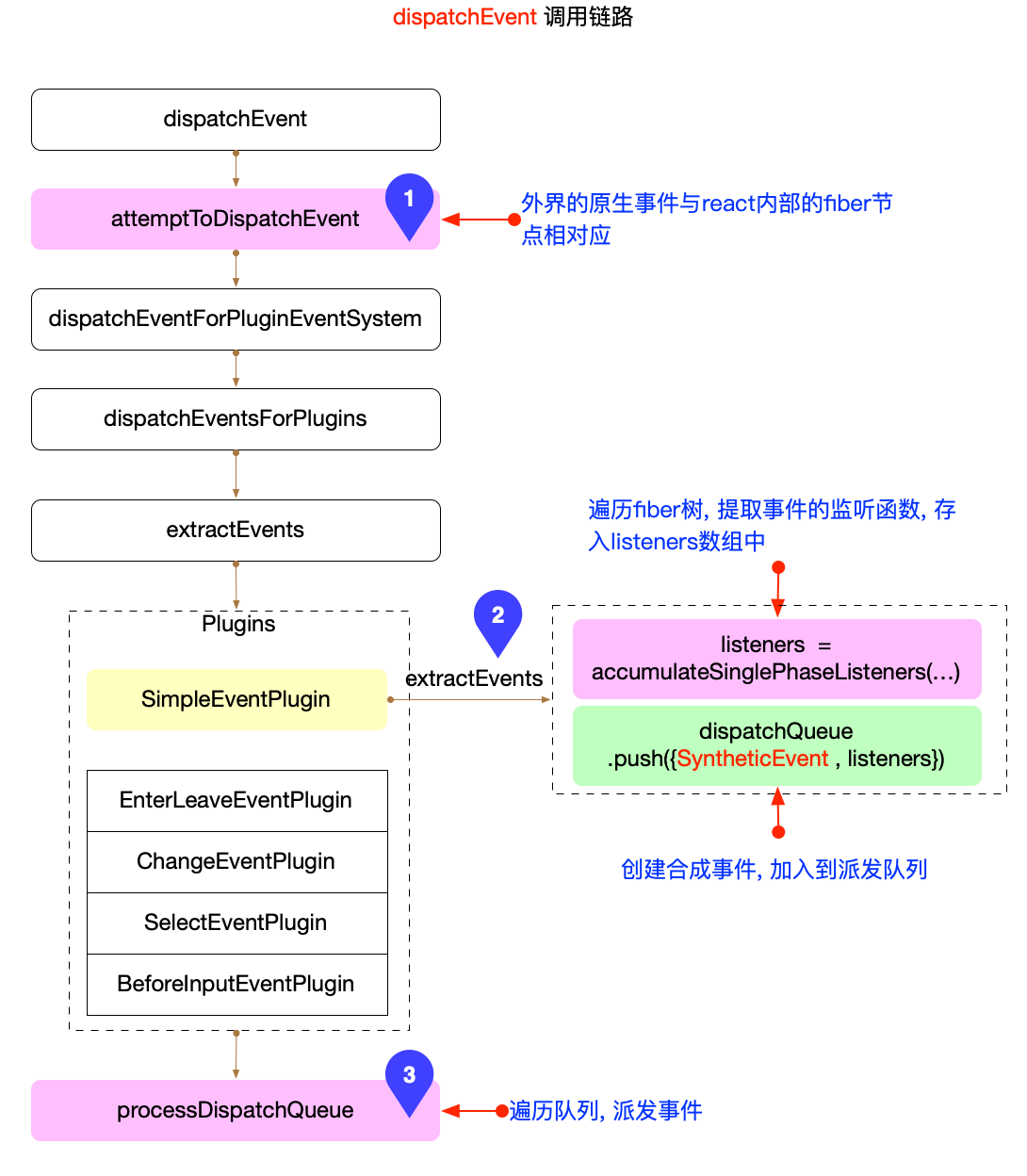
重点关注其中 3 个核心环节:
1、attemptToDispatchEvent
2、SimpleEventPlugin.extractEvents
3、processDispatchQueue
关联 fiber
attemptToDispatchEvent把原生事件和fiber树关联起来.
export function attemptToDispatchEvent(
domEventName: DOMEventName,
eventSystemFlags: EventSystemFlags,
targetContainer: EventTarget,
nativeEvent: AnyNativeEvent,
): null | Container | SuspenseInstance {
// ...省略无关代码
// 1. 定位原生DOM节点
const nativeEventTarget = getEventTarget(nativeEvent);
// 2. 获取与DOM节点对应的fiber节点
let targetInst = getClosestInstanceFromNode(nativeEventTarget);
// 3. 通过插件系统, 派发事件
dispatchEventForPluginEventSystem(
domEventName,
eventSystemFlags,
nativeEvent,
targetInst,
targetContainer,
);
return null;
}
核心逻辑:
1、定位原生 DOM 节点: 调用getEventTarget
2、获取与 DOM 节点对应的 fiber 节点: 调用getClosestInstanceFromNode
3、通过插件系统, 派发事件: 调用 dispatchEventForPluginEventSystem
收集 fiber 上的 listener
dispatchEvent函数的调用链路中, 通过不同的插件, 处理不同的事件. 其中最常见的事件都会由SimpleEventPlugin.extractEvents进行处理:
function extractEvents(
dispatchQueue: DispatchQueue,
domEventName: DOMEventName,
targetInst: null | Fiber,
nativeEvent: AnyNativeEvent,
nativeEventTarget: null | EventTarget,
eventSystemFlags: EventSystemFlags,
targetContainer: EventTarget,
): void {
const reactName = topLevelEventsToReactNames.get(domEventName);
if (reactName === undefined) {
return;
}
let SyntheticEventCtor = SyntheticEvent;
let reactEventType: string = domEventName;
const inCapturePhase = (eventSystemFlags & IS_CAPTURE_PHASE) !== 0;
const accumulateTargetOnly = !inCapturePhase && domEventName === 'scroll';
// 1. 收集所有监听该事件的函数.
const listeners = accumulateSinglePhaseListeners(
targetInst,
reactName,
nativeEvent.type,
inCapturePhase,
accumulateTargetOnly,
);
if (listeners.length > 0) {
// 2. 构造合成事件, 添加到派发队列
const event = new SyntheticEventCtor(
reactName,
reactEventType,
null,
nativeEvent,
nativeEventTarget,
);
dispatchQueue.push({ event, listeners });
}
}
核心逻辑:
1、收集所有listener回调
-
这里的是fiber.memoizedProps.onClick/onClickCapture等绑定在fiber节点上的回调函数
-
具体逻辑在accumulateSinglePhaseListeners:
export function accumulateSinglePhaseListeners(
targetFiber: Fiber | null,
reactName: string | null,
nativeEventType: string,
inCapturePhase: boolean,
accumulateTargetOnly: boolean,
): Array<DispatchListener> {
const captureName = reactName !== null ? reactName + 'Capture' : null;
const reactEventName = inCapturePhase ? captureName : reactName;
const listeners: Array<DispatchListener> = [];
let instance = targetFiber;
let lastHostComponent = null;
// 从targetFiber开始, 向上遍历, 直到 root 为止
while (instance !== null) {
const { stateNode, tag } = instance;
// 当节点类型是HostComponent时(如: div, span, button等类型)
if (tag === HostComponent && stateNode !== null) {
lastHostComponent = stateNode;
if (reactEventName !== null) {
// 获取标准的监听函数 (如onClick , onClickCapture等)
const listener = getListener(instance, reactEventName);
if (listener != null) {
listeners.push(
createDispatchListener(instance, listener, lastHostComponent),
);
}
}
}
// 如果只收集目标节点, 则不用向上遍历, 直接退出
if (accumulateTargetOnly) {
break;
}
instance = instance.return;
}
return listeners;
}
2、构造合成事件(SyntheticEvent), 添加到派发队列(dispatchQueue)
构造合成事件
SyntheticEvent, 是react内部创建的一个对象, 是原生事件的跨浏览器包装器, 拥有和浏览器原生事件相同的接口(stopPropagation,preventDefault), 抹平不同浏览器 api 的差异, 兼容性好.
具体的构造过程并不复杂, 可以直接查看源码.
此处我们需要知道, 在Plugin.extractEvents过程中, 遍历fiber树找到listener之后, 就会创建SyntheticEvent, 加入到dispatchQueue中, 等待派发.
执行派发
extractEvents完成之后, 逻辑来到processDispatchQueue, 终于要真正执行派发了.
export function processDispatchQueue(
dispatchQueue: DispatchQueue,
eventSystemFlags: EventSystemFlags,
): void {
const inCapturePhase = (eventSystemFlags & IS_CAPTURE_PHASE) !== 0;
for (let i = 0; i < dispatchQueue.length; i++) {
const { event, listeners } = dispatchQueue[i];
processDispatchQueueItemsInOrder(event, listeners, inCapturePhase);
}
// ...省略无关代码
}
function processDispatchQueueItemsInOrder(
event: ReactSyntheticEvent,
dispatchListeners: Array<DispatchListener>,
inCapturePhase: boolean,
): void {
let previousInstance;
if (inCapturePhase) {
// 1. capture事件: 倒序遍历listeners
for (let i = dispatchListeners.length - 1; i >= 0; i--) {
const { instance, currentTarget, listener } = dispatchListeners[i];
if (instance !== previousInstance && event.isPropagationStopped()) {
return;
}
executeDispatch(event, listener, currentTarget);
previousInstance = instance;
}
} else {
// 2. bubble事件: 顺序遍历listeners
for (let i = 0; i < dispatchListeners.length; i++) {
const { instance, currentTarget, listener } = dispatchListeners[i];
if (instance !== previousInstance && event.isPropagationStopped()) {
return;
}
executeDispatch(event, listener, currentTarget);
previousInstance = instance;
}
}
}
在processDispatchQueueItemsInOrder遍历dispatchListeners数组, 执行executeDispatch派发事件, 在fiber节点上绑定的listener函数被执行.
在processDispatchQueueItemsInOrder函数中, 根据捕获(capture)或冒泡(bubble)的不同, 采取了不同的遍历方式:
1、capture事件: 从上至下调用fiber树中绑定的回调函数, 所以倒序遍历dispatchListeners.
2、bubble事件: 从下至上调用fiber树中绑定的回调函数, 所以顺序遍历dispatchListeners.
从架构上来讲, SyntheticEvent打通了从外部原生事件到内部fiber树的交互渠道, 使得react能够感知到浏览器提供的原生事件, 进而做出不同的响应, 修改fiber树, 变更视图等.
从实现上讲, 主要分为 3 步:
1、监听原生事件: 对齐DOM元素和fiber元素
2、收集listeners: 遍历fiber树, 收集所有监听本事件的listener函数.
3、派发合成事件: 构造合成事件, 遍历listeners进行派发.
调和算法
调和函数(源码)是在fiber树构(对比更新)过程中对旧fiber节点与新reactElement进行比较, 判定旧fiber节点是否可以复用的一个比较函数.
调和函数仅是fiber树构造过程中的一个环节, 所以在深入理解这个函数之前, 建议对fiber树构造有一个宏观的理解(可以参考前文fiber 树构造(初次创建), fiber 树构造(对比更新)), 本节重点探讨其算法的实现细节.
它的主要作用:
1、给新增,移动,和删除节点设置fiber.flags(新增, 移动: Placement, 删除: Deletion)
2、如果是需要删除的fiber, 除了自身打上Deletion之外, 还要将其添加到父节点的effects链表中(正常副作用队列的处理是在completeWork函数, 但是该节点(被删除)会脱离fiber树, 不会再进入completeWork阶段, 所以在beginWork阶段提前加入副作用队列).
特性
算法复杂度低, 从上至下比较整个树形结构, 时间复杂度被缩短到 O(n)
基本原理
1、比较对象: fiber对象与ReactElement对象相比较.
-
注意: 此处有一个误区, 并不是两棵 fiber 树相比较, 而是旧fiber对象与新ReactElement对象向比较, 结果生成新的fiber子节点.
-
可以理解为输入ReactElement, 经过reconcileChildren()之后, 输出fiber.
2、比较方案:
-
单节点比较
-
可迭代节点比较
单节点比较
单节点的逻辑比较简明, 先直接看源码:
// 只保留主干逻辑
function reconcileSingleElement(
returnFiber: Fiber,
currentFirstChild: Fiber | null,
element: ReactElement,
lanes: Lanes,
): Fiber {
const key = element.key;
let child = currentFirstChild;
while (child !== null) {
// currentFirstChild !== null, 表明是对比更新阶段
if (child.key === key) {
// 1. key相同, 进一步判断 child.elementType === element.type
switch (child.tag) {
// 只看核心逻辑
default: {
if (child.elementType === element.type) {
// 1.1 已经匹配上了, 如果有兄弟节点, 需要给兄弟节点打上Deletion标记
deleteRemainingChildren(returnFiber, child.sibling);
// 1.2 构造fiber节点, 新的fiber对象会复用current.stateNode, 即可复用DOM对象
const existing = useFiber(child, element.props);
existing.ref = coerceRef(returnFiber, child, element);
existing.return = returnFiber;
return existing;
}
break;
}
}
// Didn't match. 给当前节点点打上Deletion标记
deleteRemainingChildren(returnFiber, child);
break;
} else {
// 2. key不相同, 匹配失败, 给当前节点打上Deletion标记
deleteChild(returnFiber, child);
}
child = child.sibling;
}
{
// ...省略部分代码, 只看核心逻辑
}
// 新建节点
const created = createFiberFromElement(element, returnFiber.mode, lanes);
created.ref = coerceRef(returnFiber, currentFirstChild, element);
created.return = returnFiber;
return created;
}
1、如果是新增节点, 直接新建 fiber, 没有多余的逻辑
2、如果是对比更新
-
如果key和type都相同(即: ReactElement.key === Fiber.key 且 Fiber.elementType === ReactElement.type), 则复用
-
否则新建
注意: 复用过程是调用useFiber(child, element.props)创建新的fiber对象, 这个新fiber对象.stateNode = currentFirstChild.stateNode, 即stateNode属性得到了复用, 故 DOM 节点得到了复用.
可迭代节点比较
可迭代节点比较, 在源码中被分为了 2 个部分:
function reconcileChildFibers(
returnFiber: Fiber,
currentFirstChild: Fiber | null,
newChild: any,
lanes: Lanes,
): Fiber | null {
if (isArray(newChild)) {
return reconcileChildrenArray(
returnFiber,
currentFirstChild,
newChild,
lanes,
);
}
if (getIteratorFn(newChild)) {
return reconcileChildrenIterator(
returnFiber,
currentFirstChild,
newChild,
lanes,
);
}
}
其中reconcileChildrenArray函数(针对数组类型)和reconcileChildrenIterator(针对可迭代类型)的核心逻辑几乎一致, 下文将分析reconcileChildrenArray()函数. 如果是新增节点, 所有的比较逻辑都无法命中, 只有对比更新过程, 才有实际作用, 所以下文重点分析对比更新的情况.
function reconcileChildrenArray(
returnFiber: Fiber,
currentFirstChild: Fiber | null,
newChildren: Array<*>,
lanes: Lanes,
): Fiber | null {
let resultingFirstChild: Fiber | null = null;
let previousNewFiber: Fiber | null = null;
let oldFiber = currentFirstChild;
let lastPlacedIndex = 0;
let newIdx = 0;
let nextOldFiber = null;
// 1. 第一次循环: 遍历最长公共序列(key相同), 公共序列的节点都视为可复用
for (; oldFiber !== null && newIdx < newChildren.length; newIdx++) {
// 后文分析
}
if (newIdx === newChildren.length) {
// 如果newChildren序列被遍历完, 那么oldFiber序列中剩余节点都视为删除(打上Deletion标记)
deleteRemainingChildren(returnFiber, oldFiber);
return resultingFirstChild;
}
if (oldFiber === null) {
// 如果oldFiber序列被遍历完, 那么newChildren序列中剩余节点都视为新增(打上Placement标记)
for (; newIdx < newChildren.length; newIdx++) {
// 后文分析
}
return resultingFirstChild;
}
// ==================分割线==================
const existingChildren = mapRemainingChildren(returnFiber, oldFiber);
// 2. 第二次循环: 遍历剩余非公共序列, 优先复用oldFiber序列中的节点
for (; newIdx < newChildren.length; newIdx++) {}
if (shouldTrackSideEffects) {
// newChildren已经遍历完, 那么oldFiber序列中剩余节点都视为删除(打上Deletion标记)
existingChildren.forEach((child) => deleteChild(returnFiber, child));
}
return resultingFirstChild;
}
reconcileChildrenArray函数源码看似很长, 梳理其主干之后, 其实非常清晰.
通过形参, 首先明确比较对象是currentFirstChild: Fiber | null和newChildren: Array<*>:
-
currentFirstChild: 是一个fiber节点, 通过fiber.sibling可以将兄弟节点全部遍历出来. 所以可以将currentFirstChild理解为链表头部, 它代表一个序列, 源码中被记为oldFiber.
-
newChildren: 是一个数组, 其中包含了若干个ReactElement对象. 所以newChildren也代表一个序列.
所以reconcileChildrenArray实际就是 2 个序列之间的比较(链表oldFiber和数组newChildren), 最后返回合理的fiber序列.
上述代码中, 以注释分割线为界限, 整个核心逻辑分为 2 步骤:
1、第一次循环: 遍历最长公共序列(key 相同), 公共序列的节点都视为可复用
-
如果newChildren序列被遍历完, 那么oldFiber序列中剩余节点都视为删除(打上Deletion标记)
-
如果oldFiber序列被遍历完, 那么newChildren序列中剩余节点都视为新增(打上Placement标记)
2、第二次循环: 遍历剩余非公共序列, 优先复用 oldFiber 序列中的节点
- 在对比更新阶段(非初次创建fiber, 此时shouldTrackSideEffects被设置为 true). 第二次循环遍历完成之后, oldFiber序列中没有匹配上的节点都视为删除(打上Deletion标记)
假设有如下图所示 2 个初始化序列:
接下来第一次循环, 会遍历公共序列A,B, 生成的 fiber 节点fiber(A), fiber(B)可以复用.
最后第二次循环, 会遍历剩余序列E,C,X,Y:
-
生成的 fiber 节点fiber(E), fiber(C)可以复用. 其中fiber(C)节点发生了位移(打上Placement标记).
-
fiber(X), fiber(Y)是新增(打上Placement标记).
-
同时oldFiber序列中的fiber(D)节点确定被删除(打上Deletion标记).
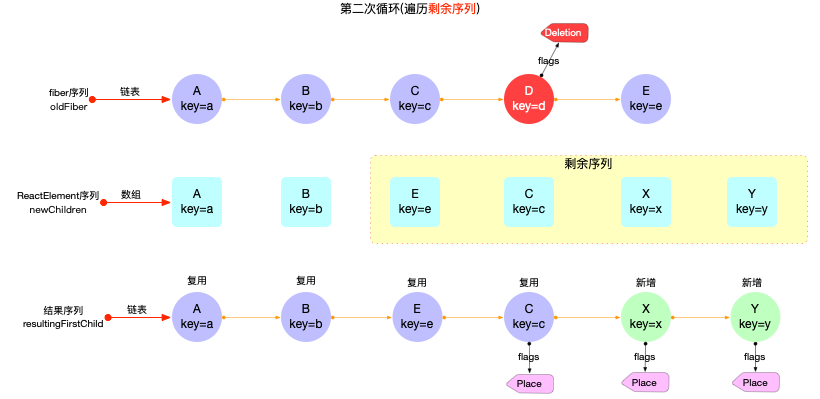
整个主干逻辑就介绍完了, 接下来贴上完整源码
第一次循环
// 1. 第一次循环: 遍历最长公共序列(key相同), 公共序列的节点都视为可复用
for (; oldFiber !== null && newIdx < newChildren.length; newIdx++) {
if (oldFiber.index > newIdx) {
nextOldFiber = oldFiber;
oldFiber = null;
} else {
nextOldFiber = oldFiber.sibling;
}
// new槽位和old槽位进行比较, 如果key不同, 返回null
// key相同, 比较type是否一致. type一致则执行useFiber(update逻辑), type不一致则运行createXXX(insert逻辑)
const newFiber = updateSlot(
returnFiber,
oldFiber,
newChildren[newIdx],
lanes,
);
if (newFiber === null) {
// 如果返回null, 表明key不同. 无法满足公共序列条件, 退出循环
if (oldFiber === null) {
oldFiber = nextOldFiber;
}
break;
}
if (shouldTrackSideEffects) {
// 若是新增节点, 则给老节点打上Deletion标记
if (oldFiber && newFiber.alternate === null) {
deleteChild(returnFiber, oldFiber);
}
}
// lastPlacedIndex 记录被移动的节点索引
// 如果当前节点可复用, 则要判断位置是否移动.
lastPlacedIndex = placeChild(newFiber, lastPlacedIndex, newIdx);
// 更新resultingFirstChild结果序列
if (previousNewFiber === null) {
resultingFirstChild = newFiber;
} else {
previousNewFiber.sibling = newFiber;
}
previousNewFiber = newFiber;
oldFiber = nextOldFiber;
}
第二次循环
// 1. 将第一次循环后, oldFiber剩余序列加入到一个map中. 目的是为了第二次循环能顺利的找到可复用节点
const existingChildren = mapRemainingChildren(returnFiber, oldFiber);
// 2. 第二次循环: 遍历剩余非公共序列, 优先复用oldFiber序列中的节点
for (; newIdx < newChildren.length; newIdx++) {
const newFiber = updateFromMap(
existingChildren,
returnFiber,
newIdx,
newChildren[newIdx],
lanes,
);
if (newFiber !== null) {
if (shouldTrackSideEffects) {
if (newFiber.alternate !== null) {
// 如果newFiber是通过复用创建的, 则清理map中对应的老节点
existingChildren.delete(newFiber.key === null ? newIdx : newFiber.key);
}
}
lastPlacedIndex = placeChild(newFiber, lastPlacedIndex, newIdx);
// 更新resultingFirstChild结果序列
if (previousNewFiber === null) {
resultingFirstChild = newFiber;
} else {
previousNewFiber.sibling = newFiber;
}
previousNewFiber = newFiber;
}
}
// 3. 善后工作, 第二次循环完成之后, existingChildren中剩余的fiber节点就是将要被删除的节点, 打上Deletion标记
if (shouldTrackSideEffects) {
existingChildren.forEach((child) => deleteChild(returnFiber, child));
}
无论是单节点还是可迭代节点的比较, 最终的目的都是生成下级子节点. 并在reconcileChildren过程中, 给一些有副作用的节点(新增, 删除, 移动位置等)打上副作用标记, 等待 commit 阶段(参考fiber 树渲染)的处理.
本节介绍了 React 源码中, fiber构造循环阶段用于生成下级子节点的reconcileChildren函数(函数中的算法被称为调和算法), 并演示了可迭代节点比较的图解示例. 该算法十分巧妙, 其核心逻辑把newChildren序列分为 2 步遍历, 先遍历公共序列, 再遍历非公共部分, 同时复用oldFiber序列中的节点.
位运算
位运算直接处理每一个比特位(bit), 是非常底层的运算, 优势是速度快, 劣势就是不直观且只支持整数运算.
特性
| 位运算 | 用法 | 描述 |
|---|---|---|
| 按位与(&) | a & b | 对于每一个比特位,两个操作数都为 1 时, 结果为 1, 否则为 0 |
| 按位或(|) | a | b | 对于每一个比特位,两个操作数都为 0 时, 结果为 0, 否则为 1 |
| 按位异或(^) | a ^ b | 对于每一个比特位,两个操作数相同时, 结果为 0, 否则为 1 |
| 按位非(~) | ~ a | 反转操作数的比特位, 即 0 变成 1, 1 变成 0 |
| 左移(«) | a « b | 将 a 的二进制形式向左移 b (< 32) 比特位, 右边用 0 填充 |
| 有符号右移(») | a » b | 将 a 的二进制形式向右移 b (< 32) 比特位, 丢弃被移除的位, 左侧以最高位来填充 |
| 无符号右移(»>) | a »> b | 将 a 的二进制形式向右移 b (< 32) 比特位, 丢弃被移除的位, 并用 0 在左侧填充 |
在ES5规范中, 对二进制位运算的说明如下:
The production A : A @ B, where @ is one of the bitwise operators in the productions above, is evaluated as follows:
1. Let lref be the result of evaluating A.
2. Let lval be GetValue(lref).
3. Let rref be the result of evaluating B.
4. Let rval be GetValue(rref).
5. Let lnum be ToInt32(lval).
6. Let rnum be ToInt32(rval).
7. Return the result of applying the bitwise operator @ to lnum and rnum. The result is a signed 32 bit integer.
意思是会将位运算中的左右操作数都转换为有符号32位整型, 且返回结果也是有符号32位整型
-
所以当操作数是浮点型时首先会被转换成整型, 再进行位运算
-
当操作数过大, 超过了Int32范围, 超过的部分会被截取
通过以上知识的回顾, 要点如下:
1、位运算只能在整型变量之间进行运算
2、js 中的Number类型在底层都是以浮点数(参考 IEEE754 标准)进行存储.
3、js 中所有的按位操作符的操作数都会被转成补码(two’s complement)形式的有符号32位整数.
所以在 js 中使用位运算时, 有 2 种情况会造成结果异常:
1、操作数为浮点型(虽然底层都是浮点型, 此处理解为显示性的浮点型)
- 转换流程: 浮点数 -> 整数(丢弃小数位) -> 位运算
2、操作数的大小超过Int32范围(-2^31 ~ 2^31-1). 超过范围的二进制位会被截断, 取低位32bit.
Before: 11100110111110100000000000000110000000000001
After: 10100000000000000110000000000001
另外由于 js 语言的隐式转换, 对非Number类型使用位运算操作符时会发生隐式转换, 相当于先使用Number(xxx)将其转换为number类型, 再进行位运算:
'str' >>> 0; // ===> Number('str') >>> 0 ===> NaN >>> 0 = 0
基本使用
为了方便比较, 以下演示代码中的注释, 都写成了 8 位二进制数(上文已经说明, 事实上在 js 中, 位运算最终的结果都是 Int32).
枚举属性:
通过位移的方式, 定义一些枚举常量
const A = 1 << 0; // 0b00000001
const B = 1 << 1; // 0b00000010
const C = 1 << 2; // 0b00000100
位掩码:
通过位移定义的一组枚举常量, 可以利用位掩码的特性, 快速操作这些枚举产量(增加, 删除, 比较).
1、属性增加|
ABC = A | B | C
2、属性删除& ~
- AB = ABC & ~C
3、属性比较
-
AB 当中包含 B: AB & B === B
-
AB 当中不包含 C: AB & C === 0
-
A 和 B 相等: A === B
const A = 1 << 0; // 0b00000001
const B = 1 << 1; // 0b00000010
const C = 1 << 2; // 0b00000100
// 增加属性
const ABC = A | B | C; // 0b00000111
// 删除属性
const AB = ABC & ~C; // 0b00000011
// 属性比较
// 1. AB当中包含B
console.log((AB & B) === B); // true
// 2. AB当中不包含C
console.log((AB & C) === 0); // true
// 3. A和B相等
console.log(A === B); // false
React 当中的使用场景
在 react 核心包中, 位运算使用的场景非常多. 此处只列举出了使用频率较高的示例.
优先级管理 lanes
lanes 是17.x版本中开始引入的重要概念, 代替了16.x版本中的expirationTime, 作为fiber对象的一个属性(位于react-reconciler包), 主要控制 fiber 树在构造过程中的优先级(这里只介绍位运算的应用, 对于 lanes 的深入分析在优先级管理章节深入解读).
变量定义:
首先看源码ReactFiberLane.js中的定义
//类型定义
export opaque type Lanes = number;
export opaque type Lane = number;
// 变量定义
export const NoLanes: Lanes = /* */ 0b0000000000000000000000000000000;
export const NoLane: Lane = /* */ 0b0000000000000000000000000000000;
export const SyncLane: Lane = /* */ 0b0000000000000000000000000000001;
export const SyncBatchedLane: Lane = /* */ 0b0000000000000000000000000000010;
export const InputDiscreteHydrationLane: Lane = /* */ 0b0000000000000000000000000000100;
const InputDiscreteLanes: Lanes = /* */ 0b0000000000000000000000000011000;
const InputContinuousHydrationLane: Lane = /* */ 0b0000000000000000000000000100000;
const InputContinuousLanes: Lanes = /* */ 0b0000000000000000000000011000000;
// ...
// ...
const NonIdleLanes = /* */ 0b0000111111111111111111111111111;
export const IdleHydrationLane: Lane = /* */ 0b0001000000000000000000000000000;
const IdleLanes: Lanes = /* */ 0b0110000000000000000000000000000;
export const OffscreenLane: Lane = /* */ 0b1000000000000000000000000000000;
源码中Lanes和Lane都是number类型, 并且将所有变量都使用二进制位来表示.
注意: 源码中变量只列出了 31 位, 由于 js 中位运算都会转换成Int32(上文已经解释), 最多为 32 位, 且最高位是符号位. 所以除去符号位, 最多只有 31 位可以参与运算.
方法定义:
function getHighestPriorityLanes(lanes: Lanes | Lane): Lanes {
// 判断 lanes中是否包含 SyncLane
if ((SyncLane & lanes) !== NoLanes) {
return_highestLanePriority = SyncLanePriority;
return SyncLane;
}
// 判断 lanes中是否包含 SyncBatchedLane
if ((SyncBatchedLane & lanes) !== NoLanes) {
return_highestLanePriority = SyncBatchedLanePriority;
return SyncBatchedLane;
}
// ...
// ... 省略其他代码
return lanes;
}
在方法定义中, 也是通过位掩码的特性来判断二进制形式变量之间的关系. 除了常规的位掩码操作外, 特别说明其中 2 个技巧性强的函数:
1、getHighestPriorityLane: 分离出最高优先级
function getHighestPriorityLane(lanes: Lanes) {
return lanes & -lanes;
}
通过lanes & -lanes可以分离出所有比特位中最右边的 1, 具体来讲:
-
假设 lanes(InputDiscreteLanes) = 0b0000000000000000000000000011000
-
那么 -lanes = 0b1111111111111111111111111101000
-
所以 lanes & -lanes = 0b0000000000000000000000000001000
-
相比最初的 InputDiscreteLanes, 分离出来了最右边的1
-
通过 lanes 的定义, 数字越小的优先级越高, 所以此方法可以获取最高优先级的lane
2、getLowestPriorityLane: 分离出最低优先级
function getLowestPriorityLane(lanes: Lanes): Lane {
// This finds the most significant non-zero bit.
const index = 31 - clz32(lanes);
return index < 0 ? NoLanes : 1 << index;
}
clz32(lanes)返回一个数字在转换成 32 无符号整形数字的二进制形式后, 前导 0 的个数(MDN 上的解释)
-
假设 lanes(InputDiscreteLanes) = 0b0000000000000000000000000011000
-
那么 clz32(lanes) = 27, 由于 InputDiscreteLanes 在源码中被书写成了 31 位, 虽然在字面上前导 0 是 26 个, 但是转成标准 32 位后是 27 个
-
index = 31 - clz32(lanes) = 4
-
最后 1 « index = 0b0000000000000000000000000010000
-
相比最初的 InputDiscreteLanes, 分离出来了最左边的1
-
通过 lanes 的定义, 数字越小的优先级越高, 所以此方法可以获取最低优先级的 lane
执行上下文 ExecutionContext
ExecutionContext定义与react-reconciler包中, 代表reconciler在运行时的上下文状态(在reconciler 执行上下文章节中深入解读, 此处介绍位运算的应用).
变量定义:
export const NoContext = /* */ 0b0000000;
const BatchedContext = /* */ 0b0000001;
const EventContext = /* */ 0b0000010;
const DiscreteEventContext = /* */ 0b0000100;
const LegacyUnbatchedContext = /* */ 0b0001000;
const RenderContext = /* */ 0b0010000;
const CommitContext = /* */ 0b0100000;
export const RetryAfterError = /* */ 0b1000000;
// ...
// Describes where we are in the React execution stack
let executionContext: ExecutionContext = NoContext;
注意: 和lanes的定义不同, ExecutionContext类型的变量, 在定义的时候采取的是 8 位二进制表示(因为变量的数量少, 8 位就够了, 没有必要写成 31 位).
使用(由于使用的地方较多, 所以举一个代表性强的例子, scheduleUpdateOnFiber 函数是react-reconciler包对react包暴露出来的 api, 每一次更新都会调用, 所以比较特殊):
// scheduleUpdateOnFiber函数中包含了好多关于executionContext的判断(都是使用位运算)
export function scheduleUpdateOnFiber(
fiber: Fiber,
lane: Lane,
eventTime: number,
) {
if (root === workInProgressRoot) {
// 判断: executionContext 不包含 RenderContext
if (
deferRenderPhaseUpdateToNextBatch ||
(executionContext & RenderContext) === NoContext
) {
// ...
}
}
if (lane === SyncLane) {
if (
// 判断: executionContext 包含 LegacyUnbatchedContext
(executionContext & LegacyUnbatchedContext) !== NoContext &&
// 判断: executionContext 不包含 RenderContext或CommitContext
(executionContext & (RenderContext | CommitContext)) === NoContext
) {
// ...
}
}
// ...
}
本节介绍了位运算的基本使用, 并列举了位运算在react源码中的高频应用. 在特定的情况下, 使用位运算不仅是提高运算速度, 且位掩码能简洁和清晰的表示出二进制变量之间的关系. 二进制变量虽然有优势, 但是缺点也很明显, 不够直观, 扩展性不好(在 js 当中的二进制变量, 除去符号位, 最多只能使用 31 位, 当变量的数量超过 31 位就需要组合, 此时就会变得复杂). 在阅读源码时, 我们需要了解二进制变量和位掩码的使用. 但在实际开发中, 需要视情况而定, 不能盲目使用.
深度优先遍历
对于树或图结构的搜索(或遍历)来讲, 分为深度优先(DFS)和广度优先(BFS).
概念
深度优先遍历: DFS(英语:Depth-First-Search,DFS)是一种用于遍历或搜索树或图的算法.
来自 wiki 上的解释(更权威): 当节点v的所在边都己被探寻过, 搜索将回溯到发现节点v的那条边的起始节点. 这一过程一直进行到已发现从源节点可达的所有节点为止. 如果还存在未被发现的节点, 则选择其中一个作为源节点并重复以上过程, 整个进程反复进行直到所有节点都被访问为止.
实现方式
DFS 的主流实现方式有 2 种.
1、递归(简单粗暴)
function Node() {
this.name = '';
this.children = [];
}
function dfs(node) {
console.log('探寻阶段: ', node.name);
node.children.forEach((child) => {
dfs(child);
});
console.log('回溯阶段: ', node.name);
}
2、利用栈存储遍历路径
function Node() {
this.name = '';
this.children = [];
// 因为要分辨探寻阶段和回溯阶段, 所以必须要一个属性来记录是否已经访问过该节点
// 如果不打印探寻和回溯, 就不需要此属性
this.visited = false;
}
function dfs(node) {
const stack = [];
stack.push(node);
// 栈顶元素还存在, 就继续循环
while ((node = stack[stack.length - 1])) {
if (node.visited) {
console.log('回溯阶段: ', node.name);
// 回溯完成, 弹出该元素
stack.pop();
} else {
console.log('探寻阶段: ', node.name);
node.visited = true;
// 利用栈的先进后出的特性, 倒序将节点送入栈中
for (let i = node.children.length - 1; i >= 0; i--) {
stack.push(node.children[i]);
}
}
}
}
React 当中的使用场景
深度优先遍历在react当中的使用非常典型, 最主要的使用时在ReactElement和fiber树的构造过程. 其次是在使用context时, 需要深度优先地查找消费context的节点.
ReactElement “树”的构造
ReactElement不能算是严格的树结构, 为了方便表述, 后文都称之为树.
在react-reconciler包中, ReactElement的构造过程实际上是嵌套在fiber树构造循环过程中的, 与fiber树的构造是相互交替进行的(在fiber 树构建章节中详细解读, 本节只介绍深度优先遍历的使用场景).
ReactElement树的构造, 实际上就是各级组件render之后的总和. 整个过程体现在reconciler工作循环之中.
源码位于ReactFiberWorkLoop.js中, 此处为了简明, 已经将源码中与 dfs 无关的旁支逻辑去掉.
function workLoopSync() {
// 1. 最外层循环, 保证每一个节点都能遍历, 不会遗漏
while (workInProgress !== null) {
performUnitOfWork(workInProgress);
}
}
function performUnitOfWork(unitOfWork: Fiber): void {
const current = unitOfWork.alternate;
let next;
// 2. beginWork是向下探寻阶段
next = beginWork(current, unitOfWork, subtreeRenderLanes);
if (next === null) {
// 3. completeUnitOfWork 是回溯阶段
completeUnitOfWork(unitOfWork);
} else {
workInProgress = next;
}
}
function completeUnitOfWork(unitOfWork: Fiber): void {
let completedWork = unitOfWork;
do {
const current = completedWork.alternate;
const returnFiber = completedWork.return;
let next;
// 3.1 回溯并处理节点
next = completeWork(current, completedWork, subtreeRenderLanes);
if (next !== null) {
// 判断在处理节点的过程中, 是否派生出新的节点
workInProgress = next;
return;
}
const siblingFiber = completedWork.sibling;
// 3.2 判断是否有旁支
if (siblingFiber !== null) {
workInProgress = siblingFiber;
return;
}
// 3.3 没有旁支 继续回溯
completedWork = returnFiber;
workInProgress = completedWork;
} while (completedWork !== null);
}
以上源码本质上是采用递归的方式进行 dfs, 假设有以下组件结构:
class App extends React.Component {
render() {
return (
<div className="app">
<header>header</header>
<Content />
<footer>footer</footer>
</div>
);
}
}
class Content extends React.Component {
render() {
return (
<React.Fragment>
<p>1</p>
<p>2</p>
<p>3</p>
</React.Fragment>
);
}
}
export default App;
则可以绘制出遍历路径如下:
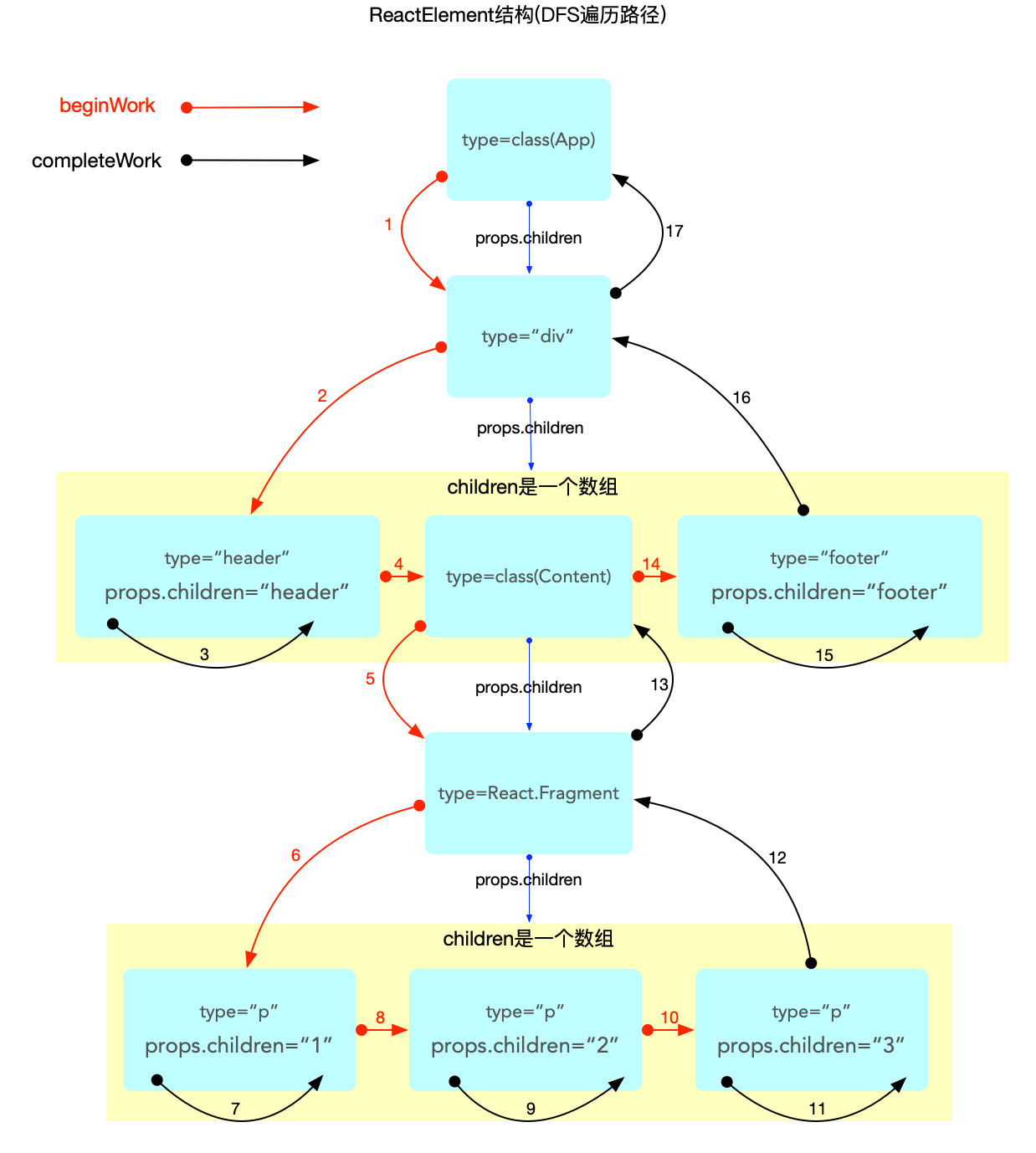
注意:
-
ReactElement树是在大循环中的beginWork阶段”逐级”生成的.
-
“逐级”中的每一级是指一个class或function类型的组件, 每调用一次render或执行一次function调用, 就会生成一批ReactElement节点.
-
ReactElement树的构造, 实际上就是各级组件render之后的总和.
fiber 树的构造
在ReactElement的构造过程中, 同时伴随着fiber树的构造, fiber树同样也是在beginWork阶段生成的.
绘制出遍历路径如下:
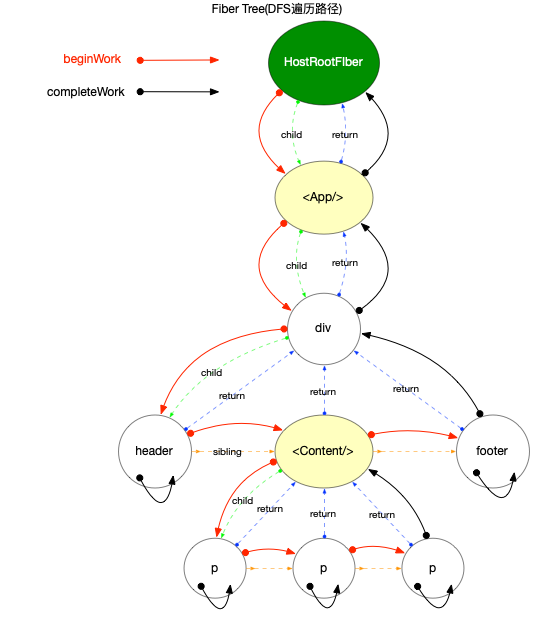
查找 context 的消费节点
当context改变之后, 需要找出依赖该context的所有子节点(详细分析会在context原理章节深入解读), 这里同样也是一个DFS, 具体源码在ReactFiberNewContext.js.
将其主干逻辑剥离出来, 可以清晰的看出采用循环递归的方式进行遍历:
export function propagateContextChange(
workInProgress: Fiber,
context: ReactContext<mixed>,
changedBits: number,
renderLanes: Lanes,
): void {
let fiber = workInProgress.child;
while (fiber !== null) {
let nextFiber;
// Visit this fiber.
const list = fiber.dependencies;
if (list !== null) {
// 匹配context等逻辑, 和dfs无关, 此处可以暂时忽略
// ...
} else {
// 向下探寻
nextFiber = fiber.child;
}
fiber = nextFiber;
}
}
由于react内部使用了ReactElement和fiber两大树形结构, 所以有不少关于节点访问的逻辑.
本节主要介绍了DFS的概念和它在react源码中的使用情况. 其中fiber树的DFS遍历, 涉及到的代码多, 分布广, 涵盖了reconciler阶段的大部分工作, 是reconciler阶段工作循环的核心流程.
除了DFS之外, 源码中还有很多逻辑都是查找树中的节点(如: 向上查找父节点等). 对树形结构的遍历在源码中的比例很高, 了解这些算法技巧能够更好的理解react源码.
堆排序
二叉堆是一种特殊的堆, 二叉堆是完全二叉树或者近似完全二叉树.
堆排序是利用二叉堆的特性, 对根节点(最大或最小)进行循环提取, 从而达到排序目的(堆排序本质上是一种选择排序), 时间复杂度为O(nlog n).
特性
1、父节点的值>=子节点的值(最大堆), 父节点的值<=子节点的值(最小堆). 每个节点的左子树和右子树都是一个二叉堆.
2、假设一个数组[k0, k1, k2, …kn]下标从 0 开始. 则ki <= k2i+1,ki <= k2i+2 或者 ki >= k2i+1,ki >= k2i+2 (i = 0,1,2,3 .. n/2)
基本使用
假设现在有一个乱序数组, [5,8,0,10,4,6,1], 现在将其构造成一个最小堆
1、构造二叉堆
- 需要从最后一个非叶子节点开始, 向下调整堆结构
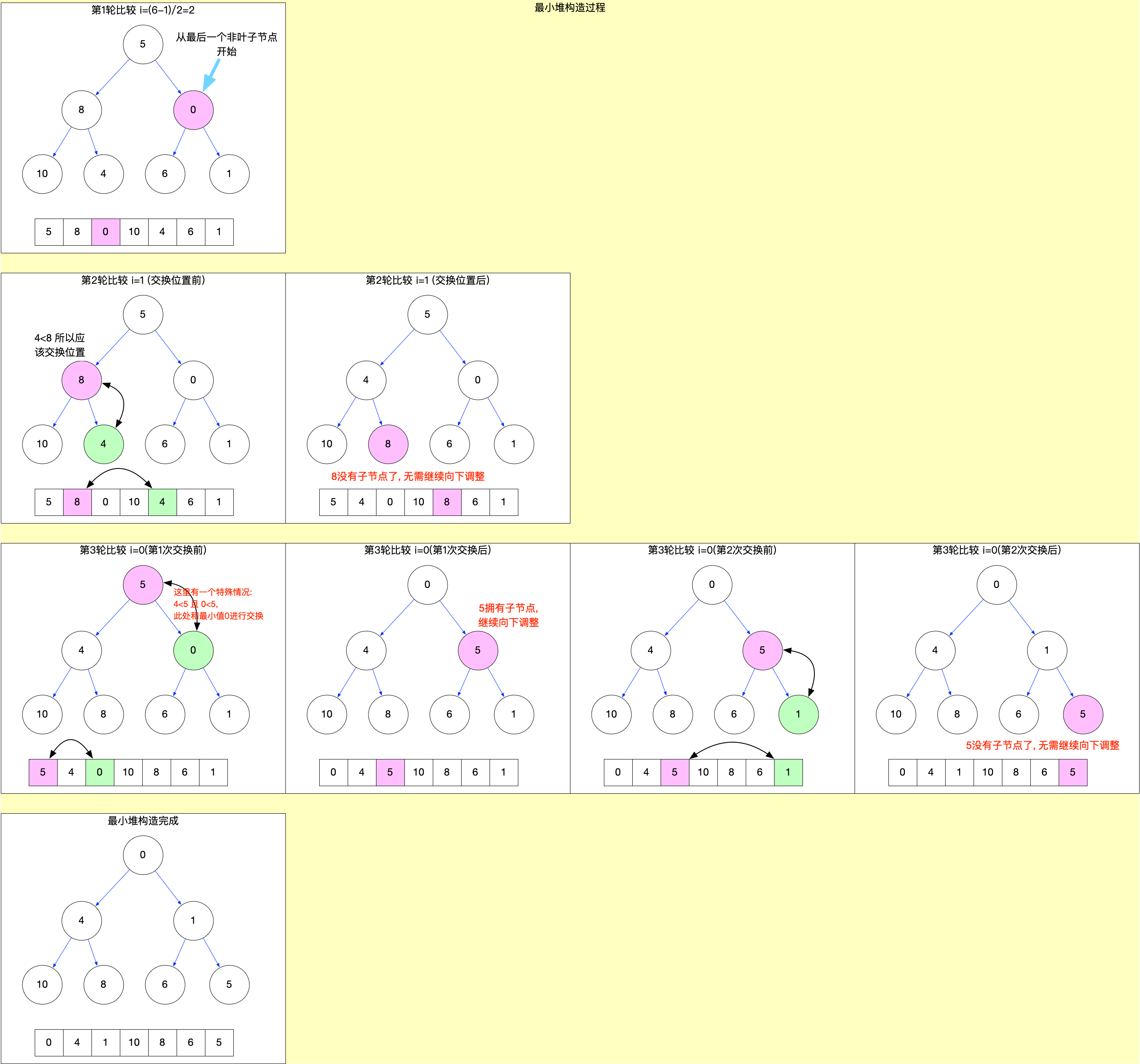
2、插入节点, 重新向上调整堆(sift-up)
- 将新元素插入到数组末尾之后, 要重新调整数组结构, 保证数组任然是最小(或最大)堆.
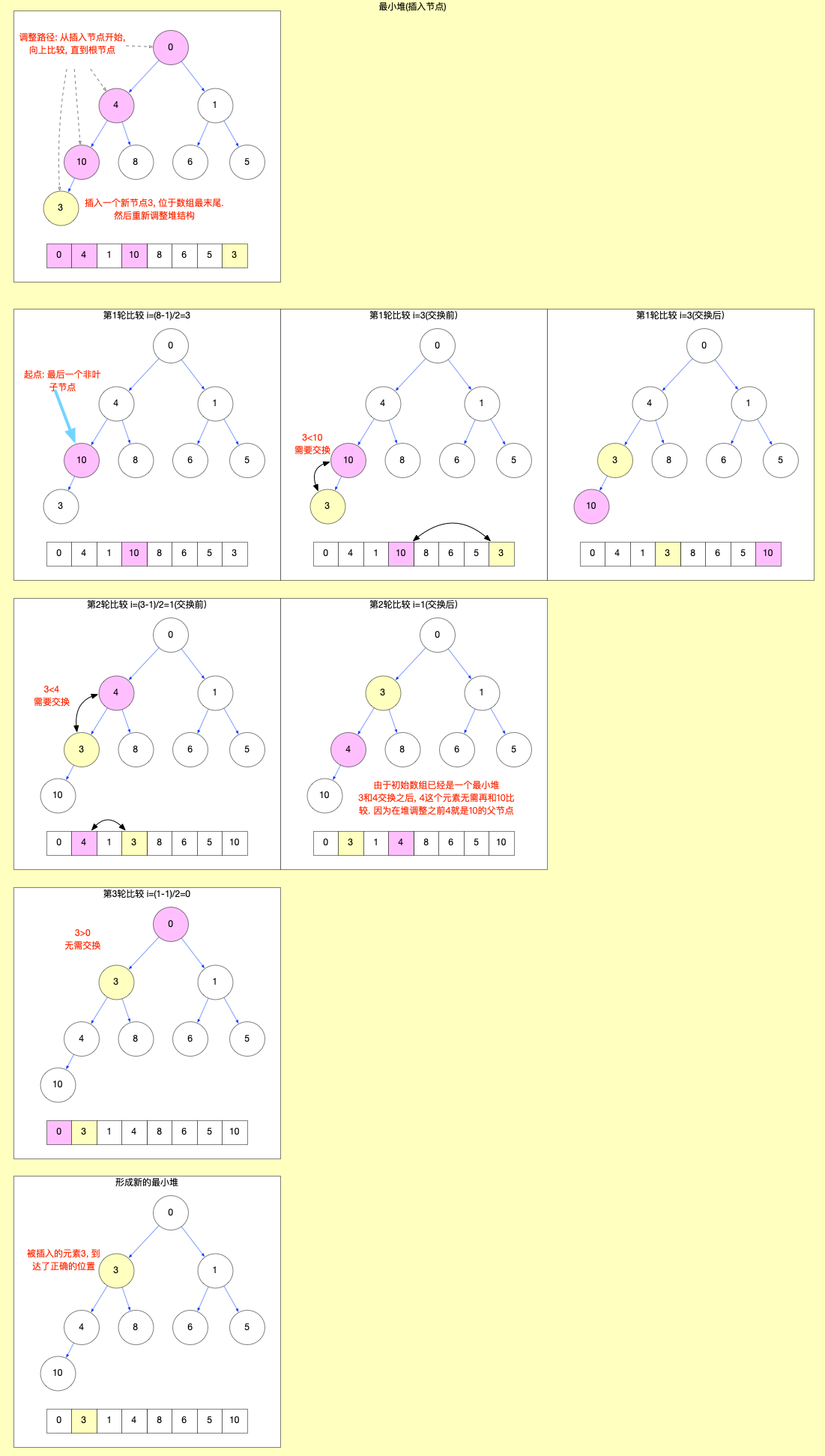
3、提取或删除根节点(顶端节点), 重新向下调整堆(sift-down)
-
对于最大堆, 提取的是最大值. 对于最小堆, 提取的是最小值.
-
顶点被提取之后, 要重新调整数组结构, 保证数组任然是最小(或最大)堆.
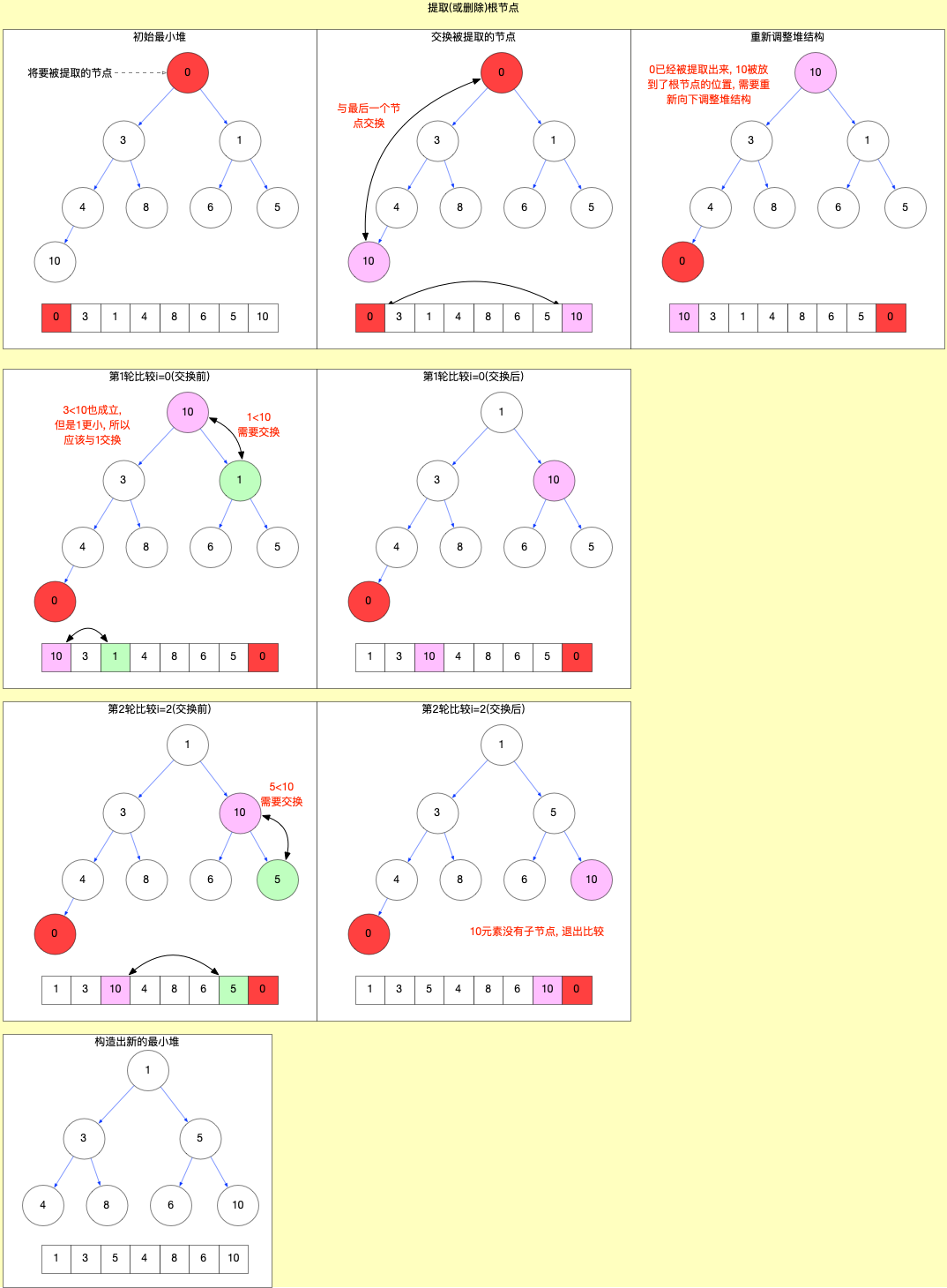
4、排序过程
利用二叉堆的特性, 排序就是循环提取根节点的过程. 循环执行步骤 3, 直到将所有的节点都提取完成, 被提取的节点构成的数组就是一个有序数组.
注意:
-
如需升序排序, 应该构造最大堆. 因为最大的元素最先被提取出来, 被放置到了数组的最后, 最终数组中最后一个元素为最大元素.
-
如需降序排序, 应该构造最小堆. 因为最小的元素最先被提取出来, 被放置到了数组的最后, 最终数组中最后一个元素为最小元素.
-
堆排序是一种不稳定排序(对于相同大小的元素, 在排序之后有可能和排序前的先后次序被打乱).
代码演示
将乱序数组[5,8,0,10,4,6,1]降序排列
步骤:
1、构造最小堆
2、循环提取根节点, 直到全部提取完
const minHeapSort = (arr) => {
// 1. 构造最小堆
buildMinHeap(arr);
// 2. 循环提取根节点arr[0], 直到全部提取完
for (let i = arr.length - 1; i > 0; i--) {
let tmp = arr[0];
arr[0] = arr[i];
arr[i] = tmp;
siftDown(arr, 0, i - 1);
}
};
// 把整个数组构造成最小堆
const buildMinHeap = (arr) => {
if (arr.length < 2) {
return arr;
}
const startIndex = Math.floor(arr.length / 2 - 1);
for (let i = startIndex; i >= 0; i--) {
siftDown(arr, i, arr.length - 1);
}
};
// 从startIndex索引开始, 向下调整最小堆
const siftDown = (arr, startIndex, endIndex) => {
const leftChildIndx = 2 * startIndex + 1;
const rightChildIndx = 2 * startIndex + 2;
let swapIndex = startIndex;
let tmpNode = arr[startIndex];
if (leftChildIndx <= endIndex) {
if (arr[leftChildIndx] < tmpNode) {
// 待定是否交换, 因为right子节点有可能更小
tmpNode = arr[leftChildIndx];
swapIndex = leftChildIndx;
}
}
if (rightChildIndx <= endIndex) {
if (arr[rightChildIndx] < tmpNode) {
// 比left节点更小, 替换swapIndex
tmpNode = arr[rightChildIndx];
swapIndex = rightChildIndx;
}
}
if (swapIndex !== startIndex) {
// 1.交换节点
arr[swapIndex] = arr[startIndex];
arr[startIndex] = tmpNode;
// 2. 递归调用, 继续向下调整
siftDown(arr, swapIndex, endIndex);
}
};
测试:
var arr1 = [5, 8, 0, 10, 4, 6, 1];
minHeapSort(arr1);
console.log(arr1); // [10, 8, 6, 5,4, 1, 0]
var arr2 = [5];
minHeapSort(arr2);
console.log(arr2); // [ 5 ]
var arr3 = [5, 1];
minHeapSort(arr3);
console.log(arr3); //[ 5, 1 ]
React 当中的使用场景
对于二叉堆的应用是在scheduler包中, 有 2 个数组taskQueue和timerQueue, 它们都是以最小堆的形式进行存储, 这样就能保证以O(1)的时间复杂度, 取到数组顶端的对象(优先级最高的 task).
具体的调用过程被封装到了SchedulerMinHeap.js, 其中有 2 个函数siftUp,siftDown分别对应向上调整和向下调整.
type Heap = Array<Node>;
type Node = {|
id: number,
sortIndex: number,
|};
// 添加新节点, 添加之后, 需要调用`siftUp`函数向上调整堆.
export function push(heap: Heap, node: Node): void {
const index = heap.length;
heap.push(node);
siftUp(heap, node, index);
}
// 查看堆的顶点, 也就是优先级最高的`task`或`timer`
export function peek(heap: Heap): Node | null {
const first = heap[0];
return first === undefined ? null : first;
}
// 将堆的顶点提取出来, 并删除顶点之后, 需要调用`siftDown`函数向下调整堆.
export function pop(heap: Heap): Node | null {
const first = heap[0];
if (first !== undefined) {
const last = heap.pop();
if (last !== first) {
heap[0] = last;
siftDown(heap, last, 0);
}
return first;
} else {
return null;
}
}
// 当插入节点之后, 需要向上调整堆结构, 保证数组是一个最小堆.
function siftUp(heap, node, i) {
let index = i;
while (true) {
const parentIndex = (index - 1) >>> 1;
const parent = heap[parentIndex];
if (parent !== undefined && compare(parent, node) > 0) {
// The parent is larger. Swap positions.
heap[parentIndex] = node;
heap[index] = parent;
index = parentIndex;
} else {
// The parent is smaller. Exit.
return;
}
}
}
// 向下调整堆结构, 保证数组是一个最小堆.
function siftDown(heap, node, i) {
let index = i;
const length = heap.length;
while (index < length) {
const leftIndex = (index + 1) * 2 - 1;
const left = heap[leftIndex];
const rightIndex = leftIndex + 1;
const right = heap[rightIndex];
// If the left or right node is smaller, swap with the smaller of those.
if (left !== undefined && compare(left, node) < 0) {
if (right !== undefined && compare(right, left) < 0) {
heap[index] = right;
heap[rightIndex] = node;
index = rightIndex;
} else {
heap[index] = left;
heap[leftIndex] = node;
index = leftIndex;
}
} else if (right !== undefined && compare(right, node) < 0) {
heap[index] = right;
heap[rightIndex] = node;
index = rightIndex;
} else {
// Neither child is smaller. Exit.
return;
}
}
}
-
peek函数: 查看堆的顶点, 也就是优先级最高的task或timer.
-
pop函数: 将堆的顶点提取出来, 并删除顶点之后, 需要调用siftDown函数向下调整堆.
-
push函数: 添加新节点, 添加之后, 需要调用siftUp函数向上调整堆.
-
siftDown函数: 向下调整堆结构, 保证数组是一个最小堆.
-
siftUp函数: 当插入节点之后, 需要向上调整堆结构, 保证数组是一个最小堆.
本节介绍了堆排序的基本使用, 并说明了堆排序在react源码中的应用. 在阅读scheduler包的源码时, 会更加清晰的理解作者的思路.
链表操作
来自 wiki 上的解释: 链表(Linked list)是一种常见的基础数据结构, 是一种线性表, 但是并不会按线性的顺序存储数据, 而是在每一个节点里存到下一个节点的指针(Pointer).由于不必须按顺序存储,链表在插入的时候可以达到 O(1)的复杂度, 但是查找一个节点或者访问特定编号的节点则需要 O(n)的时间.
1、单向链表: 每个节点包含两个域, 一个信息域和一个指针域. 这个指针指向列表中的下一个节点, 而最后一个节点则指向一个空值.
2、双向链表: 每个节点有两个连接, 一个指向前一个节点(第一个节点指向空值), 而另一个指向下一个节点(最后一个节点指向空值).
3、循环链表: 在单向链表的基础上, 首节点和末节点被连接在一起.
基本使用
1、节点插入, 时间复杂度O(1)
2、节点查找, 时间复杂度O(n)
3、节点删除, 时间复杂度O(1)
4、反转链表, 时间复杂度O(n)
// 定义Node节点类型
function Node(name) {
this.name = name;
this.next = null;
}
// 链表
function LinkedList() {
this.head = new Node('head');
// 查找node节点的前一个节点
this.findPrevious = function (node) {
let currentNode = this.head;
while (currentNode && currentNode.next !== node) {
currentNode = currentNode.next;
}
return currentNode;
};
// 在node后插入新节点newElement
this.insert = function (name, node) {
const newNode = new Node(name);
newNode.next = node.next;
node.next = newNode;
};
// 删除节点
this.remove = function (node) {
const previousNode = this.findPrevious(node);
if (previousNode) {
previousNode.next = node.next;
}
};
// 反转链表
this.reverse = function () {
let prev = null;
let current = this.head;
while (current) {
const tempNode = current.next;
// 重新设置next指针, 使其指向前一个节点
current.next = prev;
// 游标后移
prev = current;
current = tempNode;
}
// 重新设置head节点
this.head = prev;
};
}
React 当中的使用场景
在 react 中, 链表的使用非常高频, 主要集中在fiber和hook对象的属性中.
fiber 对象
在react 高频对象中对fiber对象的属性做了说明, 这里列举出 4 个链表属性.
1、effect链表(链式队列): 存储有副作用的子节点, 构成该队列的元素是fiber对象
-
fiber.nextEffect: 单向链表, 指向下一个有副作用的 fiber 节点.
-
fiber.firstEffect: 指向副作用链表中的第一个 fiber 节点.
-
fiber.lastEffect: 指向副作用链表中的最后一个 fiber 节点.
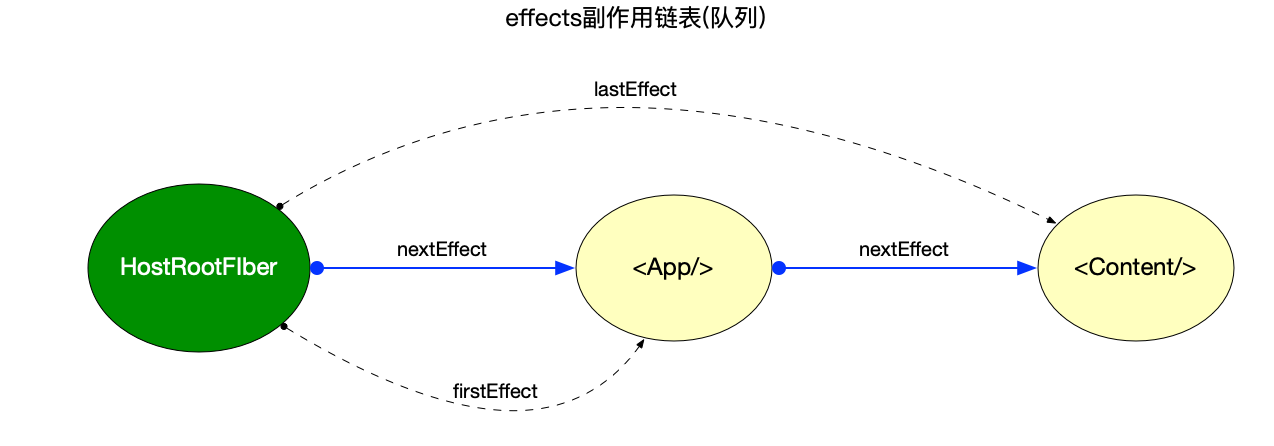
注意: 此处只表示出链表的结构示意图, 在fiber 树构造章节中会对上图的结构进行详细解读.
2、updateQueue链表(链式队列): 存储将要更新的状态, 构成该队列的元素是update对象
- fiber.updateQueue.pending: 存储state更新的队列(链式队列), class类型节点的state改动之后, 都会创建一个update对象添加到这个队列中. 由于此队列是一个环形队列, 为了方便添加新元素和快速拿到队首元素, 所以pending指针指向了队列中最后一个元素.
注意: 此处只表示出链表的结构示意图, 在状态组件(class 与 function)章节中会对上图的结构进行详细解读.
Hook 对象
在react 高频对象中对Hook对象的属性做了说明, Hook对象具备.next属性, 所以Hook对象本身就是链表中的一个节点.
此外hook.queue.pending也构成了一个链表, 将hook链表与hook.queue.pending链表同时表示在图中, 得到的结构如下:
注意: 此处只表示出链表的结构示意图, 在hook 原理章节中会对上图的结构进行详细解读.
链表合并
在react中, 发起更新之后, 会通过链表合并的方式把等待(pending状态)更新的队列(updateQueue)合并到基础队列(class组件:fiber.updateQueue.firstBaseUpdate;function组件: hook.baseQueue), 最后通过遍历baseQueue筛选出优先级足够的update对象, 组合成最终的组件状态(state). 这个过程发生在reconciler阶段, 分别涉及到class组件和function组件.
具体场景:
1、class组件中
- 在class组件中调用setState, 会创建update对象并添加到fiber.updateQueue.shared.pending链式队列(源码地址).
export function enqueueUpdate<State>(fiber: Fiber, update: Update<State>) {
const updateQueue = fiber.updateQueue;
// ...
const sharedQueue: SharedQueue<State> = (updateQueue: any).shared;
// 将新的update对象添加到fiber.updateQueue.shared.pending链表上
const pending = sharedQueue.pending;
if (pending === null) {
update.next = update;
} else {
update.next = pending.next;
pending.next = update;
}
sharedQueue.pending = update;
}
由于fiber.updateQueue.shared.pending是一个环形链表, 所以fiber.updateQueue.shared.pending永远指向末尾元素(保证快速添加新元素)
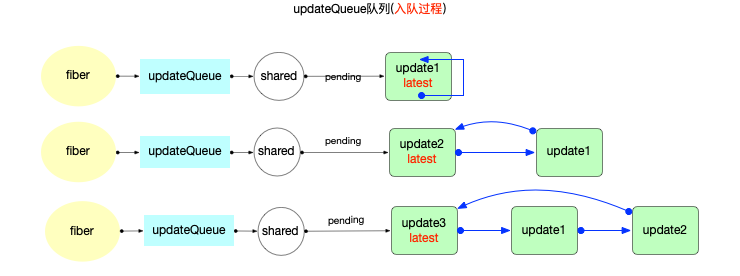
- 在fiber树构建阶段(或reconciler阶段), 会把fiber.updateQueue.shared.pending合并到fiber.updateQueue.firstBaseUpdate队列上(源码地址).
export function processUpdateQueue<State>(
workInProgress: Fiber,
props: any,
instance: any,
renderLanes: Lanes,
): void {
// This is always non-null on a ClassComponent or HostRoot
const queue: UpdateQueue<State> = (workInProgress.updateQueue: any);
let firstBaseUpdate = queue.firstBaseUpdate;
let lastBaseUpdate = queue.lastBaseUpdate;
// Check if there are pending updates. If so, transfer them to the base queue.
let pendingQueue = queue.shared.pending;
if (pendingQueue !== null) {
queue.shared.pending = null;
// The pending queue is circular. Disconnect the pointer between first
// and last so that it's non-circular.
const lastPendingUpdate = pendingQueue;
const firstPendingUpdate = lastPendingUpdate.next;
lastPendingUpdate.next = null;
// Append pending updates to base queue
if (lastBaseUpdate === null) {
firstBaseUpdate = firstPendingUpdate;
} else {
lastBaseUpdate.next = firstPendingUpdate;
}
lastBaseUpdate = lastPendingUpdate;
}
}
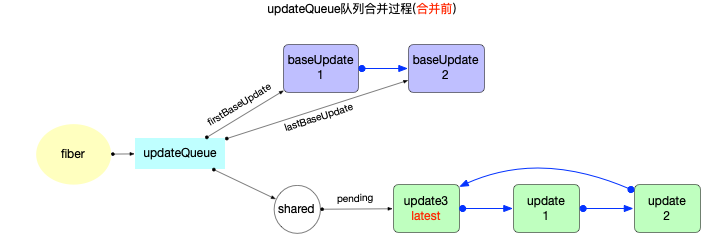
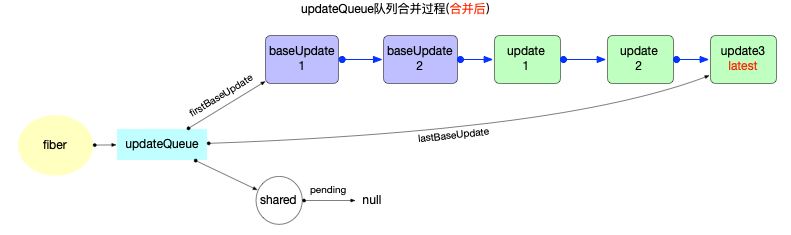
2、function组件中
-
在function组件中使用Hook对象(useState), 并改变Hook对象的值(内部会调用dispatchAction), 此时也会创建update(hook)对象并添加到hook.queue.pending链式队列(源码地址).
-
hook.queue.pending也是一个环形链表(与fiber.updateQueue.shared.pending的结构很相似)
function dispatchAction<S, A>(
fiber: Fiber,
queue: UpdateQueue<S, A>,
action: A,
) {
// ... 省略部分代码
const pending = queue.pending;
if (pending === null) {
// This is the first update. Create a circular list.
update.next = update;
} else {
update.next = pending.next;
pending.next = update;
}
queue.pending = update;
}
- 在fiber树构建阶段(或reconciler阶段), 会将hook.queue.pending合并到hook.baseQueue队列上(源码地址).
function updateReducer<S, I, A>(
reducer: (S, A) => S,
initialArg: I,
init?: (I) => S,
): [S, Dispatch<A>] {
// ... 省略部分代码
if (pendingQueue !== null) {
if (baseQueue !== null) {
// 在这里进行队列的合并
const baseFirst = baseQueue.next;
const pendingFirst = pendingQueue.next;
baseQueue.next = pendingFirst;
pendingQueue.next = baseFirst;
}
current.baseQueue = baseQueue = pendingQueue;
queue.pending = null;
}
}
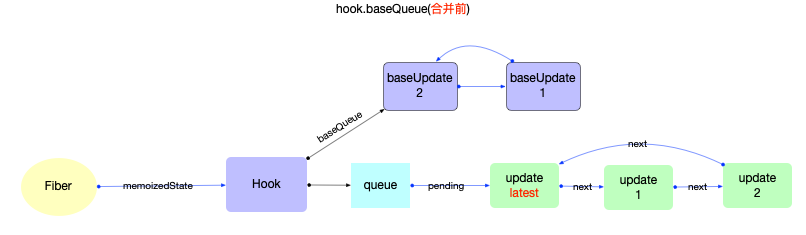
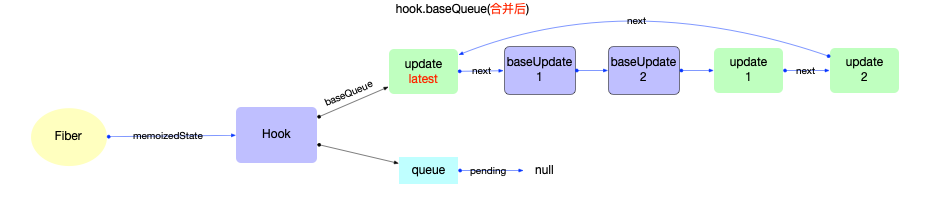
本节主要介绍了链表的概念和它在react源码中的使用情况. react中主要的数据结构都和链表有关, 使用非常高频. 源码中链表合并, 环形链表拆解, 链表遍历的代码篇幅很多, 所以深入理解链表的使用, 对理解react原理大有益处.
栈操作
来自 wiki 上的解释: 堆栈(stack)又称为栈或堆叠, 是计算机科学中的一种抽象资料类型, 只允许在有序的线性资料集合的一端(称为堆栈顶端top)进行加入数据(push)和移除数据(pop)的运算. 因而按照后进先出(LIFO, Last In First Out)的原理运作.
注意:
-
栈(stack)又叫做堆栈, 这里特指数据结构中的栈(另一种程序内存分配中的栈, 本系列不做介绍, 读者可自行了解).
-
堆栈中虽带有一个堆字, 只是命名, 不要和堆混淆.
-
常说的堆有 2 种指代, 一种是数据结构中的堆(在React 算法之堆排序中有介绍), 另一种是程序内存分配中的堆(本系列不做介绍, 读者可自行了解).
特性
1、先入后出, 后入先出.
2、除头尾节点之外, 每个元素有一个前驱, 一个后继.
基本使用
1、压栈: push()
2、弹栈: pop()
3、预览栈顶元素: peek()
class Stack {
constructor() {
this.dataStore = [];
this.top = 0;
}
// 压栈
push(element) {
this.dataStore[this.top++] = element;
}
// 弹栈
pop() {
return this.dataStore[--this.top];
}
// 预览栈顶元素
peek() {
return this.dataStore[this.top - 1];
}
// 检测栈内存储了多少个元素
length() {
return this.top;
}
// 清空栈
clear() {
this.top = 0;
}
}
测试代码:
const test = () => {
const stack = new Stack();
console.log('压栈a: ');
stack.push('a');
console.log('压栈b: ');
stack.push('b');
console.log('压栈c: ');
stack.push('c');
console.log('栈高度: ', stack.length());
console.log('栈顶元素: ', stack.peek());
console.log('弹出: ', stack.pop());
console.log('栈顶元素: ', stack.peek());
console.log('压栈d: ');
stack.push('d');
console.log('栈顶元素: ', stack.peek());
console.log('清空栈: ');
stack.clear();
console.log('栈高度: ', stack.length());
console.log('压栈e: ');
stack.push('e');
console.log('栈顶元素: ', stack.peek());
};
利用栈先进后出的特性, 在实际编码中应用非常广泛. 如回溯,递归,深度优先搜索等经典算法都可以利用栈的特性来实现. 由于本文的目的是讲解栈react中的使用场景, 所以与栈相关的经典案例本文不再列举, 请读者移步其他算法资料.
React 当中的使用场景
Context 状态管理
在fiber树创建过程中, 如果使用了Context api(具体来说是使用Context.Provider, Class.contextType, Context.Consumer等api), react内部会维护一个栈来保存提供者(Context.Provider)的状态, 供给消费者(Context.Consumer)使用.
首先看stack的定义(ReactFiberStack.js中):
export type StackCursor<T> = {| current: T |};
// 维护一个全局stack
const valueStack: Array<any> = [];
let index = -1;
// 一个工厂函数, 创建StackCursor对象
function createCursor<T>(defaultValue: T): StackCursor<T> {
return {
current: defaultValue,
};
}
function isEmpty(): boolean {
return index === -1;
}
// 出栈
function pop<T>(cursor: StackCursor<T>, fiber: Fiber): void {
if (index < 0) {
return;
}
cursor.current = valueStack[index];
valueStack[index] = null;
index--;
}
// 入栈
function push<T>(cursor: StackCursor<T>, value: T, fiber: Fiber): void {
index++;
// 注意: 这里存储的是 cursor当前值, 随后更新了cursor.current为
valueStack[index] = cursor.current;
cursor.current = value;
}
在ReactFiberStack.js源码中, 定义的valueStack作为全局变量, 用来存储所有的StackCursor.current(不仅仅存储context api相关的StackCursor, 在context 原理章节中详细解读, 本节只讨论与context api相关的栈操作).
注意StackCursor是一个泛型对象, 与context api相关的StackCursor定义在ReactFiberNewContext.js:
// 定义全局 valueCursor, 用于管理<Context.Provider/>组件的value
const valueCursor: StackCursor<mixed> = createCursor(null);
// ...省略无关代码
// 将context当前的值保存到valueCursor中, 并设置context._currentValue为最新值
// 运行完成之后context为最新状态
export function pushProvider<T>(providerFiber: Fiber, nextValue: T): void {
const context: ReactContext<T> = providerFiber.type._context;
push(valueCursor, context._currentValue, providerFiber);
context._currentValue = nextValue;
}
// 取出valueCursor中保存的旧值, 设置到context._currentValue上.
// 运行完成之后context恢复到上一个状态
export function popProvider(providerFiber: Fiber): void {
const currentValue = valueCursor.current;
pop(valueCursor, providerFiber);
const context: ReactContext<any> = providerFiber.type._context;
context._currentValue = currentValue;
}
假设有如下组件结构(平时开发很难有这样的代码, 此处完全是为了演示context api中涉及到的栈操作):
const MyContext = React.createContext(0);
export default function App() {
return (
// 第一级
<MyContext.Provider value={1}>
<MyContext.Consumer>
{(value1) => (
//第二级嵌套
<MyContext.Provider value={2}>
<MyContext.Consumer>
{(value2) => (
// 第三级嵌套
<MyContext.Provider value={3}>
<MyContext.Consumer>
{(value3) => (
<span>
{value1}-{value2}-{value3}
</span>
)}
</MyContext.Consumer>
</MyContext.Provider>
)}
</MyContext.Consumer>
</MyContext.Provider>
)}
</MyContext.Consumer>
</MyContext.Provider>
);
}
可在codesandbox中查看运行结果.
将fiber树构造过程中MyContext对象在栈中的变化情况表示出来:
1、beginWork阶段: 入栈
-
reconciler之前, 由于const MyContext = React.createContext(0);已经创建了MyContext对象, 所以其初始值是0.
-
reconciler过程中, 每当遇到Context.Provider类型的节点, 则会执行pushProvider.
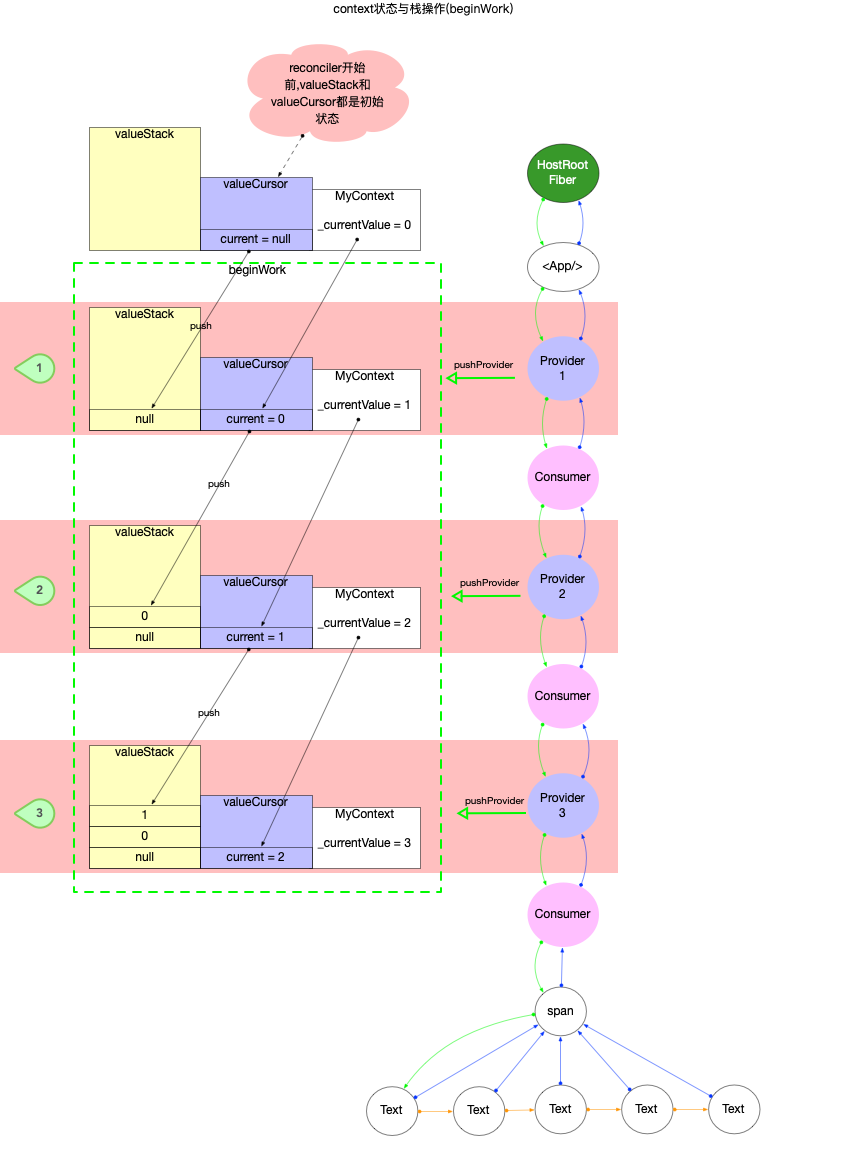
2、completeWork阶段: 出栈
-
reconciler过程中, 每当遇到Context.Provider类型的节点, 则会执行popProvider.
-
reconciler之后, valueStack和valueCursor以及MyContext都恢复到了初始状态.
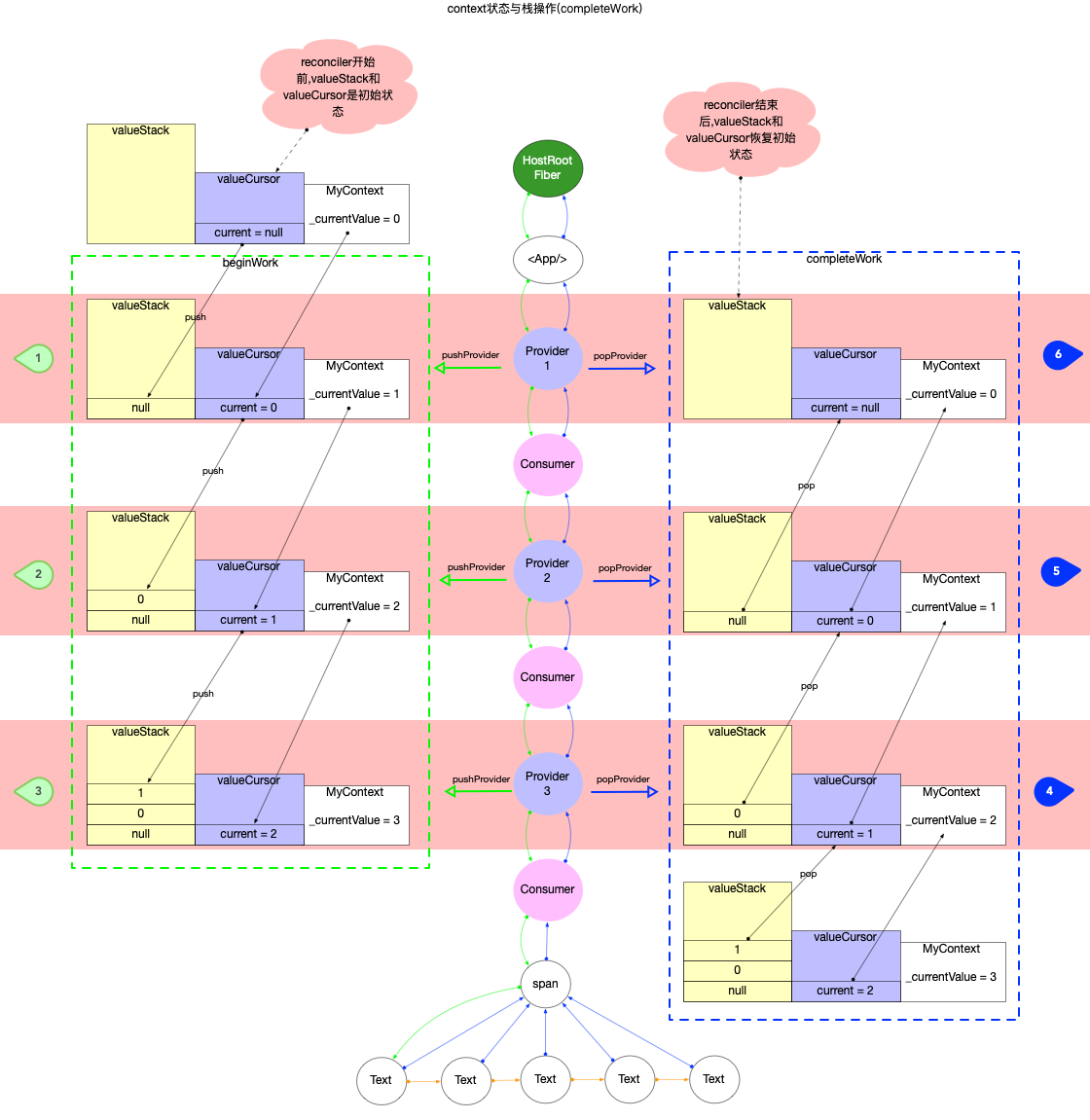
注意:
-
本节只分析context实现源码中与栈相关的部分, 所以只涉及到了Context.Provider(供应者)节点.
-
对于Context.Consumer(消费者)以及更新阶段context的运行机制的深入解读放在context原理章节中.
executionContext 执行上下文
executionContext是在ReactFiberWorkLoop.js中定义的一个全局变量(相对于该闭包), 且定义成二进制变量, 通过位运算来维护其状态(在React 算法之位运算一文中已有介绍).
表面上看executionContext和栈并没有直接关系, 但实际在改变executionContext的时候, 巧妙的利用了函数调用栈, 实现executionContext状态的维护.
本节主要是体现executionContext和函数调用栈之间的配合运用(具体源码), 这里以batchedUpdates和unbatchedUpdates为例进行分析.
export function batchedUpdates<A, R>(fn: (A) => R, a: A): R {
// 在执行回调之前, 先改变 executionContext
const prevExecutionContext = executionContext;
executionContext |= BatchedContext;
try {
return fn(a);
} finally {
// 回调执行完毕之后, 再恢复到以前的值 prevExecutionContext
executionContext = prevExecutionContext;
// ... 省略无关代码
}
}
export function unbatchedUpdates<A, R>(fn: (a: A) => R, a: A): R {
const prevExecutionContext = executionContext;
executionContext &= ~BatchedContext;
executionContext |= LegacyUnbatchedContext;
try {
return fn(a);
} finally {
executionContext = prevExecutionContext;
// ... 省略无关代码
}
}
// ... 省略其他函数
这些函数的共性:
1、执行回调之前, 先保存当前值为prevExecutionContext, 再改变 executionContext.
2、在执行回调fn期间, 无论函数fn调用栈有多深, 被改变过的executionContext始终有效.
3、回调执行完毕之后, 恢复到以前的值 prevExecutionContext.
本节主要介绍了栈在react源码中的使用情况. 涉及入栈出栈等基本操作(Context 状态管理), 以及对函数调用栈的巧妙运用(改变executionContext执行上下文).
由于reconciler过程是一个深度优先遍历过程, 对于fiber树来讲, 向下探寻(beginWork阶段)和向上回溯(completeWork阶段)天然就和栈的入栈(push)和出栈(pop)能够无缝配合(context 机制就是在这个特性上建立起来的).
面试题
setState 是同步还是异步
所谓同步还是异步指的是调用 setState 之后是否马上能得到最新的 state
不仅仅是setState了, 在对 function 类型组件中的 hook 进行操作时也是一样, 最终决定setState是同步渲染还是异步渲染的关键因素是ReactFiberWorkLoop工作空间的执行上下文.
具体代码如下:
export function scheduleUpdateOnFiber(
fiber: Fiber,
expirationTime: ExpirationTime,
) {
const priorityLevel = getCurrentPriorityLevel();
if (expirationTime === Sync) {
if (
// Check if we're inside unbatchedUpdates
(executionContext & LegacyUnbatchedContext) !== NoContext &&
// Check if we're not already rendering
(executionContext & (RenderContext | CommitContext)) === NoContext
) {
performSyncWorkOnRoot(root);
} else {
ensureRootIsScheduled(root);
schedulePendingInteractions(root, expirationTime);
if (executionContext === NoContext) {
// Flush the synchronous work now, unless we're already working or inside
// a batch. This is intentionally inside scheduleUpdateOnFiber instead of
// scheduleCallbackForFiber to preserve the ability to schedule a callback
// without immediately flushing it. We only do this for user-initiated
// updates, to preserve historical behavior of legacy mode.
flushSyncCallbackQueue();
}
}
} else {
// Schedule a discrete update but only if it's not Sync.
if (
(executionContext & DiscreteEventContext) !== NoContext &&
// Only updates at user-blocking priority or greater are considered
// discrete, even inside a discrete event.
(priorityLevel === UserBlockingPriority ||
priorityLevel === ImmediatePriority)
) {
// This is the result of a discrete event. Track the lowest priority
// discrete update per root so we can flush them early, if needed.
if (rootsWithPendingDiscreteUpdates === null) {
rootsWithPendingDiscreteUpdates = new Map([[root, expirationTime]]);
} else {
const lastDiscreteTime = rootsWithPendingDiscreteUpdates.get(root);
if (
lastDiscreteTime === undefined ||
lastDiscreteTime > expirationTime
) {
rootsWithPendingDiscreteUpdates.set(root, expirationTime);
}
}
}
// Schedule other updates after in case the callback is sync.
ensureRootIsScheduled(root);
schedulePendingInteractions(root, expirationTime);
}
}
可以看到, 是否同步渲染调度决定代码是flushSyncCallbackQueue(). 进入该分支的条件:
1、必须是legacy模式, concurrent模式下expirationTime不会为Sync
2、executionContext === NoContext, 执行上下文必须要为空.
两个条件缺一不可.
结论
同步:
1、首先在legacy模式下
2、在执行上下文为空的时候去调用setState
-
可以使用异步调用如setTimeout, Promise, MessageChannel等
-
可以监听原生事件, 注意不是合成事件, 在原生事件的回调函数中执行 setState 就是同步的
异步:
1、如果是合成事件中的回调, executionContext |= DiscreteEventContext, 所以不会进入, 最终表现出异步
2、concurrent 模式下都为异步
演示示例
export default class App extends React.Component {
state = {
count: 0
};
changeState = () => {
const newCount = this.state.count + 1;
this.setState({
count: this.state.count + 1
});
if (newCount === this.state.count) {
console.log("同步执行render");
} else {
console.log("异步执行render");
}
};
changeState2 = () => {
const newCount = this.state.count + 1;
Promise.resolve().then(() => {
this.setState({
count: this.state.count + 1
});
if (newCount === this.state.count) {
console.log("同步执行render");
} else {
console.log("异步执行render");
}
});
};
render() {
return (
<div>
<p>当前count={this.state.count}</p>
<button onClick={this.changeState}>异步+1</button>
<button onClick={this.changeState2}>同步+1</button>
</div>
);
}
}
在 concurrent 模式下, 相同的代码则都为异步 render:
React中key的作用
在 react 组件开发的过程中, key是一个常用的属性值, 多用于列表开发. 本文从源码的角度, 分析key在react内部是如何使用的, key是否可以省略.
ReactElement 对象
我们在编程时直接书写的jsx代码, 实际上是会被编译成 ReactElement 对象, 所以key是ReactElement对象的一个属性.
构造函数
在把jsx转换成ReactElement对象的语法时, 有一个兼容问题. 会根据编译器的不同策略, 编译成 2 种方案.
1、最新的转译策略: 会将jsx语法的代码, 转译成jsx()函数包裹
jsx函数: 只保留与key相关的代码(其余源码本节不讨论)
/**
* https://github.com/reactjs/rfcs/pull/107
* @param {*} type
* @param {object} props
* @param {string} key
*/
export function jsx(type, config, maybeKey) {
let propName;
// 1. key的默认值是null
let key = null;
// Currently, key can be spread in as a prop. This causes a potential
// issue if key is also explicitly declared (ie. <div {...props} key="Hi" />
// or <div key="Hi" {...props} /> ). We want to deprecate key spread,
// but as an intermediary step, we will use jsxDEV for everything except
// <div {...props} key="Hi" />, because we aren't currently able to tell if
// key is explicitly declared to be undefined or not.
if (maybeKey !== undefined) {
key = '' + maybeKey;
}
if (hasValidKey(config)) {
// 2. 将key转换成字符串
key = '' + config.key;
}
// 3. 将key传入构造函数
return ReactElement(
type,
key,
ref,
undefined,
undefined,
ReactCurrentOwner.current,
props,
);
}
2、传统的转译策略: 会将jsx语法的代码, 转译成React.createElement()函数包裹
React.createElement()函数: 只保留与key相关的代码(其余源码本节不讨论)
/**
* Create and return a new ReactElement of the given type.
* See https://reactjs.org/docs/react-api.html#createelement
*/
export function createElement(type, config, children) {
let propName;
// Reserved names are extracted
const props = {};
let key = null;
let ref = null;
let self = null;
let source = null;
if (config != null) {
if (hasValidKey(config)) {
key = '' + config.key; // key转换成字符串
}
}
return ReactElement(
type,
key,
ref,
self,
source,
ReactCurrentOwner.current,
props,
);
}
可以看到无论采取哪种编译方式, 核心逻辑都是一致的:
1、key的默认值是null
2、如果外界有显式指定的key, 则将key转换成字符串类型.
3、调用ReactElement这个构造函数, 并且将key传入.
// ReactElement的构造函数: 本节就先只关注其中的key属性
const ReactElement = function (type, key, ref, self, source, owner, props) {
const element = {
$typeof: REACT_ELEMENT_TYPE,
type: type,
key: key,
ref: ref,
props: props,
_owner: owner,
};
return element;
};
源码看到这里, 虽然还只是个皮毛, 但是起码知道了key的默认值是null. 所以任何一个reactElement对象, 内部都是有key值的, 只是一般情况下(对于单节点)很少显式去传入一个 key.
Fiber 对象
react的核心运行逻辑, 是一个从输入到输出的过程(回顾reconciler 运作流程). 编程直接操作的jsx是reactElement对象,我们(程序员)的数据模型是jsx, 而react内核的数据模型是fiber树形结构. 所以要深入认识key还需要从fiber的视角继续来看.
fiber对象是在fiber树构造循环过程中构造的, 其构造函数如下:
function FiberNode(
tag: WorkTag,
pendingProps: mixed,
key: null | string,
mode: TypeOfMode,
) {
this.tag = tag;
this.key = key; // 重点: key也是`fiber`对象的一个属性
// ...
this.elementType = null;
this.type = null;
this.stateNode = null;
// ... 省略无关代码
}
可以看到, key也是fiber对象的一个属性. 这里和reactElement的情况有所不同:
1、reactElement中的key是由jsx编译而来, key是由程序员直接控制的(即使是动态生成, 那也是直接控制)
2、fiber对象是由react内核在运行时创建的, 所以fiber.key也是react内核进行设置的, 程序员没有直接控制.
注意: fiber.key是reactElement.key的拷贝, 他们是完全相等的(包括null默认值).
接下来分析fiber创建, 剖析key在这个过程中的具体使用情况.
fiber对象的创建发生在fiber树构造循环阶段中, 具体来讲, 是在reconcileChildren调和函数中进行创建.
reconcileChildren 调和函数
reconcileChildren是react中的一个明星函数, 最热点的问题就是diff算法原理, 事实上, key的作用完全就是为了diff算法服务的.
注意: 本节只分析 key 相关的逻辑, 对于调和函数的算法原理, 请回顾算法章节React 算法之调和算法
调和函数源码(本节示例, 只摘取了部分代码):
function ChildReconciler(shouldTrackSideEffects) {
function reconcileChildFibers(
returnFiber: Fiber,
currentFirstChild: Fiber | null,
newChild: any,
lanes: Lanes,
): Fiber | null {
// Handle object types
const isObject = typeof newChild === 'object' && newChild !== null;
if (isObject) {
switch (newChild.$typeof) {
case REACT_ELEMENT_TYPE:
// newChild是单节点
return placeSingleChild(
reconcileSingleElement(
returnFiber,
currentFirstChild,
newChild,
lanes,
),
);
}
}
// newChild是多节点
if (isArray(newChild)) {
return reconcileChildrenArray(
returnFiber,
currentFirstChild,
newChild,
lanes,
);
}
// ...
}
return reconcileChildFibers;
}
单节点
这里先看单节点的情况reconcileSingleElement(只保留与key有关的逻辑):
function reconcileSingleElement(
returnFiber: Fiber,
currentFirstChild: Fiber | null,
element: ReactElement,
lanes: Lanes,
): Fiber {
const key = element.key;
let child = currentFirstChild;
while (child !== null) {
//重点1: key是单节点是否复用的第一判断条件
if (child.key === key) {
switch (child.tag) {
default: {
if (child.elementType === element.type) {
// 第二判断条件
deleteRemainingChildren(returnFiber, child.sibling);
// 节点复用: 调用useFiber
const existing = useFiber(child, element.props);
existing.ref = coerceRef(returnFiber, child, element);
existing.return = returnFiber;
return existing;
}
break;
}
}
// Didn't match.
deleteRemainingChildren(returnFiber, child);
break;
}
child = child.sibling;
}
// 重点2: fiber节点创建, `key`是随着`element`对象被传入`fiber`的构造函数
const created = createFiberFromElement(element, returnFiber.mode, lanes);
created.ref = coerceRef(returnFiber, currentFirstChild, element);
created.return = returnFiber;
return created;
}
可以看到, 对于单节点来讲, 有 2 个重点:
1、key是单节点是否复用的第一判断条件(第二判断条件是type是否改变).
- 如果key不同, 其他条件是完全不看的
2、在新建节点时, key随着element对象被传入fiber的构造函数.
所以到这里才是key的最核心作用, 是调和函数中, 针对单节点是否可以复用的第一判断条件.
对于单节点来讲, key是可以省略的, react内部会设置成默认值null. 在进行diff时, 由于null===null为true, 前后render的key是一致的, 可以进行复用比较.
如果单节点显式设置了key, 且两次render时的key如果不一致, 则无法复用.
多节点
继续查看多节点相关的逻辑:
function reconcileChildrenArray(
returnFiber: Fiber,
currentFirstChild: Fiber | null,
newChildren: Array<*>,
lanes: Lanes,
): Fiber | null {
if (__DEV__) {
// First, validate keys.
let knownKeys = null;
for (let i = 0; i < newChildren.length; i++) {
const child = newChildren[i];
// 1. 在dev环境下, 执行warnOnInvalidKey.
// - 如果没有设置key, 会警告提示, 希望能显式设置key
// - 如果key重复, 会错误提示.
knownKeys = warnOnInvalidKey(child, knownKeys, returnFiber);
}
}
let resultingFirstChild: Fiber | null = null;
let previousNewFiber: Fiber | null = null;
let oldFiber = currentFirstChild;
let lastPlacedIndex = 0;
let newIdx = 0;
let nextOldFiber = null;
// 第一次循环: 只会在更新阶段发生
for (; oldFiber !== null && newIdx < newChildren.length; newIdx++) {
if (oldFiber.index > newIdx) {
nextOldFiber = oldFiber;
oldFiber = null;
} else {
nextOldFiber = oldFiber.sibling;
}
// 1. 调用updateSlot, 处理公共序列中的fiber
const newFiber = updateSlot(
returnFiber,
oldFiber,
newChildren[newIdx],
lanes,
);
if (newFiber === null) {
// 如果无法复用, 则退出公共序列的遍历
if (oldFiber === null) {
oldFiber = nextOldFiber;
}
break;
}
}
// 第二次循环
if (oldFiber === null) {
for (; newIdx < newChildren.length; newIdx++) {
// 2. 调用createChild直接创建新fiber
const newFiber = createChild(returnFiber, newChildren[newIdx], lanes);
}
return resultingFirstChild;
}
for (; newIdx < newChildren.length; newIdx++) {
// 3. 调用updateFromMap处理非公共序列中的fiber
const newFiber = updateFromMap(
existingChildren,
returnFiber,
newIdx,
newChildren[newIdx],
lanes,
);
}
return resultingFirstChild;
}
在reconcileChildrenArray中, 有 3 处调用与fiber有关(当然顺便就和key有关了), 它们分别是:
1、updateSlot
function updateSlot(
returnFiber: Fiber,
oldFiber: Fiber | null,
newChild: any,
lanes: Lanes,
): Fiber | null {
const key = oldFiber !== null ? oldFiber.key : null;
if (typeof newChild === 'object' && newChild !== null) {
switch (newChild.$typeof) {
case REACT_ELEMENT_TYPE: {
//重点: key用于是否复用的第一判断条件
if (newChild.key === key) {
return updateElement(returnFiber, oldFiber, newChild, lanes);
} else {
return null;
}
}
}
}
return null;
}
2、createChild
function createChild(
returnFiber: Fiber,
newChild: any,
lanes: Lanes,
): Fiber | null {
if (typeof newChild === 'object' && newChild !== null) {
switch (newChild.$typeof) {
case REACT_ELEMENT_TYPE: {
// 重点: 调用构造函数进行创建
const created = createFiberFromElement(
newChild,
returnFiber.mode,
lanes,
);
return created;
}
}
}
return null;
}
3、updateFromMap
function updateFromMap(
existingChildren: Map<string | number, Fiber>,
returnFiber: Fiber,
newIdx: number,
newChild: any,
lanes: Lanes,
): Fiber | null {
if (typeof newChild === 'object' && newChild !== null) {
switch (newChild.$typeof) {
case REACT_ELEMENT_TYPE: {
//重点: key用于是否复用的第一判断条件
const matchedFiber =
existingChildren.get(
newChild.key === null ? newIdx : newChild.key,
) || null;
return updateElement(returnFiber, matchedFiber, newChild, lanes);
}
}
return null;
}
}
针对多节点的diff算法可以分为 3 步骤(请回顾算法章节React 算法之调和算法):
1、第一次循环: 比较公共序列
- 从左到右逐一遍历, 遇到一个无法复用的节点则退出循环.
2、第二次循环: 比较非公共序列
-
在第一次循环的基础上, 如果oldFiber队列遍历完了, 证明newChildren队列中剩余的对象全部都是新增.
-
此时继续遍历剩余的newChildren队列即可, 没有额外的diff比较.
-
在第一次循环的基础上, 如果oldFiber队列没有遍历完, 需要将oldFiber队列中剩余的对象都添加到一个map集合中, 以oldFiber.key作为键.
-
此时则在遍历剩余的newChildren队列时, 需要用newChild.key到map集合中进行查找, 如果匹配上了, 就将oldFiber从map中取出来, 同newChild进行diff比较.
3、清理工作
- 在第二次循环结束后, 如果map集合中还有剩余的oldFiber,则可以证明这些oldFiber都是被删除的节点, 需要打上删除标记.
通过回顾diff算法的原理, 可以得到key在多节点情况下的特性:
1、新队列newChildren中的每一个对象(即reactElement对象)都需要同旧队列oldFiber中有相同key值的对象(即oldFiber对象)进行是否可复用的比较. key就是新旧对象能够对应起来的唯一标识.
2、如果省略key或者直接使用列表index作为key, 表现是一样的(key=null时, 会采用index代替key进行比较). 在新旧对象比较时, 只能按照index顺序进行比较, 复用的成功率大大降低, 大列表会出现性能问题.
-
例如一个排序的场景: oldFiber队列有 100 个, newChildren队列有 100 个(但是打乱了顺序). 由于没有设置key, 就会导致newChildren中的第 n 个必然要和oldFiber队列中的第 n 个进行比较, 这时它们的key完全一致(都是null), 由于顺序变了导致props不同, 所以新的fiber完全要走更新逻辑(理论上比新创建一个的性能还要耗).
-
同样是排序场景可以出现的 bug: 上面的场景只是性能差(又不是不能用), key使用不当还会造成bug
-
还是上述排序场景, 只是列表中的每一个item内部又是一个组件, 且其中某一个item使用了局部状态(比如class组件里面的state). 当第二次render时, fiber对象不会delete只会update导致新组件的state还沿用了上一次相同位置的旧组件的state, 造成了状态混乱.
在react中key是服务于diff算法, 它的默认值是null, 在diff算法过程中, 新旧节点是否可以复用, 首先就会判定key是否相同, 其后才会进行其他条件的判定. 在源码中, 针对多节点(即列表组件)如果直接将key设置成index和不设置任何值的处理方案是一样的, 如果使用不当, 轻则造成性能损耗, 重则引起状态混乱造成 bug.