页面首屏性能优化
背景
页面性能一般可以分为两类,一类是首屏性能,另一类是运行时性能。前者衡量的是页面从加载开始到可以稳定交互的性能情况,后者衡量的是页面稳定后到页面关闭的性能情况。
本文主要讨论首屏性能。
在做性能优化这个事项之前,我们得先知道我们做的这个事情是否有价值。
用户体验金字塔
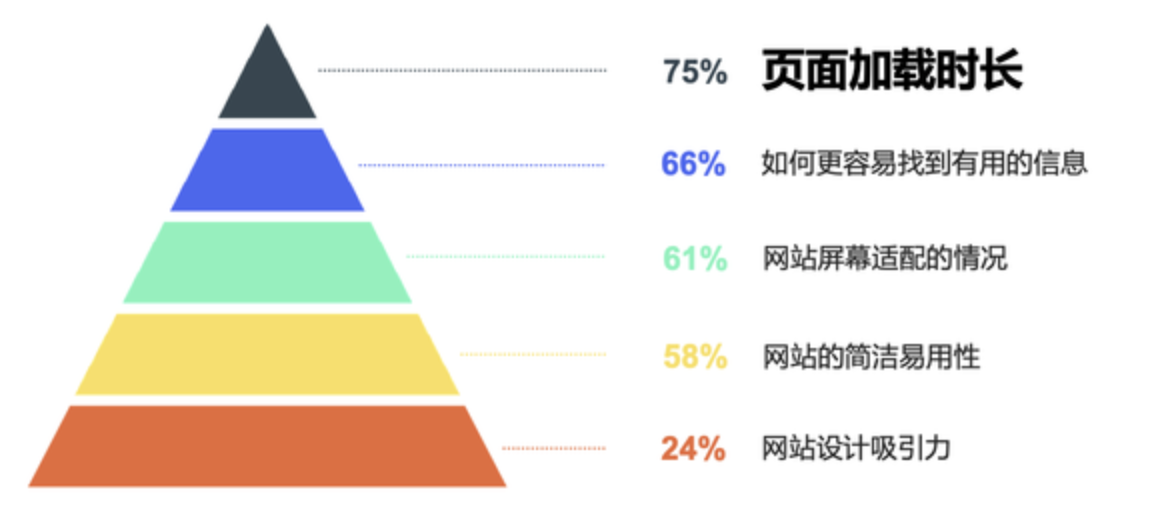
先来看一个用户体验金字塔,大家觉得对用户体验影响最大的内容是啥?
页面的颜色? 页面的信息?其实都不是,肯定是性能优化相关的内容,因为本篇文章的主题就是性能优化。
从 Google I/O 大会上,能看到对用户体验造成最大影响的就是页面的加载时长。这个其实也很好理解,你的页面做的非常精美,但是前置的流程是需要用户能看到这个页面。
性能优化业务价值
页面加载时长对用户体验有影响,那么对业务数据是否有影响呢?
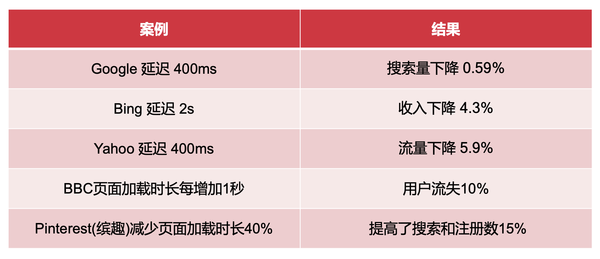
答案是肯定的,页面加载时长越长,越容易造成用户流失,超过 5s,90% 的用户就会离开。
可以想象一下,你手上的业务如果页面加载时长缩短几百毫秒,甚至更多,是不是对业务也会起到正向的作用呢?
性能指标
测量页面的加载性能是一项艰难的任务。因此 Google Developers 正和社区一起致力于建立渐进式网页指标(Progressive Web Metrics,简称 PWM’s)。
PWM’s 都是些什么,我们为什么需要它们?
性能指标历史
先来讲一点关于浏览器指标的历史。
此前我们有两个主要的点(事件)来测量性能:
-
DOMContentLoaded — 页面加载完成但脚本文件刚刚开始执行时触发(这里指初始的 HTML 文档加载并解析完成,但不包括样式表、图像和子框架的加载完成)。
-
load 事件在页面完全加载后触发,此时用户已经可以使用页面或应用。
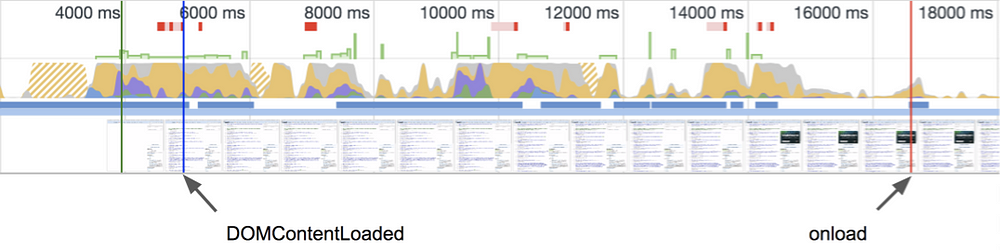
举个例子,下面是我们试验页面的跟踪时间轴(Chrome 的开发者工具可以帮助我们用蓝色和红色的垂直线来标记那些点),就可以明白为什么这些指标不是那么有用了。
-
DOMContentLoaded 的问题在于不包含解析和执行 JavaScript 的时间,如果脚本文件太大,那么这个时间就会非常长。比如移动设备,在 3G 网络的限制下测量跟踪时间轴,就会发现要花费差不多十秒才能到达 load 点。
-
另一方面,load 事件太晚触发,就无法分析出页面的性能瓶颈。
所以我们能否依赖这些指标?它们到底给我们提供了什么信息?
而且最主要的问题是,从页面开始加载直至加载完成,用户对这个过程的感知如何?
下面是试验页面的柱状图,其 X 轴展示了加载时长,Y 轴展示了实际加载时长在特定时间区间里的用户的相对数量,你就可以明白不是所有用户的体验到的加载时间都会小于两秒。
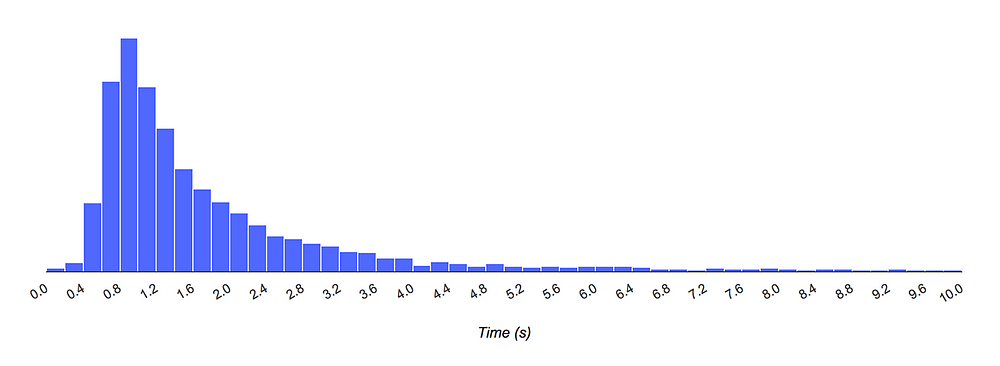
因此在我们的试验页面里,17 秒左右的 load 事件在了解用户加载感知方面是没有什么价值的。用户在这 17 秒里到底看到了什么?白屏?加载了一半的页面?页面假死(用户无法点击输入框或滚动)?如果这些问题有答案的话:
-
可以改善用户体验
-
给应用带来更多的用户
-
增加产品所有者的利益(用户、消费者、钱)
如果 DOMContentLoaded 或者 load 指标不能回答这些问题,那么什么指标可以回答?
Performance Timing API
浏览器为我们提供了原生的 Timing API,并且现在有两个标准,下面来分别介绍一下这两个标准。
Navigation Timing Level 1
1、window.performance.timing
在没有这个API之前,如果我们要收集完全加载页面所需的时间,可能需要这么做:
<html>
<head>
<script type="text/javascript">
var start = new Date().getTime();
function onLoad() {
var now = new Date().getTime();
var latency = now - start;
alert("page loading time: " + latency);
}
</script>
</head>
<body onload="onLoad()">
<!- Main page body goes from here. -->
</body>
</html>
上面的脚本计算了 head 中的第一个 js脚本执行后加载页面所需的时间,但它没有给出任何关于从服务器获取页面所需的时间,或是页面初始化生命周期的信息。
为了准确可靠的获取可用于衡量网站性能的数据,window.performance.timing 可以获取以前难以获取的数据,例如卸载前一页所需的时间、域查找所需的时间、执行窗口加载处理程序所花费的总时间等。下面这张图展示了window.performance.timing的各个属性,以及其对应的各个页面阶段。
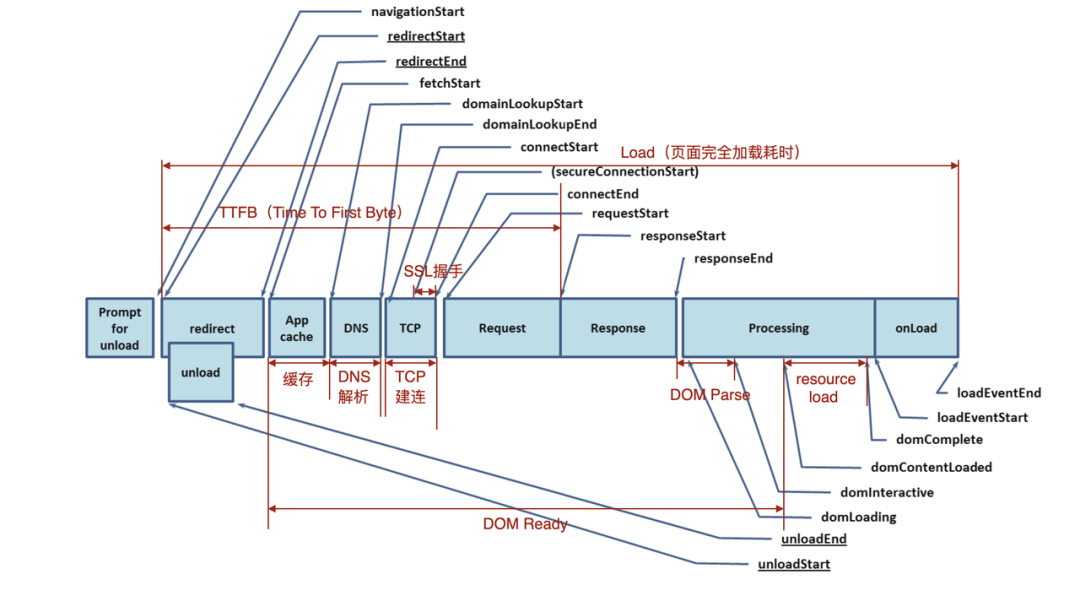
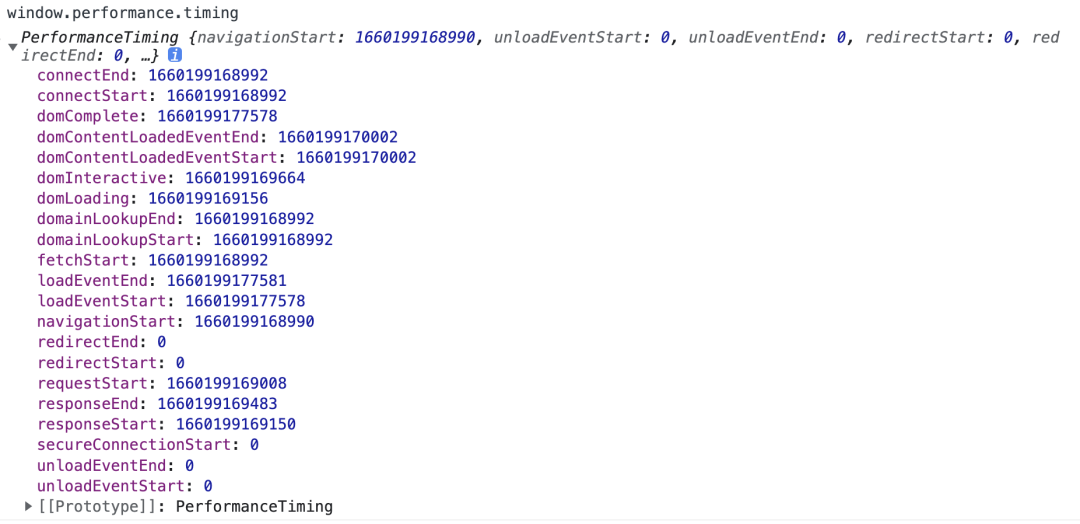
由此我们可以计算旧文档的卸载、重定向、应用缓存、DNS lookup、TCP 握手、HTTP 请求处理、HTTP 响应处理、DOM 处理、document加载完成等页面性能打点。具体可以参考navigation-timing W3C的规范。
2、window.performance.navigation
PerformanceNavigation接口呈现了如何导航到当前文档的信息。用来描述页面加载相关的操作,共有两个属性type和redirectCount。
Navigation Timing Level 2
Level 2标准废弃了level 1的timing和navigation这两个接口,取而代之的是定义了 PerformanceNavigationTiming 对象,该对象可以这样获取:
window.performance.getEntriesByType("navigation")[0];
Level 1接口的属性值是基于 JavaScript 的 Date 对象,而Level 2 使用 High Resolution Time 解决了时间精度的问题。并且Level 2的Navigation Timing API也更新了Processing Model,扩展了PerformanceResourceTiming 接口,可以获取更加详细的打点信息。
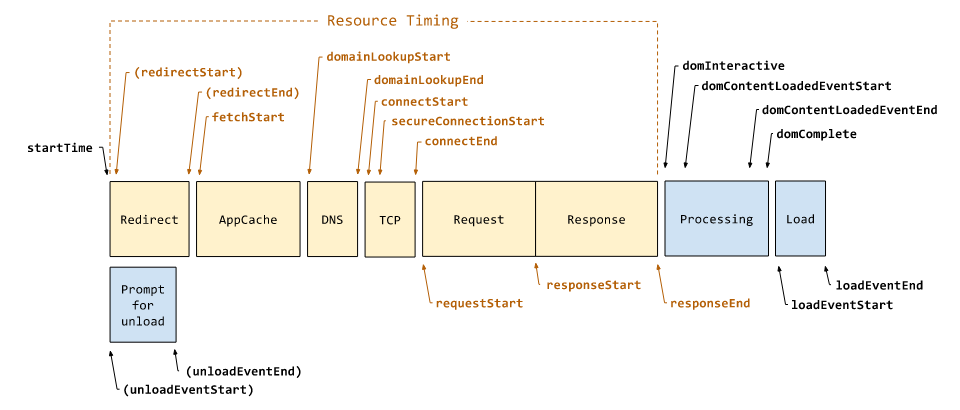
从上图中我们可以看出Document Processing是 Navigation Timing 独有的,后面我们也会介绍Resource Timing。整体而言 Level 2 标准更加的全面,把Web Performance Timing分成了各个 Performance Metric,看起来一目了然。
介绍完这两个Performance Navigation Timing API,我们顺便再来看一下其余几个主要的Performance Timing API:Resource Timing API 、 Paint Timing API 和 Long Task Timing API,以及如何使用PerformanceObserver异步获取性能数据。
1、window.performance.getEntriesByType(“resource”)
PerformanceResourceTiming 接口支持检索和分析有关应用程序资源加载的详细网络计时数据,我看可以此来确定获取特定资源(例如 XMLHttpRequest、图像或脚本)所需的时间长度
2、window.performance.getEntriesByType(“paint”)
PerformancePaintTiming 接口在网页构建期间提供有关“绘制”(也称为“渲染”)操作的耗时信息。
-
first-paint:从导航开始到浏览器将第一个像素渲染到屏幕的时间(白屏耗时)。
-
first-contentful-paint: 浏览器渲染来自 DOM 的第一位内容的时间(FCP)。
3、PerformanceLongTaskTiming
Long Tasks API 可用于了解浏览器的主线程何时被阻塞了过长时间从而影响了帧速率或输入延迟。目前,API 将报告任何执行时间超过 50 毫秒的任务。
4、使用 PerformanceObserver 监听以上介绍的性能指标
// Instantiate the performance observer
var perfObserver = new PerformanceObserver(function(list, obj) {
// Get all the resource entries collected so far
// (You can also use getEntriesByType/getEntriesByName here)
var entries = list.getEntries();
// Iterate over entries
});
// Run the observer
perfObserver.observe({
// Polls Timing entries
entryTypes: ["navigation", "resource", "longtask"]
});
PerformanceObserver 可以被动地订阅与性能相关的事件,也就是说这个 API 通常不会干扰页面主线程的性能,因为它的回调通常在空闲期间触发。默认情况下,PerformanceObserver 对象只能在条目出现时观察它们。如果想延迟加载性能分析代码(不阻止更高优先级的资源),我们需要这么做:
// Run the observer
perfObserver.observe({
// Polls for Navigation and Resource Timing entries
entryTypes: ["navigation", "resource"],
// set the buffered flag to true
buffered: true,
});
设置buffered 为true,浏览器将在第一次调用 PerformanceObserver 回调时返回其性能条目 缓冲区中的历史条目。
渐进式网页指标
PWM’s(Progressive Web Metrics,简称 PWM’s)是一组用来帮助检测性能瓶颈的指标。除开 load 和 DOMContentLoaded,PWM’s 给开发者提供了页面加载过程中更多更详细的信息。
下面让我们用试验页面的跟踪时间轴来探究一下 PWM’s,并尝试弄明白每个指标的意思。
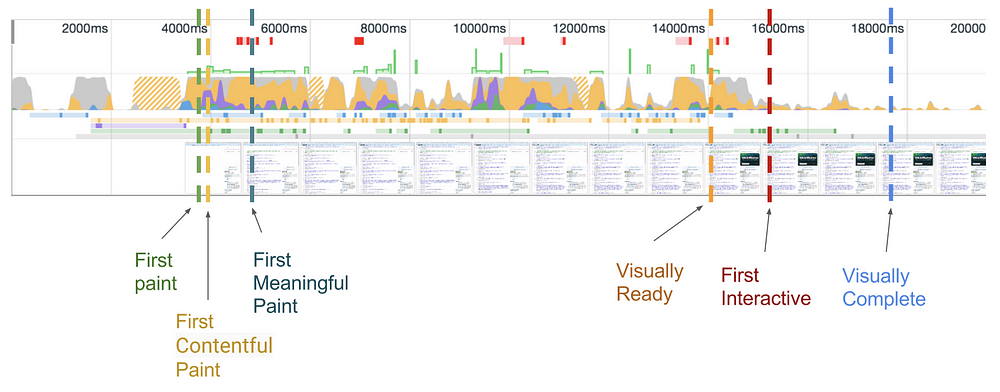
FP
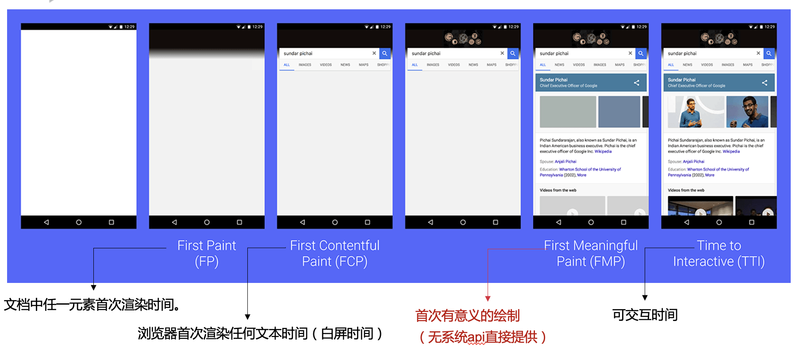
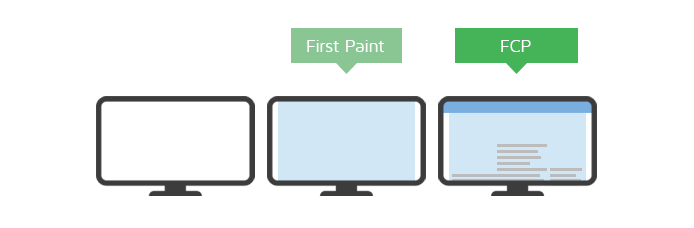
First Paint,首次渲染的时间点。FP 时间点之前,用户看到的都是没有任何内容的白色屏幕。

FP 事件在 Chromium 中 Graphic Layer 进行绘制的时候触发,而不是文本、图片或 Canvas 绘制的时候,但它也给出了一些开发者尝试使用的信息。
然而它并不是标准指标,所以测量就变得非常棘手。因此用到了一些不同的 “取巧” 技术,比如:
- 使用 requestAnimationFrame
- 捕捉 CSS 资源加载
- 甚至使用 DOMContentLoaded 和 load 事件(它们的问题之前已经讲过)
尽管做出了这些努力,但它实际并没有太大的价值,因为文本、图片和 Canvas 可能在 FP 事件触发一段时间后才会进行绘制,而这个时间间隔会受到诸如页面体积、CSS 或 JavaScript 资源大小等性能瓶颈所影响。
这个指标不属于 PWM 的一部分,但它对于理解下面将要讲到的指标很有帮助。
所以需要其他一些指标来表示真实的内容绘制。
FCP
First Contentful Paint,首次有实际内容渲染的时间点。和白屏是不一样的,它可以是文本的首次绘制,或者 SVG 的首次出现,或者 Canvas 的首次绘制等等。
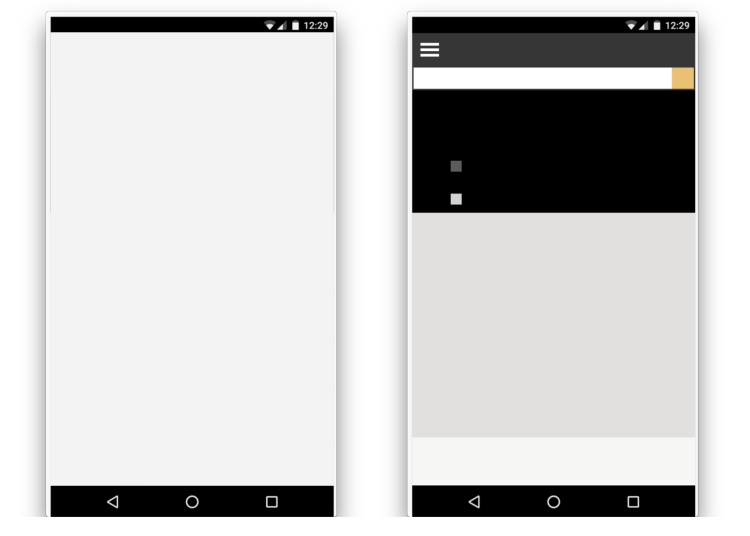
继续看一下 Chromium,FCP 事件在文本(正在等待字体文件加载的文本不计算在内)、图片、Canvas 等元素绘制时被触发。结果表明,FP 和 FCP 的时间差异可能从几毫秒到几秒不等。这个差别甚至可以从上面的图片中看出来。这就是为什么用一个指标来表示真实的首次内容绘制是有价值的。
FCP 指标如何对开发者产生价值?
如果首次内容绘制前耗时太长,那么:
- 你的网络连接可能有性能问题
- 资源太过庞大(如 index.html),传输它们消耗太多时间
采集 FP && FCP
FP 和 FCP 可以通过浏览器提供的 API 直接获取,所以采集原理并不复杂。如果页面已经完成了首次绘制和首次内容绘制,可以使用下面的方式直接获取。
window.performance.getEntriesByType('paint')
// or
window.performance.getEntriesByName('first-paint')
window.performance.getEntriesByName('first-contentful-paint')
但是如果页面还没有开始首次绘制,就需要通过监听获取。
const observer = new PerformanceObserver(function(list) {
const perfEntries = list.getEntries();
for (const perfEntry of perfEntries) {
// Process entries
// report back for analytics and monitoring
// ...
}
});
// register observer for paint timing notifications
observer.observe({entryTypes: ["paint"]});
FMP
First Meaningful Paint,完成首次有意义内容绘制的时间点。
有意义内容是什么?
当
- 博客的标题和文本
- 搜索引擎的搜索文本
- 电子商务产品中重要的图片
展示的时候。
但如果展示的是
- 下拉菜单或类似的东西
- 无样式内容闪烁(FOUC)
- 导航条或页面标题
则不计算在有意义内容之内。
FMP = 最大布局变化时的绘制
基于 Chromium 的实现,这个绘制是使用 LayoutAnalyzer 进行计算的,它会收集所有的布局变化,得到布局发生最大变化时的时间。而这个时间就是 FMP。
FMP 指标如何对开发者产生帮助?
如果有意义内容很久都没有展示出来,那么:
- 太多资源(图片、样式、字体、JavaScript)有较高的加载优先级,因此,它们阻塞了 FMP
采集 FMP
与 FP / FCP / LCP 相比, FMP 的采集相对比较复杂,它需要通过算法计算得出,而业界并没有统一的算法。
因为算法的通用性不够高,探测结果也不理想,所以 Google 已经废弃了 FMP,转而采用含义更清晰的 LCP。
虽然如此,但网上仍然有很多开源的解决方案,毕竟 Google 是要找出一套通用方案,但我们并不需要通用。
成为FMP元素的条件
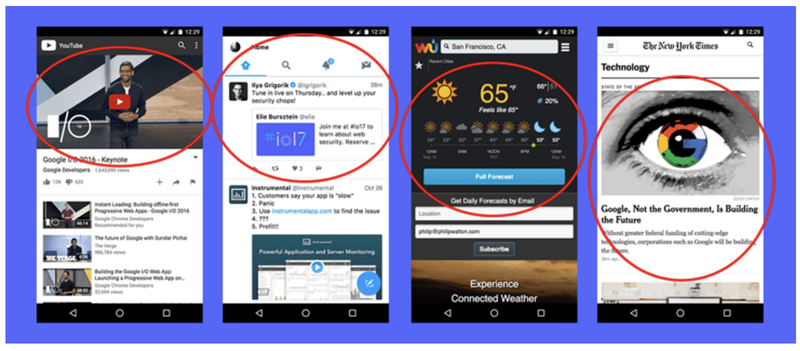
首屏中,怎么样的元素才可以成为主要元素呢? 看截图,主要是一些体积大,屏幕占比大,多是一些图片,视频,canvas等元素。这些元素加载完成的时间则可以近似的认为 FMP 的时间。
具体算法
首先,通过 MutationObserver 监听每一次页面整体的 DOM 变化,触发 MutationObserver 的回调。
然后在回调中,为每个 HTML 元素(不包括忽略的元素)打上标记,记录元素是在哪一次回调中增加的,并且用数组记录每一次的回调时间。
const IGNORE_TAG_SET = ['SCRIPT', 'STYLE', 'META', 'HEAD', 'LINK'];
const WW = window.innerWidth;
const WH = window.innerHeight;
const FMP_ATTRIBUTE = '_ts';
class FMP {
private cacheTrees: TypeTree[];
private callbackCount: number;
private observer: MutationObserver;
public constructor() {
this.cacheTrees = []; // 缓存每次更新的DOM元素
this.callbackCount = 0; // DOM 变化的计数
// 开始监控DOM的变化
this.observer = new MutationObserver((): void => {
const mutationsList = [];
// 从 body 元素开始遍历
document.body && this.doTag(document.body, this.callbackCount++, mutationsList);
this.cacheTrees.push({
ts: performance.now(),
children: mutationsList
});
// console.log("mutationsList", performance.now(), mutationsList);
});
this.observer.observe(document, {
childList: true, // 监控子元素
subtree: true // 监控后代元素
});
}
/**
* 为 HTML 元素打标记,记录是哪一次的 DOM 更新
*/
private doTag(target: Element, callbackCount: number, mutationsList: Element[]): void {
const childrenLen = target.children ? target.children.length : 0;
// 结束递归
if(childrenLen === 0)
return;
for (let children = target.children, i = childrenLen - 1; i >= 0; i--) {
const child = children[i];
const tagName = child.tagName;
if (child.getAttribute(FMP_ATTRIBUTE) === null &&
IGNORE_TAG_SET.indexOf(tagName) === -1 // 过滤掉忽略的元素
) {
child.setAttribute(FMP_ATTRIBUTE, callbackCount.toString());
mutationsList.push(child); // 记录更新的元素
}
// 继续递归
this.doTag(child, callbackCount, mutationsList);
}
}
}
接着在触发 load 事件时,先过滤掉首屏外和没有高度的元素,以及元素列表之间有包括关系的祖先元素,再计算各次变化时剩余元素的总分。
一开始是只记录没有后代的元素,但是后面发现有时候 DOM 变化时,没有这类元素。
/**
* 是否超出屏幕外
*/
private isOutScreen(node: Element): boolean {
const { left, top } = node.getBoundingClientRect();
return WH < top || WW < left;
}
/**
* 读取 FMP 信息
*/
public getFMP(): TypeMaxElement {
this.observer.disconnect(); // 停止监听
const maxObj = {
score: -1, //高分
elements: [], // 首屏元素
ts: 0 // DOM变化时的时间戳
};
// 遍历DOM数组,并计算它们的得分
this.cacheTrees.forEach((tree): void => {
let score = 0;
// 首屏内的元素
let firstScreenElements = [];
tree.children.forEach((node): void => {
// 只记录元素
if(node.nodeType !== 1 || IGNORE_TAG_SET.indexOf(node.tagName) >= 0) {
return;
}
const { height } = node.getBoundingClientRect();
// 过滤高度为 0,在首屏外的元素
if(height > 0 && !this.isOutScreen(node)) {
firstScreenElements.push(node);
}
});
// 若首屏中的一个元素是另一个元素的后代,则过滤掉该祖先元素
firstScreenElements = firstScreenElements.filter((node): boolean => {
// 只要找到一次包含关系,就过滤掉
const notFind = !firstScreenElements.some((item ): boolean=> node !== item && node.contains(item));
// 计算总得分
if(notFind) {
score += this.caculateScore(node);
}
return notFind;
});
// 得到高值
if(maxObj.score < score) {
maxObj.score = score;
maxObj.elements = firstScreenElements;
maxObj.ts = tree.ts;
}
});
// 在得分高的首屏元素中,找出长的耗时
return this.getElementMaxTimeConsuming(maxObj.elements, maxObj.ts);
}
不同类型的元素,权重也是不同的,权重越高,对页面呈现的影响也越大。
在 caculateScore() 函数中,通过getComputedStyle得到 CSS 类中的背景图属性,注意,node.style 只能得到内联样式中的属性。
const TAG_WEIGHT_MAP = {
SVG: 2,
IMG: 2,
CANVAS: 4,
OBJECT: 4,
EMBED: 4,
VIDEO: 4
};
/**
* 计算元素分值
*/
private caculateScore(node: Element): number {
const { width, height } = node.getBoundingClientRect();
let weight = TAG_WEIGHT_MAP[node.tagName] || 1;
if (weight === 1 &&
window.getComputedStyle(node)['background-image'] && // 读取CSS样式中的背景图属性
window.getComputedStyle(node)['background-image'] !== 'initial'
) {
weight = TAG_WEIGHT_MAP['IMG']; //将有图像背景的普通元素 权重设置为img
}
return width * height * weight;
}
后在得到分数大值后,从这些元素中挑选出长的耗时,作为 FMP。
/**
* 读取首屏内元素的长耗时
*/
private getElementMaxTimeConsuming(elements: Element[], observerTime: number): TypeMaxElement {
// 记录静态资源的响应结束时间
const resources = {};
// 遍历静态资源的时间信息
performance.getEntries().forEach((item: PerformanceResourceTiming): void => {
resources[item.name] = item.responseEnd;
});
const maxObj: TypeMaxElement = {
ts: observerTime,
element: ''
};
elements.forEach((node: Element): void => {
const stage = node.getAttribute(FMP_ATTRIBUTE);
let ts = stage ? this.cacheTrees[stage].ts : 0; // 从缓存中读取时间
switch(node.tagName) {
case 'IMG':
ts = resources[(node as HTMLImageElement).src];
break;
case 'VIDEO':
ts = resources[(node as HTMLVideoElement).src];
!ts && (ts = resources[(node as HTMLVideoElement).poster]); // 读取封面
break;
default: {
// 读取背景图地址
const match = window.getComputedStyle(node)['background-image'].match(/url\(\"(.*?)\"\)/);
if(!match) break;
let src: string;
// 判断是否包含协议
if (match && match[1]) {
src = match[1];
}
if (src.indexOf('http') == -1) {
src = location.protocol + match[1];
}
ts = resources[src];
break;
}
}
// console.log(node, ts)
if(ts > maxObj.ts) {
maxObj.ts = ts;
maxObj.element = node;
}
});
return maxObj;
}
在还未完成 FMP 算法之前,首屏采用的是两种有明显缺陷的计算方式。
-
第一种是算出首屏页面中所有图像都加载完后的时间,这种方法难以覆盖所有场景,例如 CSS 中的背景图、Image 元素等。
-
第二种是自定义首屏时间,也就是自己来控制何时算首屏全部加载好了,虽然相对准确点,但要修改源码。
LCP
Largest Contentful Paint,最大的内容在可视区域内变得可见的时间点。
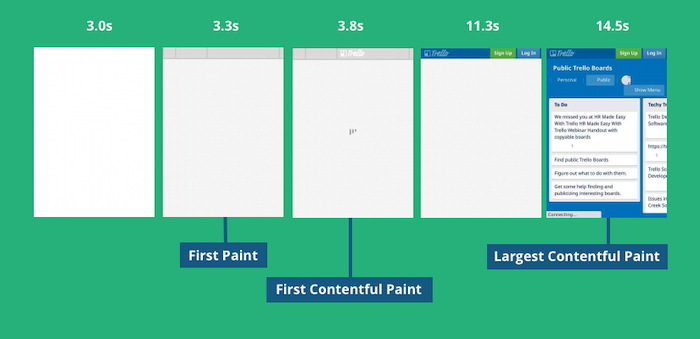
一般情况下,LCP 的时间都会比 FCP 大(如上图所示),除非页面非常简单,FCP 的重要性也比 LCP 低很多。
不过业界有测试得出, LCP 非常近似于 FMP 的时间点,同时 FMP 性能消耗较大,且会因为一些细小的变化导致数值巨大波动,所以推荐使用 LCP。
采集 LCP
LCP 的读取并不需要手动计算,浏览器已经提供了 PerformanceObserver.observe() 方法,如下所示。
/**
* 判断当前宿主环境是否支持 PerformanceObserver
* 并且支持某个特定的类型
*/
private checkSupportPerformanceObserver(type: string): boolean {
if(!(window as any).PerformanceObserver) return false;
const * = (PerformanceObserver as any).supportedEntry*;
// 浏览器兼容判断,不存在或没有关键字
if(!* || *.indexOf(type) === -1) {
return false;
}
return true;
}
/**
* 浏览器 LCP 计算
*/
public observerLCP(): void {
const lcpType = 'largest-contentful-paint';
const isSupport = this.checkSupportPerformanceObserver(lcpType);
// 浏览器兼容判断
if(!isSupport) {
return;
}
const po = new PerformanceObserver((entryList): void=> {
const entries = entryList.getEntries();
const lastEntry = (entries as any)[entries.length - 1] as TypePerformanceEntry;
this.lcp = {
time: rounded(lastEntry.renderTime || lastEntry.loadTime), // 时间取整
url: lastEntry.url, // 资源地址
element: lastEntry.element ? removeQuote(lastEntry.element.outerHTML) : '' // 参照的元素
};
});
// buffered 为 true 表示调用 observe() 之前的也算进来
po.observe({ type: lcpType, buffered: true } as any);
/**
* 当有按键或点击(包括滚动)时,就停止 LCP 的采样
* once 参数是指事件被调用一次后就会被移除
*/
['keydown', 'click'].forEach((type): void => {
window.addEventListener(type, (): void => {
// 断开此观察者的连接
po.disconnect();
}, { once: true, capture: true });
});
entries 是一组 LargestContentfulPaint 类型的对象,它有一个 url 属性,如果记录的元素是个图像,那么会存储其地址。
注册 keydown 和 click 事件是为了停止 LCP 的采样,once 参数会在事件被调用一次后将事件移除。
在 iOS 的 WebView 中,只支持三种类型的 entryType,不包括 largest-contentful-paint,所以加了段浏览器兼容判断。
在页面转移到后台后,得停止 LCP 的计算,因此需要找到隐藏到后台的时间。
let firstHiddenTime = document.visibilityState === 'hidden' ? 0 : Infinity;
// 记录页面隐藏时间 iOS 不会触发 visibilitychange 事件
const onVisibilityChange = (event) => {
// 页面不可见状态
if (lcp && document.visibilityState === 'hidden') {
firstHiddenTime = event.timeStamp;
// 移除事件
document.removeEventListener('visibilitychange', onVisibilityChange, true);
}
}
document.addEventListener('visibilitychange', onVisibilityChange, true);
利用 visibilitychange 事件,就能准确得到隐藏时间,然后在读取 LCP 时,大于这个时间的就直接忽略掉。不过在实践中发现,iOS 的 WebView 并不支持此事件。
注意,largest-contentful-paint 不会计算 iframe 中的元素,返回上一页也不会重新计算。
有个成熟的库:web-vitals,提供了 LCP、FID、CLS、FCP 和 TTFB 指标,对上述所说的特殊场景做了处理,若要了解原理,可以参考其中的计算过程。
LCP 会被一直监控(其监控的元素如下所列),这样会影响结果的准确性。
- img 元素
- 内嵌在 svg 中的 image 元素
- video 元素(使用到封面图像)
- 拥有背景图像的元素(调用 CSS 的 url() 函数)
- 包含文本节点或或行内文本节点的块级元素
如果在等待一段时间,关闭页面时才上报,那么 LCP 将会很长,所以需要选择合适的上报时机,例如 load 事件中。
TTI
Time to Interactive,页面从开始加载到主要子资源完成渲染,并能够快速、可靠地响应用户输入的时间点。
首次可交互发生需满足以下条件:
- FMP 完成
- DOMContentLoaded 事件被触发
- 页面视觉完成度在 85%
首次可交互 - 这个指标可以拆分成两个指标,首次可交互的时间(Time to First Interactive,TTFI)和首次可持续交互的时间(Time to First Consistently Interactive,TTCI)。
拆分的原因在于:
- 定义最小程度的可交互,当 UI 响应良好时满足可交互,但如果响应不好也可以接受
- 当网站完全的、令人愉悦的可交互,并严格遵循 RAIL 的指导原则时
在深入研究前,我想通过解释一些术语以便大家在理解上同步。
长任务
浏览器底层将所有用户输入打包在一个任务里(UI 任务),并将它们放到主线程的一个队列里。除此之外,浏览器还必须解析、编译并执行页面上的 JavaScript 代码(应用任务)。如果每个应用任务要耗费很长时间的话,那么用户输入任务就可能受到阻塞,直到这些应用任务执行完成。因此它就会延迟与页面的交互,页面就会表现出卡顿和延迟。
简单来说,长任务就是指解析、编译或执行 JavaScript 代码块的耗时大于 50 毫秒。
长任务 API 已经在 Chrome 里实现,并用作测量主线程的繁忙程度。
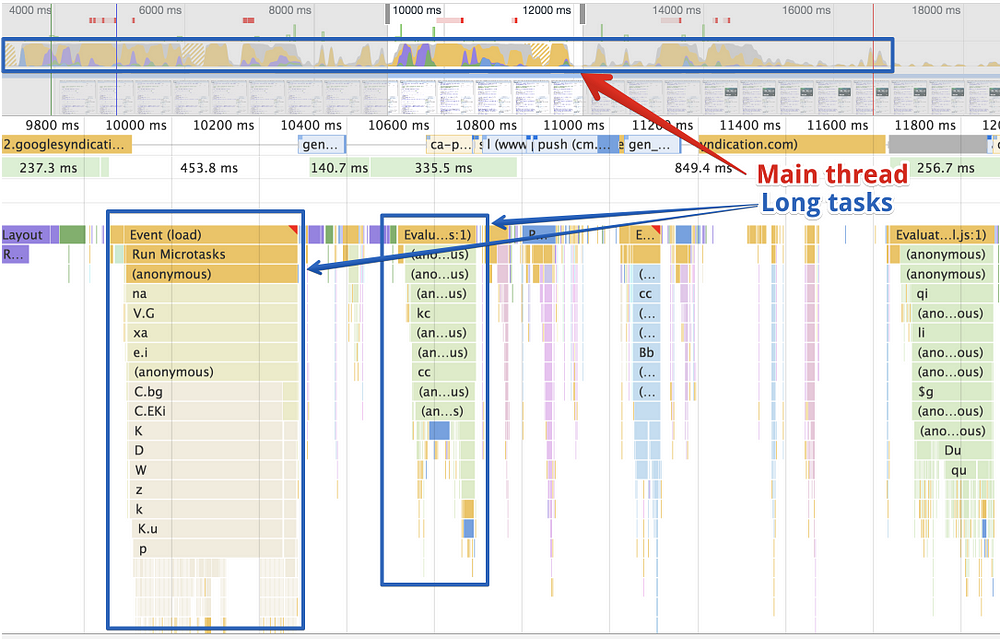
用户会假设页面响应很快,但如果主线程正忙于处理各个长任务,那么就会让用户不满意。
TTCI
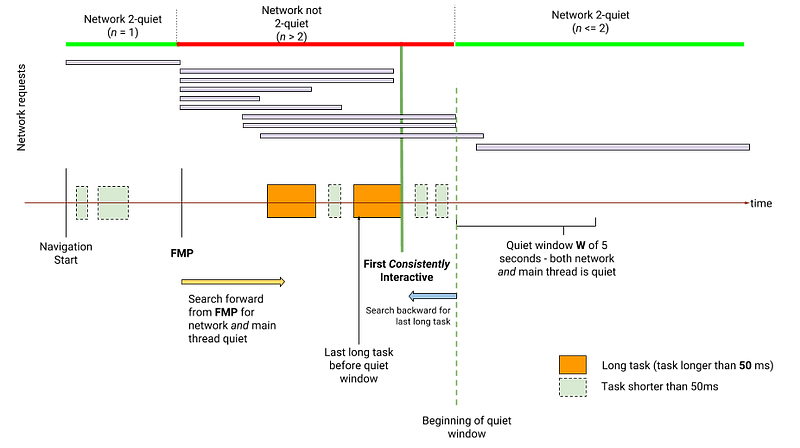
使用逆序分析,从追踪线的尾端开始看,发现页面加载活动保持了 5 秒的安静并且再无更多的长任务执行,得到了一段叫做安静窗口的时期。安静窗口之后的第一个长任务(从结束时间向前开始算)之前的时间点就是 TTCI(这里是将整个时间线反转过来看的,实际表示的是安静窗口前,最接近安静窗口的长任务的结束时间)。
TTFI
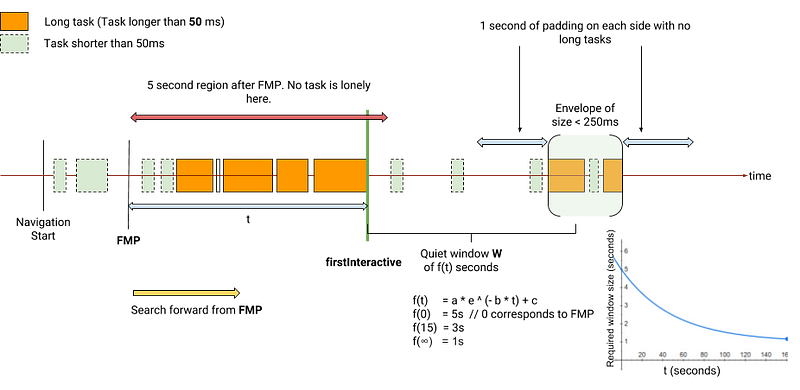
这个指标的定义和 TTCI 有一点不同。我们从头至尾来分析跟踪时间轴。在 FMP 发生后有一个 3 秒的安静窗口。这个时间已经足够说明页面对于用户来说是可交互的。但可能会有独立任务在这个安静窗口期间或之后开始执行,它们可以被忽略。
独立任务 - 将 250ms 中执行的多个任务视为一个任务,当一个任务距离 FMP 很远才执行,且在这个任务前后均有一个 1 秒的安静期,则其为一个“独立任务”。举例来说,这个任务可能是第三方广告或者分析脚本。
有时长于 250 毫秒的“独立任务”会对页面性能有严重的影响。比如检测adblock
TTFI 和 TTCI 指标如何对开发者产生帮助?
当线程在视觉上准备好和首次可交互之间忙碌了很长时间的时候
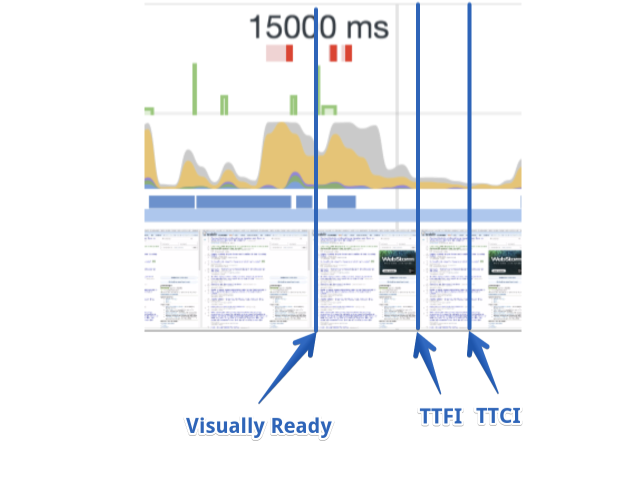
这是其中一个最复杂的瓶颈,并且没有标准方法来修复这类型的问题。它是独立的,而且取决于应用的特定情况。
TBT
Total Blocking Time,页面从 FMP 到 TTI 之间的阻塞时间,一般用来量化主线程在空闲之前的繁忙程度。
TTI 虽然可以衡量页面可以交互的时间点,但是却无法感知这个期间浏览器的繁忙状态。而结合 TBT ,就能帮助理解在加载期间,页面无法响应用户输入的时间有多久。
采集 TTI && TBT
TTI(Time to Interactive)是一个与交互有关的指标,它可测量页面从开始加载到主要子资源完成渲染,并能够快速、可靠地响应用户输入所需的时间。
它的计算规则比较繁琐:
1、先找到 FMP 的时间点。
2、沿时间轴正向搜索时长至少为 5 秒的安静窗口,其中安静窗口的定义为:没有长任务(Long Task)且不超过两个正在处理的网络 GET 请求。
3、沿时间轴反向搜索安静窗口之前的后一个长任务,如果没有找到长任务,则在 FMP 处终止。
4、TTI 是安静窗口之前后一个长任务的结束时间,如果没有找到长任务,则与 FMP 值相同。
下图有助于更直观的了解上述步骤,其中数字与步骤对应,竖的橙色虚线就是 TTI 的时间点。
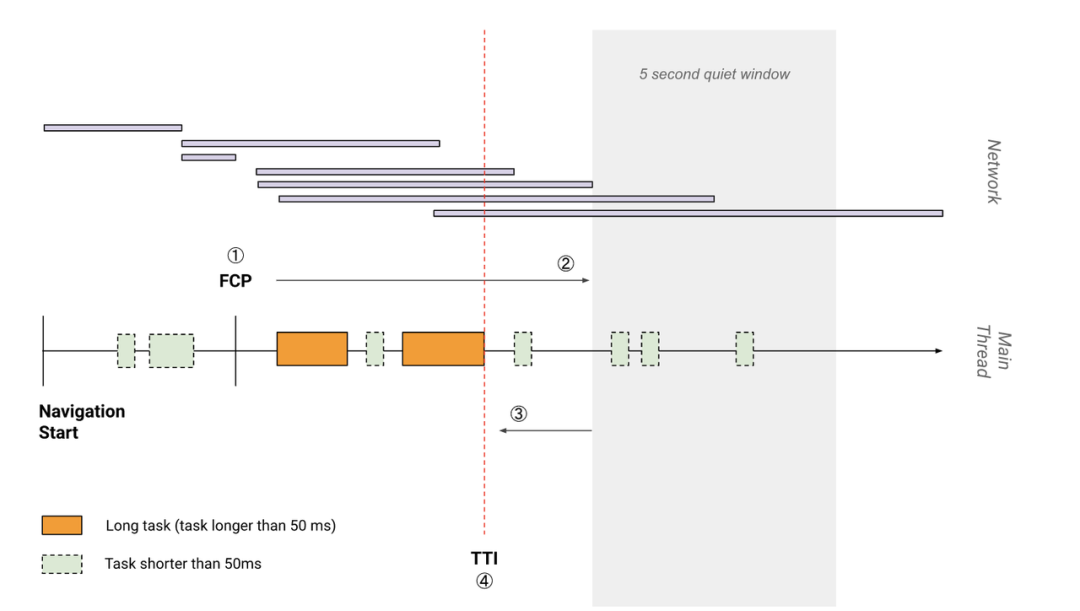
TBT(Total Blocking Time)是指页面从 FMP 到 TTI 之间的阻塞时间,一般用来量化主线程在空闲之前的繁忙程度。
它的计算方式就是取 FMP 和 TTI 之间的所有长任务消耗的时间总和。
阻塞时间是 Long task 中超过 50ms 后的任务耗时。
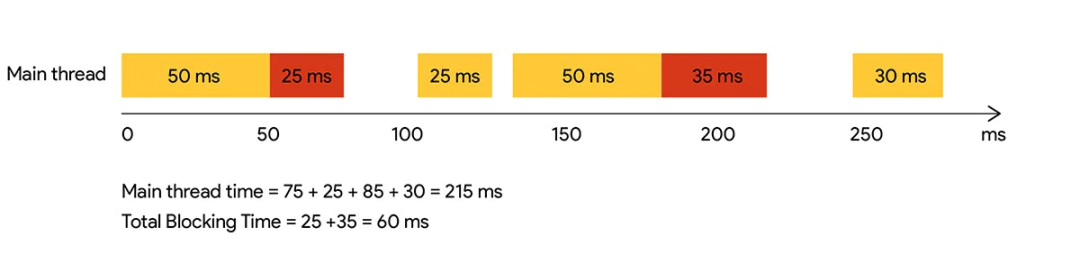
不过网上有些资料认为 TTI 可能会受当前环境的影响而导致测量结果不准确,因此更适合在实验工具中测量,例如 LightHouse、WebPageTest 等
Google 的 TTI Polyfill 库的句话就是不建议在线上搜集 TTI,建议使用 FID。
FID
First Input Delay,用户第一次与页面交互(例如当他们单击链接、点按按钮等操作)直到浏览器对交互作出响应,并且实际能够开始处理事件程序所经过的时间。
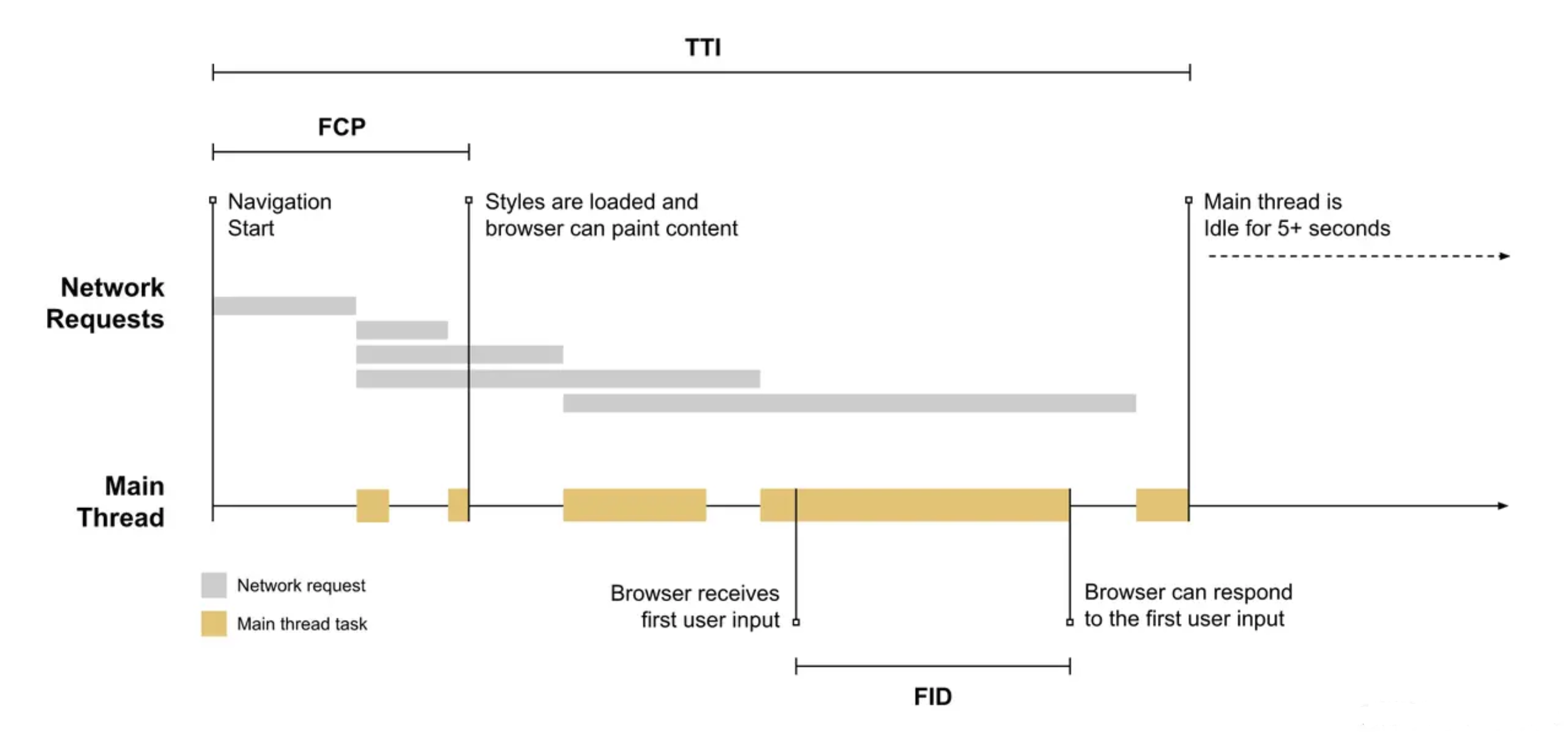
这个指标其实挺好理解,就是看用户交互事件触发到页面响应中间耗时多少,如果其中有长任务发生的话那么势必会造成响应时间变长。推荐响应用户交互在 100ms 以内.
MPFID
Max Potential First Input Delay,记录在页面加载过程中用户和页面进行首次交互操作可能花费的最长时间。
MPFID 是一个虚拟的可能的延迟时间,而FID是用户真实的首次交互的延迟时间。所以一般推荐使用FID,它是用户对页面交互性和响应性的第一印象。良好的第一印象有助于用户建立对整个应用的良好印象。同时在页面加载阶段,资源的处理任务最重,最容易产生输入延迟。
INP
INP(Interaction to Next Paint)是 Google 的一项新指标,用于衡量页面对用户输入的响应速度。
它测量用户交互(如单击或按键)与屏幕的下一次更新之间经过的时间,如下图所示。
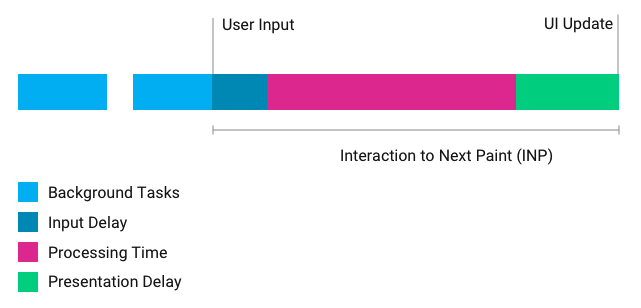
在未来,INP 将会取代 FID,因为 FID 有两个限制:
-
它只考虑用户在页面上的第一次交互。
-
它只测量浏览器开始响应用户输入所需的时间,而不是完成响应所需的时间。
采集 FID && MPFID
FID(First Input Delay)是用户第一次与页面交互(例如点击链接、按钮等操作)到浏览器对交互作出响应的时间,比较理想的时间是控制在 100ms 以内。
FID 只关注不连续的操作,例如点击、触摸和按键,不包含滚动和缩放之类的连续操作。
这个指标是用户对网站响应的印象,若延迟时间越长,那就会降低用户对网站的整体印象。
减少站点初始化时间(即加速渲染)和消除冗长的任务(避免阻塞主线程)有助于消除输入延迟。
在下图的 Chrome DevTools Performance 面板中,描绘了一个繁忙的主线程。
如果用户在较长的帧(600.9 毫秒和 994.5 毫秒)期间尝试交互,那么页面的响应需要等待比较长的时间。

FID 的计算方式和 LCP 类似,也是借助 PerformanceObserver 实现,如下所示。
public observerFID(): void {
const fidType = 'first-input';
const isSupport = this.checkSupportPerformanceObserver(fidType);
// 浏览器兼容判断
if(!isSupport) {
return;
}
const po = new PerformanceObserver((entryList, obs): void => {
const entries = entryList.getEntries();
const firstInput = (entries as any)[0] as TypePerformanceEntry;
// 测量个输入事件的延迟
this.fid = rounded(firstInput.processingStart - firstInput.startTime);
// 断开此观察者的连接,因为回调仅触发一次
obs.disconnect();
});
po.observe({ type: fidType, buffered: true } as any);
// po.observe({ entry*: [fidType] });
}
MPFID 是 FCP 之后最长的长任务耗时,可以通过监听 FCP 之后的 Long tasks,对比拿到最长的长任务就是 MPFID 。
CLS
CLS(Cumulative Layout Shift)会测量页面意外产生的累积布局的偏移分数,即衡量布局的稳定性。
布局不稳定会影响用户体验,例如按钮在用户试图点击时四处移动,或者文本在用户开始阅读后四处移动,而这类移动的元素会被定义成不稳定元素。
但是要注意的是,并不是所有的布局移动都是不好的,很多web网站都会改变元素的开始位置。只有当布局移动是非用户预期的,才是不好的。
在下图中,描绘了内容在页面中四处移动的场景。

布局偏移分数 = 影响分数 * 距离分数,而这个 CLS 分数应尽可能低,好低于 0.1。
-
影响分数指的是前一帧和当前帧的所有不稳定元素在可视区域的并集占比。
-
距离分数指的是任何不稳定元素在一帧中位移的大距离(水平或垂直)除以可视区域的大尺寸(宽高取较大者)。
若要计算 CLS,可以参考 Layout Instability Metric 给出的思路或 onCLS.ts,借助 PerformanceObserver 侦听 layout-shift 的变化,如下所示。
let clsValue = 0;
let clsEntries = [];
let sessionValue = 0;
let sessionEntries = [];
new PerformanceObserver((entryList) => {
for (const entry of entryList.getEntries()) {
// 只将不带有近用户输入标志的布局偏移计算在内。
if (!entry.hadRecentInput) {
const firstSessionEntry = sessionEntries[0];
const lastSessionEntry = sessionEntries[sessionEntries.length - 1];
// 如果条目与上一条目的相隔时间小于 1 秒且
// 与会话中个条目的相隔时间小于 5 秒,那么将条目
// 包含在当前会话中。否则,开始一个新会话。
if (sessionValue &&
entry.startTime - lastSessionEntry.startTime < 1000 &&
entry.startTime - firstSessionEntry.startTime < 5000) {
sessionValue += entry.value;
sessionEntries.push(entry);
} else {
sessionValue = entry.value;
sessionEntries = [entry];
}
// 如果当前会话值大于当前 CLS 值,
// 那么更新 CLS 及其相关条目。
if (sessionValue > clsValue) {
clsValue = sessionValue;
clsEntries = sessionEntries;
// 将更新值(及其条目)记录在控制台中。
console.log('CLS:', clsValue, clsEntries)
}
}
}
}).observe({type: 'layout-shift', buffered: true});
优化 CLS 的手段有很多,例如一次性呈现所有内容、在某些内容仍在加载时使用占位符、图像或视频预设尺寸等。
虽然浏览器提供了足够的 API 来帮助采集各个性能指标,但是在 JS 中计算具体指标要更为复杂。原因有两点:一是 API 报告的内容和指标本身的定义有部分差异,所以计算时要处理这些差异;二是 部分场景下浏览器不会报告对应内容,这些场景下需要模拟测量。
页面性能分析工具(Chrome DevTools)
一般来说,性能分析通常可以从时间和空间两个角度来进行:
-
时间:常见耗时,如页面加载耗时、渲染耗时、网络耗时、脚本执行耗时等
-
空间:资源占用,包括 CPU 占用、内存占用、本地缓存占用等
那么,下面来看看有哪些常见的工具可以借来用用。由于我们的网页基本上跑在浏览器中,所以基本上大多数的工具都来源于浏览器自身提供,首当其冲的当然是 Chrome DevTools (opens new window)。本文我们也主要围绕 Chrome DevTools 来进行说明。
Lighthouse
Lighthouse的前身是 Chrome DevTools 面板中的 Audits。在 Chrome 60 之前的版本中, 这个面板只包含网络使用率和页面性能两个测量类别,从 Chrome 60 版本开始, Audits 面板已经被 Lighthouse 的集成版取代。而在最新版本的 Chrome 中,则需要单独安装 Lighthouse 拓展程序来使用,也可以通过脚本来使用。
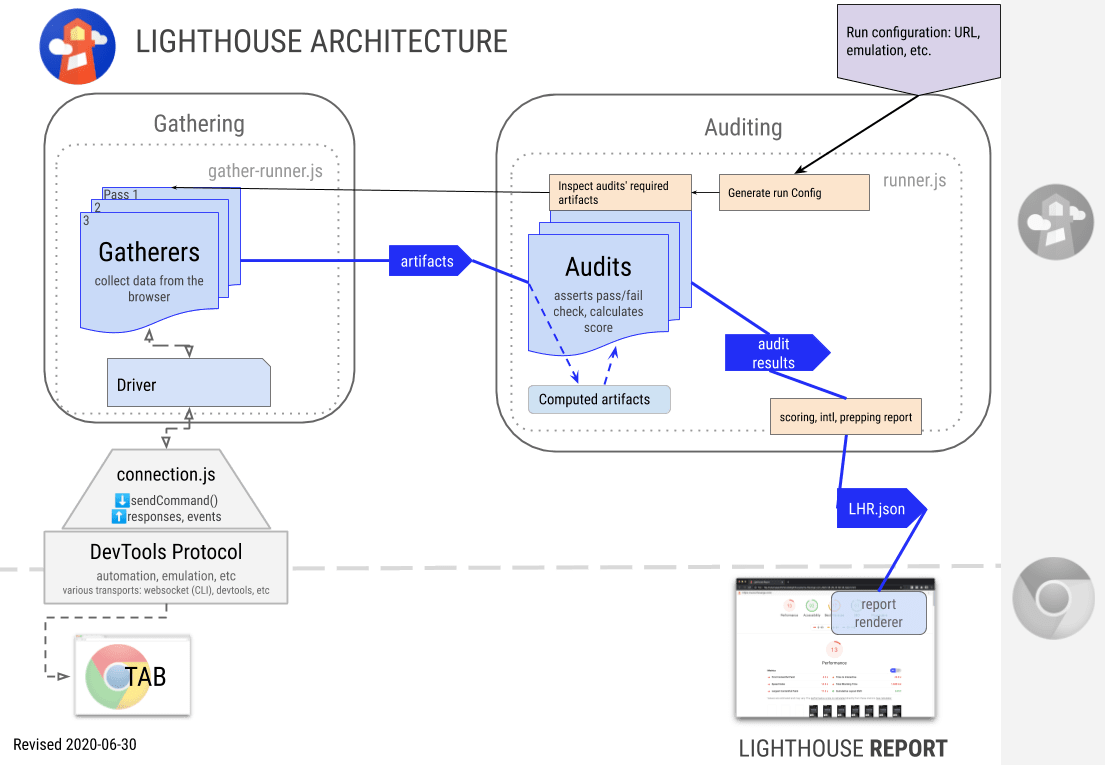
下面是 Lighthouse 的组成部分:
-
驱动(Driver):和 Chrome Debugging Protocol (opens new window)进行交互的接口
-
收集器(Gatherers):使用驱动程序收集页面的信息,收集器的输出结果被称为 Artifact
-
审查器(Audits):将 Artifact 作为输入,审查器会对其运行测试,然后分配通过/失败/得分的结果
-
报告(Report):将审查的结果分组到面向用户的报告中(如最佳实践),对该部分应用加权和总体然后得出评分
Lighthouse 会在一系列的测试下运行网页,比如不同尺寸的设备和不同的网络速度。它还会检查页面对辅助功能指南的一致性,例如颜色对比度和 ARIA 最佳实践。
在比较短的时间内,Lighthouse 可以给出这样一份报告(可将报告生成为 JSON 或 HTML):
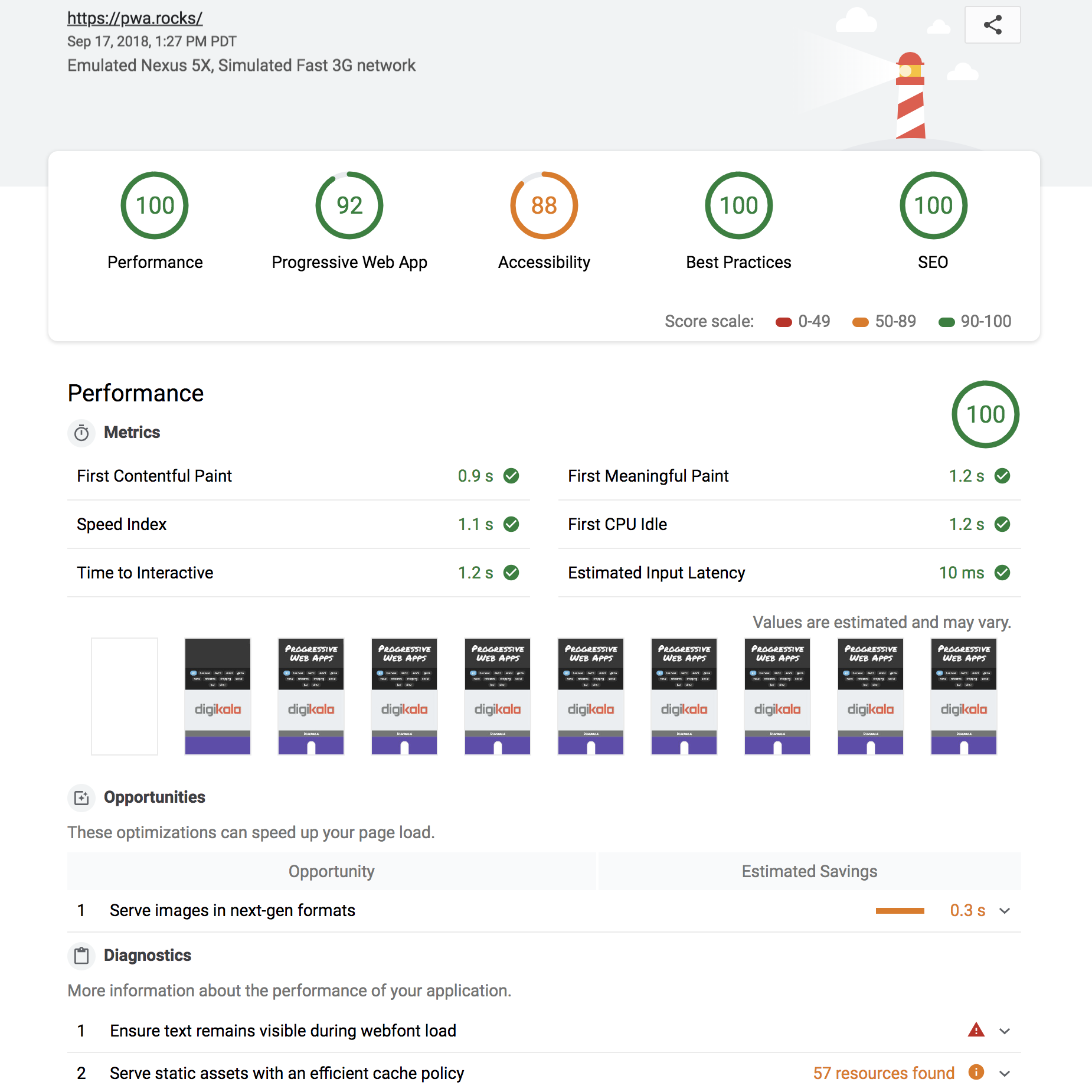
这份报告从 5 个方面来分析页面: 性能、辅助功能、最佳实践、搜索引擎优化和 PWA。像性能方面,会给出一些常见的耗时统计。除此以外,还会给到一些详细的优化方向。
如果你希望短时间内对你的网站进行较全面的评估,可以使用 Lighthouse 来跑一下分数,确定大致的优化方向。
Performance 面板
Performance面板同样有个前身,叫 Timeline。该面板用于记录和分析运行时性能,运行时性能是页面运行时(而不是加载)的性能。
Performance 面板功能特别多,具体的分析也可以单独讲一篇了。这里我们简单说一下使用的步骤:
1、在隐身模式下打开 Chrome。隐身模式可确保 Chrome 以干净状态运行,例如浏览器的扩展可能会在性能评估中产生影响。
2、在 DevTools 中,单击“Performance”选项卡,并进行一些基础配置。
3、按照提示单击记录,开始记录。进行完相应的操作之后,点击停止。
4、当页面运行时,DevTools 捕获性能指标。停止记录后,DevTools 处理数据,然后在 Performance 面板上显示结果。
关于 Performance 怎么使用的文章特别多,大家网上随便搜一下就能搜到。一般来说,主要使用以下功能:
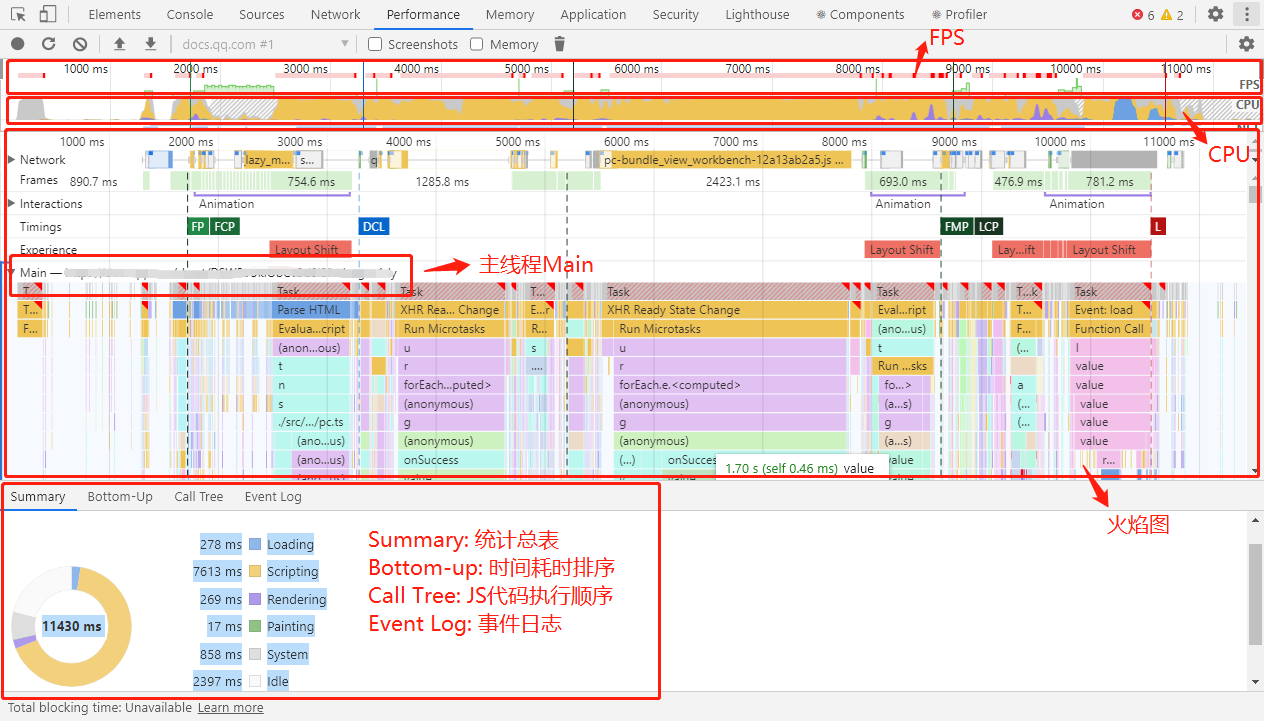
-
查看 FPS 图表:当在 FPS 上方看到红色条形时,表示帧速率下降得太低,以至于可能损害用户体验。通常,绿色条越高,FPS 越高
-
查看 CPU 图表:CPU 图表在 FPS 图表下方。CPU 图表的颜色对应于性能板的底部的 Summary 选项卡
-
查看 火焰图:火焰图直观地表示出了内部的 CPU 分析,横轴是时间,纵轴是调用指针,调用栈最顶端的函数在最下方。启用 JS 分析器后,火焰图会显示调用的每个 JavaScript 函数,可用于分析具体函数
-
查看 Buttom-up:此视图可以看到某些函数对性能影响最大,并能够检查这些函数的调用路径
怎样评估站点整体的性能好坏
虽然有众多性能指标,但是每个性能指标评估的都是单一方面,如何整体来看站点的性能是好是坏呢?对于每个单一指标,是否有标准去定义指标的值在具体哪个范围内能算优秀?线上的站点性能应该重点考量哪些性能指标?各个性能指标的权重占多少合适呢?
性能指标基准线
Google 提供了各个性能指标的基准线,有一定的参考意义。
为什么只说是有一定参考意义?首先基准线本身是在变化的,随着指标计算的逐渐更新以及软件硬件的更新,基准线也会有一定的调整。其次用户的使用场景对性能指标也会有很大的影响,比如 iOS 用户上报的性能指标一般都优于 Android 用户上报的性能指标。
下方是我们目前使用的部分性能指标基准线,基本对齐 Google 建议的基准线,通过这些数据可以分析站点的性能达标率情况。

衡量站点满意度
站点满意度的衡量除了要考虑常规的性能指标外,还要考虑体验类的指标,比如专门衡量视觉稳定性的指标 CLS。
线上的站点满意度衡量,一般会在参考lighthouse的满意度计算规则的基础上,去除一些推荐在实验室环境测量的指标的权重。
下方是我们目前使用的线上站点性能满意度的权重计算公式,去除了SI 和 TBT这两个不推荐在线上环境测量的指标。

那么有了一个站点满意度以后,我们终于能知道一个站点的性能好坏了。那么假设性能不好,我们应该怎样优化?
链路分析优化
性能优化的策略很多,如何很好的串联起这些策略点呢?可以先从这个问题开始:
从输入地址到页面显示经历了哪些过程?
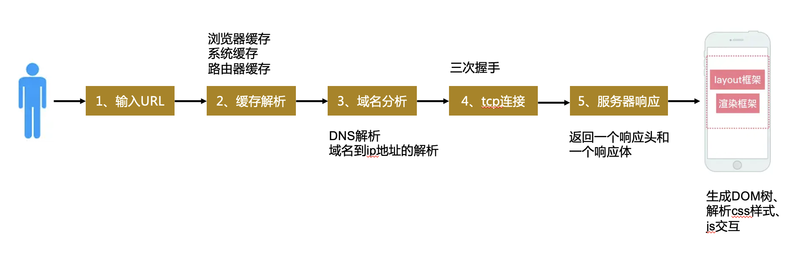
简单的可以分为这几个阶段:
- 网络请求
- 资源加载
- 浏览器渲染
网络请求优化
CDN
内容分发网络(CDN)是一组分布在多个不同地理位置的 Web 服务器。我们都知道,当服务器离用户越远时,延迟越高。CDN 就是为了解决这一问题,在多个位置部署服务器,让用户离服务器更近,从而缩短请求时间。
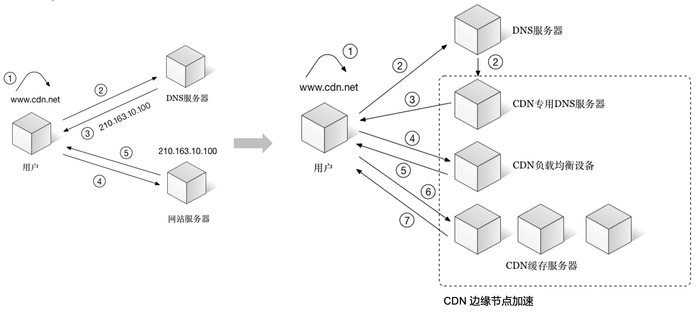
CDN服务提供商将源站的资源缓存到全国各地的高性能加速节点。当用户访问相应的服务资源时,会将用户调度到最近的节点,并将最近的节点IP返回给用户,使用户就近获取所需内容,从而可以更快、更稳定地传输内容。CDN 的核心点有两个,一个是缓存,一个是回源:
-
缓存: 将源服务器请求来的资源按要求缓存。
-
回源:CDN节点没有响应到应该缓存的资源(没有缓存过或者是缓存已经到期),就会回源站去获取
减少DNS查询时间
在浏览器可以请求网站资源之前,它需要通过域名系统(DNS)获得你的服务端IP地址。直到DNS响应前,用户看到的都是白屏。HTTP/2优化了Web浏览器和服务器之间的通信方式,但它不会影响域名系统的性能。
因为DNS查询的开销可能会很昂贵,尤其是当你从根名字服务器开始查询时,最小化网站使用的DNS查询数仍然是一个明智之举。使用HTML头部的<link rel=‘dns-prefetch’ href=‘…’ />可以帮助你提前获取DNS记录,但这不是万能的解决方案。
HTTP2
HTTP应用层的优化和TCP传输层的优化是前端性能优化的必经之路。我们都知道合并(减少)静态资源的HTTP请求(比如前端雪碧图)是一条前端优化准则,那它背后的原理是什么呢?真的要严格做到减少HTTP请求吗?下面我们从原理上探下究竟。
HTTP 1.1的缺点
1、HTTP 1.1 队头阻塞的问题
我们都知道在HTTP 1.1中使用了持久连接,虽然可以共享一个TCP管道,但一次只能在管道中处理一个请求。在当前请求结束之前,只能阻止其他请求。也就是说如果某些请求被阻止10秒,则后续排队的请求将延迟10秒。这个队头阻塞问题使得这些数据请求不能并行进行。这也就是为什么浏览器可以为每个单独的域名支持多条 TCP 连接(最多6个),请求可以分布在这些单独的连接上,起到并行请求处理的效果。
2、TCP 慢启动
TCP慢启动是TCP拥塞控制的一种策略。TCP 在刚建立连接完成后,首先是有个慢启动的过程,这个慢启动的意思就是一点一点的提高发送数据包的数量。当发送方每收到一个 确认包,拥塞窗口的大小就会加 1。说慢启动会带来性能问题就是因为如果请求一个不大的页面关键资源也要经过这样的慢启动过程,那么页面的渲染性能就会大大的降低。
所以从HTTP 1.1的缺点上看,我们一开始提到的前端雪碧图是很有必要的。一个 TCP 连接同时只能处理一个 HTTP 请求。所以在网站资源较多,加上浏览器有TCP连接数量的限制时,页面加载就会比较慢,这时将一些小图片合并成一个大的图片,从而减少 HTTP 请求是十分可取的。
HTTP 2的优点和缺点
1、多路复用(核心优点)
HTTP 2 采用了多路复用机制。
HTTP 2 通过引入二进制分帧层,浏览器会将每个请求转换为多个带有请求 ID 编号的帧,服务器接收到所有帧之后,会将相同 ID 的帧合并为一条完整的请求,处理完请求后,又把响应转换为多个带有响应 ID 编号的帧,浏览器会根据 ID 编号将帧的数据合并。通过这样的机制,HTTP 2 实现了资源的并行传输。并且,加上HTTP 2 的一个域名只使用一个 TCP 连接,这样就解决了的HTTP 1.1的队头阻塞问题,同时也可以解决多条 TCP 连接导致的竞争带宽问题。
在说说之前提到的前端雪碧图。现在我们知道了在 HTTP 2 中,多个请求不再是一件很耗费性能的事情。前端雪碧图相比于从图片格式和大小(webp等)优化出发,明显后者更能产出性能优化。所以在 HTTP 2 中,前端雪碧图不再是一个最佳实践。
2、其他优点
-
基于二进制分帧层,HTTP 2 还可以设置请求的优先级,这样就解决了资源的优先级问题。
-
服务器推送,不用浏览器去主动请求页面的关键资源,一旦HTML解析完之后,就可以拿到关键渲染路径上的资源。
-
头部压缩。HTTP 2 对请求头和响应头进行了压缩。
3、缺点:HTTP 2 的 TCP 队头阻塞问题
HTTP 2 解决了应用层面的队头阻塞问题,并没有改动到跟HTTP /1.1 相同的TCP传输层协议。我们知道TCP 是一个保证可靠的面向连接的(一对一的单连接)通信协议,如果有一个数据包丢失或者延迟了,那么整个 TCP 的连接就会处于暂停状态,需要等待重新传输丢失或者延迟数据包。但是,在HTTP 2 中一个域名又只使用一个 TCP 连接,一个一个请求是跑在一个 TCP 长连接中的,如果其中一个数据流出现了丢包的情况,那么就会阻塞该 TCP 连接中的所有请求,进而影响了HTTP 2 的传输效率。
HTTP 3的展望
1、QUIC 协议
HTTP 3和HTTP 2主要区别在于 HTTP 3 基于 QUIC 作为传输层来处理流,而 HTTP 2 使用 TCP 来处理 HTTP 层中的流。
可以把 QUIC 看成是集成了“TCP+HTTP 2 的多路复用 +TLS ”的一套协议。其中的快速握手功能(基于UDP)实现了使用 0-RTT 或者 1-RTT 来建立连接,可以大大提升首次打开页面的速度。但是,目前HTTP 3 的浏览器兼容性存在问题,Safari浏览器默认不支持该功能。
2、Preconnect & DNS-Prefetch
preconnect和dns-prefetch都是资源探嗅(resource hints)的标准,用法如下:
<link rel="preconnect" href="https://example.com">
<link rel="dns-prefetch" href="https://example.com">
preconnect可以用在请求资源前,预先完成 DNS lookup + TCP handshake + TLS handshake(如果是https),当客户端需要请求目标资源的时候,下一个 TCP 首包就可以直接发送 HTTP 请求。虽然非常简单,但它仍然会占用宝贵的 CPU 时间,尤其是在安全连接上。 如果在 10 秒内没有使用连接,浏览器会关闭它,这样就浪费所有早期的连接工作。目前Safari 11.1版本以上的浏览器都支持,但是较新的几个Firefox浏览器版本都不支持。dns-prefetch的浏览器兼容性比较好,但是它只处理了DNS查询。
HTTP缓存
1、强缓存
强缓存指的是在缓存数据未失效的情况下,直接使用浏览器的缓存数据,不在发起网络请求。强缓存由Expires和Cache-Control两个响应头实现。
Expires,它的值是一个GMT时间。该值描述的是一个绝对时间,由服务器返回。Expires 受限于本地时间,如果修改了本地时间,可能会造成缓存失效。
Cache-Control,主要有一下几个值:
-
no-cache:浏览器每次使用 URL 的缓存版本之前都必须与服务器重新验证
-
no-store:浏览器和其他中间缓存(如 CDN)从不存储文件的任何版本。
-
private:浏览器可以缓存文件,但中间缓存不能。
-
public:响应内容可以被任何服务器缓存存储。
-
max-age:缓存时长,用来指定相对的时间量。
如果以上两个响应头一起出现那么cache-control 的优先级高于 expires。
2、协商缓存
当浏览器对某个资源的请求没有命中强缓存,就会发一个请求到服务器,服务器会查看相关资源是否修改更新,若没有更新返回304状态码,若有修改更新,则返回最新资源和200状态码。
协商缓存是利用的是【Last-Modified,If-Modified-Since】和【ETag、If-None-Match】这两对Header来管理的。Last-Modified是服务器认定的资源做出修改的时间,浏览器会在下次请求时带上作为If-Modified-Since的值,由此服务器可以做资源是否被修改的检查;ETag和If-None-Match的使用方式与Last-Modified和If-Modified-Since类似,只是ETag 的值的生成比较复杂,通常是内容的哈希值、最后修改时间戳的哈希值。
ETag的优先级比Last-Modified更高。
webpack配置
为了更有效的利用缓存,我们通常会给静态资源设置一个比较长的缓存时间,在每次打包上线,为了让浏览器获取最新的资源,我们都会给变动的静态资源改成一个跟上次不一样的版本hash文件名,如main.8e0d62a03.js。我们可以借助webpack打包出这样的hash文件指纹。webpack有如下三种hash的生成方式:
- hash:和整个项目的构建相关,只要项目有修改,整个项目构建的hash值就会更改。
- chunkhash:和webpack打包的chunk有关,不同的entry会生成不同的chunkhash值。
- contenthash:根据文件内容来定义hash,文件内容不变,则contenthash不变
service worker 缓存
Service Worker 拦截网络类型的 HTTP 请求,并使用缓存策略来确定应将哪些资源返回给浏览器。 Service Worker 缓存和 HTTP 缓存具有相同的目的,但 Service Worker 缓存提供了更多的缓存功能,例如对缓存的内容以及缓存的完成方式进行细粒度控制。
下面来罗列一下几个常见的 Service Worker 缓存策略(也是Workbox提供的几个开箱即用的缓存策略)。
-
Network only:始终从网络获取最新的内容。
-
Network falling back to cache:需要提供最新的内容。但是,如果网络出现故障或不稳定,则可以提供稍微旧的内容。
-
Stale-while-revalidate:可以立即提供缓存内容,但将来应该使用更新的缓存内容。
-
Cache first, fall back to network:优先从缓存中提供内容以提高性能,但 Service Worker 应该偶尔检查更新。
-
Cache only:只使用缓存。
关于stale-while-revalidate:
在上面的service worker 缓存策略中我们提到过stale-while-revalidate。它其实是一种由 HTTP RFC 5861 推广的 HTTP 缓存失效策略。这种策略首先从缓存中返回数据(过期的),同时发送 fetch 请求(重新验证),最后得到最新数据。stale-while-revalidate的用法和max-age相同:
Cache-Control: max-age=1, stale-while-revalidate=59
如果在接下来的 1 秒内重复请求时间,则先前缓存的值仍将是最新的,并按原样使用,无需任何重新验证。 如果请求在 1 到 59 秒后重复,虽然缓存是过期了,但仍可以直接使用这个过期缓存,同时进行异步 revalidate。在 59秒之后,缓存就是完全过期了,需要进行网络请求。
Vercel根据stale-while-revalidate的思想,推出了一个SWR用于获取数据的 React Hooks 库。它能够使我们的组件立即加载缓存的数据,同时能够异步的刷新订阅的数据,以便提供更新后的界面数据。组件就有了不断自动地获得数据更新流的能力。
上面我们介绍了浏览器的HTTP缓存和service worker缓存,我们来简单梳理一下浏览器在请求资源时遵循的缓存顺序(优先级从高到低):
1、memory cache(如果有)
2、Service worker cache
3、HTTP 缓存(先强缓存然后协商缓存)
4、服务器或CDN缓存
预加载
preload预加载
<link rel="preload" href="sintel-short.mp4" as="video" type="video/mp4">
link元素的 rel 属性的 preload 值允许在 HTML 的 中声明获取请求,以此来指明资源在后续会被很快的用到,这样浏览器就可以尽早的去加载资源(也提高了资源的优先级)。这样就确保了资源更早可用,并且不太可能阻止页面的渲染,从而提高性能。
1、preload的适用场景 使用preload的基本使用方式是尽早加载后期发现的资源。 虽然浏览器的预加载器可以很早就发现大多数在HTML标记上的资源,但并非所有资源都是在HTML上的。一些资源就会隐藏在 CSS 和 JavaScript 中,浏览器无法尽早的发现和下载他们。 因此,在很多情况下,这些资源最终会延迟首次渲染或页面关键部分的加载。
字体资源的加载是很适合使用preload来优化的。在大多数情况下,字体对于在页面上呈现文本至关重要,并且字体的使用深埋在 CSS 中,即使浏览器的预加载器解析了 CSS,也无法确定是否需要它们。
<link rel="preload" href="font.woff2" as="font" type="font/woff2">
使用preload后,我们就可以提高字体资源的优先级,这样浏览器就可以尽早的预加载。有案例表明,使用preload进行字体加载后,可以将整体页面的加载时间缩短一半。
2、preload的使用注意事项
-
虽然preload的好处很明显,但是如果滥用的话可能会浪费用户的带宽。并且如果没有在3s 内用到 preload的资源,在浏览器的console会显示警告。
-
不要省略as属性。省略 as 属性或者使用一个无效值,会使preload请求相当于 XHR 请求,浏览器不知道它正在获取什么,并且以相当低的优先级获取它。
-
目前主流浏览器都支持preload。如果是不支持的浏览器,也会忽略它而不是报错。
prefetch资源提示
<link rel="prefetch" href="/library.js" as="script">
prefetch是W3C Resource Hints 标准的其中一个指令。prefetch的用法是和preload相同的,但是功能却和preload大不一样。它主要是告诉浏览器获取下一次导航可能需要的资源。 这主要意味着资源将以极低的优先级获取(因为浏览器知道当前页面中需要的所有内容都比我们猜测下一个页面中可能需要的资源更重要)。 这意味着预取的资源主要是用于加速下一个导航而不是当前导航。在浏览器的兼容性上,prefetch可以支持到IE11。同时也要说明的是,prefetch和preload的资源如果可以被缓存(例如,有一个有效的cache-control )那么缓存是被存储在 HTTP 缓存中的,并放入浏览器的内存缓存;如果资源不可缓存,则不会存储在 HTTP 缓存中。 相反,它上升到内存缓存并停留在那里直到它被使用。
使用Webpack来对prefetch和preload进行支持
Webpack v4.6.0+ 增加了对预获取和预加载的支持。
import(/* webpackPrefetch: true */ './path/to/LoginModal.js');
这会生成 <link rel="prefetch" href="login-modal-chunk.js"> 并追加到页面头部,指示着浏览器在闲置时间预取 login-modal-chunk.js 文件。并且只要父 chunk 完成加载,webpack 就会添加 prefetch hint(预取提示)。
import(/* webpackPreload: true */ 'ChartingLibrary');
preload chunk 会在父 chunk 加载时,以并行方式开始加载。而prefetch chunk 会在父 chunk 加载结束后才开始加载。
quicklink
quicklink是google chrome labs出品的一个很小(< 1KB minified/gzipped)的npm库,旨在是通过在空闲时段内预取视口内链接来加快后续页面加载。
它的主要原理是:
-
检测视口内的链接(使用 Intersection Observer)
-
等待浏览器空闲,以便在浏览器空闲时进行页面资源的预取(使用 requestIdleCallback)
-
检查用户是否处于慢速连接(使用 navigator.connection.effectiveType)或启用了数据节省(使用 navigator.connection.saveData)
-
预加载链接的 URL(使用 或 XHR)。 提供对请求优先级的一些控制:默认为低优先级,使用rel=prefetch 或 XHR,对于高优先级的资源,尝试使用 fetch() 或回退到 XHR。
quicklink提供的一个demo显示使用quicklink可以将页面加载性能提高4秒
懒加载
上面一小节介绍了几个预加载的技术,接下来我们要说一下懒加载。懒加载就是延迟加载,它可以极大的减少无效资源的加载,从而提高页面的性能。懒加载的核心适用场景就是在当前视口(viewport)外的资源(或者是非关键渲染路径下的资源)不需要加载。代码层面的懒加载最为常见的是我们使用的第三方库的懒加载(Dynamic Import)或者组件懒加载(React的React.lazy),其本质就是动态 import() 语法。下面我们来介绍一下其他资源懒加载的实现方式:
Intersection Observer
Intersection Observers API允许用户知道观察到的元素何时进入或退出浏览器的视口。利用这个特性,我们可以做到对非当前视口内的资源不加载。
在众多第三方前端懒加载实现库中,有一个高性能轻量级的js库Lozad.js,它可以支持 img、picture、iframe、视频、音频、响应式图片、背景图片和多背景图片等多种资源的懒加载。不同于现有的延迟加载库与浏览器滚动事件挂钩或者周期性的需要在延迟加载的元素上调用 getBoundingClientRect(),Lozad.js使用的是不阻塞js主线程的Intersection Observers API ,而每次调用 getBoundingClientRect() 都会迫使浏览器重新布局整个页面,可能会给浏览器带来卡顿。
图片懒加载
当图片出现在可视区域或者即将出现在可视区域时再加载图片,避免一次性加载全部图片,会对用户体验造成很大影响。
浏览器原生的图片延迟加载
<img src="image.png" loading="lazy" alt="…" width="200" height="200">
上面的代码可以实现浏览器原生的图片懒加载(基于Chromium 的浏览器和 Firefox,不支持loading属性的浏览器会忽略它的存在)。这样我们就不用使用其他js库来实现图片的懒加载。
loading属性有三种取值:
-
auto:使用浏览器的默认加载行为,与不使用loading属性相同。
-
lazy:推迟加载资源,直到它达到与视口距离的阈值。
-
eager:立即加载资源,无论它位于页面上的什么位置。
如何理解loading=lazy时的与视口距离的阀值?
Chromium 的延迟加载实现试图确保屏幕外图像足够早地加载,以便在用户滚动到它们附近时它们已经完成加载。 通过在它们在视口中可见之前获取图片资源,最大限度地提高了它们在变得可见时已经加载的机会。那么如何尽早的加载图片?也就是说不可见的图片在和当前视口的距离为多少时浏览器才会去加载后面的图片呢?答案是Chromium的这个距离阈值不是固定的,取决于以下几个因素:
-
图片资源的类型。
-
data-savings是否被开启。
-
当前网络的状况(effective connection type)。
根据上面三个因素,Chromium在不断改进这个距离阀值的算法,在节省图片下载的同时,也能保证在用户滚动到图片时图片已加载。
资源大小优化
我们来看一下几个常见资源的大小优化,其实这些资源基本上都可以在webpack打包阶段进行优化,当然有些压缩也可以在http层面进行。
代码压缩
Webpack 压缩
在 webpack 可以使用如下插件进行压缩:
-
JavaScript:UglifyPlugin
-
CSS :MiniCssExtractPlugin
-
HTML:HtmlWebpackPlugin
其实,我们还可以做得更好。那就是使用 gzip 压缩。可以通过向 HTTP 请求头中的 Accept-Encoding 头添加 gzip 标识来开启这一功能。当然,服务器也得支持这一功能。
开启 gzip 压缩
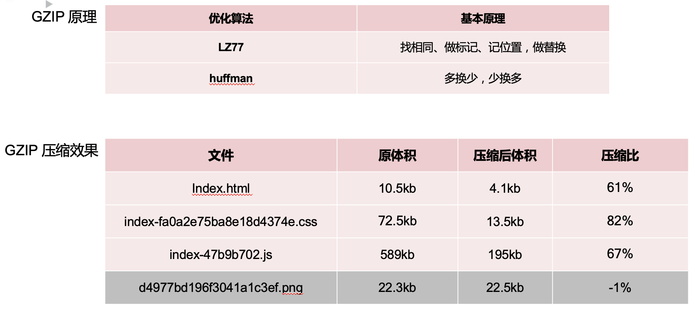
服务器返回响应体,响应体的内容未经压缩的话,体积往往比较大,采用 GZIP 压缩,可以大大的缩减文本类的资源体积,而对于图片资源则效果不大。
因为 GZIP 采用的是 LZ77 和哈夫曼算法,都是针对文本类的压缩算法,挺有意思,大家有兴趣的可以了解下。
主要使用了content-encoding这个实体消息首部,用于对特定媒体类型的数据进行压缩。借助nginx配置,我们就可以实现:
# 开启gzip 压缩
gzip on;
# 设置gzip所需的http协议最低版本 (HTTP 1.1, HTTP/1.0)
gzip_http_version 1.1;
# 设置压缩级别,压缩级别越高压缩时间越长 (1-9)
gzip_comp_level 4;
# 设置压缩的最小字节数, 页面Content-Length获取
gzip_min_length 1000;
# 设置压缩文件的类型 (text/html)
gzip_types text/plain application/javascript text/css;
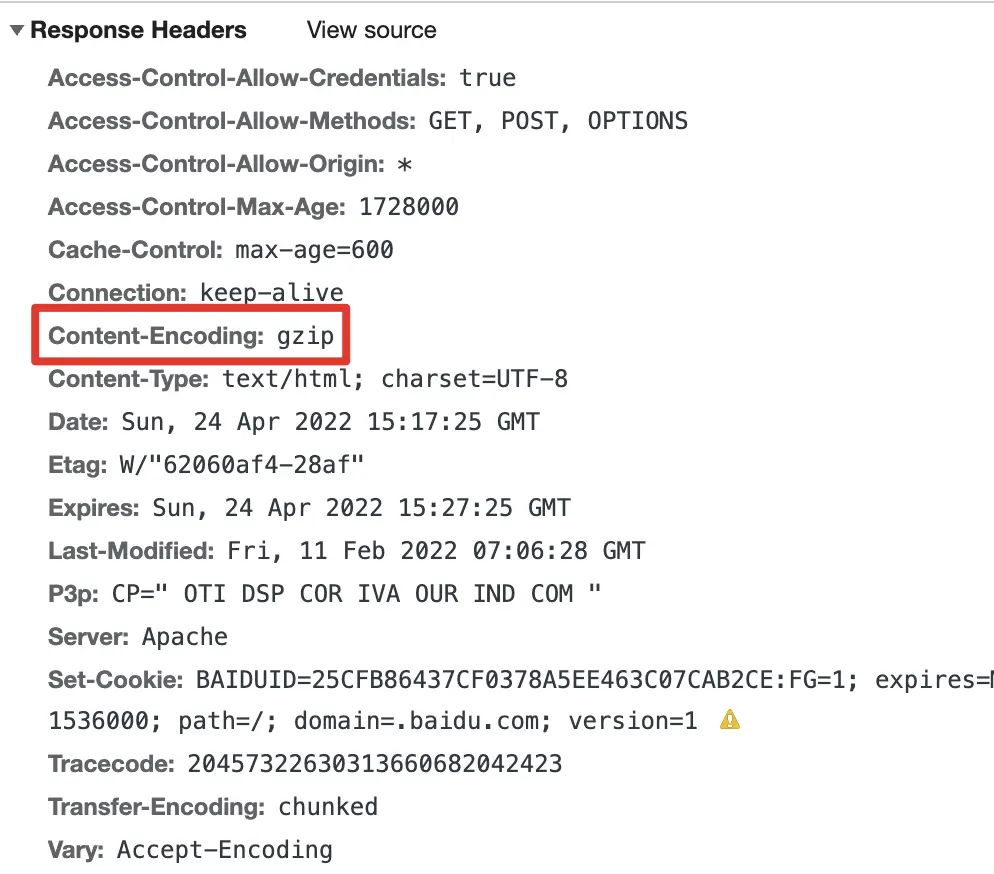
重启服务,观察网络面板里面的 response header,如果看到如下红圈里的字段则表明 gzip 开启成功:
使用 Brotli 压缩
2015 年,Google 推出了 Brotli,一种新开源的无损数据格式,现已被所有现代浏览器所支持。实际上,Brotli 比 Gzip 和 Deflate 有效得多。因为它比较依赖配置,所以这种压缩可能会(非常)慢,但较慢的压缩意味着更高的压缩率。不过它解压速度很快。所以你可以考虑 Brotli 为你的网站所节省的成本。
只有用户通过 HTTPS 访问站点时,浏览器才会接受这种格式。那代价是什么呢?Brotli 并没有预安装在一些服务器上,所以如果没有自编译 Nginx,那么配置就会相对困难。尽管如此,它也并非是不可攻破的难题,比如,Apache 自 2.4.26 版本起,开始逐步对它进行支持。得益于 Brotli 被众多厂商支持,许多 CDN 也开始支持它(Akamai、AWS、KeyCDN、Fastly、Cloudlare、CDN77),你甚至(结合 service worker 一起使用)可以在不支持它的 CDN 上,启用 Brotli。
在最高级别压缩时,Brotli 会非常缓慢,以至于服务器在开始发送响应前等待动态压缩资源所花费的时间,可能会抵消文件大小(被压缩后)的潜在增益。但对于静态压缩,应该首选更高级别的压缩。
js
scope hoisting
scope hoisting 翻译过来就是作用域提升。在webpack中,这个特性被用来检测引用链(import chaining)是否可以被内联,从而减少没有必要的module 代码。在webpack中开启ModuleConcatenationPlugin插件可以开启scope hoisting。此插件只在 production mode生产环境中默认开启。
code splitting
webpack的code splitting能够把代码分离到不同的 bundle 中,然后可以按需加载或并行加载这些文件。代码分离可以用于获取更小的 bundle,减少文件加载的耗时。常见的方案有:
-
开箱即用的SplitChunksPlugin配置可以做到自动拆分 chunks。
-
动态导入(dynamic import)可以做到代码的按需加载。
-
使用 entry 配置可以配置多个代码打包入口点,从而做到手动地分离代码。
SplitChunksPlugin 的配置项很多,可以先去官网了解如何配置,我们现在只简单列举了一下配置元素。
如果我们想抽取第三方库可以这样简单配置
splitChunks: {
chunks: 'all', // initial、async和all
minSize: 30000, // 形成一个新代码块最小的体积
maxAsyncRequests: 5, // 按需加载时候最大的并行请求数
maxInitialRequests: 3, // 最大初始化请求数
automaticNameDelimiter: '~', // 打包分割符
name: true,
cacheGroups: {
vendor: {
name: "vendor",
test: /[\\/]node_modules[\\/]/, //打包第三方库
chunks: "all",
priority: 10 // 优先级
},
common: { // 打包其余的的公共代码
minChunks: 2, // 引入两次及以上被打包
name: 'common', // 分离包的名字
chunks: 'all',
priority: 5
},
}
},
这样似乎大功告成了?并没有,我们的配置有很大的问题:
1、我们粗暴得将第三方库一起打包可行吗? 当然是有问题的,因为将第三方库一块打包,只要有一个库我们升级或者引入一个新库,这个 chunk 就会变动,那么这个chunk 的变动性会很高,并不适合长期缓存,还有一点,我们要提高首页加载速度,第一要务是减少首页加载依赖的代码量,请问像 react vue reudx 这种整个应用的基础库我们是首页必须要依赖的之外,像 d3.js three.js这种特定页面才会出现的特殊库是没必要在首屏加载的,所以我们需要将应用基础库和特定依赖的库进行分离。
2、当 chunk 在强缓存期,但是服务器代码已经变动了我们怎么通知客户端?上面我们的示意图已经看到了,当命中的资源在缓存期内,浏览器是直接读取缓存而不会向服务器确认的,如果这个时候服务器代码已经变动了,怎么办?这个时候我们不能将 index.html 缓存(反正webpack时代的 html 页面小到没有缓存的必要),需要每次引入 script 脚本的时候去服务器更新,并开启 hashchunk,它的作用是当 chunk 发生改变的时候会生成新的 hash 值,如果不变就不发生变动,这样当 index 加载后续 script资源时如果 hashchunk 没变就会命中缓存,如果改变了那么会重新去服务端加载新资源。
下面示意了如何将第三方库进行拆包,基础型的 react 等库与工具性的 lodash 和特定库 Echarts 进行拆分
cacheGroups: {
reactBase: {
name: 'reactBase',
test: (module) => {
return /react|redux/.test(module.context);
},
chunks: 'initial',
priority: 10,
},
utilBase: {
name: 'utilBase',
test: (module) => {
return /rxjs|lodash/.test(module.context);
},
chunks: 'initial',
priority: 9,
},
uiBase: {
name: 'chartBase',
test: (module) => {
return /echarts/.test(module.context);
},
chunks: 'initial',
priority: 8,
},
commons: {
name: 'common',
chunks: 'initial',
priority: 2,
minChunks: 2,
},
}
我们对 chunk 进行 hash 化,我们变动 chunk2 相关的代码后,其它 chunk 都没有变化,只有 chunk2 的 hash 改变了
output: {
filename: mode === 'production' ? '[name].[chunkhash:8].js' : '[name].js',
chunkFilename: mode === 'production' ? '[id].[chunkhash:8].chunk.js' : '[id].js',
path: getPath(config.outputPath)
}
tree shaking
Tree shaking是一个用在js中删除无用代码的术语。在webpack 2版本中webpack内置支持了ES2015 modules,并且也支持了无用模块的导出检测。webpack 4版本在此功能上进行了扩展,并通过在package.json 中添加 “sideEffects” 属性向编译器提供提示,以标示项目中的哪些文件是“纯”的,从而可以安全的移除。
Tree Shaking虽然出现很早了,比如js基础库的事实标准打包工具 rollup 就是Tree Shaking的祖师爷,react用 rollup 打包之后体积减少了 30%,这就是Tree Shaking的厉害之处。
Tree Shaking的作用就是,通过程序流分析找出你代码中无用的代码并剔除,如果不用Tree Shaking那么很多代码虽然定义了但是永远都不会用到,也会进入用户的客户端执行,这无疑是性能的杀手,Tree Shaking依赖es6的module模块的静态特性,通过分析剔除无用代码.
目前在 webpack4.x 版本之后在生产环境下已经默认支持Tree Shaking了,所以Tree Shaking可以称得上开箱即用的技术了,但是并不代表Tree Shaking真的会起作用,因为这里面还是有很多坑.
-
坑 1: Babel 转译,我们已经提到用Tree Shaking的时候必须用 es6 的module,如果用 common.js那种动态module,Tree Shaking就失效了,但是 Babel 默认状态下是启用 common.js的,所以需要我们手动关闭.
-
坑 2: 第三方库不可控,我们已经知道Tree Shaking的程序分析依赖 ESM,但是市面上很多库为了兼容性依然只暴露出了ES5 版本的代码,这导致Tree Shaking对很多第三方库是无效的,所以我们要尽量依赖有 ESM 的库,比如之前有一个 ESM 版的 lodash(lodash-es),我们就可以这样引用了import { dobounce } from ‘lodash-es’
JavaScript 差异化服务
我们希望通过网络发送必要的 JavaScript,但这意味着需要更加集中精力并且细粒度地关注这些静态资源的传送。前一阵子 Philip Walton 介绍了差异化服务的想法。该想法是编译和提供两个独立的 JavaScript 包:“常规”构建,带有 Babel-transforms 和 polyfill 的构建,只提供给实际需要它们的旧浏览器,以及另一个没有转换和 polyfill 的包(具有相同功能)。
结果,通过减少浏览器需要处理的脚本数量来帮助减少主线程的阻塞。
polyfill动态加载
polyfill是为了浏览器兼容性而生,是否需要 polyfill 应该有客户端的浏览器自己决定,而不是开发者决定,但是我们在很长一段时间里都是开发者将各种 polyfill 打包,其实很多情况下导致用户加载了根本没有必要的代码.
解决这个问题的方法很简单,直接引入 <script src="https://cdn.polyfill.io/v2/polyfill.min.js"></script> 即可,而对于 Vue 开发者就更友好了,vue-cli 现在生成的模板就自带这个引用.
这个原理就是服务商通过识别不同浏览器的浏览器User Agent,使得服务器能够识别客户使用的操作系统及版本、CPU 类型、浏览器及版本、浏览器渲染引擎、浏览器语言、浏览器插件等,然后根据这个信息判断是否需要加载 polyfill,开发者在浏览器的 network 就可以查看User Agent。
css
内联首屏关键CSS
内联首屏关键CSS文件,可以提高页面的渲染时间。因为CSS会阻塞JS的执行,而JS会阻塞DOM的生成,也就是会阻塞页面的渲染,那么css也有可能会阻塞页面的渲染。一些CSS-in-J的方案,比如styled-components 也是critical CSS友好的,styled-components会跟踪页面上呈现的组件,并完全自动地注入它们的内联样式,而不是一些CSS link。结合组件级别的代码拆分,可以按需加载更少的代码。
动态异步加载CSS
对于大的 CSS 文件,可以通过媒体查询属性,将其拆分为多个不同用途的 CSS 文件,这样只有在特定的场景下才会加载特定的 CSS 文件。
图片
降低图片质量
一些图片适当降低图片质量时,通常是看不出来区别的,尤其是作为背景图片时,可以使用 image-webpack-loader进行图片压缩。当然如果图片很小我们也可以考虑内联base64图片(url-loader)。
尽量使用 CSS 代替图片
一些简单的图片效果如果可以通过 CSS 效果实现则进行用 CSS 来实现,可以减小请求次数或者打包体积大小。
iconfont 代替图片图标
字体图标就是将图标制作成一个字体,使用时就跟字体一样,可以设置属性,例如 font-size、color 等,非常方便,并且字体图标是矢量图,不会失真。还有一个优点是生成的文件特别小,无论是加载还是打包所消耗的资源都相对较小一些。
使用 webp 图
WebP 是 Google 团队开发的加快图片加载速度的图片格式,其优势体现在它具有更优的图像数据压缩算法,能带来更小的图片体积,而且拥有肉眼识别无差异的图像质量;同时具备了无损和有损的压缩模式、Alpha 透明以及动画的特性,在 JPEG 和 PNG 上的转化效果都相当优秀、稳定和统一。
渐进式加载图片
其实就是延迟加载,在真实的图片加载出来之前,可以使用一张公共的图片,一般是公司的logo,先将布局撑起来,然后再换成真实的图片。
lqip这个工具可以将真实的图片虚化,转换为很小的base64编码。这样我们可以先使用base64加载虚化的图片。
也可以使用低质量图片占位符, 他是基于SVG的图像占位符实现的。
const sqip = require('sqip');
const result = sqip({
filename:'./in.png',
numberOfPrimitives:10 // 效果值
});
console.log(result.final_svg); // 输出svg格式

相比lqip来说sqip效果会好很多,而且可以设置不同的大小。
GIF 图
对于 GIF 图,可以只加载 GIF 的第一帧,等首屏渲染完成后,再完整加载 GIF 的资源,约缩小 97% 的首屏图片资源
图片服务器自动优化
图片服务器优化是指可以在图片url连接上增加不同特殊参数,让服务器自动生成不同格式,大小,质量的图片。
比如说可以对图片做一些裁剪,裁剪成我们需要的图片,也可以支持不同格式的转换,比如说jpg,gif,png,webp等也可以设置图片的压缩比。 也可以对图片添加一些水印,高斯模糊,重心处理等还可以增加一些AI的能力,比如说用户上传的图片是否涉黄。还可以通过智能抠图,智能排版,智能配色智能合成等功能完善图片。
渲染优化
上面我们从网络的连接和资源的加载两个角度总结了网络资源的优化。接下来我们会在拿到页面资源后,对页面的渲染进行分析和优化总结。
浏览器有多种进程,其中最主要的5种进程如下
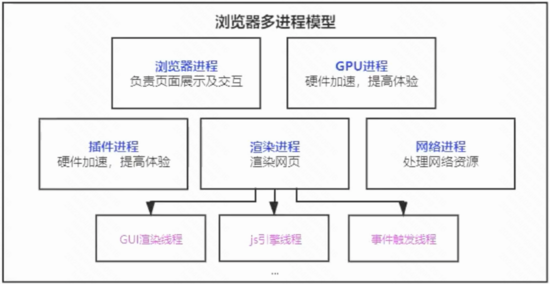
1、浏览器进程 负责界面展示、用户交互、子进程管理、提供存储等
2、渲染进程 每个页面都有一个单独的渲染进程,用于渲染页面,包含webworker线程
3、网络进程 主要处理网络资源加载(HTML、CSS、JS、IMAGE、AJAX等)
4、GPU进程 3D绘制,提高性能
5、插件进程 chrome插件,每个插件占用一个进程
渲染流程简析
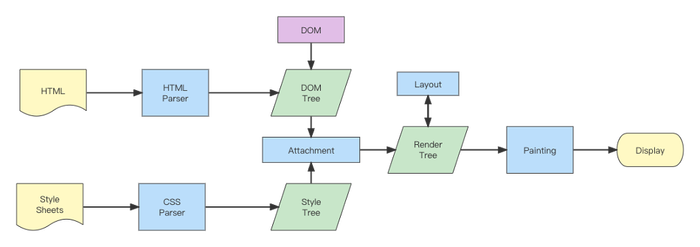
首先我们知道当网络进程接收到请求的响应头之后,如果检查到响应头中的 content-type 字段是text/html,那么会判断这是一个 HTML 类型的文件,也就会为该请求准备一个渲染进程,后续的页面渲染流水线也就在这个渲染进程中展开。我们可以把HTML代码看作浏览器页面UI构建初始DOM的蓝图。每当解析到脚本元素时,浏览器就会停止从HTML构建DOM,并开始执行Javascrip代码;接收到 CSS 文本时,会将 CSS 文本转换为浏览器可以理解的styleSheets。所以,渲染器进程的核心工作是将 HTML、CSS 和 JavaScript 转换为用户可以与之交互的网页。
1、HTML的解析
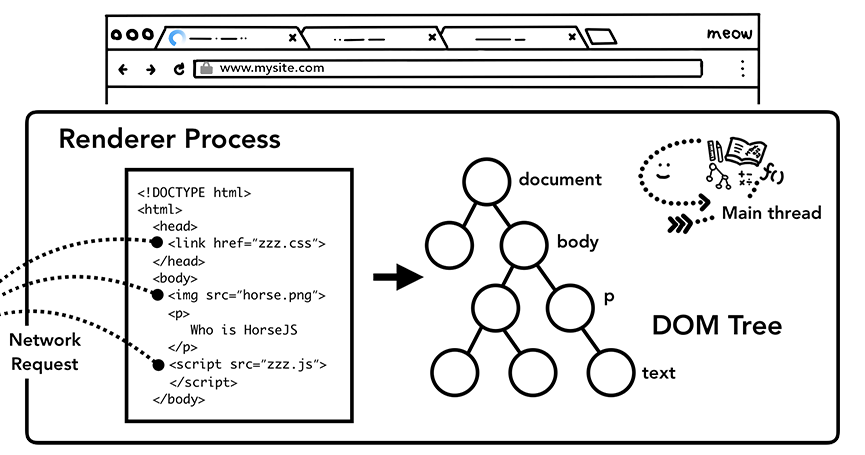
当渲染器进程收到导航的提交消息并开始接收 HTML 数据时,主线程开始解析文本字符串 (HTML) 并将其转换为文档对象模型 (DOM)。
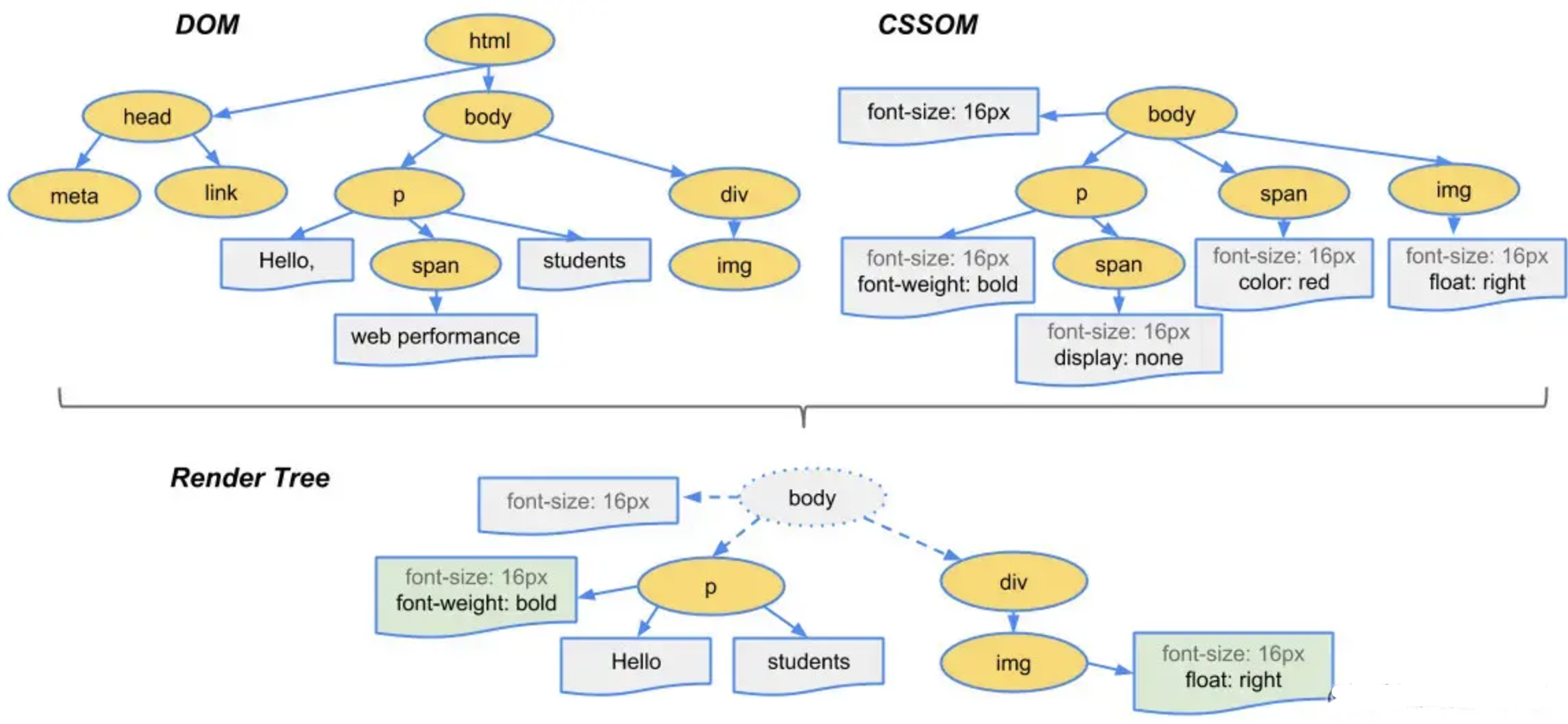
大概的解析流程是:当渲染器进程收到从网络进程中过来的字节流时,HTML解析器就会将字节流转换为多个Token( Tag Token 和文本 Token),Tag Token 又分 StartTag 和 EndTag,比如就是 StartTag ,就是EndTag 。然后通过维护一个Token 栈结构,不断的将新产生的 Token 压栈和出栈,把Token解析为 DOM 节点,并将 DOM 节点添加到 DOM 树中。
主线程解析HTML并构建DOM树
如果 HTML 文档中存在 img 或 link之类的内容,则预加载扫描器会查看 HTML 解析器生成的Token,并将请求发送到网络进程。
2、script的解析
当 HTML 解析器遇到script标签时,解析器会暂停 HTML 文档的解析,并必须加载、解析和执行 JavaScript 代码。 为什么? 因为 JavaScript 可以使用 document.write() 之类的东西来改变文档的形状,这会改变整个 DOM 结构。 这就是 HTML 解析器必须等待 JavaScript 运行才能继续解析 HTML 文档的原因。
3、css的解析
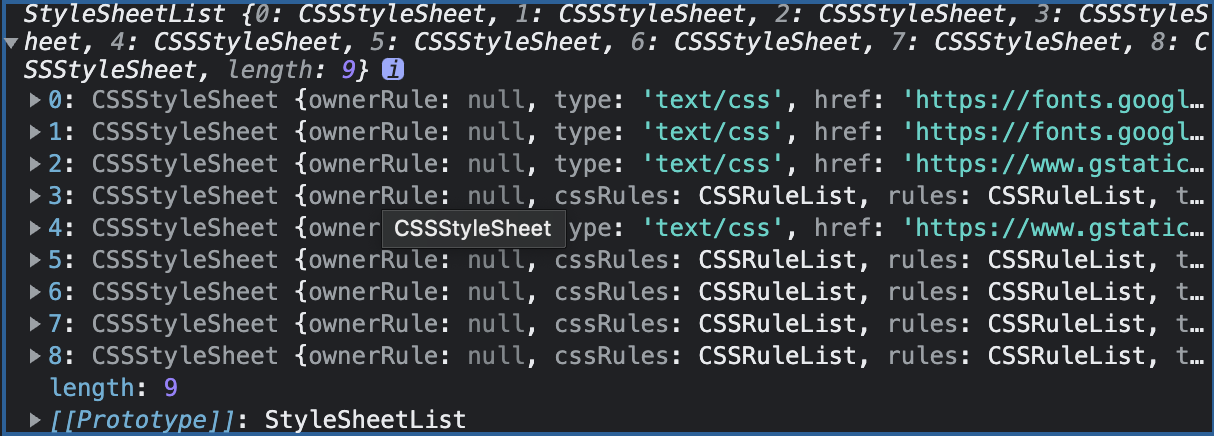
拥有 DOM 并不足以知道页面会是什么样子,因为我们可以在 CSS 中设置页面元素的样式。与HTML文件一样,浏览器无法直接理解纯文本的CSS样式,因此当渲染引擎接收到CSS文本时,它将执行转换操作,将CSS文本转换为浏览器可以理解的styleSheets,我们可以用document.styleSheets获取。
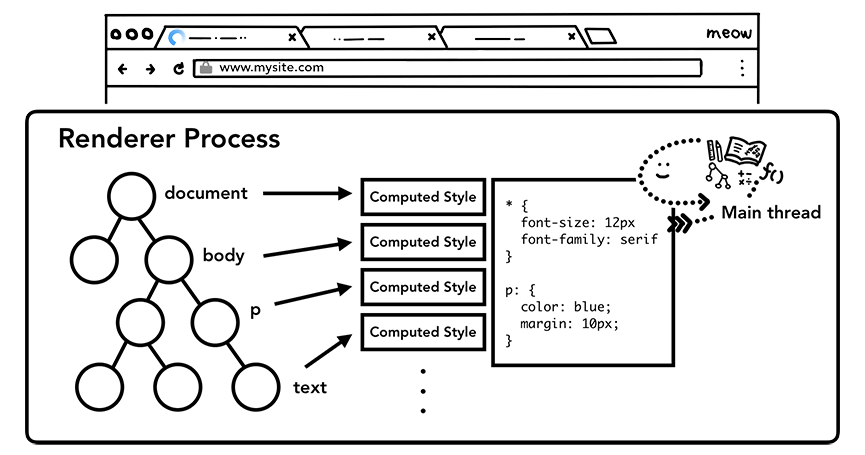
现在浏览器可以理解CSS样式表的结构了,再经过CSS属性值的标准化操作和加上CSS 的继承规则和层叠规则,我们就可以计算出 DOM 树中每个节点的具体样式。
主线程解析CSS,给DOM节点添加计算样式
4、布局
现在渲染器进程知道文档的结构和每个节点的样式,但这还不足以渲染页面,后续还要经过一个布局阶段。布局是一个寻找元素几何形状的过程。 主线程遍历 DOM 和计算样式,并创建布局树,其中包含 xy 坐标和边界框大小等信息。 布局树可能与 DOM 树的结构相似,但它只包含与页面上可见元素相关的信息。 如果有节点被应用了display: none ,那么该元素就不是布局树的一部分了。 类似地,如果应用了内容类似于p::before{content:”Hi!”} 的伪类,即使它不在 DOM 中,它也会包含在布局树中。
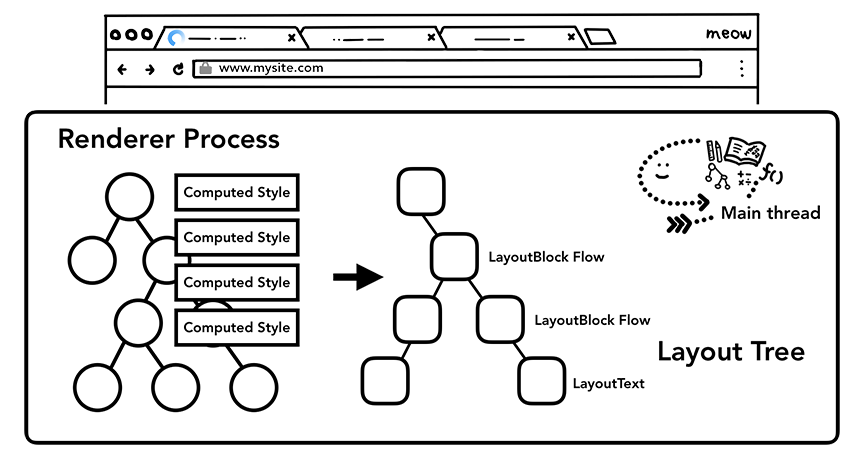
主线程使用计算样式遍历 DOM 树并生成布局树
5、绘制(Paint)
拥有 DOM、样式和布局树仍然不足以渲染页面,我们还需要知道绘制这些节点的顺序。比如,我们可能会为某些元素设置 z-index,在这种情况下,按照 HTML 中编写的元素顺序绘制将导致渲染不正确。在此绘制步骤中,主线程会遍历布局树以创建绘制记录。 绘画记录是对“先背景,后文字,再矩形”这样的绘画过程的记录。
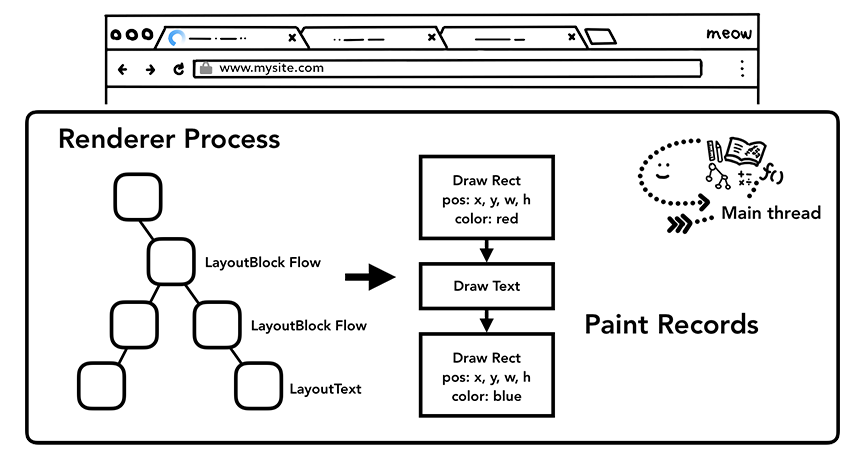
主线程遍历布局树并生成绘制记录
渲染流水线中最重要的一点是,在每一步都使用前一操作的结果来创建新数据。 例如,如果布局树中的某些内容发生了变化,则需要为文档的受影响部分重新生成绘制顺序。这就牵扯到了重绘和重排的概念,我们后续会说到。
6、合成
既然浏览器知道了文档的结构、每个元素的样式、页面的几何形状和绘制顺序,它如何绘制(draw)页面?处理这个问题最简单的方法是在视口内对部分进行光栅化(光栅化可以理解为把布局信息转换为屏幕上的像素)。 如果用户滚动页面,则移动光栅框架,并通过更多光栅(像素)填充缺失的部分。 这就是 Chrome 在首次发布时处理光栅化的方式。 然而,现代浏览器运行一个更复杂的过程,称为合成。
合成是一种将页面的各个部分分成多个图层,然后单独光栅化它们,并在一个叫做合成线程的单独线程中合成为一个页面的技术。 如果发生滚动,因为图层已经被光栅化,它所要做的就是合成一个新的帧。
a、分层
为了找出哪些元素需要在哪些层,主线程需要遍历布局树创建层树(LayerTree)。CSS 的transform动画、页面滚动,或者使用了 z-index 的页面节点都会生成专用的图层。
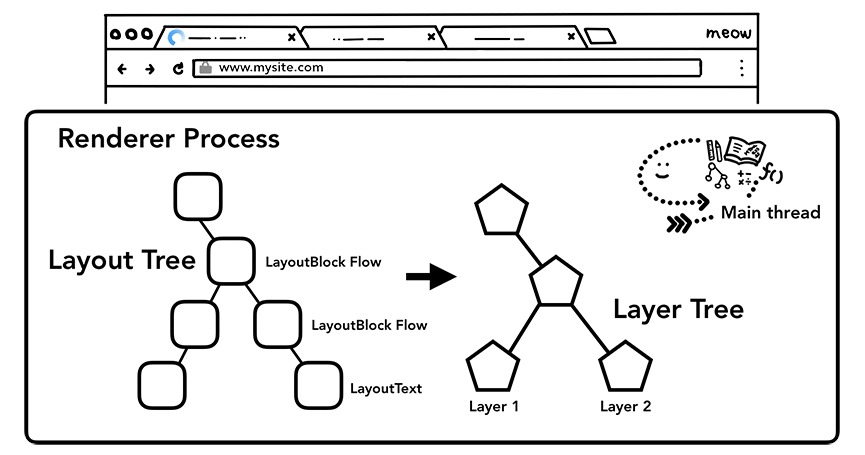
主线程遍历布局树生成层树
b、栅格化操作
一旦创建了层树并确定了绘制顺序,主线程就会将该信息提交给合成线程。 合成线程然后光栅化每一层。 一个图层可能像页面的整个长度一样大,因此合成线程将它们分成多个图块并将每个图块发送到光栅线程。 光栅线程光栅化每个图块并将它们存储在 GPU 内存中。
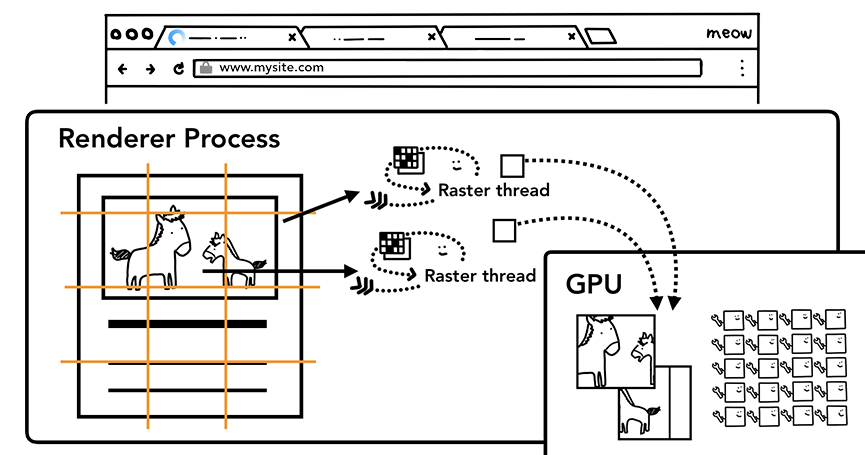
光栅线程创建出图块的位图并发送到GPU
合成线程可以对不同的光栅线程进行优先级排序,以便可以首先对视口内(或附近)的事物进行光栅化
c、合成显示
一旦所有图块都被光栅化,合成线程将会收集图块的信息(图块在内存中的位置信息和在页面绘制的位置信息),以此来生成一个合成帧(也就是页面的一个帧,该帧包含了所有图块的信息)。
这个合成帧就会通过IPC(进程间通信)被提交到浏览器进程,随后多个合成帧就会被送到GPU,以此来展示到屏幕上。如果有一个屏幕滚动事件,那么合成线程就会创建下一个合成帧,然后发送给GPU。
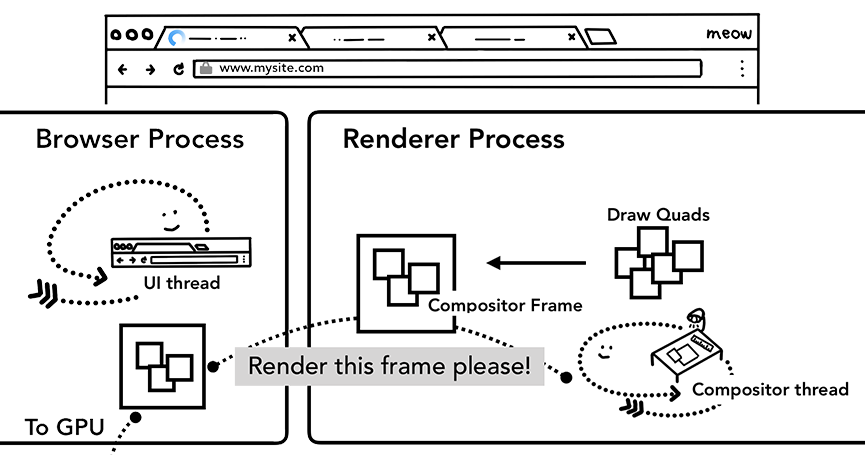
合成线程创建合成帧。帧被发送到浏览器进程然后到 GPU
自此我们从HTML,JS和CSS解析到页面帧的合成了解了一个页面的渲染流水线。那我们如何从这个过程中得到页面渲染的性能优化呢?
从渲染流水线得出的优化方法
我们可以从上面的渲染流水线中得到一下几个关键点:
1、渲染流水线中每一步都使用了前一操作的结果来创建新数据。 例如,如果布局树中的某些内容发生了变化,则需要为文档的受影响部分重新生成绘制顺序。
2、布局是一个寻找元素几何形状的过程。 主线程会遍历 DOM 和计算样式,并创建布局树。
3、页面帧的合成是在不涉及主线程的情况下完成的。合成线程不需要等待样式计算或 JavaScript 执行。
4、单个图层上有变动,渲染引擎会通过合成线程直接去处理变换,这些变换并不会涉及到主线程。
带着这几个关键点我们来看一下重排、重绘问题和CSS动画比 JavaScript 动画高效的原因:
-
重排:更新了元素的几何属性(高度等)。也就是说重排需要从布局阶段开始更新渲染流水线。
-
重绘:更新元素的绘制属性(字体颜色等),会直接进入了绘制阶段,省去了布局和分层阶段。
-
CSS动画高效的原因:如果我们用JS来做元素的动画,浏览器必须在每一帧之间运行这些操作。 我们的大多数显示器每秒刷新屏幕 60 次 (60 fps); 只有当每一帧在屏幕上移动物体时,动画对人眼来说才会显得平滑。如果我们的动画是用JS频繁的改变元素的几何属性,那么无疑我们会频繁的触发重排。即使我们的动画渲染操作跟上了屏幕刷新,JS的计算也在主线程上运行,它也可能会阻塞我们的页面。但是,如果我们使用CSS 的 transform 来实现动画效果,那么浏览器会单独给这个动画元素分为一个图层,那后续的变换效果是直接在合成线程上操作后,提交给了GPU。相比于JavaScript 动画需要JavaScript的执行和样式计算,CSS动画无疑是很高效的。
同时再说一个CSS的will-change属性,will-change为web开发者提供了一种告知浏览器该元素会有哪些变化的方法。用了它之后,浏览器就会给相关元素单独成为一个图层,等这些变换发生时,渲染引擎会通过合成线程直接去处理变换,从而提升了渲染效果。但是我们不能滥用这个属性,其中有一点就是图层信息是存在内存中的,过多的图层可能导致页面响应缓慢或者消耗非常多的资源。
流式渲染
渲染流水线的源头就是渲染进程收到从网络进程中过来的响应为text/html的字节流响应。其实渲染进程和网络进程之间会建立一个共享数据的管道,网络进程接收到数据后就往这个管道里面放,而渲染进程则从管道的另外一端不断地读取数据,将其解析为 DOM。也就是说浏览器解析DOM时,不是等拿到整个HTML才开始渲染的,这也是浏览器的渐进式 HTML 渲染功能。
为了充分利用浏览器的这个能力,我们使用服务端渲染(SSR)的同时,可以采用服务端的流式渲染。流式服务端渲染允许我们以块的形式发送 HTML,浏览器可以在接收到时就可以逐步呈现HTML。 这可以极大的提高FP(First Paint)和FCP (First Contentful Paint)指标。 在 React 的SSR中,我们用renderToNodeStream来实现异步的流,这样我们也可以大大的提高页面首字节响应。
除了服务端的流式渲染,我们还可以使用Service Worker来实现流式响应。
self.addEventListener('fetch', event => {
var stream = new ReadableStream({
start(controller) {
if (/* there's more data */) {
controller.enqueue(/* your data here */);
} else {
controller.close();
}
});
});
var response = new Response(stream, {
headers: {'content-type': /* your content-type here */}
});
event.respondWith(response);
});
一旦 event.respondWith() 被调用,其请求触发了 fetch 事件的页面就会得到一个流响应,并且只要 Service Worker继续 enqueue() 附加数据,它就会继续从该流中读取。 从 Service Worker 流向页面的响应是真正异步的,我们可以完全控制填充流。
也就是如果我们把服务端流式响应的动态数据再加上通过Service Worker实现的流式响应的缓存数据,就真正做到了流式的快速响应。
时序优化
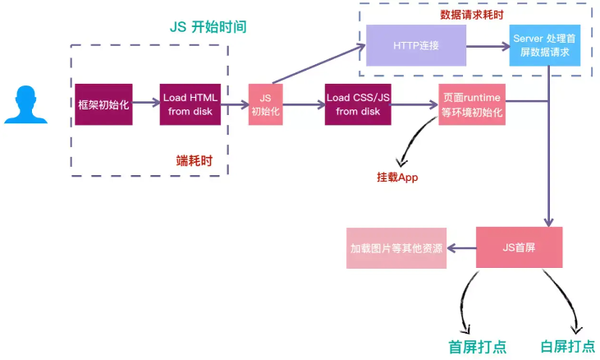
首屏渲染中,关注必要的数据请求接口,缩短关键路径长度。
比如页面中初始化的接口,可以采用极简的代码在页面 head 处执行,获取返回数据缓存到内存中,等到业务代码加载执行时可以直接获取缓存数据,理想情况下,就可以节省整个请求的耗时。
这类接口提前对于依赖初始化接口的页面做性能优化非常有效。
CSS 策略
想要优化 CSS 的性能,我们首先需要了解 CSS 的渲染规则,CSS 选择器是从右向左进行匹配的。
看个示例:
#block .text p {
color: red;
}
1、查找所有 P 元素。
2、查找结果 1 中的元素是否有类名为 text 的父元素
3、查找结果 2 中的元素是否有 id 为 block 的父元素
CSS 中更多的选择器是不会匹配的,所以在考虑性能问题时,需要考虑的是如何在选择器不匹配时提升效率。从右向左匹配就是为了达成这一目的的,通过这一策略能够使得 CSS 选择器在不匹配的时候效率更高。这样想来,在匹配时多耗费一些性能也能够想的通了。
-
避免出现超过三层的嵌套规则:元素的嵌套层级不能超过 3 级,过度的嵌套会导致代码变得臃肿,沉余,复杂。导致 css 文件体积变大,造成性能浪费,影响渲染的速度!而且过于依赖 HTML 文档结构。这样的 css 样式,维护起来,极度麻烦。
-
避免为 ID 选择器添加多余选择器:在 ID 选择器前面嵌套其它选择器纯粹是多余的。
-
避免使用通配选择器,只对目标节点声明规则。
-
避免重复匹配重复定义,关注可继承属性。
Dom 离线化
所谓的 Dom 离线化就是将要操作的元素从文档流中脱离,然后再恢复它。离线的 DOM 不属于当前 DOM 树中的任何一部分,这也就意味着我们对离线 DOM 处理就不会引起页面的回流与重绘。可以使用display: none,上面我们说到了 (display: none) 将元素从渲染树中完全移除,元素既不可见,也不是布局的组成部分,之后在该 DOM 上的操作不会触发回流与重绘,操作完之后再将 display 属性改为显示,只会触发这一次回流与重绘。
SSR
在 SPA 模式下,所有的数据请求和 Dom 渲染都在浏览器端完成,所以当我们第一次访问页面的时候很可能会存在“白屏”等待,而服务端渲染所有数据请求和 html 内容已在服务端处理完成,浏览器收到的是完整的 html 内容,可以更快的看到渲染内容,在服务端完成数据请求肯定是要比在浏览器端效率要高的多。
SSR 对 SEO 是相对友好的,有些网站的流量来源主要还是靠搜索引擎,所以网站的 SEO 还是很重要的,而 SPA 模式对搜索引擎不够友好,要想彻底解决这个问题只能采用服务端直出。
当然,SSR 也会带了很多额外的工作量,而且会很大程度上增加项目的复杂度,这里需要做一个工作量与优化之间的权衡~
节流和防抖
防抖(debounce)
防止抖动,单位时间内事件触发会被重置,避免事件被误伤触发多次。代码实现重在清零 clearTimeout。防抖可以比作等电梯,只要有一个人进来,就需要再等一会儿。业务场景有避免登录按钮多次点击的重复提交。
// 在事件被触发n秒后再执行回调,如果在这n秒内又被触发,则重新计时。
function debounce(func, delay) {
let time = null;
return function (...args) {
const context = this;
if (time) {
clearTimeout(time);
}
time = setTimeout(() => {
func.call(context, ...args);
}, delay);
};
}
节流(throttle)
控制流量,单位时间内事件只能触发一次,与服务器端的限流 (Rate Limit) 类似。代码实现重在开锁关锁 timer=timeout; timer=null。节流可以比作过红绿灯,每等一个红灯时间就可以过一批。
// 规定在一个单位时间内,只能触发一次函数。如果这个单位时间内触发多次函数,只有一次生效。
function throttle(func, delay) {
let prevTime = Date.now();
return function (...args) {
const context = this;
let curTime = Date.now();
if (curTime - prevTime > delay) {
prevTime = curTime;
func.call(context, ...args);
}
};
}
Web Worker
Web Worker 是 HTML5 标准的一部分,这一规范定义了一套 API,它允许一段 JavaScript 程序运行在主线程之外的另外一个线程中。可以加载一个 JS 进行大量的复杂计算而不挂起主进程,并通过 postMessage,onmessage 进行通信,解决了大量计算对 UI 渲染的阻塞问题。
Skeleton
在FCP 和 FMP 之间虽然开始绘制页面,但是整个页面是没有意义的,用户依然在焦虑等待,而且这个时候可能出现乱序的元素或者闪烁的元素,很影响体验,此时我们可能需要进行用户体验上的一些优化。
Skeleton是一个好方法,Skeleton现在已经很开始被广泛应用了,它的意义在于事先撑开即将渲染的元素,避免闪屏,同时提示用户这要渲染东西了,较少用户焦虑。
比如微博的Skeleton就做的很不错
在不同框架上都有相应的Skeleton实现
以 vue-cli 3 为例,我们可以直接在vue.config.js 中配置
//引入插件
const SkeletonWebpackPlugin = require('vue-skeleton-webpack-plugin');
module.exports = {
// 额外配置参考官方文档
configureWebpack: (config)=>{
config.plugins.push(new SkeletonWebpackPlugin({
webpackConfig: {
entry: {
app: path.join(__dirname, './src/Skeleton.js'),
},
},
minimize: true,
quiet: true,
}))
},
//这个是让骨架屏的css分离,直接作为内联style处理到html里,提高载入速度
css: {
extract: true,
sourceMap: false,
modules: false
}
}
然后就是基本的 vue 文件编写了,直接看文档即可。
keep-alive
对于使用 vue 的开发者 keep-alive 这个 API 应该是最熟悉不过了,keep-alive 的作用是在页面已经跳转后依然不销毁组件,保存组件对应的实例在内存中,当此页面再次需要渲染的时候就可以利用已经缓存的组件实例了。
如果大量实例不销毁保存在内存中,那么这个 API 存在内存泄漏的风险,所以要注意调用deactivated销毁
但是在 React 中并没有对应的实现,而官方 issue 中官方也明确不会添加类似的 API,但是给出了两个自行实现的方法
1、利用全局状态管理工具例如 redux 进行状态缓存
2、利用 style= 进行控制
如果你看了这两个建议就知道不靠谱,redux 已经足够啰嗦了,我们为了缓存状态而利用 redux 这种全局方案,其额外的工作量和复杂度提升是得不偿失的,用 dispaly 控制显示是个很简单的方法,但是也足够粗暴,我们会损失很多可操作的空间,比如动画。
react-keep-alive 在一定程度上解决这个问题,它的原理是利用React 的 Portals API 将缓存组件挂载到根节点以外的 dom 上,在需要恢复的时候再将缓存组件挂在到相应节点上,同时也可以在额外的生命周期 componentWillUnactivate 进行销毁处理。
不要覆盖原生方法
无论你的 JavaScript 代码如何优化,都比不上原生方法。因为原生方法是用低级语言写的(C/C++),并且被编译成机器码,成为浏览器的一部分。当原生方法可用时,尽量使用它们,特别是数学运算和 DOM 操作。
使用事件委托(简化DOM操作)
<ul>
<li>苹果</li>
<li>香蕉</li>
<li>凤梨</li>
</ul>
<script>
// good
document.querySelector('ul').onclick = (event) => {
const target = event.target
if (target.nodeName === 'LI') {
console.log(target.innerHTML)
}
}
// bad
document.querySelectorAll('li').forEach((e) => {
e.onclick = function() {
console.log(this.innerHTML)
}
})
</script>
JS动画
尽量避免添加大量的JS动画,CSS3动画和 Canvas 动画都比 JS 动画性能好。
使用requestAnimationFrame来代替setTimeout和setInterval,因为requestAnimationFrame可以在正确的时间进行渲染,setTimeout 和setInterval无法保证渲染时机。不要在定时器里面绑定事件。
利用线上监控定位性能问题
了解全面的优化措施固然重要,但把每个措施都做一遍并不一定能够高效地解决站点面临的关键性能问题。如何立竿见影、具有针对性的去优化?通过还原用户加载时的情况来帮助定位性能问题是一个思路。

我们可以借助性能衡量指标来做一个性能监控平台,一个好的监控平台,往往有以下功能:
-
数据可视化:可以直观的看到各业务的实时数据大盘
-
慢加载追踪:提供慢页面列表和多维度数据
-
性能瓶颈定位:可以针对性的查看某个用户访问路径,查看用户各节点的性能瓶颈
-
性能报警:性能报告和线上报警
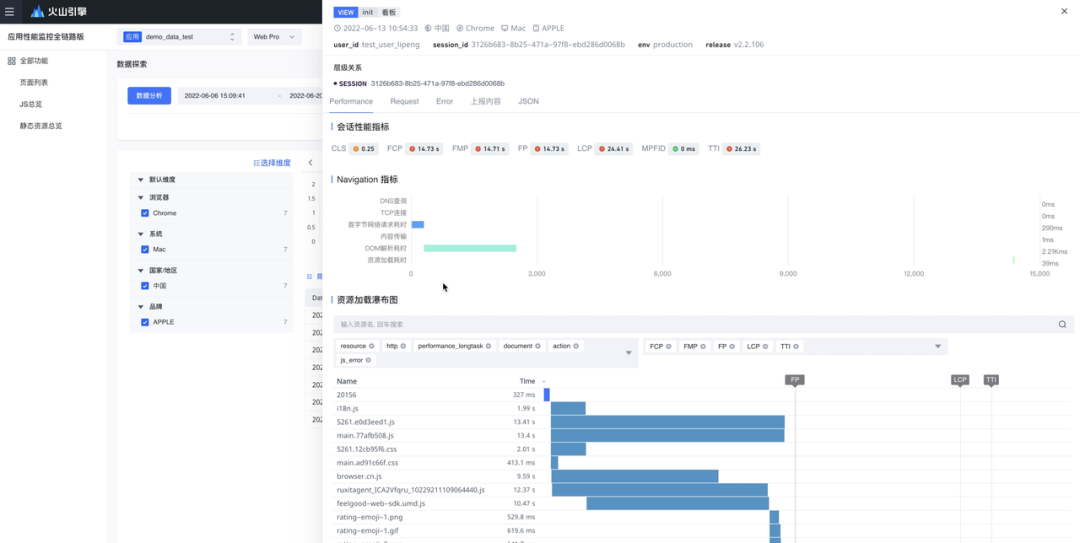
一般情况下,前端监控除了监控性能指标以外,还会监控请求和资源的加载以及 Long tasks 等数据,这些数据可以帮助还原用户的加载现场,帮助找到蛛丝马迹。
比如下面这个例子, 多项性能指标都很差。通过监控平台还原出的资源加载瀑布图,可以看出绝大部分时间都耗在了拉取资源上。那么就可以初步得出性能优化方案,将优化措施侧重在资源优化上,比如缩小JS文件体积、延迟加载未使用的JS代码等等。