RPC详解
RPC(Remote Procedure Call),即远程过程调用。RPC 的核心目的是实现进程间通信,在分布式环境中广泛应用。RPC 框架面向开发者屏蔽了网络底层逻辑,使远程调用可以像本地调用一样方便。
本地调用
假设你有一个Calculator,那么单体应用时,要调用Calculator的add方法来执行一个加运算,你可以方法中直接使用,因为在同一个地址空间,或者说在同一块内存,这个称为本地函数调用。
func main() {
var a = 2
var b = 3
result = Calculator.add(a, b)
fmt.Println(result)
return
}
calsee Calculator {
add(x, y) {
z = x * y
return z
}
}
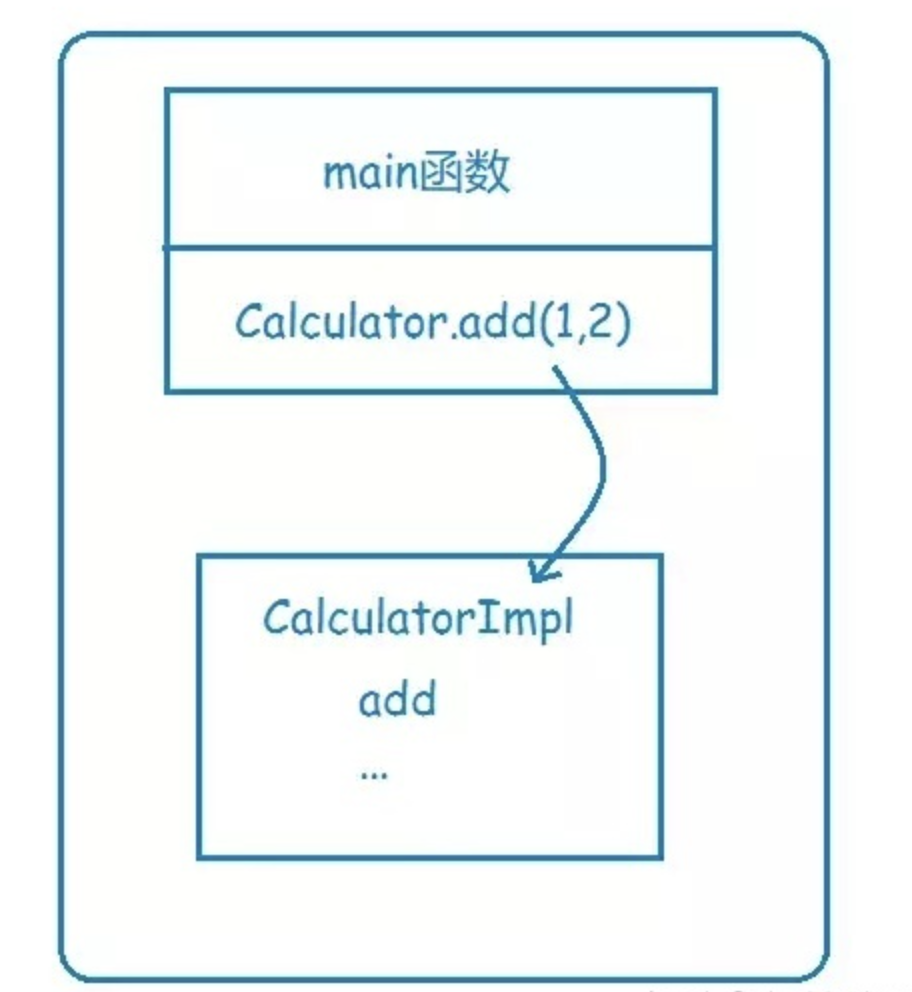
执行过程:
1、将a和b的值压栈
2、通过函数指针找到calculate函数,进入函数取出栈中的值2和3,将其赋予x和y
3、计算x*y,并将结果存在z
4、将z的值压栈,然后从calculate返回
5、从栈中取出z返回值,并赋值给result
远程调用
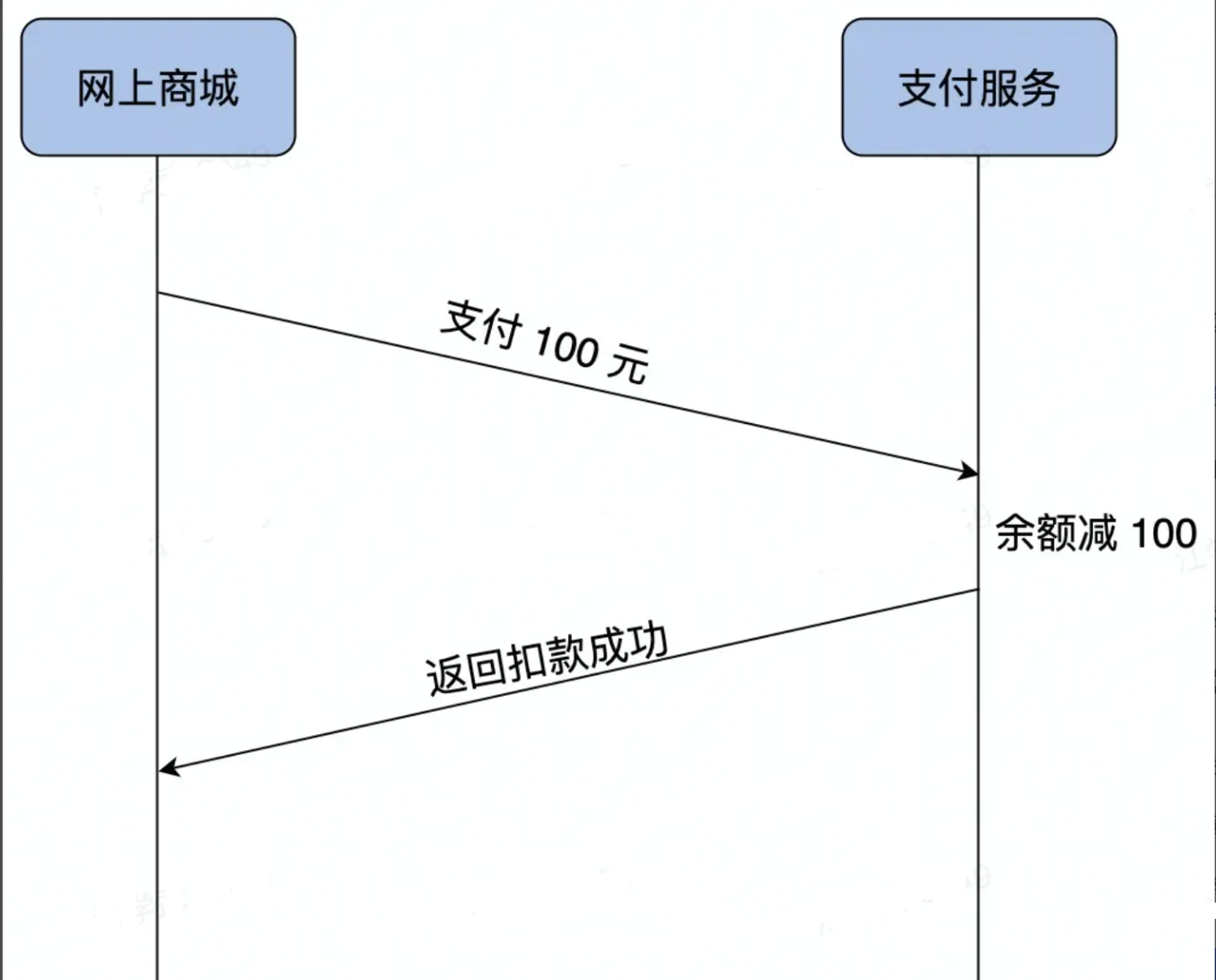
软件系统越来越复杂,从单机走向了分布式(集群/分布式/异地 部署),就需要支持分布式环境下的通信技术和方案。

1、TCP/UDP:最基础最底层的通信方式,所有应用层通信协议都基于 TCP/UDP。
2、CORBA:底层结构基于面向对象模型。曾经是分布式环境解决互联的主流技术,开发和部署成本较高,现已基本被遗弃。
3、Web Service:基于 HTTP + XML 的标准化 Web API,传统行业的信息系统仍在广泛使用。
4、RESTful:基于 HTTP,可以使用 XM格式定义或JSON格式定义。
5、RMI(Remote Method Invocation):Java 提供的远程方法调用。
6、MQ(Message Queue):消息队列(消息中间件),包括对JMS提供支持。
7、RPC(Remote Procedure Call):远程过程调用,使远程调用像本地调用一样方便。
TCP
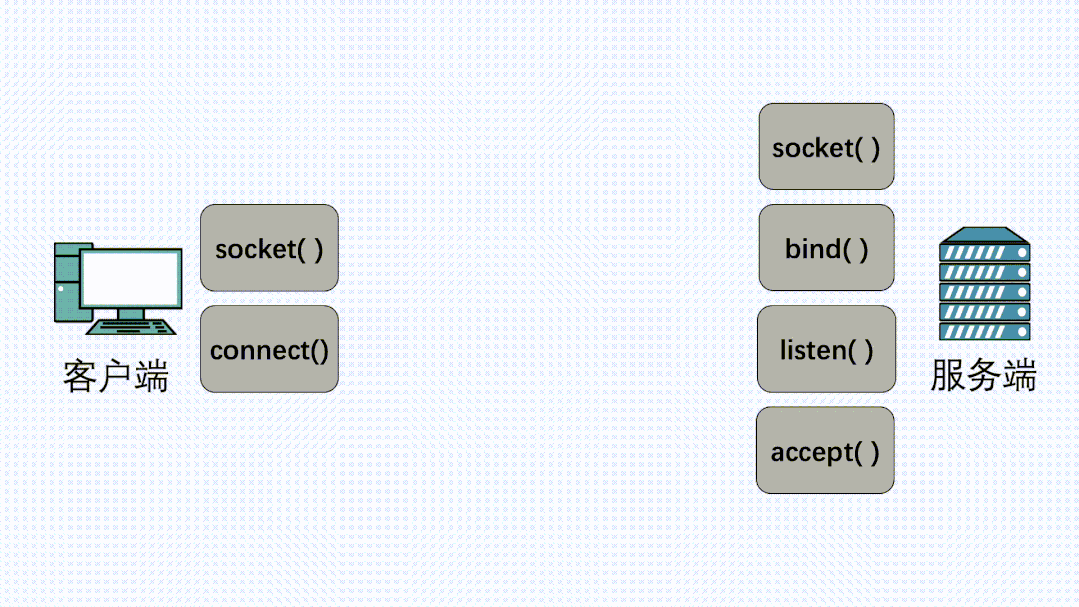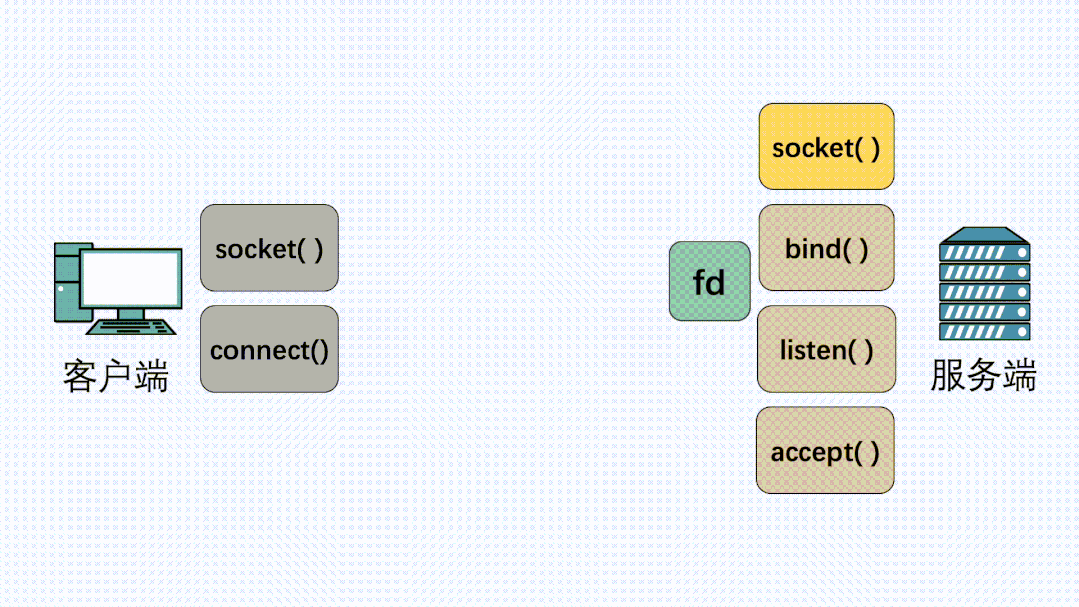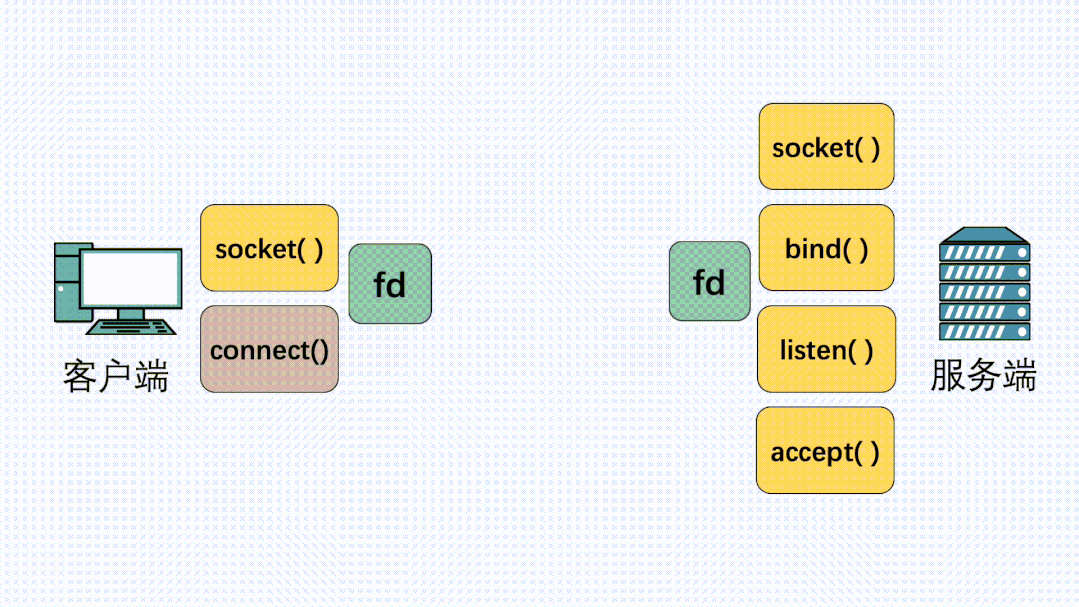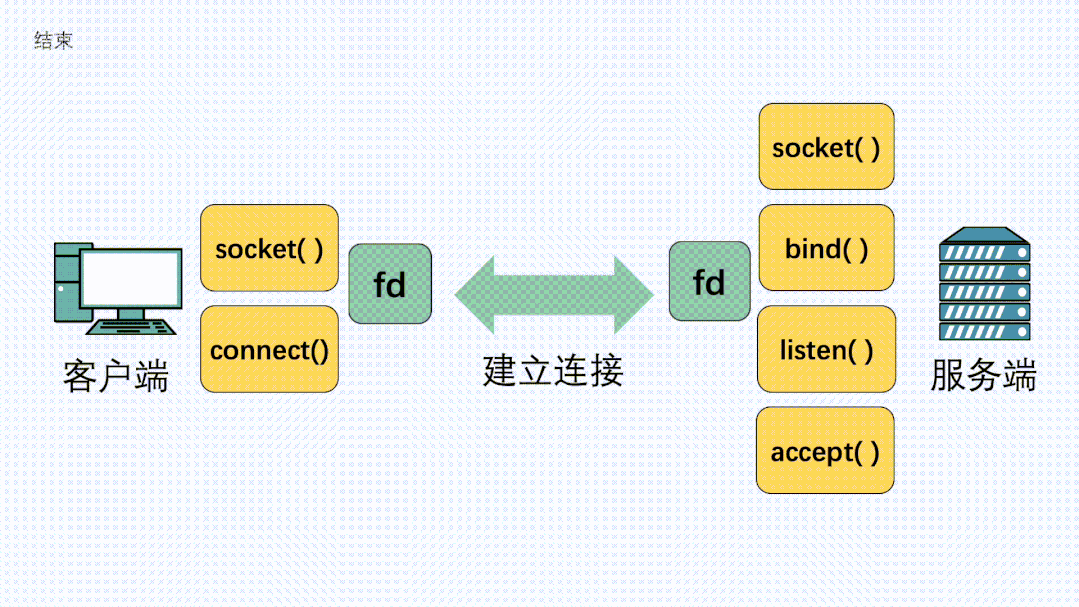
作为一个程序员,假设我们需要在 A 电脑的进程发一段数据到 B 电脑的进程,我们一般会在代码里使用 Socket 进行编程。
这时候,我们可选项一般也就 TCP 和 UDP 二选一。TCP 可靠,UDP 不可靠。除非是马总这种神级程序员(早期 QQ 大量使用 UDP),否则,只要稍微对可靠性有些要求,普通人一般无脑选 TCP 就对了。
类似下面这样。
fd = socket(AF_INET,SOCK_STREAM,0);
其中 SOCK_STREAM,是指使用字节流传输数据,说白了就是 TCP 协议。
在定义了 Socket 之后,我们就可以愉快的对这个 Socket 进行操作,比如用 bind() 绑定 IP 端口,用 connect() 发起建连。
在连接建立之后,我们就可以使用 send() 发送数据,recv() 接收数据。
光这样一个纯裸的 TCP 连接,就可以做到收发数据了,那是不是就够了?
不行,这么用会有问题。
使用纯裸 TCP 会有什么问题
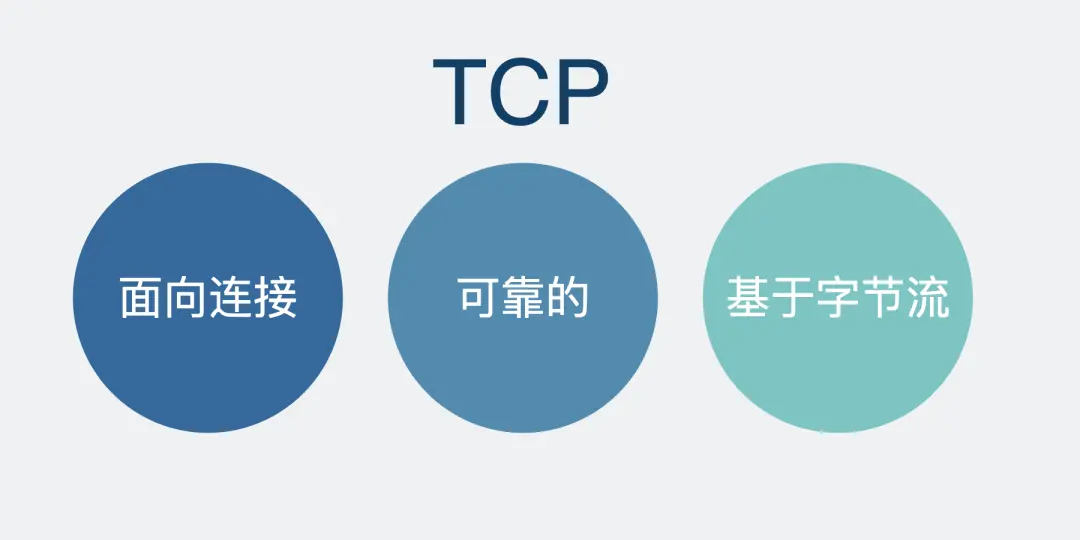
八股文常背,TCP 是有三个特点,面向连接、可靠、基于字节流。
这三个特点真的概括的非常精辟,这个八股文我们没白背。
每个特点展开都能聊一篇文章,而今天我们需要关注的是基于字节流这一点。
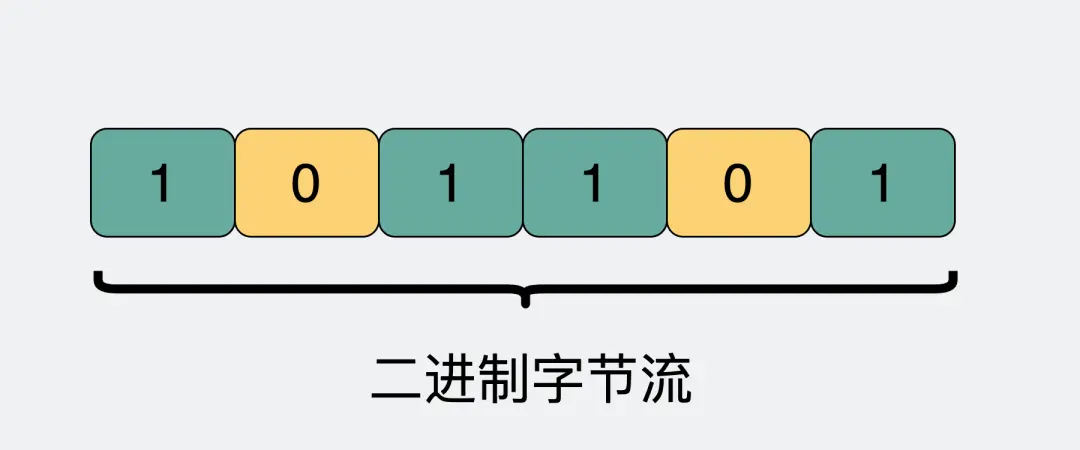
字节流可以理解为一个双向的通道里流淌的数据,这个数据其实就是我们常说的二进制数据,简单来说就是一大堆 01 串。纯裸 TCP 收发的这些 01 串之间是没有任何边界的,你根本不知道到哪个地方才算一条完整消息。
正因为这个没有任何边界的特点,所以当我们选择使用 TCP 发送”夏洛”和”特烦恼”的时候,接收端收到的就是”夏洛特烦恼”,这时候接收端没发区分你是想要表达”夏洛”+”特烦恼”还是”夏洛特”+”烦恼”。
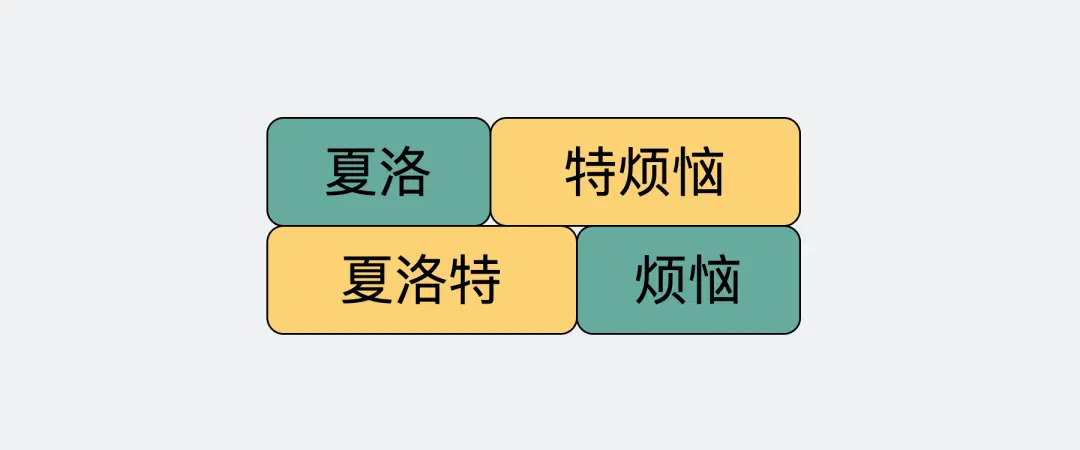
这就是所谓的粘包问题,说这个的目的是为了告诉大家,纯裸 TCP 是不能直接拿来用的,你需要在这个基础上加入一些自定义的规则,用于区分消息边界。
于是我们会把每条要发送的数据都包装一下,比如加入消息头,消息头里写清楚一个完整的包长度是多少,根据这个长度可以继续接收数据,截取出来后它们就是我们真正要传输的消息体。

而这里头提到的消息头,还可以放各种东西,比如消息体是否被压缩过和消息体格式之类的,只要上下游都约定好了,互相都认就可以了,这就是所谓的协议。
每个使用 TCP 的项目都可能会定义一套类似这样的协议解析标准,他们可能有区别,但原理都类似。
于是基于 TCP,就衍生了非常多的协议,比如 HTTP 和 RPC。
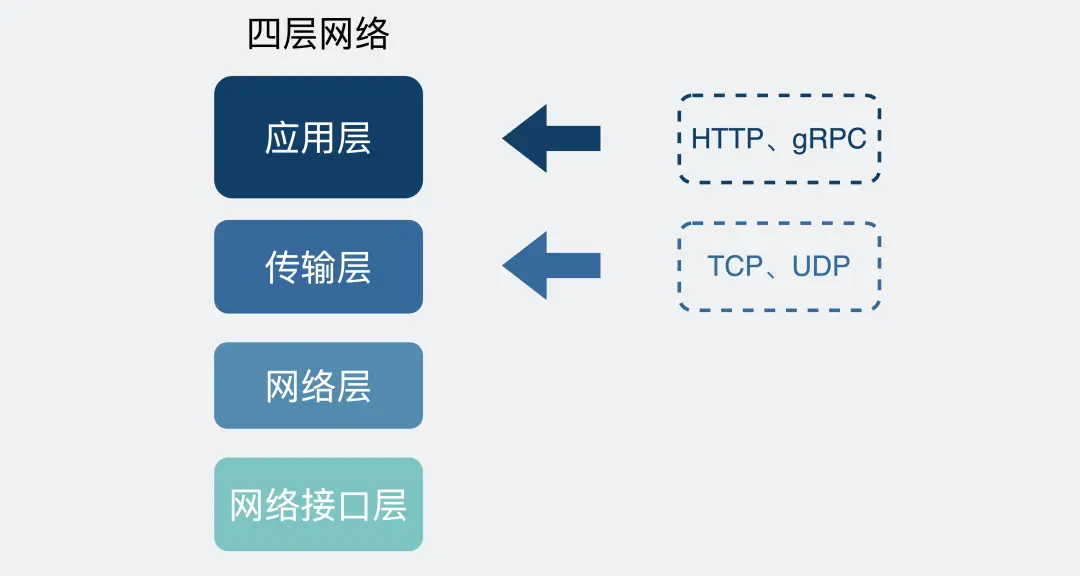
TCP 是传输层的协议,而基于 TCP 造出来的 HTTP 和各类 RPC 协议,它们都只是定义了不同消息格式的应用层协议而已。
Web Service
Web Service 指 W3C组织制定的web service规范技术。其包括:
-
SOAP:一个基于XML的可扩展消息信封格式,需同时绑定一个网络传输协议。这个协议通常是HTTP或HTTPS,但也可能是SMTP或XMPP
-
WSDL:一个XML格式文档,用以描述服务端口访问方式和使用协议的细节。通常用来辅助生成服务器和客户端代码及配置信息
-
UDDI:一个用来发布和搜索WEB服务的协议,应用程序可借由此协议在设计或运行时找到目标WEB服务
从上面三个定义就可以看出,这种规范技术是一个重量级的协议。
SOAP
SOAP是基于XML数据格式来交换数据的;其内部定义了一套复杂完善的XML标签,标签中包含了调用的远程过程、参数、返回值和出错信息等等,通信双方根据这套标签来解析数据或者请求服务。与SOAP相关的配套协议是WSDL (Web Service Description Language),用来描述哪个服务器提供什么服务,怎样找到它,以及该服务使用怎样的接口规范,类似我们现在聊服务治理中的服务发现功能。
SOAP服务整体流程是:
1)获得该服务的WSDL描述,根据WSDL构造一条格式化的SOAP请求发送给服务器,
2)接收一条同样SOAP格式的应答,
3)根据先前的WSDL解码数据。
绝大多数情况下,请求和应答使用HTTP协议传输,那么发送请求就使用HTTP的POST方法。
REST
由于SOAP方案过于庞大复杂,在很多简单的web服务应用场景中,轻量级的REST就出现替代SOAP方案了。
REST 是基于 HTTP 实现,使用 HTTP 协议处理数据通信,更加标准化与通用,因为无论哪种语言都支持 HTTP 协议。常见的 http API 都可以称为 Rest 接口。REST 是一种架构风格,指一组架构约束条件和原则,满足 REST 原则的应用程序或设计就是 RESTful,RESTful 把一切内容都视为资源。REST 强调组件交互的扩展性、接口的通用性、组件的独立部署、以及减少交互延迟的中间件,它强化安全,也能封装遗留系统。
HTTP 协议(Hyper Text Transfer Protocol),又叫做超文本传输协议。我们用的比较多,平时上网在浏览器上敲个网址就能访问网页,这里用到的就是 HTTP 协议。
特点
REST 的几个特点为:资源、统一接口、URI 和无状态。
①资源
所谓”资源”,就是网络上的一个实体,或者说是网络上的一个具体信息。它可以是一段文本、一张图片、一首歌曲、一种服务,就是一个具体的实在。
②统一接口
RESTful 架构风格规定,数据的元操作,即 CRUD(Create,Read,Update 和 Delete,即数据的增删查改)操作,分别对应于 HTTP 方法:GET 用来获取资源,POST 用来新建资源(也可以用于更新资源),PUT 用来更新资源,DELETE 用来删除资源,这样就统一了数据操作的接口,仅通过 HTTP 方法,就可以完成对数据的所有增删查改工作。
③URL
可以用一个 URI(统一资源定位符)指向资源,即每个 URI 都对应一个特定的资源。
要获取这个资源,访问它的 URI 就可以,因此 URI 就成了每一个资源的地址或识别符。
④无状态
所谓无状态的,即所有的资源,都可以通过 URI 定位,而且这个定位与其他资源无关,也不会因为其他资源的变化而改变。有状态和无状态的区别,举个简单的例子说明一下。
如查询员工的工资,如果查询工资是需要登录系统,进入查询工资的页面,执行相关操作后,获取工资的多少,则这种情况是有状态的。
因为查询工资的每一步操作都依赖于前一步操作,只要前置操作不成功,后续操作就无法执行。
如果输入一个 URI 即可得到指定员工的工资,则这种情况是无状态的,因为获取工资不依赖于其他资源或状态。
且这种情况下,员工工资是一个资源,由一个 URI 与之对应,可以通过 HTTP 中的 GET 方法得到资源,这是典型的 RESTful 风格。
RMI
Java 原生就有一套远程调用框架 叫做 RMI(Remote Method Invocation), 它可以让 Java 程序通过网络,调用另一台机器上的 Java 对象的方法。它是一种远程调用的方法,也是 J2EE 时代大名鼎鼎的 EJB 的实现基础。

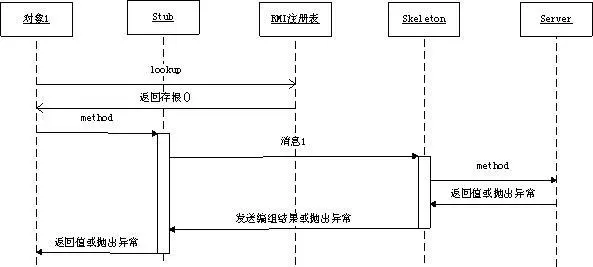
概念说明:
-
stub(桩):stub实际上就是远程过程在客户端上面的一个代理proxy。当我们的客户端代码调用API接口提供的方法的时候,RMI生成的stub代码块会将请求数据序列化,交给远程服务端处理,然后将结果反序列化之后返回给客户端的代码。这些处理过程,对于客户端来说,基本是透明无感知的。
-
remote:这层就是底层网络处理了,RMI对用户来说,屏蔽了这层细节。stub通过remote来和远程服务端进行通信。
-
skeleton(骨架):和stub相似,skeleton则是服务端生成的一个代理proxy。当客户端通过stub发送请求到服务端,则交给skeleton来处理,其会根据指定的服务方法来反序列化请求,然后调用具体方法执行,最后将结果返回给客户端。
-
registry(服务发现):借助JNDI发布并调用了rmi服务。实际上,JNDI就是一个注册表,服务端将服务对象放入到注册表中,客户端从注册表中获取服务对象。rmi服务,在服务端实现之后需要注册到rmi server上,然后客户端从指定的rmi地址上lookup服务,调用该服务对应的方法即可完成远程方法调用。registry是个很重要的功能,当服务端开发完服务之后,要对外暴露,如果没有服务注册,则客户端是无从调用的,即使服务端的服务就在那里。
时至今日,你仍然可以通过 Spring 的 RmiServiceExporter 将 Spring 管理的 bean 暴露成一个 RMI 的服务,从而继续使用 RMI 来实现跨进程的方法调用。之所以 RMI 没有像 Dubbo,Grpc 一样大火, 是因为它存在着一些缺陷:
-
RMI 使用专为 Java 远程对象定制的协议 JRMP(Java Remote Messaging Protocol)进行通信,这限制了它的通信双方,只能是 Java 语言的程序,无法实现跨语言通信;
-
RMI 使用 Java 原生的对象序列化方式,生成的字节数组空间较大,效率很差。
RPC 概述
RPC(Remote Procedure Call)远程过程调用,在分布式应用中,RPC 是一个计算机通信协议,是一种进程间通信的模式。该协议允许运行于一台计算机的程序调用另一个地址空间(通常为一个开放网络的一台计算机)的程序,而程序员就像调用本地程序一样,无需关注底层网络通信的实现。
RPC 是一种服务器 / 客户端(Client/Server)模式,经典实现是一个通过发送请求-接受回应进行信息交互的系统。
RPC家族中,RMI是Java制定的远程通信协议。RMI既然是Java的标准RPC组件,那必然其他编程语言就无法使用了;因此,Thrift这种基于IDL来跨语言的RPC组件就出现了。Thrift的使用者,只需要按照Thrift官方规定的方式来写API结构,然后生成对应语言的API接口,继而就可以跨语言完成远程过程调用了。但是,作为服务化的组件,如果没有服务治理来完成大规模应用集群中服务调用管理工作,则运维工作则是非常繁重的,因此类似dubbo这种包含服务治理的RPC组件出现了。
完整框架
在一个典型 RPC 的使用场景中,包含了服务发现、负载、容错、网络传输、序列化等组件,其中“RPC 协议”就指明了程序如何进行网络传输和序列化。
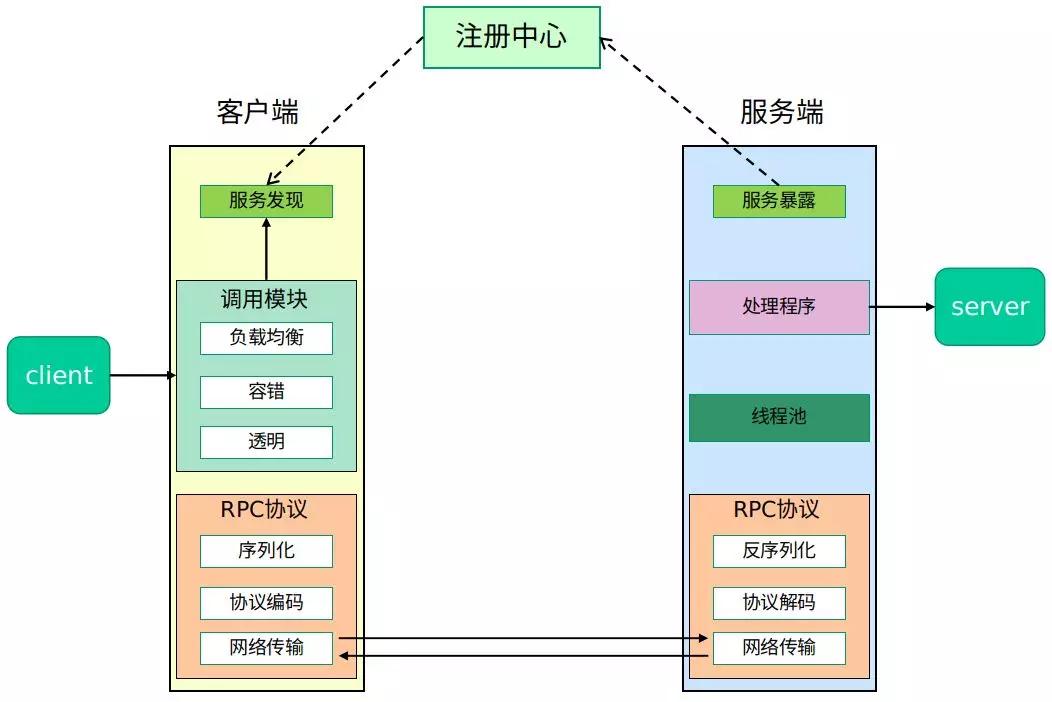
核心功能
RPC 的核心功能是指实现一个 RPC 最重要的功能模块,就是上图中的”RPC 协议”部分:

一个 RPC 的核心功能主要有 5 个部分组成,分别是:客户端、客户端 Stub、网络传输模块、服务端 Stub、服务端等。
下面分别介绍核心 RPC 框架的重要组成:
-
客户端(Client):服务调用方。
-
客户端存根(Client Stub):存放服务端地址信息,将客户端的请求参数数据信息打包成网络消息,再通过网络传输发送给服务端。
-
服务端存根(Server Stub):接收客户端发送过来的请求消息并进行解包,然后再调用本地服务进行处理。
-
服务端(Server):服务的真正提供者。
-
Network Service:底层传输,可以是 TCP 或 HTTP。
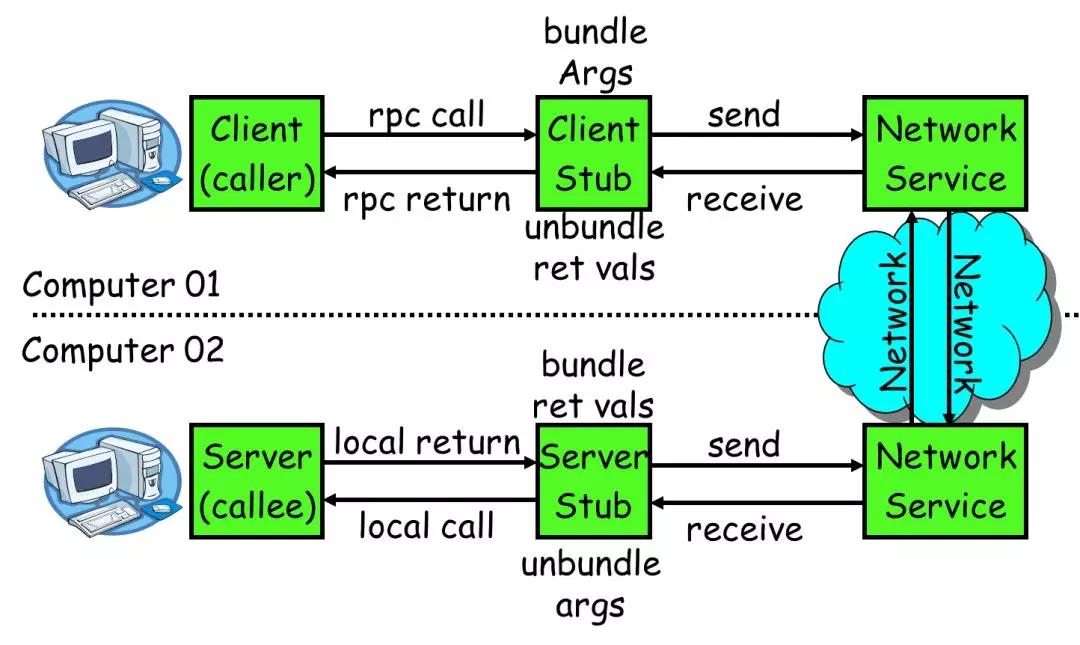
调用过程
RPC实现过程中流程和分工角色可以用下图来表示:
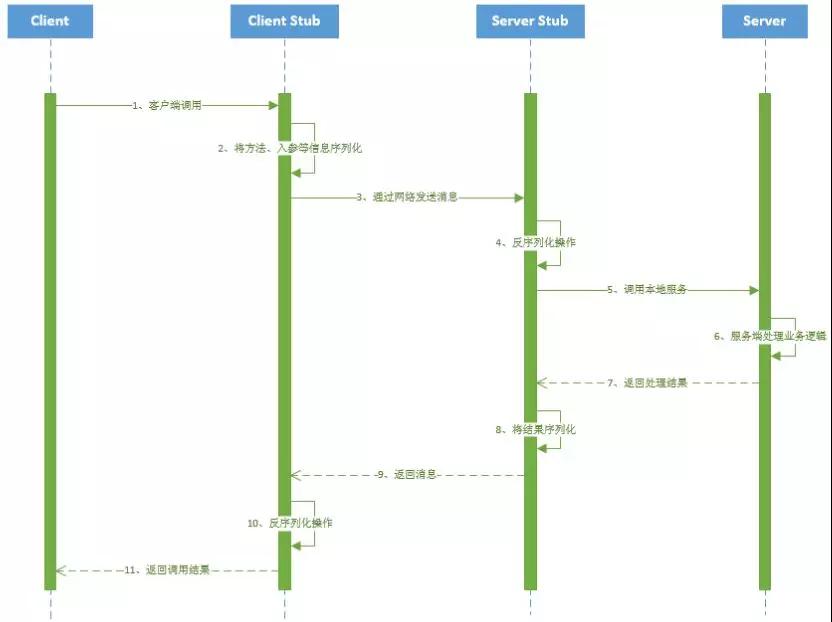
一次 RPC 调用流程如下:
1、服务消费者(Client 客户端)通过本地调用的方式调用服务。
2、客户端存根(Client Stub)接收到调用请求后负责将方法、入参等信息序列化(组装)成能够进行网络传输的消息体。
3、客户端存根(Client Stub)找到远程的服务地址,并且将消息通过网络发送给服务端。
4、服务端存根(Server Stub)收到消息后进行解码(反序列化操作)。
5、服务端存根(Server Stub)根据解码结果调用本地的服务进行相关处理
6、服务端(Server)本地服务业务处理。
7、处理结果返回给服务端存根(Server Stub)。
8、服务端存根(Server Stub)序列化结果。
9、服务端存根(Server Stub)将结果通过网络发送至消费方。
10、客户端存根(Client Stub)接收到消息,并进行解码(反序列化)。
11、服务消费方得到最终结果。
RPC 框架是把 2、3、4、5、8、9、10 这些步骤封装起来。
应用场景
RPC在分布式系统中的系统环境建设和应用程序设计中有着广泛的应用,应用包括如下方面:
1、分布式操作系统的进程间通讯。进程间通讯是操作系统必须提供的基本设施之一,分布式操作系统必须提供分布于异构的结点机上进程间的通讯机制,RPC是实现消息传送模式的分布式进程间通讯方式之一。
2、分布式应用程序设计。RPC机制与RPC工具为分布式应用程序设计提供了手段和方便, 用户可以无需知道网络结构和协议细节而直接使用RPC工具设计分布式应用程序。
3、分布式程序的调试。RPC可用于分布式程序的调试。使用反向RPC使服务器成为客户并向它的客户进程发出RPC,可以调试分布式程序。例如,在服务器上运行一个远端调试程序,它不断接收客户端的RPC,当遇到一个调试程序断点时,它向客户机发回一个RPC,通知断点已经到达,这也是RPC用于进程通讯的例子。
4、构造分布式计算的软件环境。由于分布式软件设计,服务与环境的分布性, 它的各个组成成份之间存在大量的交互和通讯, RPC是其基本的实现方法之一。Dubbo分布式服务框架基于RPC实现,Hadoop也采用了RPC方式实现客户端与服务端的交互。
5、远程数据库服务。在分布式数据库系统中,数据库一般驻存在服务器上,客户机通过远程数据库服务功能访问数据库服务器,现有的远程数据库服务是使用RPC模式的。例如,Sybase和Oracle都提供了存储过程机制,系统与用户定义的存储过程存储在数据库服务器上,用户在客户端使用RPC模式调用存储过程。
优点和不足

rpc优点:
1、单一职责,有利于分功协作和运维开发。可以采用不同的语言进行开发,部署运维上线都是独立的。可以不同的团队进行维护
2、可扩展性强,资源使用率更优。压力大的时候可以独立扩充资源。例如,双十一的时候只需要对直播间购物的进行扩容就可以。整体来说就是资源利用率会更高
3、故障隔离,服务的整体可靠性更高。某一个服务崩溃不会造成整体进行崩溃。
RPC带来的问题:
1、服务宕机,对方应该如何处理?
2、在调用过程中发生网络异常,如何保证消息的可达性?
3、请求量突增导致服务无法及时处理,有哪些应对措施?
RPC带来好处的同时也带来了不少新的问题,这些将由RPC框架来解决。
RPC vs Rest
| 类别 | RPC | REST |
|---|---|---|
| 报文格式 | 二进制 | XML、JSON |
| 网络协议 | TCP/HTTP/HTTP2 | HTTP/HTTP2 |
| 序列化开销 | 低 | 一般 |
| 网络开销 | 低 | 一般 |
| 性能 | 高 | 一般 |
| 访问便利性 | 客户端比较方便,但二进制消息不可读 | 文本消息开发者可读,浏览器可访问 |
| 代码耦合度 | 耦合度高 | 松散耦合 |
| 通用性 | 低,对外开发需进一步转换成REST协议 | 高,可直接对外开发 |
| 使用场景 | 内部服务 | 外部服务 |
服务发现
首先要向某个服务器发起请求,你得先建立连接,而建立连接的前提是,你得知道 IP 地址和端口。这个找到服务对应的 IP 端口的过程,其实就是服务发现。
在 HTTP 中,你知道服务的域名,就可以通过 DNS 服务去解析得到它背后的 IP 地址,默认 80 端口。
而 RPC 的话,就有些区别,一般会有专门的中间服务去保存服务名和IP信息,比如 Consul 或者 Etcd,甚至是 Redis。想要访问某个服务,就去这些中间服务去获得 IP 和端口信息。由于 DNS 也是服务发现的一种,所以也有基于 DNS 去做服务发现的组件,比如CoreDNS。
可以看出服务发现这一块,两者是有些区别,但不太能分高低。
底层连接形式
以主流的 HTTP/1.1 协议为例,其默认在建立底层 TCP 连接之后会一直保持这个连接(Keep Alive),之后的请求和响应都会复用这条连接。
而 RPC 协议,也跟 HTTP 类似,也是通过建立 TCP 长链接进行数据交互,但不同的地方在于,RPC 协议一般还会再建个连接池,在请求量大的时候,建立多条连接放在池内,要发数据的时候就从池里取一条连接出来,用完放回去,下次再复用,可以说非常环保。

由于连接池有利于提升网络请求性能,所以不少编程语言的网络库里都会给 HTTP 加个连接池,比如 Go 就是这么干的。
可以看出这一块两者也没太大区别,所以也不是关键。
传输的内容
基于 TCP 传输的消息,说到底,无非都是消息头 Header 和消息体 Body。
Header 是用于标记一些特殊信息,其中最重要的是消息体长度。
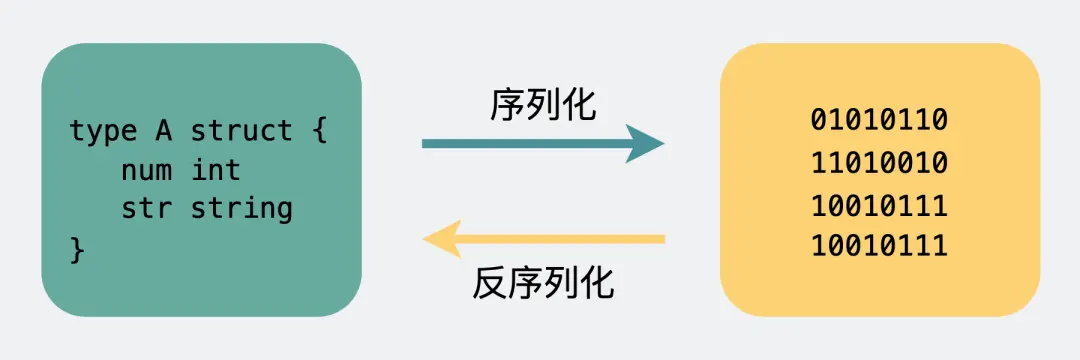
Body 则是放我们真正需要传输的内容,而这些内容只能是二进制 01 串,毕竟计算机只认识这玩意。所以 TCP 传字符串和数字都问题不大,因为字符串可以转成编码再变成 01 串,而数字本身也能直接转为二进制。但结构体呢,我们得想个办法将它也转为二进制 01 串,这样的方案现在也有很多现成的,比如 Json,Protobuf。
这个将结构体转为二进制数组的过程就叫序列化,反过来将二进制数组复原成结构体的过程叫反序列化。
对于主流的 HTTP/1.1,虽然它现在叫超文本协议,支持音频视频,但 HTTP 设计初是用于做网页文本展示的,所以它传的内容以字符串为主。Header 和 Body 都是如此。在 Body 这块,它使用 Json 来序列化结构体数据。
我们可以随便截个图直观看下。
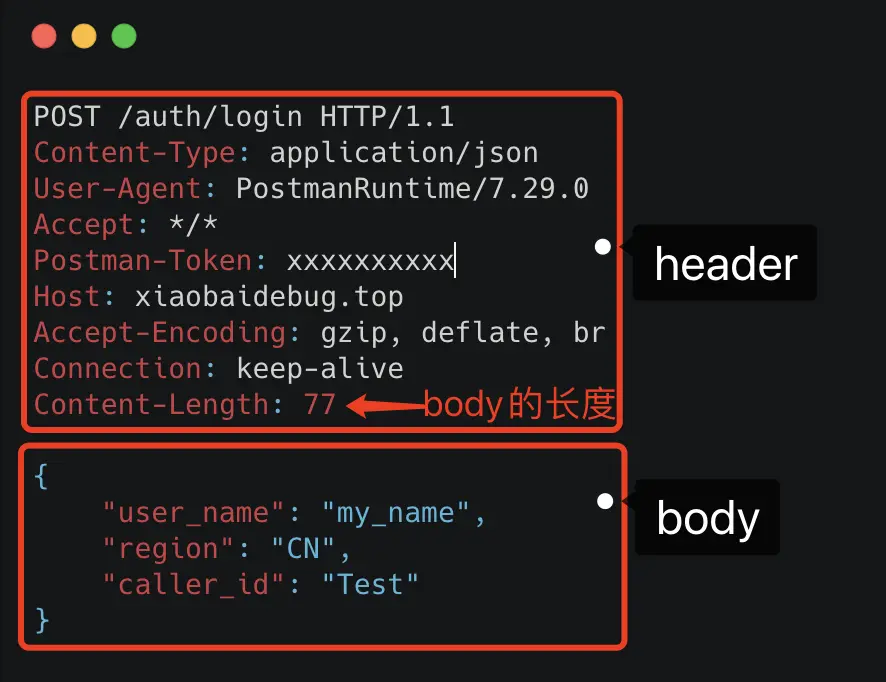
可以看到这里面的内容非常多的冗余,显得非常啰嗦。最明显的,像 Header 里的那些信息,其实如果我们约定好头部的第几位是 Content-Type,就不需要每次都真的把”Content-Type”这个字段都传过来,类似的情况其实在 body 的 Json 结构里也特别明显。
而 RPC,因为它定制化程度更高,可以采用体积更小的 Protobuf 或其他序列化协议去保存结构体数据,同时也不需要像 HTTP 那样考虑各种浏览器行为,比如 302 重定向跳转啥的。因此性能也会更好一些,这也是在公司内部微服务中抛弃 HTTP,选择使用 RPC 的最主要原因。

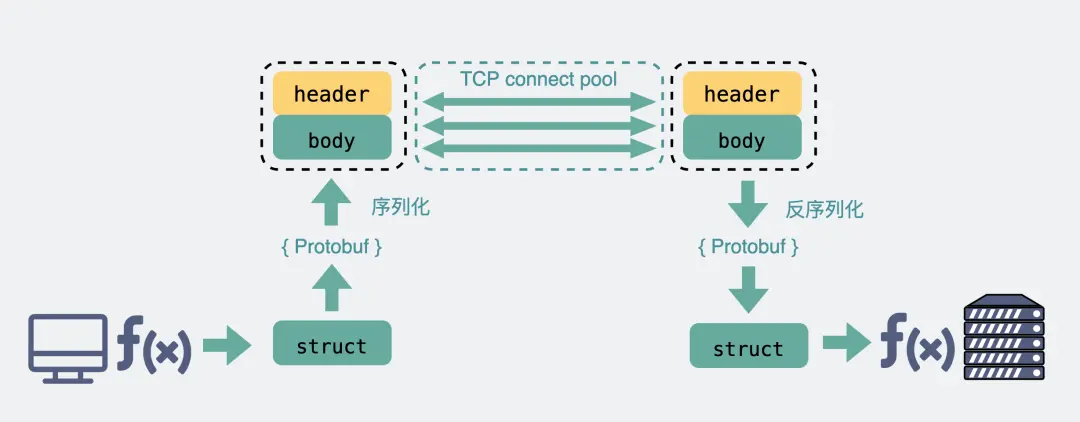
当然上面说的 HTTP,其实特指的是现在主流使用的 HTTP/1.1,HTTP/2 在前者的基础上做了很多改进,所以性能可能比很多 RPC 协议还要好,甚至连 gRPC 底层都直接用的 HTTP/2。
总结
(1)传输协议与性能:RPC 的传输协议灵活,可基于 TCP 实现,由于 TCP 协议处于协议栈的下层,能够更灵活地对协议字段进行定制,让请求报文体积更小,减少网络开销,提高传输性能并缩短传输耗时,实现更大的吞吐量和并发数。REST 的 HTTP 协议是上层协议,发送包含同等内容的信息,请求中会包含很多无用的内容,所占用的字节数比使用 TCP 协议传输更高,因此在同等网络下,HTTP 会比基于 TCP 协议的数据传输效率要低,传输耗时更长,不仅如此,REST 的 HTTP 大部分是通过 JSON 来实现的,序列化也更消耗性能,但如果是基于 HTTP2.0,那么经过封装也是可以作为一个 RPC 来使用的。
(2)灵活性、开放性与通用性:REST 通过 HTTP 实现,相对更加规范与通用,无论哪种语言都支持 HTTP 协议,所以 REST 的调用和测试都很方便,但使用 RPC 则会有很多约束,而如果 RPC 需要对外开放的话,需要进一步处理,灵活性不如 REST
(3)使用场景:REST 主要用于对外开放的异构环境,比如浏览器接口调用,Api 接口调用,第三方接口调用等。RPC 主要用于公司内部的服务调用,性能消耗低,传输效率高,特别是大型的网站,内部子系统较多、接口非常多的情况下适合使用 RPC
RPC 核心功能
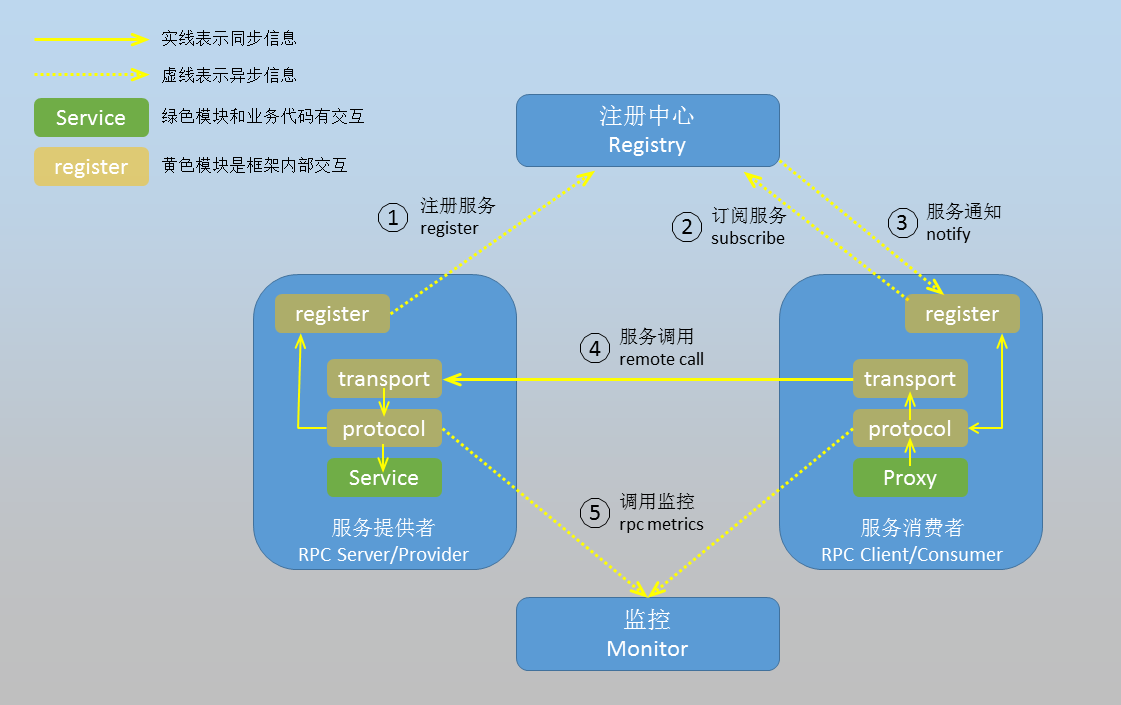
RPC 用于解决分布式系统中服务之间的调用问题。通俗地讲,就是开发者能够像调用本地方法一样调用远程的服务。下面我们通过一幅图来说说 RPC 框架的基本架构。
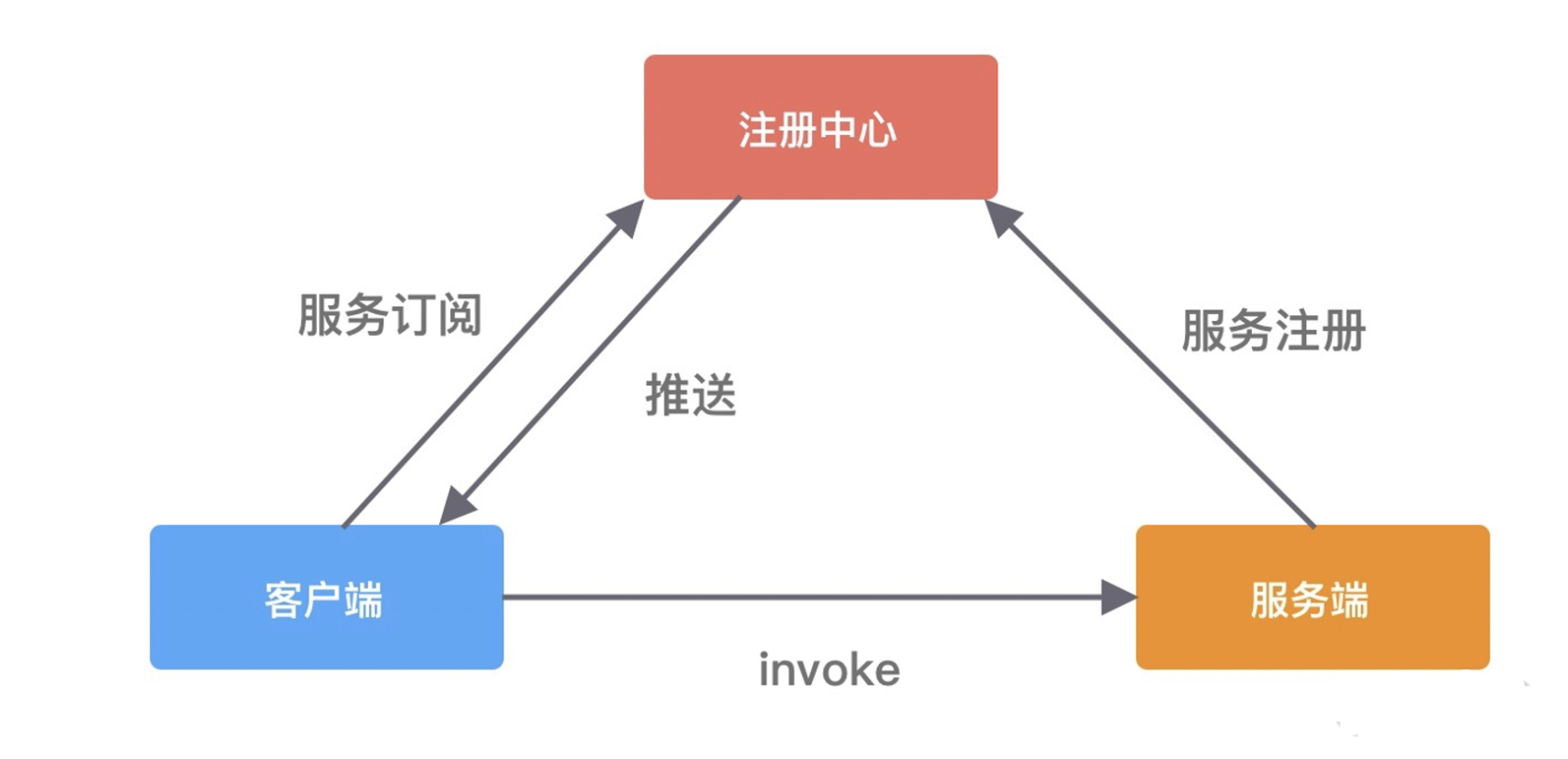
RPC 框架包含三个最重要的组件,分别是客户端、服务端和注册中心。在一次 RPC 调用流程中,这三个组件是这样交互的:
-
服务端在启动后,会将它提供的服务列表发布到注册中心,客户端向注册中心订阅服务地址;
-
客户端会通过本地代理模块 Proxy 调用服务端,Proxy 模块收到负责将方法、参数等数据转化成网络字节流;
-
客户端从服务列表中选取其中一个的服务地址,并将数据通过网络发送给服务端;
-
服务端接收到数据后进行解码,得到请求信息;
-
服务端根据解码后的请求信息调用对应的服务,然后将调用结果返回给客户端。

RPC 框架可以很复杂,例如 Apache Dubbo,其提供了非常多的功能,不过 RPC 框架的核心为如下几个组件:
-
代理层:RPC 接口向上暴露一个普通的方法调用,但是其内部却隐藏了复杂的序列化、协议解析、网络传输等过程。代理层就可以完成这样一件事:隐藏复杂实现细节,对外暴露一个简单的 API;
-
序列化层:RPC 中通过网络来完成消息传递,例如调用具体哪个接口的哪个方法,方法入口参数是什么。我们无法直接传输面向对象世界中的类与对象,因此需要序列化层将它们转换为字节数据来进行传输;
-
服务注册层:当分布式应用的主机数达到一定规模后,主机的下线以及上线将非常频繁。服务注册层能够很好地起到集群元数据信息中转站的作用,当客户端通过代理层进行 RPC 调用时,能够通过读取服务注册层的注册信息来得知哪个服务器能够提供此 RPC 调用对应的服务;
-
负载均衡层:当 Consumer 从服务注册中心拿到了多个可以调用的 Provider 后,选择哪一个 Provider 进行访问依赖于负载均衡层的设计。常见的负载均衡策略是:简单随机、权重随机、轮询、最少活跃调用数优先、一致性 Hash。
-
协议层:协议层的存在是基于 TCP 层开发自定义通信协议的内在要求。由于 TCP 协议不一定按照应用层的数据分包来传递,存在所谓的”TCP 粘包”、“TCP 拆包” 现象,而自定义协议的目的就是为了解决 TCP 的这些问题;总之,协议层主要为 TCP 传输的数据包提供元数据;
-
网络传输层:网络传输层对应于第一节 RPC 内部结构图的 sockets 层,其负责网络数据的传输,其需要负责 TCP 连接的管理、TCP 数据包的编解码等工作;
插件的语义在于组件是动态可配置的。下面将按照框架各个层进行展开说明。
代理层
代理层的实现策略有多种方式,例如 Dubbo 基于 Spring 容器在加载 Bean 时为接口实例织入网络传输 RPC 调用请求包的逻辑。当然,不借助于 Spring 容器,我们也能够实现代理逻辑,例如借助于 CGLIB、Javassist 等代理框架实现动态代理。
内部接口如何调用实现?
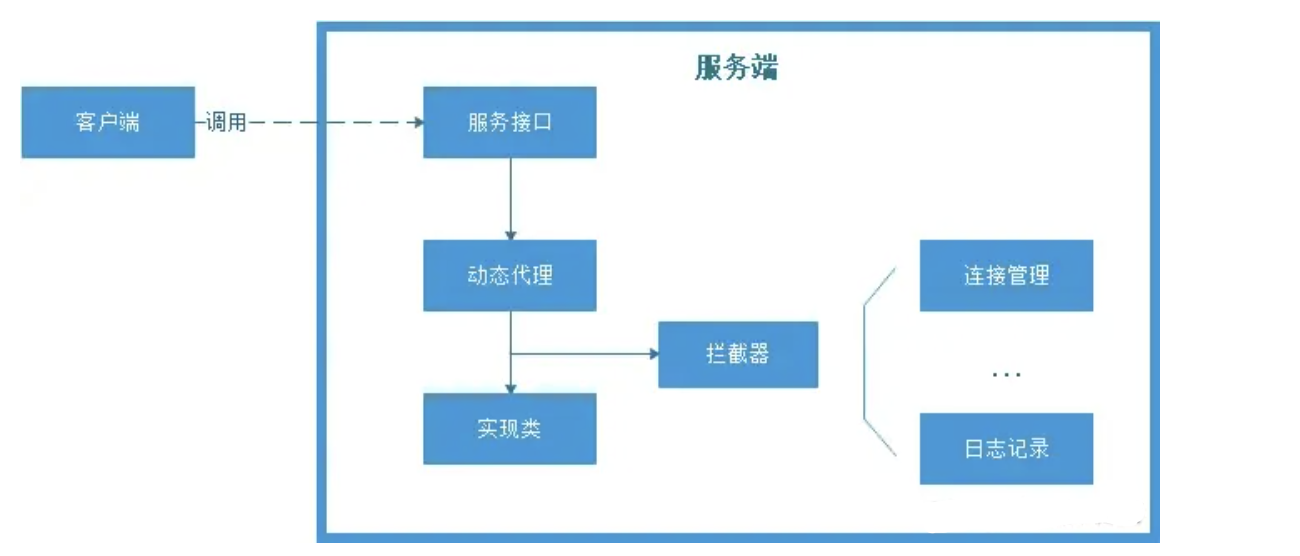
RPC的调用对用户来讲是透明的,那内部是如何实现呢?内部核心技术采用的就是动态代理,RPC 会自动给接口生成一个代理类,当我们在项目中注入接口的时候,运行过程中实际绑定的是这个接口生成的代理类。在接口方法被调用的时候,它实际上是被生成代理类拦截到了,这样就可以在生成的代理类里面,加入其他调用处理逻辑,比如连接负载管理,日志记录等等。
为什么要加入动态代理?
-
第一, 如果没有动态代理, 服务端大量的接口将不便于管理,需要大量的if判断,如果扩展了新的接口,需要更改调用逻辑, 不利于扩展维护。
-
第二, 是可以拦截,添加其他额外功能, 比如连接负载管理,日志记录等等。
序列化层

在本地调用中,我们只需要把参数信息压到内存栈中,然后让函数自己去栈中读取,但是远程过程调用时,客户端跟服务端是不同的进程,不能通过内存来传递参数。
所以远程过程调用中,客户端和服务端交互时,方法的参数和结果需要通过底层的网络协议如TCP传递,由于网络协议是基于二进制的(只有二进制数据才能在网络中传输),那么这些值需要序列化成二进制的形式,通过寻址和传输将序列化的二进制发送目标服务器。目标服务器接收到数据时,需要对数据进行反序列化。序列化和反序列化的速度也会影响远程调用的效率。
-
将对象转换成二进制流的过程叫做序列化
-
将二进制流转换成对象的过程叫做反序列化
考察一个序列化框架一般会关注以下几点:
-
解析效率:序列化协议应该首要考虑的因素,像xml/json解析起来比较耗时,需要解析dom树,二进制自定义协议解析起来效率要快很多。
-
压缩率:同样一个对象,xml/json传输起来有大量的标签冗余信息,信息有效性低,二进制自定义协议占用的空间相对来说会小很多。
-
扩展性与兼容性:是否能够利于信息的扩展,并且增加字段后旧版客户端是否需要强制升级,这都是需要考虑的问题,在自定义二进制协议时候,要做好充分考虑设计。
-
可读性与可调试性:xml/json的可读性会比二进制协议好很多,并且通过网络抓包是可以直接读取,二进制则需要反序列化才能查看其内容。
-
跨语言:有些序列化协议是与开发语言紧密相关的,例如dubbo的Hessian序列化协议就只能支持Java的RPC调用。
-
通用性:xml/json非常通用,都有很好的第三方解析库,各个语言解析起来都十分方便,二进制数据的处理方面也有Protobuf和Hessian等插件,在做设计的时候尽量做到较好的通用性。
序列化方式非常多,常见的RPC序列化协议:
-
XML(Extensible Markup Language)是一种常用的序列化和反序列化协议,具有跨机器,跨语言等优点。狭义web service就是基于SOAP消息传递协议(一个基于XML的可扩展消息信封格式)来进行数据交换的。
-
Hessian是一个动态类型,简洁的,可以移植到各个语言的二进制序列化对象协议。采用简单的结构化标记、采用定长的字节记录值、采用引用取代重复遇到的对象。
-
JSON(Javascript Object Notation)起源于弱类型语言Javascript, 是采用”Attribute-value”的方式来描述对象协议。与XML相比,其协议比较简单,解析速度比较快。
-
Protocol Buffers 是google提供的一个开源序列化框架,是一种轻便高效的结构化数据存储格式,可以用于结构化数据串行化,或者说序列化。它很适合做数据存储或 RPC 数据交换格式。可用于通讯协议、数据存储等领域的语言无关、平台无关、可扩展的序列化结构数据格式。同 XML 相比, Protobuf 的主要优点在于性能高。它以高效的二进制方式存储,比 XML 小 3 到 10 倍,快 20 到 100 倍。
-
Thrift 既是rpc框架,同时也具有自己内部定义的传输协议规范(TProtocol)和传输数据标准(TTransports),通过IDL脚本对传输数据的数据结构(struct) 和传输数据的业务逻辑(service)根据不同的运行环境快速的构建相应的代码,并且通过自己内部的序列化机制对传输的数据进行简化和压缩提高高并发、 大型系统中数据交互的成本。
综合上面的几个考虑点,我们的序列化方案选择主要有以下几种:
首先是大家熟知的 JSON,它起源于 JavaScript,是一种最广泛使用的序列化协议,它的优势简单易用,人言可读,同时在性能上相比 XML 有比较大的优势。
另外的 Thrift 和 Protobuf 都是需要引入 IDL(Interface description language)的,也就是需要按照约定的语法写一个 IDL 文件,然后通过特定的编译器将它转换成各语言对应的代码,从而实现跨语言的特点。
Thrift 是 Facebook 开源的高性能的序列化协议,也是一个轻量级的 RPC 框架;Protobuf 是谷歌开源的序列化协议。它们的共同特点是,无论在空间上还是时间上都有着很高的性能,缺点就是由于 IDL 存在带来一些使用上的不方便。
那么,要如何选择这几种序列化协议呢?
-
如果对于性能要求不高,在传输数据占用带宽不大的场景下,可以使用 JSON 作为序列化协议;
-
如果对于性能要求比较高,那么使用 Thrift 或者 Protobuf 都可以。而 Thrift 提供了配套的 RPC 框架,所以想要一体化的解决方案,你可以优先考虑 Thrift;
-
在一些存储的场景下,比如说你的缓存中存储的数据占用空间较大,那么你可以考虑使用 Protobuf 替换 JSON,作为存储数据的序列化方式。
Protocol Buffers
下面详细展开 Protocol Buffers,看看为什么作为工业界用得最多的高性能序列化类库,好在哪里。
首先去官网查看它的 Encoding format
https://developers.google.com/protocol-buffers/docs/encoding
紧凑高效 是 PB 的特点,使用字段的序号作为标识,而不是包名类名(Java 的 Native Serialization 序列化后数据大就在于什么都一股脑放进去),使用 varint 和 zigzag 对整型做特殊处理。
PB 可以跨各种语言,但是前提是使用 IDL 编写描述文件,然后 codegen 工具生成各种语言的代码。
举个例子,有个 Person 对象,包含内容如下图所示,经过 PB 序列化后只有 33 个字节,可以对比 XML、JSON 或者 Java 的 Native Serialization 都会大非常多,而且序列化、反序列化的速度也不会很好。
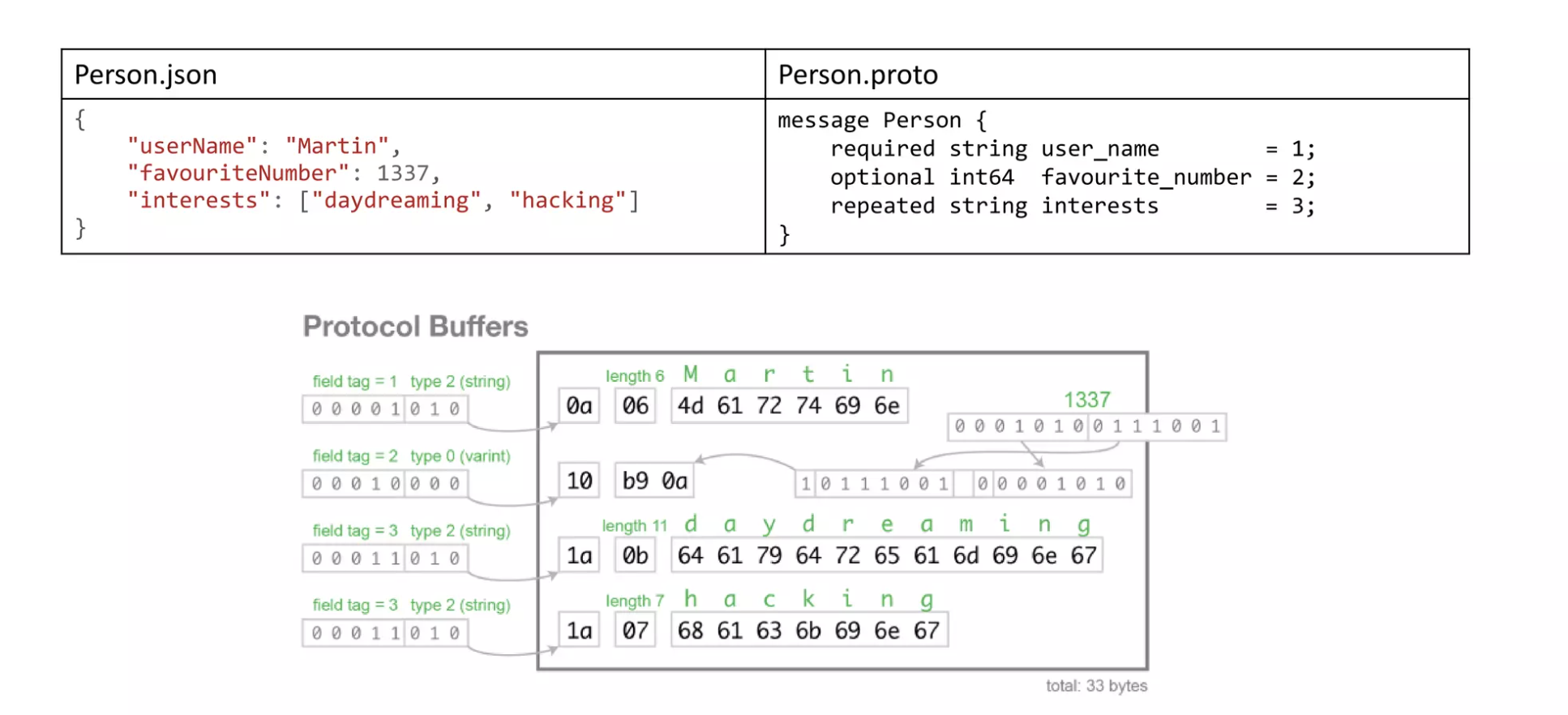
Thrift
再举个例子,使用 Thrift 做同样的序列化,采用 Binary Protocol 和 Compact Protocol 的大小是不一样的,但是 Compact Protocol 和 PB 虽然序列化的编码不一样,但是同样是非常高效的。

服务注册层

在分布式系统中,不同服务之间应该如何通信呢?传统的方式可以通过 HTTP 请求调用、保存服务端的服务列表等,这样做需要开发者主动感知到服务端暴露的信息,系统之间耦合严重。为了更好地将客户端和服务端解耦,以及实现服务优雅上线和下线,于是注册中心就出现了。
(1)从服务提供者的角度看:
-
当服务提供者启动的时候,需要将自己提供的服务注册到指定的注册中心,以便服务消费者能够通过服务注册中心进行查找;
-
当服务提供者由于各种原因致使提供的服务停止时,需要向注册中心注销停止的服务;服务的提供者需要定期向服务注册中心发送心跳检测,服务注册中心如果一段时间未收到来自服务提供者的心跳后,认为该服务提供者已经停止服务,则将该服务从注册中心上去掉。
(2)从调用者的角度看:
-
服务的调用者启动的时候根据自己订阅的服务向服务注册中心查找服务提供者的地址等信息;
-
当服务调用者消费的服务上线或者下线的时候,注册中心会告知该服务的调用者;
-
服务调用者下线的时候,则取消订阅。
由此可见,采用注册中心的好处是可以解耦客户端和服务端之间错综复杂的关系,并且能够实现对服务的动态管理。服务配置可以支持动态修改,然后将更新后的配置推送到客户端和服务端,无须重启任何服务。
Dubbo 中使用 ZooKeeper 服务中心如下图所示:

负载均衡层
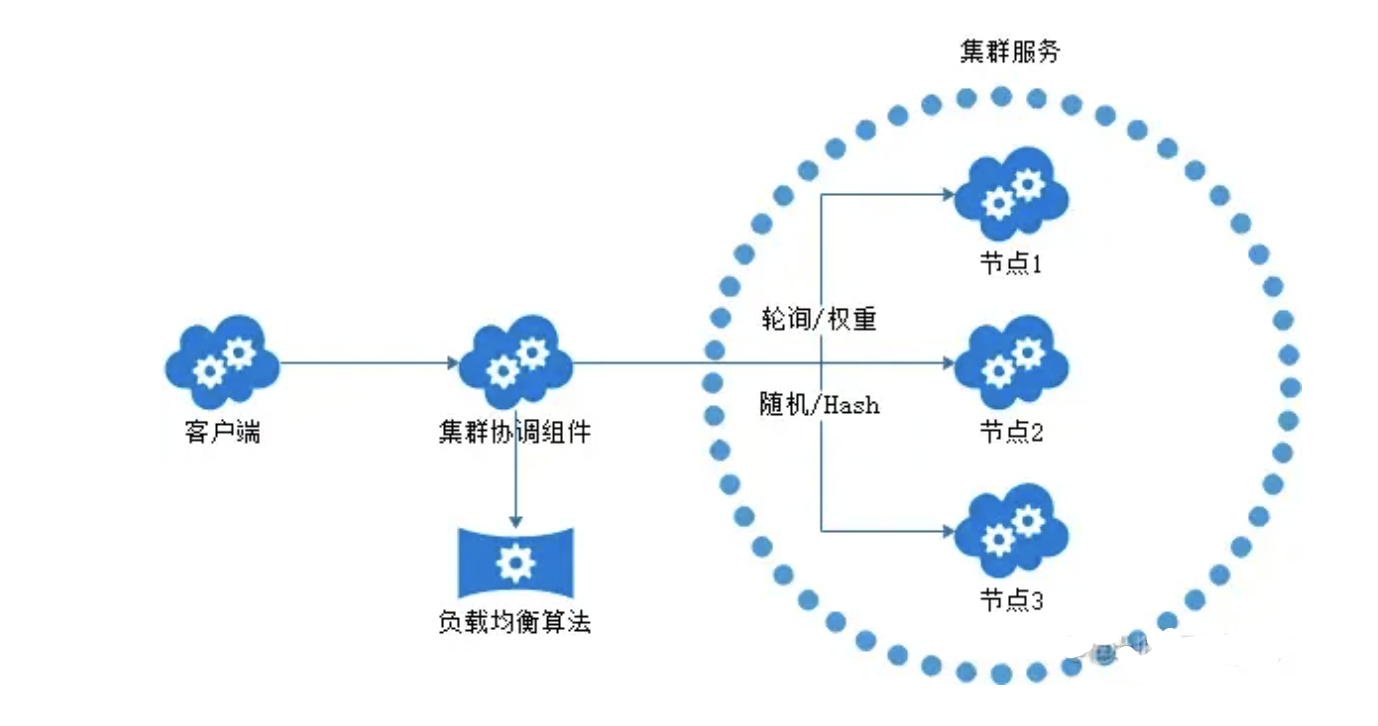
在分布式系统中,服务提供者和服务消费者都会有多台节点,如何保证服务提供者所有节点的负载均衡呢?客户端在发起调用之前,需要感知有多少服务端节点可用,然后从中选取一个进行调用。客户端需要拿到服务端节点的状态信息,并根据不同的策略实现负载均衡算法。负载均衡策略是影响 RPC 框架吞吐量很重要的一个因素,下面我们介绍几种最常用的负载均衡策略。
-
Round-Robin 轮询。Round-Robin 是最简单有效的负载均衡策略,并没有考虑服务端节点的实际负载水平,而是依次轮询服务端节点。
-
Weighted Round-Robin 权重轮询。对不同负载水平的服务端节点增加权重系数,这样可以通过权重系数降低性能较差或者配置较低的节点流量。权重系数可以根据服务端负载水平实时进行调整,使集群达到相对均衡的状态。
-
Least Connections 最少连接数。客户端根据服务端节点当前的连接数进行负载均衡,客户端会选择连接数最少的一台服务器进行调用。Least Connections 策略只是服务端其中一种维度,我们可以演化出最少请求数、CPU 利用率最低等其他维度的负载均衡方案。
-
Consistent Hash 一致性 Hash。目前主流推荐的负载均衡策略,Consistent Hash 是一种特殊的 Hash 算法,在服务端节点扩容或者下线时,尽可能保证客户端请求还是固定分配到同一台服务器节点。Consistent Hash 算法是采用哈希环来实现的,通过 Hash 函数将对象和服务器节点放置在哈希环上,一般来说服务器可以选择 IP + Port 进行 Hash,然后为对象选择对应的服务器节点,在哈希环中顺时针查找距离对象 Hash 值最近的服务器节点。
此外,负载均衡算法可以是多种多样的,客户端可以记录例如健康状态、连接数、内存、CPU、Load 等更加丰富的信息,根据综合因素进行更好地决策。
协议层
协议层是必要的,试想这样一个问题:客户端连续发送了两个 RpcRequest 消息,而且在接收端同时接收到了这两个 RpcRequest 实例对应的序列化后的字节数据,那么:接收端如何将该字节数组数据解析为两个 RpcRequest 实例呢?如果没有协议层,接收端将无法完成此任务。当然,对于服务端向客户端回复的响应 RpcReponse 实例也有着完全一样的道理。
什么是TCP粘包、拆包
TCP 传输协议是面向流的,没有数据包界限,也就是说消息无边界。客户端向服务端发送数据时,可能将一个完整的报文拆分成多个小报文进行发送,也可能将多个报文合并成一个大的报文进行发送。 因此就有了拆包和粘包。
在网络通信的过程中,每次可以发送的数据包大小是受多种因素限制的,如 MTU 传输单元大小、滑动窗口等。
所以如果一次传输的网络包数据大小超过传输单元大小,那么我们的数据可能会拆分为多个数据包发送出去。如果每次请求的网络包数据都很小,比如一共请求了 10000 次,TCP 并不会分别发送 10000 次。 TCP采用的 Nagle(批量发送,主要用于解决频繁发送小数据包而带来的网络拥塞问题) 算法对此作出了优化。
所以,网络传输会出现这样:
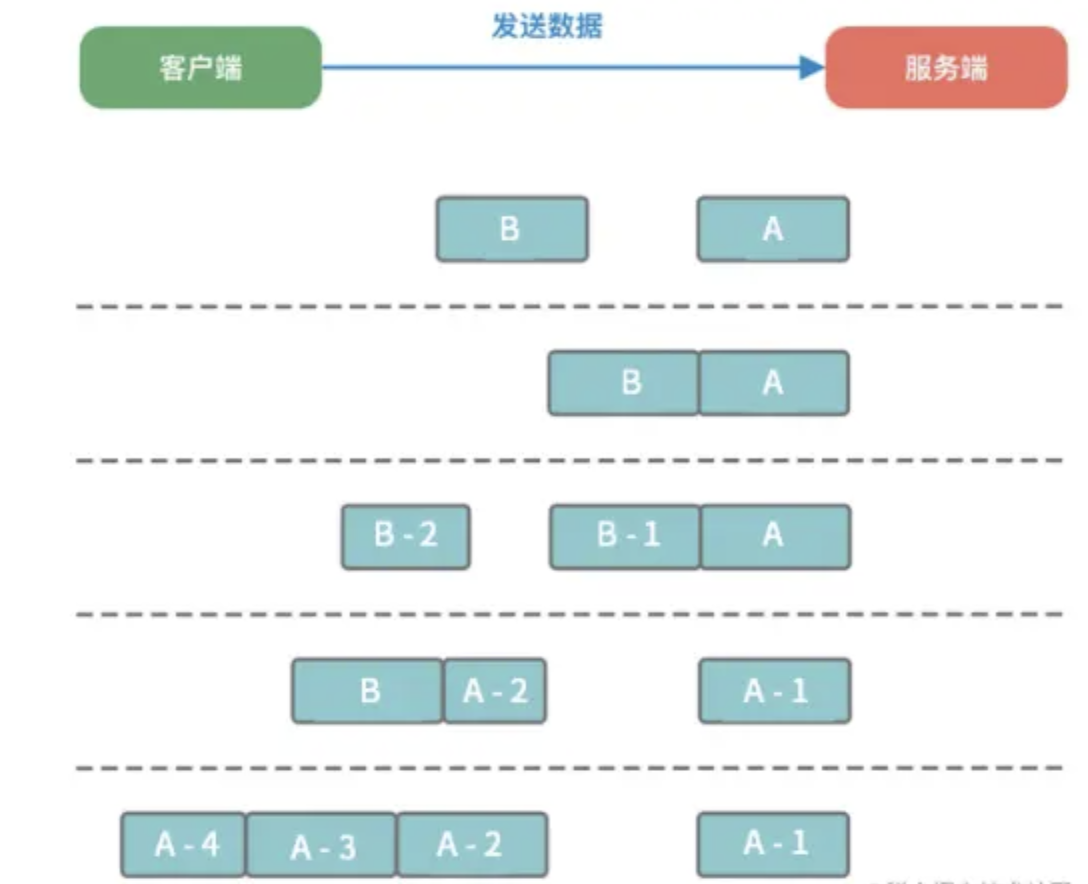
1、服务端恰巧读到了两个完整的数据包 A 和 B,没有出现拆包/粘包问题;
2、服务端接收到 A 和 B 粘在一起的数据包,服务端需要解析出 A 和 B;
3、服务端收到完整的 A 和 B 的一部分数据包 B-1,服务端需要解析出完整的 A,并等待读取完整的 B 数据包;
4、服务端接收到 A 的一部分数据包 A-1,此时需要等待接收到完整的 A 数据包;
5、数据包 A 较大,服务端需要多次才可以接收完数据包 A。
如何解决TCP粘包、拆包问题
解决问题的根本手段:找出消息的边界:
-
消息长度固定 每个数据报文都需要一个固定的长度。当接收方累计读取到固定长度的报文后,就认为已经获得一个完整的消息。当发送方的数据小于固定长度时,则需要空位补齐。 消息定长法使用非常简单,但是缺点也非常明显,无法很好设定固定长度的值,如果长度太大会造成字节浪费,长度太小又会影响消息传输,所以在一般情况下消息定长法不会被采用。
-
特定分隔符 在每次发送报文的尾部加上特定分隔符,接收方就可以根据特殊分隔符进行消息拆分。 分隔符的选择一定要避免和消息体中字符相同,以免冲突。否则可能出现错误的消息拆分。比较推荐的做法是将消息进行编码,例如 base64 编码,然后可以选择 64 个编码字符之外的字符作为特定分隔符
-
消息长度 + 消息内容 消息长度 + 消息内容是项目开发中最常用的一种协议,接收方根据消息长度来读取消息内容。
举个例子,正如下图中的例子,ABC+DEF+GHI 分 3 个 message,也就是分 3 个 Frame 发送出去,而接收端分四次收到 4 个 Frame。

这时候应用层如何做语义级别的 message 识别是个问题,只有做好了协议的结构,才能把一整个数据片段做序列化或者反序列化处理。
方式 1:消息定长,例如每个报文的大小为固定长度 100 字节,如果不够用空格补足。
方式 2:在包尾特殊结束符进行分割。
比如 memcache 由客户端发送的命令使用的是文本行\r\n 做为 mesage 的分隔符,组织成一个有意义的 message。
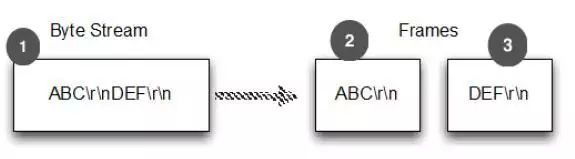
图中的说明:
1.字节流
2.第一帧
3.第二帧
方式 3、将消息分为消息头和消息体,消息头中包含表示消息总长度(或者消息体长度)的字段。
比如 HTTP 协议,HTTP 头中肯定有一个 body length 告知应用层如何去读懂一个 message,做 HTTP 包的识别。

在 HTTP/2 协议中,详细见 Hypertext Transfer Protocol Version 2 (HTTP/2)
https://tools.ietf.org/html/rfc7540
虽然精简了很多,加入了流的概念,但是 header+payload 的方式是绝对不能变的。

网络传输层
网络传输层非常关键,因为网络 I/O 的设计最大程度上影响 RPC 调用效率。
通信协议
远程调用中,客户端和服务端的通讯是基于网络连接的,所以首先需要建立通信连接,通过这个连接把请求信息的字节流传给服务端,然后再把序列化后的响应结果传回客户端,在这个通讯过程中,它所使用的协议是没有限制的,能完成传输就行,但是在这里我们需要考虑两个问题:如何选择网络协议 和 如何建立连接。
网络协议的选择
多数 RPC 框架选择 TCP 作为传输协议,但其实 UDP 也可以,也有部分选择HTTP,比如 gRPC 使用 HTTP2,但是不同的协议各有优劣势,TCP 更加高效,而 HTTP 在实际应用中更加的灵活,具体需要根据使用场景来选择。
-
基于 TCP 的协议实现的 RPC 调用,由于 TCP 协议处于协议栈的下层,能够更加灵活地对协议字段进行定制,让请求报文体积更小,减少网络开销,提高传输性能并缩短传输耗时,实现更大的吞吐量和并发数。但是需要更多关注底层复杂的细节,实现的代价更高,同时对不同平台,如安卓,iOS 等,需要重新开发出不同的工具包来进行请求发送和相应解析,工作量大,难以快速响应和满足用户需求。
-
基于 HTTP 协议实现的 RPC 则可以使用 JSON 和 XML 格式的请求或响应数据,而 JSON 和 XML 作为通用的格式标准(使用 HTTP 协议也需要序列化和反序列化,不过这不是该协议下关心的内容,成熟的 Web 程序已经做好了序列化内容),开源的解析工具已经相当成熟,在其上进行二次开发会非常便捷和简单。但是由于 HTTP 协议是上层协议,发送包含同等内容的信息,请求中会包含很多无用的内容,所占用的字节数比使用 TCP 协议传输更高,因此在同等网络下,HTTP 会比基于 TCP 协议的数据传输效率要低,传输耗时更长,当然压缩数据,能够缩小这一差距。
成熟的 RCP 框架能够支持多种协议,例如阿里开源的 Dubbo 框架被很多互联网公司广泛使用,其中可插拔的协议支持是 Dubbo 的一大特色,这样不仅可以给开发者提供多种不同的选择,而且为接入异构系统提供了便利。
通讯连接的建立
RPC 所有交换的数据都在这个连接里传输,这个连接可以是按需连接(需要调用时就先建立连接,调用结束后就立马断掉),也可以是长连接(客户端和服务器建立起连接之后保持长期持有,不管此时有无数据包的发送,可以配合心跳检测机制定期检测建立的连接是否存活有效),多个远程过程调用共享同一个连接。
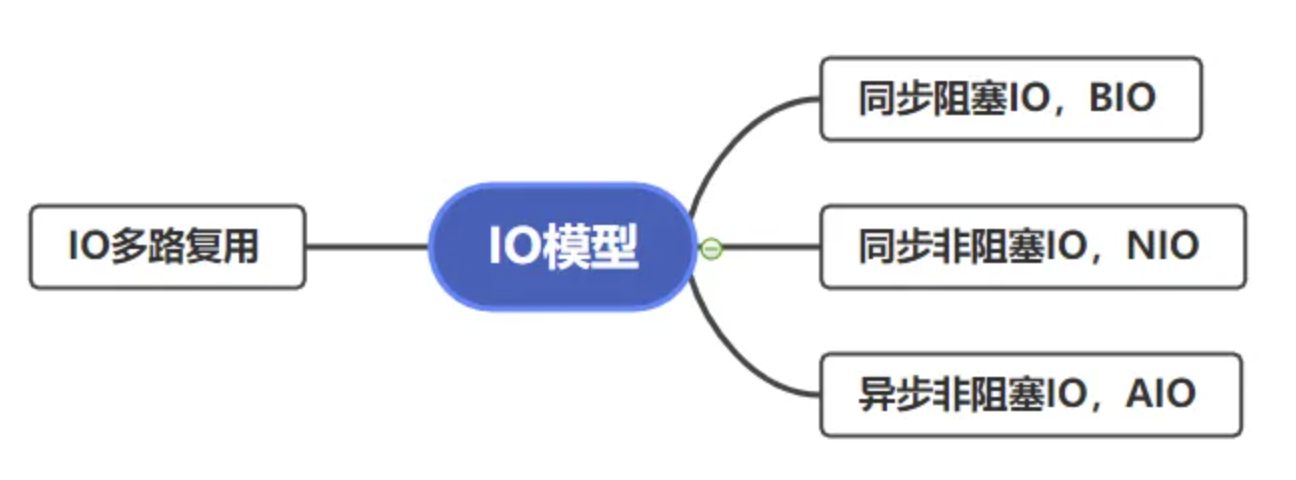
I/O 模型
在网络传输优化中,你首要做的,是选择一种高性能的 I/O 模型。所谓 I/O 模型,就是我们处理 I/O 的方式。而一般单次 I/O 请求会分为两个阶段,每个阶段对于 I/O 的处理方式是不同的。
首先,I/O 会经历一个等待资源的阶段, 比方说,等待网络传输数据可用,在这个过程中我们对 I/O 会有两种处理方式:
-
阻塞。指的是在数据不可用时,I/O 请求一直阻塞,直到数据返回;
-
非阻塞。指的是数据不可用时,I/O 请求立即返回,直到被通知资源可用为止。
然后是使用资源的阶段, 比如说从网络上接收到数据,并且拷贝到应用程序的缓冲区里面。在这个阶段我们也会有两种处理方式:
-
同步处理。指的是 I/O 请求在读取或者写入数据时会阻塞,直到读取或者写入数据完成;
-
异步处理。指的是 I/O 请求在读取或者写入数据时立即返回,当操作系统处理完成 I/O 请求,并且将数据拷贝到用户提供的缓冲区后,再通知应用 I/O 请求执行完成。
将这两个阶段的四种处理方式,做一些排列组合,再做一些补充,就得到了我们常见的五种 I/O 模型:
-
同步阻塞 I/O
-
同步非阻塞 I/O
-
同步多路 I/O 复用
-
信号驱动 I/O
-
异步 I/O
这五种 I/O 模型,你需要理解它们的区别和特点,不过在理解上你可能会有些难度,所以我来做个比喻,方便你理解。
我们来把 I/O 过程比喻成烧水倒水的过程,等待资源(就是烧水的过程),使用资源(就是倒水的过程):
-
如果你站在炤台边上一直等着(等待资源)水烧开,然后倒水(使用资源),那么就是同步阻塞 I/O;
-
如果你偷点儿懒,在烧水的时候躺在沙发上看会儿电视(不再时时刻刻等待资源),但是还是要时不时的去看看水开了没有,一旦水开了,马上去倒水(使用资源),那么这就是同步非阻塞 I/O;
-
如果你想要洗澡,需要同时烧好多壶水,那你就在看电视的间隙去看看哪壶水开了(等待多个资源),哪一壶开了就先倒哪一壶,这样就加快了烧水的速度,这就是同步多路 I/O 复用;
-
不过你发现自己总是跑厨房去看水开了没,太累了,于是你考虑给你的水壶加一个报警器(信号),只要水开了就马上去倒水,这就是信号驱动 I/O;
-
最后一种就高级了,你发明了一个智能水壶,在水烧好后自动就可以把水倒好,这就是异步 I/O。
这里再举一个形象的例子,就用 银行办业务 这个生活的场景描述。
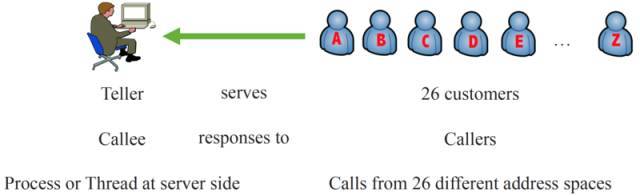
下图是使用 传统的阻塞 I/O 模型。一个柜员服务所有客户,可见当客户填写单据的时候也就是发生网络 I/O 的时候,柜员,也就是宝贵的线程或者进程就会被阻塞,白白浪费了 CPU 资源,无法服务后面的请求。
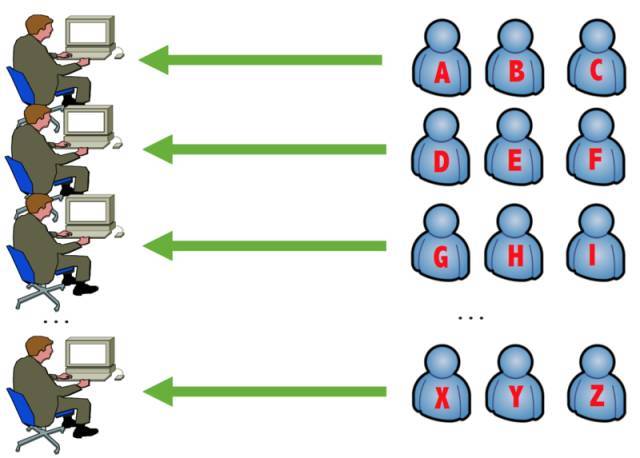
下图是上一个的进化版,如果一个柜员不够,那么就 并发处理,对应采用线程池或者多进程方案,一个客户对应一个柜员,这明显加大了并发度,在并发不高的情况下性能够用,但是仍然存在柜员被 I/O 阻塞的可能。
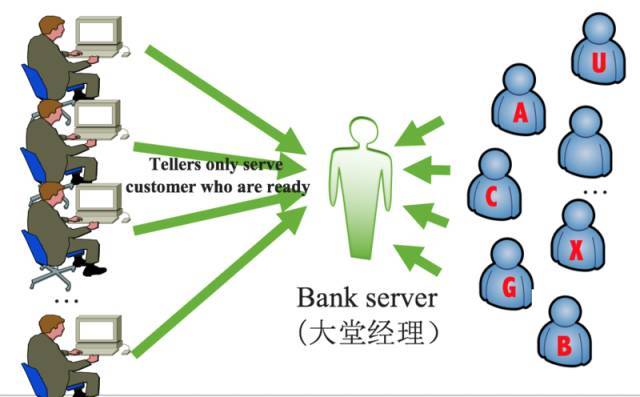
下图是 I/O 多路复用,存在一个大堂经理,相当于代理,它来负责所有的客户,只有当客户写好单据后,才把客户分配一个柜员处理,可以想象柜员不用阻塞在 I/O 读写上,这样柜员效率会非常高,这也就是 I/O 多路复用的精髓。
下图是 异步 I/O,完全不存在大堂经理,银行有一个天然的“高级的分配机器”,柜员注册自己负责的业务类型,例如 I/O 可读,那么由这个“高级的机器”负责 I/O 读,当可读时候,通过 回调机制,把客户已经填写完毕的单据主动交给柜员,回调其函数完成操作。

重点说下高性能,并且工业界普遍使用的方案,也就是后两种。
I/O 多路复用
这五种 I/O 模型中最被广泛使用的是 多路 I/O 复用, Linux 系统中的 select、epoll 等系统调用都是支持多路 I/O 复用模型的,Java 中的高性能网络框架 Netty 默认也是使用这种模型。
基于内核,建立在 epoll 或者 kqueue 上实现,I/O 多路复用最大的优势是用户可以在一个线程内同时处理多个 Socket 的 I/O 请求。用户可以订阅事件,包括文件描述符或者 I/O 可读、可写、可连接事件等。
通过一个线程监听全部的 TCP 连接,有任何事件发生就通知用户态处理即可,这么做的目的就是 假设 I/O 是慢的,CPU 是快的,那么要让用户态尽可能的忙碌起来去,也就是最大化 CPU 利用率,避免传统的 I/O 阻塞。
异步 I/O
这里重点说下同步 I/O 和异步 I/O,理论上前三种模型都叫做同步 I/O,同步是指用户线程发起 I/O 请求后需要等待或者轮询内核 I/O 完成后再继续,而异步是指用户线程发起 I/O 请求直接退出,当内核 I/O 操作完成后会通知用户线程来调用其回调函数。
一个高性能的 RPC,需要能够满足:
1、服务端尽可能多的处理并发请求
2、同时尽可能短的处理完毕。
CPU 和 I/O 之间天然存在着差异,网络传输的延时不可控,最简单的模型下,如果有线程或者进程在调用 I/O,I/O 没响应时,CPU 只能选择挂起,线程或者进程也被 I/O 阻塞住。
而 CPU 资源宝贵,要让 CPU 在该忙碌的时候尽量忙碌起来,而不需要频繁地挂起、唤醒做切换,同时很多宝贵的线程和进程占用系统资源也在做无用功。
进程 / 线程模型
进程 / 线程模型往往和 I/O 模型有联系,当 Socket I/O 可以很高效的工作时候,真正的业务逻辑如何利用 CPU 更快地处理请求,也是有 pattern 可寻的。这里主要说 Scalable I/O 一般是如何做的,它的 I/O 需要经历 5 个环节:
Read -> Decode -> Compute -> Encode -> Send
使用传统的阻塞 I/O + 线程池的方案(Multitasks)会遇 C10k问题。
https://en.wikipedia.org/wiki/C10k_problem
但是业界有很多实现都是这个方式,比如 Java web 容器 Tomcat/Jetty 的默认配置就采用这个方案,可以工作得很好。
但是从 I/O 模型可以看出 I/O Blocking is killer to performance,它会让工作线程卡在 I/O 上,而一个系统内部可使用的线程数量是有限的(本文暂时不谈协程、纤程的概念),所以才有了 I/O 多路复用和异步 I/O。
I/O 多路复用往往对应 Reactor 模式,异步 I/O 往往对应 Proactor。
Reactor 一般使用 epoll+ 事件驱动 的经典模式,通过 分治 的手段,把耗时的网络连接、安全认证、编码等工作交给专门的线程池或者进程去完成,然后再去调用真正的核心业务逻辑层,这在 *nix 系统中被广泛使用。
著名的 Redis、Nginx、Node.js 的 Socket I/O 都用的这个,而 Java 的 NIO 框架 Netty 也是,Spark 2.0 RPC 所依赖的同样采用了 Reactor 模式。
Proactor 在 *nix 中没有很好的实现,但是在 Windows 上大放异彩(例如 IOCP 模型)。
关于 Reactor 可以参考 Doug Lea 的 PPT
http://gee.cs.oswego.edu/dl/cpjslides/nio.pdf
以及 这篇 paper
http://www.dre.vanderbilt.edu/~schmidt/PDF/reactor-siemens.pdf
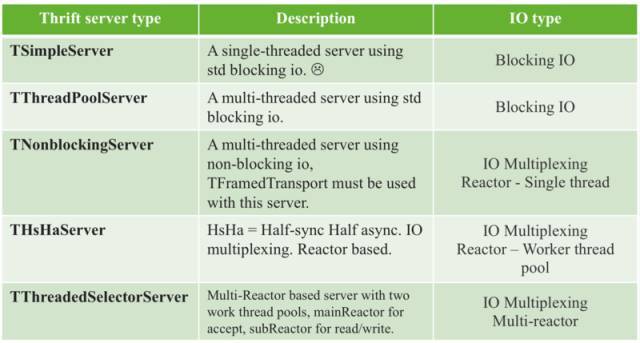
说个具体的例子,Thrift 作为一个融合了 序列化 +RPC 的框架,提供了很多种 Server 的构建选项,从名称中就可以看出他们使用哪种 I/O 和线程模型。
以 Dubbo 框架为例,Dubbo 使用 Netty 作为底层的网络通信框架,采用了我们熟悉的主从 Reactor 线程模型,其中 Boss 和 Worker 线程池就可以看作 I/O 线程。I/O 线程可以理解为主要负责处理网络数据,例如事件轮询、编解码、数据传输等。如果业务逻辑能够立即完成,也可以使用 I/O 线程进行处理,这样可以省去线程上下文切换的开销。如果业务逻辑耗时较多,例如包含查询数据库、复杂规则计算等耗时逻辑,那么 I/O 必须将这些请求分发到业务线程池中进行处理,以免阻塞 I/O 线程。
那么哪些请求需要在 I/O 线程中执行,哪些又需要在业务线程池中执行呢?Dubbo 框架的做法值得借鉴,它给用户提供了多种选择,它一共提供了 5 种分发策略,如下表格所示。

RPC框架
RPC 都常用于微服务架构中,微服务的好处之一,就是不限定服务的提供方使用什么技术选型,能够实现大公司跨团队的技术解耦。 但是,如果没有统一的通信框架,各个团队的服务提供方就需要各自实现一套序列化、反序列化、网络框架、连接池、收发线程、超时处理、状态机等 “业务之外” 的重复技术劳动,造成整体的低效。所以,统一通信框架把上述 “业务之外” 的技术劳动统一处理,是服务化首要解决的问题。
RPC 框架的目标就是让远程服务调用更简单、透明,由 RPC 框架负责屏蔽底层的序列化、传输方式和通信的细节,开发者在使用时只需要了解谁在什么位置提供了什么样的远程服务接口即可,并不需要关心底层通信细节和调用过程。RPC 框架作为架构微服务化的基础组件,它能大大降低架构微服务化的成本,提高调用方与服务提供方的研发效率。
常见RPC框架:
-
gRPC:是 Google 公布的开源软件,基于 HTTP 2.0 协议,底层网络库是基于Netty开发而来,并支持常见的众多编程语言。
-
Thrift:是Apache的一个项目,前身是Facebook开发的一个RPC框架,采用thrift作为IDL (Interface description language)。是支持跨语言的RPC框架。(https://thrift.apache.org)
-
Dubbo:是阿里集团开源的一个极为出名的 RPC 框架,在很多互联网公司和企业应用中广泛使用。协议和序列化框架都可以插拔是极其鲜明的特色。远程接口基于Java Interface, 依托于Spring框架。
上述都是现在常用的解决方案。这些是有网络资料的,实际上很多公司内部都会针对自己的业务场景,以及和公司内的平台相融合(比如监控平台等),自研一套框架,但是殊途同归,都逃不掉刚刚上面所列举的 RPC 的要考虑的各个部分。
框架关键指标
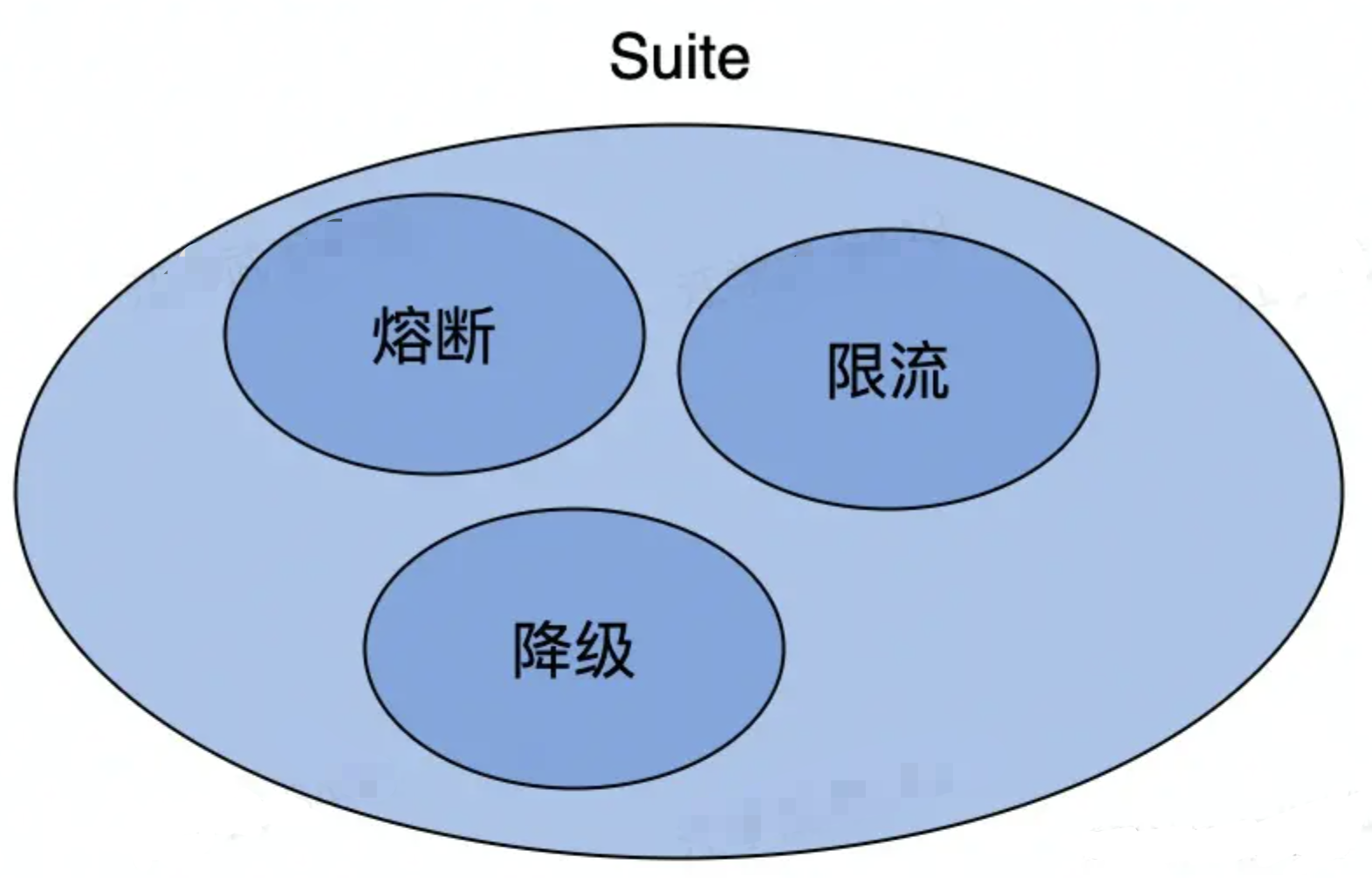
框架关键指标主要有五个方面:稳定性、易用性、扩展性、观测性、高性能
稳定性
保障策略
-
熔断:保护调用方,防止被调用的服务出现问题而影响到整个链路
-
限流:保护被调用方,防止大流量把服务压垮
-
超时控制:避免浪费资源在不可用节点上

请求成功率
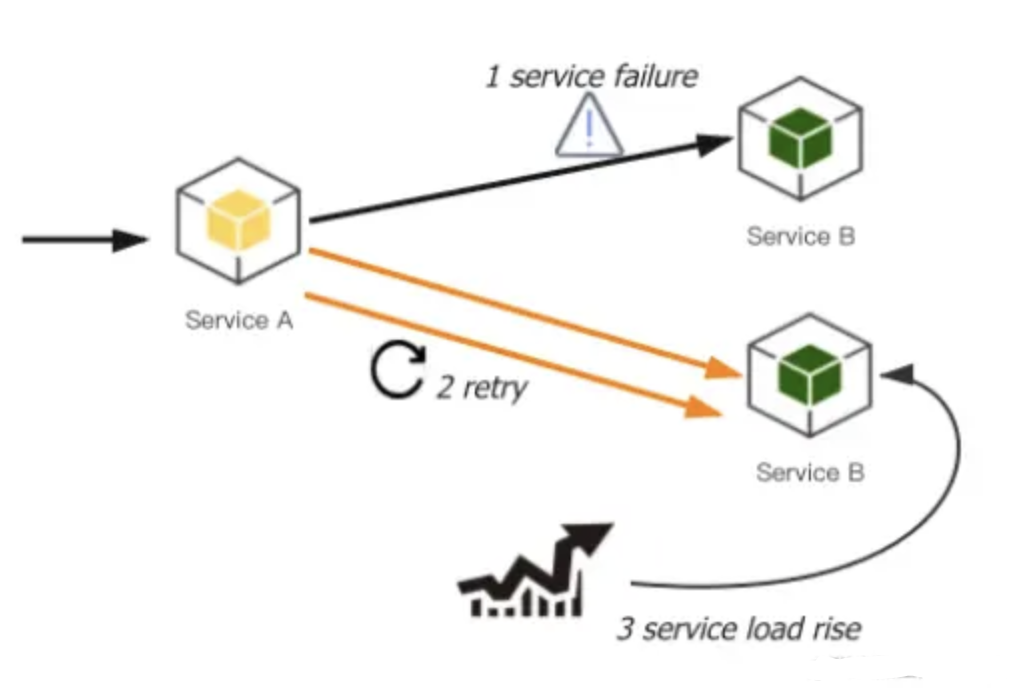
负载均衡(不至于其中一个服务压力过大而崩溃,从而提高成功率)

重试(增加成功率)
长尾请求
Backup Request
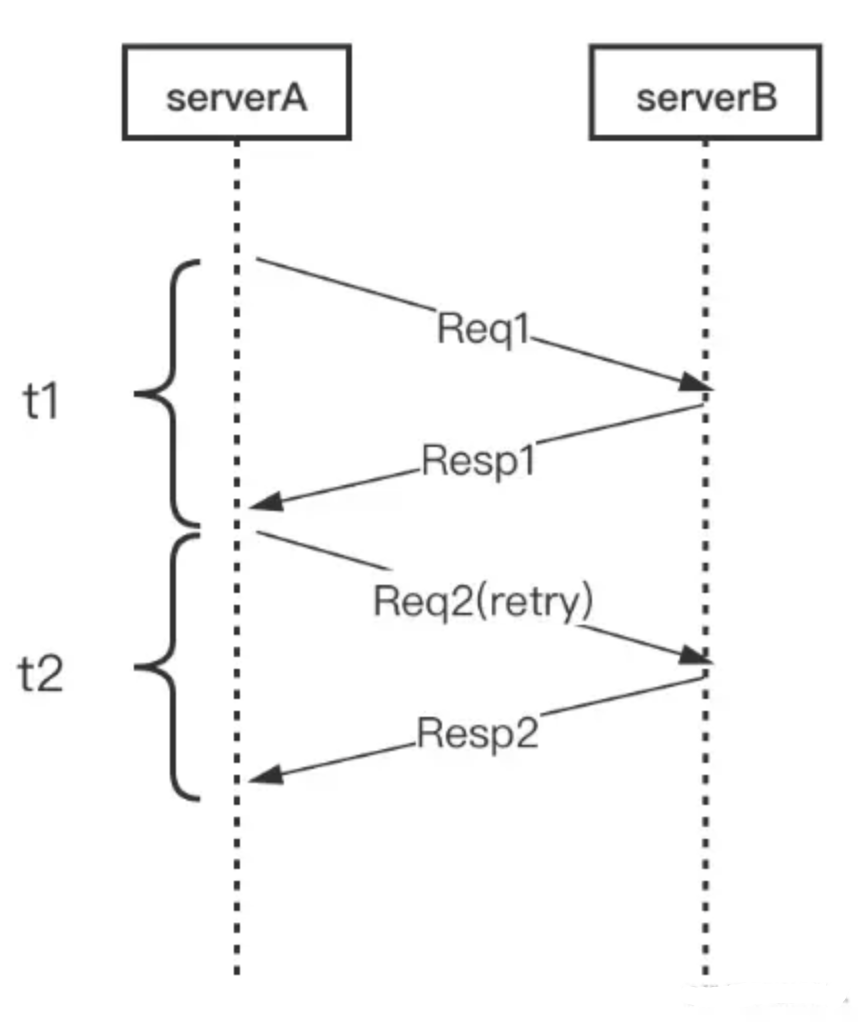
t1+t2=总用时(增加了总时间)

只请求一次,过t3时后再一次请求返回代表上一次在等待并且上一次可以成功,所以总时间为t4,是一个针对长尾请求的处理。
注册中间件
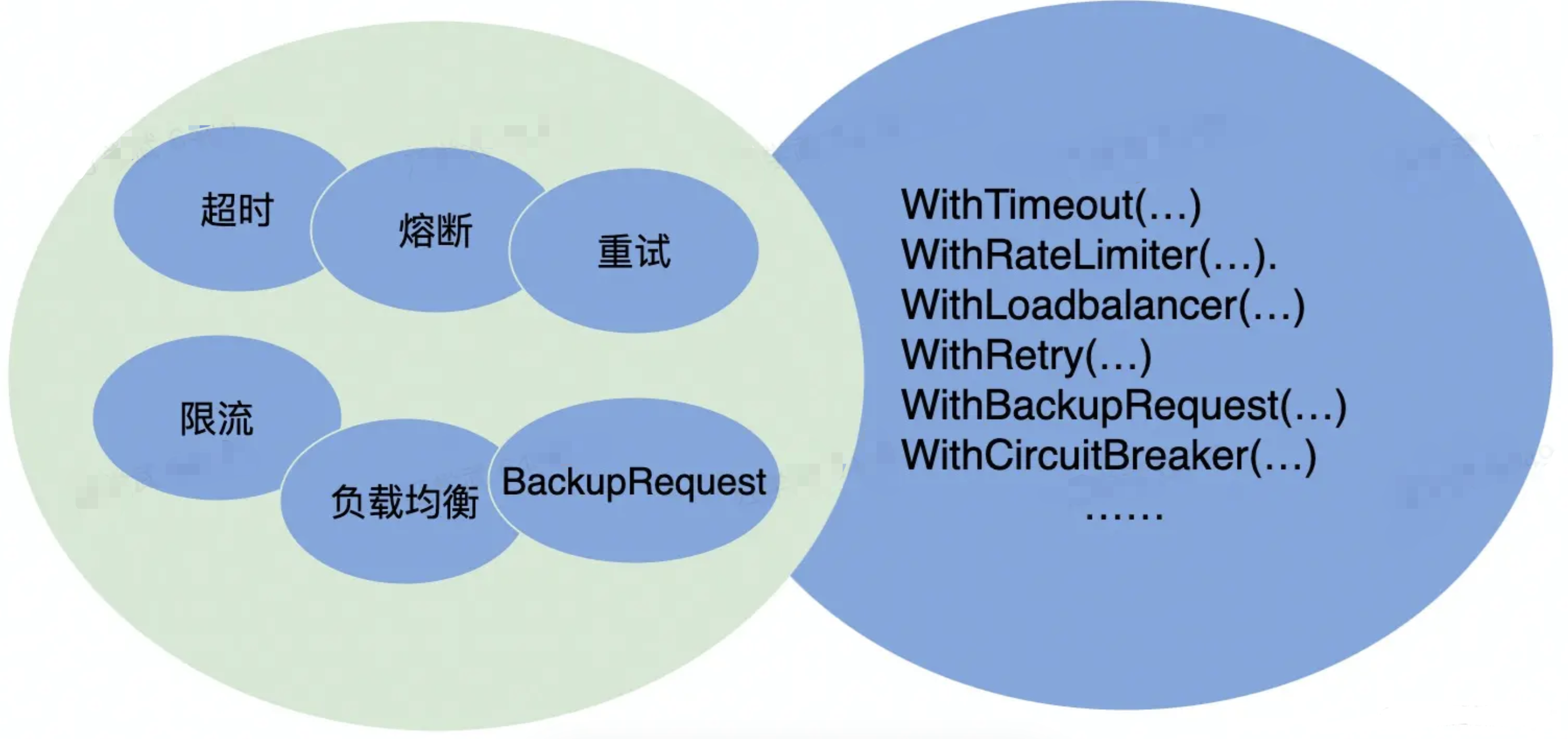
易用性
-
开箱即用
- 合理的默认参数选项、丰富的文档
-
周边工具
- 生成代码工具、脚手架工具
扩展性
-
Middleware
-
Option
-
编解码层
-
协议层
-
网络传输层
-
代码生成工具插件扩展
观测性
-
Log、Metric、Tracing
-
内置观测性服务

查看操作系统耗费资源工具(Linux top分析工具)
高性能
-
场景:单机多机、单连接多连接、单/多client 单/多 server、不同大小的请求包、不同请求类型:列如pingpong、streaming等
-
目标:高吞吐、低延迟
-
手段:连接池、多路复用、高性能编解码协议、高性能网络库
gRPC 介绍
gRPC 是一个开源的 RPC 框架,可以在任何环境中运行并连接不同的应用程序和服务。它是由谷歌基于其名为 Stubby 的内部 RPC 基础设施开发的。它使用 HTTP/2、协议缓冲区和各种功能,如身份验证、流式传输和负载平衡。它还可以为 API 接口生成文档。
如下图,DATA部分即业务层面内容,下面所有的信息都由gRPC进行封装。

gRPC 特点
-
语言中立,支持多种语言;
-
基于 IDL 文件定义服务,通过 proto3 工具生成指定语言的数据结构、服务端接口以及客户端 Stub;
-
通信协议基于标准的 HTTP/2 设计,支持双向流、消息头压缩、单 TCP 的多路复用、服务端推送等特性,这些特性使得 gRPC 在移动端设备上更加省电和节省网络流量;
-
序列化支持 PB(Protocol Buffer)和 JSON,PB 是一种语言无关的高性能序列化框架,基于 HTTP/2 + PB, 保障了 RPC 调用的高性能。
gRPC 交互过程

-
交换机在开启gRPC功能后充当gRPC客户端的角色,采集服务器充当gRPC服务器角色;
-
交换机会根据订阅的事件构建对应数据的格式(GPB/JSON),通过Protocol Buffers进行编写proto文件,交换机与服务器建立gRPC通道,通过gRPC协议向服务器发送请求消息;
-
服务器收到请求消息后,服务器会通过Protocol Buffers解译proto文件,还原出最先定义好格式的数据结构,进行业务处理;
-
数据处理完后,服务器需要使用Protocol Buffers重编译应答数据,通过gRPC协议向交换机发送应答消息;
-
交换机收到应答消息后,结束本次的gRPC交互。
简单地说,gRPC就是在客户端和服务器端开启gRPC功能后建立连接,将设备上配置的订阅数据推送给服务器端。我们可以看到整个过程是需要用到Protocol Buffers将所需要处理数据的结构化数据在proto文件中进行定义。
什么是Protocol Buffers
你可以理解ProtoBuf是一种更加灵活、高效的数据格式,与XML、JSON类似,在一些高性能且对响应速度有要求的数据传输场景非常适用。ProtoBuf在gRPC的框架中主要有三个作用:
-
定义数据结构
-
定义服务接口
-
通过序列化和反序列化,提升传输效率
为什么ProtoBuf会提高传输效率呢?
我们知道使用XML、JSON进行数据编译时,数据文本格式更容易阅读,但进行数据交换时,设备就需要耗费大量的CPU在I/O动作上,自然会影响整个传输速率。Protocol Buffers不像前者,它会将字符串进行序列化后再进行传输,即二进制数据。

可以看到其实两者内容相差不大,并且内容非常直观,但是Protocol Buffers编码的内容只是提供给操作者阅读的,实际上传输的并不会以这种文本形式,而是序列化后的二进制数据。字节数会比JSON、XML的字节数少很多,速率更快。
如何支撑跨平台,多语言呢?
Protocol Buffers自带一个编译器也是一个优势点。前面提到的proto文件就是通过编译器进行编译的,proto文件需要编译生成一个类似库文件,基于库文件才能真正开发数据应用。具体用什么编程语言编译生成这个库文件呢?由于现网中负责网络设备和服务器设备的运维人员往往不是同一组人,运维人员可能会习惯使用不同的编程语言进行运维开发,那么Protocol Buffers其中一个优势就能发挥出来——跨语言。
从上面的介绍,我们得出在编码方面Protocol Buffers对比JSON、XML的优点:
-
简单,体积小,数据描述文件大小只有1/10至1/3;
-
传输和解析的速率快,相比XML等,解析速度提升20倍甚至更高;
-
可编译性强。
基于HTTP 2.0标准设计
除了Protocol Buffers之外,从交互图中和分层框架可以看到, gRPC还有另外一个优势——它是基于HTTP 2.0协议的。
由于gRPC基于HTTP 2.0标准设计,带来了更多强大功能,如多路复用、二进制帧、头部压缩、推送机制。这些功能给设备带来重大益处,如节省带宽、降低TCP连接次数、节省CPU使用等。gRPC既能够在客户端应用,也能够在服务器端应用,从而以透明的方式实现两端的通信和简化通信系统的构建。
HTTP 版本分为HTTP 1.X、 HTTP 2.0,其中HTTP 1.X是当前使用最广泛的HTTP协议,HTTP 2.0称为超文本传输协议第二代。HTTP 1.X定义了四种与服务器交互的方式,分别为:GET、POST、PUT、DELETE,这些在HTTP 2.0中均保留。HTTP 2.0的新特性:
-
双向流、多路复用
-
二进制帧
-
头部压缩
Dubbo 介绍
Apache Dubbo 是一个易于使用、高性能的 WEB 和 RPC 框架,具有内置的服务发现、流量管理、可观察性、安全功能、工具和构建企业级微服务的最佳实践。
执行流程

-
紫色虚线:启动时完成的功能
-
蓝色虚线:运行过程中执行的功能,异步调用
-
蓝色实线:运行过程中执行的功能,同步调用
dubbo 的总体执行流程
(1)启动容器,加载,运行服务提供者。
(2)服务提供者在启动时,向注册中心注册自己提供的服务。
(3)服务消费者在启动时,向注册中心订阅自己所需的服务。
(4)注册中心返回服务提供者地址列表给消费者,消费者接收到之后,缓存在本地中,如果内容有变更,注册中心将基于长连接推送变更数据给消费者。
(5)服务消费者,从提供者地址列表中,基于软负载均衡算法,选择一台提供者进行调用,如果调用失败,再选另一台调用。
(6)服务消费者和提供者,在内存中累计调用次数和调用时间,定时每分钟发送一次统计数据到监控中心。
dubbo 的整个执行流程可以理解为生产者-消费者模型+注册中心+监控中心,这样设计的原因在于:
-
Consumer 与 Provider 解偶,双方都可以横向增减节点数
-
注册中心对本身可做对等集群,可动态增减节点,并且任意一台宕掉后,将自动切换到另一台
-
去中心化,双方不直接依懒注册中心,即使注册中心全部宕机短时间内也不会影响服务的调用
-
服务提供者无状态,任意一台宕掉后,不影响使用
dubbo 同步调用流程
-
(1)客户端线程调用远程接口,向服务端发送请求,同时当前线程应该处于“暂停“状态,即线程不能向后执行了,必需要拿到服务端给自己的结果后才能向后执行
-
(2)服务端接到客户端请求后,处理请求,将结果给客户端
-
(3)客户端收到结果,然后当前线程继续往后执行
dubbo 中使用了 Socket 来建立长连接、数据传输,而底层结合了的 Apache mina 框架,Apache mina 框架基于Reactor模型通信框架,基于tcp长连接。dubbo 使用 IoSession.write() 方法进行远程调用与发送消息,这个方法的远程调用过程异步的,即对于当前线程来说,将请求发送出来,线程就可以往后执行了,至于服务端的结果,是服务端处理完成后,再以消息的形式发送给客户端的。于是这里出现了2个问题:
(1)当前线程怎么让它“暂停”,等结果回来后,再向后执行:
先生成一个对象 obj,在一个全局 map 里 put(ID,obj) 存放起来,再用 synchronized 获取 obj 锁,再调用 obj.wait() 让当前线程处于等待状态,然后另一消息监听线程等到服务端处理结果到来,再 map.get(ID) 找到 obj,再用 synchronized 获取obj锁,再调用 obj.notifyAll() 唤醒前面处于等待状态的线程。
(2)Socket通信是一个全双工的方式,当有多个线程同时进行远程方法调用,这时 client 与 server 间的 socket 连接上会有很多双方发送的消息传递,前后顺序也可能是乱七八糟的,server处理完结果后,将结果消息发送给client,client收到很多消息,怎么知道哪个消息结果是原先哪个线程调用的:
使用一个ID,让其唯一,然后传递给服务端,再服务端又回传回来,这样就知道结果是原先哪个线程的了
dubbo同步调用原理
(1)客户端使用一个线程调用远程接口,生成一个唯一 ID,Dubbo 是使用 AtomicLong 从 0 开始累计数字的
(2)将打包的方法调用信息(如调用的接口名称,方法名称,参数值列表等),和处理结果的回调对象callback,全部封装在一起,组成一个对象object
(3)向专门存放调用信息的全局 ConcurrentHashMap 里面 put(ID, object)
(4)将 ID 和打包的方法调用信息封装成一对象 connRequest,使用 IoSession.write(connRequest) 异步发送出去
(5)当前线程再使用 callback 的 get() 方法试图获取远程返回的结果,在get()内部,则先使用synchronized获取回调对象callback的锁, 检测是否已经获取到结果,如果没有,然后调用 callback 的 wait() 方法,释放 callback 上的锁,让当前线程处于等待状态。
(6)服务端接收到请求并处理后,将结果(包含了唯一ID)回传给客户端,客户端 socket 连接上专门监听消息的线程收到消息后,分析结果,取到ID,再从前面的 ConcurrentHashMap 里面 get(ID),从而找到 callback,将方法调用结果设置到callback对象里。
(7)最后监听线程再获取回调对象 callback 的 synchronized 锁(因为前面调用过wait() 导致释放callback的锁),先使用 notifyAll() 唤醒前面处于等待状态的线程继续执行,这样 callback 的 get( )方法继续执行就能拿到调用结果了,至此,整个过程结束
需要注意的是,这里的callback对象是每次调用产生一个新的,不能共享;另外ID必需至少保证在一个Socket连接里面是唯一的。
负载均衡策略
负载均衡机制解决的是如何在多个可用远程服务提供者中,选择下一个进行调用,常见的负载均衡策略有
(1)随机调用策略(默认):随机选择服务器节点,该策略可以对不同服务器实例设置不同的权重,权重越大分配流量越高
(2)轮询调用策略:均匀地将请求分配到各个机器上。如果各个机器的性能不一样,容易导致性能差的机器负载过高,所以此时需要调整权重,让性能差的机器承载权重小一些,流量少一些。
(3)最少活跃数策略:根据服务器的运行状态去选择服务,如果某个机器性能越差,那么接收的请求越少,越不活跃,此时就会给不活跃的性能差的机器分配更少的请求
(4)一致性哈希算法:相同参数的请求一定会被分发到固定的服务器节点。当某个服务器节点挂掉的时候,会基于虚拟节点均匀分配剩余的流量,抖动不会太大。
容错机制
容错策略解决的是,一旦发现远程调用失败,如果进行下一步操作以减少错误影响,常见的容错策略有
Failover(默认):失败自动切换,当出现失败,重试其它服务器,默认为2次。通常用于读操作,但重试会带来更长延迟。
Failfast:快速失败,只发起一次调用,失败立即报错。通常用于非幂等性的写操作,比如新增记录。
Failsafe:失败安全,出现异常时,直接忽略。通常用于写入审计日志等操作。
Failback:失败自动恢复,后台记录失败请求,定时重发。通常用于消息通知操作。
Forking:并行调用多个服务器,只要一个成功即返回。通常用于实时性要求较高的读操作,但需要浪费更多服务资源。可通过 forks=”2″ 来设置最大并行数。
Broadcast:广播调用所有提供者,逐个调用,任意一台报错则报错 。通常用于通知所有提供者更新缓存或日志等本地资源信息。
支持协议和适用场景
(1)dubbo:单一长连接和 NIO 异步通讯,适合大并发小数据量的服务调用,以及消费者远大于提供者的情况。传输协议 TCP,异步 Hessian 序列化。Dubbo 官方推荐使用 dubbo 协议。但是,dubbo 协议不适合传送大数据量的服务,比如传文件,传视频等,除非请求量很低
(2)RMI: 采用 JDK 标准的 RMI 协议实现,使用 Java 标准序列化机制,传输参数和返回参数对象需要实现 Serializable 接口,使用阻塞式短连接,传输数据包大小混合,消费者和提供者个数差不多,可传文件,传输协议 TCP。多个短连接,基于 TCP 协议传输,同步传输,适用常规的远程服务调用和 RMI 互操作。在依赖低版本的 Common-Collections 包,Java 序列化存在安全漏洞。
(3)WebService:基于 WebService 的远程调用协议,集成 CXF 实现,提供和原生 WebService 的互操作。多个短连接,基于 HTTP 传输,同步传输,适用系统集成和跨语言调用。
(4)HTTP: 基于 Http 表单提交的远程调用协议,使用 Spring 的 HttpInvoke 实现。多个短连接,传输协议 HTTP,传入参数大小混合,提供者个数多于消费者,需要给应用程序和浏览器 JS 调用。
(5)Hessian:集成 Hessian 服务,基于 HTTP 通讯,采用 Servlet 暴露服务,Dubbo 内嵌 Jetty 作为服务器时默认实现,提供与 Hession 服务互操作。多个短连接,同步 HTTP 传输,Hessian 序列化,传入参数较大,提供者大于消费者,提供者压力较大,可传文件。
(6)Redis:基于 Redis 实现的RPC协议。
(7)Memcache:基于 Memcache实现的 RPC 协议。
通信框架
dubbo 默认使用 Netty 作为通讯框架
架构设计
升为apache顶级项目的dubbo可以说是java语言中RPC架构最流行的框架。同时Dubbo的文档也是开源软件中写的最详细的文档之一,细看dubbo官方文档。如下是 Dubbo 的设计架构图,分层清晰,功能复杂:
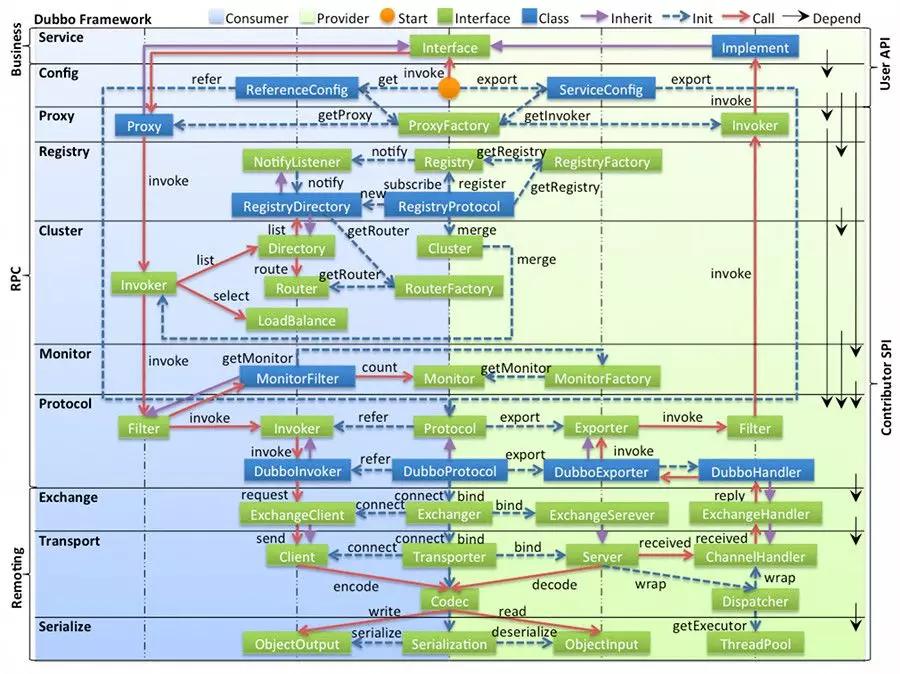
图例说明
-
图中左边淡蓝背景的为服务消费方使用的接口,右边淡绿色背景的为服务提供方使用的接口,位于中轴线上的为双方都用到的接口。
-
图中从下至上分为十层,各层均为单向依赖,右边的黑色箭头代表层之间的依赖关系,每一层都可以剥离上层被复用,其中,Service 和 Config 层为 API,其它各层均为 SPI。
-
图中绿色小块的为扩展接口,蓝色小块为实现类,图中只显示用于关联各层的实现类。
-
图中蓝色虚线为初始化过程,即启动时组装链,红色实线为方法调用过程,即运行时调时链,紫色三角箭头为继承,可以把子类看作父类的同一个节点,线上的文字为调用的方法。
各层说明
-
config 配置层:对外配置接口,以 ServiceConfig, ReferenceConfig 为中心,可以直接初始化配置类,也可以通过 spring 解析配置生成配置类
-
proxy 服务代理层:服务接口透明代理,生成服务的客户端 Stub 和服务器端 Skeleton, 以 ServiceProxy 为中心,扩展接口为 ProxyFactory
-
registry 注册中心层:封装服务地址的注册与发现,以服务 URL 为中心,扩展接口为 RegistryFactory, Registry, RegistryService
-
cluster 路由层(RMI没有这一层,因为直接指定具体服务端或客户端):封装多个提供者的路由及负载均衡,并桥接注册中心,以 Invoker 为中心,扩展接口为 Cluster, Directory, Router, LoadBalance
-
monitor 监控层(非核心,非必须):RPC 调用次数和调用时间监控,以 Statistics 为中心,扩展接口为 MonitorFactory, Monitor, MonitorService
-
protocol 远程调用层(从protocol 远程调用层往下4层可以看成RMI图中的Remote层):封装 RPC 调用,以 Invocation, Result 为中心,扩展接口为 Protocol, Invoker, Exporter
-
exchange 信息交换层:封装请求响应模式,同步转异步,以 Request, Response 为中心,扩展接口为 Exchanger, ExchangeChannel, ExchangeClient, ExchangeServer
-
transport 网络传输层:抽象 mina 和 netty 为统一接口,以 Message 为中心,扩展接口为 Channel, Transporter, Client, Server, Codec
-
serialize 数据序列化层:可复用的一些工具,扩展接口为 Serialization, ObjectInput, ObjectOutput, ThreadPool
Thrif 介绍
thrift 允许您在一个简单的定义文件中定义数据类型和服务接口。以该文件为输入,编译器生成代码,用于轻松构建跨编程语言无缝通信的RPC客户端和服务器。您可以直接进入业务,而不是编写大量样板代码来序列化和传输对象以及调用远程方法。
2007年由facebook贡献到apache基金,是apache下的顶级项目,具备如下特点:
-
支持多语言
-
消息定义文件支持注释,数据结构与传输表现的分离,支持多种消息格式
-
包含完整的客户端/服务端堆栈,可快速实现RPC,支持同步和异步通信
分层设计
分为三层:编解码层、协议层、网络通信层
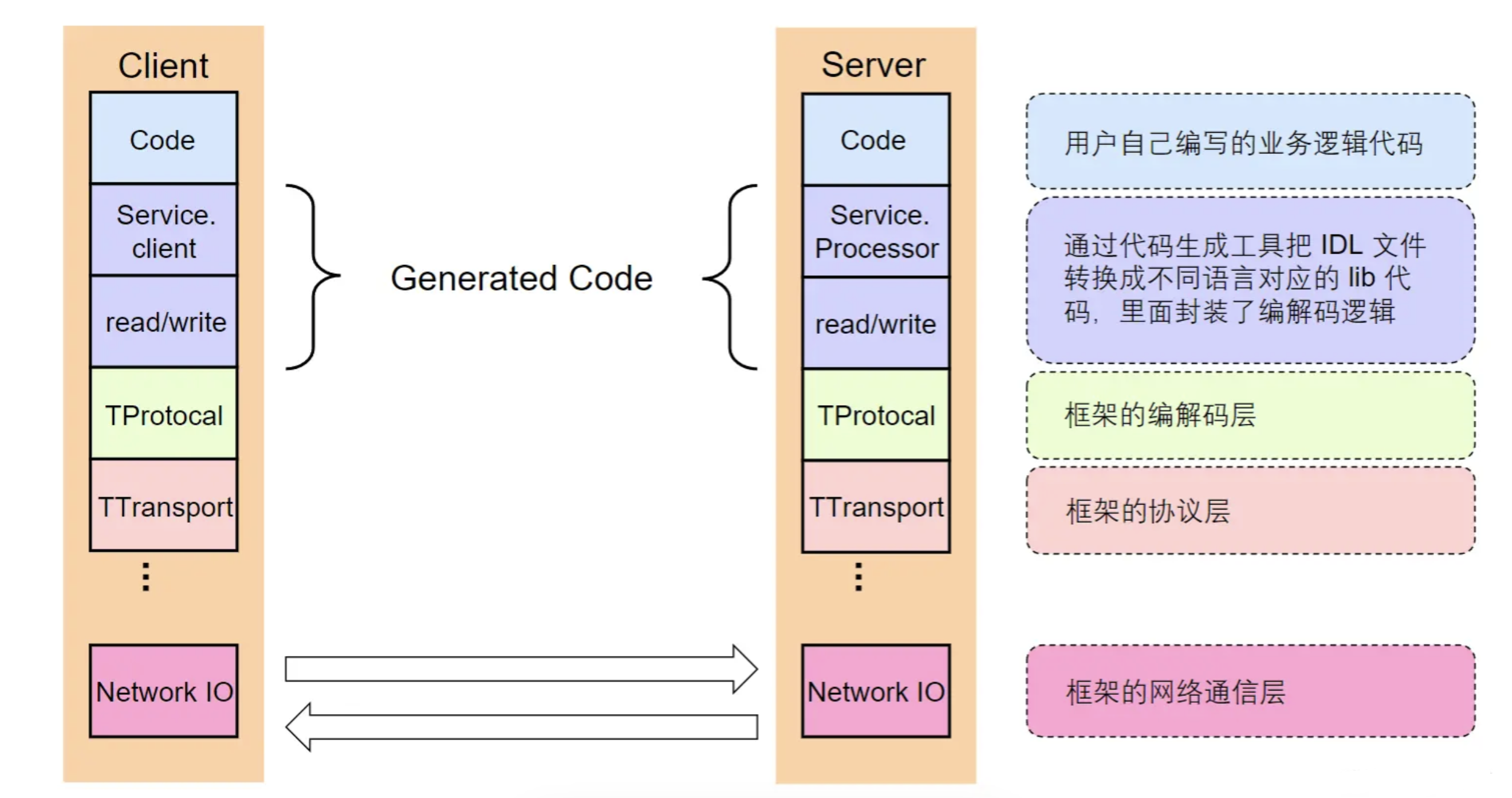
图中code是用户实现的业务逻辑,接下来的 Service.Client和 write()/read()是thrift根据IDL生成的客户端和服务端的代码,对应于RPC中Client stub和Server stub。TProtocol 用来对数据进行序列化与反序列化,具体方法包括二进制,JSON 或者 Apache Thrift 定义的格式。TTransport 提供数据传输功能,使用 Apache Thrift 可以方便地定义一个服务并选择不同的传输协议。
编解码层

生成代码
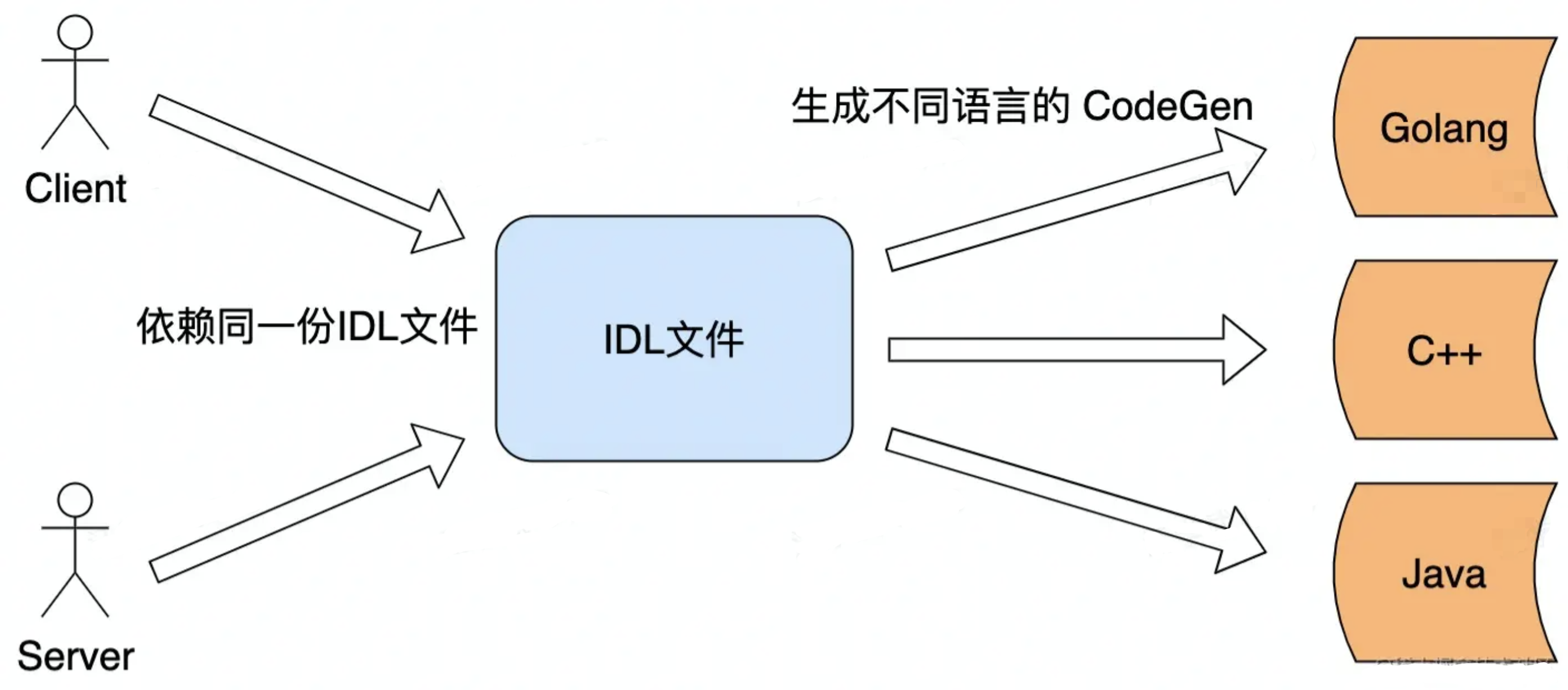
因为跨语言之间的调用,需要一个跨语言的服务接口定义,IDL就是为了满足这个场景而出现的。IDL是很多RPC框架用来支持跨语言环境调用的一个服务描述组件,一般都是采用文本格式来定义。接口定义文件是 Thrift 开发的核心,定义了 RPC 过程中通信的数据结构和通信的接口方法定义等。Thrift的不同版本定义IDL的语法也不太相同,这里使用Thrift-0.9.2这个版本来介绍Java下的IDL定义:
-
namespace 定义包名
-
struct 定义服务接口的参数,返回值使用到的类结构。如果接口的参数都是基本类型,则不需要定义struct
-
service 定义接口
-
基本类型(https://thrift.apache.org/docs/types)
详细的接口定义参考官方文档(https://thrift.apache.org/docs/idl)。
数据格式
-
语言特定的格式(优点:非常方便可以用额外很少的代码实现内存对象的保存和恢复。缺点:因为是和语言进行绑定的所以每个语言间的兼容性是一个问题。)
- 许多编码语言都内建了将内存对象编码为字节序列的支持,例如 Java 有 java.io.Serializable
-
文本格式(例如json格式只有字符串和整性类型,不能处理浮点数的类型,对于处理大量数据问题就很严重,并且没有产品的模型约束,只有文档约束,调试起来不方便)
- JSON、XML、CSV等文本格式,具有人类可读性
-
二进制编码(指将数据转换成二进制流,实现方式有tlv编码等)
- 具备跨语言和高性能等优点,常见有Thrift的BinaryProtocol,Protobuf等
二进制编码
TLV 编码
-
Tag:标签,可以理解为类型
-
Lenght:长度
-
Value:值,Value也可以是个TLB结构


选型
-
兼容性
- 支持自动增加新的字段,而不影响老的服务,这将提高系统的灵活度
-
通用性
- 支持跨平台、跨语言
-
性能
- 从空间和时间两个维度来考虑,也就是编码后数据大小和编码耗费时长
协议层

概念
-
特殊结束符
- 一个特殊字符作为每个协议单元结束的标示

-
变长协议
- 以定长加不定长的部分组成,其中定长的部分需要描述

协议构造
-
LENGTH: 数据包大小,不包含自身
-
HEADER MAGIC: 标识版本信息,协议解析时候快速校验
-
SEQUENCE NUMBER: 表示数据包的seqID,可用于多路复用,单连接内递增
-
HEADER SIZE:头部长度,从第14个字节开始计算一直到PAYLOAD前
-
PROTOCOL ID: 编解码方式,有Binary和Compact两种
-
TRANSFORM ID: 压缩方式,如zlib和snappy
-
INFO ID: 传递一些定制的meta信息
-
PAYLOAD: 消息体

协议解析

一个简单的协议解析过程
网络通信层

Sockets API
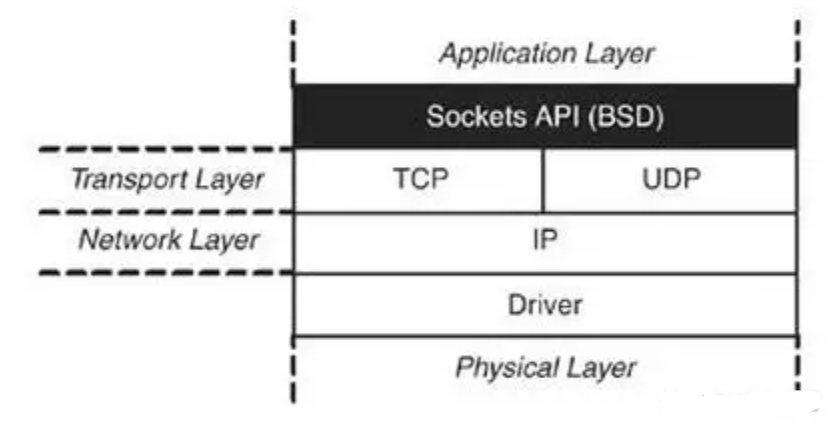
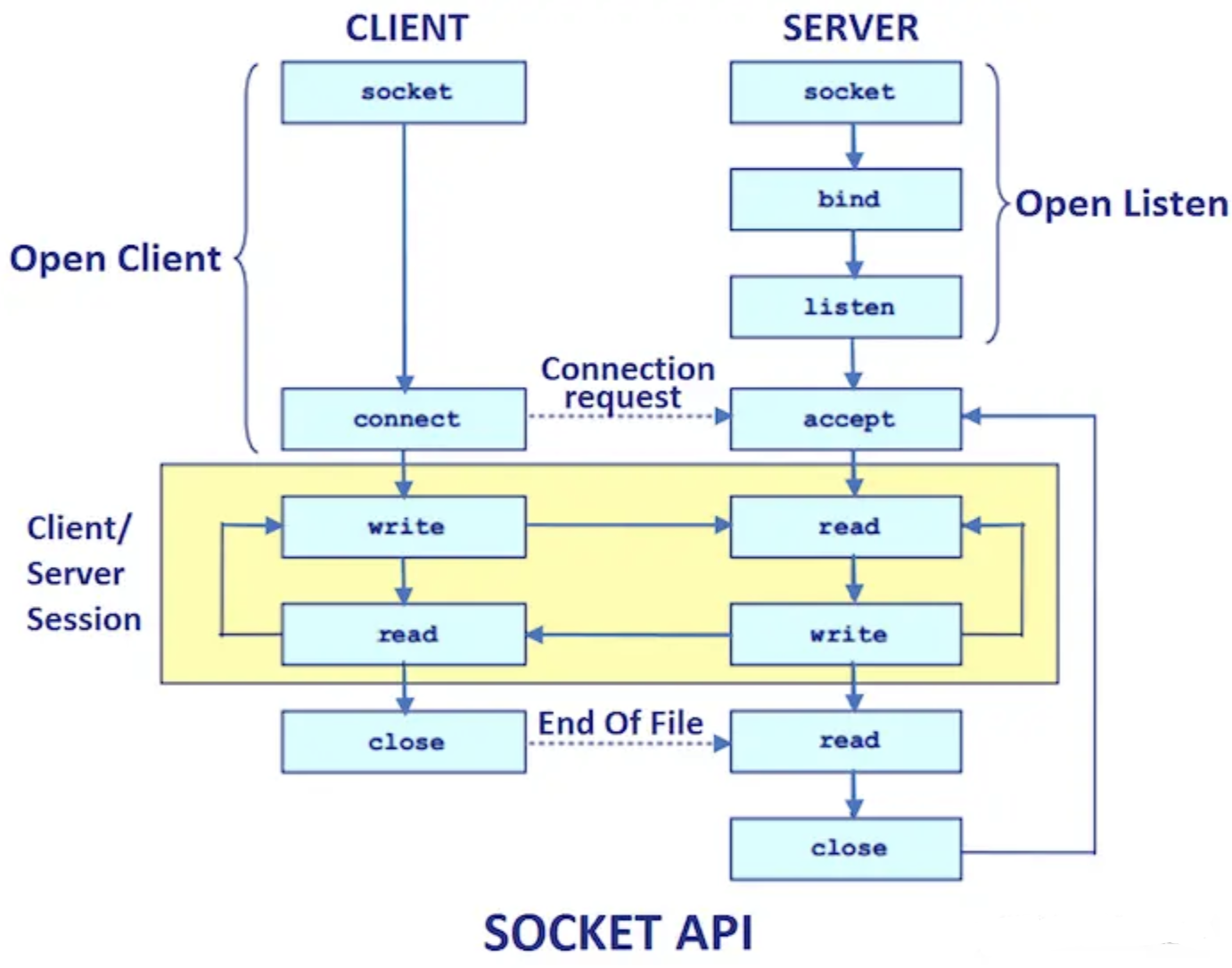
网络库
-
提供易用 API
-
封装底层Socket API
-
连接管理和事件分发
-
-
功能
-
协议支持:tcp、udp和uds等
-
优雅退出、异常处理等
-
-
性能
-
应用层buffer 减少 copy
-
高性能定时器、对象池等
-