serviceworker运用与实践
工作者线程(Web Workers)
官方文档规范参考:https://html.spec.whatwg.org/multipage/workers.html
JavaScript 是单线程的,这样可以保证它与浏览器 API 兼容。如果 JavaScript 可以多线程执行并发更改,那么像 DOM 这样的 API 就会出现问题。因此 POSIX 线程与 Java 的 Thread 类等传统并发结构都不适合 JavaScript。
单线程意味着不能把工作委托给独立的线程、进程去做。这就是 工作者线程(Web Workers) 的价值所在:允许把主线的工作转嫁给独立的实体,而不会改变现有的单线程模型。它的特点是独立于 JavaScript 主执行环境。
JS 运行在虚拟环境,浏览器中,每打开一个页面,就会分配一个它自己的环境。每个页面都有自己的内存、事件循环、DOM,等等。每个页面相当于一个沙盒,不会干扰其他页面。对浏览器来说,这些环境都是并行执行的。
使用 工作者线程 浏览器可以在环境之外再分配一个完全独立的二级子环境,这个子环境不能与依赖单线程交互的 API(如 DOM)互相操作,但可以与父环境并行执行代码。
工作者线程与线程
工作者线程与线程的比较:
-
工作者线程基于实际线程实现
-
工作者线程并行执行
-
工作者线程可以共享某些内容,不共享全部内存。
-
工作者线程不一定在同一个进程里
-
创建工作者线程的开销较大。它有自己独立的事件循环、全局对象、事件处理程序和其他 JS 环境必须的特性。
WARNING 工作者线程相对比较重,不建议大量使用。工作者线程应该是长期运行的,启动成本比较高、每个实例占用的内存比较大。
三种工作者线程类型
Web Workers 规范中定义了三种主要的工作者线程:
1、专用工作者线程(Dedicated Workers),通常简称 Web Worker 或 Worker,可以单独创建一个 JS 线程,这个线程只能被创建它的页面使用。
2、共享工作者线程(Shared Workers),与专用工作者线程类似,任何与创建共享工作者线程的 JS 同源的 JS,都可以向共享工作者线程发送、接收消息。
3、服务工作者线程(Service Workers),与专用工作者线程和共享工作者线程不同,它主要用于拦截、重定向和修改页面发出的请求,充当网络请求的仲裁者角色。
服务工作者线程(Service Workers)

Service Worker 服务工作者线程,是一种类似浏览器中代理服务器的线程。可以拦截请求、缓存响应,可以让网页在没有网络连接的情况下正常使用。服务工作者线程也可以使用 Notifications API、Push API、Background Sync API 和 Channel Messaging API.
与共享工作者线程(Shared Workers)类似,来自一个域的多个页面共享一个服务工作者线程。为了使用 Push API 等特性,服务工作者线程也可以在相关的标签页或浏览器关闭后继续等待到来的推送事件。
对大多数开发者而言,Service Worker 在两个主要任务上最有用:充当网络请求的缓存层、启用推送通知。在这个意义上,Service Worker 就是用于把网页变成像原生应用程序一样的工具。
基础
服务工作者线程(Service Worker) 与 专用工作者线程(Dedicated Workers) 和 共享工作者线程(Shared Workers) 的一个区别是:没有全局构造函数。由 navigator.serviceWorker 来管理。它的类型是 ServiceWorkerContainer。
console.log(navigator.serviceWorker)
// ServiceWorkerContainer { controller: null, ready: Promise, oncontrollerchange: null, onmessage: null, onmessageerror: null}
创建服务工作者线程
// 注册成功,走 console.log 逻辑
navigator.serviceWorker.register('./serviceWorker.js')
.then(console.log, console.error)
// ServiceWorkerRegistration { .. }
// 注册失败,走 console.error 逻辑
navigator.serviceWorker.register('./notExistWorker.js')
.then(console.log, console.error)
// A bad HTTP response code (404) was received when fetching the script.
// TypeError: Failed to register a ServiceWorker for scope ...
一般服务工作者线程对于何时注册是比较灵活的,多次调用 register(),后面的实际什么都不会执行。一般如果之前没有注册过,一般在 load 事件里注册,这样不会影响页面的首次加载。除非该服务工作者线程负责管理缓存(这样的话就要尽早注册,比如使用后面要介绍的 clients.claim())。
if ('serviceWorker' in navigator) {
window.addEventListener('load', () => {
navigator.serviceWorker.register('./serviceWorker.js');
});
}
使用 ServiceWorkerContainer 对象
navigator.serviceWorker 支持如下属性、方法、事件:
-
ready 属性返回 resolve 为激活的 ServiceWorkerRegistration 对象的 Promise,该 Promise 不会 reject。 -
controller 属性返回当前页面关联的、激活的 ServiceWorker 对象,如果没有激活的 ServiceWorker 则返回 null -
register(url, options) 方法创建或更新 ServiceWorkerRegistration. -
getRegistration() 方法返回 resolve 为当前作用域匹配的 ServiceWorkerRegistration 对象的 Promise,如果没有匹配的,则返回 undefined -
getRegistrations() 方法返回 resolve 为当前作用域匹配的 ServiceWorkerRegistration 对象数组的 Promise,如果没有匹配的,则返回空数组 -
startMessage() 方法开始传送通过 Client.postMessage() 派发的消息 -
controllerchange 事件在获得新激活的 ServiceWorkerRegistration 时触发 -
message 事件在 ServiceWorker 脚本向父上下文发送消息时触发 -
error 事件在 ServiceWorker 内部抛出错误时触发,以上事件均可以使用 on 或 addEventListener 监听处理
使用 ServiceWorkerRegistration 对象
调用 navigator.serviceWorker.register() 成功之后会返回一个 resolve ServiceWorkerRegistration 对象的 Promise。同一页面使用同一 URL 多次调用该方法会返回相同的注册对象。ServiceWorkerRegistration 支持以下属性、方法、事件:
-
scope 属性返回 Service Worker 作用域完整的 URL 路径。比如:”http://127.0.0.1:5502/src/” -
navigationPreload 属性返回与注册对象关联的 NavigationPreloadManager 实例 -
pushManager 属性返回与注册对象关联的 pushManager 实例 -
installing 属性返回状态为 installing 的 ServiceWorker 对象,否则为 null -
waiting 属性返回状态为 waiting 的 ServiceWorker 对象,否则为 null -
active 属性返回状态为 active 的 ServiceWorker 对象,否则为 null -
getNotifications() 方法返回 resolve 为 Notification 对象数组的 Promise -
showNotifications() 方法显示通知,可以配置 title 和 options 配置 -
update() 方法直接从服务器重新请求服务脚本,如果新脚本不同,则重新初始化 -
unregister() 方法取消 ServiceWorker 的注册,该方法会在 ServiceWorker 执行完再取消注册 -
updatefound 事件在 ServiceWorker 开始安装新版本时触发,表现为 ServiceWorkerRegistration.installing 收到一个新的 ServiceWorker
使用 ServiceWorker 对象
ServiceWorker 对象继承自 Worker 对象,可以使用以下两种方法获取
1、navigator.serviceWorker.controller
2、ServiceWorkerRegistration对象.active
ServcieWorker 对象支持以下属性、方法、事件:
-
scriptURL 属性解析后注册 ServiceWorker 的 URL,比如 “http://127.0.0.1:5502/src/serviceWorker.js” -
state 属性表示 ServiceWorker 状态,值可能是:installing、installed、activating、activated、redundant 冗余的、不需要的(已失效) -
postMessage() 方法向父上下文发送消息 -
statechange 事件在 ServcieWorker.state 状态变更时触发 -
error 事件在 serviceWorker 发送错误时触发
ServiceWorker 的安全限制
与其他工作者线程一样,服务工作者线程也需要同源。另外由于 ServiceWorker 几乎可以任意修改和重定向网络请求,以及加载静态资源,ServiceWorker API 只能在安全上下文(HTTPS)中使用。在 http 中 navigator.serviceWorker 为 undefined。为方便开发浏览器豁免了 localhost 和 http://127.0.0.1 在安全方面的限制,可以使用 window.isSecureContext 确定当前上下文是否安全。
ServiceWorkerGlobalScope
在 ServiceWorker 内部,全局上下文是 ServiceWorkerGlobalScope 实例。它继承自 WorkerGlobalScope,因此拥有它的所有属性和方法。可通过 self 关键字访问全局上下文。ServiceWorkerGlobalScope 扩展了以下属性、方法、事件
-
caches返回 ServiceWorker 的 CacheStorage 对象 -
clients返回 ServiceWorker 的 Clients 接口,用于访问底层的 Client 对象 -
registration返回 ServiceWorker 的 ServiceWorkerRegistration 对象 -
skipWaiting() 方法强制 ServiceWorker 进入 active 状态,需要跟 Clients.claim [kleɪm] 一起使用。 -
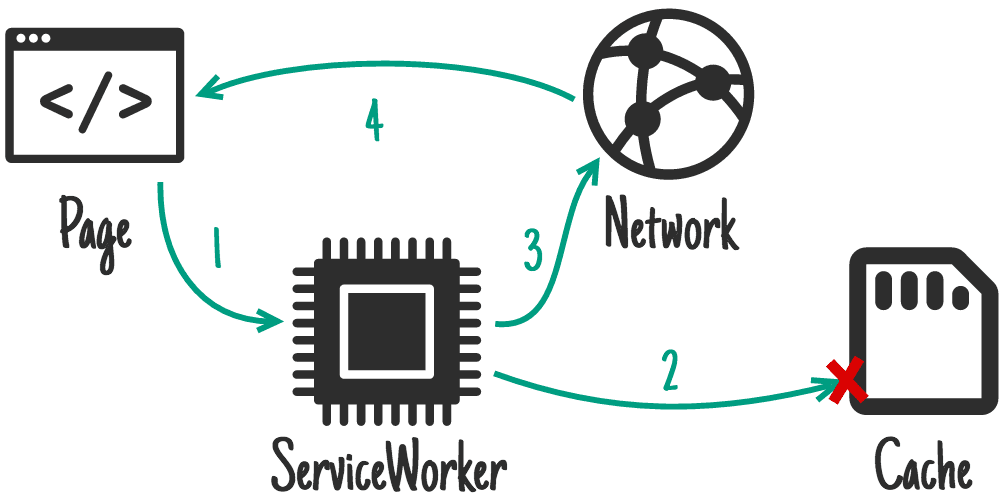
fetch() 方法在 serviceWorker 内发送常规网络请求,用于 serviceWorker 确定有必要发送实际网络请求,而不是返回缓存值时。 -
install 事件在 ServiceWorker 进入安装状态时触发,通过 ServiceWorkerRegistration.installing 判断,serviceWorker 内部接收到的第一个事件,一开始执行就会触发。每个 service worker 只调用一次。 -
activate 事件在 ServceWorker 进入 激活 或 已激活状态时触发,通过 ServiceWorkerRegistration.active 判断。一般发生在 ServiceWorker 准备好处理功能性事件和控制客户端时触发。表示具有控制客户端的条件。 -
fetch 事件Fetch API ,在 ServiceWorker 截获来自主页面的 fetch() 请求时触发 -
message 事件Message API,在 ServiceWorker 通过 postMessage() 获取数据时触发 -
notificationclick 事件Notification API,在用户点击了 ServiceWorkerRegistration.showNotification() 生成的通知时触发。 -
notificationclose 事件在用户关闭或取消了 ServiceWorkerRegistration.showNotification() 生成的通知时触发。 -
push 事件Push API,在 ServiceWorker 接收到消息推送时触发 -
pushsubscriptionchange 事件在应用控制外的因素(非 JS 显式操作)导致推送订阅状态发生变化时触发
ServiceWorker 作用域限制
ServiceWorker 仅能拦截其作用域内的客户端发送的请求,默认为 serviceWorker 脚本路径,也可以在 register() 时,通过 options 参数的 scope 指定
navigator.serviceWorker.register('/serviceWorker.js', {
scope: '/foo/'
}).then(serviceWorkerRegistration => {
console.log(serviceWorkerRegistration.scope)
// 'http://www.xxx.com/foo/'
})
// 会被拦截
fetch('/foo/fooScript.js')
// 不会被拦截
fetch('/foo.js')
fetch('/baz/bazScript.js')
一般 scope 参数,只能缩小作用域,如果 serviceWorker.js 在 /foo/ 目录下,而 scope 指定为 / 则会抛出错误。因为这样扩展了作用域。如果想要 扩展 扩展 serviceWorker 作用域有两种方法:
1、修改 seriveWorker.js 的路径到想要的作用域路径下
2、设置服务器响应头 Service-Worker-Allowed 为想要的作用域,或者 *
缓存
在 Service Worker 前,网页缺少缓存网络请求的稳健机制,浏览器一直使用 HTTP 缓存,但 HTTP 缓存并没有对 JS 暴露编程接口。之前的缓存方案 AppCache 需要很多前提条件,已废弃。
Service Worker 的一个主要能力就是可以通过编程方式实现真正的网络请求缓存控制。 它遵循以下几点
1、ServiceWorker 缓存不自动缓存任何内容,所有缓存必须明确指定
2、ServiceWorker 缓存没有失效的概念,除非明确删除,否则缓存内容一直有效
3、ServiceWorker 缓存必须手动更新和删除
4、缓存版本必须手动管理
5、ServiceWorker 缓存占用空间超过限制时,会将最近最少使用(LRU,Least Recently Used)的缓存内容删除,为新缓存腾出空间。
在 ServiceWorker 脚本中,使用 caches 或 self.caches 获取 CacheStorage 对象,它类似于 Map。支持如下方法
-
caches.open(keyStr)通过字符串键获取对应的 Cache,如果不存在,就会创建。Cache 对象通过 Promise resolve 返回 。如果参数是非字符串,会转换为字符串 -
caches.has(keyStr)返回 Promise,resolve 为是否包含该 key 的布尔值 -
caches.delete(keyStr)返回 Promise,删除对应的 key -
caches.keys()返回 Promise,resolve 为 caches 中对应的 key 数组 -
caches.match(request, options)根据 Request 对象搜索 CacheStorage 中的所有 Cache 对象,所示顺序按 CacheStorage.keys() 顺序,返回匹配的第一个响应
navigator.serviceWorker.register('./serviceWorker.js')
.then((registration) => {
caches.open('v1').then(cache => {
caches.has('v1').then(console.log) // true
console.log(cache) // Cache {}
caches.has('v2').then(console.log) // false
caches.delete('v1')
.then(() => caches.has('v1'))
.then(console.log) // false
})
caches.open('a1')
.then(() => caches.open('a2'))
.then(() => caches.open('a3'))
.then(() => caches.keys())
.then(console.log) // ["a1", "a2", "a3"]
const request = new Request('abc') // key
const response1 = new Response('s1')
const response2 = new Response('s2')
caches.open('s1')
.then((s1cache) => s1cache.put(request, response1))
.then(() => caches.open('s2'))
.then((s2cache) => s2cache.put(request, response2))
.then(() => caches.match(request))
.then((res) => res.text())
.then(console.log) // s1
}, console.error)
通过 caches.open() 方法可以获取或创建 Cache 对象,Cache 对象和 Map 类似,也是键值对,他的 key 可以是 URL 字符串、Request 对象。这些键会映射到 Response 对象。
Service Worker 缓存只考虑缓存 HTTP 的 GET 请求,Cache 不允许使用 POST、PUT、DELETE 等请求方法。Cache 对象支持如下方法
-
put(request, response)在键(Request 对象或 URL 字符串)和值(Response 对象)都存在时,添加缓存项。返回 Promise,添加成功后 resolve -
add(request)在只有 Request 对象或 URL 时,使用此方法发送 fetch() 请求,并缓存响应。返回 Promise,在添加成功后 resolve -
addAll(requests)addAll() 会对 request 数组中的每一项都调用 add(),返回 Promise,在所有缓存内容添加成功时 resolve -
delete(request)删除,Promise 方式 -
keys()列出所有 key,Promise 方式 -
matchAll(request, options)根据 request 检索缓存,返回 Promise,resolve 为 Response 数组。 -
match(request, options)根据 request 检索缓存,返回 Promise,resolve 为 Response 对象。相当于 matchAll(request, options)[0],查找不到则为 undefined
navigator.serviceWorker.register('./serviceWorker.js')
.then(registration => {
const request1 = 'https://www.foo.com'
const request2 = new Request('https://www.bar.com')
const response1 = new Response('fooResponse')
const response2 = new Response('barResponse')
caches.open('v1').then(cache => {
cache.put(request1, response1)
.then(() => cache.put(request2, response2))
.then(() => cache.match(new Request('https://www.foo.com')))
.then(res => res.text())
.then(console.log) // 'fooResponse'
.then(() => cache.match('https://www.bar.com'))
.then(res => res.text())
.then(console.log) // 'barResponse'
})
})
注意 Cache 对象 添加值时,key 和 value 都是 clone() 后存储的。并不等于之前的 Request 和 Response 对象
Catch.match()、Cache.matchAll() 和 CatchStorage.match() 都支持可选的 options 对象,它允许通过以下属性来配置 URL 匹配的行为
-
cacheName只有 CatchStorage.matchAll() 支持,设置字符串时,只会匹配 Ciche 键为指定字符串的缓存值 -
ignoreSearch设置为 true 时,在匹配 URL 时会忽略查询字符串 -
ignoreMethod设置为 true 时,在匹配时忽略查询的 HTTP 方法。比如如果设置了该参数为 true,用 POST 的 request 可以匹配到对应的 GET request -
ignoreVary匹配时是否考虑 HTTP 的 Vary 头部,为 ture 时忽略 该头部
最大存储空间,使用 StorageEstimate API 可以大致的获取有多少空间可用,以及当前使用了多少空间,此方法只在安全上下文中可用。
navigator.storage.estimate().then(console.log)
// 可用空间,单位 字节 299,977,904,946
// 不同的浏览器可能不同,mac chrome
// {quota: 299977904946, usage: 0, usageDetails: {…}}
客户端
使用 self.clients 或 clients 可以获取 Clients 接口。可以通过 Clients 接口访问 Client 对象。Client 对象用于跟踪关联的窗口、Web Worker、Service Worker。Client 对象支持以下属性和方法
-
id返回客户端的全局唯一标识,例如 ‘ab123e43-xxxx-xxxx..’,id 可用于 clients.get() 获取客户端的引用 -
type客户端类型,可能是 window, worker 或 shadowworker -
url返回客户端的 URL -
postMessage()向单个客户端发送消息
Clients 接口支持如下属性和方法
-
get(id)返回一个匹配给定 id 的 Client 的 Promise . -
matchAll(options)返回一个 Client 对象数组的 Promise . options对象,允许为匹配操作设置选项。 可用选项包括: -
includeUncontrolled: Boolean 如果设置为true, 匹配操作将返回与当前服务工作者共享相同源的所有服务工作者客户端。 否则,它仅返回由当前服务工作者控制的服务工作者客户端。 默认值为false. -
type: 设置想要匹配的 clients 类型. 可用值包括 window, worker, sharedworker, 和 all. 默认是 all. -
openWindow(url)在新窗口中打开之地你个 url,实际会给当前 service worker 添加一个新的 Client,以 Promise 方式返回。 -
claim()允许一个激活的 service worker 将自己设置为其 scope 内所有 clients 的 controller。可用于不希望等页面重新加载而让 Service Worker 开始管理页面。
一致性
Service Worker 的最终用途是:让网页能够模拟原生应用,像原生应用一样,service worker 必须支持版本控制(versioning)
Service Worker 版本控制,可以确保任何时候两个玩个的操作都有一致性。该一致性可表现为以下两种形式
-
代码一致性
-
数据一致性
为确保一致性,Servcie Worker 声明周期会尽量避免出现有损一致性的现象。比如下面这些可能
-
Service Worker 提早失败,在 register Service Worker 时,任何预料之内的问题都可能阻止 Servcie Worker 成功安装。
-
Service Worker 激进更新,浏览器再次加载 service worker 脚本时,服务脚本或通过 importScripts() 加载的依赖中哪怕有一个字节的差异,也会启动安装新版本的 service worker
-
未激活的 Service Worker 消极活动,当页面上第一次调用 register() 时,service worker 会被安装,但不会被激活,且在导航事件发生前不会控制页面。可以认为当前页面已经加载了资源,因此 Service Worker 不应该被激活,否则就会加载不一样的资源。
-
活动的 Service Worker 粘连,只要有一个客户端关联到活动的服务工作者线程,浏览器就会在该源的所有页面使用它,浏览器在活动实例关联的客户端为 0 之前不会切换到新 service worker.
生命周期
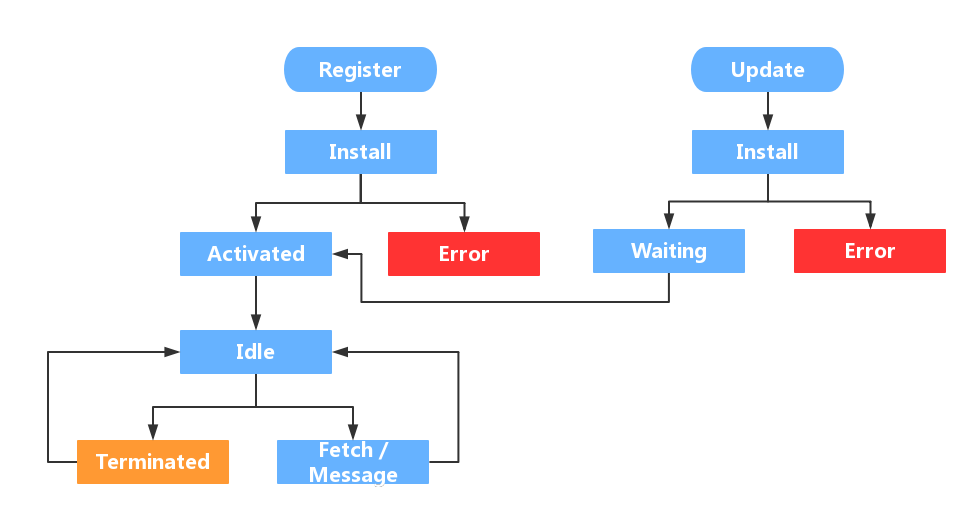
Service Worker 有 6 种可能存在的状态:
navigator.serviceWorker.register('./serviceWorker.js')
.then((registration) => {
// 首次加载时
registration.installing.onstatechange = ({ target: { state }}) => {
console.log('state changed to', state)
}
// state changed to installed
// state changed to activating
// state changed to activated
})
-
已解析(parsed)状态,register() 第一次调用时会创建 service worker 实例,刚创建实例时,会进入 parsed 状态,该状态并没有事件,也没有与之相关的 ServiceWorker.state。浏览器获取脚本文件,然后执行一些初始化任务,Service Worker 生命周期就开始了。所有下面的任务 OK 后,会返回一个 resolve 为 ServiceWorkerRegistration 对象的 Promise,创建的 Service Worker 进入安装中状态。
-
确保 service worker 脚本来自相同的源
-
确保在安全的上下文 https 中注册 service worker
-
确保服务脚可以被浏览器 JS 解释器成功解析而不会抛出任何错误
-
捕获服务脚本的快照,下一次加载该脚本时进行比对,并据此决定是否更新该 service worker
-
-
安装中(installing)状态,该状态时 ServiceWorkerRegistration.installing 值为 ServiceWorker 对象。在 serviceWorker.js 中 self.oninstall 可以指定该状态时的事件处理程序。该事件 event 为 InstallEvent 对象,继承自 ExtendableEvnet 对象,该对象暴露了一个 API waitUitl() 允许将状态延迟到这个 Promise resolve。一般在这个状态会通过 Cache.addAll() 缓存一组资源后再过渡到 已安装 状态。
navigator.serviceWorker.register('./serviceWorker.js')
.then((registration) => {
if (registration.installing) {
console.log('service worker 处于 installing 状态')
}
registration.onupdatefound = () => {
console.log('有新版本,service worker 处于 installing 状态')
}
})
// serviceWorker.js
console.log('start serviceWorker.js')
self.oninstall = installEvent => {
console.log(installEvent, installEvent.waitUntil)
// 状态停留在 安装中,5s 后状态变为 已安装 状态
installEvent.waitUntil((async () => {
await new Promise(r => setTimeout(r, 5000))
// 5s 后执行,然后状态变为
console.log('5s 后')
})())
}
- 已安装(installed) 状态,已安装状态也称为 等待中(waiting) 状态,可以检查 ServiceWorkerRegistration.waiting 是否设置为 ServiceWorker 实例来确定。如果没有活动的 ServiceWorker 则新安装的 ServiceWorker 会跳过这个状态,直接进入 激活中。 可以通过 self.skipWaiting() 强制进入激活中状态。
navigator.serviceWorker.register('./serviceWorker.js')
.then((registration) => {
if (registration.waiting) {
console.log('service worker 处于 installed/waiting 状态')
}
})
-
激活中(activating)状态,表示 Service Worker 已经被浏览器选中,即将变成可以控制页面的 Service Worker。如果浏览器中没有活动的 Service Worker 则新的 Service Worker 自动到达激活中状态。如果有一个活动 ServiceWorker,则这个作为替代的 ServiceWorker 可以通过如下方式进入激活中状态:
-
原有 ServiceWorker 空值的客户数变为 0,意味着标签页都关闭了。在下一个导航时间时,新 Service Worker 会达到激活中状态。
-
调用 self.skipWaiting(),这样可以立即生效,而不必等下一次导航事件
-
// 激活中的状态不能像已激活状态中那样,执行发送请求或推送事件的操作
// 激活中或已激活状态 SercieWorkerRegistration.active 会被设置为 ServiceWorker 对象
// 激活中状态会触发 self.onactivate 事件
// activateEvent 也继承自 ExtendableEvent,因此也支持 waitUntil 方法
// 可以延迟过渡到已激活状态
const CACHE_KEY = 'v3'
self.onactivate = activateEvent => {
console.log('Servcie worker 处于激活中状态')
// 可以将老版本的缓存清除
caches.keys()
.then(keys => keys.filter(key => key != CACHE_KEY))
.then(oldKeys => oldKeys.forEach(oldKey => caches.delete(oldKey)))
}
- 已激活(activated)状态,表示 ServiceWorker 正在控制一个或多个客户端。在这个状态中,Service Worker 可以捕获其作用域内的 fetch() 事件,通知和推送事件。
navigator.serviceWorker.register('./serviceWorker.js')
.then((registration) => {
if (registration.active) {
console.log('service worker 处于 activating/activated 状态')
console.log(navigator.serviceWorker.controller) // ServiceWorker
}
})
navigator.serviceWorker.oncontrollerchange = () => {
// 未触发
console.log('一个新的 service worker 控制了该客户端')
}
navigator.serviceWorker.ready.then(() => {
console.log('ready:service worker 进入已激活状态')
})
-
已失效(redundant)状态,在 Chrome DevTools 中,Application - Service Workers 中点击 Unregister 可以让一个 service worker 失效,失效后的 service worker 不会再有事件发给他。
-
更新 Service Worker,因为版本控制的概率存在与整个生命周期,如果 service worker 版本变化,会更新检查,如果有更新,会初始化一个新的 service worker。
浏览器针对 Service Workers 有如下机制:
1、每次打开接入了 Service Workers 的网页时,浏览器都会去重新下载 Service Workers 脚本文件(所以要注意该脚本文件不能太大),如果发现和当前已经注册过的文件存在字节差异,就将其视为“新服务工作线程”。
2、新 Service Workers 线程将会启动,且将会触发其 install 事件。
3、当网站上当前打开的页面关闭时,旧 Service Workers 线程将会被终止,新 Service Workers 线程将会取得控制权。
4、新 Service Workers 线程取得控制权后,将会触发其 activate 事件。
新 Service Workers 线程中的 activate 事件就是最佳的清理旧缓存的时间点,代码如下:
// 当前缓存白名单,在新脚本的 install 事件里将使用白名单里的 key
var cacheWhitelist = [cacheKey];
self.addEventListener('activate', function(event) {
event.waitUntil(
caches.keys().then(function(cacheNames) {
return Promise.all(
cacheNames.map(function(cacheName) {
// 不在白名单的缓存全部清理掉
if (cacheWhitelist.indexOf(cacheName) === -1) {
// 删除缓存
return caches.delete(cacheName);
}
})
);
})
);
});
IoC 与 Service Worker 持久化
专有 Worker 和 共享 Worker 是有状态的,但 ServiceWorker 是无状态的,它遵循控制反转(IoC, Inversion of Control)模式并且是事件驱动的。
Service Worker 不应该依赖其全局状态,绝大多数代码应该在事件处理程序中定义。
通过 updateViaCache 管理服务文件缓存
在 HTTP 缓存中,服务端有两种方式来控制前端使用缓存
-
强缓存,通过响应头设置缓存时间 Expries(http 1.0)/Cache-Control (http 1.1),前端状态码 200
-
弱缓存,也叫协商缓存,服务器再验证的方式,通过设置 Last-Modified(最后一次修改时间) 或 ETag(资源标识) 响应头,再次接收到请求时,将对应的 If-Modified-Since/if-None-Macth 进行比对,如果没变化就返回状态码 304,Not Modified
前端有两种方式控制不使用服务器 HTTP 缓存
-
设置请求头 Cache-Control’: ‘no-cache’
-
设置请求头 Pragma: ‘no-cache’
在注册/创建 Service Worker 时,可以通过 options 中的 updateViaCache 字段在前端控制 service worker 脚本缓存
navigator.serviceWorker.register('./serviceWorker.js', {
updateViaCache: 'none'
})
updateViaCache 可以是如下三个值
-
imports默认值,顶级 service worker 脚本永远不会缓存,但通过 importScripts() 导入的文件会遵循普通 HTTP 缓存规则 -
allservice worker 脚本没有任何特殊待遇,所有文件都会遵循 HTTP 缓存规则 -
noneservice worker 脚本和 importScripts() 导入的文件都不会被缓存
强制性操作
Service Worker 中有三种强制操作
-
self.skipWaiting()让 service worker 进入激活状态,一般在 self.oninstall 中缓存资源后再调用该方法 -
clients.claim()强制 service worker 接管客户端,会在每个客户端触发 controllerchange 事件。一般在 self.onactive 激活中状态时调用,会变为已激活 -
registration.update()强制重新获取 service worker 脚本
Service Worker 消息
在客户端,创建 service worker 后,会返回一个 ServiceWorkerRegistration 对象,在服务已激活后,使用该 active 属性可以获取 ServiceWorker 对象,可以使用 ServiceWorker 对象的 postMessage() 给 service worker 发送消息。service worker 接收到消息后,通过消息中的 source 可以拿到 WindowClient 对象,通过该对象的 postMessage() 可以给客户端发送信息
main.js
navigator.serviceWorker.onmessage = (res) => {
// res - MessageEvent
console.log(res, res.data)
console.log('接收到来自 service worker 的消息:', res.data)
// 接收到来自 service worker 的消息: msg from service
}
navigator.serviceWorker.register('./serviceWorker.js')
.then((registration) => {
if (registration.active) {
// registration.active - ServiceWorker {}
registration.active.postMessage('msg from client')
}
})
serviceWorker.js
self.onmessage = (res) => {
// res - ExtendableMessageEvent {}
// res.source - WindowClient => 继承自 Client,所以有 postMessage()
console.log(res, res.data, res.source)
console.log('servcie 接收到消息:', res.data)
// servcie 接收到消息: msg from client
res.source.postMessage('msg from service')
}
在 main.js 中,还可以通过 navigator.serviceWorker.controller 来获取 ServiceWorker 对象
// main.js
navigator.serviceWorker.register('./serviceWorker.js')
.then((registration) => {
if (navigator.serviceWorker.controller) {
// ServiceWorker {}
navigator.serviceWorker.controller.postMessage('msg from client')
}
})
上面的例子中是客户端先发送消息,service worker 再接通过消息中的 source 来向客户端发消息。如果 service worker 首先发消息,可以通过下面的方法
// servcieWorker.js
self.onmessage = (res) => {
console.log('servcie 接收到消息:', res.data)
}
// 只触发一次,调试时需要在控制台,将该 service worker Unregister 刷新测试
self.onactivate = () => {
self.clients.matchAll({ includeUncontrolled: true })
.then((clientMatchs) => clientMatchs[0].postMessage('foo'))
}
main.js
navigator.serviceWorker.onmessage = (res) => {
console.log('接收到来自 service worker 的消息:', res.data)
// 接收到来自 service worker 的消息: foo
}
navigator.serviceWorker.register('./serviceWorker.js')
.then((registration) => {
})
除了通过上面的方法发送消息外,也可以通过 MessageChannel 和 BroadcastChannel 来发送消息
拦截 fetch 事件
Service Worker 最重要的一个特性就是拦截网络请求,service worker 作用域中的网络请求会注册为 fetch 事件。它的拦截不限于 fetch() 方法发送的请求,也拦截 js、css、image、html文档 等资源发送的请求。
客户端发送请求,在 service worker 中的 self 上会触发 fetch 事件,该事件的 event 是 FetchEvent 类型,继承自 ExtendableEvent。支持如下属性、方法
-
request拦截请求的 Request 对象 -
respondWith()拦截请求后,决定怎么响应数据给前端。
respondWidth() 一般有如下几种请求
- 从网络返回 仅转发 fetch 事件,适用于 PUT、POST 请求等,如果 respondWith() 没有被调用,浏览器也会通过网络发送请求
self.onfetch = fetchEvent => {
fetchEvent.respondWith(fetch(fetchEvent.request))
}
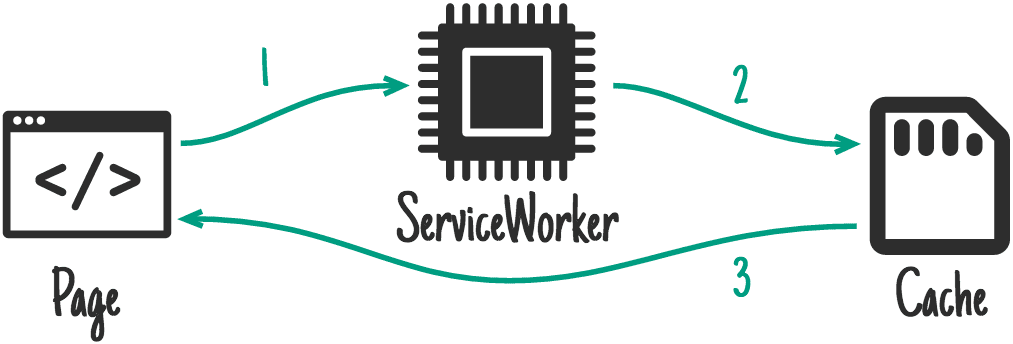
- 从缓存返回,对于肯定有缓存的资源,可以采用该策略,比如安装阶段缓存的资源
self.onfetch = fetchEvent => {
fetchEvent.respondWith(caches.match(fetchEvent.request))
}
- 从网络返回,缓存作为后备,将网络获取新数据作为首选,如果需要展示最新数据,但在离线时仍要展示一些信息时,就可以采用该策略
self.onfetch = fetchEvent => {
fetchEvent.respondWith(
fetch(fetchEvent.request)
.catch(() => caches.match(fetchEvent.request))
)
}
- 优先查缓存,网络作为后备,这个策略优先考虑响应速度,但仍然会在没有缓存的情况下发送网络请求,这是绝大多数 PWA (Progress Web Application) 采取的首选策略。
self.onfetch = fetchEvent => {
fetchEvent.respondWith(
caches.match(fetchEvent.request)
.then(response => response || fetch(fetchEvent.request))
)
}
- 通用后备 考虑到缓存和网络都不可用的气你,servcie worker 可以在 安装时缓存后备资源,然后在缓存和网络都失败时返回他们
self.onfetch = fetchEvent => {
fetchEvent.respondWith(
caches.match(fetchEvent.request)
.then(response => response || fetch(fetchEvent.request))
.catch(() => catchs.match('/fallback.html'))
)
}
推送通知
推送通知一般需要支持服务器推送,在常规网页中是不可能的。service worker 可以实现该行为
-
service worker 可以显示通知
-
service worker 可以处理这些通知的交互
-
service worker 能够订阅服务器发送的推送通知
-
service worker 能够处理推送消息,即使应用没有在前台运行或者根本没打开
1. 显示通知
在 service worker 中可以使用 ServcieWorkerRegistration 对象支持 showNotifications() 方法来显示通知,可以配置 title 和 options 配置
navigator.serviceWorker.register('./serviceWorker.js')
.then((registration) => {
Notification.requestPermission()
.then(status => {
if (status === 'granted') {
registration.showNotification('title')
}
})
})
在 serviceWorker.js 中使用 self.registration 也可以显示通知
// 注意 onactivate 默认只触发一次
self.onactivate = () => self.registration.showNotification('bar')
2. 处理通知事件
ServiceWorkerRegistration 对象创建的通知会向 service worker 发送 notificationclick 和 notificationclose 事件
self.onnotificationclick = (event) => {
// NotificationEvent {}, Notification {}
console.log('notification click', event, event.notification)
// 点击通知后,在新的 tab 打开网页
clients.openWindow('http://www.zuo11.com')
}
self.onnotificationclose = (event) => {
console.log('notification close', event, event.notification)
}
3.订阅推送事件
使用 registration.pushManager.subscribe() 可以对服务器推送消息发起订阅。注意这个过程中不会发送请求到我们的应用服务器。该函数包含两个参数:
-
userVisibleOnly通常被设置为 true,用来表示后续信息是否展示给用户。 -
applicationServerKey秘钥,类型为 Uint8Array,用于加密服务端的推送信息,防止中间人攻击,会话被攻击者篡改。测试时,可以通过 web-push-codelab (opens new window)网站获取秘钥并验证全流程,将该网站随机生产的 Application Server Keys 中的 Public Key 使用 urlBase64ToUint8Array() 转换后即可当做 applicationServerKey 使用
urlBase64ToUint8Array() 函数代码
function urlBase64ToUint8Array(base64String) {
const padding = '='.repeat((4 - base64String.length % 4) % 4);
const base64 = (base64String + padding)
.replace(/-/g, '+')
.replace(/_/g, '/');
const rawData = window.atob(base64);
const outputArray = new Uint8Array(rawData.length);
for (let i = 0; i < rawData.length; ++i) {
outputArray[i] = rawData.charCodeAt(i);
}
return outputArray;
}
该函数返回一个 Promise,resolve 为 PushSubscription 对象,该对象包含服务器推送时必要的信息 不同的浏览器,对应的 endpoint 不一样。Chrome 和 Firefox 会不一样,如下图

WARNING 如果一直卡在 registration.pushManager.subscribe(),不向下执行,状态一直时 pending,可能是因为 Chrome 浏览器关于推送消息的功能,被墙了,需要翻墙才能正常返回
订阅代码如下:
// main.js
(async () => {
try {
const registration = await navigator.serviceWorker.register("sw.js");
const status = await Notification.requestPermission()
if (status === 'granted') {
const vapidPublicKey = 'BF9WWlvQiKSOwziO4gVeBdMeuhDW2HU2aCWAmaSLgXqGCGZK3ho15l30oQ6pdavh8acsc1kiXJNK-DtaqbHaZCQ';
const convertedVapidKey = urlBase64ToUint8Array(vapidPublicKey);
// 防止 DOMException: Failed to execute 'subscribe' on 'PushManager': Subscription failed - no active Service Worker
if (!registration.active) {
// 等待变为激活状态
await new Promise(r => setTimeout(r, 500))
}
const pushSubscription = await registration.pushManager.subscribe({
applicationServerKey: convertedVapidKey, // 来自服务器的公钥
userVisibleOnly: true
});
console.log(pushSubscription) // PushSubscription
console.log(JSON.stringify(pushSubscription)) // 这个消息可用于服务端发起推送
// {
// "endpoint": "https://fcm.googleapis.com/fcm/send/ecbqKLEnhB8:APA91bGvTW0x3k57bT9gDMLPPVkwLotGJyqJ1kk8yvNHyNAJ8Z0F6O74BuA8QxVNPIsgf1gWlGrUe0bYSs4L6fo-Fl18WkwGyHc3FEo2YvSUXBr5AA7KenaZBkL1D87WuAE7ERl-JCM4",
// "expirationTime": null,
// "keys": {
// "p256dh": "BIpKDNOPNQcBnfJVmdtZM2eJ0qS-FjicsiZK8jyUU07lGREwM_VZe2ulIWdrdlNlg7RFnHge8vJSe5y6TagW3Oc",
// "auth": "IlAite8VLBLWV5ubUXg91w"
// }
// }
}
} catch (err) {
console.log(err);
}
})()
上面的例子中,成功拿到 JSON.stringify(pushSubscription) 后,就可以在服务端使用该信息进行推送通知了。
4.处理服务端推送消息
// sw.js
// 当接收到服务端推送的消息时
self.onpush = pushEvent => {
// 服务器推送的消息文本
console.log(pushEvent.data.text())
// 保持 service worker 活动到显示通知 resolve
pushEvent.waitUntil(
// 将服务器推送的消息作为通知显示
self.registration.showNotification(pushEvent.data.text())
)
}
// 点击消息时
self.onnotificationclick = (event) => {
// NotificationEvent {}, Notification {}
console.log('notification click', event, event.notification)
// 点击通知后,在新的 tab 打开网页
clients.openWindow('http://www.zuo11.com')
}
现在来测试下,上面的例子中,我们使用 web-push-codelab 网站获取了 applicationServerKey 秘钥,我们同样可以在该网站发起服务端消息推送。将之前我们获取的 JSON.stringify(pushSubscription) 字符串拷贝到该网站的 Subscription to Send To 那一栏,然后在 Text to Send 中填写需要推送的消息。再点击 Send Push Message 按钮即可进行服务器推送。
这样就可以看到通知了。上面只是为了方便测试,如果需要使用程序化的方式来进行服务端推送,那就需要把 JSON.stringify(pushSubscription) 字符串传到后端,以 Node.js 为例,后端可以使用 web-push 来进行服务端推送。
离线存储方案对比
前端主流离线存储方案对比如下所示:
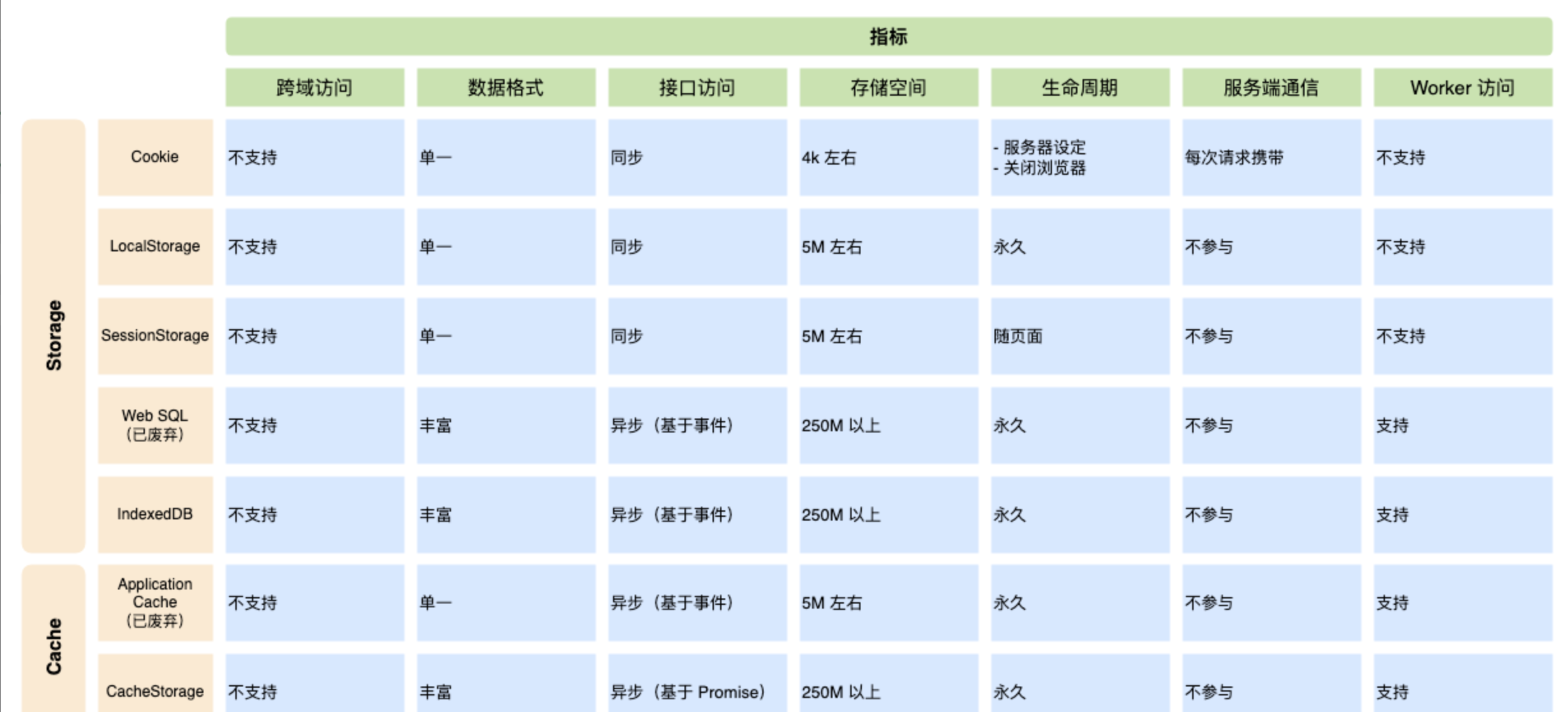
Cache API 是为资源请求与响应的存储量身定做的,它采用了键值对的数据模型存储格式,以请求对象为键、响应对象为值,正好对应了发起网络资源请求时请求与响应一一对应的关系。因此 Cache API 适用于请求响应的本地存储。
IndexedDB 则是一种非关系型(NoSQL)数据库,它的存储对象主要是数据,比如数字、字符串、Plain Objects、Array 等,以及少量特殊对象比如 Date、RegExp、Map、Set 等等,对于 Request、Response 这些是无法直接被 IndexedDB 存储的。
可以看到,Cache API 和 IndexedDB 在功能上是互补的。在设计本地资源缓存方案时通常以 Cache API 为主,但在一些复杂的场景下,Cache API 这种请求与响应一一对应的形式存在着局限性,因此需要结合上功能上更为灵活的 IndexedDB,通过 IndexedDB 存取一些关键的数据信息,辅助 Cache API 进行资源管理。
通过上述对比,我们可以使用 IndexedDB 及 CacheStorage 来为 Service Worker 的离线存储提供底层服务,根据社区的经验,它们各自的适用场景为:
对于网址可寻址的(比如脚本、样式、图片、HTML 等)资源使用 CacheStorage 其他资源则使用 IndexedDB
有了 HTTP 缓存为什么还需要 Service Worker
Service worker除了针对PWA(推送和消息)以外,对普通web来说,在缓存方面,能比http缓存带来一些额外的好处。
可以理解为,SW就是浏览器把缓存管理开放一层接口给开发者。
优势如下:
1、改写默认行为。
例如,浏览器默认在刷新时,会对所有资源都重新发起请求,即使缓存还是有效期内,而使用了SW,就可以改写这个行为,直接返回缓存。
2、缓存和更新并存。
要让网页离线使用,就需要整站使用长缓存,包括HTML。而HTML使用了长缓存,就无法及时更新(浏览器没有开放接口直接删除某个html缓存)。而使用SW就可以,每次先使用缓存部分,然后再发起SW js的请求,这个请求我们可以实施变更,修改HTML版本,重新缓存一份。那么用户下次打开就可以看到新版本了。
3、无侵入式。
无侵入式版本控制。最优的版本控制,一般是HTML中记录所有js css的文件名(HASH),然后按需发起请求。每个资源都长缓存。而这个过程,就需要改变了项目结构,至少多一个js或者一段js控制版本号,发起请求时还需要url中注入冬天的文件名。使用了SW,就可以把这部分非业务逻辑整合到sw js中。
无侵入式请求统计。例如缓存比例统计、图片404统计。
4、额外缓存。
HTTP缓存空间有限,容易被冲掉。虽然部分浏览器实现SW的存储也有淘汰机制,但多一层缓存,命中的概率就要更高了。
5、离线处理。
当监测到离线,而且又没有缓存某个图片时,可以做特殊处理,返回离线的提示。又或者做一个纯前端的404/断网页面。类似Chrome的小恐龙页面。
6、预加载资源。
这个类似prefetch标签。
7、前置处理。
例如校验html/JS是否被运营商劫持?js文件到了UI进程执行后,就无法删除恶意代码,而在SW中,我们可以当作文本一样,轻松解决。当然,在HTTPS环境下出现劫持的概率是极低的。
Service Worker 实战
Service Worker本质上也是浏览器缓存资源用的,只不过他不仅仅是cache,也是通过worker的方式来进一步优化。
他基于h5的web worker,所以绝对不会阻碍当前js线程的执行,sw最重要的工作原理就是
1、后台线程:独立于当前网页线程;
2、网络代理:在网页发起请求时代理,来缓存文件;
功能和特性
service worker 的功能和特性可以总结为以下几点:
1、service worker 是一个独立 worker 线程,独立于当前网页进程,有自己独立的 worker context
2、service worker 的线程能力基于 webworker 而生,通过 postMessage 和 onMessage 进行线程之间的通信;缓存机制是依赖 cache API 实现的。service worker = webworker + cache API
3、一旦被 install 之后,就永远存在,除非被 uninstall;需要的时候可以直接唤醒,不需要的时候自动睡眠
4、可以可编程拦截代理请求( https 请求)和缓存文件,缓存的文件直接可以被网页进程取到(包括网络离线状态)
5、离线内容开发者可控;能向客户端推送消息;不能直接操作 dom
6、必须在 https 环境下才能工作,当然 localhost 或者 127.0.0.1 也是 ok 的
7、service worker 是异步的,内部通过 Promise 实现, localStorage 是同步的,因此 service worker 内不许用使用 loaclStorage
8、依赖 HTML5 fetch API 和 Promise
兼容性和成熟度

如图所示,除了 IE 和 Opera Mini 不支持,大部分现代浏览器都没有问题,兼容度超过 96%
判断一个技术是否值得尝试,肯定要考虑下它的成熟程度,否则过一段时间又和应用缓存一样被规范抛弃就尴尬了。
所以这里我列举了几个使用Service Worker的页面:
-
语雀
-
CSDN
-
GitHub
-
微博
-
谷歌地图
-
爱奇艺
-
网易新闻
如果想看看还有哪些你浏览过的网站启动了该功能,可以通过chrome访问 chrome://serviceworker-internals/?devtools
所以说还是可以尝试下的。
调试方法
一个网站是否启用Service Worker,可以通过开发者工具中的Application来查看:
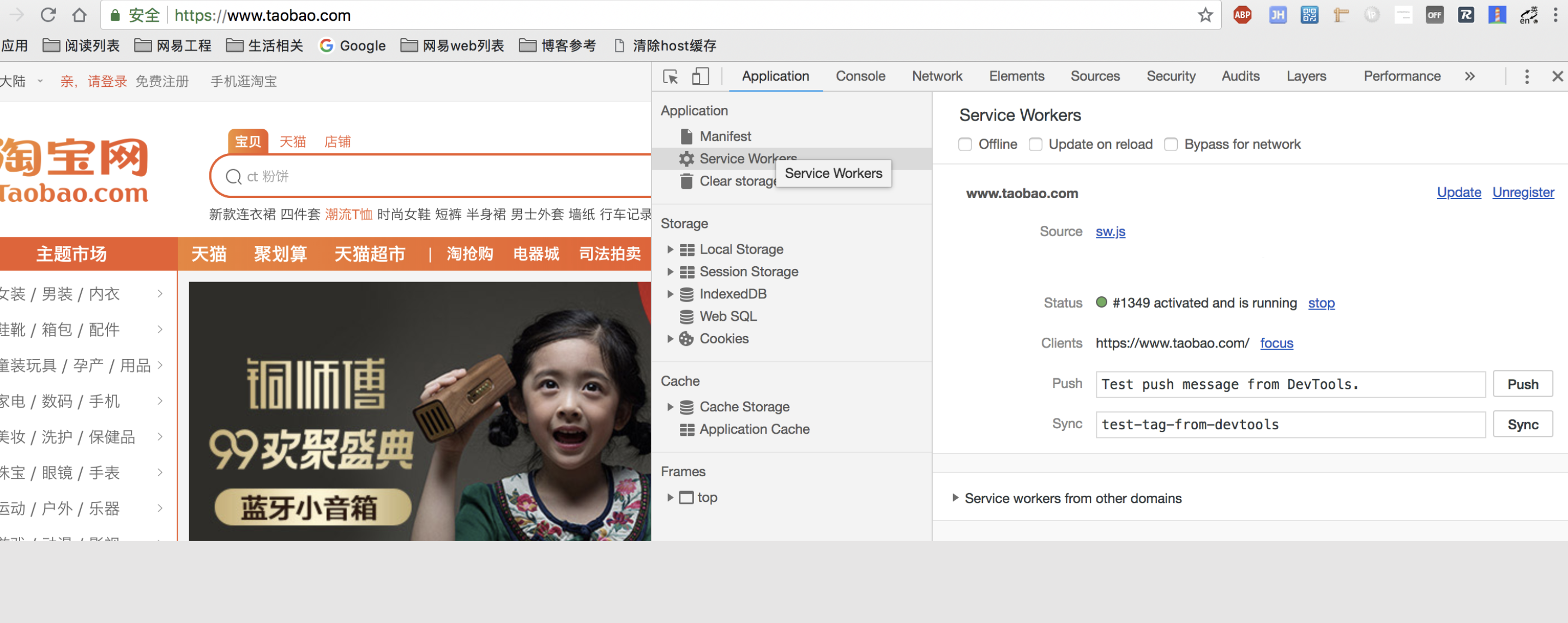
被Service Worker缓存的文件,可以在Network中看到Size项为 from ServiceWorker:

也可以在Application的Cache Storage中查看缓存的具体内容:

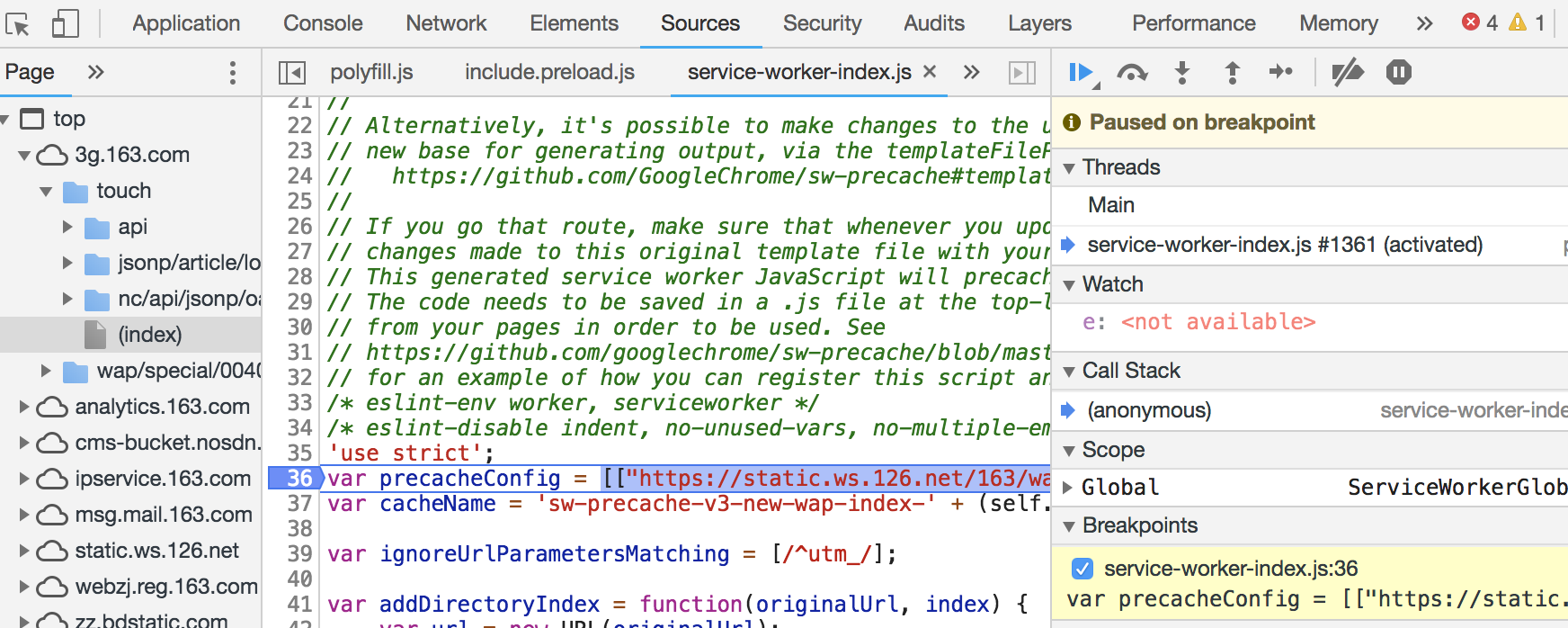
如果是具体的断点调试,需要使用对应的线程,不再是main线程了,这也是webworker的通用调试方法:
生命周期
注册
要使用Service worker,首先需要注册一个sw,通知浏览器为该页面分配一块内存,然后sw就会进入安装阶段。
一个简单的注册方式:
(function() {
if('serviceWorker' in navigator) {
navigator.serviceWorker.register('./sw.js');
}
})()
当然也可以考虑全面点,参考网易新闻的注册方式:
"serviceWorker" in navigator && window.addEventListener("load",
function() {
var e = location.pathname.match(/\/news\/[a-z]{1,}\//)[0] + "article-sw.js?v=08494f887a520e6455fa";
navigator.serviceWorker.register(e).then(function(n) {
n.onupdatefound = function() {
var e = n.installing;
e.onstatechange = function() {
switch (e.state) {
case "installed":
navigator.serviceWorker.controller ? console.log("New or updated content is available.") : console.log("Content is now available offline!");
break;
case "redundant":
console.error("The installing service worker became redundant.")
}
}
}
}).
catch(function(e) {
console.error("Error during service worker registration:", e)
})
})
前面提到过,由于sw会监听和代理所有的请求,所以sw的作用域就显得额外的重要了,比如说我们只想监听我们专题页的所有请求,就在注册时指定路径:
navigator.serviceWorker.register('/topics/sw.js');
这样就只会对topics/下面的路径进行优化。
installing
我们注册后,浏览器就会开始安装sw,可以通过事件监听:
//service worker安装成功后开始缓存所需的资源
var CACHE_PREFIX = 'cms-sw-cache';
var CACHE_VERSION = '0.0.20';
var CACHE_NAME = CACHE_PREFIX+'-'+CACHE_VERSION;
var allAssets = [
'./main.css'
];
self.addEventListener('install', function(event) {
//调试时跳过等待过程
self.skipWaiting();
// Perform install steps
//首先 event.waitUntil 你可以理解为 new Promise,
//它接受的实际参数只能是一个 promise,因为,caches 和 cache.addAll 返回的都是 Promise,
//这里就是一个串行的异步加载,当所有加载都成功时,那么 SW 就可以下一步。
//另外,event.waitUntil 还有另外一个重要好处,它可以用来延长一个事件作用的时间,
//这里特别针对于我们 SW 来说,比如我们使用 caches.open 是用来打开指定的缓存,但开启的时候,
//并不是一下就能调用成功,也有可能有一定延迟,由于系统会随时睡眠 SW,所以,为了防止执行中断,
//就需要使用 event.waitUntil 进行捕获。另外,event.waitUntil 会监听所有的异步 promise
//如果其中一个 promise 是 reject 状态,那么该次 event 是失败的。这就导致,我们的 SW 开启失败。
event.waitUntil(
caches.open(CACHE_NAME)
.then(function(cache) {
console.log('[SW]: Opened cache');
return cache.addAll(allAssets);
})
);
});
安装时,sw就开始缓存文件了,会检查所有文件的缓存状态,如果都已经缓存了,则安装成功,进入下一阶段。
activated
如果是第一次加载sw,在安装后,会直接进入activated阶段,而如果sw进行更新,情况就会显得复杂一些。流程如下:
首先老的sw为A,新的sw版本为B。
B进入install阶段,而A还处于工作状态,所以B进入waiting阶段。只有等到A被terminated后,B才能正常替换A的工作。
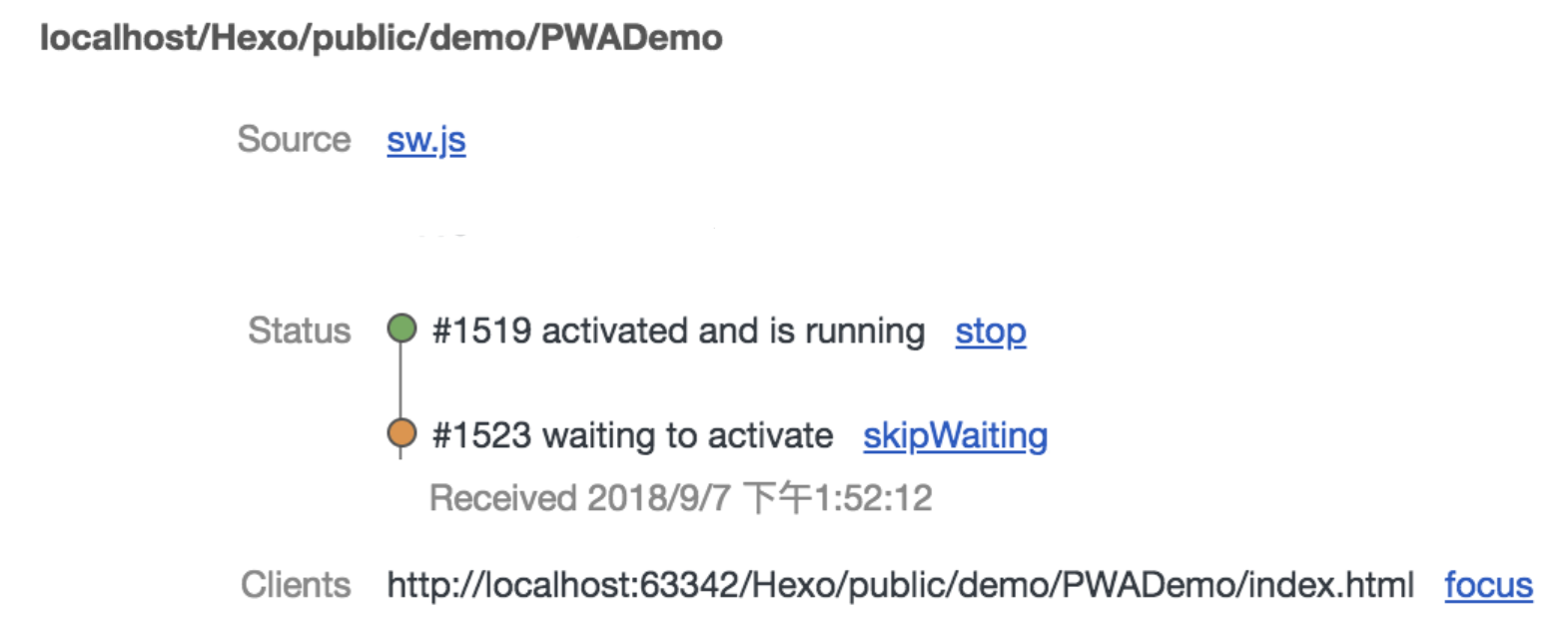
这个terminated的时机有如下几种方式:
1、关闭浏览器一段时间;
2、手动清除serviceworker;
3、在sw安装时直接跳过waiting阶段
//service worker安装成功后开始缓存所需的资源
self.addEventListener('install', function(event) {
//跳过等待过程
self.skipWaiting();
});
然后就进入了activated阶段,激活sw工作。
activated阶段可以做很多有意义的事情,比如更新存储在cache中的key和value:
var CACHE_PREFIX = 'cms-sw-cache';
var CACHE_VERSION = '0.0.20';
/**
* 找出对应的其他key并进行删除操作
* @returns {*}
*/
function deleteOldCaches() {
return caches.keys().then(function (keys) {
var all = keys.map(function (key) {
if (key.indexOf(CACHE_PREFIX) !== -1 && key.indexOf(CACHE_VERSION) === -1){
console.log('[SW]: Delete cache:' + key);
return caches.delete(key);
}
});
return Promise.all(all);
});
}
//sw激活阶段,说明上一sw已失效
self.addEventListener('activate', function(event) {
event.waitUntil(
// 遍历 caches 里所有缓存的 keys 值
caches.keys().then(deleteOldCaches)
);
});
idle
这个空闲状态一般是不可见的,这种一般说明sw的事情都处理完毕了,然后处于闲置状态了。
浏览器会周期性的轮询,去释放处于idle的sw占用的资源。
fetch
该阶段是sw最为关键的一个阶段,用于拦截代理所有指定的请求,并进行对应的操作。
所有的缓存部分,都是在该阶段,这里举一个简单的例子:
//监听浏览器的所有fetch请求,对已经缓存的资源使用本地缓存回复
self.addEventListener('fetch', function(event) {
event.respondWith(
caches.match(event.request)
.then(function(response) {
//该fetch请求已经缓存
if (response) {
return response;
}
return fetch(event.request);
}
)
);
});
install vs fetch
-
install 的优点是第二次访问即可离线,缺点是需要将需要缓存的资源 URL 在编译时插入到脚本中,增加代码量和降低可维护性;
-
fetch 的优点是无需更改编译过程,也不会产生额外的流量,缺点是需要多一次访问才能离线可用。
生命周期大概讲清楚了,我们就以一个具体的例子来说明下原生的serviceworker是如何在生产环境中使用的吧。
工作流程
service worker 基于注册、安装、激活等步骤在浏览器 js 主线程中独立分担缓存任务。
-
首先在页面的 javaScript 主线程中使用 navigator.serviceWorker.register() 来注册 servcie worker。
-
如果注册成功,service worker 在 ServiceWorkerGlobalScope 环境中运行; 这是一个特殊的 worker context,与主脚本的运行线程相独立,同时也没有访问 DOM 的能力。
-
后台开始安装步骤,通常在安装的过程中需要缓存一些静态资源。install 事件回调中有两个方法:
-
event.waitUntil():传入一个 Promise 为参数,等到该 Promise 为 resolve 状态为止。
-
self.skipWaiting():self 是当前 context 的 global 变量,执行该方法表示强制当前处在 waiting 状态的 Service Worker 进入 activate 状态。
-
-
当 service worker 安装完成后,会接收到一个激活事件(activate event)。激活事件的处理函数中,主要操作是清理旧版本的 service worker 脚本中使用资源。activate 回调中有两个方法:
-
event.waitUntil():传入一个 Promise 为参数,等到该 Promise 为 resolve 状态为止。
-
self.clients.claim():在 activate 事件回调中执行该方法表示取得页面的控制权, 这样之后打开页面都会使用版本更新的缓存。旧的 Service Worker 脚本不再控制着页面,之后会被停止。
-
-
激活成功后 service worker 可以控制页面了,刷新页面可以查看 service worker 的工作成果。
service worker 更新
/sw.js 控制着页面资源和请求的缓存,如果 /sw.js 需要更新应该怎么办呢?
-
service worker 控制着整个 App 的离线缓存。 为了避免 service worker 缓存自己导致死锁无法升级,通常将 sw.js 本身的缓存直接交给 HTTP 服务器缓存。
-
更新 sw.js 文件,当浏览器获取到了新的文件,发现 sw.js 文件发生更新,就会安装新的文件并触发 install 事件。
-
但是此时已经处于激活状态的旧的 service worker 还在运行,新的 service worker 完成安装后会进入 waiting 状态,直到所有已打开的页面都关闭。
-
新服务工作线程取得控制权后,将会触发其 activate 事件。
// 安装阶段跳过等待,直接进入 activate
self.addEventListener('install', function (event) {
event.waitUntil(self.skipWaiting());
});
self.addEventListener('activate', function (evnet) {
event.waitUntil(
Promise.all([
// 更新客户端
self.clients.claim(),
// 清理旧版本
caches.keys().then(function (cacheList) {
return Promise.all(
cacheList.map(function (cacheName) {
if (cacheName !== 'my-test-cache-v1') {
return caches.delete(cacheName);
}
})
);
})
])
);
});
注意:如果 sw.js 文件被浏览器缓存,则可能导致更新得不到响应。如遇到该问题,可尝试这么做:在 webserver 上添加对该文件的过滤规则,不缓存或设置较短的有效期。
手动更新 /sw.js
也可以借助 Registration.update() 手动更新
var version = '1.0.1';
navigator.serviceWorker.register('/sw.js').then(function (reg) {
if (localStorage.getItem('sw_version') !== version) {
reg.update().then(function () {
localStorage.setItem('sw_version', version)
});
}
});
自动更新
除了浏览器触发更新之外,service worker 还有一个特殊的缓存策略: 如果该文件已 24 小时没有更新,当 Update 触发时会强制更新。这意味着最坏情况下 service worker 会每天更新一次。
调试时更新
可以单独设置调试时 service worker 安装后立即激活:
self.addEventListener('install', function() {
self.skipWaiting();
});
举个例子
我们可以以网易新闻的wap页为例,其针对不怎么变化的静态资源开启了sw缓存,具体的sw.js逻辑和解读如下:
'use strict';
//需要缓存的资源列表
var precacheConfig = [
["https://static.ws.126.net/163/wap/f2e/milk_index/bg_img_sm_minfy.png",
"c4f55f5a9784ed2093009dadf1e954f9"],
["https://static.ws.126.net/163/wap/f2e/milk_index/change.png",
"9af1b102ef784b8ff08567ba25f31d95"],
["https://static.ws.126.net/163/wap/f2e/milk_index/icon-download.png",
"1c02c724381d77a1a19ca18925e9b30c"],
["https://static.ws.126.net/163/wap/f2e/milk_index/icon-login-dark.png",
"b59ba5abe97ff29855dfa4bd3a7a9f35"],
["https://static.ws.126.net/163/wap/f2e/milk_index/icon-refresh.png",
"a5b1084e41939885969a13f8dbc88abd"],
["https://static.ws.126.net/163/wap/f2e/milk_index/icon-video-play.png",
"065ff496d7d36345196d254aff027240"]
];
var cacheName = 'sw-precache-v3-new-wap-index-' + (self.registration ? self.registration.scope : '');
var ignoreUrlParametersMatching = [/^utm_/];
var addDirectoryIndex = function(originalUrl, index) {
var url = new URL(originalUrl);
if (url.pathname.slice(-1) === '/') {
url.pathname += index;
}
return url.toString();
};
var cleanResponse = function(originalResponse) {
// If this is not a redirected response, then we don't have to do anything.
if (!originalResponse.redirected) {
return Promise.resolve(originalResponse);
}
// Firefox 50 and below doesn't support the Response.body stream, so we may
// need to read the entire body to memory as a Blob.
var bodyPromise = 'body' in originalResponse ?
Promise.resolve(originalResponse.body) :
originalResponse.blob();
return bodyPromise.then(function(body) {
// new Response() is happy when passed either a stream or a Blob.
return new Response(body, {
headers: originalResponse.headers,
status: originalResponse.status,
statusText: originalResponse.statusText
});
});
};
var createCacheKey = function(originalUrl, paramName, paramValue,
dontCacheBustUrlsMatching) {
// Create a new URL object to avoid modifying originalUrl.
var url = new URL(originalUrl);
// If dontCacheBustUrlsMatching is not set, or if we don't have a match,
// then add in the extra cache-busting URL parameter.
if (!dontCacheBustUrlsMatching ||
!(url.pathname.match(dontCacheBustUrlsMatching))) {
url.search += (url.search ? '&' : '') +
encodeURIComponent(paramName) + '=' + encodeURIComponent(paramValue);
}
return url.toString();
};
var isPathWhitelisted = function(whitelist, absoluteUrlString) {
// If the whitelist is empty, then consider all URLs to be whitelisted.
if (whitelist.length === 0) {
return true;
}
// Otherwise compare each path regex to the path of the URL passed in.
var path = (new URL(absoluteUrlString)).pathname;
return whitelist.some(function(whitelistedPathRegex) {
return path.match(whitelistedPathRegex);
});
};
var stripIgnoredUrlParameters = function(originalUrl,
ignoreUrlParametersMatching) {
var url = new URL(originalUrl);
// Remove the hash; see https://github.com/GoogleChrome/sw-precache/issues/290
url.hash = '';
url.search = url.search.slice(1) // Exclude initial '?'
.split('&') // Split into an array of 'key=value' strings
.map(function(kv) {
return kv.split('='); // Split each 'key=value' string into a [key, value] array
})
.filter(function(kv) {
return ignoreUrlParametersMatching.every(function(ignoredRegex) {
return !ignoredRegex.test(kv[0]); // Return true iff the key doesn't match any of the regexes.
});
})
.map(function(kv) {
return kv.join('='); // Join each [key, value] array into a 'key=value' string
})
.join('&'); // Join the array of 'key=value' strings into a string with '&' in between each
return url.toString();
};
var hashParamName = '_sw-precache';
//定义需要缓存的url列表
var urlsToCacheKeys = new Map(
precacheConfig.map(function(item) {
var relativeUrl = item[0];
var hash = item[1];
var absoluteUrl = new URL(relativeUrl, self.location);
var cacheKey = createCacheKey(absoluteUrl, hashParamName, hash, false);
return [absoluteUrl.toString(), cacheKey];
})
);
//把cache中的url提取出来,进行去重操作
function setOfCachedUrls(cache) {
return cache.keys().then(function(requests) {
//提取url
return requests.map(function(request) {
return request.url;
});
}).then(function(urls) {
//去重
return new Set(urls);
});
}
//sw安装阶段
self.addEventListener('install', function(event) {
event.waitUntil(
//首先尝试取出存在客户端cache中的数据
caches.open(cacheName).then(function(cache) {
return setOfCachedUrls(cache).then(function(cachedUrls) {
return Promise.all(
Array.from(urlsToCacheKeys.values()).map(function(cacheKey) {
//如果需要缓存的url不在当前cache中,则添加到cache
if (!cachedUrls.has(cacheKey)) {
//设置same-origin是为了兼容旧版本safari中其默认值不为same-origin,
//只有当URL与响应脚本同源才发送 cookies、 HTTP Basic authentication 等验证信息
var request = new Request(cacheKey, {credentials: 'same-origin'});
return fetch(request).then(function(response) {
//通过fetch api请求资源
if (!response.ok) {
throw new Error('Request for ' + cacheKey + ' returned a ' +
'response with status ' + response.status);
}
return cleanResponse(response).then(function(responseToCache) {
//并设置到当前cache中
return cache.put(cacheKey, responseToCache);
});
});
}
})
);
});
}).then(function() {
//强制跳过等待阶段,进入激活阶段
return self.skipWaiting();
})
);
});
self.addEventListener('activate', function(event) {
//清除cache中原来老的一批相同key的数据
var setOfExpectedUrls = new Set(urlsToCacheKeys.values());
event.waitUntil(
caches.open(cacheName).then(function(cache) {
return cache.keys().then(function(existingRequests) {
return Promise.all(
existingRequests.map(function(existingRequest) {
if (!setOfExpectedUrls.has(existingRequest.url)) {
//cache中删除指定对象
return cache.delete(existingRequest);
}
})
);
});
}).then(function() {
//self相当于webworker线程的当前作用域
//当一个 service worker 被初始注册时,页面在下次加载之前不会使用它。 claim() 方法会立即控制这些页面
//从而更新客户端上的serviceworker
return self.clients.claim();
})
);
});
self.addEventListener('fetch', function(event) {
if (event.request.method === 'GET') {
// 标识位,用来判断是否需要缓存
var shouldRespond;
// 对url进行一些处理,移除一些不必要的参数
var url = stripIgnoredUrlParameters(event.request.url, ignoreUrlParametersMatching);
// 如果该url不是我们想要缓存的url,置为false
shouldRespond = urlsToCacheKeys.has(url);
// 如果shouldRespond未false,再次验证
var directoryIndex = 'index.html';
if (!shouldRespond && directoryIndex) {
url = addDirectoryIndex(url, directoryIndex);
shouldRespond = urlsToCacheKeys.has(url);
}
// 再次验证,判断其是否是一个navigation类型的请求
var navigateFallback = '';
if (!shouldRespond &&
navigateFallback &&
(event.request.mode === 'navigate') &&
isPathWhitelisted([], event.request.url)) {
url = new URL(navigateFallback, self.location).toString();
shouldRespond = urlsToCacheKeys.has(url);
}
// 如果标识位为true
if (shouldRespond) {
event.respondWith(
caches.open(cacheName).then(function(cache) {
//去缓存cache中找对应的url的值
return cache.match(urlsToCacheKeys.get(url)).then(function(response) {
//如果找到了,就返回value
if (response) {
return response;
}
throw Error('The cached response that was expected is missing.');
});
}).catch(function(e) {
// 如果没找到则请求该资源
console.warn('Couldn\'t serve response for "%s" from cache: %O', event.request.url, e);
return fetch(event.request);
})
);
}
}
});
这里的策略大概就是优先在cache中寻找资源,如果找不到再请求资源。可以看出,为了实现一个较为简单的缓存,还是比较复杂和繁琐的,所以很多工具就应运而生了。
其实所有站点 SW 的 install 和 active 都差不多,无非是做预缓存资源列表,更新后缓存清理的工作,逻辑不太复杂,而重点在于 fetch 事件。你需要根据不同文件的扩展名把不同的资源通过不同的策略缓存在 caches 中,各种 CSS,JS,HTML,图片,都需要单独搞一套缓存策略,你就知道 fetch 中需要写多少东西了吧。
常见问题
首次访问
当用户第一次访问网站时,并不会有激活的 Service Worker 来控制页面,只有当 Service Worker 安装完成并且用户刷新了页面或跳转至网站的其他页面时,Service Worker 才会激活并开始拦截请求。如果我们希望 Service Worker 能尽快开始工作,包括在其未激活期间所发起的请求该怎么办?
self.addEventListener('install', function (event) {
event.waitUntil(self.skipWaiting())
})
skipWaiting() 函数强制等待中的 Service Worker 成为激活的 Service Worker,self.skipWaiting() 函数还可以与 self.clients.claim() 一起使用,以确保底层 Service Worker 的更新立即生效。
self.addEventListener('active', function (event) {
event.waitUntil(self.clients.claim())
})
同时使用以上两段代码,可以立即激活 Service Worker。
运行时间
service worker并不是一直在后台运行的。在页面关闭后,浏览器可以继续保持service worker运行,也可以关闭service worker,这取决与浏览器自己的行为。所以不要定义一些全局变量,例如下面的代码
var hitCounter = 0;
this.addEventListener('fetch', function(event) {
hitCounter++;
event.respondWith(
new Response('Hit number ' + hitCounter)
);
});
返回的结果可能是没有规律的:1,2,1,2,1,1,2….,原因是hitCounter并没有一直存在,如果浏览器关闭了它,下次启动的时候hitCounter就赋值为0了 这样的事情导致调试代码困难,当你更新一个service worker以后,只有在打开新页面以后才可能使用新的service worker,在调试过程中经常等上一两分钟才会使用新的,比较抓狂。
权限太大
当service worker监听fetch事件以后,对应的请求都会经过service worker。通过chrome的network工具,可以看到此类请求会标注:from service worker。如果service worker中出现了问题,会导致所有请求失败,包括普通的html文件。所以service worker的代码质量、容错性一定要很好才能保证web app正常运行。
Workbox
在页面线程中,虽然可以直接使用底层 API 来处理 Service Worker 的注册、更新与通信,但在较为复杂的应用场景下(比如,页面中不同窗口注册不同的 Service Worker),我们往往会因为要处理各种情况而逐步陷入复杂、混乱的深渊,并且,在出现运行结果与预期结果不一致时,我们往往不知所措、不知如何进行排查。
正是因为这些原因,Google Chrome 团队推出的一套 PWA 的解决方案 Workbox ,这套解决方案当中包含了核心库和构建工具,因此我们可以利用 Workbox 实现 Service Worker 的快速开发。
引入
Service Worker 文件引入 Workbox 的方法非常简单,只需要在文件顶部增加一行代码即可:
importScripts('https://storage.googleapis.com/workbox-cdn/releases/4.2.0/workbox-sw.js')
Workbox 从 3.x 版本开始便将其核心文件托管到 CDN 上进行维护,开发者也可以下载下来自行维护。
我们可以通过判断全局对象 workbox 是否存在来确认 Workbox 是否加载完成:
if (workbox) {
// Workbox 加载完成
}
一旦 Workbox 加载完成,我们便可以使用挂载到 workbox 对象上的各种功能了。
配置
Workbox 提供了默认的预缓存和动态缓存的名称,可分别通过 workbox.core.cacheNames.precache 和 workbox.core.cacheNames.runtime 获取当前定义的预缓存和动态缓存名称。在通常情况下,我们使用默认的缓存名称进行资源存取即可,假如遇到缓存名称冲突的情况,也可以调用 workbox.core.setCacheNameDetails 方法去修改这些默认名称。下面的代码演示了修改默认名称的方法以及修改结果:
// 修改默认配置
workbox.core.setCacheNameDetails({
prefix: 'app',
suffix: 'v1',
precache: 'precache',
runtime: 'runtime'
})
// 打印修改结果
// 将打印 'app-precache-v1'
console.log(worbox.core.cacheNames.precache)
// 将打印 'app-runtime-v1'
console.log(workbox.core.cacheNames.runtime)
预缓存功能
workbox.precaching 对象提供了常用的预缓存功能,其中最常用的方法是 workbox.precaching.precacheAndRoute。它的作用跟我们前面实现的 Precacher.precacheAndRoute() 的功能类似, 都是将传入的资源列表进行预缓存,同时对匹配到的预缓存请求直接从本地缓存中读取并返回。
workbox.routing.precacheAndRoute([
{
url: '/index.html',
revision: 'asdf'
},
'/index.abc.js',
'/index.bcd.css'
])
precache对应的是在installing阶段进行读取缓存的操作。它让开发人员可以确定缓存文件的时间和长度,以及在不进入网络的情况下将其提供给浏览器,这意味着它可以用于创建Web离线工作的应用。
工作原理
首次加载Web应用程序时,workbox会下载指定的资源,并存储具体内容和相关修订的信息在indexedDB中。
当资源内容和sw.js更新后,workbox会去比对资源,然后将新的资源存入cache,并修改indexedDB中的版本信息。
我们举一个例子:
workbox.precaching.precacheAndRoute([
'./main.css'
]);
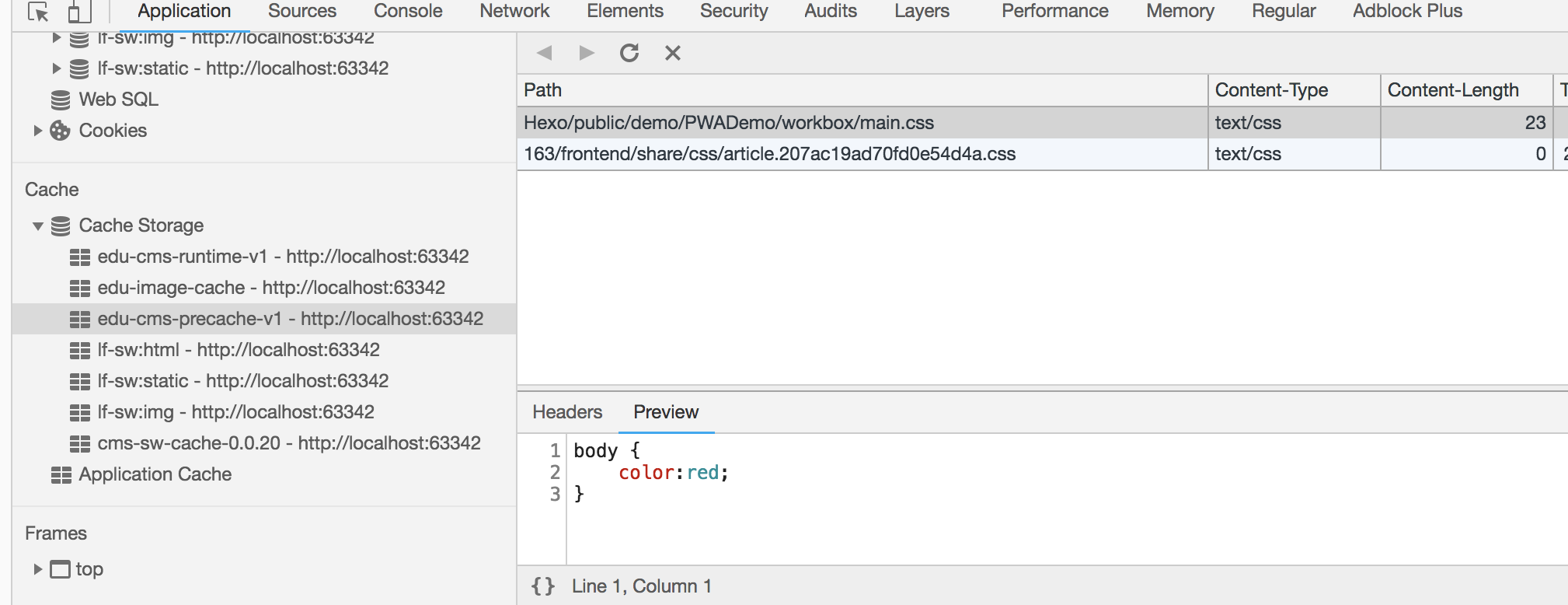
indexedDB中会保存其相关信息

这个时候我们把main.css的内容改变后,再刷新页面,会发现除非强制刷新,否则workbox还是会读取cache中存在的老的main.css内容。
即使我们把main.css从服务器上删除,也不会对页面造成影响。
所以这种方式的缓存都需要配置一个版本号。在修改sw.js时,对应的版本也需要变更。
使用实践
当然了,一般我们的一些不经常变的资源,都会使用cdn,所以这里自然就需要支持域外资源了,配置方式如下:
var fileList = [
{
url:'https://edu-cms.nosdn.127.net/topics/js/cms_specialWebCommon_js_f26c710bd7cd055a64b67456192ed32a.js'
},
{
url:'https://static.ws.126.net/163/frontend/share/css/article.207ac19ad70fd0e54d4a.css'
}
];
//precache 适用于支持跨域的cdn和域内静态资源
workbox.precaching.suppressWarnings();
workbox.precaching.precacheAndRoute(fileList, {
"ignoreUrlParametersMatching": [/./]
});
这里需要对应的资源配置跨域允许头,否则是不能正常加载的。且文件都要以版本文件名的方式,来确保修改后cache和indexDB会得到更新。
理解了原理和实践后,说明这种方式适合于上线后就不会经常变动的静态资源。
动态缓存功能
Workbox 对资源请求匹配和对应的缓存策略执行进行了统一管理,采用路由注册的组织形式,以此来规范化动态缓存。与前面我们封装的 Router 类似,Workbox 提供了 worbox.routing.registerRoute 方法进行路由注册,使用方法如下所示:
workbox.routing.registerRoute(match, handlerCb)
接下来我们将对两个参数进行介绍。
路由匹配规则
workbox.routing.registerRoute 的第一个参数 match 是路由的匹配规则,支持以下几种匹配模式:
1.对资源 URL 进行字符串匹配。URL 字符串可以是完整 URL 或者是相对路径,如果是相对路径,Workbox 首先会以当前网页的 URL 为基准进行补全再进行字符串匹配。假设当前页面的 URL 为 http://127.0.0.1:8080/index.html,那么如下所示所注册的路由都是能够正常匹配到 http://127.0.0.1:8080/index.css 这个资源请求的:
workbox.routing.registerRoute('http://127.0.0.1:8080/index.css', handlerCb)
workbox.routing.registerRoute('/index.css', handlerCb)
workbox.routing.registerRoute('./index.css', handlerCb)
2.对资源 URL 进行正则匹配。假设我们注册这样一条正则匹配的路由规则:
workbox.routing.registerRoute(/\/index\.css$/, handlerCb)
那么以下以 ‘/index.css’ 为结尾的同域资源都能够命中这条路由规则:
-
http://127.0.0.1:8080/index.css -
http://127.0.0.1:8080/a/index.css -
http://127.0.0.1:8080/a/b/index.css
但是对于跨域资源来说并不会命中这条路由规则。这是因为 Workbox 在正则匹配的模式下对跨域资源做了特殊处理,一般情况下会忽略掉对跨域资源的匹配,只有当正则表达式能够匹配到跨域资源 URL 的开头,Workbox 才会明确地知道这类跨域资源需要进行动态缓存处理。因此,如下所示的正则匹配规则才会命中 https://third-party-site.com 这个域下的跨域资源请求:
workbox.routing.registerRoute(
/^https:\/\/third-party-site\.com\/.*\/index\.css$/,
handlerCb
)
3.自定义路由匹配方法。match 允许传入一个自定义方法来实现较为复杂的资源请求匹配规则,这个自定义方法可以仿造下面的代码实现:
const match = ({url, event}) => {
return url.pathname === '/index.html'
}
其中 url 是 URL 类的实例,event 是 fetch 事件的回调参数。url 可通过对 URL 类进行实例化,从 event.request.url 转换得到:
let url = new URL(event.request.url)
自定义路由匹配方法有两点要求,首先要求是个同步执行函数,其次函数在表示资源请求匹配成功的时候,只需要返回一个真值(即强制转化为布尔值后为 true 的值)即可。
资源请求处理方法
workbox.routing.registerRoute 的第二个参数 handlerCb 是对匹配到的资源请求进行处理的方法,开发者可以在这里决定如何响应请求,无论是从网络、从本地缓存还是在 Service Worker 中直接生成都是可以的。比如:
const handlerCb = ({url, event, params}) => {
return Promise.resolve(new Response('Hello World!'))
}
其中,传入资源请求处理方法的对象包含以下属性:
-
url:event.request.url 经 URL 类实例化的对象;
-
event:fetch 事件回调参数;
-
params:自定义路由匹配方法所返回的值。
对资源请求处理方法的要求是,函数必须是个异步方法并返回一个 Promise,且这个 Promise 解析的结果必须是一个 Response 对象。
动态缓存策略
运行时缓存是在install之后,activated和fetch阶段做的事情。
既然在fetch阶段发送,那么runtimecache 往往应对着各种类型的资源,对于不同类型的资源往往也有不同的缓存策略。
workbox.strategies 对象提供了一系列常用的动态缓存策略来实现对资源请求的处理。包括了以下几种策略:
-
NetworkFirst:网络优先
-
CacheFirst:缓存优先
-
NetworkOnly:仅使用正常的网络请求
-
CacheOnly:仅使用缓存中的资源
-
StaleWhileRevalidate:从缓存中读取资源的同时发送网络请求更新本地缓存
staleWhileRevalidate
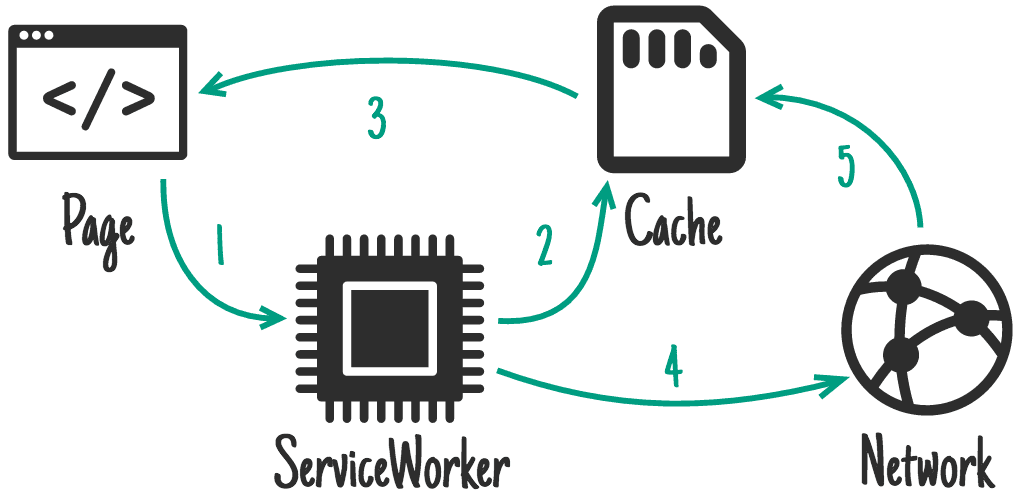
这种策略的意思是当请求的路由有对应的 Cache 缓存结果就直接返回, 在返回 Cache 缓存结果的同时会在后台发起网络请求拿到请求结果并更新 Cache 缓存,如果本来就没有 Cache 缓存的话,直接就发起网络请求并返回结果,这对用户来说是一种非常安全的策略,能保证用户最快速的拿到请求的结果。
但是也有一定的缺点,就是还是会有网络请求占用了用户的网络带宽。可以像如下的方式使用 State While Revalidate 策略:
workbox.routing.registerRoute(
new RegExp('https://edu-cms\.nosdn\.127\.net/topics/'),
workbox.strategies.staleWhileRevalidate({
//cache名称
cacheName: 'lf-sw:static',
plugins: [
new workbox.expiration.Plugin({
//cache最大数量
maxEntries: 30
})
]
})
);
networkFirst
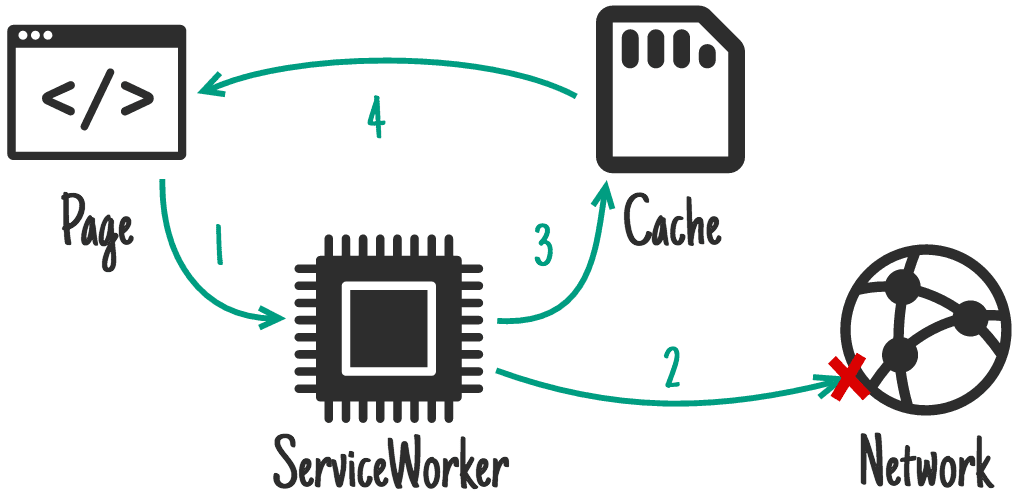
这种策略就是当请求路由是被匹配的,就采用网络优先的策略,也就是优先尝试拿到网络请求的返回结果,如果拿到网络请求的结果,就将结果返回给客户端并且写入 Cache 缓存。
如果网络请求失败,那最后被缓存的 Cache 缓存结果就会被返回到客户端,这种策略一般适用于返回结果不太固定或对实时性有要求的请求,为网络请求失败进行兜底。可以像如下方式使用 Network First 策略:
//自定义要缓存的html列表
var cacheList = [
'/Hexo/public/demo/PWADemo/workbox/index.html'
];
workbox.routing.registerRoute(
//自定义过滤方法
function(event) {
// 需要缓存的HTML路径列表
if (event.url.host === 'localhost:63342') {
if (~cacheList.indexOf(event.url.pathname)) return true;
else return false;
} else {
return false;
}
},
workbox.strategies.networkFirst({
cacheName: 'lf-sw:html',
plugins: [
new workbox.expiration.Plugin({
maxEntries: 10
})
]
})
);
cacheFirst
这个策略的意思就是当匹配到请求之后直接从 Cache 缓存中取得结果,如果 Cache 缓存中没有结果,那就会发起网络请求,拿到网络请求结果并将结果更新至 Cache 缓存,并将结果返回给客户端。这种策略比较适合结果不怎么变动且对实时性要求不高的请求。可以像如下方式使用 Cache First 策略:
workbox.routing.registerRoute(
new RegExp('https://edu-image\.nosdn\.127\.net/'),
workbox.strategies.cacheFirst({
cacheName: 'lf-sw:img',
plugins: [
//如果要拿到域外的资源,必须配置
//因为跨域使用fetch配置了
//mode: 'no-cors',所以status返回值为0,故而需要兼容
new workbox.cacheableResponse.Plugin({
statuses: [0, 200]
}),
new workbox.expiration.Plugin({
maxEntries: 40,
//缓存的时间
maxAgeSeconds: 12 * 60 * 60
})
]
})
);
networkOnly

比较直接的策略,直接强制使用正常的网络请求,并将结果返回给客户端,这种策略比较适合对实时性要求非常高的请求。
cacheOnly
这个策略也比较直接,直接使用 Cache 缓存的结果,并将结果返回给客户端,这种策略比较适合一上线就不会变的静态资源请求。
这些策略与前面介绍资源请求响应策略的章节中简易实现的缓存策略做对比可以发现,其原理基本是一致的,当然在具体实现上 Workbox 考虑得更为复杂而全面以应对各式各样的生产环境。我们可以通过前面简易实现的策略来加深对 Workbox 缓存策略的认识。
接下来通过一些例子来演示缓存策略的配置以及配置生效的情况。
指定资源缓存名称
假设我们需要针对图片资源单独进行存储管理,那么可以在策略中设置 cacheName 来指定缓存名称:
workbox.routing.registerRoute(
/\.(jpe?g|png)/,
new workbox.strategies.CacheFirst({
cacheName: 'image-runtime-cache'
})
)
这样当站点图片资源缓存成功之后,打开 Chrome 开发者工具 > Applications > Cache Storage,就可以看到此时多了一个名为“image-runtime-cache”的缓存空间,里面缓存的内容全是图片资源。
添加插件
Workbox 提供了一些功能强大的插件来强化缓存策略,在这里简单演示一下如何使用 workbox.expiration.Plugin 来实现对图片资源的过期管理:
workbox.routing.registerRoute(
/\.(jpe?g|png)/,
new workbox.strategies.CacheFirst({
plugins: [
new workbox.expiration.Plugin({
// 对图片资源缓存 1 星期
maxAgeSeconds: 7 * 24 * 60 * 60,
// 匹配该策略的图片最多缓存 10 张
maxEntries: 10
})
]
})
)
配置 fetchOptions
对于设置了 CORS 的跨域请求的图片资源,可以通过配置 fetchOptions 将策略中 Fetch API 的请求模式设置为 cors:
workbox.routing.registerRoute(
/^https:\/\/third-party-site\.com\/.*\.(jpe?g|png)/,
new workbox.strategies.CacheFirst({
fetchOptions: {
mode: 'cors'
}
})
)
配置 matchOptions
假设图片资源缓存的存取需要忽略请求 URL 的 search 参数,可以通过设置 matchOptions 来实现:
workbox.routing.registerRoute(
/\.(jpe?g|png)/,
new workbox.strategies.CacheFirst({
matchOptions: {
ignoreSearch: true
}
})
)
举个例子
又到了举个栗子的阶段了,这次我们用淘宝好了,看看他们是如何通过workbox来配置serviceworker的:
//首先是异常处理
self.addEventListener('error', function(e) {
self.clients.matchAll()
.then(function (clients) {
if (clients && clients.length) {
clients[0].postMessage({
type: 'ERROR',
msg: e.message || null,
stack: e.error ? e.error.stack : null
});
}
});
});
self.addEventListener('unhandledrejection', function(e) {
self.clients.matchAll()
.then(function (clients) {
if (clients && clients.length) {
clients[0].postMessage({
type: 'REJECTION',
msg: e.reason ? e.reason.message : null,
stack: e.reason ? e.reason.stack : null
});
}
});
})
//然后引入workbox
importScripts('https://storage.googleapis.com/workbox-cdn/releases/3.3.0/workbox-sw.js');
workbox.setConfig({
debug: false,
modulePathPrefix: 'https://g.alicdn.com/kg/workbox/3.3.0/'
});
//直接激活跳过等待阶段
workbox.skipWaiting();
workbox.clientsClaim();
//定义要缓存的html
var cacheList = [
'/',
'/tbhome/home-2017',
'/tbhome/page/market-list'
];
//html采用networkFirst策略,支持离线也能大体访问
workbox.routing.registerRoute(
function(event) {
// 需要缓存的HTML路径列表
if (event.url.host === 'www.taobao.com') {
if (~cacheList.indexOf(event.url.pathname)) return true;
else return false;
} else {
return false;
}
},
workbox.strategies.networkFirst({
cacheName: 'tbh:html',
plugins: [
new workbox.expiration.Plugin({
maxEntries: 10
})
]
})
);
//静态资源采用staleWhileRevalidate策略,安全可靠
workbox.routing.registerRoute(
new RegExp('https://g\.alicdn\.com/'),
workbox.strategies.staleWhileRevalidate({
cacheName: 'tbh:static',
plugins: [
new workbox.expiration.Plugin({
maxEntries: 20
})
]
})
);
//图片采用cacheFirst策略,提升速度
workbox.routing.registerRoute(
new RegExp('https://img\.alicdn\.com/'),
workbox.strategies.cacheFirst({
cacheName: 'tbh:img',
plugins: [
new workbox.cacheableResponse.Plugin({
statuses: [0, 200]
}),
new workbox.expiration.Plugin({
maxEntries: 20,
maxAgeSeconds: 12 * 60 * 60
})
]
})
);
workbox.routing.registerRoute(
new RegExp('https://gtms01\.alicdn\.com/'),
workbox.strategies.cacheFirst({
cacheName: 'tbh:img',
plugins: [
new workbox.cacheableResponse.Plugin({
statuses: [0, 200]
}),
new workbox.expiration.Plugin({
maxEntries: 30,
maxAgeSeconds: 12 * 60 * 60
})
]
})
);
Workbox 的功能非常完善,插件机制也能够很好的满足各种业务场景需求,如果自己手动维护一个应用的原生的 Service Worker 文件工作量非常巨大,而且有很多潜在的问题不容易被发现,Workbox 很好的规避了很多 Service Worker 潜在的问题,也大大减小了 Service Worker 的维护成本,所以建议大家在开始考虑使用 Service Worker 的时候优先考虑 Workbox。
总结
在经过一段时间的使用和思考以后,给出我认为最为合理,最为保守的缓存策略。
HTML,如果你想让页面离线可以访问,使用 NetworkFirst,如果不需要离线访问,使用 NetworkOnly,其他策略均不建议对 HTML 使用。
CSS 和 JS,情况比较复杂,因为一般站点的 CSS,JS 都在 CDN 上,SW 并没有办法判断从 CDN 上请求下来的资源是否正确(HTTP 200),如果缓存了失败的结果,问题就大了。这种我建议使用 Stale-While-Revalidate 策略,既保证了页面速度,即便失败,用户刷新一下就更新了。
如果你的 CSS,JS 与站点在同一个域下,并且文件名中带了 Hash 版本号,那可以直接使用 Cache First 策略。
图片建议使用 Cache First,并设置一定的失效事件,请求一次就不会再变动了。
上面这些只是普适性的策略,见仁见智。
还有,要牢记,对于不在同一域下的任何资源,绝对不能使用 Cache only 和 Cache first。