Monorepo最佳实践
为什么使用 monorepo
随着业务复杂度的上升,前端项目不管是从代码量上,还是从依赖关系上都会爆炸式增长。对于单页面应用或者多应用项目来说,各个应用之间的关系也会更加复杂,多个应用之间如何配合,如何维护相互关系?公共库版本如何管理?如何兼顾开发体验和上线构建效率?应用复杂度的问题如何解决,随着前端业务的发展逐渐浮出水面。
应用复杂度的场景场景大概有如下几类:
-
需要维护多个不同的包在下游业务中使用
-
包除了被下游业务依赖之外,也可能存在不同依赖关系
-
不同的包位于不同的仓库,并有各自的测试,构建,发布流程
如果纯粹只靠 npm install,那么所有的包都必须发布到 NPM 之后才能被其他的包更新。在「联调」这些包的时候,每次稍有更改都走一遍正式的发布流程,无疑是非常繁琐而影响效率的。
当初团队从 multirepo 迁移到 monorepo,主要还是因为方便共享和调试工具库,但是除了这点,monorepo 还有其他优势,比如:
便捷共享和调试代码
团队最初使用 multirepo 最主要的问题是多仓库共享代码、调试非常不方便,也就是开发工具库/组件库时调试很麻烦,每次都需要使用 yarn link 的模式来开发,然后开发完成后再进行发版才能供其他项目使用,这就导致了多仓库共享代码成本非常高。
切换成 monorepo 的模式后,对基础库的开发就非常省事,我们可以直接在项目中引用工具库进行开发调试,不需要再使用 yarn link。
重复的基础建设
除了共享代码繁琐,每个工具库还需要配置自己的基础设施、CI/CD 流程、开发环境,同时每个项目都需要专人来维护,这样就很容易导致项目之间的不一致性,而后提升多项目维护成本。
试想一下,如果你需要开发多个项目,而每个项目的开发模式都是不一致的,这种体验是非常糟糕的,也是非常耗费人力成本的。
但是当我们使用 monorepo 时,我们就可以在使用一套基础建设、开发规范等来降低项目维护的成本。且只需要抽出单独的 1-2 个人力去专门维护基础建设,其他项目完全不需要再关心。
简化依赖管理
同时因为不再使用的发包模式来管理公共代码,所以对 monorepo 内的公共依赖都是使用的最新版本,这样就很容易追踪到公共代码的变更会对其他项目的影响,当然这个时候就更需要注重公共代码的自动化测试,因为公共代码只要合并到 master 后就会立即影响所有线上项目。
快速协助其他项目开发
因为使用了完全相同的基础建设、工作流、开发环境,所以在团队之间相互协助的时候,不需要在配置开发环境、如何部署项目等等流程上重复浪费时间,只需要关心业务的开发即可。
Monorepo 演进
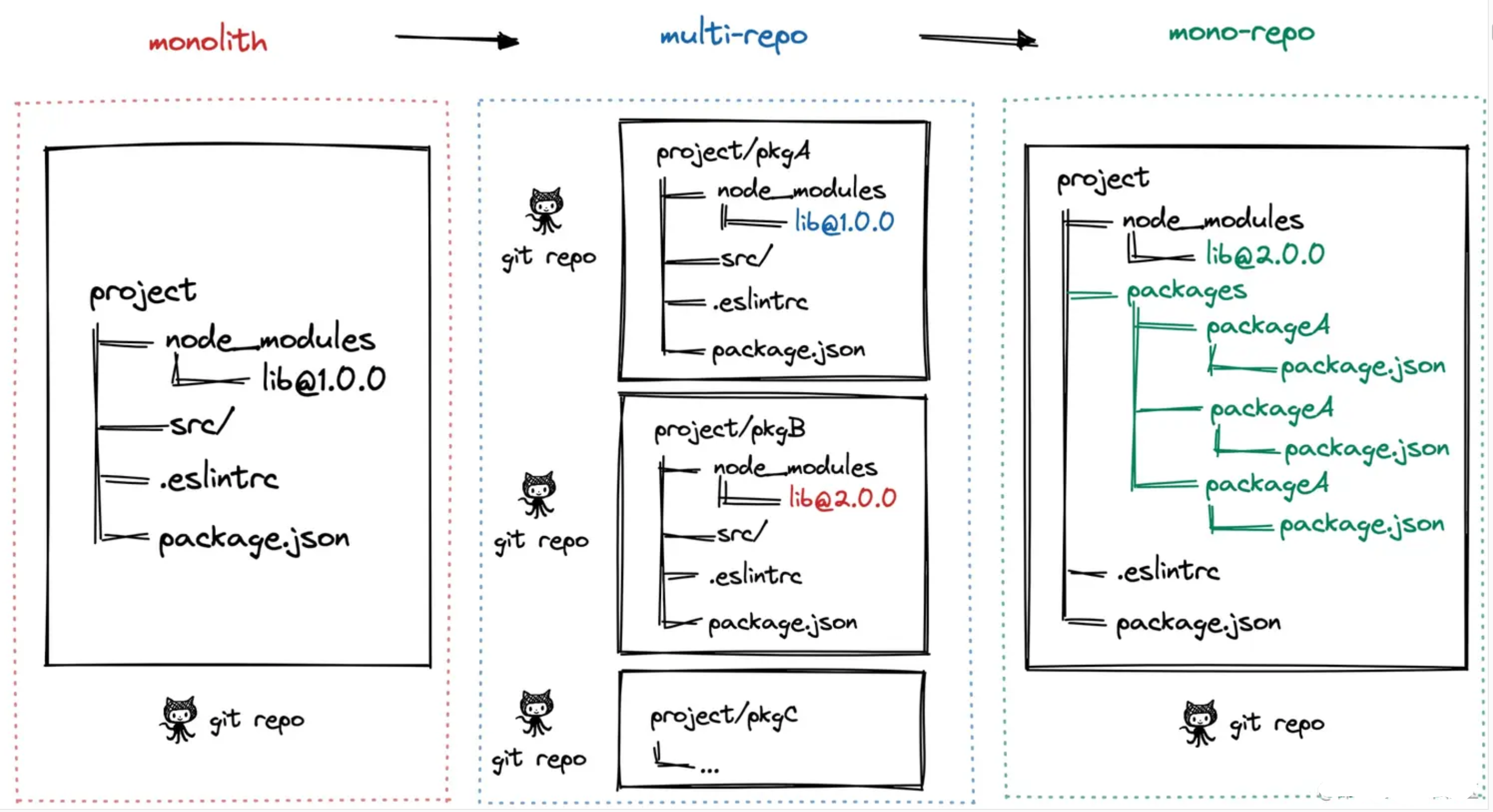
阶段一:单仓库巨石应用, 一个 Git 仓库维护着项目代码,随着迭代业务复杂度的提升,项目代码会变得越来越多,越来越复杂,大量代码构建效率也会降低,最终导致了单体巨石应用,这种代码管理方式称之为 Monolith。
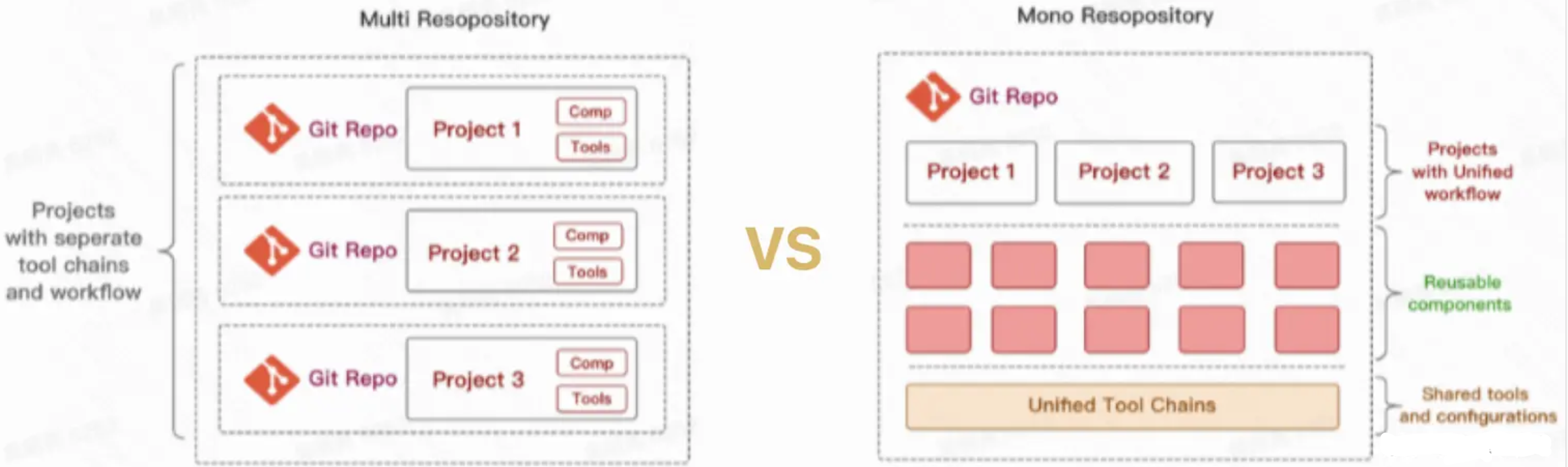
阶段二:多仓库多模块应用,于是将项目拆解成多个业务模块,并在多个 Git 仓库管理,模块解耦,降低了巨石应用的复杂度,每个模块都可以独立编码、测试、发版,代码管理变得简化,构建效率也得以提升,这种代码管理方式称之为 MultiRepo。
阶段三:单仓库多模块应用,随着业务复杂度的提升,模块仓库越来越多,MultiRepo这种方式虽然从业务上解耦了,但增加了项目工程管理的难度,随着模块仓库达到一定数量级,会有几个问题:跨仓库代码难共享;分散在单仓库的模块依赖管理复杂(底层模块升级后,其他上层依赖需要及时更新,否则有问题);增加了构建耗时。于是将多个项目集成到一个仓库下,共享工程配置,同时又快捷地共享模块代码,成为趋势,这种代码管理方式称之为 MonoRepo。
MultiRepo vs Monorepo
| 场景 | MultiRepo | MonoRepo |
|---|---|---|
| 代码可见性 | ✅ 代码隔离,研发者只需关注自己负责的仓库 ❌ 包管理按照各自owner划分,当出现问题时,需要到依赖包中进行判断并解决。 |
✅ 一个仓库中多个相关项目,很容易看到整个代码库的变化趋势,更好的团队协作。 ❌ 增加了非owner改动代码的风险 |
| 依赖管理 | ❌ 多个仓库都有自己的 node_modules,存在依赖重复安装情况,占用磁盘内存大。 | ✅ 多项目代码都在一个仓库中,相同版本依赖提升到顶层只安装一次,节省磁盘内存, |
| 代码权限 | ✅ 各项目单独仓库,不会出现代码被误改的情况,单个项目出现问题不会影响其他项目。 | ❌ 多个项目代码都在一个仓库中,没有项目粒度的权限管控,一个项目出问题,可能影响所有项目。 |
| 开发迭代 | ✅ 仓库体积小,模块划分清晰,可维护性强。 ❌ 多仓库来回切换(编辑器及命令行),项目多的话效率很低。多仓库见存在依赖时,需要手动 npm link,操作繁琐。 ❌ 依赖管理不便,多个依赖可能在多个仓库中存在不同版本,重复安装,npm link 时不同项目的依赖会存在冲突。 |
✅ 多个项目都在一个仓库中,可看到相关项目全貌,编码非常方便。 ✅ 代码复用高,方便进行代码重构。 ✅ 依赖调试方便,依赖包迭代场景下,借助工具自动 npm link,直接使用最新版本依赖,简化了操作流程。 ❌ 多项目在一个仓库中,代码体积多大几个 G,git clone时间较长。 |
| 工程配置 | ❌ 各项目构建、打包、代码校验都各自维护,不一致时会导致代码差异或构建差异。 | ✅ 多项目在一个仓库,工程配置一致,代码质量标准及风格也很容易一致。 |
| 构建部署 | ❌ 多个项目间存在依赖,部署时需要手动到不同的仓库根据先后顺序去修改版本及进行部署,操作繁琐效率低。 | ✅ 构建性 Monorepo 工具可以配置依赖项目的构建优先级,可以实现一次命令完成所有的部署。 |
Monorepo 选型
构建型 Monorepo 方案
此类工具,主要解决大仓库 Monorepo 构建效率低的问题。项目代码仓库越来越庞大,工作流(int、构建、单元测试、集成测试)也会越来越慢;这类工具,是专门针对这样的场景进行极致的性能优化。适用于包非常多、代码体积非常大的 Monorepo 项目。
Turborepo
Turborepo 是 Vercel 团队开源的高性能构建代码仓库系统,允许开发者使用不同的构建系统。
构建加速思路
-
Multiple Running Task:构建任务并行进行,构建顺序交给开发者配置
-
Cache、Remote Cache:通过缓存 及 远程缓存,减少构建时间
举例 Multiple Running Task
我们现在有一个 Monorepo 的项目,有以下几个 package:
-
apps/web,依赖 shared
-
apps/docs,依赖 shared
-
package/shared,被 web 和 docs 依赖
# 当我们使用正常的 yarn workspace 去管理 monorepo 的工作流任务时,例如执行以下命令:
yarn workspaces run lint
yarn workspaces run test
yarn workspaces run build
传统的 yarn workspace 问题:串行构建,性能差
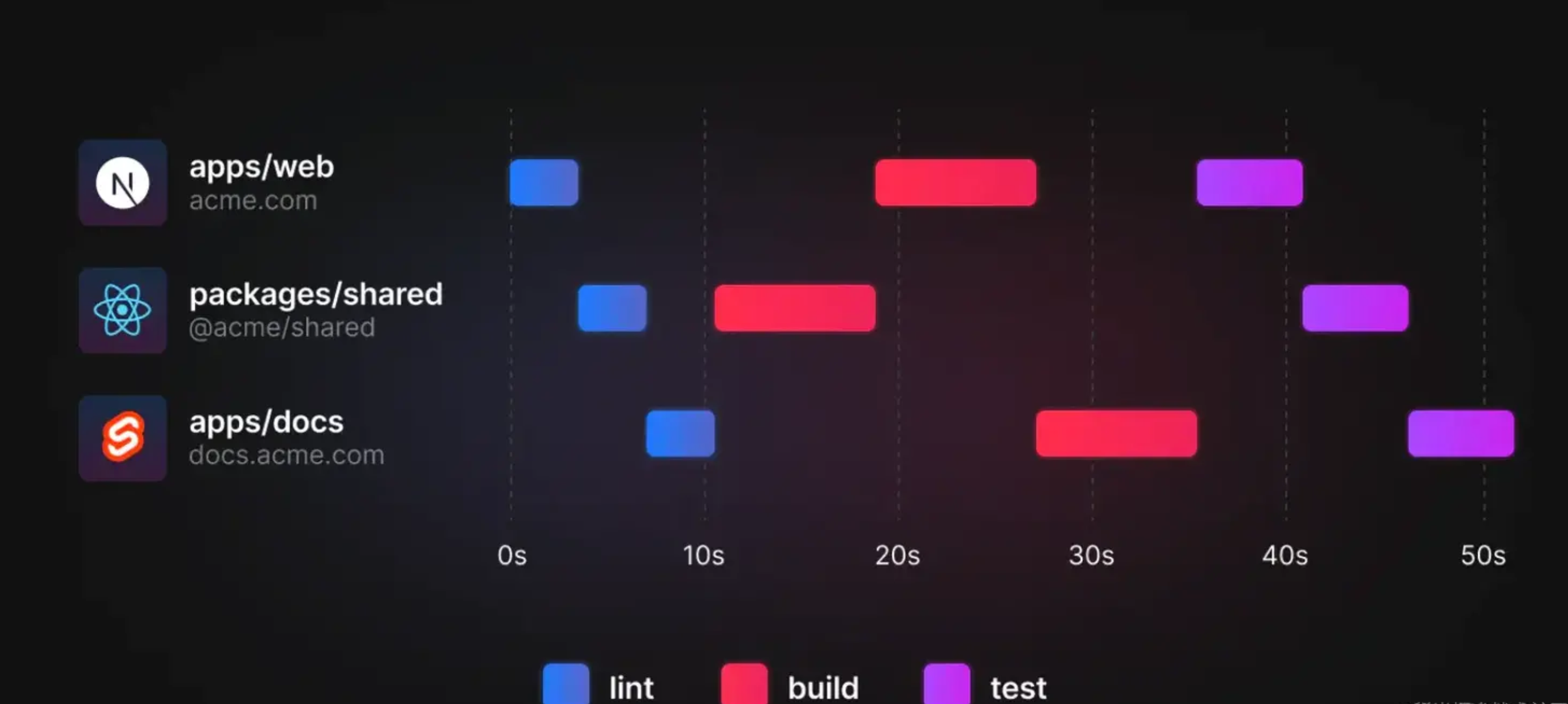
Turborepo Multiple Running Task:允许用户在 turbo.json 中声明 task 之间依赖关系,优化后构建如下

举例 Local Cache
第一次trubo run build后,会生成缓存存放在 node_modules/.cache/turbo/
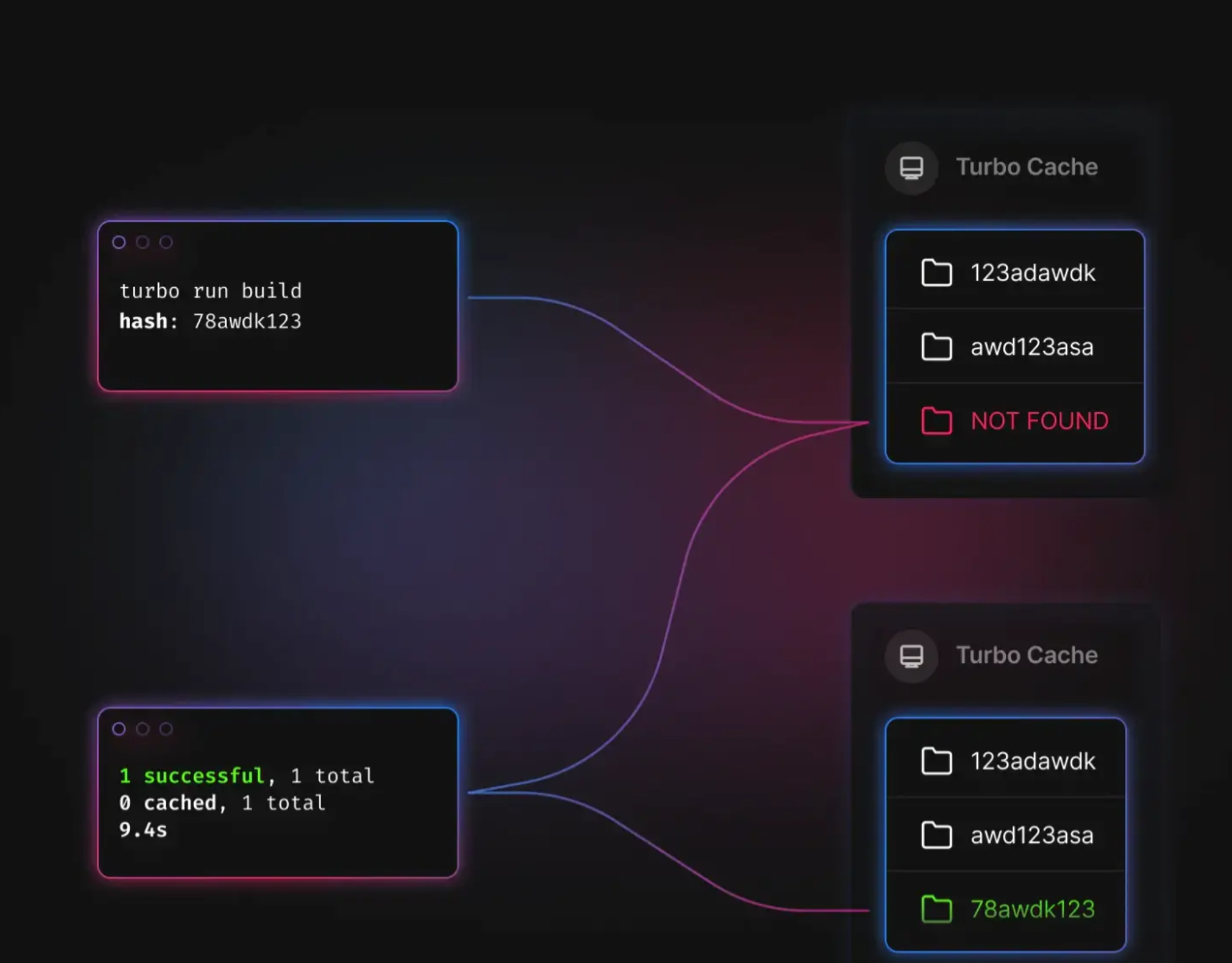
(第一次构建示意图)
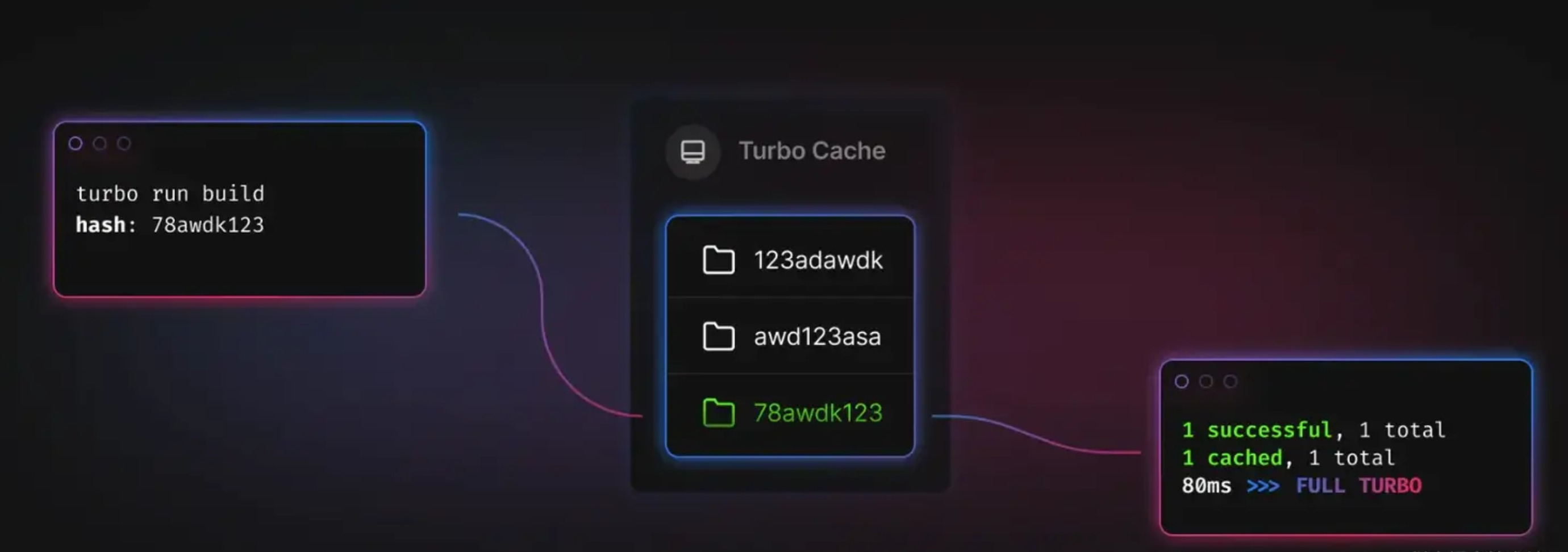
(第二次构建示意图)
举例 Remote Cache
想要在 CI/CD 或团队中共享打包缓存,把缓存保存到了云端,构建时被拉取
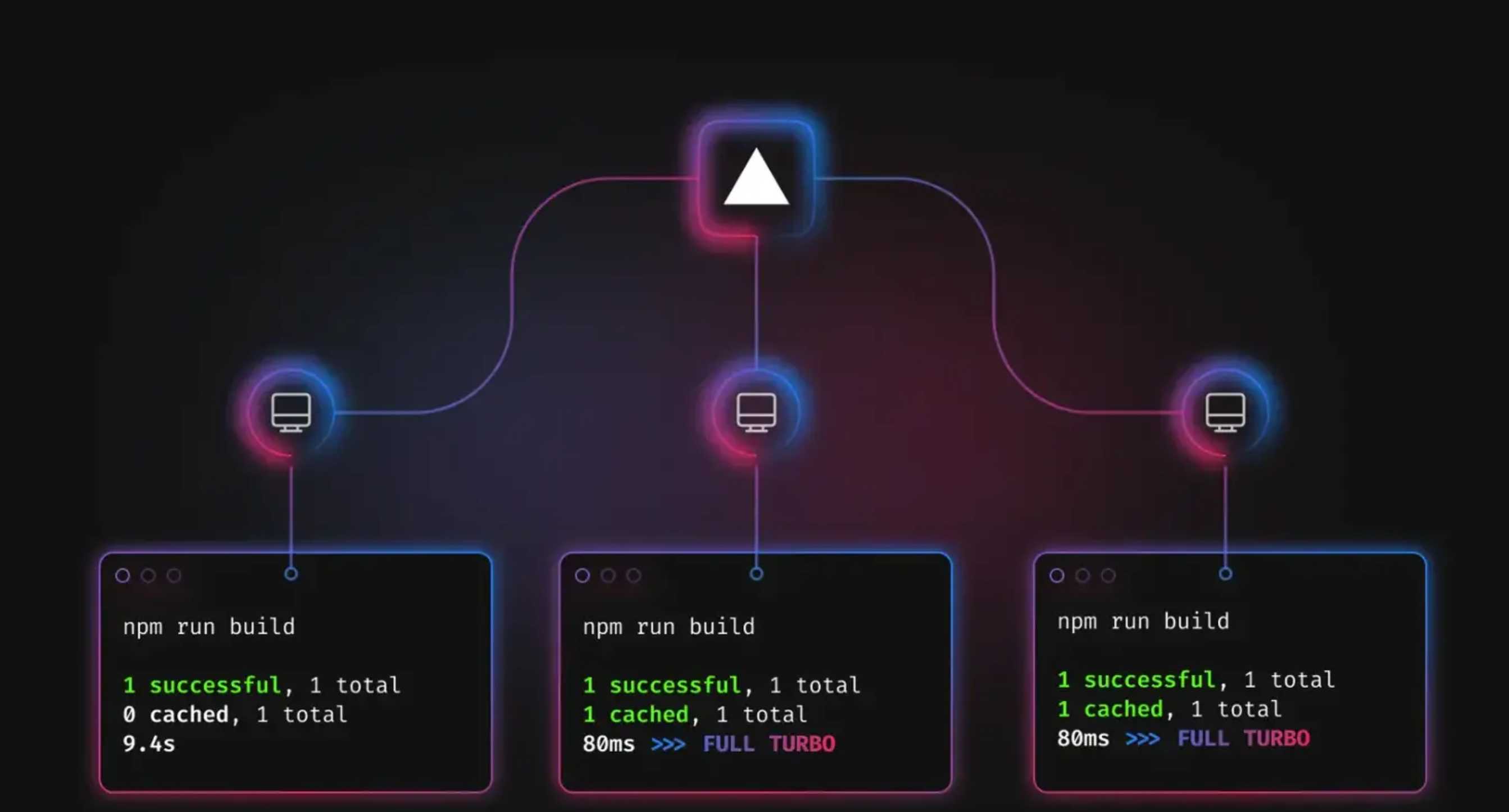
(远程缓存构建示意图)
Rush
Rush 是微软开发的可扩展的 Monorepo 工具及解决方案。早期,只提供了 Rush 作为构建调取器,其余事项交给用户灵活的选择任意构建工具链,由于过于灵活带来了很大的选型及维护成本,后来成立了 Rush Stack 来提供了一套可复用的解决方案,涵盖多项目的构建、测试、打包和发布,实现了更强大的工作流。有如下工具:
-
Rush: 可扩展的 monorepo 构建编排工具
-
Heft: 可以与 Rush 交互的可扩展构建系统
-
API Extractor: 为工具库审阅 API 并生成 .d.ts 文件
-
API Documenter: 生成你的 API 文档站
-
@rushstack/eslint-config: 专门为大型 TypeScript monorepo 仓库设计的 ESLint 规则集
-
@rushstack/eslint-plugin-packlets: 可用于在单个项目内来组织代码,NPM 发包的一个轻量级解决方案
-
Rundown: 用于优化 Node.js 启动时间的工具
Rush 功能列举
-
解决了幽灵依赖:将项目所有依赖都安装到 Repo根目录的common/temp下,通过软链接到各项目,保证了 node_modules 下依赖与 package.json 一致
-
并行构建:Rush 支持并行构建多个项目,提高了构建效率
-
插件系统:Rush 提供了丰富的插件系统,可以扩展其功能,满足不同的需求,具体参考
-
项目发布,ChangeLog 支持友好:自动修改项目版本号,自动生成 ChangeLog
Nx
Nx 是 Nrwl 团队开发的,同时在维护 Lerna,目前 Nx 可以与 Learn 5.1及以上集成使用
构建加速思路(比 Turborepo 更丰富)
-
缓存: 通过缓存 及 远程缓存,减少构建时间(远程缓存:Nx 公开了一个公共 API,它允许您提供自己的远程缓存实现,Turborepo 必须使用内置的远程缓存)
-
增量构建: 最小范围构建,非全量构建
-
并行构建: Nx 自动分析项目的关联关系,对这些任务进行排序以最大化并行性
-
分布式构建: 结合 Nx Cloud,您的任务将自动分布在 CI 代理中(多台远程构建机器),同时考虑构建顺序、最大化并行化和代理利用率

(分布式构建示意图)
用 Nx 强大的任务调度器加速 Lerna:Lerna 擅长管理依赖关系和发布,但扩展基于 Lerna 的 Monorepos 很快就会变得很痛苦,因为 Lerna 很慢。这就是 Nx 的闪光点,也是它可以真正加速你的 monorepo 的地方。
轻量化 Monorepo 方案
Lerna
Lerna 是什么?
-
Lerna 是 Babel 为实现 Monorepo 开发的工具;最擅长管理依赖关系和发布
-
Lerna 优化了多包工作流,解决了多包依赖、发版手动维护版本等问题
-
Lerna 不提供构建、测试等任务,工程能力较弱,项目中往往需要基于它进行顶层能力的封装
Lerna 主要做三件事
-
为单个包或多个包运行命令 (lerna run)
-
管理依赖项 (lerna bootstrap)
-
发布依赖包,处理版本管理,并生成变更日志 (lerna publish)
Lerna 解决了什么问题?
-
代码共享,调试便捷: 一个依赖包更新,其他依赖此包的包/项目无需安装最新版本,因为 Lerna 自动 Link
-
安装依赖,减少冗余:多个包都使用相同版本的依赖包时,Lerna 优先将依赖包安装在根目录
-
规范版本管理: Lerna 通过 Git 检测代码变动,自动发版、更新版本号;两种模式管理多个依赖包的版本号
-
自动生成发版日志:使用插件,根据 Git Commit 记录,自动生成 ChangeLog
Lerna 自动检测发布,判断逻辑
-
校验本地是否有没有被 commit 内容?
-
判断当前的分支是否正常?
-
判断当前分支是否在 remote 存在?
-
判断当前分支是否在 lerna.json 允许的 allowBranch 设置之中?
-
判断当前分支提交是否落后于 remote
Lerna 工作模式
Lerna 允许您使用两种模式来管理您的项目:固定模式(Fixed)、独立模式(Independent)
① 固定模式(Locked mode)
-
Lerna 把多个软件包当做一个整体工程,每次发布所有软件包版本号统一升级(版本一致),无论是否修改
-
项目初始化时,lerna init 默认是 Locked mode
{
"version": "0.0.0"
}
② 独立模式(Independent mode)
-
Lerna 单独管理每个软件包的版本号,每次执行发布指令,Git 检查文件变动,只发版升级有调整的软件包
-
项目初始化时,lerna init –independent
{
"version": "independent"
}
Lerna 常用指令
① 初始化:init
lerna init
执行成功后,目录下将会生成这样的目录结构
- packages(目录)
- lerna.json(配置文件)
- package.json(工程描述文件)
{
"version": "0.0.0",
"useWorkspaces": true,
"packages": [
"packages/*",
],
}
需要在项目根目录下的 package.json中设置 “private”: true
{
"name": "xxxx",
"version": "0.0.1",
"description": "",
"main": "index.js",
"private": true,
"scripts": {
"test": "echo "Error: no test specified" && exit 1"
},
"keywords": [],
"author": "",
"license": "ISC",
"devDependencies": {
"lerna": "^6.4.1"
},
"workspaces": [
"packages/*"
]
}
② 创建 package:create
lerna create <name> [location]
lerna create package1
执行 lerna init 后,默认的 lerna workspace 是 packages/*,需要手动修改 package.json 中的 workspaces,再执行指令生成特定目录下的 package
# 在 packages/pwd1 目录下,生成 package2 依赖包
lerna create package2 packages/pwd1
③ 给 package 添加依赖:add
安装的依赖,如果是本地包,Lerna 会自动 npm link 到本地包
# 给所有包安装依赖,默认作为 dependencies
lerna add module-1
lerna add module-1 --dev # 作为 devDependencies
lerna add module-1 --peer # 作为 peerDependencies
lerna add module-1[@version] --exact # 安装准确版本的依赖
lerna add module-1 --scope=module-2 # 给指定包安装依赖
lerna add module-1 packages/prefix-* # 给前缀为 xxx 的包,安装依赖
④ 给所有 package 安装依赖:bootstrap
# 项目根目录下执行,将安装所有依赖
lerna bootstrap
执行 lerna bootstrap 指令:会自动为每个依赖包进行 npm install 和 npm link 操作
关于冗余依赖的安装:
-
npm 场景下 lerna bootstrap 会安装冗余依赖(多个 package 共用依赖,每个目录都会安装)
-
yarn 会自动 hosit 依赖包(相同版本的依赖,安装在根目录),无需关心
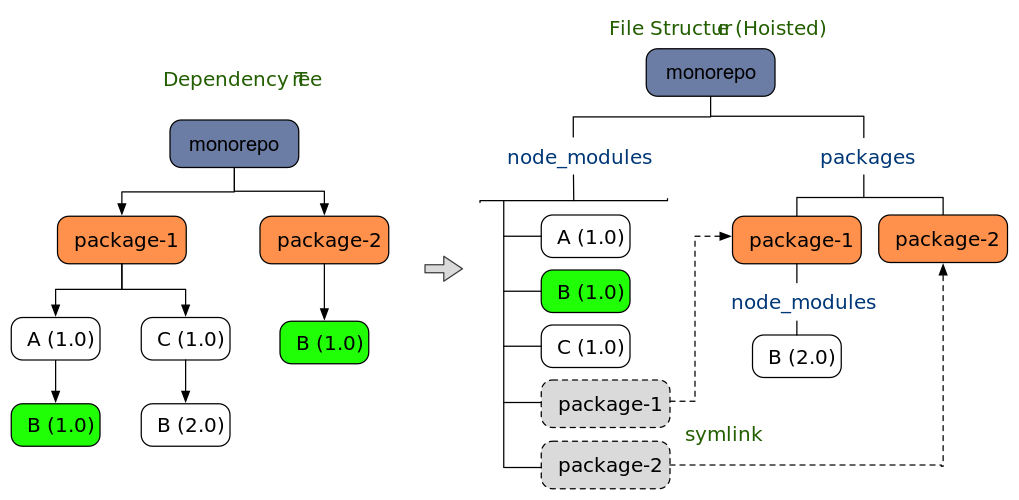
npm 场景下冗余依赖解决方案:
-
方案一: lerna bootstrap –hoist
-
方案二:配置 lerna.json/command.bootsrap.hoist = true
⑤ 给 package 执行 shell 指令:exec
# 删除所有包内的 lib 目录
lerna exec -- rm -rf lib
# 给xxx软件包,删除依赖
lerna exec --scope=xxx -- yarn remove yyy
⑥ 给 package 执行 scripts 指令:run
# 所有依赖执行 package.json 文件 scripts 中的指令 xxx
lerna run xxx
# 指定依赖执行 package.json 文件 scripts 中的指令 xxx
lerna run --scope=my-component xxx
⑦ 清除所有 package 下的依赖:clean
清楚所有依赖包下的 node_modules,根目录下不会删除
lerna clean
⑧ 发布软件包,自动检测:publish
lerna publish
lerna publish 做那些事儿
-
运行lerna updated来决定哪一个包需要被publish
-
如果有必要,将会更新lerna.json中的version
-
将所有更新过的的包中的package.json的version字段更新
-
将所有更新过的包中的依赖更新
-
为新版本创建一个git commit或tag
-
将包publish到npm上
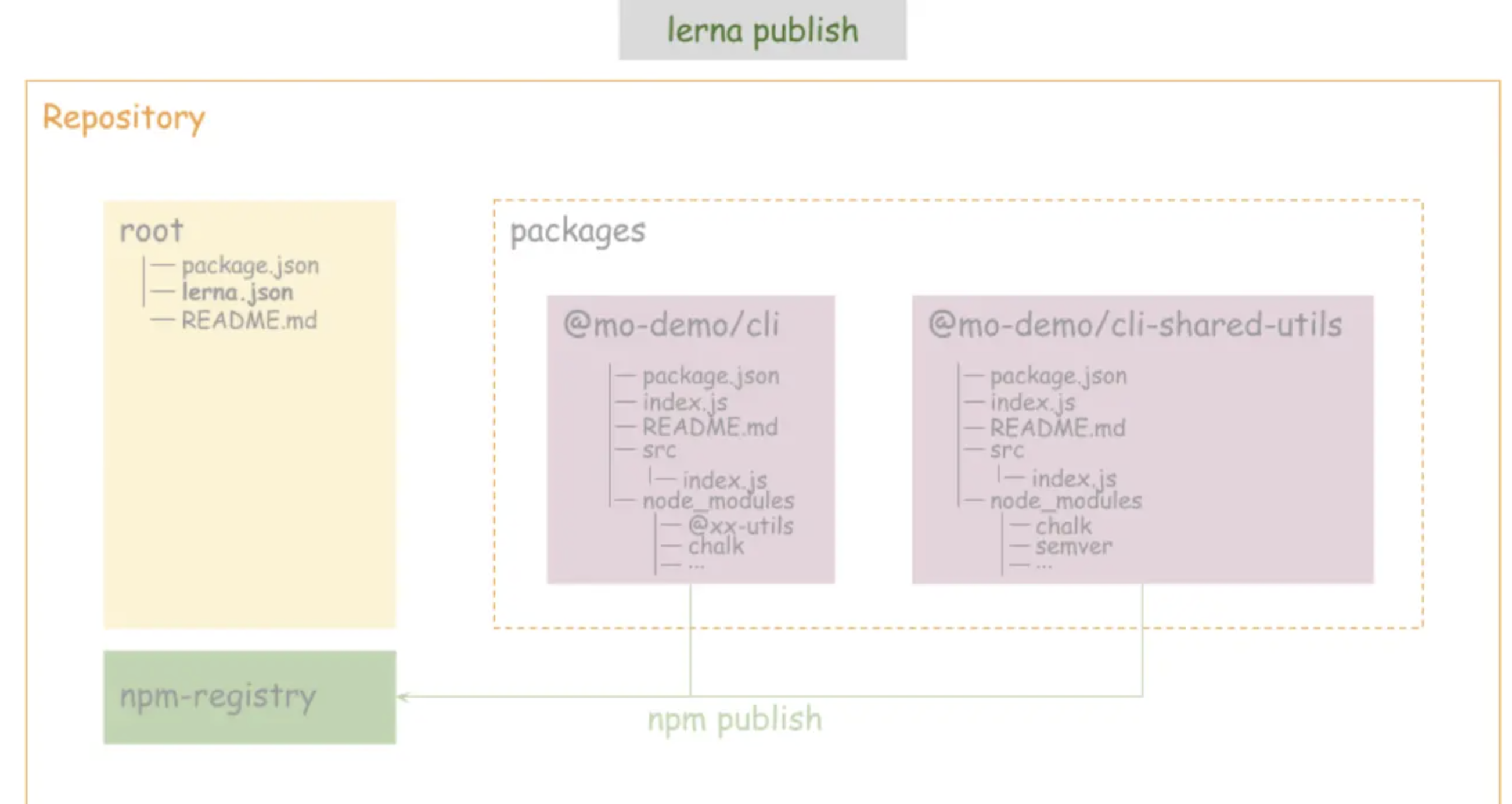
⑨ 查看自上次发布的变更:diff、changed
# 查看自上次relase tag以来有修改的包的差异
lerna diff
# 查看自上次relase tag以来有修改的包名
lerna changed
⑩ 导入已有包:import
lerna import [npm 包所在本地路径]
⑪ 列出所有包:list
lerna list
yarn/npm + workspace
yarn 1.x 及以上版本,新增 workspace 能力,不借助 Lerna,也可以提供原生的 Monorepo 支持,需要在根目录下 package.json 中,声明 workspace
{
"private": true, // 必须是私有项目
"workspaces": ["project1", "project2/*"]
}
yarn workspace VS Lerna
两者功能有重叠,比较类似prettier和eslint的关系形成互补。一般用的时候都是用各自的一部分功能。
yarn workspace是yarn的一个特性,主要是支持工作区的相互依赖,类似于npm link但只影响工作区的依赖树。 它将永远不会试图提供像 Lerna 那么高级的功能,但通过实现该解决方案的核心逻辑和 Yarn 内部的连接步骤,希望能够提供新的用法并提高性能。
lerna是babel自己用来维护monorepo并开源的一个工作流管理项目。对于lerna而言,它的主要功能是版本控制与发布。
-
yarn workspace 更突出对依赖的管理: 依赖提升到根目录的 node_modules 下,安装更快,体积更小
-
Lerna 更突出工作流方面:使用 Lerna 命令来优化多个包的管理,如:依赖发包、版本管理,批量执行脚本
能力及性能对比
| 能力 | Lerna | NPM Workspace | Yarn Workspace |
|---|---|---|---|
| 依赖管理 | lerna bootstrap | npm install | yarn |
| 安装依赖 | lerna add xxx –scope=pkg | npm install xxx -w pkg | yarn workspace pkg add xxx |
| 移除依赖 | 无 | npm uninstall xxx -w pkg | yarn workspace pkg remove xxx |
| 依赖发布 | lerna run xxx –scope=pkg | npm run xxx -w pkg | yarn workspace pkg run xxx |
| 统一执行 scipts 指令 | lerna run xxx | npm run xxx –ws | yarn workspaces run xxx |
| 在每个包下动态执行指令 | lerna exec – command | npm exec -c ‘command’ –ws | yarn workspaces foreach command(需插件支持) |
| 统一发布配置、changelog、tag 和 commit 等 | lerna.json/lerna publish | 无 | 无 |
| 相对缺点 | 1.无法一次安装多个依赖 2. 未提供依赖移除能力 |
1.未提供更为精细的发布控制配置 2. 依赖安装耗时相对较长 |
1.未提供更为精细的发布控制配置 2.不原生支持在每个包下动态执行指令 |
更佳方案: yarn workspace + Lerna
如上 VS 可以看出,yarn workspace 和 Lerna 各有所长,yarn workspace + Lerna 是更好的 Monorepo 方案,执行命令 yarn(相当于执行 lerna bootstrap),即可安装所有依赖,指令过渡更平滑,自动依赖提升,减少依赖安装。
能力分工:Lerna 将依赖管理交给 yarn workspace;Lerna 承担依赖发布能力。
操作步骤:
1、配置 Lerna 使用 Yarn 管理依赖:learn.json 中配置 “npmClient”: “yarn”
2、配置 Lerna 启用 Yarn Workspaces:
-
配置 lerna.json/useWorkspaces = true
-
配置根目录 package.json/workspaces = [“pacages/*”] , 此时 lerna.json 中的 packages 配置项将不再使用
-
配置根目录 package.json/private = true
说明:
上面三个配置项需同时开启, 只开启一个 lerna 会报错
此时执行 lerna bootstrap 相当于执行yarn install,等同于执行 lerna bootstrap --npm-client yarn --use-workspaces
由于 yarn 会自动 hosit 依赖包, 无需再 lerna bootstrap 时增加参数 --hoist (加了参数 lerna 也会报错)
3、不需要发包的项目,配置 package.json/private = true
Lerna + pnpm + workspace
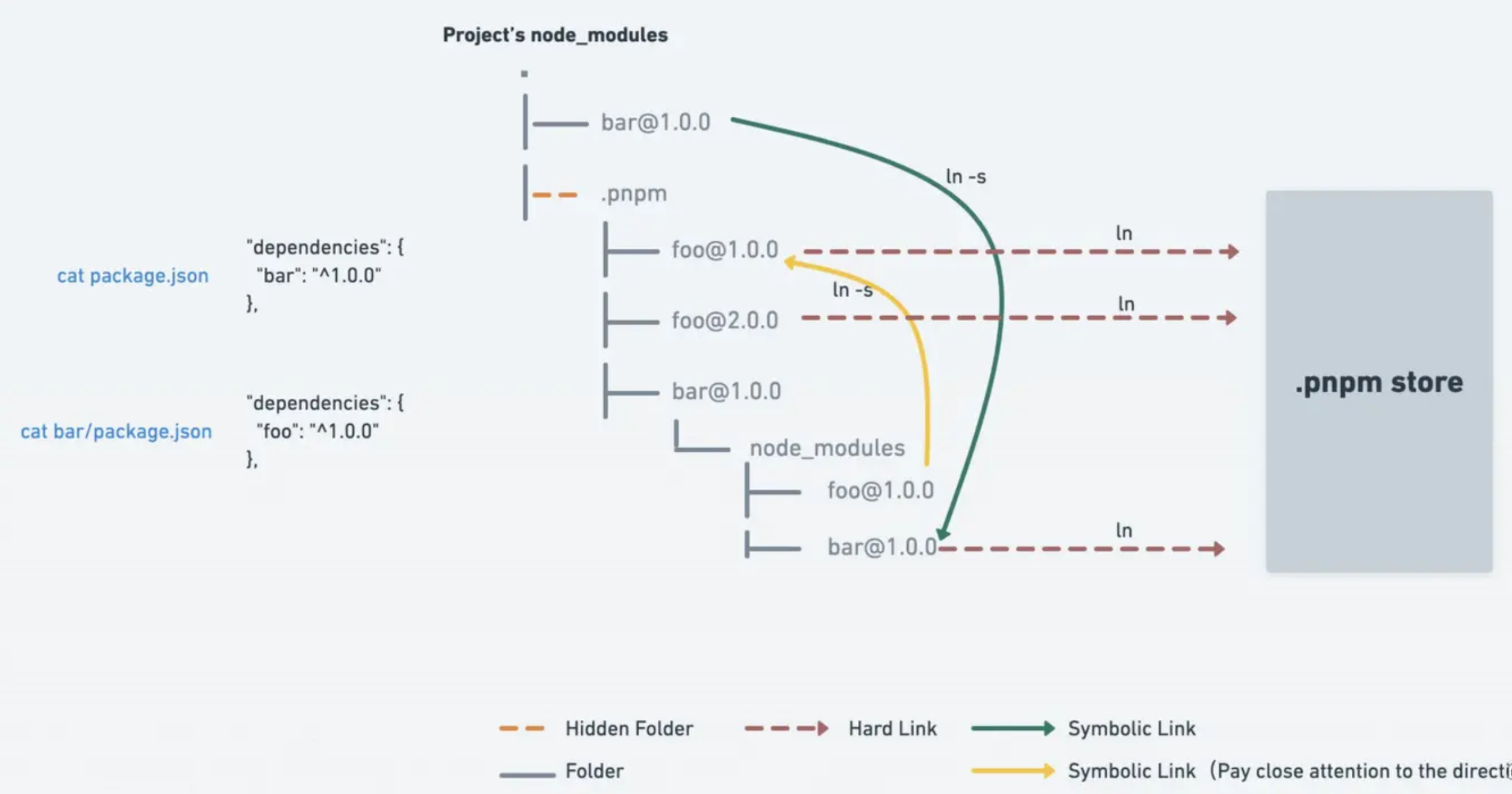
pnpm 是新一代 Node 包管理器,它由 npm/yarn 衍生而来,解决了 npm/yarn 内部潜在的风险,并且极大提升依赖安装速度。pnpm 内部使用基于内容寻址的文件系统,来管理磁盘上依赖,减少依赖安装;node_modules/.pnmp为虚拟存储目录,该目录通过<package-name>@<version>来实现相同模块不同版本之间隔离和复用,由于它只会根据项目中的依赖生成,并不存在提升。
CAS 内容寻址存储,是一种存储信息的方式,根据内容而不是位置进行检索信息的存储方式。
Virtual store 虚拟存储,指向存储的链接的目录,所有直接和间接依赖项都链接到此目录中,项目当中的.pnpm目录
pnpm 相比于 npm、yarn 的包管理器,优势如下:
-
装包速度极快: 缓存中有的依赖,直接硬链接到项目的 node_module 中;减少了 copy 的大量 IO 操作
-
磁盘利用率极高: 软/硬链接方式,同一版本的依赖共用一个磁盘空间;不同版本依赖,只额外存储 diff 内容
-
解决了幽灵依赖: node_modules 目录结构 与 package.json 依赖列表一致
补充:pnpm 原理
-
存储中心 Store 集中管理依赖:不同项目,相同版本依赖安装只进行硬链接;不同版本依赖,只增加Diff文件
-
项目 package.json 依赖列表,和node_modules/.pnpm目录结构一致
-
相同依赖安装时,将 Store 中的依赖硬链接到项目的 node_modules/.pnpm 下,而不是复制,速度快
-
项目node_modules中已有依赖重复安装时,会被软链接到指定目录下
小结:如何选择
工具对比
| 工具 | Turborepo | Rush | Nx | Lerna | Pnpm Workspace |
|---|---|---|---|---|---|
| 依赖管理 | ❌ | ✅ | ❌ | ❌ | ✅ |
| 版本管理 | ❌ | ✅ | ❌ | ✅ | ❌ |
| 增量构建 | ✅ | ✅ | ✅ | ❌ | ❌ |
| 插件扩展 | ✅ | ✅ | ✅ | ❌ | ❌ |
| 云端缓存 | ✅ | ✅ | ✅ | ❌ | ❌ |
| Stars | 20.4K | 4.9K | 17K | 34.3K | 22.7K |
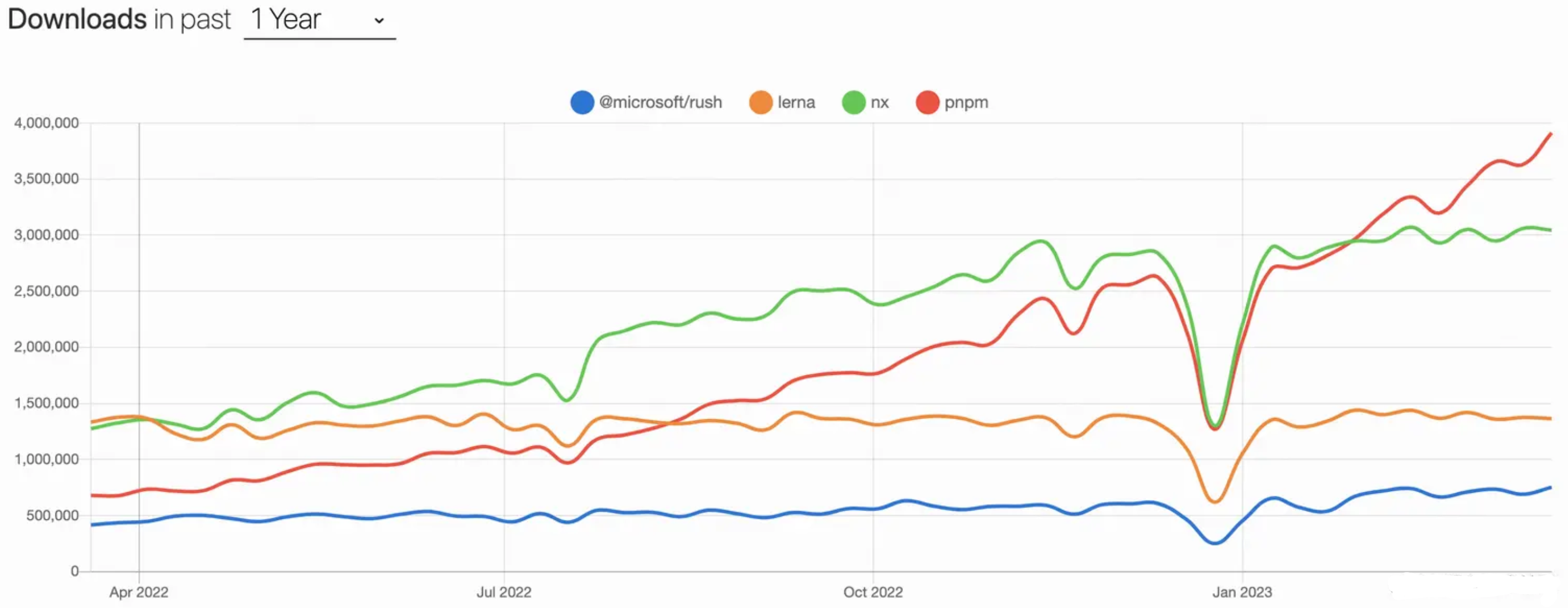
选型建议
建议采用渐进式架构方案,即对于轻量级 Monorepo 项目,我们初期可以选择 Lerna + pnpm workspace,解决了依赖管理、发版管理等问题,为开发者带来便利;随着后续项目迭代,代码变多或多个项目间依赖关系复杂,可以很平滑的接入 Nx 来提升构建打包效率。
实战
Lerna 是一个管理多个 npm 模块的工具,是 Babel 自己用来维护自己的 Monorepo 并开源出的一个项目。优化维护多包的工作流,解决多个包互相依赖,且发布需要手动维护多个包的问题。
一个基本的 Lerna 管理的仓库结构如下:

安装
推荐全局安装,因为会经常用到 lerna 命令
npm i -g lerna
项目初始化
lerna init
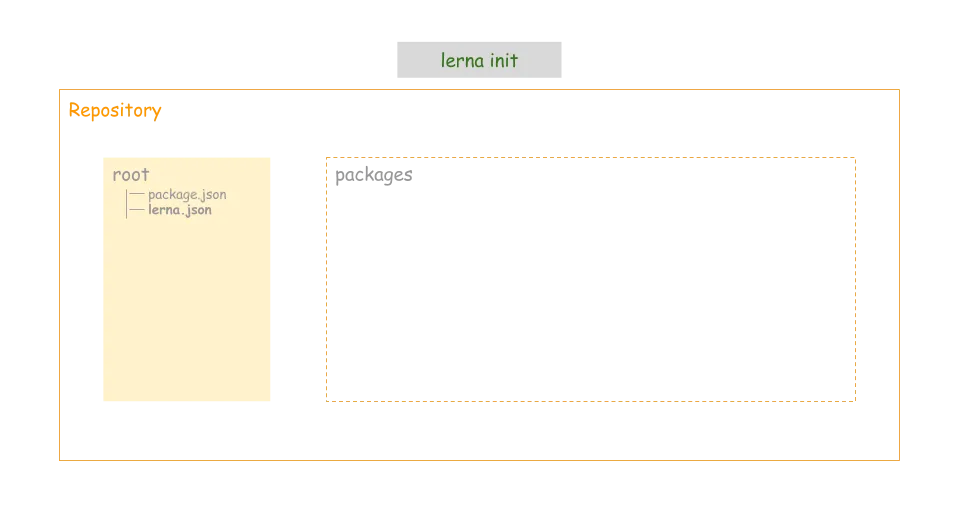
其中 package.json & lerna.json 如下:
// package.json
{
"name": "root",
"private": true, // 私有的,不会被发布,是管理整个项目,与要发布到npm的解耦
"devDependencies": {
"lerna": "^3.15.0"
}
}
// lerna.json
{
"packages": [
"packages/*"
],
"version": "0.0.0"
}
增加两个 packages
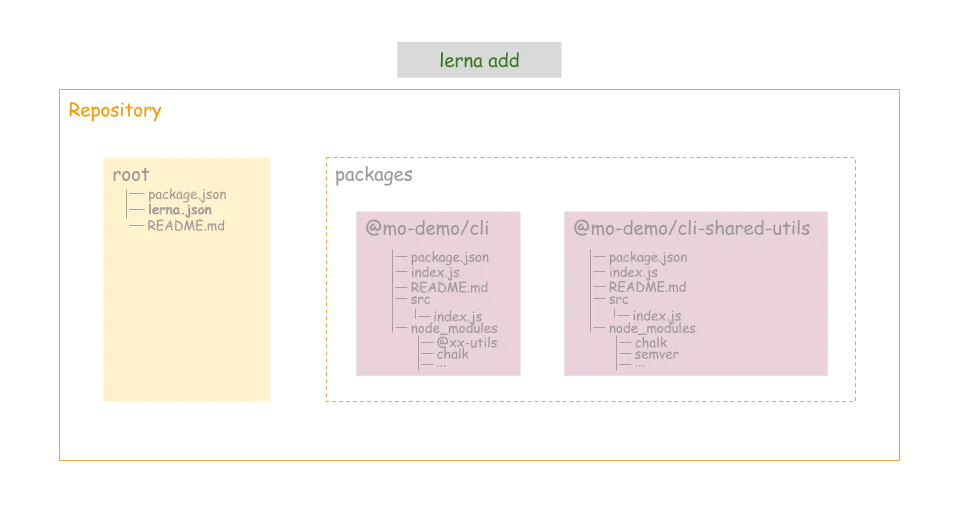
lerna create @mo-demo/cli
lerna create @mo-demo/cli-shared-utils
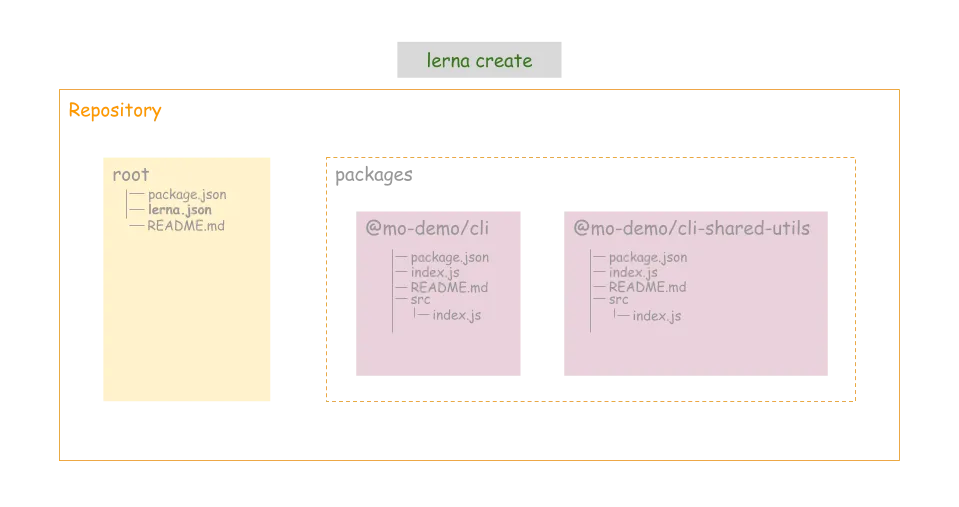
分别给相应的 package 增加依赖模块
lerna add chalk // 为所有 package 增加 chalk 模块
lerna add semver --scope @mo-demo/cli-shared-utils // 为 @mo-demo/cli-shared-utils 增加 semver 模块
lerna add @mo-demo/cli-shared-utils --scope @mo-demo/cli // 增加内部模块之间的依赖
发布
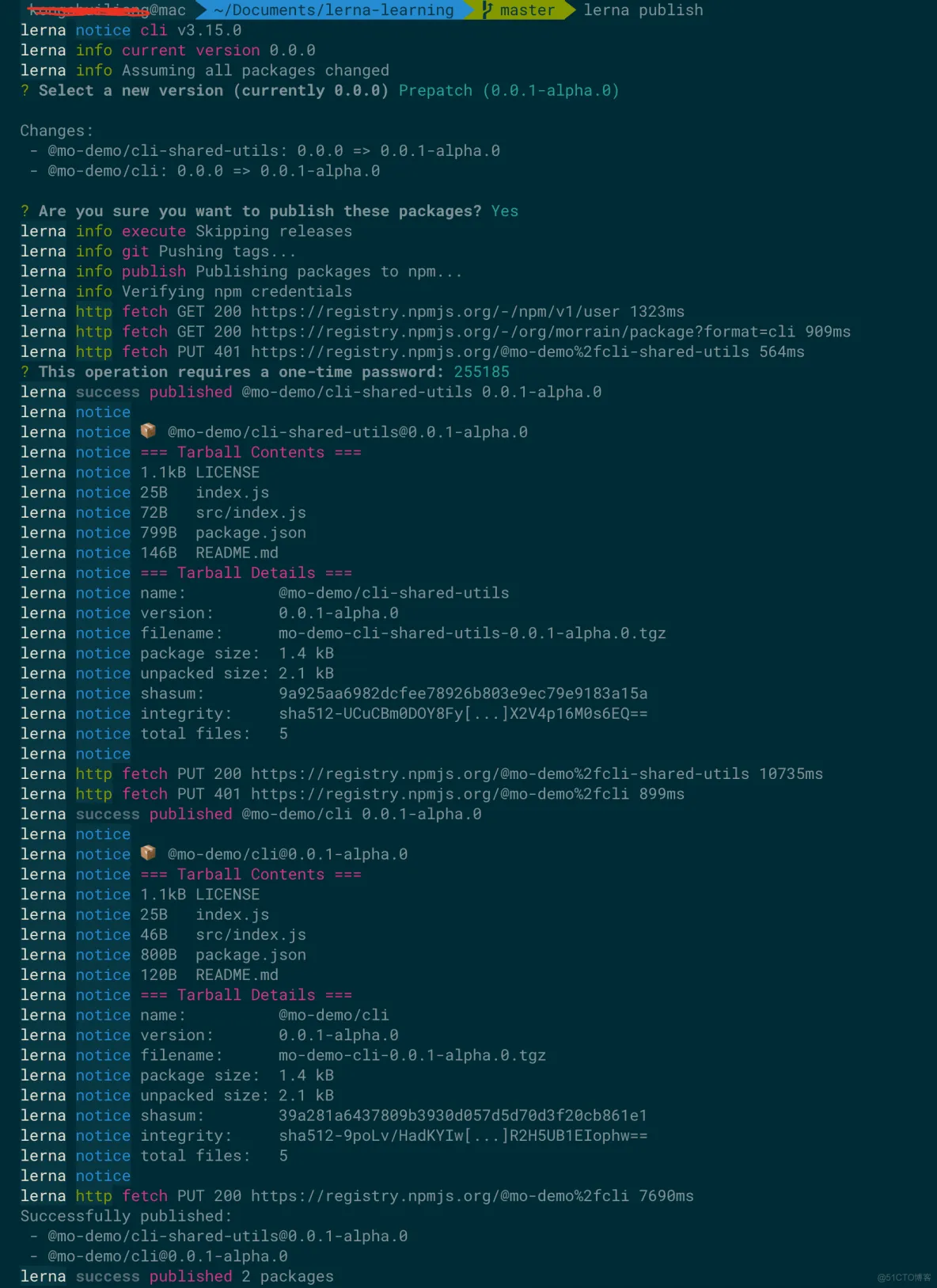
lerna publish
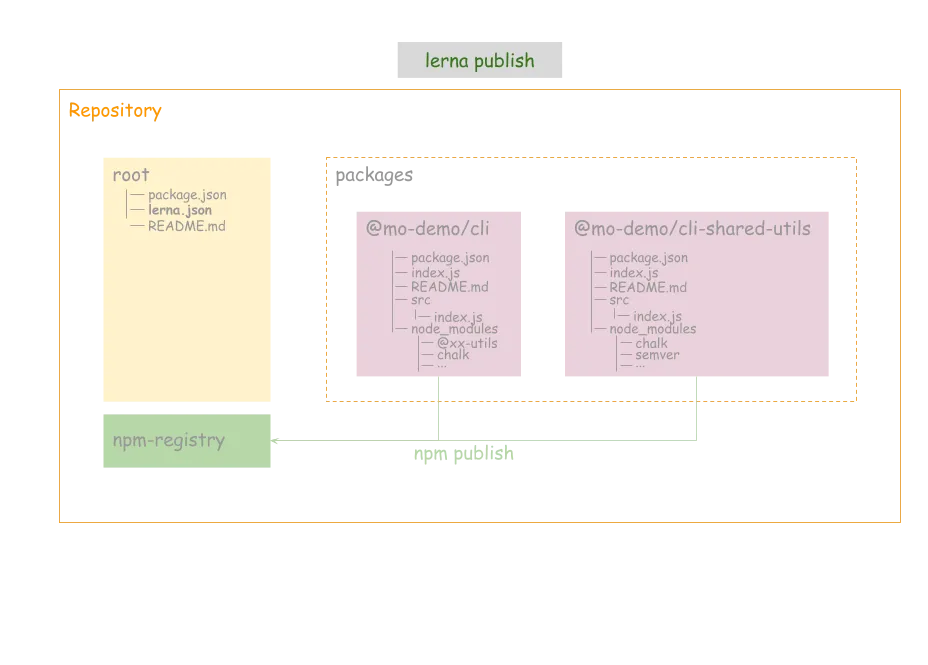
如下是发布的情况,lerna会让你选择要发布的版本号,我发了@0.0.1-alpha.0 的版本。
发布 npm 包需要登陆 npm 账号
安装依赖包 & 清理依赖包
上述1-4步已经包含了 Lerna 整个生命周期的过程了,但当我们维护这个项目时,新拉下来仓库的代码后,需要为各个 package 安装依赖包。
我们在第4步 lerna add 时也发现了,为某个 package 安装的包被放到了这个 package 目录下的 node_modules 目录下。这样对于多个 package 都依赖的包,会被多个 package 安装多次,并且每个 package 下都维护 node_modules ,也不清爽。于是我们使用 –hoist 来把每个 package 下的依赖包都提升到工程根目录,来降低安装以及管理的成本
lerna bootstrap --hoist
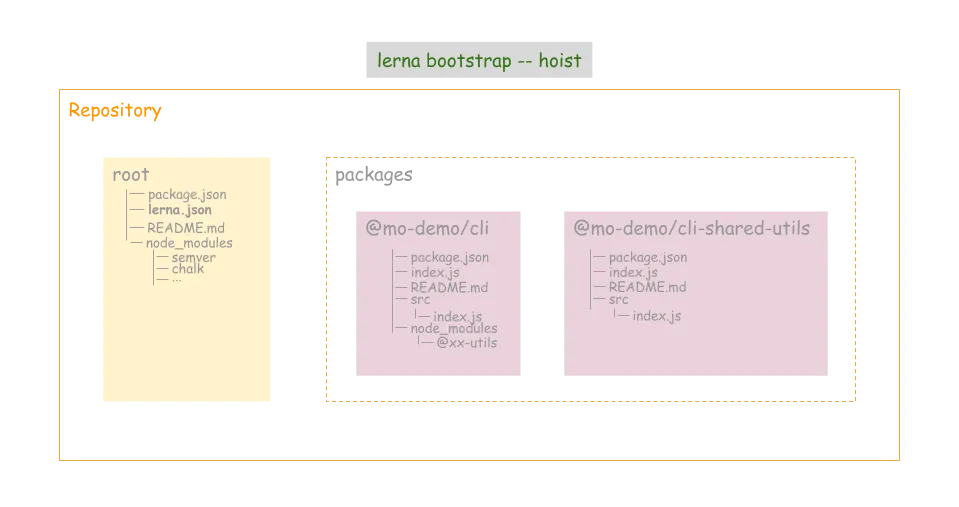
为了省去每次都输入 –hoist 参数的麻烦,可以在 lerna.json 配置:
{
"packages": [
"packages/*"
],
"command": {
"bootstrap": {
"hoist": true
}
},
"version": "0.0.1-alpha.0"
}
配置好后,对于之前依赖包已经被安装到各个 package 下的情况,我们只需要清理一下安装的依赖即可:
lerna clean
然后执行 lerna bootstrap 即可看到 package 的依赖都被安装到根目录下的 node_modules 中了。
优雅的提交
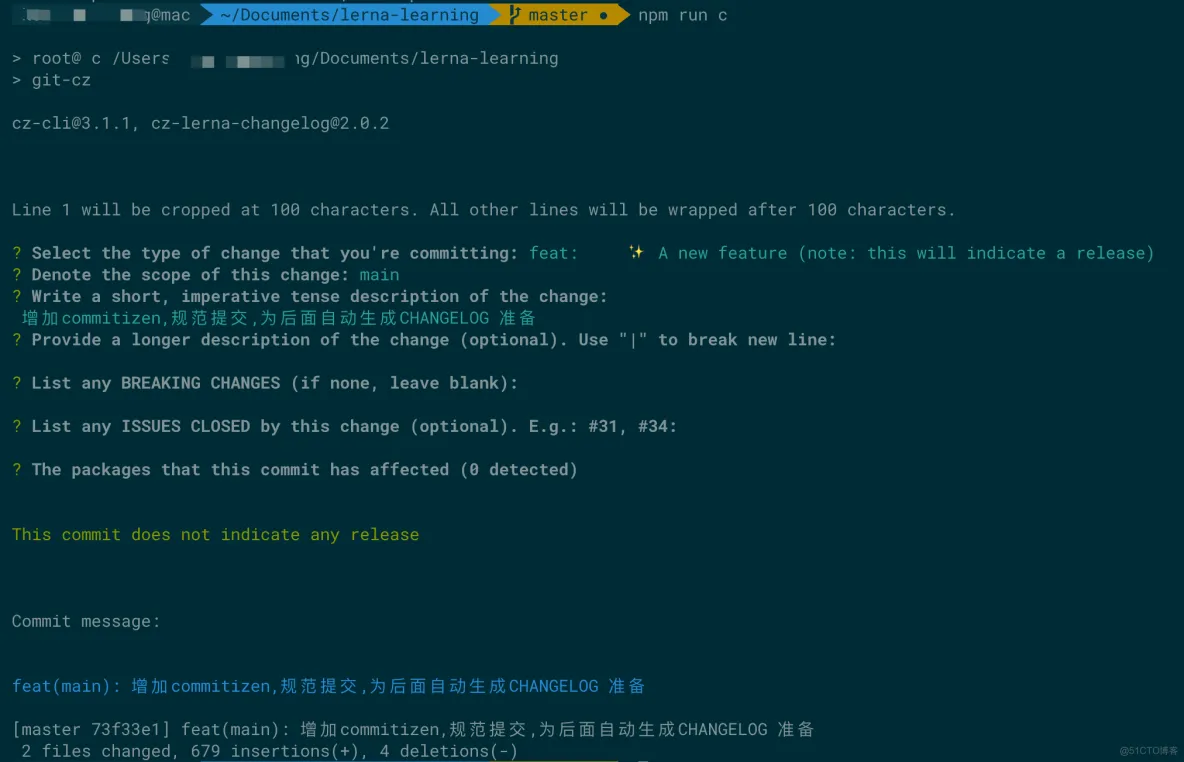
commitizen 是用来格式化 git commit message 的工具,它提供了一种问询式的方式去获取所需的提交信息。
cz-lerna-changelog 是专门为 Lerna 项目量身定制的提交规范,在问询的过程,会有类似影响哪些 package 的选择。如下:

我们使用 commitizen 和 cz-lerna-changelog 来规范提交,为后面自动生成日志作好准备。
因为这是整个工程的开发依赖,所以在根目录安装:
npm i -D commitizen
npm i -D cz-lerna-changelog
安装完成后,在 package.json 中增加 config 字段,把 cz-lerna-changelog 配置给 commitizen。同时因为commitizen不是全局安装的,所以需要添加 scripts 脚本来执行 git-cz
{
"name": "root",
"private": true,
"scripts": {
"c": "git-cz"
},
"config": {
"commitizen": {
"path": "./node_modules/cz-lerna-changelog"
}
},
"devDependencies": {
"commitizen": "^3.1.1",
"cz-lerna-changelog": "^2.0.2",
"lerna": "^3.15.0"
}
}
之后在常规的开发中就可以使用 npm run c 来根据提示一步一步输入,来完成代码的提交。
commitlint && husky
上面我们使用了 commitizen 来规范提交,但这个要靠开发自觉使用 npm run c 。万一忘记了,或者直接使用 git commit 提交怎么办?
答案就是在提交时对提交信息进行校验,如果不符合要求就不让提交,并提示。校验的工作由 commitlint 来完成,校验的时机则由 husky 来指定。husky 继承了 Git 下所有的钩子,在触发钩子的时候,husky 可以阻止不合法的 commit,push 等等。
// 安装 commitlint 以及要遵守的规范
npm i -D @commitlint/cli @commitlint/config-conventional
// 在工程根目录为 commitlint 增加配置文件 commitlint.config.js 为commitlint 指定相应的规范
module.exports = { extends: ['@commitlint/config-conventional'] }
// 安装 husky
npm i -D husky
// 在 package.json 中增加如下配置
"husky": {
"hooks": {
"commit-msg": "commitlint -E HUSKY_GIT_PARAMS"
}
}
“commit-msg”是git提交时校验提交信息的钩子,当触发时便会使用 commitlit 来校验。安装配置完成后,想通过 git commit 或者其它第三方工具提交时,只要提交信息不符合规范就无法提交。从而约束开发者使用 npm run c 来提交。
standardjs && lint-staged
除了规范提交信息,代码本身肯定也少了靠规范来统一风格。
standardjs就是完整的一套 JavaScript 代码规范,自带 linter & 代码自动修正。它无需配置,自动格式化代码并修正,提前发现风格以及程序问题。
lint-staged staged 是 Git 里的概念,表示暂存区,lint-staged 表示只检查并矫正暂存区中的文件。一来提高校验效率,二来可以为老的项目带去巨大的方便。
// 安装
npm i -D standard lint-staged
// package.json
{
"name": "root",
"private": true,
"scripts": {
"c": "git-cz"
},
"config": {
"commitizen": {
"path": "./node_modules/cz-lerna-changelog"
}
},
"husky": {
"hooks": {
"pre-commit": "lint-staged",
"commit-msg": "commitlint -E HUSKY_GIT_PARAMS"
}
},
"lint-staged": {
"*.js": [
"standard --fix",
"git add"
]
},
"devDependencies": {
"@commitlint/cli": "^8.1.0",
"@commitlint/config-conventional": "^8.1.0",
"commitizen": "^3.1.1",
"cz-lerna-changelog": "^2.0.2",
"husky": "^3.0.0",
"lerna": "^3.15.0",
"lint-staged": "^9.2.0",
"standard": "^13.0.2"
}
}
安装完成后,在 package.json 增加 lint-staged 配置,如上所示表示对暂存区中的 js 文件执行 standard –fix 校验并自动修复。那什么时候去校验呢,就又用到了上面安装的 husky ,husky的配置中增加’pre-commit’的钩子用来执行 lint-staged 的校验操作,如上所示。
此时提交 js 文件时,便会自动修正并校验错误。即保证了代码风格统一,又能提高代码质量。
自动生成日志
有了之前的规范提交,自动生成日志便水到渠成了。再详细看下 lerna publish 时做了哪些事情:
1.调用 lerna version

-
找出从上一个版本发布以来有过变更的 package
-
提示开发者确定要发布的版本号
-
将所有更新过的的 package 中的package.json的version字段更新
-
将依赖更新过的 package 的 包中的依赖版本号更新
-
更新 lerna.json 中的 version 字段
-
提交上述修改,并打一个 tag
-
推送到 git 仓库
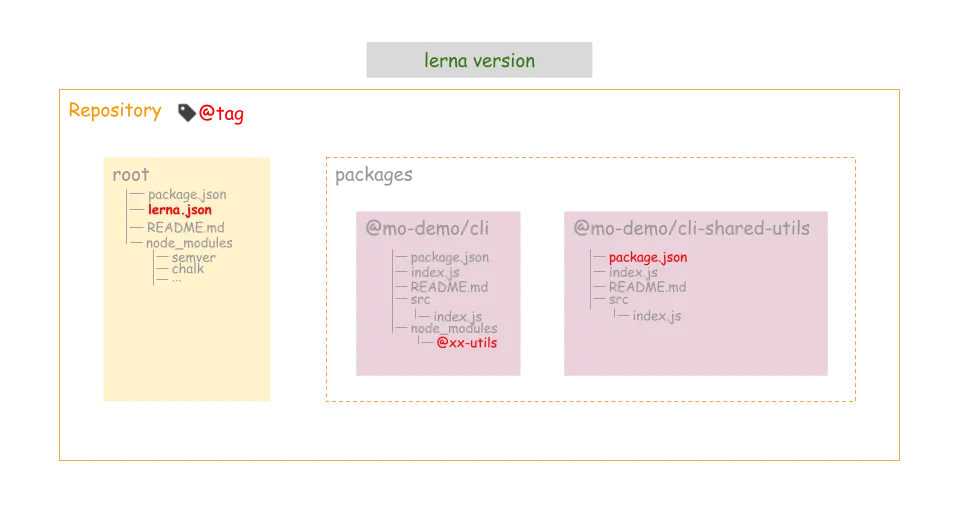
2.使用 npm publish 将新版本推送到 npm
CHANGELOG 很明显是和 version 一一对应的,所以需要在 lerna version 中想办法,查看 lerna version 命令的详细说明后,会看到一个配置参数 –conventional-commits。没错,只要我们按规范提交后,在 lerna version 的过程中会便会自动生成当前这个版本的 CHANGELOG。为了方便,不用每次输入参数,可以配置在 lerna.json中,如下:
{
"packages": [
"packages/*"
],
"command": {
"bootstrap": {
"hoist": true
},
"version": {
"conventionalCommits": true
}
},
"ignoreChanges": [
"**/*.md"
],
"version": "0.0.1-alpha.1"
}
lerna version 会检测从上一个版本发布以来的变动,但有一些文件的提交,我们不希望触发版本的变动,譬如 .md 文件的修改,并没有实际引起 package 逻辑的变化,不应该触发版本的变更。可以通过 ignoreChanges 配置排除。如上。

实际 lerna version 很少直接使用,因为它包含在 lerna publish 中了,直接使用 lerna publish就好了。
编译、压缩、调试
采用 Monorepo 结构的项目,各个 package 的结构最好保持统一。
根据目前的项目状况,设计如下:
1、各 package 入口统一为 index.js
2、各 package 源码入口统一为 src/index.js
3、各 package 编译入口统一为 dist/index.js
4、各 package 统一使用 ES6 语法、使用 Babel 编译、压缩并输出到 dist
5、各 package 发布时只发布 dist 目录,不发布 src 目录
6、各 package 注入 LOCAL_DEBUG 环境变量, 在index.js 中区分是调试还是发布环境,调试环境 ruquire(./src/index.js) 保证所有源码可调试。发布环境 ruquire(./dist/index.js) 保证所有源码不被发布。
接下来,我们按上面的规范,搭建 package 的结构。
首先安装依赖
npm i -D @babel/cli @babel/core @babel/preset-env // 使用 Babel 必备 详见官网用法
npm i -D @babel/node // 用于调试 因为用了 import&export 等 ES6 的语法
npm i -D babel-preset-minify // 用于压缩代码
由于各 package 的结构统一,所以类似 Babel 这样的工具,只在根目录安装就好了,不需要在各 package 中安装,简直是清爽的要死了。
增加 Babel 配置
// 根目录新建 babel.config.js
module.exports = function (api) {
api.cache(true)
const presets = [
[
'@babel/env',
{
targets: {
node: '8.9'
}
}
]
]
// 非本地调试模式才压缩代码,不然调试看不到实际变量名
if (!process.env['LOCAL_DEBUG']) {
presets.push([
'minify'
])
}
const plugins = []
return {
presets,
plugins,
ignore: ['node_modules']
}
}
修改各 package 的代码
// @mo-demo/cli/index.js
if (process.env.LOCAL_DEBUG) {
require('./src/index') // 如果是调试模式,加载src中的源码
} else {
require('./dist/index') // dist会发到npm
}
// @mo-demo/cli/src/index.js
import { log } from '@mo-demo/cli-shared-utils' // 从 utils 模块引入依赖并使用 log 函数
log('cli/index.js as cli entry exec!')
// @mo-demo/cli/package.json
{
"main": "index.js",
"files": [
"dist" // 发布 dist
]
}
// @mo-demo/cli-shared-utils/index.js
if (process.env.LOCAL_DEBUG) {
module.exports = require('./src/index') // 如果是调试模式,加载src中的源码
} else {
module.exports = require('./dist/index') // dist会发到npm
}
// @mo-demo/cli-shared-utils/src/index.js
const log = function (str) {
console.log(str)
}
export { //导出 log 接口
log
}
// @mo-demo/cli-shared-utils/package.json
{
"main": "index.js",
"files": [
"dist"
]
}
修改发布的脚本
npm run b 用来对各 pacakge 执行 babel 的编译,从 src 目录输出出 dist 目录,使用根目录的配置文件 babel.config.js。
npm run p 用来取代 lerna publish,在 publish 前先执行 npm run b来编译。
其它常用的 lerna 命令也添加到 scripts 中来,方便使用。
// 工程根目录 package.json
"scripts": {
"c": "git-cz",
"i": "lerna bootstrap",
"u": "lerna clean",
"p": "npm run b && lerna publish",
"b": "lerna exec -- babel src -d dist --config-file ../../babel.config.js"
}
结语
到这里,基本上已经构建了基于 Lerna 管理 packages 的 Monorepo 项目的最佳实践了,该有的功能都有:
-
完善的工作流
-
风格统一的编码
-
一键式的发布机制
-
完美的更新日志

当然,Lerna 还有更多的功能等待着你去发掘,还有很多可以结合 Lerna 一起使用的工具。构建一套完善的仓库管理机制,能在日常的工作中极大的提高工作效率,解放生产力,节省大量的人力成本。
实践过程中遇到问题
使用 monorepo 的模式的确解决了多仓库联调、基础建设复用等问题,但同时也带来了一些特有的问题。
幽灵依赖(Phantom dependencies)
问题:
npm/yarn 安装依赖时,存在依赖提升,某个项目使用的依赖,并没有在其 package.json 中声明,也可以直接使用,这种现象称之为 “幽灵依赖”;随着项目迭代,这个依赖不再被其他项目使用,不再被安装,使用幽灵依赖的项目,会因为无法找到依赖而报错。
举例:
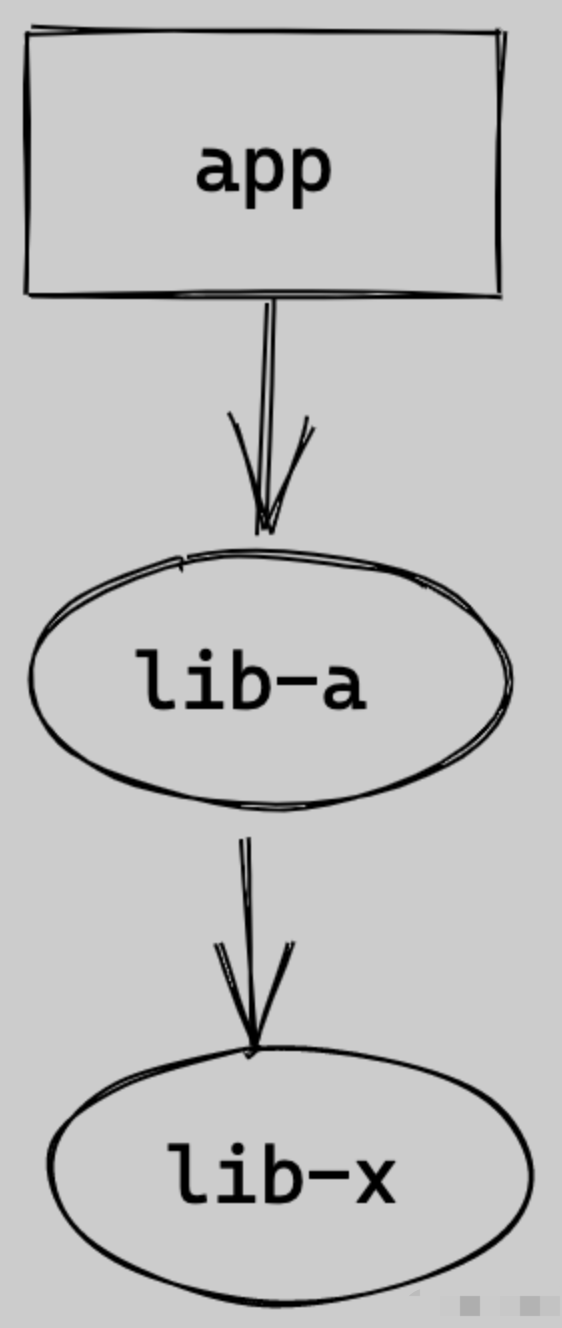
由于无法保证幻影依赖的版本正确性,给程序运行带来了不可控的风险。app 依赖了 lib-a,lib-a 依赖了 lib-x,由于依赖提升,我们可以在 app 中直接引用 lib-x,这并不可靠,我们能否引用到 lib-x,以及引用到什么版本的 lib-x 完全取决于 lib-a 的开发者。
方案:
幽灵依赖是一个比较常见的问题,容易导致线上问题是因为比较隐蔽,很难发现,出现问题也很难定位,所以我们需要从根源上杜绝幽灵依赖的问题。
导致问题发生的罪魁祸首就是 ”依赖提升“,所以我们只需要想办法解决掉它就可以了。
我们可以将包管理器换成 pnpm ,直接帮我们解决使用依赖但是不写到 dependencies 中的问题。
peerDependencies 错误
问题:
Yarn 依赖提升,在 peerDependencies 场景下可能导致 BUG。
举例:
1、app1 依赖 A@1.0.0
2、app2 依赖 B@2.0.0
3、B@2.0.0 将 A@2.0.0 作为 peerDependency,故 app2 也应该安装 A@2.0.0
若 app2 忘记安装 A@2.0.0,那么结构如下
--apps
--app1
--app2
--node_modules
--A@1.0.0
--B@2.0.0
此时 B@2.0.0 会错误引用 A@1.0.0。
编译时间变长
问题:
多个项目构建任务存在依赖时,往往是串行构建 或 全量构建,导致构建时间较长
举例:
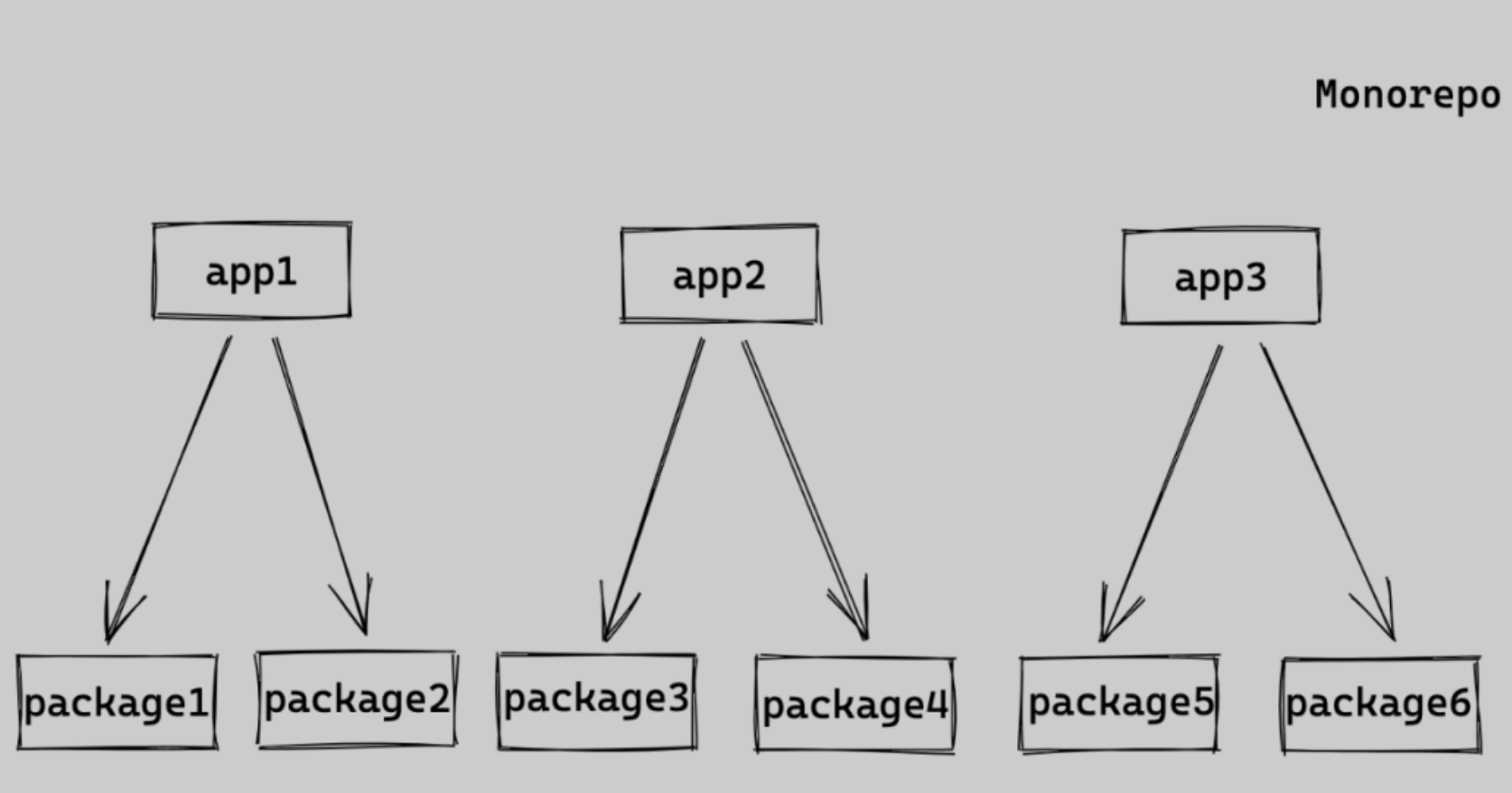
如果我们需要发布 app1,则会
1、全量安装依赖,app1、app2、app3 以及 package1 至 package6 的依赖都会被安装;
2、package 全部被构建,而非仅有 app1 依赖的 package1 与 package2 被构建。
方案:
增量构建,而非全量构建;也可以将串行构建,优化成并行构建。可以通过这两种方式降低构建时间:
1、按需构建减少需要构建的项目
编译时间变长主要是因为需要对所有项目进行构建,但是我们其实只需要构建变更的项目和被变更项目影响到的项目,也就是按需构建。
如果项目使用的是 lerna,那么就可以使用 yarn lerna:changed 找出所有需要构建的项目,然后只对这部分项目进行构建。
2、手动指定编译项目
当我们不需要将整个 monorepo 合并到主干分支前,我们可以只对需要构建的项目进行构建。我们可以在 commit body 中指定需要编译的项目,在 CI 脚本中对 commit body 进行识别,从而只进行单个项目的构建。
当需要合并的主干分支时,再对整个项目进行构建,只有所以项目都完成 CI 构建 & 校验,才能被合并到主干分支。
依赖安装时间变长
问题:
MonoRepo 中每个项目都有自己的 package.json 依赖列表,随着 MonoRepo 中依赖总数的增长,每次 install 时,耗时会较长。
方案:
相同版本依赖提升到 Monorepo 根目录下,减少冗余依赖安装;使用 pnpm 按需安装及依赖缓存。
Git 记录混乱
问题:
因为所有人的 commit 在 monorepo 里都在一个线性历史里面,所以很乱。如果团队内没有对 commit 信息进行规范强制校验的话,就会导致项目的 commit 信息直接废弃。
方案:
想解决这个问题就需要团队定义好 commit 规则,加上 Git Hooks 做好前置校验即可。
不过即使做了规范化的处理,也顶不住异常多的 commit 记录,所以建议使用可视化工具去看 Git 记录。例如笔者使用的就是 IDE 自带的 Git 工具。
项目隐私性和安全性的问题
问题:
如果 monorepo 采用单个仓库,那么所有项目的代码对该仓库的所有开发者都是可见的,如果希望对某一个项目施加细粒度的权限控制,采用单仓库是很难实现的。所以如果你的项目需要做保密处理,那么就需要谨慎选择使用 monorepo。
IDE 卡顿
问题:
实话实说,使用 monorepo 之后,我的电脑只有四个字:“芜湖起飞”,因为我习惯使用 WebStorm / IDEA 来开发项目,众所周知 JetBrains 家的 IDE 是真的吃性能,而我们的代码仓库又实在太大了,约几十个项目,且每个项目的代码量都不小。
方案:
如果你也使用的是 IDEA 可以通过 exclude 不需要关注的项目来减缓这个问题,或者只打开自己需要开发的项目。想要彻底解决这个问题的话,建议直接换成 M1 的 Mac。