http压缩方式gzip、brotli比较
压缩原理
信息熵:数据为何是可以压缩的,因为数据都会表现出一定的特性,称为熵。绝大多数的数据所表现出来的容量往往大于其熵所建议的最佳容量。比如所有的数据都会有一定的冗余性,我们可以把冗余的数据采用更少的位对频繁出现的字符进行标记,也可以基于数据的一些特性基于字典编码,代替重复多余的短语
压缩原理其实很简单,就是找出那些重复出现的字符串,然后用更短的符号代替, 从而达到缩短字符串的目的。比如,有一篇文章大量使用”中华人民共和国”这个词语, 我们用”中国”代替,就缩短了 5 个字符,如果用”华”代替,就缩短了6个字符。事实上, 只要保证对应关系,可以用任意字符代替那些重复出现的字符串
本质上,所谓”压缩”就是找出文件内容的概率分布,将那些出现概率高的部分代替成更短的形式。所以:
1、内容越是重复的文件,就可以压缩地越小。比如,”ABABABABABABAB”可以压缩成”7AB”
2、相应地,如果内容毫无重复,就很难压缩。极端情况就是,遇到那些均匀分布的随机字符串,往往连一个字符都压缩不了。比如,任意排列的10个阿拉伯数字 (5271839406),就是无法压缩的;再比如,无理数(比如π)也很难压缩
HTTP压缩
所有的现代浏览器以及服务器都支持压缩技术,唯一需要协商的是所采用的压缩算法。
为了选择采用的压缩算法,HTTP客户端和服务器之间会使用主动协商机制,HTTP客户端发送 Accept-Encoding 首部,(其中包含它所支持的压缩算法,以及各自的优先级)服务器则从中选择一种,使用该算法对响应的消息主体进行压缩,并且发送 Content-Encoding 首部来告知HTTP客户端它选择了哪一种算法。
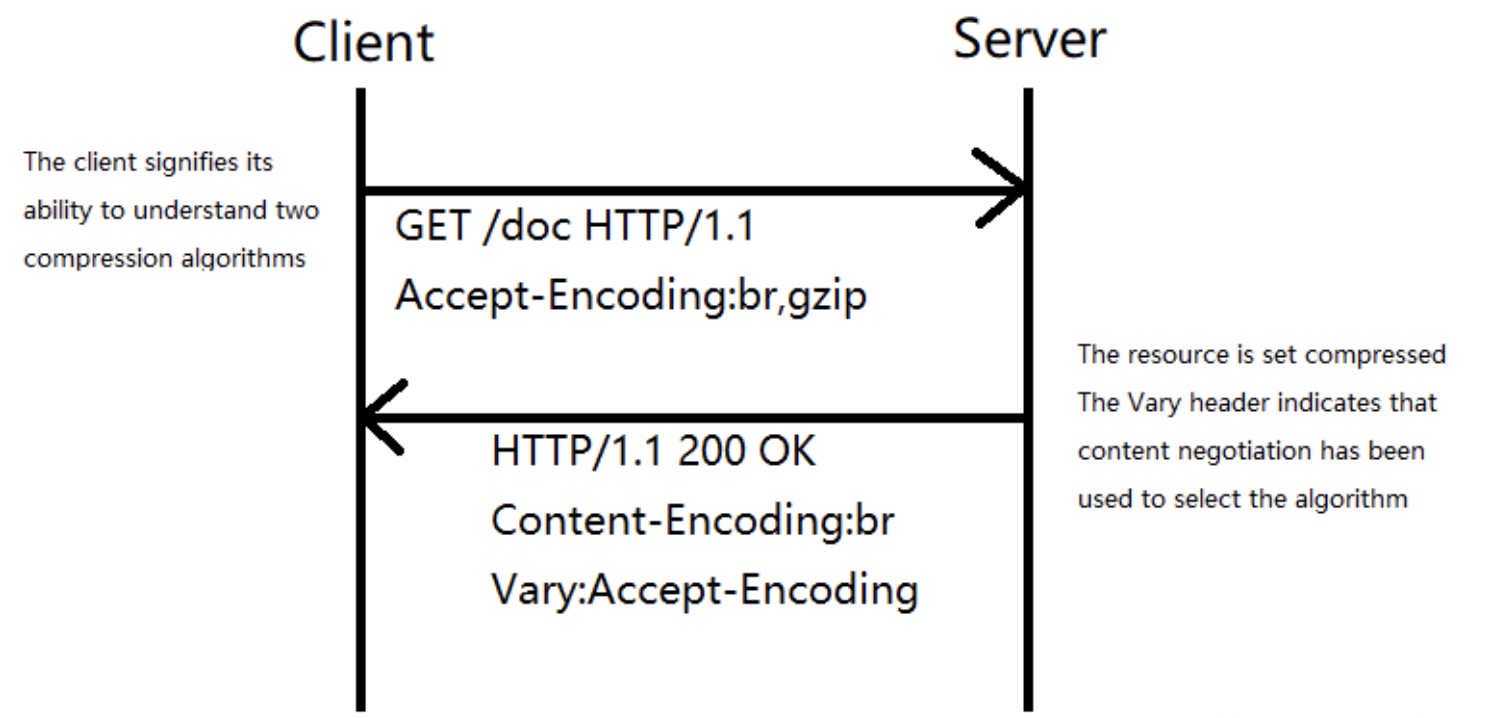
虽然各种压缩算法适用于不同场景,但是它们的底层都是基于 DEFLATE。DEFLATE 是同时使用了 LZ77 算法与哈夫曼编码(Huffman Coding)的一种无损数据压缩算法。在应用具体的 Gzip 或 Brotli 等方案之前我们先了解这两种压缩算法的基本原理。
LZ77 算法
Ziv和Lempel于1977年发表题为“顺序数据压缩的一个通用算法(A Universal Algorithm for Sequential Data Compression )。LZ77 压缩算法采用字典的方式进行压缩, 是一个简单但十分高效的数据压缩算法。其方式就是把数据中一些可以组织成短语(最长字符)的字符加入字典,然后再有相同字符出现采用标记来代替字典中的短语,如此通过标记代替多数重复出现的方式以进行压缩
关键词术语
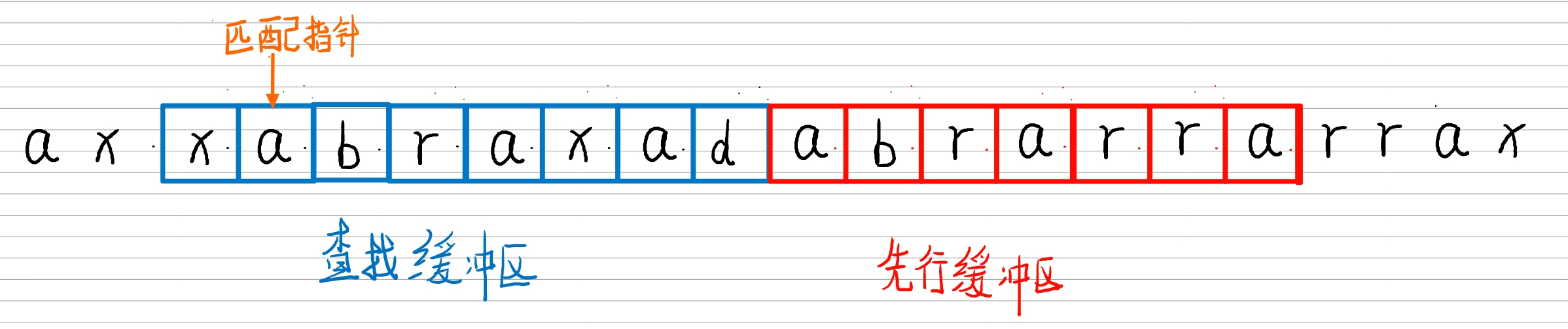
前向缓冲区:每次读取数据的时候,先把一部分数据预载入前向缓冲区。为移入滑动窗口做准备,大小可以自己设定
滑动窗口:一旦数据通过缓冲区,那么它将移动到滑动窗口中,并变成字典的一部分。滑动窗口的大小也可以自己设定的
短语字典:从字符序列 S1…Sn,组成n个短语。比如字符(A,B,D),可以组合的短语为 {(A),(A,B),(A,B,D),(B),(B,D),(D)},如果这些字符在滑动窗口里面,就可以记为当前的短语字典,因为滑动窗口不断的向前滑动,所以短语字典也是不断的变化
基本原理
我们平时使用的文件总是会有很多重复的部分, LZ77 压缩算法正是利用了这一点. 它会试图尽可能地找出文件中重复的内容, 然后用一个标记代替重复的部分, 这个标记能够明确地指示这部分在哪里出现过. 举个例子, 以 葛底斯堡演说 的第一段为例:
Four score and seven years ago our fathers brought forth, on this continent, a new nation, conceived in Liberty, and dedicated to the proposition that all men are created equal.
我们可以找出不少重复的片段. 我们规定, 只要有两个以上的字符与前文重复, 就使用重复标记 <d,l> 代替它。 <d,l> 表示这个位置的字符串等价与 d 个字符前, 长度为 l 的字符串. 于是上面的内容就可以表示为:
Four score and seven years ago <30,4>fathe<16,3>brought forth, on this continent, a new nation,<25,4>ceived in Liberty<36,3><102,3>dedicat<26,3>to<69,3>e proposi<56,4><85,3>at all m<138,3>a<152,3>cre<44,5>equal.
呃, 你可能已经发现了这样 “压缩” 后的结果比原文还长. 别急, 这只是个演示, 稍后我们能看到如何解决这个问题.
实现这个算法最简单的方式就是遍历字符串, 对于每个字符都在前文中顺序查找是否有重复的字符, 然后求出最长重复子串. 这种做法时间复杂度为 O(n^2), 效率较低, 特别是在处理大文件的时候. 为了提高效率, 我们使用哈希表和滑动窗口优化.
使用哈希表
顺序查找过于缓慢, 我们可以使用哈希表来提升效率. 我们使用一个哈希表把一个长度为三的字符串映射成一个列表, 包含这个字符串所有曾经出现过的位置. 压缩时从头到尾扫描字符串. 假设接下来的三个字符为 XYZ, 首先检查字符串 XYZ 是否在哈希表中. 如果不在, 则原样输出字符 X 并移动到下一个字符. 否则把当前位置开始的字符串与所有 XYZ 出现过的位置开始的字符串相比较, 寻找出一个长度为 N 的最长的匹配并输出重复标记, 然后向后移动 N 个字符. 无论能否在哈希表中找到匹配, 都会把当前位置插入到 XYZ 在哈希表映射的列表中.
举个例子, 考虑字符串 abcabcdabcde, 算法运行时有以下几步:
1、扫描到第 0 个字符 a, 哈希表为空, 原样输出字符 a, 并且将字符串 abc 插入哈希表中.
hash table: {}
abcabcdabcde
^
output: a
2、扫描到第 3 个字符 a, 哈希表指示 abc 在 0 处出现过. 最长的匹配就是 abc, 因此输出 <3,3>. 同时把当前位置插入到 abc 映射的列表中.
hash table: {"abc":[0],"bca":[1],"cab":[2]}
abcabcdabcde
^
output: abc<3,3>
3、扫描到第 7 个字符 a, 哈希表指示 abc 在 0, 3 处出现过. 依次与当前位置匹配, 0 处只能匹配到 abc, 而 3 处能匹配到 abcd, 最长的匹配为 abcd, 于是输出 <4,4>. 同时把当前位置插入到 abc 映射的列表中.
hash table: {"abc":[0,3],"bca":[1],"cab":[2],"bcd":[4],"cda":[5],"dab":[6]}
abcabcdabcde
^
output: abc<3,3>d<4,4>
滑动窗口
即使有了哈希表, 过长的文件仍然会导致效率问题. 为此我们使用滑动窗口, 查找重复内容时仅在窗口中查找. 窗口的长度是固定的, 通常是 32KB. 在 zlib 的实现中, 使用一个两倍窗口大小的缓冲区, 如下所示:
|-------search-------+------lookahead-----|
^
初始时将待压缩数据填入缓冲区, 指针位于缓冲区的开始处; 随后指针向后扫描, 对数据进行压缩. 我们把指针扫描过的的部分称为 search 区, 未扫描过的部分称为 lookahead 区. 对于每个扫描的字符, 算法都只会在 search 区中寻找匹配. 当 lookahead 区长度不足(小于一个固定值)时, 算法就会移动窗口以继续扫描更多的数据. 具体的做法时将缓冲区后半部分的数据复制到前半部分并移动指针, 然后在缓冲区的后半部分读入新数据, 接着还要更新哈希表, 因为数据的位置发生了改变.
惰性匹配(lazy matching)
有的时候这种策略并不能得到最优的压缩结果. 举个例子, 考虑字符串 abcbcdabcda, 当扫描到第 6 个字符的时候是这样的:
hash table: {"abc":[0],"bcb":[1],"cbc":[2],"bcd":[3],"cda":[4],"dab":[5]}
abcbcdabcda
^
output: abcbcd<6,3>
哈希表指示 abc 在 0 处出现过, 最长匹配为 abc, 于是输出 <6,3>; 后面的 da 没有与之重复的内容, 原样输出. 因此压缩的结果是 abcbcd<6,3>da. 然而在第 7 个字符的位置能在前文找到一个更长的匹配 bcda, 更好的压缩结果应该是 abcbcda<4,4>.
为了解决这个问题, DEFLATE 采用一叫做惰性匹配的策略优化. 每当算法找到一个长度为 N 的匹配后, 就会试图在下一个字符寻找更长的匹配. 只有当没有找到更长的匹配时, 才为当前匹配输出重复标记; 否则就会丢弃当前匹配, 使用更长的匹配. 注意惰性匹配可以连续触发, 如果一次惰性匹配发现了更长的匹配, 仍会继续进行惰性匹配, 直到无法在下一个字符找到更长匹配为止.
惰性匹配能够提高压缩率, 但是会让压缩变慢. 运行时的参数会控制惰性匹配, 只有在当前匹配不够长, i.e. 小于某个配置的值的时候, 才会触发惰性匹配. 可以根据需求是压缩率优先还是速度优先来调整这个值, 或者关闭惰性匹配.
优缺点
大多数情况下LZ77压缩算法的压缩比相当高,当然了也和你选择滑动窗口大小, 以及前向缓冲区大小,以及数据熵有关系
缺点:其压缩过程是比较耗时的,因为要花费很多时间寻找滑动窗口中的短语匹配
优点:不过解压过程会很快,因为每个标记都明确告知在哪个位置可以读取了
Huffman 霍夫曼编码
如果我们真的使用 <d,l> 这样的格式表示重复的内容, 那就太愚蠢了. 首先是这样的格式太占空间了, 使用这种方式 “压缩” 甚至原文还长. 其次这种格式让尖括号变成了特殊字符, 还得设法转义它们. 那么应该如何表示重复部分距离和长度呢? 使用 Huffman 编码对数据重新编码.
哈夫曼设计了一个贪心算法来构造最优前缀码,被称为哈夫曼编码(Huffman code), 其正确性证明依赖于贪心选择性质和最优子结构。哈夫曼编码可以很有效的压缩数据,具体压缩率依赖于数据本身的特性 这里我们先介绍几个概念:
1、码字:每个字符可以用一个唯一的二进制串表示,这个二进制串称为这个字符的码字
2、码字长度:这个二进制串的长度称为这个码字的码字长度
3、定长编码:码字长度固定就是定长编码。
4、变长编码:码字长度不同则为变长编码。
变长编码可以达到比定长编码好得多的压缩率,其思想是赋予高频字符(出现频率高的字符)短(码字长度较短)码字,赋予低频字符长码字。例如,我们 用 ASCII 字符编辑一个文本文档,不论字符在整个文档中出现的频率,每个字符都要占 用一个字节。如果我们使用变长编码的方式,每个字符因在整个文档中的出现频率不同导致码字长度不同,有的可能占用一个字节,而有的可能只占用一比特,这个时候,整 文档占用空间就会比较小了。当然,如果这个文本文档相当大,导致每个字符的出现频率基本相同,那么此时所谓变长编码在压缩方面的优势就基本不存在了
前缀编码
为什么每个字符占的位数都不同却能明确地区分它们呢? 这就是前缀编码的作用. 为了说明什么是前缀编码, 试想我们在打电话. 电话号码的长度是不一样的: 有三位的, 如 110, 119; 有五位的, 如 10086, 10010; 有 7 位或 8 位的固定电话, 又有 11 位的手机号码等等. 然而拨号的时候依次输入号码, 总能正确识别 (固定电话摘机拨号无需按呼叫键). 这是因为除了匪警 110 之外不会有任何一个电话号码以 110 开头, 任何一个固定电话号都不可能是某个手机号的前缀. 电话号码就是一种前缀编码. 所以, 虽然 Huffman 编码中每个字符的编码位数都不同, 但是短的编码不会是长的编码的前缀. 这样就保证了 Huffman 编码没有歧义.
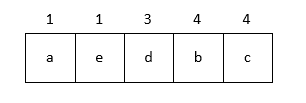
我们使用 Huffman 树构造 Huffman 编码. 前文说了, Huffman 编码有长有短, 那么显然让使用频率高的字符编码短, 使用频率高的字符编码长比较合理. 假设我们要对字符 a, b, c, d, e 进行编码, 它们的使用频率如下表所示:
| character | times |
|---|---|
| a | 1 |
| b | 4 |
| c | 4 |
| d | 3 |
| e | 1 |
构造方式非常简单. 我们把字符的出现频率视为优先级, 放入一个最小优先队列中:
然后弹出两个优先级最低的字符作为子节点, 构造出第一个二叉树; 父节点的优先级视为两个字节优先级之和, 然后把父节点插入队列中:
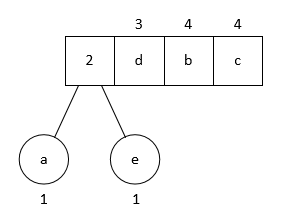
重复这个操作, 最后我们会得到一颗二叉树. 这便是 Huffman 树.
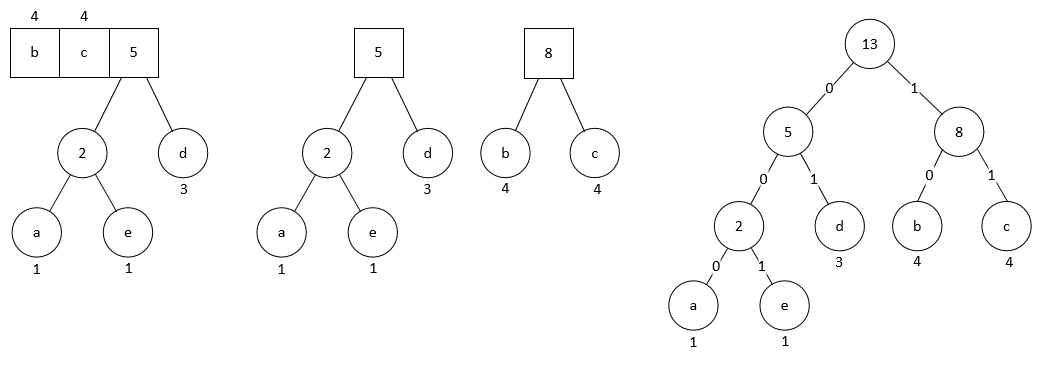
我们把这棵树的左支编码为 0, 右支编码为 1, 那么从根节点向下遍历到叶子节点, 即可得出相应字符的 Huffman 编码. 因此我们得到上面例子的 Huffman 编码表为:
| character | code |
|---|---|
| a | 000 |
| b | 10 |
| c | 11 |
| d | 01 |
| e | 001 |
假设有字符串 badbec, 使用 Huffman 编码后得到 10000011000111. 解码也很简单, 依次读入每个比特, 利用 Huffman 树, 自根节点开始逢 0 向左逢 1 向右, 到达叶子节点即输出相应的字符, 然后回到根节点继续扫描.
对距离和长度进行编码
一个字节有 8 位, 因此我们需要 0 至 255 一共 256 个 Huffman 编码. 统计文件各个字符的使用频率, 构造出 Huffman 树即可计算出这 256 个编码. 那么如何用 Huffman 编码表示重复标记中的距离和长度呢? DEFLATE 算法是这样做的:
1、对于距离, 它有 0 至 29 一共 30 个编码. 距离编码的含义如下表所示:
| code | extra | distance | code | extra | distance | code | extra | distance |
|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 1 | 10 | 4 | 33-48 | 20 | 9 | 1025-1536 |
| 1 | 0 | 2 | 11 | 4 | 49-64 | 21 | 9 | 1537-2048 |
| 2 | 0 | 3 | 12 | 5 | 65-96 | 22 | 10 | 2049-3072 |
| 3 | 0 | 4 | 13 | 5 | 97-128 | 23 | 10 | 3073-4096 |
| 4 | 1 | 5,6 | 14 | 6 | 129-192 | 24 | 11 | 4097-6144 |
| 5 | 1 | 7,8 | 15 | 6 | 193-256 | 25 | 11 | 6145-8192 |
| 6 | 2 | 9-12 | 16 | 7 | 257-384 | 26 | 12 | 8193-12288 |
| 7 | 2 | 13-16 | 17 | 7 | 385-512 | 27 | 12 | 12289-16384 |
| 8 | 3 | 17-24 | 18 | 8 | 513-768 | 28 | 13 | 16385-24576 |
| 9 | 3 | 25-32 | 19 | 8 | 769-1024 | 29 | 13 | 24577-32768 |
每个编码都表示一个或多个距离. 当它表示多个距离时, 意味着接下来会有 extra 位表示具体的距离是多少. 例如假设编码 14 接下来的 6 位为 011010, 则表示距离为 129 + 0b011010 = 129 + 26 = 155. 这样距离编码能表示的距离范围为 1 至 32768.
2、对于长度, 它与普通字符共用同一编码空间. 这个编码空间一共有 286 个编码, 范围是从 0 至 285. 其中 0 至 255 为普通字符编码, 256 表示压缩块的结束; 而 257 至 285 则表示长度. 长度编码的含义如下表所示:
| code | extra | length(s) | code | extra | length(s) | code | extra | length(s) |
|---|---|---|---|---|---|---|---|---|
| 257 | 0 | 3 | 267 | 1 | 15,16 | 277 | 4 | 67-82 |
| 258 | 0 | 4 | 268 | 1 | 17,18 | 278 | 4 | 83-98 |
| 259 | 0 | 5 | 269 | 2 | 19-22 | 279 | 4 | 99-114 |
| 260 | 0 | 6 | 270 | 2 | 23-26 | 280 | 4 | 115-130 |
| 261 | 0 | 7 | 271 | 2 | 27-30 | 281 | 5 | 131-162 |
| 262 | 0 | 8 | 272 | 2 | 31-34 | 282 | 5 | 163-194 |
| 263 | 0 | 9 | 273 | 3 | 35-42 | 283 | 5 | 195-226 |
| 264 | 0 | 10 | 274 | 3 | 43-50 | 284 | 5 | 227-257 |
| 265 | 1 | 11,12 | 275 | 3 | 51-58 | 285 | 0 | 258 |
| 266 | 1 | 13,14 | 276 | 3 | 59-66 |
与距离编码类似, 每个编码都表示一个或多个长度, 表示多个长度时后面会有 extra 位指示具体的长度. 长度编码能表示的长度范围为 3 至 258.
解压时, 当读到编码小于等于 255, 则认为这是个普通字符, 原样输出即可; 若在 257 至 285 之间, 则说明遇到了一个重复标记, 这意味着当前编码表示的是长度, 且下一个编码表示的是距离. 解码得到长度和距离, 再在解压缓冲区中找到相应的部分输出即可; 若为 256, 则说明压缩块结束了.
Huffman 编码表的存储
我们知道, Huffman 编码是根据字符的出现频率构造的. 不同的文件字符出现的频率都不同, 因此 Huffman 编码也不同. 为了能够正确地解压, 压缩块中还必须存储 Huffman 编码表. 这一节我们来讨论如何用最小的空间存储这个 Huffman 编码表.
将 Huffman 编码表表示为长度序列
为了高效地存储 Huffman 编码表, DEFLATE 算法规定, Huffman 树的每一层的叶子节点必须从这一层的最左侧开始, 按照 Huffman 编码的数值大小从小到大依次排列; 内部节点排列在随后. 此外同一层的字符应该按照字符表(如 ASCII 码表)的顺序依次排列. 这样上面内容中的 Huffman 树就应该调整为:
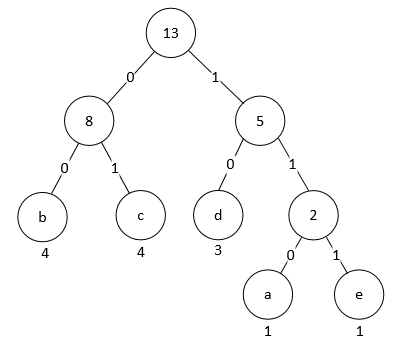
调整后的 Huffman 编码表就是:
| character | code |
|---|---|
| a | 110 |
| b | 00 |
| c | 01 |
| d | 10 |
| e | 111 |
注意调整后的 Huffman 编码并不影响压缩率: 各个字符编码的长度不变, 最常用的字符的编码仍是最短的. 不难发现, 相同长度的编码都是依次递增的, 且某个长度的编码的最小值取决于上个长度的编码的最小值和数量. 现设长度为i的编码的最小值为 m[i], 有n[i]个; 又设长度为 0 的编码的最小值为 0, 有 0 个. 那么易得
m[i+1] = (m[i] + n[i]) << 1
这里的 “«” 表示左移. 这样, 我们只需要知道每个字符的 Huffman 编码长度, 即可推算出所有字符的 Huffman 编码了. 对如上面的例子, 我们只需存储长度序列 <3,2,2,2,3>即可. 解压时扫描这个序列, 得到各个长度的编码的数量, 即可求算出各个长度的编码的最小值; 相同长度的编码都是依次递增的, 所以依次加一, 即可得出所有字符的 Huffman 编码. 特别地, 长度 0 表示这个字符没有在压缩块中出现过, 构造 Huffman 编码的时候会排除它.
对长度序列编码
长度序列中很容易出现连续重复的值; 并且由于文件中可能有很多未使用的字符, 也会出现很多 0. 因此会对这个长度序列编码, 如下所示:
| code | meaning |
|---|---|
| 0-15 | 表示长度 0 至 15 |
| 16 | 前面的长度重复 3 到 6 次. 接下来的两位指示具体重复多少次, 这与 3.2 节中的长度和距离编码类似. |
| 17 | 长度 0 重复 3 至 10 次. 接下来的 3 位指示具体重复多少次. |
| 18 | 长度 0 重复 11 至 138 次. 接下来的 7 位指示具体重复多少次. |
使用 Huffman 编码压缩 Huffman 编码表
将 Huffman 编码表表示成编码后的长度序列已经比较精简了, 但是这还不够. 还可以对这个编码后的长度序列再次使用 Huffman 编码压缩. 这一步就有一点点绕了. 为了做到这一点, 我们需要为长度序列的编码 – – 0 至 18, 构造 Huffman 编码表(然而这个长度序列表示的就是一个 Huffman 编码表, 等于我们是在为一个 Huffman 编码表构造 Huffman 编码表). 问题来了, 怎么表示这个 Huffman 编码表的 Huffman 编码表呢? 首先,定义一个数组:
A={16,17,18,0,8,7,9,6,10,5,11,4,12,3,13,2,14,1,15}
因为有可能不是所有的长度都能用上, 因此我们会先用一个数字标识使用这个数组中的前 k 个编码. 例如长度序列编码只使用了 2, 3, 4, 16, 17, 则 k = 16. 接下来会有 k 个数字, 第 i个数字表示长度序列编码 A[i]的 Huffman 编码的长度, 0 表示相应的编码未使用. 因为只要知道了每个字符的 Huffman 编码长度, 就能推算出所有字符的 Huffman 编码. 这样我们就得到了编码后的长度序列的 Huffman 编码表.
在压缩数据中先存储编码后的长度序列的 Huffman 编码表, 紧接着再存储编码后的长度序列的 Huffman 编码数据. 这样我们就在压缩块中用较小的空间存储了压缩数据的 Huffman 编码表.
Deflate压缩算法
deflate压缩算法用在很多地方:zip、7z, xz 等压缩文件。gzip压缩算法、zlib压缩算法等都是对defalte压缩算法的封装;
gzip、zlib等压缩程序都是无损压缩,因此对于文本的压缩效果比较好,对视频、图片等压缩效果不是很好(视频一般都是采用有损压缩算法),所以对于视频、图片这种已经是二进制形式的文件可以不需要压缩,因为效果也不是很明显。
实际上deflate只是一种压缩数据流的算法。 任何需要流式压缩的地方都可以,Deflate压缩算法=LZ77算法+哈夫曼编码,deflate算法下的压缩器有三种压缩模型:
1、不压缩数据,对于已经压缩过的数据,这是一个明智的选择。 这样的数据会会稍稍增加,但是会小于在其上再应用一种压缩算法
2、静态压缩,先用LZ77压缩,然后用huffman编码。 在这个模型中压缩的树是Deflate规范规定定义的, 所以不需要额外的空间来存储这个树
3、动态压缩,先用LZ77压缩,然后用huffman编码。 压缩树是由压缩器生成的,并与数据 一起存储
数据被分割成不同的块,每个块使用单一的压缩模式。 如过压缩器要在这三种压缩模式中相互切换,必须先结束当前的块,重新开始一个新的块
gzip
概况
GZIP是GNU Zip的缩写,是网络上最流行的无损数据压缩方法。它允许您减小站点的HTML页面、样式表和脚本的大小。
GZIP不仅是一种数据压缩算法,也是一种文件扩展名(.gz)和一种用于文件压缩/解压的软件。
它基于DEFLATE算法,它是LZ77编码和霍夫曼编码算法的混合体。重复度越高的文件可压缩的空间就越大。

GZIP压缩器获取一组原始数据并对其进行无损压缩。原始数据可以来自任何文件类型,但GZIP最适用于基于文本的资产(例如HTML、CSS、JS)。
工作原理
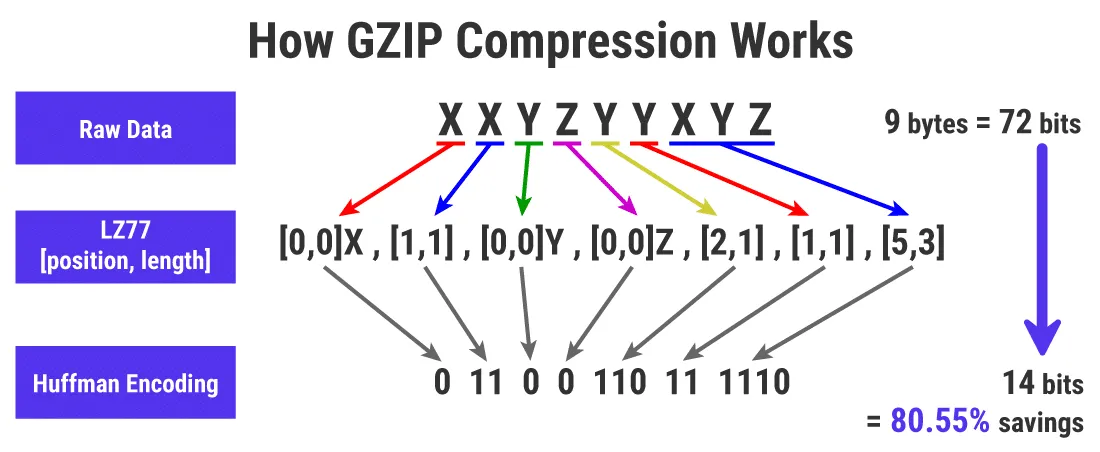
首先,GZIP压缩器对原始数据运行LZ77压缩算法以消除冗余。该算法通过在预定义的滑动窗口(原始数据的一小部分)中查找重复模式来工作。
然后用元组替换所有重复的字符串以压缩原始数据。
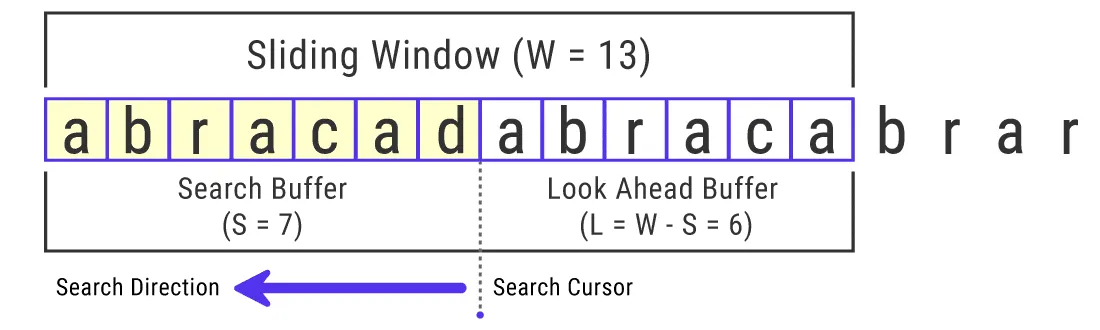
在上面的例子中,滑动窗口大小只有13个字符长(13个字节)。但是,GZIP压缩可以使用32KB(32,768字节)的最大滑动窗口大小。滑动窗口的大小对LZ77压缩性能起着关键作用。
用LZ77算法压缩原始数据后,GZIP压缩器再用霍夫曼编码算法进一步压缩。它通过为出现频率更高的字符分配最少的位数,同时为稀有字符分配最高的位数来实现这一点。
这种技术类似于摩尔斯电码中使用的技术,其中英语中出现频率更高的字母得到最短的序列。
要了解霍夫曼编码算法的工作原理,请考虑单词BOOKKEEPER。它有10个字符长,但它只有6个独特的字符。这个词很好地混合了单、双和三字母。
几乎所有网站都使用UTF-8字符编码来表示字母和符号。UTF-8中的每个ASCII字符(也包括英文字母)使用1个字节(8位)。

10个字符的字符串如BOOKKEEPER将需要10个字节(80位)的内存。您可以看到它包含1个字母实例B, P, R,2个字母实例O和K,3个字母实例E。
霍夫曼编码算法使用这些知识来无损压缩字符串。它通过生成一个将每个唯一字母作为叶子的二叉树来实现。
出现频率最低的字母(例如B、P、R)将位于树的底部,而那些频繁出现的字母(例如E、O、K)将理想地位于顶部。
树中最顶层的节点是root,其值等于字符串中的总字符数。
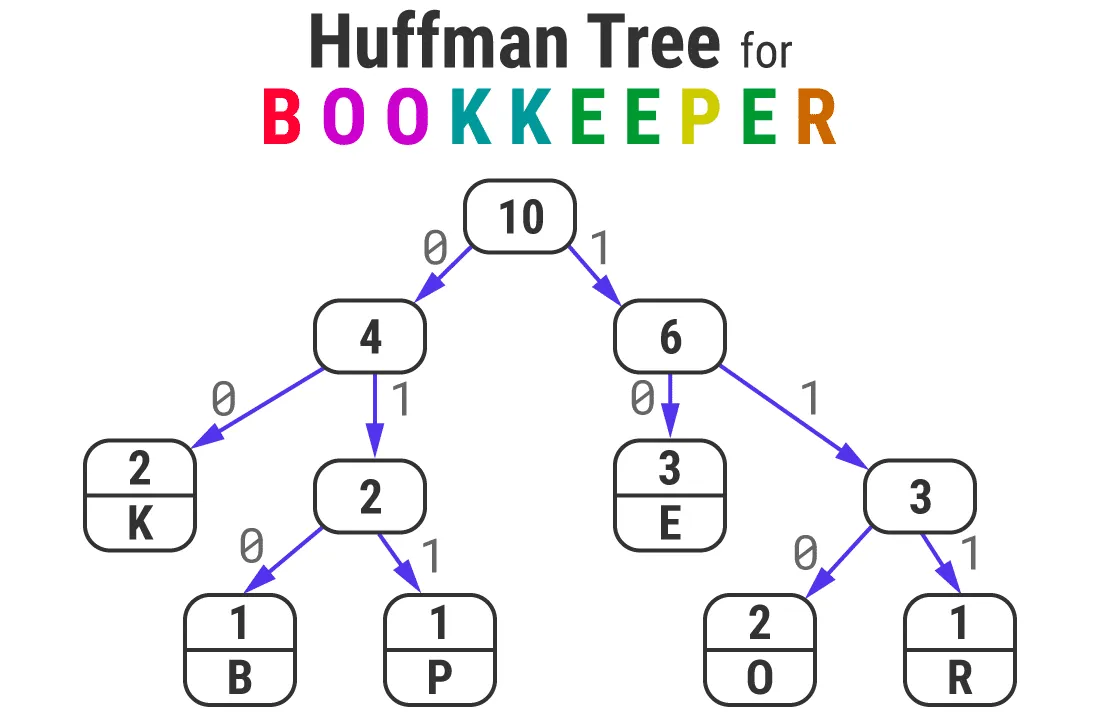
生成霍夫曼树后,所有的左分支和右分支箭头分别被赋予了0和1数字。然后,您可以通过跟踪从根到叶的路径并连接所有0和1来为任何字符生成霍夫曼代码。

您可以注意到频率最高的字母具有最小位大小的霍夫曼代码。
注意:霍夫曼编码算法可以通过对频率相同的字符使用不同的排序策略来生成替代的二进制代码。但是,编码字符串的总大小将保持不变。

存储原始单词所需的内存减少了68.75%。
使用具有0 / 1约定的霍夫曼树生成满足前缀属性的二进制代码。它确保任何特定字符的Huffman代码不是任何其他字符代码的前缀,从而可以轻松地使用Huffman树对编码的字符串进行解码。这对GZIP解压速度起主要作用。
就像上面的单词一样,GZIP压缩器使用Huffman编码算法进一步优化LZ77算法生成的元组。这会导致具有.gz扩展名的高度压缩文件。
静态、动态huffman
这里还存在静态huffman和动态huffman的区别:
1、静态Huffman编码就是使用gzip自己预先定义好了一套编码进行压缩,解压缩的时候也使用这套编码,这样不需要传递用来生成树的信息。
2、动态Huffman编码就是使用统计好的各个符号的出现次数,建立Huffman树,产生各个符号的Huffman编码,用这产生的Huffman编码进行压缩,这样需要传递生成树的信息。
Gzip 在为一块进行Huffman编码之前,会同时建立静态Huffman树,和动态Huffman树,然后根据要输出的内容和生成的Huffman树,计算使用静态Huffman树编码,生成的块的大小,以及计算使用动态Huffman树编码,生成块的大小。然后进行比较,使用生成块较小的方法进行Huffman编码。
对于静态树来说,不需要传递用来生成树的那部分信息。动态树需要传递这个信息。而当文件比较小的时候,传递生成树的信息得不偿失,反而会使压缩文件变大。也就是说对于文件比较小的时候,就可能会出现使用静态Huffman编码比使用动态Huffman编码,生成的块小。
gzip 的格式
Gzip 格式由头部信息, 压缩主体和尾部信息组成. 头部包括文件基本信息, 时间, 压缩方法, 操作系统等; 尾部则包含校验和与原始大小. 这些信息与压缩算法无关, 这里就不深入讨论了, 需要了解的同学可直接参阅 RFC1952.
压缩主体由一个或多个区块(block)组成. 每个区块的长度不固定, 都有自己的压缩和编码方式. 区块可能起始或结束于任何一个比特, 不必对齐字节. 需要说明的是, 重复标记指示的距离有可能跨越区块.
上文阐述的都是使用动态 Huffman 编码压缩. 事实上一个区块还有可能使用静态 Huffman 编码压缩或者不压缩. 使用静态 Huffman 编码压缩的区块会使用算法预设的 Huffman 编码进行压缩和解压, 不需要存储 Huffman 编码表.
所有的区块都以一个 3 位的头部开始, 包含以下数据:
| name | length | description |
|---|---|---|
| BFINAL | 1 位 | 标识是否是最后一个区块 |
| BTYPE | 2 位 | 标识类型. 00: 未压缩; 01: 静态 Huffman 编码压缩; 10: 动态 Huffman 编码压缩; 11: 保留 |
未压缩区块
未压缩区块包含以下数据(紧接着头部):
| name | length | description |
|---|---|---|
| LEN | 2 位 | 区块数据长度 |
| NLEN | 2 位 | LEN 的补码 |
| DATA | LEN 字节 | 有效数据 |
压缩区块
动态 Huffman 编码压缩区块包含以下数据(紧接着头部):
| name | length | description |
|---|---|---|
| HLIT | 5 位 | 长度/字符编码的最大值减 257. 因为并不是所有的长度编码都被使用, 因此这里标记最大的长度/字符编码(长度与普通字符共用同一编码空间). |
| HDIST | 5 位 | 距离编码最大值减 1. 原理同上. |
| HCLEN | 4 位 | 上文中的 k 减 4. 标识使用了数组中的前几个编码. |
| 编码后的长度序列的 Huffman 编码表 | (HCLEN + 4) * 3 位 | 如 上文所述的 “k 个数字”. 因为长度序列编码只有 19 个, 因此每个数字 3 位就够了. |
| 长度/字符编码的 Huffman 编码表 | 变长 | 根据上述 Huffman 编码表编码的长度序列, 用于表示长度/字符编码的 Huffman 编码表. |
| 距离编码的 Huffman 编码表 | 变长 | 根据上述 Huffman 编码表编码的长度序列, 用于表示距离编码的 Huffman 编码表. |
| DATA | 变长 | 有效压缩数据 |
| 256 结束标记 | 变长 | 标识区块的结束 |
静态压缩区块比较简单, 头部后紧接着就是有效压缩数据, 最后在加一个 256 结束标记.
关于gzip的Q & A
Q:gzip是否仅限制于文本文件,对于二进制文件呢?音频?图片等资源呢? A:gzip压缩不仅适用于文本文件,其实也可以对图片等二进制文件进行压缩,但是不推荐这么做,由于gzip的压缩过程首先基于字符串进行LZ77处理,接下里再通过huffman编码,然而,大多数的二进制文件,已经有自己的编码和压缩方式了,对二进制文件进行在压缩,可能导致文件更大,同时,会增大客户端解压缩的压力,带来不必要的CPU损耗。
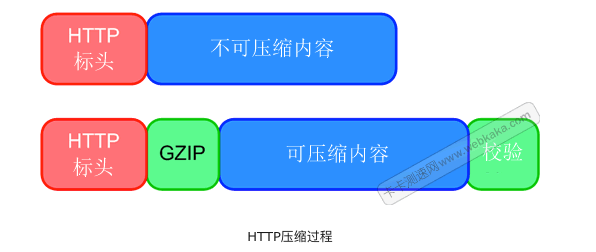
一些开发者使用HTTP压缩那些已经本地已经压缩过的文件,而这些已经压缩过的文件再次被GZip压缩时,是不能提高性能的,表现在如下两个方面。 首先,HTTP压缩需要成本。Web服务器获得需要的内容,然后压缩它,最后将它发送到客户端。如果内容不能被进一步压缩,你只是在浪费CPU做无意义的任务。 其次,采用HTTP压缩已经被过压缩的东西并不能使它更小。事实上,添加标头,压缩字典,并校验响应体实际上使它变得更大,如下图所示:
Q:gzip压缩过得文件,可以再进行一次gzip压缩吗?多次呢? A:可以进行再压缩,但是gzip首次压缩过后的文件,本身已经是二进制文件,对文件进行再压缩只会带来没必要的性能损耗,同时可能导致文件增大。
Q:需要对所有文本内容都进行GZIP压缩吗? A:答案是否定的,可以看到我们的压缩过程中,需要执行算法,假如传输的字符串仅仅几十个字符,那么执行算法是完全没有必要的,并且,对过短的字符进行压缩,可能反而导致传输数据量增大,例如可能要传输动态构造的huffman树信息等。
Q:在哪个阶段对文件进行gzip压缩比较合适? A:在本地构建部署的时候,通过webpack生成最终的gz压缩文件部署上服务器,是最高效的,假如通过引入中间件,在请求到来时再对文本文件进行压缩,只会让用户的等待时间更长,所以笔者认为,在webpack打包构建的时候做这件事是最合理的。
brotli
Brotli 是 Google 推出的开源无损压缩算法, 通过变种的 LZ77 算法、Huffman 编码以及二阶文本建模等方式进行数据压缩,与其他压缩算法相比,它有着更高的压缩效率,性能也比我们目前常见的 Gzip 高17-25%,侧重于HTTP压缩,可以帮我们高效的压缩网页中的各类文件。
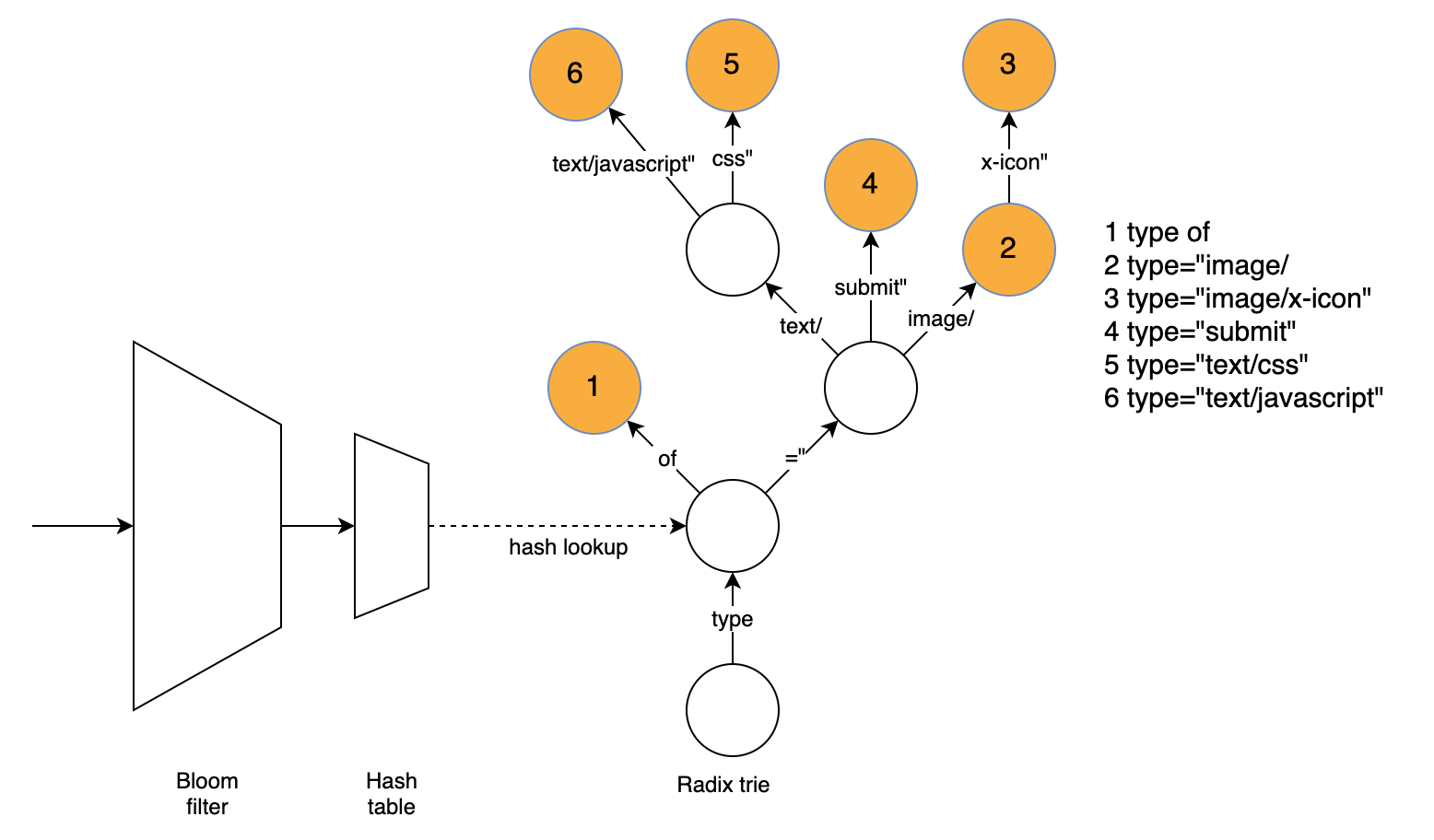
在文本Web内容压缩的上下文中,brotli文件格式的一个更有趣的特性是包含了一个内置的120千字节静态词典。该字典包含超过13000个常用单词、短语和其他子字符串,这些来自一个文本和HTML文档的大型语料库。除了包含多种语言的各种字符串外,它还支持对这些单词应用多个转换的选项,从而增加了它的通用性。
开源的brotli库实现了brotli的编码器和解码器,它为编码器预定义了11个质量级别,更高的质量级别需要更多的CPU来换取更好的压缩比。由于静态字典功能的CPU成本较高,因此从级别5开始有限地使用,并且仅在级别10和11全面使用。
如果字节序列不能与使用LZ77的较早序列匹配,则编码器将尝试通过引用静态字典来匹配该序列,可能使用多个转换中的一个。例如,每个HTML文件都包含不能用LZ77压缩的开始<;html>;标记,因为它是唯一的,但它包含在brotli静态字典中,并将被替换为对它的引用。引用通常比序列本身占用更少的空间,从而减小压缩文件的大小。
这部词典收录了6种语言的13504个单词,长度从4到24个字符不等。为了改进对真实文本和Web数据的压缩,一些词典单词是Web内容中常见的短语(当前)或字符串(‘type=“text/javascript”’)。与通常的LZ77压缩不同,字典中的单词只能作为一个整体进行匹配。Brotli格式不支持在词典单词中间开始匹配,在单词结尾之前结束匹配,甚至扩展到下一个单词。
取而代之的是,该词典支持120个词典单词的转换,以支持更大数量的匹配并查找更长的匹配。转换包括添加后缀(“work”变为“work”),添加前缀(“book”=&>;“the book”),使第一个字符大写(“;process”;=>;&34;process”;)或将整个单词转换为大写(“html”=&>;“HTML”)。除了使单词变长或大写的转换之外,Cut转换还允许缩短匹配(“Consistent”=>;“consistent”),这使得查找更多匹配成为可能。
在包含转换的情况下,静态词典包含1633,984个不同的单词–对于穷举搜索来说太多了,除非使用较慢的brotli压缩级别10和11。当使用较低的压缩级别时,brotli要么禁用词典,要么只搜索大约5500个单词的子集,以便在可接受的时间范围内找到匹配项。它还只考虑无法找到LZ77匹配项的位置的匹配项,并且只使用CUT变换。
gzip vs brotli
用户数
谈到纯用户数,GZIP压缩仍然是第一位的。然而,Brotli压缩每天都有更多的使用。这部分是由于主要浏览器采取了更广泛的采用措施;基于Chromium的浏览器的兴起也有帮助。
兼容性
Can I Use网站(https://caniuse.com/brotli)记录了浏览器采用的技术,并提供了各种历史记录。该网站指出,超过95%的浏览器在当前写作时支持使用Brotli压缩,包括所有主要版本。

压缩性能和压缩比
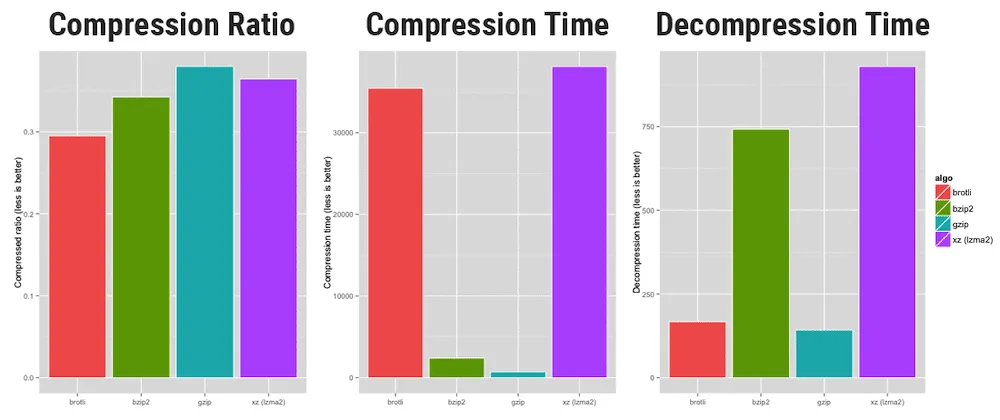
在基准测试中,与竞争算法相比,Brotli具有更好的压缩比,但在压缩和解压缩时间方面落后:
然而,另有一个测试显示了一个不同的故事——一个更微妙的故事。真正的收获是,总体而言,Brotli比GZIP更灵活,压缩比普遍更高。以下是这个调查结果的摘要:
1、Brotli在每个压缩级别都有更好的压缩比(即它产生更小的压缩文件)。
2、虽然GZIP在大多数情况下确实在速度上击败了Brotli,但您压缩的级别会影响您将看到的结果。
3、Brotli需要更多CPU能力来提供更大的文件压缩系数。这显示在最高和最低压缩级别。
4、文件越小,压缩速度数字越近。
总结
到目前为止,有很多关于Brotli压缩的信息。但是,我们可以总结一下您为什么应该选择Brotli而不是GZIP:
1、它采用与GZIP相同的技术,并使用现代方法对其进行增强。
2、Brotli基于字典的解析意味着它可以将更多文件压缩到更深层次。
3、虽然与GZIP相比,Brotli需要更多的计算能力,但结果意味着文件更小。
4、在大多数Web主机使用的压缩级别——诸如四级或五级之类的中等压缩级别——Brotli的性能比GZIP更好,而且毫不费力。
5、你会发现 Brotli 在浏览器中几乎得到了普遍支持,如果不是你习惯的一些基准测试工具的话。
6、Brotli是免费使用和开源的。如果您使用与Broti兼容的CDN,这是一个优势。
开启 gzip/br 压缩
这里仅讨论在私有化需求场景下, Node.js 服务如何压缩静态资源。CDN 场景需和 CDN 厂商沟通,不在本文范围内。
静态压缩(推荐)
静态压缩是在构建时生成 gzip 和 br 文件。
优点是:服务端运行时可快速响应压缩文件。相比于动态压缩,可以配置更高的压缩级别。
缺点是:会增加构建时间和资源上传时间。
1、配置 webpack 构建时生成 gzip/br 文件
在 webpack 中增加两个插件,一个用于生成 gzip,一个用于生成 brotli。具体参数可参考 CompressionWebpackPlugin。
new CompressionPlugin({
filename: '[path][base].gz',
algorithm: 'gzip',
test: /\.js$|\.css$|\.html$/,
threshold: 10240,
minRatio: 0.8,
})
new CompressionPlugin({
filename: '[path][base].br',
algorithm: 'brotliCompress',
test: /\.(js|css|html|svg)$/,
compressionOptions: {
params: {
[zlib.constants.BROTLI_PARAM_QUALITY]: 11,
},
},
threshold: 10240,
minRatio: 0.8,
})
2、服务端 express-static-gzip 根据 Accept-Encoding 自动降级
由于 express-static-gzip 是基于 express.static() 开发的,所以支持 express.static() 的所有功能。但其增加的额外功能有两点:
1、可以根据 Accept-Encoding 请求头解析不同的压缩文件并响应。
2、解析压缩文件时有优先级顺序,brotli > gzip > raw,支持自动降级解析。
代码也很简单,如下所示。
expressStaticGzip(StaticDir, {
enableBrotli: true,
orderPreference: ['br'],
serveStatic: {
maxAge: '30 days', // 开启强缓存 30 天
}
});
动态压缩(不推荐)
动态压缩是指服务在响应静态资源的时候,服务端对静态资源进行实时压缩返回。优缺点和静态压缩相反。
使用的三方包为 shrink-ray。使用也很简单,只需要一行代码,其内部已经对 Accept-Encoding 和 MIME 类型进行检查。
app.use(shrinkRay());
验证压缩生效
1、accept-encoding
客户端在向服务端发起请求时,会在请求头(request header)中添加accept-encoding字段,其值标明客户端支持的压缩内容编码格式

2、content-encoding
服务端在对返回内容执行压缩后,通过在响应头(response header)中添加content-encoding,来告诉浏览器内容实际压缩使用的编码算法
