git文件夹探索
git是一款分布式代码版本管理工具,通过git能够更加高效地协同编程。了解git的工作原理将有助于我们使用git工具更好地管理项目。通过了解.git文件夹中的文件组成,我们可以从一个角度去窥探git的实现原理。
学习知识需要找到知识的源头,git学习也不例外,首先我们找到git官方文档,对git了解不够的小伙伴可以先阅读文档补充知识。我们主要对.git文件夹下的相关文件进行逐一分析,了解他们的作用,最后结合实际项目介绍一下相关运用。
git内部原理
基本知识
git的三个区域
-
Git 的工作目录
-
暂存区域
-
本地仓库
对于任何一个文件,在 Git 内都只有三种状态:
-
已修改(modified),已修改表示修改了某个文件,但还没有提交保存 –> Git 的工作目录
-
已暂存(staged),已暂存表示把已修改的文件放在下次提交时要保存的清单中 –>暂存区域
-
已提交(committed),已提交表示该文件已经被安全地保存在本地数据库中了 –>本地仓库
Git 对象
Git 是一个内容寻址文件系统。 看起来很酷, 但这是什么意思呢? 这意味着,Git 的核心部分是一个简单的键值对数据库(key-value data store)。 你可以向该数据库插入任意类型的内容,它会返回一个键值,通过该键值可以在任意时刻再次检索(retrieve)该内容。 可以通过底层命令 hash-object 来演示上述效果——该命令可将任意数据保存于 .git 目录,并返回相应的键值。 首先,我们需要初始化一个新的 Git 版本库,并确认 objects 目录为空:
$ git init test
Initialized empty Git repository in /tmp/test/.git/
$ cd test
$ find .git/objects
.git/objects
.git/objects/info
.git/objects/pack
$ find .git/objects -type f
数据对象
可以看到 Git 对 objects 目录进行了初始化,并创建了 pack 和 info 子目录,但均为空。 接着,往 Git 数据库存入一些文本:
$ echo 'test content' | git hash-object -w --stdin
d670460b4b4aece5915caf5c68d12f560a9fe3e4
-w 选项指示 hash-object 命令存储数据对象;若不指定此选项,则该命令仅返回对应的键值。 –stdin 选项则指示该命令从标准输入读取内容;若不指定此选项,则须在命令尾部给出待存储文件的路径。 该命令输出一个长度为 40 个字符的校验和。 这是一个 SHA-1 哈希值——一个将待存储的数据外加一个头部信息(header)一起做 SHA-1 校验运算而得的校验和。后文会简要讨论该头部信息。 现在我们可以查看 Git 是如何存储数据的:
$ find .git/objects -type f
.git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4
可以在 objects 目录下看到一个文件。 这就是开始时 Git 存储内容的方式——一个文件对应一条内容,以该内容加上特定头部信息一起的 SHA-1 校验和为文件命名。 校验和的前两个字符用于命名子目录,余下的 38 个字符则用作文件名。
可以通过 cat-file 命令从 Git 那里取回数据。 这个命令简直就是一把剖析 Git 对象的瑞士军刀。 为 cat-file 指定 -p 选项可指示该命令自动判断内容的类型,并为我们显示格式友好的内容:
$ git cat-file -p d670460b4b4aece5915caf5c68d12f560a9fe3e4
test content
至此,你已经掌握了如何向 Git 中存入内容,以及如何将它们取出。 我们同样可以将这些操作应用于文件中的内容。 例如,可以对一个文件进行简单的版本控制。 首先,创建一个新文件并将其内容存入数据库:
$ echo 'version 1' > test.txt
$ git hash-object -w test.txt
83baae61804e65cc73a7201a7252750c76066a30
接着,向文件里写入新内容,并再次将其存入数据库:
$ echo 'version 2' > test.txt
$ git hash-object -w test.txt
1f7a7a472abf3dd9643fd615f6da379c4acb3e3a
数据库记录下了该文件的两个不同版本,当然之前我们存入的第一条内容也还在:
$ find .git/objects -type f
.git/objects/1f/7a7a472abf3dd9643fd615f6da379c4acb3e3a
.git/objects/83/baae61804e65cc73a7201a7252750c76066a30
.git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4
现在可以把文件内容恢复到第一个版本:
$ git cat-file -p 83baae61804e65cc73a7201a7252750c76066a30 > test.txt
$ cat test.txt
version 1
或者第二个版本:
$ git cat-file -p 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a > test.txt
$ cat test.txt
version 2
然而,记住文件的每一个版本所对应的 SHA-1 值并不现实;另一个问题是,在这个(简单的版本控制)系统中,文件名并没有被保存——我们仅保存了文件的内容。 上述类型的对象我们称之为数据对象(blob object)。 利用 cat-file -t 命令,可以让 Git 告诉我们其内部存储的任何对象类型,只要给定该对象的 SHA-1 值:
$ git cat-file -t 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a
blob
树对象
接下来要探讨的对象类型是树对象(tree object),它能解决文件名保存的问题,也允许我们将多个文件组织到一起。 Git 以一种类似于 UNIX 文件系统的方式存储内容,但作了些许简化。 所有内容均以树对象和数据对象的形式存储,其中树对象对应了 UNIX 中的目录项,数据对象则大致上对应了 inodes 或文件内容。 一个树对象包含了一条或多条树对象记录(tree entry),每条记录含有一个指向数据对象或者子树对象的 SHA-1 指针,以及相应的模式、类型、文件名信息。 例如,某项目当前对应的最新树对象可能是这样的:
$ git cat-file -p master^{tree}
100644 blob a906cb2a4a904a152e80877d4088654daad0c859 README
100644 blob 8f94139338f9404f26296befa88755fc2598c289 Rakefile
040000 tree 99f1a6d12cb4b6f19c8655fca46c3ecf317074e0 lib
master^{tree} 语法表示 master 分支上最新的提交所指向的树对象。 请注意,lib 子目录(所对应的那条树对象记录)并不是一个数据对象,而是一个指针,其指向的是另一个树对象:
$ git cat-file -p 99f1a6d12cb4b6f19c8655fca46c3ecf317074e0
100644 blob 47c6340d6459e05787f644c2447d2595f5d3a54b simplegit.rb
从概念上讲,Git 内部存储的数据有点像这样:
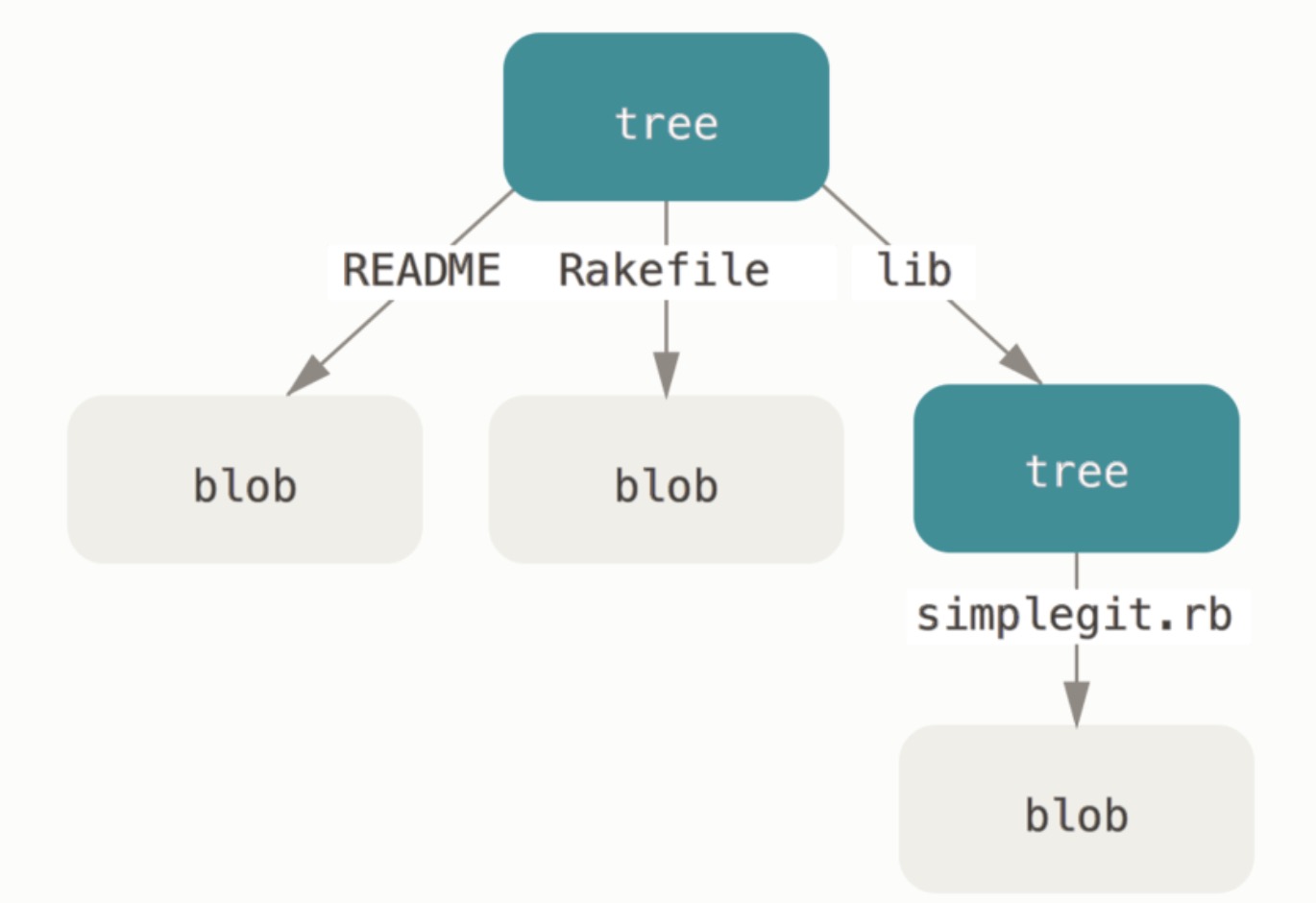
简化版的 Git 数据模型
你可以轻松创建自己的树对象。 通常,Git 根据某一时刻暂存区(即 index 区域,下同)所表示的状态创建并记录一个对应的树对象,如此重复便可依次记录(某个时间段内)一系列的树对象。 因此,为创建一个树对象,首先需要通过暂存一些文件来创建一个暂存区。 可以通过底层命令 update-index 为一个单独文件——我们的 test.txt 文件的首个版本——创建一个暂存区。 利用该命令,可以把 test.txt 文件的首个版本人为地加入一个新的暂存区。 必须为上述命令指定 –add 选项,因为此前该文件并不在暂存区中(我们甚至都还没来得及创建一个暂存区呢);同样必需的还有 –cacheinfo 选项,因为将要添加的文件位于 Git 数据库中,而不是位于当前目录下。 同时,需要指定文件模式、SHA-1 与文件名:
$ git update-index --add --cacheinfo 100644 \
83baae61804e65cc73a7201a7252750c76066a30 test.txt
本例中,我们指定的文件模式为 100644,表明这是一个普通文件。 其他选择包括:100755,表示一个可执行文件;120000,表示一个符号链接。 这里的文件模式参考了常见的 UNIX 文件模式,但远没那么灵活——上述三种模式即是 Git 文件(即数据对象)的所有合法模式(当然,还有其他一些模式,但用于目录项和子模块)。
现在,可以通过 write-tree 命令将暂存区内容写入一个树对象。 此处无需指定 -w 选项——如果某个树对象此前并不存在的话,当调用 write-tree 命令时,它会根据当前暂存区状态自动创建一个新的树对象:
$ git write-tree
d8329fc1cc938780ffdd9f94e0d364e0ea74f579
$ git cat-file -p d8329fc1cc938780ffdd9f94e0d364e0ea74f579
100644 blob 83baae61804e65cc73a7201a7252750c76066a30 test.txt
不妨验证一下它确实是一个树对象:
$ git cat-file -t d8329fc1cc938780ffdd9f94e0d364e0ea74f579
tree
接着我们来创建一个新的树对象,它包括 test.txt 文件的第二个版本,以及一个新的文件:
$ echo 'new file' > new.txt
$ git update-index --cacheinfo 100644 \
1f7a7a472abf3dd9643fd615f6da379c4acb3e3a test.txt
$ git update-index --add new.txt
暂存区现在包含了 test.txt 文件的新版本,和一个新文件:new.txt。 记录下这个目录树(将当前暂存区的状态记录为一个树对象),然后观察它的结构:
$ git write-tree
0155eb4229851634a0f03eb265b69f5a2d56f341
$ git cat-file -p 0155eb4229851634a0f03eb265b69f5a2d56f341
100644 blob fa49b077972391ad58037050f2a75f74e3671e92 new.txt
100644 blob 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a test.txt
我们注意到,新的树对象包含两条文件记录,同时 test.txt 的 SHA-1 值(1f7a7a)是先前值的“第二版”。 只是为了好玩:你可以将第一个树对象加入第二个树对象,使其成为新的树对象的一个子目录。 通过调用 read-tree 命令,可以把树对象读入暂存区。 本例中,可以通过对 read-tree 指定 –prefix 选项,将一个已有的树对象作为子树读入暂存区:
$ git read-tree --prefix=bak d8329fc1cc938780ffdd9f94e0d364e0ea74f579
$ git write-tree
3c4e9cd789d88d8d89c1073707c3585e41b0e614
$ git cat-file -p 3c4e9cd789d88d8d89c1073707c3585e41b0e614
040000 tree d8329fc1cc938780ffdd9f94e0d364e0ea74f579 bak
100644 blob fa49b077972391ad58037050f2a75f74e3671e92 new.txt
100644 blob 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a test.txt
如果基于这个新的树对象创建一个工作目录,你会发现工作目录的根目录包含两个文件以及一个名为 bak 的子目录,该子目录包含 test.txt 文件的第一个版本。 可以认为 Git 内部存储着的用于表示上述结构的数据是这样的:
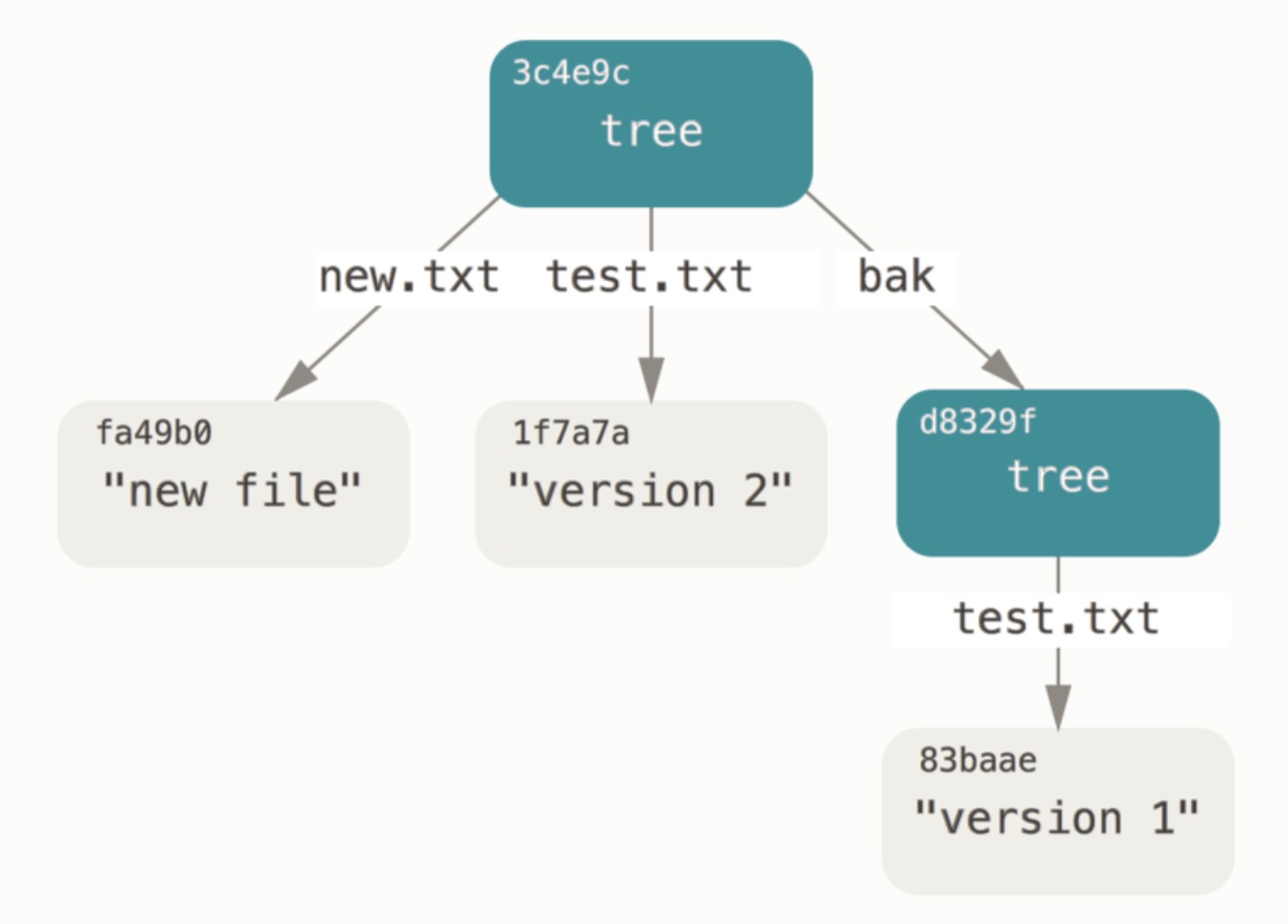
提交对象
现在有三个树对象,分别代表了我们想要跟踪的不同项目快照。然而问题依旧:若想重用这些快照,你必须记住所有三个 SHA-1 哈希值。 并且,你也完全不知道是谁保存了这些快照,在什么时刻保存的,以及为什么保存这些快照。 而以上这些,正是提交对象(commit object)能为你保存的基本信息。
可以通过调用 commit-tree 命令创建一个提交对象,为此需要指定一个树对象的 SHA-1 值,以及该提交的父提交对象(如果有的话)。 我们从之前创建的第一个树对象开始:
$ echo 'first commit' | git commit-tree d8329f
fdf4fc3344e67ab068f836878b6c4951e3b15f3d
现在可以通过 cat-file 命令查看这个新提交对象:
$ git cat-file -p fdf4fc3
tree d8329fc1cc938780ffdd9f94e0d364e0ea74f579
author Scott Chacon <schacon@gmail.com> 1243040974 -0700
committer Scott Chacon <schacon@gmail.com> 1243040974 -0700
first commit
提交对象的格式很简单:它先指定一个顶层树对象,代表当前项目快照;然后是作者/提交者信息(依据你的 user.name 和 user.email 配置来设定,外加一个时间戳);留空一行,最后是提交注释。
接着,我们将创建另两个提交对象,它们分别引用各自的上一个提交(作为其父提交对象):
$ echo 'second commit' | git commit-tree 0155eb -p fdf4fc3
cac0cab538b970a37ea1e769cbbde608743bc96d
$ echo 'third commit' | git commit-tree 3c4e9c -p cac0cab
1a410efbd13591db07496601ebc7a059dd55cfe9
这三个提交对象分别指向之前创建的三个树对象快照中的一个。 现在,如果对最后一个提交的 SHA-1 值运行 git log 命令,会出乎意料的发现,你已有一个货真价实的、可由 git log 查看的 Git 提交历史了:
$ git log --stat 1a410e
commit 1a410efbd13591db07496601ebc7a059dd55cfe9
Author: Scott Chacon <schacon@gmail.com>
Date: Fri May 22 18:15:24 2009 -0700
third commit
bak/test.txt | 1 +
1 file changed, 1 insertion(+)
commit cac0cab538b970a37ea1e769cbbde608743bc96d
Author: Scott Chacon <schacon@gmail.com>
Date: Fri May 22 18:14:29 2009 -0700
second commit
new.txt | 1 +
test.txt | 2 +-
2 files changed, 2 insertions(+), 1 deletion(-)
commit fdf4fc3344e67ab068f836878b6c4951e3b15f3d
Author: Scott Chacon <schacon@gmail.com>
Date: Fri May 22 18:09:34 2009 -0700
first commit
test.txt | 1 +
1 file changed, 1 insertion(+)
太神奇了: 就在刚才,你没有借助任何上层命令,仅凭几个底层操作便完成了一个 Git 提交历史的创建。 这就是每次我们运行 git add 和 git commit 命令时, Git 所做的实质工作——将被改写的文件保存为数据对象,更新暂存区,记录树对象,最后创建一个指明了顶层树对象和父提交的提交对象。 这三种主要的 Git 对象——数据对象、树对象、提交对象——最初均以单独文件的形式保存在 .git/objects 目录下。 下面列出了目前示例目录内的所有对象,辅以各自所保存内容的注释:
$ find .git/objects -type f
.git/objects/01/55eb4229851634a0f03eb265b69f5a2d56f341 # tree 2
.git/objects/1a/410efbd13591db07496601ebc7a059dd55cfe9 # commit 3
.git/objects/1f/7a7a472abf3dd9643fd615f6da379c4acb3e3a # test.txt v2
.git/objects/3c/4e9cd789d88d8d89c1073707c3585e41b0e614 # tree 3
.git/objects/83/baae61804e65cc73a7201a7252750c76066a30 # test.txt v1
.git/objects/ca/c0cab538b970a37ea1e769cbbde608743bc96d # commit 2
.git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4 # 'test content'
.git/objects/d8/329fc1cc938780ffdd9f94e0d364e0ea74f579 # tree 1
.git/objects/fa/49b077972391ad58037050f2a75f74e3671e92 # new.txt
.git/objects/fd/f4fc3344e67ab068f836878b6c4951e3b15f3d # commit 1
如果跟踪所有的内部指针,将得到一个类似下面的对象关系图:
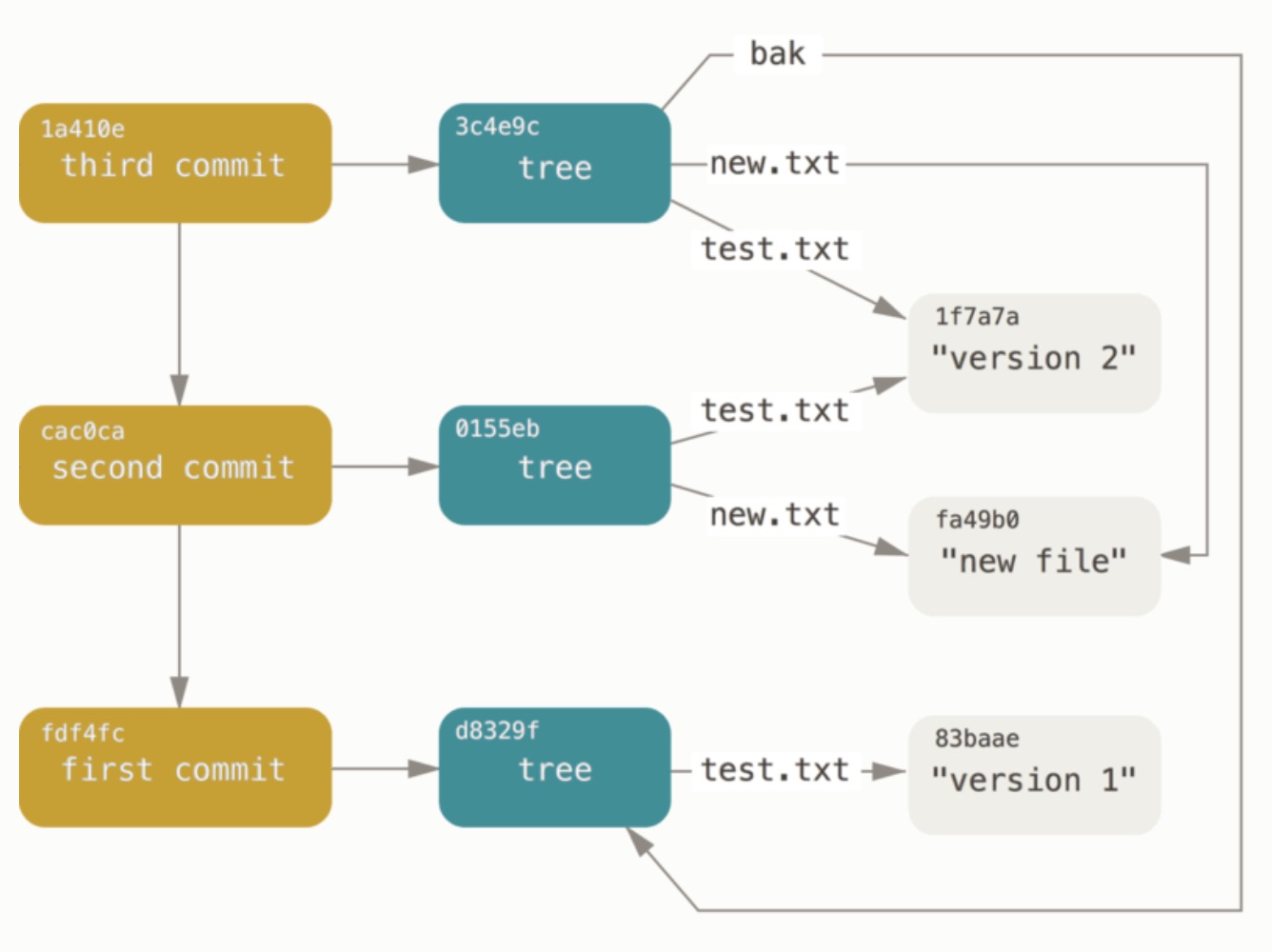
对象存储
前文曾提及,在存储内容时,会有个头部信息一并被保存。 让我们略花些时间来看看 Git 是如何存储其对象的。 通过在 Ruby 脚本语言中交互式地演示,你将看到一个数据对象——本例中是字符串“what is up, doc?”——是如何被存储的。
可以通过 irb 命令启动 Ruby 的交互模式:
$ irb
>> content = "what is up, doc?"
=> "what is up, doc?"
Git 以对象类型作为开头来构造一个头部信息,本例中是一个“blob”字符串。 接着 Git 会添加一个空格,随后是数据内容的长度,最后是一个空字节(null byte):
>> header = "blob #{content.length}\0"
=> "blob 16\u0000"
Git 会将上述头部信息和原始数据拼接起来,并计算出这条新内容的 SHA-1 校验和。 在 Ruby 中可以这样计算 SHA-1 值——先通过 require 命令导入 SHA-1 digest 库,然后对目标字符串调用 Digest::SHA1.hexdigest():
>> store = header + content
=> "blob 16\u0000what is up, doc?"
>> require 'digest/sha1'
=> true
>> sha1 = Digest::SHA1.hexdigest(store)
=> "bd9dbf5aae1a3862dd1526723246b20206e5fc37"
Git 会通过 zlib 压缩这条新内容。在 Ruby 中可以借助 zlib 库做到这一点。 先导入相应的库,然后对目标内容调用 Zlib::Deflate.deflate():
>> require 'zlib'
=> true
>> zlib_content = Zlib::Deflate.deflate(store)
=> "x\x9CK\xCA\xC9OR04c(\xCFH,Q\xC8,V(-\xD0QH\xC9O\xB6\a\x00_\x1C\a\x9D"
最后,需要将这条经由 zlib 压缩的内容写入磁盘上的某个对象。 要先确定待写入对象的路径(SHA-1 值的前两个字符作为子目录名称,后 38 个字符则作为子目录内文件的名称)。 如果该子目录不存在,可以通过 Ruby 中的 FileUtils.mkdir_p() 函数来创建它。 接着,通过 File.open() 打开这个文件。最后,对上一步中得到的文件句柄调用 write() 函数,以向目标文件写入之前那条 zlib 压缩过的内容:
>> path = '.git/objects/' + sha1[0,2] + '/' + sha1[2,38]
=> ".git/objects/bd/9dbf5aae1a3862dd1526723246b20206e5fc37"
>> require 'fileutils'
=> true
>> FileUtils.mkdir_p(File.dirname(path))
=> ".git/objects/bd"
>> File.open(path, 'w') { |f| f.write zlib_content }
=> 32
就是这样——你已创建了一个有效的 Git 数据对象。 所有的 Git 对象均以这种方式存储,区别仅在于类型标识——另两种对象类型的头部信息以字符串“commit”或“tree”开头,而不是“blob”。 另外,虽然数据对象的内容几乎可以是任何东西,但提交对象和树对象的内容却有各自固定的格式。
Git 引用
我们可以借助类似于 git log 1a410e 这样的命令来浏览完整的提交历史,但为了能遍历那段历史从而找到所有相关对象,你仍须记住 1a410e 是最后一个提交。 我们需要一个文件来保存 SHA-1 值,并给文件起一个简单的名字,然后用这个名字指针来替代原始的 SHA-1 值。
在 Git 里,这样的文件被称为“引用(references,或缩写为 refs)”;你可以在 .git/refs 目录下找到这类含有 SHA-1 值的文件。 在目前的项目中,这个目录没有包含任何文件,但它包含了一个简单的目录结构:
$ find .git/refs
.git/refs
.git/refs/heads
.git/refs/tags
$ find .git/refs -type f
若要创建一个新引用来帮助记忆最新提交所在的位置,从技术上讲我们只需简单地做如下操作:
$ echo "1a410efbd13591db07496601ebc7a059dd55cfe9" > .git/refs/heads/master
现在,你就可以在 Git 命令中使用这个刚创建的新引用来代替 SHA-1 值了:
$ git log --pretty=oneline master
1a410efbd13591db07496601ebc7a059dd55cfe9 third commit
cac0cab538b970a37ea1e769cbbde608743bc96d second commit
fdf4fc3344e67ab068f836878b6c4951e3b15f3d first commit
我们不提倡直接编辑引用文件。 如果想更新某个引用,Git 提供了一个更加安全的命令 update-ref 来完成此事:
$ git update-ref refs/heads/master 1a410efbd13591db07496601ebc7a059dd55cfe9
这基本就是 Git 分支的本质:一个指向某一系列提交之首的指针或引用。 若想在第二个提交上创建一个分支,可以这么做:
$ git update-ref refs/heads/test cac0ca
这个分支将只包含从第二个提交开始往前追溯的记录:
$ git log --pretty=oneline test
cac0cab538b970a37ea1e769cbbde608743bc96d second commit
fdf4fc3344e67ab068f836878b6c4951e3b15f3d first commit
至此,我们的 Git 数据库从概念上看起来像这样:
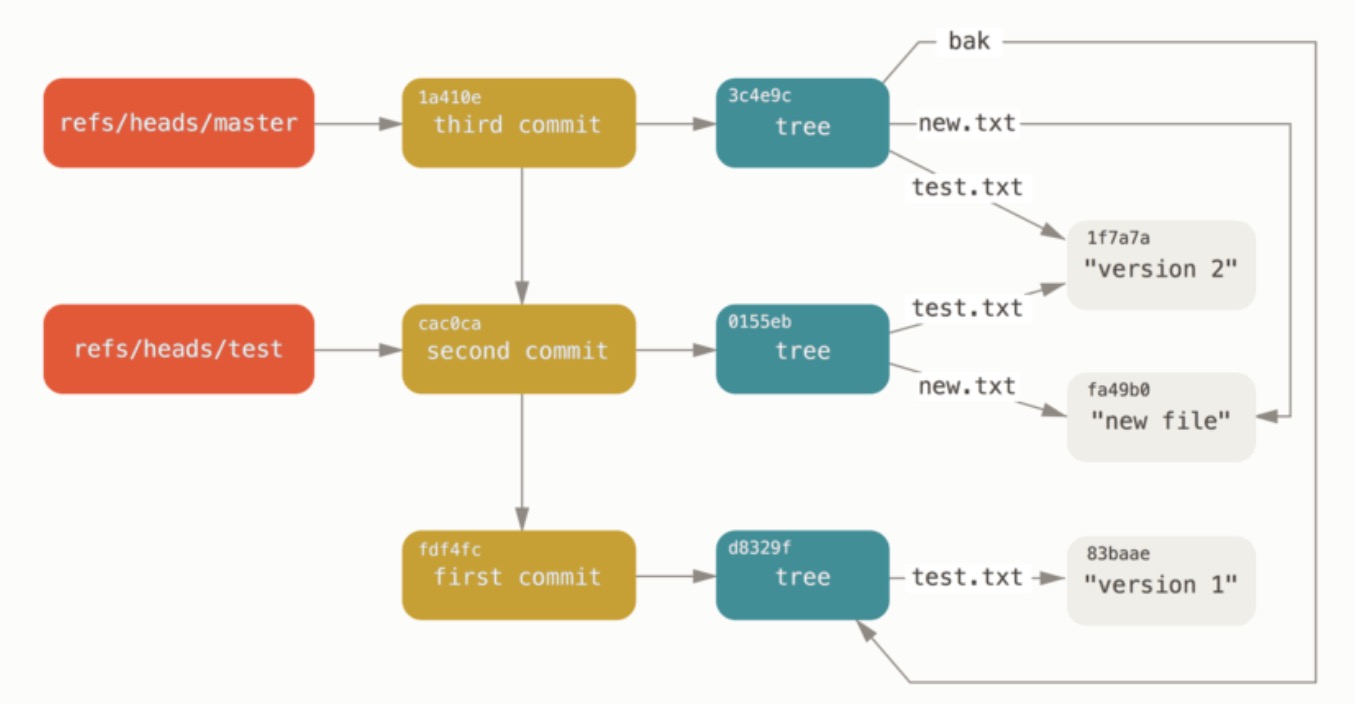
当运行类似于 git branch (branchname) 这样的命令时,Git 实际上会运行 update-ref 命令,取得当前所在分支最新提交对应的 SHA-1 值,并将其加入你想要创建的任何新引用中。
HEAD 引用
现在的问题是,当你执行 git branch (branchname) 时,Git 如何知道最新提交的 SHA-1 值呢? 答案是 HEAD 文件。
HEAD 文件是一个符号引用(symbolic reference),指向目前所在的分支。 所谓符号引用,意味着它并不像普通引用那样包含一个 SHA-1 值——它是一个指向其他引用的指针。 如果查看 HEAD 文件的内容,一般而言我们看到的类似这样:
$ cat .git/HEAD
ref: refs/heads/master
如果执行 git checkout test,Git 会像这样更新 HEAD 文件:
$ cat .git/HEAD
ref: refs/heads/test
当我们执行 git commit 时,该命令会创建一个提交对象,并用 HEAD 文件中那个引用所指向的 SHA-1 值设置其父提交字段。
你也可以手动编辑该文件,然而同样存在一个更安全的命令来完成此事:symbolic-ref。 可以借助此命令来查看 HEAD 引用对应的值:
$ git symbolic-ref HEAD
refs/heads/master
同样可以设置 HEAD 引用的值:
$ git symbolic-ref HEAD refs/heads/test
$ cat .git/HEAD
ref: refs/heads/test
不能把符号引用设置为一个不符合引用格式的值:
$ git symbolic-ref HEAD test
fatal: Refusing to point HEAD outside of refs/
标签引用
前文我们刚讨论过 Git 的三种主要对象类型,事实上还有第四种。 标签对象(tag object)非常类似于一个提交对象——它包含一个标签创建者信息、一个日期、一段注释信息,以及一个指针。 主要的区别在于,标签对象通常指向一个提交对象,而不是一个树对象。 它像是一个永不移动的分支引用——永远指向同一个提交对象,只不过给这个提交对象加上一个更友好的名字罢了。
正如 Git 基础 中所讨论的那样,存在两种类型的标签:附注标签和轻量标签。 可以像这样创建一个轻量标签:
$ git update-ref refs/tags/v1.0 cac0cab538b970a37ea1e769cbbde608743bc96d
这就是轻量标签的全部内容——一个固定的引用。 然而,一个附注标签则更复杂一些。 若要创建一个附注标签,Git 会创建一个标签对象,并记录一个引用来指向该标签对象,而不是直接指向提交对象。 可以通过创建一个附注标签来验证这个过程(-a 选项指定了要创建的是一个附注标签):
$ git tag -a v1.1 1a410efbd13591db07496601ebc7a059dd55cfe9 -m 'test tag'
下面是上述过程所建标签对象的 SHA-1 值:
$ cat .git/refs/tags/v1.1
9585191f37f7b0fb9444f35a9bf50de191beadc2
现在对该 SHA-1 值运行 cat-file 命令:
$ git cat-file -p 9585191f37f7b0fb9444f35a9bf50de191beadc2
object 1a410efbd13591db07496601ebc7a059dd55cfe9
type commit
tag v1.1
tagger Scott Chacon <schacon@gmail.com> Sat May 23 16:48:58 2009 -0700
test tag
我们注意到,object 条目指向我们打了标签的那个提交对象的 SHA-1 值。 另外要注意的是,标签对象并非必须指向某个提交对象;你可以对任意类型的 Git 对象打标签。 例如,在 Git 源码中,项目维护者将他们的 GPG 公钥添加为一个数据对象,然后对这个对象打了一个标签。 可以克隆一个 Git 版本库,然后通过执行下面的命令来在这个版本库中查看上述公钥:
$ git cat-file blob junio-gpg-pub
Linux 内核版本库同样有一个不指向提交对象的标签对象——首个被创建的标签对象所指向的是最初被引入版本库的那份内核源码所对应的树对象。
远程引用
我们将看到的第三种引用类型是远程引用(remote reference)。 如果你添加了一个远程版本库并对其执行过推送操作,Git 会记录下最近一次推送操作时每一个分支所对应的值,并保存在 refs/remotes 目录下。 例如,你可以添加一个叫做 origin 的远程版本库,然后把 master 分支推送上去:
$ git remote add origin git@github.com:schacon/simplegit-progit.git
$ git push origin master
Counting objects: 11, done.
Compressing objects: 100% (5/5), done.
Writing objects: 100% (7/7), 716 bytes, done.
Total 7 (delta 2), reused 4 (delta 1)
To git@github.com:schacon/simplegit-progit.git
a11bef0..ca82a6d master -> master
此时,如果查看 refs/remotes/origin/master 文件,可以发现 origin 远程版本库的 master 分支所对应的 SHA-1 值,就是最近一次与服务器通信时本地 master 分支所对应的 SHA-1 值:
$ cat .git/refs/remotes/origin/master
ca82a6dff817ec66f44342007202690a93763949
远程引用和分支(位于 refs/heads 目录下的引用)之间最主要的区别在于,远程引用是只读的。 虽然可以 git checkout 到某个远程引用,但是 Git 并不会将 HEAD 引用指向该远程引用。因此,你永远不能通过 commit 命令来更新远程引用。 Git 将这些远程引用作为记录远程服务器上各分支最后已知位置状态的书签来管理。
包文件
让我们重新回到示例 Git 版本库的对象数据库。 目前为止,可以看到有 11 个对象——4 个数据对象、3 个树对象、3 个提交对象和 1 个标签对象:
$ find .git/objects -type f
.git/objects/01/55eb4229851634a0f03eb265b69f5a2d56f341 # tree 2
.git/objects/1a/410efbd13591db07496601ebc7a059dd55cfe9 # commit 3
.git/objects/1f/7a7a472abf3dd9643fd615f6da379c4acb3e3a # test.txt v2
.git/objects/3c/4e9cd789d88d8d89c1073707c3585e41b0e614 # tree 3
.git/objects/83/baae61804e65cc73a7201a7252750c76066a30 # test.txt v1
.git/objects/95/85191f37f7b0fb9444f35a9bf50de191beadc2 # tag
.git/objects/ca/c0cab538b970a37ea1e769cbbde608743bc96d # commit 2
.git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4 # 'test content'
.git/objects/d8/329fc1cc938780ffdd9f94e0d364e0ea74f579 # tree 1
.git/objects/fa/49b077972391ad58037050f2a75f74e3671e92 # new.txt
.git/objects/fd/f4fc3344e67ab068f836878b6c4951e3b15f3d # commit 1
Git 使用 zlib 压缩这些文件的内容,而且我们并没有存储太多东西,所以上文中的文件一共只占用了 925 字节。 接下来,我们会指引你添加一些大文件到版本库中,以此展示 Git 的一个很有趣的功能。 为了便于展示,我们要把之前在 Grit 库中用到过的 repo.rb 文件添加进来——这是一个大小约为 22K 的源代码文件:
$ curl https://raw.githubusercontent.com/mojombo/grit/master/lib/grit/repo.rb > repo.rb
$ git add repo.rb
$ git commit -m 'added repo.rb'
[master 484a592] added repo.rb
3 files changed, 709 insertions(+), 2 deletions(-)
delete mode 100644 bak/test.txt
create mode 100644 repo.rb
rewrite test.txt (100%)
如果你查看生成的树对象,可以看到 repo.rb 文件对应的数据对象的 SHA-1 值:
$ git cat-file -p master^{tree}
100644 blob fa49b077972391ad58037050f2a75f74e3671e92 new.txt
100644 blob 033b4468fa6b2a9547a70d88d1bbe8bf3f9ed0d5 repo.rb
100644 blob e3f094f522629ae358806b17daf78246c27c007b test.txt
接下来你可以使用 git cat-file 命令查看这个对象有多大:
$ git cat-file -s 033b4468fa6b2a9547a70d88d1bbe8bf3f9ed0d5
22044
现在,稍微修改这个文件,然后看看会发生什么:
$ echo '# testing' >> repo.rb
$ git commit -am 'modified repo a bit'
[master 2431da6] modified repo.rb a bit
1 file changed, 1 insertion(+)
查看这个提交生成的树对象,你会看到一些有趣的东西:
$ git cat-file -p master^{tree}
100644 blob fa49b077972391ad58037050f2a75f74e3671e92 new.txt
100644 blob b042a60ef7dff760008df33cee372b945b6e884e repo.rb
100644 blob e3f094f522629ae358806b17daf78246c27c007b test.txt
repo.rb 对应一个与之前完全不同的数据对象,这意味着,虽然你只是在一个 400 行的文件后面加入一行新内容,Git 也会用一个全新的对象来存储新的文件内容:
$ git cat-file -s b042a60ef7dff760008df33cee372b945b6e884e
22054
你的磁盘上现在有两个几乎完全相同、大小均为 22K 的对象。 如果 Git 只完整保存其中一个,再保存另一个对象与之前版本的差异内容,岂不更好?
事实上 Git 可以那样做。 Git 最初向磁盘中存储对象时所使用的格式被称为“松散(loose)”对象格式。 但是,Git 会时不时地将多个这些对象打包成一个称为“包文件(packfile)”的二进制文件,以节省空间和提高效率。 当版本库中有太多的松散对象,或者你手动执行 git gc 命令,或者你向远程服务器执行推送时,Git 都会这样做。 要看到打包过程,你可以手动执行 git gc 命令让 Git 对对象进行打包:
$ git gc
Counting objects: 18, done.
Delta compression using up to 8 threads.
Compressing objects: 100% (14/14), done.
Writing objects: 100% (18/18), done.
Total 18 (delta 3), reused 0 (delta 0)
这个时候再查看 objects 目录,你会发现大部分的对象都不见了,与此同时出现了一对新文件:
$ find .git/objects -type f
.git/objects/bd/9dbf5aae1a3862dd1526723246b20206e5fc37
.git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4
.git/objects/info/packs
.git/objects/pack/pack-978e03944f5c581011e6998cd0e9e30000905586.idx
.git/objects/pack/pack-978e03944f5c581011e6998cd0e9e30000905586.pack
仍保留着的几个对象是未被任何提交记录引用的数据对象——在此例中是你之前创建的 “what is up, doc?” 和 “test content” 这两个示例数据对象。 因为你从没将它们添加至任何提交记录中,所以 Git 认为它们是悬空(dangling)的,不会将它们打包进新生成的包文件中。
剩下的文件是新创建的包文件和一个索引。 包文件包含了刚才从文件系统中移除的所有对象的内容。 索引文件包含了包文件的偏移信息,我们通过索引文件就可以快速定位任意一个指定对象。 有意思的是运行 gc 命令前磁盘上的对象大小约为 22K,而这个新生成的包文件大小仅有 7K。 通过打包对象减少了2/3的磁盘占用空间。
Git 是如何做到这点的? Git 打包对象时,会查找命名及大小相近的文件,并只保存文件不同版本之间的差异内容。 你可以查看包文件,观察它是如何节省空间的。 git verify-pack 这个底层命令可以让你查看已打包的内容:
$ git verify-pack -v .git/objects/pack/pack-978e03944f5c581011e6998cd0e9e30000905586.idx
2431da676938450a4d72e260db3bf7b0f587bbc1 commit 223 155 12
69bcdaff5328278ab1c0812ce0e07fa7d26a96d7 commit 214 152 167
80d02664cb23ed55b226516648c7ad5d0a3deb90 commit 214 145 319
43168a18b7613d1281e5560855a83eb8fde3d687 commit 213 146 464
092917823486a802e94d727c820a9024e14a1fc2 commit 214 146 610
702470739ce72005e2edff522fde85d52a65df9b commit 165 118 756
d368d0ac0678cbe6cce505be58126d3526706e54 tag 130 122 874
fe879577cb8cffcdf25441725141e310dd7d239b tree 136 136 996
d8329fc1cc938780ffdd9f94e0d364e0ea74f579 tree 36 46 1132
deef2e1b793907545e50a2ea2ddb5ba6c58c4506 tree 136 136 1178
d982c7cb2c2a972ee391a85da481fc1f9127a01d tree 6 17 1314 1 \
deef2e1b793907545e50a2ea2ddb5ba6c58c4506
3c4e9cd789d88d8d89c1073707c3585e41b0e614 tree 8 19 1331 1 \
deef2e1b793907545e50a2ea2ddb5ba6c58c4506
0155eb4229851634a0f03eb265b69f5a2d56f341 tree 71 76 1350
83baae61804e65cc73a7201a7252750c76066a30 blob 10 19 1426
fa49b077972391ad58037050f2a75f74e3671e92 blob 9 18 1445
b042a60ef7dff760008df33cee372b945b6e884e blob 22054 5799 1463
033b4468fa6b2a9547a70d88d1bbe8bf3f9ed0d5 blob 9 20 7262 1 \
b042a60ef7dff760008df33cee372b945b6e884e
1f7a7a472abf3dd9643fd615f6da379c4acb3e3a blob 10 19 7282
non delta: 15 objects
chain length = 1: 3 objects
.git/objects/pack/pack-978e03944f5c581011e6998cd0e9e30000905586.pack: ok
此处,033b4 这个数据对象(即 repo.rb 文件的第一个版本,如果你还记得的话)引用了数据对象 b042a,即该文件的第二个版本。 命令输出内容的第三列显示的是各个对象在包文件中的大小,可以看到 b042a 占用了 22K 空间,而 033b4 仅占用 9 字节。 同样有趣的地方在于,第二个版本完整保存了文件内容,而原始的版本反而是以差异方式保存的——这是因为大部分情况下需要快速访问文件的最新版本。
最妙之处是你可以随时重新打包。 Git 时常会自动对仓库进行重新打包以节省空间。当然你也可以随时手动执行 git gc 命令来这么做。
引用规格
纵观全书,我们已经使用过一些诸如远程分支到本地引用的简单映射方式,但这种映射可以更复杂。 假设你添加了这样一个远程版本库:
$ git remote add origin https://github.com/schacon/simplegit-progit
上述命令会在你的 .git/config 文件中添加一个小节,并在其中指定远程版本库的名称(origin)、URL 和一个用于获取操作的引用规格(refspec):
[remote "origin"]
url = https://github.com/schacon/simplegit-progit
fetch = +refs/heads/*:refs/remotes/origin/*
引用规格的格式由一个可选的 + 号和紧随其后的 <src>:<dst> 组成,其中 <src> 是一个模式(pattern),代表远程版本库中的引用;<dst> 是那些远程引用在本地所对应的位置。 + 号告诉 Git 即使在不能快进的情况下也要(强制)更新引用。
默认情况下,引用规格由 git remote add 命令自动生成, Git 获取服务器中 refs/heads/ 下面的所有引用,并将它写入到本地的 refs/remotes/origin/ 中。 所以,如果服务器上有一个 master 分支,我们可以在本地通过下面这种方式来访问该分支上的提交记录:
$ git log origin/master
$ git log remotes/origin/master
$ git log refs/remotes/origin/master
上面的三个命令作用相同,因为 Git 会把它们都扩展成 refs/remotes/origin/master。
如果想让 Git 每次只拉取远程的 master 分支,而不是所有分支,可以把(引用规格的)获取那一行修改为:
fetch = +refs/heads/master:refs/remotes/origin/master
这仅是针对该远程版本库的 git fetch 操作的默认引用规格。 如果有某些只希望被执行一次的操作,我们也可以在命令行指定引用规格。 若要将远程的 master 分支拉到本地的 origin/mymaster 分支,可以运行:
$ git fetch origin master:refs/remotes/origin/mymaster
你也可以指定多个引用规格。 在命令行中,你可以按照如下的方式拉取多个分支:
$ git fetch origin master:refs/remotes/origin/mymaster \
topic:refs/remotes/origin/topic
From git@github.com:schacon/simplegit
! [rejected] master -> origin/mymaster (non fast forward)
* [new branch] topic -> origin/topic
在这个例子中,对 master 分支的拉取操作被拒绝,因为它不是一个可以快进的引用。 我们可以通过在引用规格之前指定 + 号来覆盖该规则。
你也可以在配置文件中指定多个用于获取操作的引用规格。 如果想在每次获取时都包括 master 和 experiment 分支,添加如下两行:
[remote "origin"]
url = https://github.com/schacon/simplegit-progit
fetch = +refs/heads/master:refs/remotes/origin/master
fetch = +refs/heads/experiment:refs/remotes/origin/experiment
我们不能在模式中使用部分通配符,所以像下面这样的引用规格是不合法的:
fetch = +refs/heads/qa*:refs/remotes/origin/qa*
但我们可以使用命名空间(或目录)来达到类似目的。 假设你有一个 QA 团队,他们推送了一系列分支,同时你只想要获取 master 和 QA 团队的所有分支而不关心其他任何分支,那么可以使用如下配置:
[remote "origin"]
url = https://github.com/schacon/simplegit-progit
fetch = +refs/heads/master:refs/remotes/origin/master
fetch = +refs/heads/qa/*:refs/remotes/origin/qa/*
如果项目的工作流很复杂,有 QA 团队推送分支、开发人员推送分支、集成团队推送并且在远程分支上展开协作,你就可以像这样(在本地)为这些分支创建各自的命名空间,非常方便。
引用规格推送
像上面这样从远程版本库获取已在命名空间中的引用当然很棒,但 QA 团队最初应该如何将他们的分支放入远程的 qa/ 命名空间呢? 我们可以通过引用规格推送来完成这个任务。
如果 QA 团队想把他们的 master 分支推送到远程服务器的 qa/master 分支上,可以运行:
$ git push origin master:refs/heads/qa/master
如果他们希望 Git 每次运行 git push origin 时都像上面这样推送,可以在他们的配置文件中添加一条 push 值:
[remote "origin"]
url = https://github.com/schacon/simplegit-progit
fetch = +refs/heads/*:refs/remotes/origin/*
push = refs/heads/master:refs/heads/qa/master
正如刚才所指出的,这会让 git push origin 默认把本地 master 分支推送到远程 qa/master 分支。
删除引用
你还可以借助类似下面的命令通过引用规格从远程服务器上删除引用:
$ git push origin :topic
因为引用规格(的格式)是 <src>:<dst>,所以上述命令把 <src> 留空,意味着把远程版本库的 topic 分支定义为空值,也就是删除它。
或者你可以使用更新的语法(自 Git v1.7.0以后可用):
$ git push origin --delete topic
.git文件夹
我们随便找一个git项目,打开.git文件夹,接下来我们一个个分析他们的作用:
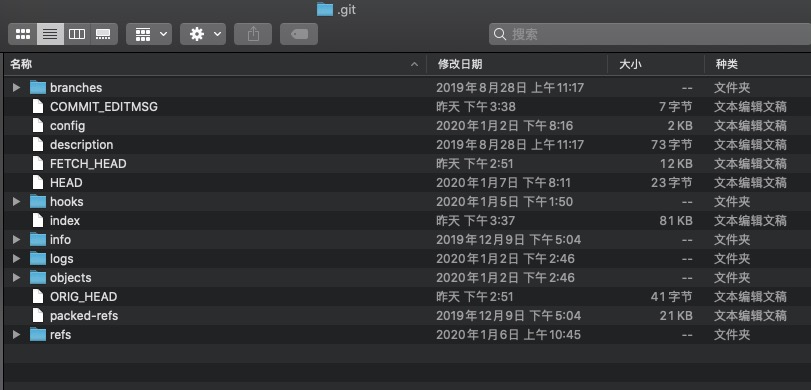
hooks文件夹
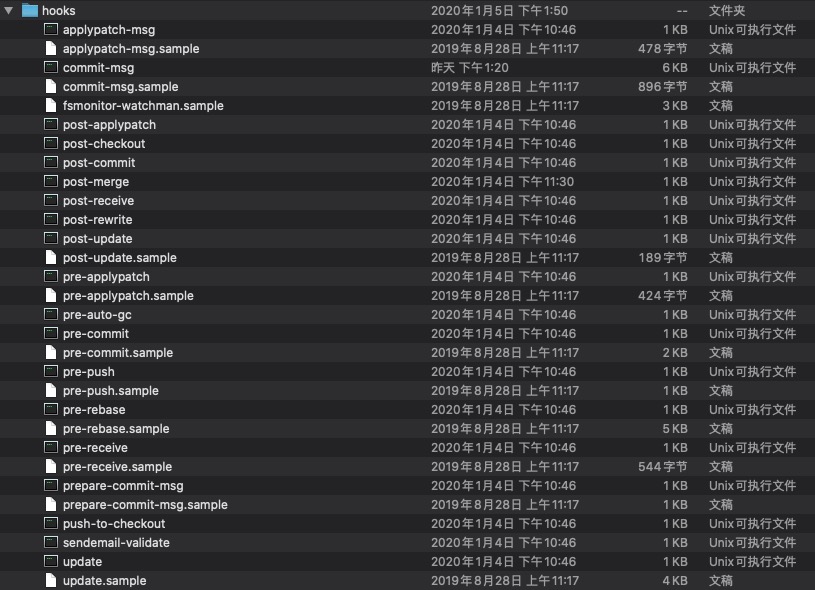
用于存储shell脚本,当执行某些git指令后,会触发存储在该文件夹下指定的shell脚本。
其中以.sample为后缀的是脚本例子,没有后缀的则是会执行的脚本。
logs文件夹
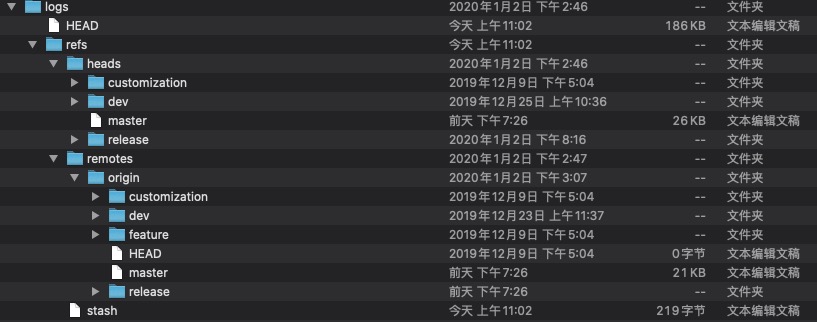
用于记录分支提交记录,保存所有更改的引用记录,包含refs文件夹和HEAD文件
HEAD文件
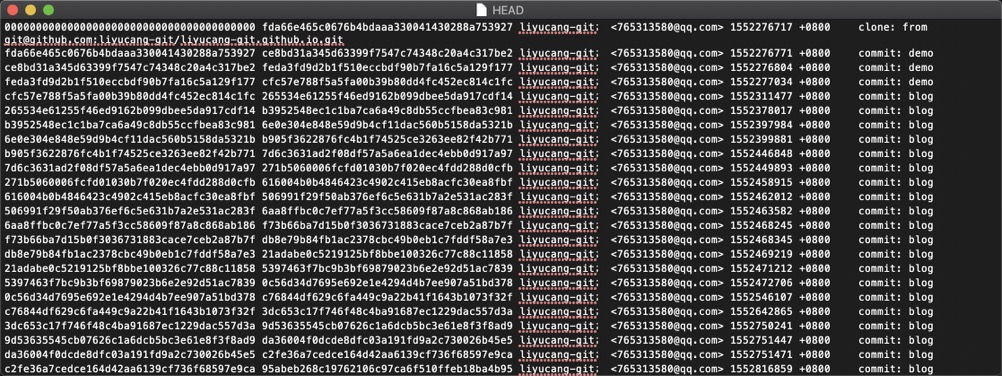
主要记录每次的变更操作,所有类型的变更都会记录,git reflog命令查询出的列表就是HEAD中存储的列表。
refs文件夹
refs文件夹包含heads文件夹、remotes文件夹和stash文件
-
stash文件存储的是所有你使用git stash命令暂存的记录,是一个列表。使用git stash list时,查询出的列表就是从stash中取出来的。
-
heads文件里面存储的是一系列的本地分支的对象,每个对象的文件名就是本地的一个分支名,使用git branch查看本地分支命令时,查询出的所有本地分支就是取的heads文件夹下所有文件的名称。
-
remotes文件夹里存储的是远端的一系列分支的对象,每个对象的文件名称就是远端的一个分支名称,使用git branch -a查看远端分支命令时,查询出的所有本地分支就是取的remotes文件夹下所有文件的名称。
objects文件夹
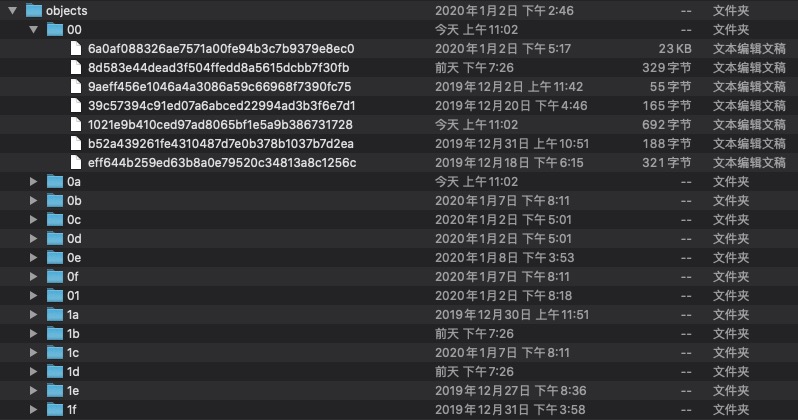
objects可以认为是一种“key-value数据库”,之所以将数据库打引号,是因为这个“git的数据库”不具备数据库的基本功能,而仅仅具备可以通过key值能够找到与之对应的value。
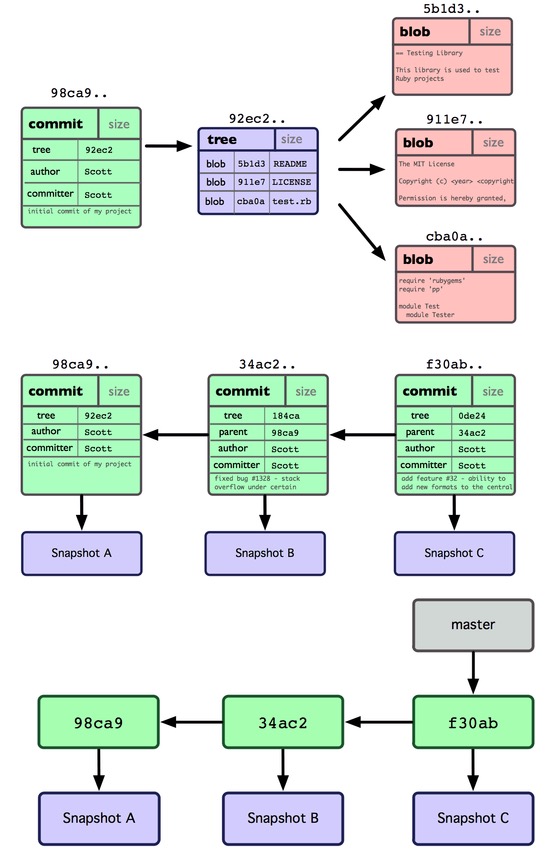
正如之前git原理中所说,git系统中主要存在三个实体,即“提交结点”、“节点内容”、“文件内容”。
提交结点实体
是整个git中的核心实体,提交节点中描述了提交节点之间的继承关系,即本次提交的内容是基于哪个或哪几个之前的提交的内容,提交结点实体之间的关系形成了一个DAG图,通过这个DAG图可以清晰地理顺整个项目的发展脉络,提交节点的内容如下:
tree <SHA1-signature>
[
parent <SHA1-signature>
...
]
author <author name> <\<author email\>> <timestamp> <time zone>
committer <committer name> <\<committer email\>> <timestamp> <time zone>
<commit message>
tree用于指向与该提交结点实体关联的节点内容实体。parent用于指向该提交节点实体所基于的之前的提交结点实体,可以看到,parent可以是多个。author用于记录本次提交的作者姓名、作者邮箱、作者所添加的内容时间以及时区。committer用于记录本次提交的提交者姓名、邮箱等内容。commit message用于记录当前提交的消息日志。
节点内容实体
用于记录本次提交时,提交中所包含的所有文件名,以及文件名所对应的key值,值得注意的是,可能由于查询性能的缘故,并非是仅记录本次提交时修改的文件,而是记录本次提交时所有的文件。另有一点值得注意的是,即便项目仓库中的文件不变,仅改变某个或某几个文件内容的前后两次提交,生成的前后两次提交节点中的tree值是不同的,换句话说,节点内容与提交节点是逻辑上的一对一关系。随着之后的讨论我们会很自然地得出这样的结论,这种一对一关系也同样是必须的,尽管在实际情况中允许两个不同的提交节点实体指向相同的节点内容实体。
文件内容实体
用于记录具体的文件内容。也就是说,在一个git仓库中,并非只有程序员们所能看到的当前项目文件夹下的代码版本,包括所有的历史代码都会在.git文件夹中有一个备份。
在objects文件夹中,三种数据实体无差别的以key-value的形式进行存储。因此一次提交操作,在objects文件夹中至少生成两个文件。存储时采用deflate算法对原始文件内容进行压缩,而key值是根据原始文件内容、文件大小等数据生成的消息摘要,在当前版本的git中,消息摘要生成算法采用SHA1算法,生成过程是将文件格式与文件长度组成头部,将文件内容作为尾部,由头部和尾部拼接后作为原文,经过SHA1算法计算之后得到该文件的160位长的SHA1签名。为防止一个文件夹内的文件数量过多,将签名每四位用字符表示十六进制数,于是得到一个长度为40的字符串,将字符串的前两个字符作为文件夹,后38个字符作为文件名进行存储。
观察仔细的同学可以发现,在三个实体的内容里,没有任何一个字段提供分支概念的信息。
三种实体在实际提交中的关联关系:
refs文件夹
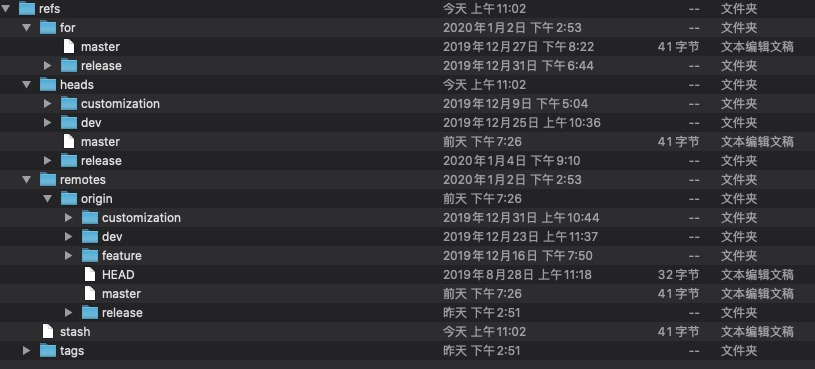
引用(Refs)是一种间接引用commit的方式。它是一种对用户来说更亲和的commit哈希的别名。使Git表示分支与标签的内部机制。
heads文件夹
描述了了在你仓库中所有的本地分支。每一个文件名对应了相应的分支,在文件夹内部的文件中你会看他对应的commit哈希。这个哈希是现在的分支最末端的那个commit的哈希。
remotes文件夹
将所有由git remote命令创建的所有远程分支存储为单独的子目录。在每个子目录中,可以发现被fetch进仓库的对应的远程分支。
要更改主分支的位置就必须要改到refs/heads/master的内容。同样地,创建一个新的分支就是把commit哈希写入新文件这样简单。这也是为何Git与SVN相比是如此轻量的部分原因。
tag文件夹
实际上以同样的方式工作着,只是其中存放的是tag而非分支。当使用git tag v1.0给当前分支,打上标签时,就会在tags文件夹下,生成对应文件,文件里存储的是当前分支所对应的哈希值,以后就可以使用v1.0这个标签来代替分支名称,通常发布稳定的线上版本时,使用这种做法。方便以后查询,因为使用标签容易记,更简洁。
stash文件
是使用git stash命令时,会将生成的git对象的哈希值存储到stash文件里,更进一步说stash文件中,就存了一个40位的哈希值。对应的git对象在objects文件夹里。使用git stash pop时,会先去stash文件中,找到该哈希值(或者也可以认为是指针),然后到对应的objects文件夹下,查找对应的git对象,将其中的数据取出来,转换成我们能看懂的代码。
COMMIT_EDITMSG文件
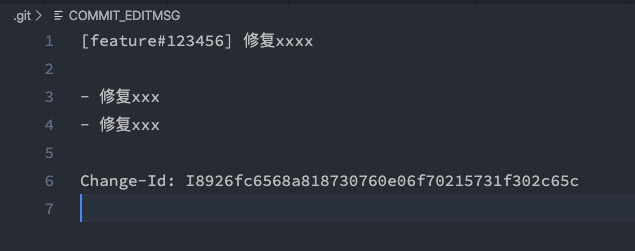
最新提交的一次Commit Message,git系统不会用到,给用户一个参考
config文件
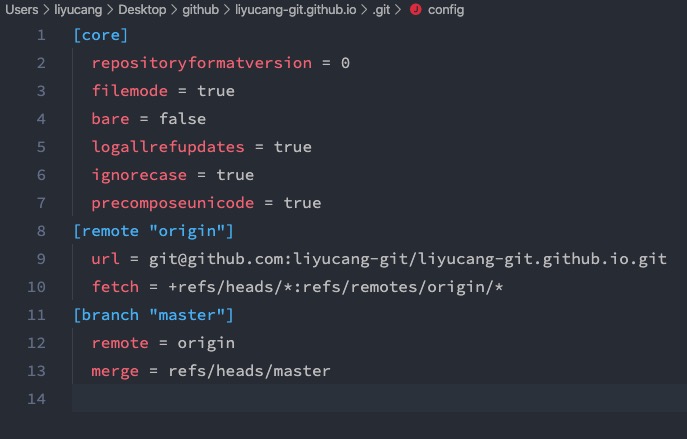
记录着仓库的配置信息。
info文件夹
用于存储该项目仓库的相关信息
description文件
仓库的描述信息,主要给gitweb等git托管系统使用
index文件
暂存区(stage),一个二进制文件。
HEAD文件
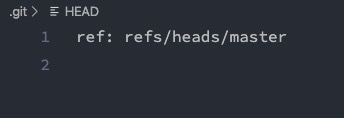
HEAD引用有可能是一个指向其他引用的象征性的引用,也可能是一个commit哈希。当你在主分支下,查看你的HEAD文件内容:
git checkout master
cat .git/HEAD
你将看到ref: refs/heads/master,这意味着HEAD指向refs/heads/master的引用。这就是为什么Git能获悉当前主分支被检出了的原因。如果切换到其他分支,HEAD的内容将被更新为指向那个分支。
但是如果你在commit的层面使用check out而非分支层面,HEAD的内容将会是一个commit哈希而非引用。这就是为什么Git能获悉它处在独立的状态的原因。
多数情况,HEAD仅仅是一个你可以直接使用的引用。其他仅仅在使用Git内部工作的底层脚本时才会用到。
FETCH_HEAD文件
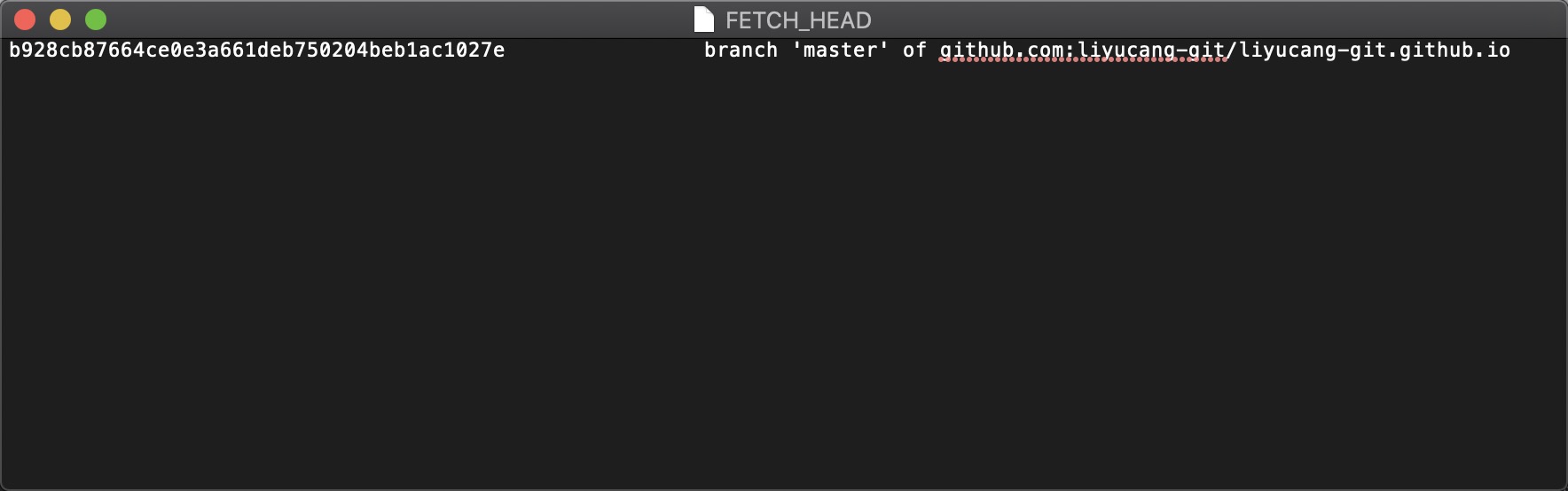
是一个版本链接,指向着目前已经从远程仓库取下来的分支的末端版本,包括所有远程分支。
git fetch
这将更新git remote 中所有的远程repo 所包含分支的最新commit-id, 将其记录到FETCH_HEAD文件中
ORIG_HEAD文件
针对某些 危险操作 ,Git通过记录HEAD指针的上次所在的位置ORIG_HEAD提供了回退的功能。当你发现某些操作失误了,比如错误的reset到了一个很早很早的版本,可以使用 git reset –hard ORIG_HEAD回退到上一次reset之前。
Git在1.8.5版本之后,加入了HEAD@{}功能,它通过一个链表记录HEAD的移动路径。
输入 git reflog,结果类似于:
$ git reflog
ea34578 HEAD@{0}: reset: moving to HEAD^
d628164 HEAD@{1}: commit: xxx
ea34578 HEAD@{2}: commit: xxxx
cb926e7 HEAD@{3}: commit: xxxx
每一次移动HEAD指针,Git都会将移动的路径通过链表串起来,链表头部的HEAD@{0}即HEAD指针。
但是HEAD@{1}并不一定是ORIG_HEAD!注意到,ORIG_HEAD仅仅是当进行 危险操作 (比如merge)时才会变更为HEAD指针的原值,而HEAD@{}链表则记录了每次HEAD的移动(包括commit)。
考虑以下情况:
1.commit -> 2.merge -> 3.commit
此时,HEAD@{0}、HEAD@{1}、HEAD@{2}分别指向3、2、1,而ORIG_HEAD指向的是1而非2。
显然,有了reflog命令后HEAD链表比不知道什么变过的ORIG_HEAD更好用,因此如果你使用的是1.8.5版本之后的Git,推荐使用HEAD{}链表来代替ORIG_HEAD指针。
packed-refs文件
对于大型仓库,Git将会周期性地运行垃圾回收将移除不必需要的对象,并将引用压缩至单个文件中,来提高性能。你可以执行下面命令来强制启动这一过程:
git gc
这将把在refs文件夹所有单独的分支与标签文件移动到在.git根目录中的一个叫做packed-refs的文件。
当查找一个引用时,git首先在refs目录下查找,如果未找到则到packed-refs文件中去查找。
如果你打开这个文件,你将会发现commit哈希与引用映射表:
00f54250cf4e549fdfcafe2cf9a2c90bc3800285 refs/heads/feature
0e25143693cfe9d5c2e83944bbaf6d3c4505eb17 refs/heads/master
bb883e4c91c870b5fed88fd36696e752fb6cf8e6 refs/tags/v0.9
垃圾回收对于正常的Git功能并不会有任何影响。但是,如果你想知道你的.git/refs文件为什么是空的话,现在你知道答案了。
相关运用
代码质量检查
在项目git init后,在.git/hooks文件中,有一些.simple结尾的钩子示例脚本,如果想启用对应的钩子函数,只需手动删除后缀。
我们以yorkie为例,给大家展示如何利用git hooks来进行提交前的代码检测。
yorkie使用
使用yorkie后,我们不再需要借助scripts来执行提交前的代码检测任务:
{
"scripts": {
- "precommit": "lint-staged",
- "commitmsg": "node scripts/verify-commit-msg.js"
},
+ "gitHooks": {
+ "pre-commit": "lint-staged",
+ "commit-msg": "node scripts/verify-commit-msg.js"
+ }
"lint-staged": {
"*.js": [
"eslint --fix",
"git add"
]
}
}
利用git diff,只lint当前改动的文件,lint-staged就非常准确的解决了这一问题,从这个包名,就可以看出,Run linters on git staged files,只针对改动的文件进行处理。
使用了eslint,需要配置.eslintrc, lint-staged还有一个好处,可以在lint后,更加灵活,执行其他脚本,尝试进行修改错误,比如 eslint –fix 检查后并修复错误。
上面列出的vue 文件使用了类似的配置,另外增加了 commit-msg 钩子,对提交说明进行检查,在 scripts/verify-commit-msg.js文件中可以找到检查脚本,
const chalk = require('chalk')
const msgPath = process.env.GIT_PARAMS
const msg = require('fs').readFileSync(msgPath, 'utf-8').trim()
const commitRE = /^(revert: )?(feat|fix|polish|docs|style|refactor|perf|test|workflow|ci|chore|types|build)(\(.+\))?: .{1,50}/
if (!commitRE.test(msg)) {
console.log()
console.error(
` ${chalk.bgRed.white(' ERROR ')} ${chalk.red(`invalid commit message format.`)}\n\n` +
chalk.red(` Proper commit message format is required for automated changelog generation. Examples:\n\n`) +
` ${chalk.green(`feat(compiler): add 'comments' option`)}\n` +
` ${chalk.green(`fix(v-model): handle events on blur (close #28)`)}\n\n` +
chalk.red(` See .github/COMMIT_CONVENTION.md for more details.\n`) +
chalk.red(` You can also use ${chalk.cyan(`npm run commit`)} to interactively generate a commit message.\n`)
)
process.exit(1)
}
yorkie源码解析
找到yorkie的package.json文件:
...
"scripts": {
"format": "prettier --single-quote --no-semi --write **/*.js",
"install": "node bin/install.js",
"test": "jest",
"uninstall": "node bin/uninstall.js"
},
...
发现yorkie会在包安装和卸载的时候执行对应的脚本,我们继续找到安装脚本:
'use strict'
const fs = require('fs')
const path = require('path')
const findParent = require('./utils/find-parent')
const findHooksDir = require('./utils/find-hooks-dir')
const getHookScript = require('./utils/get-hook-script')
const is = require('./utils/is')
const hooks = require('./hooks.json')
const SKIP = 'SKIP'
const UPDATE = 'UPDATE'
const MIGRATE_GHOOKS = 'MIGRATE_GHOOKS'
const MIGRATE_PRE_COMMIT = 'MIGRATE_PRE_COMMIT'
const CREATE = 'CREATE'
function write(filename, data) {
fs.writeFileSync(filename, data)
fs.chmodSync(filename, parseInt('0755', 8))
}
function createHook(depDir, projectDir, hooksDir, hookName, runnerPath) {
const filename = path.join(hooksDir, hookName)
let packageDir
// prioritize package.json next to .git
// this avoids double-install in lerna monorepos where both root and sub
// package depends on this module
if (fs.existsSync(path.join(projectDir, 'package.json'))) {
packageDir = projectDir
} else {
packageDir = findParent(depDir, 'package.json')
}
// In order to support projects with package.json in a different directory
// than .git, find relative path from project directory to package.json
const relativePath = path.join('.', path.relative(projectDir, packageDir))
const hookScript = getHookScript(hookName, relativePath, runnerPath)
// Create hooks directory if needed
if (!fs.existsSync(hooksDir)) fs.mkdirSync(hooksDir)
if (!fs.existsSync(filename)) {
write(filename, hookScript)
return CREATE
}
if (is.ghooks(filename)) {
write(filename, hookScript)
return MIGRATE_GHOOKS
}
if (is.preCommit(filename)) {
write(filename, hookScript)
return MIGRATE_PRE_COMMIT
}
if (is.huskyOrYorkie(filename)) {
write(filename, hookScript)
return UPDATE
}
return SKIP
}
function installFrom(depDir) {
try {
const isInSubNodeModule = (depDir.match(/node_modules/g) || []).length > 1
if (isInSubNodeModule) {
return console.log(
"trying to install from sub 'node_module' directory,",
'skipping Git hooks installation'
)
}
const projectDir = findParent(depDir, 'package.json')
const hooksDir = findHooksDir(projectDir)
const runnerPath = './node_modules/yorkie/src/runner.js'
if (hooksDir) {
hooks
.map(function(hookName) {
return {
hookName: hookName,
action: createHook(depDir, projectDir, hooksDir, hookName, runnerPath)
}
})
.forEach(function(item) {
switch (item.action) {
case MIGRATE_GHOOKS:
console.log(`migrating existing ghooks ${item.hookName} script`)
break
case MIGRATE_PRE_COMMIT:
console.log(
`migrating existing pre-commit ${item.hookName} script`
)
break
case UPDATE:
break
case SKIP:
console.log(`skipping ${item.hookName} hook (existing user hook)`)
break
case CREATE:
break
default:
console.error('Unknown action')
}
})
console.log('done\n')
} else {
console.log("can't find .git directory, skipping Git hooks installation")
}
} catch (e) {
console.error(e)
}
}
module.exports = installFrom
其中createHook函数会去项目的.git/hooks文件夹下查找如下名字的钩子执行文件,如果不存在或者是被认为可以覆盖的钩子执行文件,yorkie构造自己的钩子执行文件写入项目中。
// hooks.json
[
"applypatch-msg",
"pre-applypatch",
"post-applypatch",
"pre-commit",
"prepare-commit-msg",
"commit-msg",
"post-commit",
"pre-rebase",
"post-checkout",
"post-merge",
"pre-push",
"pre-receive",
"update",
"post-receive",
"post-update",
"push-to-checkout",
"pre-auto-gc",
"post-rewrite",
"sendemail-validate"
]
我们来看写入的钩子执行文件,由于所有的钩子文件都是一个模版,我们以commit-msg为例给大家讲解:
...
# Run hook
node "./node_modules/yorkie/src/runner.js" commit-msg || {
echo
echo "commit-msg hook failed (cannot be bypassed with --no-verify due to Git specs)"
exit 1
}
...
这里只展示了关键内容,git钩子文件执行了./node_modules/yorkie/src/runner.js文件,并且传入对应但钩子名,这里是commit-msg。
接着看runner.js:
const fs = require('fs')
const path = require('path')
const execa = require('execa')
const cwd = process.cwd()
const pkg = fs.readFileSync(path.join(cwd, 'package.json'))
const hooks = JSON.parse(pkg).gitHooks
if (!hooks) {
process.exit(0)
}
const hook = process.argv[2]
const command = hooks[hook]
if (!command) {
process.exit(0)
}
console.log(` > running ${hook} hook: ${command}`)
try {
execa.shellSync(command, { stdio: 'inherit' })
} catch (e) {
process.exit(1)
}
内容很简单,从项目但package.json中找出对应钩子的执行命令,并执行,如果报错则退出git commit。这里即执行:
node scripts/verify-commit-msg.js
我们最后再看看卸载方法:
'use strict'
const fs = require('fs')
const hooks = require('./hooks.json')
const findParent = require('./utils/find-parent')
const findHooksDir = require('./utils/find-hooks-dir')
const is = require('./utils/is')
function removeHook(dir, name) {
const filename = `${dir}/${name}`
if (fs.existsSync(filename) && is.huskyOrYorkie(filename)) {
fs.unlinkSync(`${dir}/${name}`)
}
}
function uninstallFrom(huskyDir) {
try {
const hooksDir = findHooksDir(findParent(huskyDir, '.git'))
hooks.forEach(function(hookName) {
removeHook(hooksDir, hookName)
})
console.log('done\n')
} catch (e) {
console.error(e)
}
}
module.exports = uninstallFrom
代码依旧很简单,即删除我们安装时加上的git钩子文件。
代码中获取git相关信息
我们也可以获取到git相关信息来方便我们在报错时进行调试。
首先定义一个获取git信息的函数,注意这里需要区分代码是在一个分支上还是在一个提交点上:
exports.getLastGitCommit = () => {
// ref: refs/heads/master or 747d122e7f54548c534e3247ad39e1ba2ffe5076
const HEAD = fs.readFileSync('.git/HEAD').toString().trim();
// 在一个commit提交点上,没有对应的分支、tag
if (!HEAD.includes(':')) {
return {
commitId: HEAD,
};
}
const branch = HEAD.substring(5); // refs/heads/master
const head = (`.git/${branch}`); // .git/refs/heads/master
const commitId = fs.readFileSync(head).toString().trim(); // 747d122e7f54548c534e3247ad39e1ba2ffe5076
const exec = require('child_process').execSync;
const tag = exec(`git tag --contains ${commitId}`).toString().trim();
return {
commitId,
branch,
tag
}
};
然后在webpack中使用插件定义变量:
...
plugins: [
new webpack.DefinePlugin({
__VERSION__: JSON.stringify(utils.getLastGitCommit()),
}),
]
...
最后定义调试函数:
// 全局调试工具,集中挂载在window.test上,禁止在项目其他地方挂载全局变量或方法
const test = {};
test.getCurrentVersion = () => {
const {
commitId = '',
branch = '',
tag = ''
} = __VERSION__;
console.log(`%ccommitId:%c${commitId}`,
'color: #fff; background: green; font-size: 10px; padding: 2px 4px; margin-right: 4px; border-radius: 4px',
'',
);
console.log(`%cbranch:%c${branch}`,
'color: #fff; background: green; font-size: 10px; padding: 2px 4px; margin-right: 4px; border-radius: 4px',
'',
);
console.log(`%ctag:%c${tag}`,
'color: #fff; background: green; font-size: 10px; padding: 2px 4px; margin-right: 4px; border-radius: 4px',
'',
);
};
if (window) {
window.test = test
}