js 中的文件和二进制数据的操作
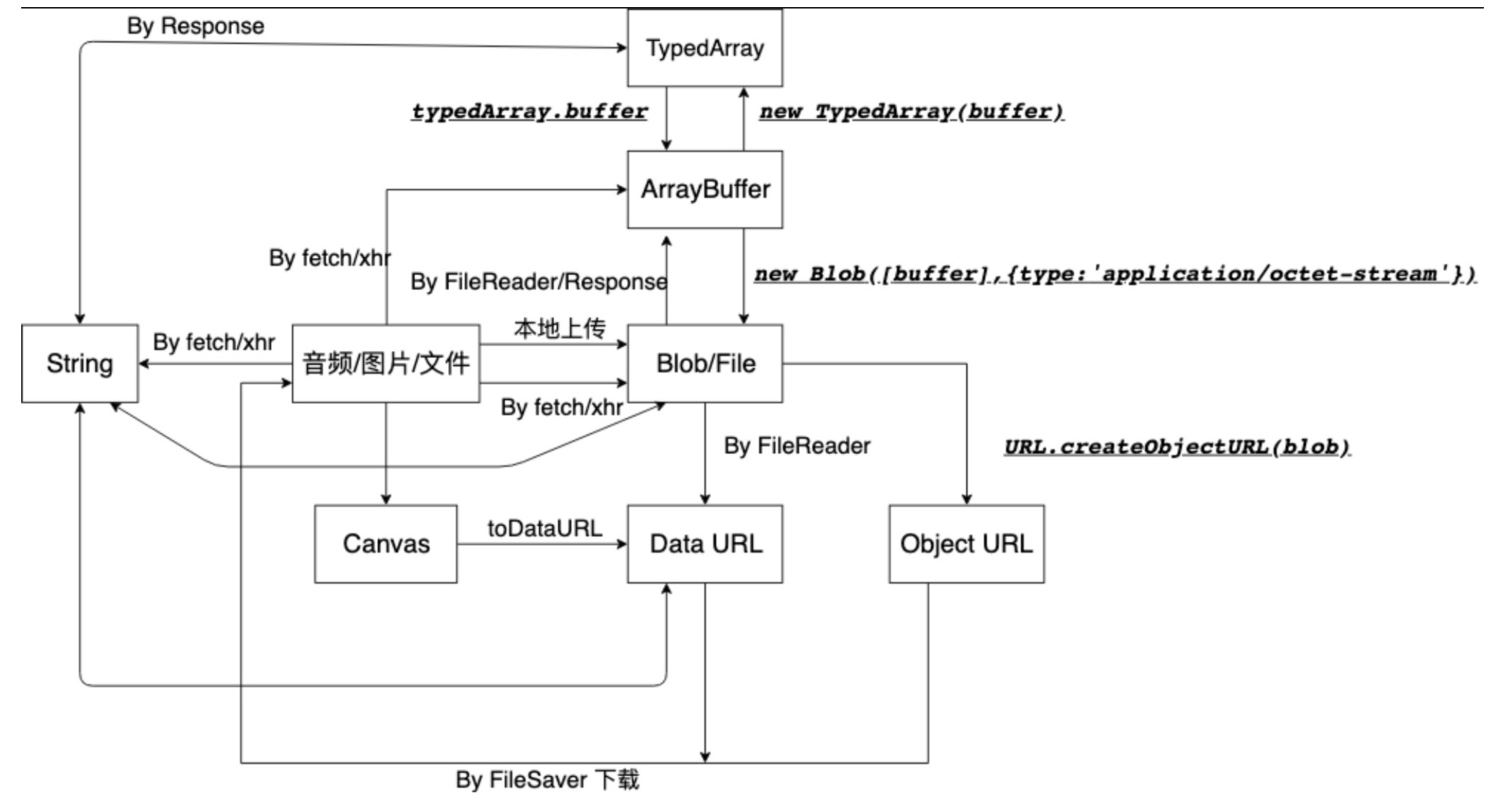
本篇文章总结了浏览器端的二进制以及有关数据之间的转化,如 ArrayBuffer,TypedArray,Blob,DataURL,ObjectURL,Text 之间的互相转换。为了更好的理解与方便以后的查询,特意做了一张图做总结。
为了后续的方便,这里简单写一个函数,用来下载一个链接:
function download (url, name) {
const a = document.createElement('a')
a.download = name
a.rel = 'noopener'
a.href = url
// 触发模拟点击
a.dispatchEvent(new MouseEvent('click'))
// 或者 a.click()
}
Blob 对象
Blob(Binary Large Object)对象代表了一段二进制数据,提供了一系列操作接口。其他操作二进制数据的 API(比如 File 对象),都是建立在 Blob 对象基础上的,继承了它的属性和方法。
生成 Blob 对象有两种方法:一种是使用 Blob 构造函数,另一种是对现有的 Blob 对象使用 slice 方法切出一部分。
(1)Blob 构造函数,接受两个参数。
第一个参数必须是个 Array 类型的,哪怕你只有一项,也必须用 [ ] 包着,如 [‘hello’]。
第二个参数是个可选的,是个对象,有 2 个选项,type 和 endings,type 指定第一个参数的 MIME-Type, endings 指定第一个参数的数据格式,其可选值有 transparent(不变,默认) 和 native(随系统转换)
var myBlob = new Blob(["<a id=\"a\"><b id=\"b\">hey!<\/b><\/a>"], { "type" : "text\/xml" });
const blob = new Blob(['hello file-reader'], { type: 'text/plain'});
下面是一个利用 Blob 对象,生成可下载文件的例子:
var blob = new Blob(["Hello 你好"]);
download(window.URL.createObjectURL(blob), hellow.txt)
上面的代码生成了一个超级链接,点击后提示下载文本文件 hello-world.txt,文件内容为”Hello 你好”。
(2)Blob.slice() 方法可以返回一个新的 Blob 对象,包含了源 Blob 对象中指定范围内的数据, 共接收 3 个参数,前两个参数和 Array.slice 的参数类似。
参数 1:开始索引,默认为 0 参数 2:截取结束索引(不包括当前值) 参数 3:新 Blob 的 MIME 类型,默认为空字符串
const newBlob = blob.slice(0, 5, 'text/plain');
下面是一个使用 XMLHttpRequest 对象,将大文件分割上传的例子。
function upload(blobOrFile) {
var xhr = new XMLHttpRequest();
xhr.open('POST', '/server', true);
xhr.onload = function(e) { ... };
xhr.send(blobOrFile);
}
document.querySelector('input[type="file"]').addEventListener('change', function(e) {
var blob = this.files[0];
const BYTES_PER_CHUNK = 1024 * 1024; // 1MB chunk sizes.
const SIZE = blob.size;
var start = 0;
var end = BYTES_PER_CHUNK;
while(start < SIZE) {
upload(blob.slice(start, end));
start = end;
end = start + BYTES_PER_CHUNK;
}
}, false);
})();
(3)Blob 对象有两个只读属性:
- size:二进制数据的大小,单位为字节。
- type:二进制数据的 MIME 类型,全部为小写,如果类型未知,则该值为空字符串。
在 Ajax 操作中,如果 xhr.responseType 设为 blob,接收的就是二进制数据。
FileList 对象
FileList 对象针对表单的 file 控件。当用户通过 file 控件选取文件后,这个控件的 files 属性值就是 FileList 对象。它在结构上类似于数组,包含用户选取的多个文件。
<input type="file" id="input" onchange="console.log(this.files.length)" multiple />
当用户选取文件后,就可以读取该文件。
var selected_file = document.getElementById('input').files[0];
采用拖放方式,也可以得到 FileList 对象。
var dropZone = document.getElementById('drop_zone');
dropZone.addEventListener('drop', handleFileSelect, false);
function handleFileSelect(evt) {
evt.stopPropagation();
evt.preventDefault();
var files = evt.dataTransfer.files; // FileList object.
// ...
}
上面代码的 handleFileSelect 是拖放事件的回调函数,它的参数 evt 是一个事件对象,该参数的 dataTransfer.files 属性就是一个 FileList 对象,里面包含了拖放的文件。
File API
File API 提供 File 对象,它是 FileList 对象的成员,包含了文件的一些元信息,比如文件名、上次改动时间、文件大小和文件类型。
var selected_file = document.getElementById('input').files[0];
var fileName = selected_file.name;
var fileSize = selected_file.size;
var fileType = selected_file.type;
File 对象的属性值如下。
- name:文件名,该属性只读。
- size:文件大小,单位为字节,该属性只读。
- type:文件的 MIME 类型,如果分辨不出类型,则为空字符串,该属性只读。
- lastModified:文件的上次修改时间,格式为时间戳。
- lastModifiedDate:文件的上次修改时间,格式为 Date 对象实例。
$('#upload-file').files[0]
// {
// lastModified: 1449370355682,
// lastModifiedDate: Sun Dec 06 2015 10:52:35 GMT+0800 (CST),
// name: "HTTP 2 is here Goodbye SPDY Not quite yet.png",
// size: 17044,
// type: "image/png"
// }
FileReader API
FileReader API 用于读取文件,即把文件内容读入内存。它的参数是 File 对象或 Blob 对象。
对于不同类型的文件,FileReader 提供不同的方法读取文件。
-
readAsBinaryString(Blob|File):返回二进制字符串,该字符串每个字节包含一个 0 到 255 之间的整数。 -
readAsText(Blob|File, opt_encoding):返回文本字符串。默认情况下,文本编码格式是’UTF-8’,可以通过可选的格式参数,指定其他编码格式的文本。 -
readAsDataURL(Blob|File):返回一个基于 Base64 编码的 data-uri 对象。 -
readAsArrayBuffer(Blob|File):返回一个 ArrayBuffer 对象。
readAsText 方法用于读取文本文件,它的第一个参数是 File 或 Blob 对象,第二个参数是前一个参数的编码方法,如果省略就默认为 UTF-8 编码。该方法是异步方法,一般监听 onload 事件,用来确定文件是否加载结束,方法是判断 FileReader 实例的 result 属性是否有值。其他三种读取方法,用法与 readAsText 方法类似。
var reader = new FileReader();
reader.onload = function(e) {
var text = reader.result;
}
reader.readAsText(file, encoding);
readAsDataURL 方法返回一个 data URL,它的作用基本上是将文件数据进行 Base64 编码。如果资源过大,地址便会很长。 使用以下形式表示。
data:[<mediatype>][;base64],<data>
先来一个 hello, world。把以下地址粘入地址栏,会访问到 hello, world。
data:text/html,<h1>Hello%2C%20World!</h1>
你也可以将返回值设为图像的 src 属性:
var file = document.getElementById('destination').files[0];
if(file.type.indexOf('image') !== -1) {
var reader = new FileReader();
reader.onload = function (e) {
var dataURL = reader.result;
}
reader.readAsDataURL(file);
}
readAsBinaryString 方法可以读取任意类型的文件,而不仅仅是文本文件,返回文件的原始的二进制内容。这个方法与 XMLHttpRequest.sendAsBinary 方法结合使用,就可以使用 JavaScript 上传任意文件到服务器。
var reader = new FileReader();
reader.onload = function(e) {
var rawData = reader.result;
}
reader.readAsBinaryString(file);
readAsArrayBuffer 方法读取文件,返回一个类型化数组(ArrayBuffer),即固定长度的二进制缓存数据。在文件操作时(比如将 JPEG 图像转为 PNG 图像),这个方法非常方便。
var reader = new FileReader();
reader.onload = function(e) {
var arrayBuffer = reader.result;
}
reader.readAsArrayBuffer(file);
除了以上四种不同的读取文件方法,FileReader API 还有一个 abort 方法,用于中止文件上传。
var reader = new FileReader();
reader.abort();
FileReader 对象采用异步方式读取文件,可以为一系列事件指定回调函数。
- onabort 方法:读取中断或调用 reader.abort()方法时触发。
- onerror 方法:读取出错时触发。
- onload 方法:读取成功后触发。
- onloadend 方法:读取完成后触发,不管是否成功。触发顺序排在 onload 或 onerror 后面。
- onloadstart 方法:读取将要开始时触发。
- onprogress 方法:读取过程中周期性触发。
下面的代码是如何展示文本文件的内容。
var reader = new FileReader();
reader.onload = function(e) {
console.log(e.target.result);
}
reader.readAsText(blob);
onload 事件的回调函数接受一个事件对象,该对象的 target.result 就是文件的内容。
下面是一个使用 readAsDataURL 方法,为 img 元素添加 src 属性的例子。
var reader = new FileReader();
reader.onload = function(e) {
document.createElement('img').src = e.target.result;
};
reader.readAsDataURL(f);
下面是一个 onerror 事件回调函数的例子。
var reader = new FileReader();
reader.onerror = errorHandler;
function errorHandler(evt) {
switch(evt.target.error.code) {
case evt.target.error.NOT_FOUND_ERR:
alert('File Not Found!');
break;
case evt.target.error.NOT_READABLE_ERR:
alert('File is not readable');
break;
case evt.target.error.ABORT_ERR:
break;
default:
alert('An error occurred reading this file.');
};
}
下面是一个 onprogress 事件回调函数的例子,主要用来显示读取进度。
var reader = new FileReader();
reader.onprogress = updateProgress;
function updateProgress(evt) {
if (evt.lengthComputable) {
var percentLoaded = Math.round((evt.loaded / evt.totalEric Bidelman) * 100);
var progress = document.querySelector('.percent');
if (percentLoaded < 100) {
progress.style.width = percentLoaded + '%';
progress.textContent = percentLoaded + '%';
}
}
}
读取大文件的时候,可以利用 Blob 对象的 slice 方法,将大文件分成小段,逐一读取,这样可以加快处理速度。
由于 FileReader 可以把文件读取成各种格式,所以这里可以利用这个特性,进行编码的转换,如 ArrayBuffer, Blob 对象 和 字符串, base64 之间的相互转换/单向转换, 部分类型只能单向转换,是因为 FileReader 只接受 File 或 Blob 类型的数据(事实上 File 也 Blob 的一种),如果数据无法转换成指定类型,就无法用 FileReader 转换.
var reader = new FileReader();
reader.onload = function(e){
console.log(e.target.result);
}
reader.readAsDataURL(new Blob(['hello 你好']));
// data:application/octet-stream;base64,aGVsbG8g5L2g5aW9
URL 对象
URL 对象用于生成指向 File 对象或 Blob 对象的 URL。
var objecturl = window.URL.createObjectURL(blob);
上面的代码会对二进制数据生成一个 URL,类似于“blob:http%3A//test.com/666e6730-f45c-47c1-8012-ccc706f17191”。这个 URL 可以放置于任何通常可以放置 URL 的地方,比如 img 标签的 src 属性。需要注意的是,即使是同样的二进制数据,每调用一次 URL.createObjectURL 方法,就会得到一个不一样的 URL。
这个 URL 的存在时间,等同于网页的存在时间,一旦网页刷新或卸载,这个 URL 就失效。除此之外,也可以手动调用 URL.revokeObjectURL 方法,使 URL 失效。
window.URL.revokeObjectURL(objectURL);
下面是一个利用 URL 对象,在网页插入图片的例子。
var img = document.createElement("img");
img.src = window.URL.createObjectURL(files[0]);
img.height = 60;
img.onload = function(e) {
window.URL.revokeObjectURL(this.src);
}
body.appendChild(img);
var info = document.createElement("span");
info.innerHTML = files[i].name + ": " + files[i].size + " bytes";
body.appendChild(info);
还有一个本机视频预览的例子。
var video = document.getElementById('video');
var obj_url = window.URL.createObjectURL(blob);
video.src = obj_url;
video.play()
window.URL.revokeObjectURL(obj_url);
Base64
所谓 Base64,就是说选出 64 个字符—-小写字母 a-z、大写字母 A-Z、数字 0-9、符号”+”、”/”(再加上作为垫字的”=”,实际上是 65 个字符)—-作为一个基本字符集。然后,其他所有符号都转换成这个字符集中的字符。
具体来说,转换方式可以分为四步。
-
将每三个字节作为一组,一共是 24 个二进制位。
-
将这 24 个二进制位分为四组,每个组有 6 个二进制位。
-
在每组前面加两个 00,扩展成 32 个二进制位,即四个字节。
-
根据下表,得到扩展后的每个字节的对应符号,这就是 Base64 的编码值。
0 A 17 R 34 i 51 z
1 B 18 S 35 j 52 0
2 C 19 T 36 k 53 1
3 D 20 U 37 l 54 2
4 E 21 V 38 m 55 3
5 F 22 W 39 n 56 4
6 G 23 X 40 o 57 5
7 H 24 Y 41 p 58 6
8 I 25 Z 42 q 59 7
9 J 26 a 43 r 60 8
10 K 27 b 44 s 61 9
11 L 28 c 45 t 62 +
12 M 29 d 46 u 63 /
13 N 30 e 47 v
14 O 31 f 48 w
15 P 32 g 49 x
16 Q 33 h 50 y
因为,Base64 将三个字节转化成四个字节,因此 Base64 编码后的文本,会比原文本大出三分之一左右。
举一个具体的实例,演示英语单词 Man 如何转成 Base64 编码。
| 字符 | M | a | n |
|---|---|---|---|
| asc 码 | 77 | 97 | 110 |
| 二进制表示 | 01001101 | 01100001 | 01101110 |
| 二进制表示 | 010011 | 010110 | 000101 | 101110 |
|---|---|---|---|---|
| base64 对应字符 | T | W | F | u |
-
“M”、”a”、”n”的 ASCII 值分别是 77、97、110,对应的二进制值是 01001101、01100001、01101110,将它们连成一个 24 位的二进制字符串 010011010110000101101110。
-
将这个 24 位的二进制字符串分成 4 组,每组 6 个二进制位:010011、010110、000101、101110。
-
在每组前面加两个 00,扩展成 32 个二进制位,即四个字节:00010011、00010110、00000101、00101110。它们的十进制值分别是 19、22、5、46。
-
根据上表,得到每个值对应 Base64 编码,即 T、W、F、u。
因此,Man 的 Base64 编码就是 TWFu。
如果字节数不足三,则这样处理:
a)二个字节的情况:将这二个字节的一共 16 个二进制位,按照上面的规则,转成三组,最后一组除了前面加两个 0 以外,后面也要加两个 0。这样得到一个三位的 Base64 编码,再在末尾补上一个”=”号。
比如,”Ma”这个字符串是两个字节,可以转化成三组 00010011、00010110、00010000 以后,对应 Base64 值分别为 T、W、E,再补上一个”=”号,因此”Ma”的 Base64 编码就是 TWE=。
b)一个字节的情况:将这一个字节的 8 个二进制位,按照上面的规则转成二组,最后一组除了前面加二个 0 以外,后面再加 4 个 0。这样得到一个二位的 Base64 编码,再在末尾补上两个”=”号。
比如,”M”这个字母是一个字节,可以转化为二组 00010011、00010000,对应的 Base64 值分别为 T、Q,再补上二个”=”号,因此”M”的 Base64 编码就是 TQ==。
再举一个中文的例子,汉字”严”如何转化成 Base64 编码?
这里需要注意,汉字本身可以有多种编码,比如 gb2312、utf-8、gbk 等等,每一种编码的 Base64 对应值都不一样。下面的例子以 utf-8 为例。
首先,”严”的 utf-8 编码为 E4B8A5,写成二进制就是三字节的”11100100 10111000 10100101”。将这个 24 位的二进制字符串,按照第 3 节中的规则,转换成四组一共 32 位的二进制值”00111001 00001011 00100010 00100101”,相应的十进制数为 57、11、34、37,它们对应的 Base64 值就为 5、L、i、l。
所以,汉字”严”(utf-8 编码)的 Base64 值就是 5Lil。
var reader = new FileReader();
reader.onload = function(e) {
console.log(reader.result);
}
reader.readAsArrayBuffer(new Blob(['严']));
// ArrayBuffer(3) {}
[[Int8Array]]: Int8Array(3) [-28, -72, -91]
[[Uint8Array]]: Uint8Array(3) [228, 184, 165]
[228, 184, 165] 即 11100100 10111000 10100101。
这一节介绍如何用 Javascript 语言进行 Base64 编码
首先,假定网页的编码是 utf-8,这里就会产生一个问题。因为 Javascript 内部的字符串,都以 utf-16 的形式进行保存,因此编码的时候,我们首先必须将 utf-16 的值转成 utf-8 再编码,解码的时候,则是解码后还需要将 utf-8 的值转回成 utf-16。
function utf16to8(str) {
let out,
i,
len,
c;
out = '';
len = str.length;
for (i = 0; i < len; i++) {
c = str.charCodeAt(i);
if ((c >= 0x0001) && (c <= 0x007F)) {
out += str.charAt(i);
} else if (c > 0x07FF) {
out += String.fromCharCode(0xE0 | ((c >> 12) & 0x0F));
out += String.fromCharCode(0x80 | ((c >> 6) & 0x3F));
out += String.fromCharCode(0x80 | ((c >> 0) & 0x3F));
} else {
out += String.fromCharCode(0xC0 | ((c >> 6) & 0x1F));
out += String.fromCharCode(0x80 | ((c >> 0) & 0x3F));
}
}
return out;
}
function utf8to16(str) {
let out,
i,
len,
c;
let char2,
char3;
out = '';
len = str.length;
i = 0;
while (i < len) {
c = str.charCodeAt(i++);
switch (c >> 4) {
case 0: case 1: case 2: case 3: case 4: case 5: case 6: case 7:
// 0xxxxxxx
out += str.charAt(i - 1);
break;
case 12: case 13:
// 110x xxxx 10xx xxxx
char2 = str.charCodeAt(i++);
out += String.fromCharCode(((c & 0x1F) << 6) | (char2 & 0x3F));
break;
case 14:
// 1110 xxxx 10xx xxxx 10xx xxxx
char2 = str.charCodeAt(i++);
char3 = str.charCodeAt(i++);
out += String.fromCharCode(((c & 0x0F) << 12) |
((char2 & 0x3F) << 6) |
((char3 & 0x3F) << 0));
break;
}
}
return out;
}
上面的这段代码中定义了两个函数,utf16to8()用于将 utf-16 转成 utf-8,utf8to16 用于将 utf-8 转成 utf-16。
下面才是真正用于 base64 编码的函数。
const base64EncodeChars = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/';
const base64DecodeChars = new Array(
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, 62, -1, -1, -1, 63,
52, 53, 54, 55, 56, 57, 58, 59, 60, 61, -1, -1, -1, -1, -1, -1,
-1, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14,
15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, -1, -1, -1, -1, -1,
-1, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40,
41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, -1, -1, -1, -1, -1);
function base64encode(str) {
let out,
i,
len;
let c1,
c2,
c3;
len = str.length;
i = 0;
out = '';
while (i < len) {
c1 = str.charCodeAt(i++) & 0xff;
if (i == len) {
out += base64EncodeChars.charAt(c1 >> 2);
out += base64EncodeChars.charAt((c1 & 0x3) << 4);
out += '==';
break;
}
c2 = str.charCodeAt(i++);
if (i == len) {
out += base64EncodeChars.charAt(c1 >> 2);
out += base64EncodeChars.charAt(((c1 & 0x3) << 4) | ((c2 & 0xF0) >> 4));
out += base64EncodeChars.charAt((c2 & 0xF) << 2);
out += '=';
break;
}
c3 = str.charCodeAt(i++);
out += base64EncodeChars.charAt(c1 >> 2);
out += base64EncodeChars.charAt(((c1 & 0x3) << 4) | ((c2 & 0xF0) >> 4));
out += base64EncodeChars.charAt(((c2 & 0xF) << 2) | ((c3 & 0xC0) >> 6));
out += base64EncodeChars.charAt(c3 & 0x3F);
}
return out;
}
function base64decode(str) {
let c1,
c2,
c3,
c4;
let i,
len,
out;
len = str.length;
i = 0;
out = '';
while (i < len) {
/* c1 */
do {
c1 = base64DecodeChars[str.charCodeAt(i++) & 0xff];
} while (i < len && c1 == -1);
if (c1 == -1) { break; }
/* c2 */
do {
c2 = base64DecodeChars[str.charCodeAt(i++) & 0xff];
} while (i < len && c2 == -1);
if (c2 == -1) { break; }
out += String.fromCharCode((c1 << 2) | ((c2 & 0x30) >> 4));
/* c3 */
do {
c3 = str.charCodeAt(i++) & 0xff;
if (c3 == 61) { return out; }
c3 = base64DecodeChars[c3];
} while (i < len && c3 == -1);
if (c3 == -1) { break; }
out += String.fromCharCode(((c2 & 0XF) << 4) | ((c3 & 0x3C) >> 2));
/* c4 */
do {
c4 = str.charCodeAt(i++) & 0xff;
if (c4 == 61) { return out; }
c4 = base64DecodeChars[c4];
} while (i < len && c4 == -1);
if (c4 == -1) { break; }
out += String.fromCharCode(((c3 & 0x03) << 6) | c4);
}
return out;
}
上面代码中的 base64encode()用于编码,base64decode()用于解码。
因此,对 utf-8 字符进行编码要这样写:
sEncoded=base64encode(utf16to8(str));
然后,解码要这样写:
sDecoded=utf8to16(base64decode(sEncoded));
atob 和 btoa
js 中提供了 btoa()转码 和 atob() 解码的方法处理 Base64 格式
例如我们将 http://webxiaoma.com/assets/images/manong.jpg 进行编码和解码
let url = "http://webxiaoma.com/assets/images/manong.jpg"
let btoaStr = btoa(url) // 将url编码为Base64格式
//aHR0cDovL3dlYnhpYW9tYS5jb20vYXNzZXRzL2ltYWdlcy9tYW5vbmcuanBn
let atobStr = atob(btoaStr) //将Base64格式解码
//http://webxiaoma.com/assets/images/manong.jpg
btoa()转码 和 atob() 解码的中文问题
当我们要将中文编码为 Base64 格式后,在进行解码是会乱码,而在谷歌浏览器上在编码中文时会直接报错
let url = "你好"
let btoaStr = btoa(url) // 在谷歌浏览器上报错
我们这时需要借助 encodeURIComponent 和 decodeURIComponent 转义中文字符,这里是由于 btoa 仅支持 ASCII 字符序列,如果通过 encodeURIComponent 将中文字符编码成 ASCII 字符序列,再通过 btoa 进行 base64 编码。
let url = "你好"
let btoaStr = btoa(encodeURIComponent(url)) //编码: JUU0JUJEJUEwJUU1JUE1JUJE
let atobStr = decodeURIComponent(atob(btoaStr)) // 解码: 你好
第三方 Base64 工具
webtoolkit.base64 是一个第三方实现的 Base64 编码工具,完美的支持 unicode 编码的字符串。
Base64.encode('中文')
// "5Lit5paH"
Base64.decode('5Lit5paH');
// "中文"
另外,如果服务端为 Nodejs ,可用如下代码进行 base64 的编码和解码。
btoa: (s)->
(new Buffer(s, 'utf8')).toString('base64')
atob: (s)->
(new Buffer(s, 'base64').toString('utf8'))
ArrayBuffer
ArrayBuffer 对象、TypedArray 视图和 DataView 视图是 JavaScript 操作二进制数据的一个接口。这些对象早就存在,属于独立的规格(2011 年 2 月发布),ES6 将它们纳入了 ECMAScript 规格,并且增加了新的方法。它们都是以数组的语法处理二进制数据,所以统称为二进制数组。
这个接口的原始设计目的,与 WebGL 项目有关。所谓 WebGL,就是指浏览器与显卡之间的通信接口,为了满足 JavaScript 与显卡之间大量的、实时的数据交换,它们之间的数据通信必须是二进制的,而不能是传统的文本格式。文本格式传递一个 32 位整数,两端的 JavaScript 脚本与显卡都要进行格式转化,将非常耗时。这时要是存在一种机制,可以像 C 语言那样,直接操作字节,将 4 个字节的 32 位整数,以二进制形式原封不动地送入显卡,脚本的性能就会大幅提升。
二进制数组就是在这种背景下诞生的。它很像 C 语言的数组,允许开发者以数组下标的形式,直接操作内存,大大增强了 JavaScript 处理二进制数据的能力,使得开发者有可能通过 JavaScript 与操作系统的原生接口进行二进制通信。
二进制数组由三类对象组成。
(1)ArrayBuffer 对象:代表内存之中的一段二进制数据,可以通过“视图”进行操作。“视图”部署了数组接口,这意味着,可以用数组的方法操作内存。
(2)TypedArray 视图:共包括 9 种类型的视图,比如 Uint8Array(无符号 8 位整数)数组视图, Int16Array(16 位整数)数组视图, Float32Array(32 位浮点数)数组视图等等。
(3)DataView 视图:可以自定义复合格式的视图,比如第一个字节是 Uint8(无符号 8 位整数)、第二、三个字节是 Int16(16 位整数)、第四个字节开始是 Float32(32 位浮点数)等等,此外还可以自定义字节序。
简单说,ArrayBuffer 对象代表原始的二进制数据,TypedArray 视图用来读写简单类型的二进制数据,DataView 视图用来读写复杂类型的二进制数据。
TypedArray 视图支持的数据类型一共有 9 种(DataView 视图支持除 Uint8C 以外的其他 8 种)。
| 数据类型 | 字节长度 | 含义 | 对应的 C 语言类型 |
|---|---|---|---|
| Int8 | 1 | 8 位带符号整数 | signed char |
| Uint8 | 1 | 8 位不带符号整数 | unsigned char |
| Uint8C | 1 | 8 位不带符号整数(自动过滤溢出) | unsigned char |
| Int16 | 2 | 16 位带符号整数 | short |
| Uint16 | 2 | 16 位不带符号整数 | unsigned short |
| Int32 | 4 | 32 位带符号整数 | int |
| Uint32 | 4 | 32 位不带符号的整数 | unsigned int |
| Float32 | 4 | 32 位浮点数 | float |
| Float64 | 8 | 64 位浮点数 | double |
注意,二进制数组并不是真正的数组,而是类似数组的对象。
很多浏览器操作的 API,用到了二进制数组操作二进制数据,下面是其中的几个。
- Canvas
- Fetch API
- File API
- WebSockets
- XMLHttpRequest
ArrayBuffer 对象
概述
ArrayBuffer 对象代表储存二进制数据的一段内存,它不能直接读写,只能通过视图(TypedArray 视图和 DataView 视图)来读写,视图的作用是以指定格式解读二进制数据。
ArrayBuffer 也是一个构造函数,可以分配一段可以存放数据的连续内存区域。
const buf = new ArrayBuffer(32);
上面代码生成了一段 32 字节的内存区域,每个字节的值默认都是 0。可以看到,ArrayBuffer 构造函数的参数是所需要的内存大小(单位字节)。
为了读写这段内容,需要为它指定视图。DataView 视图的创建,需要提供 ArrayBuffer 对象实例作为参数。
const buf = new ArrayBuffer(32);
const dataView = new DataView(buf);
dataView.getUint8(0) // 0
上面代码对一段 32 字节的内存,建立 DataView 视图,然后以不带符号的 8 位整数格式,从头读取 8 位二进制数据,结果得到 0,因为原始内存的 ArrayBuffer 对象,默认所有位都是 0。
另一种 TypedArray 视图,与 DataView 视图的一个区别是,它不是一个构造函数,而是一组构造函数,代表不同的数据格式。
const buffer = new ArrayBuffer(12);
const x1 = new Int32Array(buffer);
x1[0] = 1;
const x2 = new Uint8Array(buffer);
x2[0] = 2;
x1[0] // 2
上面代码对同一段内存,分别建立两种视图:32 位带符号整数(Int32Array 构造函数)和 8 位不带符号整数(Uint8Array 构造函数)。由于两个视图对应的是同一段内存,一个视图修改底层内存,会影响到另一个视图。
TypedArray 视图的构造函数,除了接受 ArrayBuffer 实例作为参数,还可以接受普通数组作为参数,直接分配内存生成底层的 ArrayBuffer 实例,并同时完成对这段内存的赋值。
const typedArray = new Uint8Array([0,1,2]);
typedArray.length // 3
typedArray[0] = 5;
typedArray // [5, 1, 2]
上面代码使用 TypedArray 视图的 Uint8Array 构造函数,新建一个不带符号的 8 位整数视图。可以看到,Uint8Array 直接使用普通数组作为参数,对底层内存的赋值同时完成。
ArrayBuffer.prototype.byteLength
ArrayBuffer 实例的 byteLength 属性,返回所分配的内存区域的字节长度。
const buffer = new ArrayBuffer(32);
buffer.byteLength
// 32
如果要分配的内存区域很大,有可能分配失败(因为没有那么多的连续空余内存),所以有必要检查是否分配成功。
if (buffer.byteLength === n) {
// 成功
} else {
// 失败
}
ArrayBuffer.prototype.slice()
ArrayBuffer 实例有一个 slice 方法,允许将内存区域的一部分,拷贝生成一个新的 ArrayBuffer 对象。
const buffer = new ArrayBuffer(8);
const newBuffer = buffer.slice(0, 3);
上面代码拷贝 buffer 对象的前 3 个字节(从 0 开始,到第 3 个字节前面结束),生成一个新的 ArrayBuffer 对象。slice 方法其实包含两步,第一步是先分配一段新内存,第二步是将原来那个 ArrayBuffer 对象拷贝过去。
slice 方法接受两个参数,第一个参数表示拷贝开始的字节序号(含该字节),第二个参数表示拷贝截止的字节序号(不含该字节)。如果省略第二个参数,则默认到原 ArrayBuffer 对象的结尾。
除了 slice 方法,ArrayBuffer 对象不提供任何直接读写内存的方法,只允许在其上方建立视图,然后通过视图读写。
ArrayBuffer.isView()
ArrayBuffer 有一个静态方法 isView,返回一个布尔值,表示参数是否为 ArrayBuffer 的视图实例。这个方法大致相当于判断参数,是否为 TypedArray 实例或 DataView 实例。
const buffer = new ArrayBuffer(8);
ArrayBuffer.isView(buffer) // false
const v = new Int32Array(buffer);
ArrayBuffer.isView(v) // true
TypedArray 视图
概述
ArrayBuffer 对象作为内存区域,可以存放多种类型的数据。同一段内存,不同数据有不同的解读方式,这就叫做“视图”(view)。ArrayBuffer 有两种视图,一种是 TypedArray 视图,另一种是 DataView 视图。前者的数组成员都是同一个数据类型,后者的数组成员可以是不同的数据类型。
目前,TypedArray 视图一共包括 9 种类型,每一种视图都是一种构造函数。
- Int8Array:8 位有符号整数,长度 1 个字节。
- Uint8Array:8 位无符号整数,长度 1 个字节。
- Uint8ClampedArray:8 位无符号整数,长度 1 个字节,溢出处理不同。
- Int16Array:16 位有符号整数,长度 2 个字节。
- Uint16Array:16 位无符号整数,长度 2 个字节。
- Int32Array:32 位有符号整数,长度 4 个字节。
- Uint32Array:32 位无符号整数,长度 4 个字节。
- Float32Array:32 位浮点数,长度 4 个字节。
- Float64Array:64 位浮点数,长度 8 个字节。
这 9 个构造函数生成的数组,统称为 TypedArray 视图。它们很像普通数组,都有 length 属性,都能用方括号运算符([])获取单个元素,所有数组的方法,在它们上面都能使用。普通数组与 TypedArray 数组的差异主要在以下方面。
- TypedArray 数组的所有成员,都是同一种类型。
- TypedArray 数组的成员是连续的,不会有空位。
- TypedArray 数组成员的默认值为 0。比如,new Array(10)返回一个普通数组,里面没有任何成员,只是 10 个空位;new Uint8Array(10)返回一个 TypedArray 数组,里面 10 个成员都是 0。
- TypedArray 数组只是一层视图,本身不储存数据,它的数据都储存在底层的 ArrayBuffer 对象之中,要获取底层对象必须使用 buffer 属性。
构造函数
TypedArray 数组提供 9 种构造函数,用来生成相应类型的数组实例。
构造函数有多种用法。
(1)TypedArray(buffer, byteOffset=0, length?)
同一个 ArrayBuffer 对象之上,可以根据不同的数据类型,建立多个视图。
// 创建一个8字节的ArrayBuffer
const b = new ArrayBuffer(8);
// 创建一个指向b的Int32视图,开始于字节0,直到缓冲区的末尾
const v1 = new Int32Array(b);
// 创建一个指向b的Uint8视图,开始于字节2,直到缓冲区的末尾
const v2 = new Uint8Array(b, 2);
// 创建一个指向b的Int16视图,开始于字节2,长度为2
const v3 = new Int16Array(b, 2, 2);
上面代码在一段长度为 8 个字节的内存(b)之上,生成了三个视图:v1、v2 和 v3。
视图的构造函数可以接受三个参数:
- 第一个参数(必需):视图对应的底层 ArrayBuffer 对象。
- 第二个参数(可选):视图开始的字节序号,默认从 0 开始。
- 第三个参数(可选):视图包含的数据个数,默认直到本段内存区域结束。
因此,v1、v2 和 v3 是重叠的:v1[0]是一个 32 位整数,指向字节 0 ~字节 3;v2[0]是一个 8 位无符号整数,指向字节 2;v3[0]是一个 16 位整数,指向字节 2 ~字节 3。只要任何一个视图对内存有所修改,就会在另外两个视图上反应出来。
注意,byteOffset 必须与所要建立的数据类型一致,否则会报错。
const buffer = new ArrayBuffer(8);
const i16 = new Int16Array(buffer, 1);
// Uncaught RangeError: start offset of Int16Array should be a multiple of 2
上面代码中,新生成一个 8 个字节的 ArrayBuffer 对象,然后在这个对象的第一个字节,建立带符号的 16 位整数视图,结果报错。因为,带符号的 16 位整数需要两个字节,所以 byteOffset 参数必须能够被 2 整除。
如果想从任意字节开始解读 ArrayBuffer 对象,必须使用 DataView 视图,因为 TypedArray 视图只提供 9 种固定的解读格式。
(2)TypedArray(length)
视图还可以不通过 ArrayBuffer 对象,直接分配内存而生成。
const f64a = new Float64Array(8);
f64a[0] = 10;
f64a[1] = 20;
f64a[2] = f64a[0] + f64a[1];
上面代码生成一个 8 个成员的 Float64Array 数组(共 64 字节),然后依次对每个成员赋值。这时,视图构造函数的参数就是成员的个数。可以看到,视图数组的赋值操作与普通数组的操作毫无两样。
(3)TypedArray(typedArray)
TypedArray 数组的构造函数,可以接受另一个 TypedArray 实例作为参数。
const typedArray = new Int8Array(new Uint8Array(4));
上面代码中,Int8Array 构造函数接受一个 Uint8Array 实例作为参数。
注意,此时生成的新数组,只是复制了参数数组的值,对应的底层内存是不一样的。新数组会开辟一段新的内存储存数据,不会在原数组的内存之上建立视图。
const x = new Int8Array([1, 1]);
const y = new Int8Array(x);
x[0] // 1
y[0] // 1
x[0] = 2;
y[0] // 1
上面代码中,数组 y 是以数组 x 为模板而生成的,当 x 变动的时候,y 并没有变动。
如果想基于同一段内存,构造不同的视图,可以采用下面的写法。
const x = new Int8Array([1, 1]);
const y = new Int8Array(x.buffer);
x[0] // 1
y[0] // 1
x[0] = 2;
y[0] // 2
(4)TypedArray(arrayLikeObject)
构造函数的参数也可以是一个普通数组,然后直接生成 TypedArray 实例。
const typedArray = new Uint8Array([1, 2, 3, 4]);
注意,这时 TypedArray 视图会重新开辟内存,不会在原数组的内存上建立视图。
上面代码从一个普通的数组,生成一个 8 位无符号整数的 TypedArray 实例。
TypedArray 数组也可以转换回普通数组。
const normalArray = [...typedArray];
// or
const normalArray = Array.from(typedArray);
// or
const normalArray = Array.prototype.slice.call(typedArray);
数组方法
普通数组的操作方法和属性,对 TypedArray 数组完全适用。
注意,TypedArray 数组没有 concat 方法。如果想要合并多个 TypedArray 数组,可以用下面这个函数。
function concatenate(resultConstructor, ...arrays) {
let totalLength = 0;
for (let arr of arrays) {
totalLength += arr.length;
}
let result = new resultConstructor(totalLength);
let offset = 0;
for (let arr of arrays) {
result.set(arr, offset);
offset += arr.length;
}
return result;
}
concatenate(Uint8Array, Uint8Array.of(1, 2), Uint8Array.of(3, 4))
// Uint8Array [1, 2, 3, 4]
另外,TypedArray 数组与普通数组一样,部署了 Iterator 接口,所以可以被遍历。
let ui8 = Uint8Array.of(0, 1, 2);
for (let byte of ui8) {
console.log(byte);
}
// 0
// 1
// 2
字节序
字节序指的是数值在内存中的表示方式。
const buffer = new ArrayBuffer(16);
const int32View = new Int32Array(buffer);
for (let i = 0; i < int32View.length; i++) {
int32View[i] = i * 2;
}
上面代码生成一个 16 字节的 ArrayBuffer 对象,然后在它的基础上,建立了一个 32 位整数的视图。由于每个 32 位整数占据 4 个字节,所以一共可以写入 4 个整数,依次为 0,2,4,6。
如果在这段数据上接着建立一个 16 位整数的视图,则可以读出完全不一样的结果。
const int16View = new Int16Array(buffer);
for (let i = 0; i < int16View.length; i++) {
console.log("Entry " + i + ": " + int16View[i]);
}
// Entry 0: 0
// Entry 1: 0
// Entry 2: 2
// Entry 3: 0
// Entry 4: 4
// Entry 5: 0
// Entry 6: 6
// Entry 7: 0
由于每个 16 位整数占据 2 个字节,所以整个 ArrayBuffer 对象现在分成 8 段。然后,由于 x86 体系的计算机都采用小端字节序(little endian),相对重要的字节排在后面的内存地址,相对不重要字节排在前面的内存地址,所以就得到了上面的结果。
比如,一个占据四个字节的 16 进制数 0x12345678,决定其大小的最重要的字节是“12”,最不重要的是“78”。小端字节序将最不重要的字节排在前面,储存顺序就是 78563412;大端字节序则完全相反,将最重要的字节排在前面,储存顺序就是 12345678。目前,所有个人电脑几乎都是小端字节序,所以 TypedArray 数组内部也采用小端字节序读写数据,或者更准确的说,按照本机操作系统设定的字节序读写数据。
这并不意味大端字节序不重要,事实上,很多网络设备和特定的操作系统采用的是大端字节序。这就带来一个严重的问题:如果一段数据是大端字节序,TypedArray 数组将无法正确解析,因为它只能处理小端字节序!为了解决这个问题,JavaScript 引入 DataView 对象,可以设定字节序,下文会详细介绍。
下面是另一个例子。
// 假定某段buffer包含如下字节 [0x02, 0x01, 0x03, 0x07]
const buffer = new ArrayBuffer(4);
const v1 = new Uint8Array(buffer);
v1[0] = 2;
v1[1] = 1;
v1[2] = 3;
v1[3] = 7;
const uInt16View = new Uint16Array(buffer);
// 计算机采用小端字节序
// 所以头两个字节等于258
if (uInt16View[0] === 258) {
console.log('OK'); // "OK"
}
// 赋值运算
uInt16View[0] = 255; // 字节变为[0xFF, 0x00, 0x03, 0x07]
uInt16View[0] = 0xff05; // 字节变为[0x05, 0xFF, 0x03, 0x07]
uInt16View[1] = 0x0210; // 字节变为[0x05, 0xFF, 0x10, 0x02]
下面的函数可以用来判断,当前视图是小端字节序,还是大端字节序。
const BIG_ENDIAN = Symbol('BIG_ENDIAN');
const LITTLE_ENDIAN = Symbol('LITTLE_ENDIAN');
function getPlatformEndianness() {
let arr32 = Uint32Array.of(0x12345678);
let arr8 = new Uint8Array(arr32.buffer);
switch ((arr8[0]*0x1000000) + (arr8[1]*0x10000) + (arr8[2]*0x100) + (arr8[3])) {
case 0x12345678:
return BIG_ENDIAN;
case 0x78563412:
return LITTLE_ENDIAN;
default:
throw new Error('Unknown endianness');
}
}
总之,与普通数组相比,TypedArray 数组的最大优点就是可以直接操作内存,不需要数据类型转换,所以速度快得多。
BYTES_PER_ELEMENT 属性
每一种视图的构造函数,都有一个 BYTES_PER_ELEMENT 属性,表示这种数据类型占据的字节数。
Int8Array.BYTES_PER_ELEMENT // 1
Uint8Array.BYTES_PER_ELEMENT // 1
Uint8ClampedArray.BYTES_PER_ELEMENT // 1
Int16Array.BYTES_PER_ELEMENT // 2
Uint16Array.BYTES_PER_ELEMENT // 2
Int32Array.BYTES_PER_ELEMENT // 4
Uint32Array.BYTES_PER_ELEMENT // 4
Float32Array.BYTES_PER_ELEMENT // 4
Float64Array.BYTES_PER_ELEMENT // 8
这个属性在 TypedArray 实例上也能获取,即有TypedArray.prototype.BYTES_PER_ELEMENT。
溢出
不同的视图类型,所能容纳的数值范围是确定的。超出这个范围,就会出现溢出。比如,8 位视图只能容纳一个 8 位的二进制值,如果放入一个 9 位的值,就会溢出。
TypedArray 数组的溢出处理规则,简单来说,就是抛弃溢出的位,然后按照视图类型进行解释。
const uint8 = new Uint8Array(1);
uint8[0] = 256;
uint8[0] // 0
uint8[0] = -1;
uint8[0] // 255
上面代码中,uint8 是一个 8 位视图,而 256 的二进制形式是一个 9 位的值 100000000,这时就会发生溢出。根据规则,只会保留后 8 位,即 00000000。uint8 视图的解释规则是无符号的 8 位整数,所以 00000000 就是 0。
负数在计算机内部采用“2 的补码”表示,也就是说,将对应的正数值进行否运算,然后加 1。比如,-1 对应的正值是 1,进行否运算以后,得到 11111110,再加上 1 就是补码形式 11111111。uint8 按照无符号的 8 位整数解释 11111111,返回结果就是 255。
一个简单转换规则,可以这样表示。
正向溢出(overflow):当输入值大于当前数据类型的最大值,结果等于当前数据类型的最小值加上余值,再减去 1。负向溢出(underflow):当输入值小于当前数据类型的最小值,结果等于当前数据类型的最大值减去余值的绝对值,再加上 1。上面的“余值”就是模运算的结果,即 JavaScript 里面的%运算符的结果。
12 % 4 // 0
12 % 5 // 2
上面代码中,12 除以 4 是没有余值的,而除以 5 会得到余值 2。
请看下面的例子。
const int8 = new Int8Array(1);
int8[0] = 128;
int8[0] // -128
int8[0] = -129;
int8[0] // 127
上面例子中,int8 是一个带符号的 8 位整数视图,它的最大值是 127,最小值是-128。输入值为 128 时,相当于正向溢出 1,根据“最小值加上余值(128 除以 127 的余值是 1),再减去 1”的规则,就会返回-128;输入值为-129 时,相当于负向溢出 1,根据“最大值减去余值的绝对值(-129 除以-128 的余值的绝对值是 1),再加上 1”的规则,就会返回 127。
Uint8ClampedArray 视图的溢出规则,与上面的规则不同。它规定,凡是发生正向溢出,该值一律等于当前数据类型的最大值,即 255;如果发生负向溢出,该值一律等于当前数据类型的最小值,即 0。
const uint8c = new Uint8ClampedArray(1);
uint8c[0] = 256;
uint8c[0] // 255
uint8c[0] = -1;
uint8c[0] // 0
上面例子中,uint8C 是一个 Uint8ClampedArray 视图,正向溢出时都返回 255,负向溢出都返回 0。
复合视图
由于视图的构造函数可以指定起始位置和长度,所以在同一段内存之中,可以依次存放不同类型的数据,这叫做“复合视图”。
const buffer = new ArrayBuffer(24);
const idView = new Uint32Array(buffer, 0, 1);
const usernameView = new Uint8Array(buffer, 4, 16);
const amountDueView = new Float32Array(buffer, 20, 1);
上面代码将一个 24 字节长度的 ArrayBuffer 对象,分成三个部分:
字节 0 到字节 3:1 个 32 位无符号整数字节 4 到字节 19:16 个 8 位整数字节 20 到字节 23:1 个 32 位浮点数这种数据结构可以用如下的 C 语言描述:
struct someStruct {
unsigned long id;
char username[16];
float amountDue;
};
DataView 视图
如果一段数据包括多种类型(比如服务器传来的 HTTP 数据),这时除了建立 ArrayBuffer 对象的复合视图以外,还可以通过 DataView 视图进行操作。
DataView 视图提供更多操作选项,而且支持设定字节序。本来,在设计目的上,ArrayBuffer 对象的各种 TypedArray 视图,是用来向网卡、声卡之类的本机设备传送数据,所以使用本机的字节序就可以了;而 DataView 视图的设计目的,是用来处理网络设备传来的数据,所以大端字节序或小端字节序是可以自行设定的。
DataView 视图本身也是构造函数,接受一个 ArrayBuffer 对象作为参数,生成视图。
DataView(ArrayBuffer buffer [, 字节起始位置 [, 长度]]);
下面是一个例子。
const buffer = new ArrayBuffer(24);
const dv = new DataView(buffer);
DataView 实例有以下属性,含义与 TypedArray 实例的同名方法相同。
- DataView.prototype.buffer:返回对应的 ArrayBuffer 对象
- DataView.prototype.byteLength:返回占据的内存字节长度
- DataView.prototype.byteOffset:返回当前视图从对应的 ArrayBuffer 对象的哪个字节开始
DataView 实例提供 8 个方法读取内存。
- getInt8:读取 1 个字节,返回一个 8 位整数。
- getUint8:读取 1 个字节,返回一个无符号的 8 位整数。
- getInt16:读取 2 个字节,返回一个 16 位整数。
- getUint16:读取 2 个字节,返回一个无符号的 16 位整数。
- getInt32:读取 4 个字节,返回一个 32 位整数。
- getUint32:读取 4 个字节,返回一个无符号的 32 位整数。
- getFloat32:读取 4 个字节,返回一个 32 位浮点数。
- getFloat64:读取 8 个字节,返回一个 64 位浮点数。
这一系列 get 方法的参数都是一个字节序号(不能是负数,否则会报错),表示从哪个字节开始读取。
const buffer = new ArrayBuffer(24);
const dv = new DataView(buffer);
// 从第1个字节读取一个8位无符号整数
const v1 = dv.getUint8(0);
// 从第2个字节读取一个16位无符号整数
const v2 = dv.getUint16(1);
// 从第4个字节读取一个16位无符号整数
const v3 = dv.getUint16(3);
上面代码读取了 ArrayBuffer 对象的前 5 个字节,其中有一个 8 位整数和两个十六位整数。
如果一次读取两个或两个以上字节,就必须明确数据的存储方式,到底是小端字节序还是大端字节序。默认情况下,DataView 的 get 方法使用大端字节序解读数据,如果需要使用小端字节序解读,必须在 get 方法的第二个参数指定 true。
// 小端字节序
const v1 = dv.getUint16(1, true);
// 大端字节序
const v2 = dv.getUint16(3, false);
// 大端字节序
const v3 = dv.getUint16(3);
DataView 视图提供 8 个方法写入内存。
- setInt8:写入 1 个字节的 8 位整数。
- setUint8:写入 1 个字节的 8 位无符号整数。
- setInt16:写入 2 个字节的 16 位整数。
- setUint16:写入 2 个字节的 16 位无符号整数。
- setInt32:写入 4 个字节的 32 位整数。
- setUint32:写入 4 个字节的 32 位无符号整数。
- setFloat32:写入 4 个字节的 32 位浮点数。
- setFloat64:写入 8 个字节的 64 位浮点数。
这一系列 set 方法,接受两个参数,第一个参数是字节序号,表示从哪个字节开始写入,第二个参数为写入的数据。对于那些写入两个或两个以上字节的方法,需要指定第三个参数,false 或者 undefined 表示使用大端字节序写入,true 表示使用小端字节序写入。
// 在第1个字节,以大端字节序写入值为25的32位整数
dv.setInt32(0, 25, false);
// 在第5个字节,以大端字节序写入值为25的32位整数
dv.setInt32(4, 25);
// 在第9个字节,以小端字节序写入值为2.5的32位浮点数
dv.setFloat32(8, 2.5, true);
如果不确定正在使用的计算机的字节序,可以采用下面的判断方式。
const littleEndian = (function() {
const buffer = new ArrayBuffer(2);
new DataView(buffer).setInt16(0, 256, true);
return new Int16Array(buffer)[0] === 256;
})();
如果返回 true,就是小端字节序;如果返回 false,就是大端字节序。
TextEncoder 和 TextDecoder
ArrayBuffer 和字符串的相互转换,使用原生 TextEncoder 和 TextDecoder 方法。
TextEncoder
const encoder = new TextEncoder();
根据指定的编码格式生成 encoder 实例
Firefox 48 和 Chrome 53 之后的版本为了与 规范 保持一致,构造函数不需要传递参数,默认的编码格式为 UTF-8,即使传了其他的编码格式,也会调整为 UTF-8;可以通过 polyfill 库,补充不支持的编码格式。
new TextEncoder().encoding; // 'utf-8'
只读属性,返回指定的编码格式
new TextEncoder().encode([input = ""])
返回编码后的字符对象(Unit8Array 格式)
TextDecoder
decoder = new TextDecoder([label = "utf-8" [, options]])
根据指定的解码格式生成 decoder 实例
如果提供未知或模棱两可的解码格式 ,会报 RangeError
options:包含 fatal 、ignoreBOM 属性的 TextDecoderOptions 对象
-
fatal:布尔值,指明在解码过程中发生的错误是否需要抛出,默认为 false
-
ignoreBOM:布尔值,是否忽略字节顺序标记(Byte Order Mark)
new TextDecoder().fatal;
只读属性,指明在解码过程中发生的错误是否需要抛出
new TextDecoder().ignoreBOM;
只读属性,是否忽略字节顺序标记
new TextDecoder().decode([input [, options]]);
根据指定的解码方式对编码数据进行解码,并返回解码后的字符串数据
input:需要解码的数据(ArrayBuffer 格式或 ArrayBufferView 格式)
options:包含 stream 属性的 TextDecodeOptions 对象
- stream:布尔值,是否需要解码额外的数据
来看个完整的例子:
const text = 'hello word';
const encode_text = new TextEncoder().encode(text);
const decode_text = new TextDecoder('utf-8', {fatal: true}).decode(encode_text);
console.info(Object.is(text, decode_text)); // true
我们发现,这个 api 可以将中文(utf-8 编码)编码为二进制数据的。
new TextEncoder().encode('严');
Uint8Array(3) [228, 184, 165]
Nodejs 中的 Buffer
在 Node.js 中,定义了一个 Buffer 类,该类用来创建一个专门存放二进制数据的缓存区。
在 Node.js 中,Buffer 类是随 Node 内核一起发布的核心库。Buffer 库为 Node.js 带来了一种存储原始数据的方法,可以让 Node.js 处理二进制数据,每当需要在 Node.js 中处理 I/O 操作中移动的数据时,就有可能使用 Buffer 库。原始数据存储在 Buffer 类的实例中。一个 Buffer 类似于一个整数数组,但它对应于 V8 堆内存之外的一块原始内存。
在 v6.0 之前创建 Buffer 对象直接使用 new Buffer()构造函数来创建对象实例,但是 Buffer 对内存的权限操作相比很大,可以直接捕获一些敏感信息,所以在 v6.0 以后,官方文档里面建议使用 Buffer.from() 接口去创建 Buffer 对象。
Buffer 与字符编码
Buffer 实例一般用于表示编码字符的序列,比如 UTF-8 、 UCS2 、 Base64 、或十六进制编码的数据。 通过使用显式的字符编码,就可以在 Buffer 实例与普通的 JavaScript 字符串之间进行相互转换。
const buf = Buffer.from('runoob', 'ascii');
// 输出 72756e6f6f62
console.log(buf.toString('hex'));
// 输出 cnVub29i
console.log(buf.toString('base64'));
Buffer.from('严','utf8').toString('base64');
// '5Lil'
Node.js 目前支持的字符编码包括:
-
ascii - 仅支持 7 位 ASCII 数据。如果设置去掉高位的话,这种编码是非常快的。
-
utf8 - 多字节编码的 Unicode 字符。许多网页和其他文档格式都使用 UTF-8 。
-
utf16le - 2 或 4 个字节,小字节序编码的 Unicode 字符。支持代理对(U+10000 至 U+10FFFF)。
-
ucs2 - utf16le 的别名。
-
base64 - Base64 编码。
-
latin1 - 一种把 Buffer 编码成一字节编码的字符串的方式。
-
binary - latin1 的别名。
-
hex - 将每个字节编码为两个十六进制字符。
创建 Buffer 类
Buffer 提供了以下 API 来创建 Buffer 类:
- Buffer.alloc(size[, fill[, encoding]]): 返回一个指定大小的 Buffer 实例,如果没有设置 fill,则默认填满 0
- Buffer.allocUnsafe(size): 返回一个指定大小的 Buffer 实例,但是它不会被初始化,所以它可能包含敏感的数据
- Buffer.allocUnsafeSlow(size)
- Buffer.from(array): 返回一个被 array 的值初始化的新的 Buffer 实例(传入的 array 的元素只能是数字,不然就会自动被 0 覆盖)
- Buffer.from(arrayBuffer[, byteOffset[, length]]): 返回一个新建的与给定的 ArrayBuffer 共享同一内存的 Buffer。
- Buffer.from(buffer): 复制传入的 Buffer 实例的数据,并返回一个新的 Buffer 实例
- Buffer.from(string[, encoding]): 返回一个被 string 的值初始化的新的 Buffer 实例
// 创建一个长度为 10、且用 0 填充的 Buffer。
const buf1 = Buffer.alloc(10);
// 创建一个长度为 10、且用 0x1 填充的 Buffer。
const buf2 = Buffer.alloc(10, 1);
// 创建一个长度为 10、且未初始化的 Buffer。
// 这个方法比调用 Buffer.alloc() 更快,
// 但返回的 Buffer 实例可能包含旧数据,
// 因此需要使用 fill() 或 write() 重写。
const buf3 = Buffer.allocUnsafe(10);
// 创建一个包含 [0x1, 0x2, 0x3] 的 Buffer。
const buf4 = Buffer.from([1, 2, 3]);
// 创建一个包含 UTF-8 字节 [0x74, 0xc3, 0xa9, 0x73, 0x74] 的 Buffer。
const buf5 = Buffer.from('tést');
// 创建一个包含 Latin-1 字节 [0x74, 0xe9, 0x73, 0x74] 的 Buffer。
const buf6 = Buffer.from('tést', 'latin1');
写入缓冲区
写入 Node 缓冲区的语法如下所示:
buf.write(string[, offset[, length]][, encoding])
参数描述如下:
-
string - 写入缓冲区的字符串。
-
offset - 缓冲区开始写入的索引值,默认为 0 。
-
length - 写入的字节数,默认为 buffer.length
-
encoding - 使用的编码。默认为 ‘utf8’ 。
根据 encoding 的字符编码写入 string 到 buf 中的 offset 位置。 length 参数是写入的字节数。 如果 buf 没有足够的空间保存整个字符串,则只会写入 string 的一部分。 只部分解码的字符不会被写入。
返回实际写入的大小。如果 buffer 空间不足, 则只会写入部分字符串。
buf = Buffer.alloc(256);
len = buf.write("www.runoob.com");
console.log("写入字节数 : "+ len);
// 写入字节数 : 14
从缓冲区读取数据
读取 Node 缓冲区数据的语法如下所示:
buf.toString([encoding[, start[, end]]])
参数描述如下:
-
encoding - 使用的编码。默认为 ‘utf8’ 。
-
start - 指定开始读取的索引位置,默认为 0。
-
end - 结束位置,默认为缓冲区的末尾。
解码缓冲区数据并使用指定的编码返回字符串。
buf = Buffer.alloc(26);
for (var i = 0 ; i < 26 ; i++) {
buf[i] = i + 97;
}
console.log( buf.toString('ascii')); // 输出: abcdefghijklmnopqrstuvwxyz
console.log( buf.toString('ascii',0,5)); // 输出: abcde
console.log( buf.toString('utf8',0,5)); // 输出: abcde
console.log( buf.toString(undefined,0,5)); // 使用 'utf8' 编码, 并输出: abcde
Nodejs 中的 Stream
不光手动初始化可以获取一个 Buffer 对象,通过 fs 模块来读取文件,也可以获取一个 buffer 对象。
> var fs = require('fs');
undefined
> fs.readFileSync('/Users/liyucang/Desktop/test.txt')
<Buffer 7b 22 6d 65 6e 75 73 22 3a 7b 22 69 64 22 3a 33 38 38 30 2c 22 63 72 65 61 74 65 54 69 6d 65 22 3a 31 35 35 33 30 30 32 32 33 38 33 37 32 2c 22 75 70 ... >
这样 test.txt 文件就被读取到了内存中,nodejs 中有了一个 Buffer 对象。
Buffer 对象可以被写入本地文件系统,或者通过网络写入远程的机器中,或者转换为字符串来做更多的操作,或者不做任何处理。
上面例子中的场景,我们可以在当前目录下用次 buffer 写入一个新的文件
var fs = require('fs');
var fileBuffer = fs.readFileSync('/Users/liyucang/Desktop/test.txt')
fs.writeFileSync('test2.txt',fileBuffer)
这个例子可以行得通,然而事情不会一直这么简单。
我的电脑内存大小是 8G,当我想用这段代码 copy 一个 12G 的文件时,会发生什么事情呢? 在第一步读取文件的时候,我们需要创建一个占用 12G 大小内存空间的 Buffer 对象,这样显然是行不通的,内存会爆掉。那怎么办呢?
显然我们就需要把数据分成一小块一小块,一块一块的放到内存中去处理,这样内存就不会爆掉了~
在这里我想比喻一下,方便理解:
CPU 相当于一个工人
工人需要操作工具加热水(CPU 需要运行代码执行计算)
硬盘相当于一个水池
水池里边可以蓄水,容量很大,但是不能在水池里边直接加热水,需要把水放进锅中(硬盘可以存放数据,容量很大,但是不能直接在硬盘中利用数据执行计算,需要把数据读进内存中)
内存相当于一口锅
锅可以盛水并加热,但是容量不大(内存中可以存放数据用于计算,但是容量不大)
加热-导入水(计算-导入数据)
那么上面小节中我们遇到的问题就是:池子中的水太多,一次倒锅里去就溢出来了,加热不了了。于是我们采取一种措施:
从水池中连接一个管道到锅中,这根管道(stream.Readable 类)可以把水从池子中导入锅中
管子一开始是封闭的,我们可以把开关打开(绑定 Event: ‘data’,此事件绑定之后即刻触发)
也可以暂停导入(readable.pause())
可以恢复导入(readable.resume())
还可以手动导入(readable.read())
加热完毕—导出水(计算完毕-导出数据)
当导入的一锅水烧好以后,需要把这一锅水倒出去才能处理下一锅,于是从锅中连接一根管道(stream.Writable 类)到另外的容器中(可能是硬盘中的另外一块区域,也可能是远程的另外一台机器)和上面的 readStream 一样,管子可以向另外一个地方导出水(writable.write)
不计算只中转
当锅只是起一个中转的作用时,可以把导入管接到导出管上去(readable.pipe(destination[, options]))过程中也可以把他们分开(readable.unpipe([destination]))
既可以导出也可以导入的 Stream
有的管道既可以导入,也可以导出(stream.Transform)
Stream 的应用场景
用到 Stream 的地方有:
- 刚才说的 file system
- http 模块的 request 对象和 response 对象
- net 模块的数据传输
var readStream = fs.createReadStream(test.txt);
var writeStream = fs.createWriteStream(test1.txt);
readStream.pipe(writeStream);
//或者
readStream.on('readable', function() {
var chunk;
while (null !== (chunk = readStream.read())) {
console.log(chunk, chunk.length);
writeStream.write(chunk);
}
})
readstream 中的内容默认是 Buffer 对象,在读取之前设置字符编码,读取的时候即可获取字符串。
nodejs 中的 buffer 和浏览器中的 Uint8Array 的关系
> var b = Buffer.alloc(10);
undefined
> var b2 = new Uint8Array(10);
undefined
> b instanceof Uint8Array;
true
> b2 instanceof Buffer;
false
> Buffer.prototype instanceof Uint8Array;
true
可见,nodejs 中实现的 Buffer 实际上是 Uint8Arr 数组的一个子类,是 nodejs 为了进一步提升 JavaScript 的二进制数据处理能力而封装的一个类。
实际上 ArrayBuffer 和类型化数组也并不是浏览器环境下独有的东西,他们是 es5 规范里边的内容,在 nodejs 环境下也可以使用。
二进制数组的应用
fetch
fetch 应该是大家比较熟悉的,但大多使用环境比较单一,一般用来请求 json 数据。其实, 它也可以设置返回数据格式为 Blob 或者 ArrayBuffer。
fetch 返回一个包含 Response 对象的 Promise,Response 有以下方法
- Response.prototype.arrayBuffer
- Response.prototype.blob
- Response.prototype.text
- Response.prototype.json
fetch('/api/ping').then(res => {
// true
console.log(res instanceof Response)
// 最常见的使用
return res.json()
// 返回 Blob
// return res.blob()
// 返回 ArrayBuffer
// return res.arrayBuffer()
})
另外,Response API 既可以可以使用 TypedArray,Blob,Text 作为输入,又可以使用它们作为输出。
AJAX
传统上,服务器通过 AJAX 操作只能返回文本数据,即 responseType 属性默认为 text。XMLHttpRequest 第二版 XHR2 允许服务器返回二进制数据,这时分成两种情况。如果明确知道返回的二进制数据类型,可以把返回类型(responseType)设为 arraybuffer;如果不知道,就设为 blob。
let xhr = new XMLHttpRequest();
xhr.open('GET', someUrl);
xhr.responseType = 'arraybuffer';
xhr.onload = function () {
let arrayBuffer = xhr.response;
// ···
};
xhr.send();
如果知道传回来的是 32 位整数,可以像下面这样处理。
xhr.onreadystatechange = function () {
if (req.readyState === 4 ) {
const arrayResponse = xhr.response;
const dataView = new DataView(arrayResponse);
const ints = new Uint32Array(dataView.byteLength / 4);
xhrDiv.style.backgroundColor = "#00FF00";
xhrDiv.innerText = "Array is " + ints.length + "uints long";
}
}
Canvas
网页 Canvas 元素输出的二进制像素数据,就是 TypedArray 数组。
const canvas = document.getElementById('myCanvas');
const ctx = canvas.getContext('2d');
const imageData = ctx.getImageData(0, 0, canvas.width, canvas.height);
const uint8ClampedArray = imageData.data;
需要注意的是,上面代码的 uint8ClampedArray 虽然是一个 TypedArray 数组,但是它的视图类型是一种针对 Canvas 元素的专有类型 Uint8ClampedArray。这个视图类型的特点,就是专门针对颜色,把每个字节解读为无符号的 8 位整数,即只能取值 0 ~ 255,而且发生运算的时候自动过滤高位溢出。这为图像处理带来了巨大的方便。
举例来说,如果把像素的颜色值设为 Uint8Array 类型,那么乘以一个 gamma 值的时候,就必须这样计算:
u8[i] = Math.min(255, Math.max(0, u8[i] * gamma));
因为 Uint8Array 类型对于大于 255 的运算结果(比如 0xFF+1),会自动变为 0x00,所以图像处理必须要像上面这样算。这样做很麻烦,而且影响性能。如果将颜色值设为 Uint8ClampedArray 类型,计算就简化许多。
pixels[i] *= gamma;
Uint8ClampedArray 类型确保将小于 0 的值设为 0,将大于 255 的值设为 255。注意,IE 10 不支持该类型。
WebSocket
WebSocket 可以通过 ArrayBuffer,发送或接收二进制数据。
let socket = new WebSocket('ws://127.0.0.1:8081');
socket.binaryType = 'arraybuffer';
// Wait until socket is open
socket.addEventListener('open', function (event) {
// Send binary data
const typedArray = new Uint8Array(4);
socket.send(typedArray.buffer);
});
// Receive binary data
socket.addEventListener('message', function (event) {
const arrayBuffer = event.data;
// ···
});
上传本地图片并在网页上展示
由以上整理的转换图得出途径
本地上传图片 -> Blob -> Object URL
json 数据下载
json 视为字符串,由以上整理的转换图得出途径
Text -> DataURL
除了使用 DataURL,还可以转化为 Object URL 进行下载。
Text -> Blob -> Object URL
可以把以下代码直接粘贴到控制台下载文件
const json = {
a: 3,
b: 4,
c: 5
}
const str = JSON.stringify(json, null, 2)
const dataUrl = `data:,${str}`
const url = URL.createObjectURL(new Blob(str.split('')))
download(dataUrl, 'demo.json')
download(url, 'demo1.json')
拼接两个音频文件
由以上整理的转换图得出途径
fetch请求音频资源 -> ArrayBuffer -> TypedArray -> 拼接成一个 TypedArray -> ArrayBuffer -> Blob -> Object URL
前端生成文件
背景
既然要生成文件,我们首先需要了解一下文件编码等概念。
因为中文的博大精深,以及早期文件编码的不统一,造成了现在可能碰到的文件编码有 GB2312、GBK、GB18030、UTF-8、BIG5 等。因为编解码的知识比较底层和冷门,一直以来我对这几个编码的认知也很肤浅,很多时候也会疑惑编码名到底是大写还是小写,英文和数字之间是不是需要加“-”,规则到底是谁定的等等。
| 编码 | 说明 |
|---|---|
| GB2312 | 最早的简体中文编码,还有海外版的 HZ-GB-2312 |
| BIG5 | 繁体中文编码,主要用于台湾地区。些繁体中文游戏乱码,其实都是因为 BIG5 编码和 GB2312 编码的错误使用导致 |
| GBK | 简体+繁体,我就当它是 GB2312+BIG5,非国家标准,只是中文环境内基本都遵守。后来了解到,K 居然是“扩展”的拼音首字母,这很中国。。。 |
| GB18030 | GB 家族的新版,向下兼容,最新国家标准,现在中文软件都理应支持的编码格式,文件解码的新选择 |
| UTF-8 | 不解释了,国际化编码标准,html 现在最标准的编码格式。 |
概念梳理
首先要消化整个字符编解码知识,先要明确两个概念——字符集和字符编码。
字符集
顾名思义就是字符的集合,不同的字符集最直观的区别就是字符数量不相同,常见的字符集有 ASCII 字符集、GB2312 字符集、BIG5 字符集、 GB18030 字符集、Unicode 字符集等。
字符编码
字符编码决定了字符集到实际二进制字节的映射方式,每一种字符编码都有自己的设计规则,例如是固定字节数还是可变长度,此处不一一展开。
常提到的 GB2312、BIG5、UTF-8 等,如果未特殊说明,一般语义上指的是字符编码而不是字符集。
字符集和字符编码是一对多的关系,同一字符集可以存在多个字符编码,典型代表是 Unicode 字符集下有 UTF-8、UTF-16 等等。
BOM(Byte Order Mark)
当使用 windows 记事本保存文件的时候,编码方式可以选择 ANSI(通过 locale 判断,简体中文系统下是 GB 家族)、Unicode、Utf-8 等。
为了清晰概念,需要指出此处的 Unicode,编码方式其实是 UTF-16LE。
有这么多编码方式,那文件打开的时候,windows 系统是如何判断该使用哪种编码方式呢?
答案是:windows(例如:简体中文系统)在文件头部增加了几个字节以表示编码方式,三个字节(0xef, 0xbb, 0xbf)表示 UTF-8;两个字节(0xff, 0xfe 或者 0xfe, 0xff)表示 UTF-16(Unicode);无表示 GB**。
值得注意的是,由于 BOM 不表意,在解析文件内容的时候应该舍弃,不然会造成解析出来的内容头部有多余的内容。
LE(little-endian)和 BE(big-endian)
这个涉及到字节相关的知识了,不是本文重点,不过提到了就顺带解释下。LE 和 BE 代表字节序,分别表示字节从低位/高位开始。
我们常接触到的 CPU 都是 LE,所以 windows 里 Unicode 未指明字节序时默认指的是 LE。 node 的 Buffer API 中基本都有相应的 2 种函数来处理 LE、BE,贴个文档如下:
const buf = Buffer.from([0, 5]);
// Prints: 5
console.log(buf.readInt16BE());
// Prints: 1280
console.log(buf.readInt16LE());
生成 csv 文件
前端编码完成后,一般都会顺势实现文件生成,示例代码如下:
const a = document.createElement('a')
const buf = new TextEncoder()
const blob = new Blob([buf.encode('我是文本')], {
type: 'text/plain'
})
a.download = 'file'
a.href = URL.createObjectURL(blob)
a.click()
// 主动调用释放内存
URL.revokeObjectURL(blob)
复制代码这样就会生成一个文件名为 file 的文件,后缀由 type 决定。如果需要导出 csv,那只需要修改对应的 MIME type:
var blob = new Blob([ new TextEncoder().encode('第一行,1\r\n第二行,2')], {
type: 'text/csv'
})
download(URL.createObjectURL(blob),'test.csv')