js 垃圾回收机制
JS 内存管理
内存基本概念
无论高级语言,还是低级语言。内存的管理都是:
- 内存分配:申明变量、函数、对象,系统会自动分配内存
- 内存使用:读写内存,使用变量、函数等
- 内存回收:使用完毕,由垃圾回收机制自动回收不再使用的内存
像 C 语言这样的高级语言一般都有底层的内存管理接口,比如 malloc()和 free()。另一方面,JavaScript 创建变量(对象,字符串等)时分配内存,并且在不再使用它们时“自动”释放。 后一个过程称为垃圾回收。这个“自动”是混乱的根源,并让 JavaScript(和其他高级语言)开发者感觉他们可以不关心内存管理。
JS 内存空间分为栈(stack)、堆(heap)、池(一般也会归类为栈中)。 其中栈存放变量,堆存放复杂对象,池存放常量。
对象放在 heap(堆)里,常见的基础类型和函数放在 stack(栈)里,函数执行的时候在栈里执行。
基础数据类型与栈内存
JS 中的基础数据类型,这些值都有固定的大小,往往都保存在栈内存中(闭包除外),由系统自动分配存储空间。
stack 中主要存放一些基本类型的变量和对象的引用,存在栈中的数据大小与生存期必须是确定的。可以明确知道每个区块的大小,因此,stack 的寻址速度要快于 heap。
Number String Null Undefined Boolean
(es6新引入了一种数据类型,Symbol)
var a = 1
我们定义一个变量 a,系统自动分配存储空间。我们可以直接操作保存在栈内存空间的值,因此基础数据类型都是按值访问。
数据在栈内存中的存储与使用方式类似于数据结构中的栈数据结构,遵循后进先出的原则。
引用数据类型与堆内存
与其他语言不同,JS 的引用数据类型,比如数组 Array,它们值的大小是不固定的。引用数据类型的值是保存在堆内存中的对象。JavaScript 不允许直接访问堆内存中的位置,因此我们不能直接操作对象的堆内存空间。
在操作对象时,实际上是在操作对象的引用而不是实际的对象。因此,引用类型的值都是按引用访问的。这里的引用,我们可以粗浅地理解为保存在栈内存中的一个地址,该地址与堆内存的实际值相关联。
heap 是没有结构的,数据可以任意存放。heap 用于复杂数据类型(引用类型)分配空间,例如数组对象、object 对象。
var b = { xi : 20 }
比较
var a1 = 0; // 栈
var a2 = 'this is string'; // 栈
var a3 = null; // 栈
var b = { m: 20 }; // 变量b存在于栈中,{m: 20} 作为对象存在于堆内存中
var c = [1, 2, 3]; // 变量c存在于栈中,[1, 2, 3] 作为对象存在于堆内存中
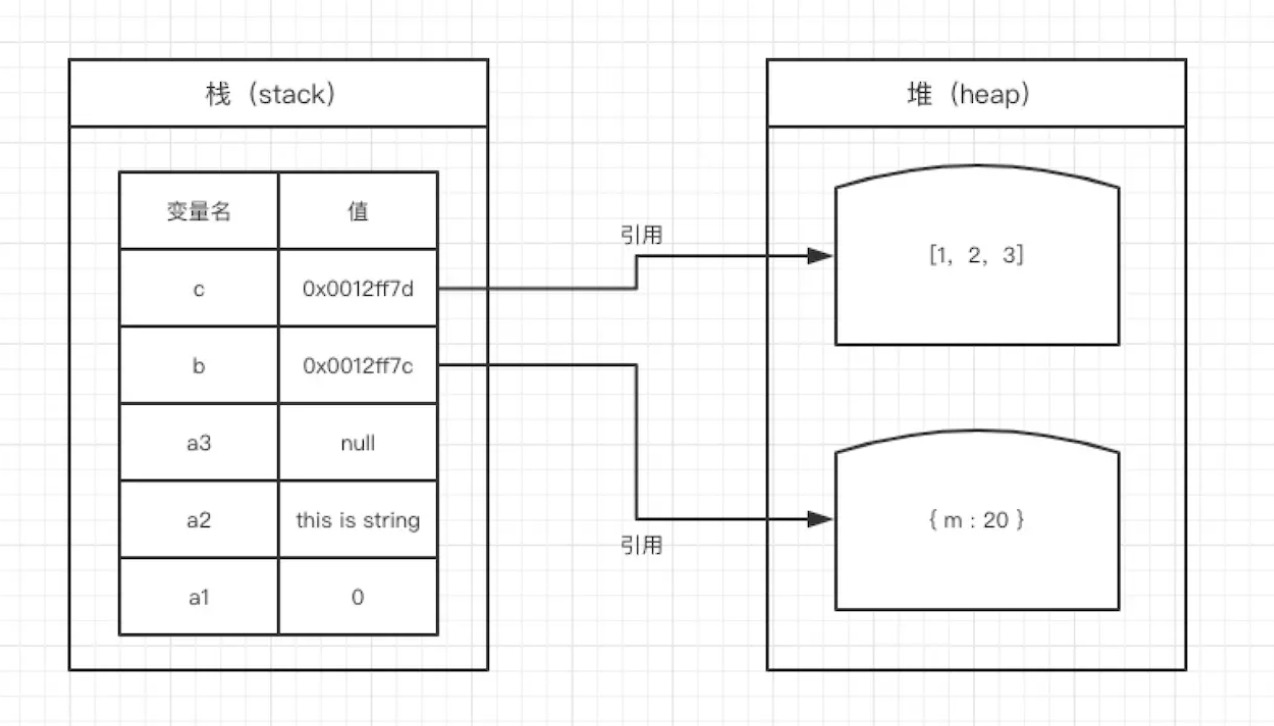
因此当我们要访问堆内存中的引用数据类型时,实际上我们首先是从栈中获取了该对象的地址引用(或者地址指针),然后再从堆内存中取得我们需要的数据。
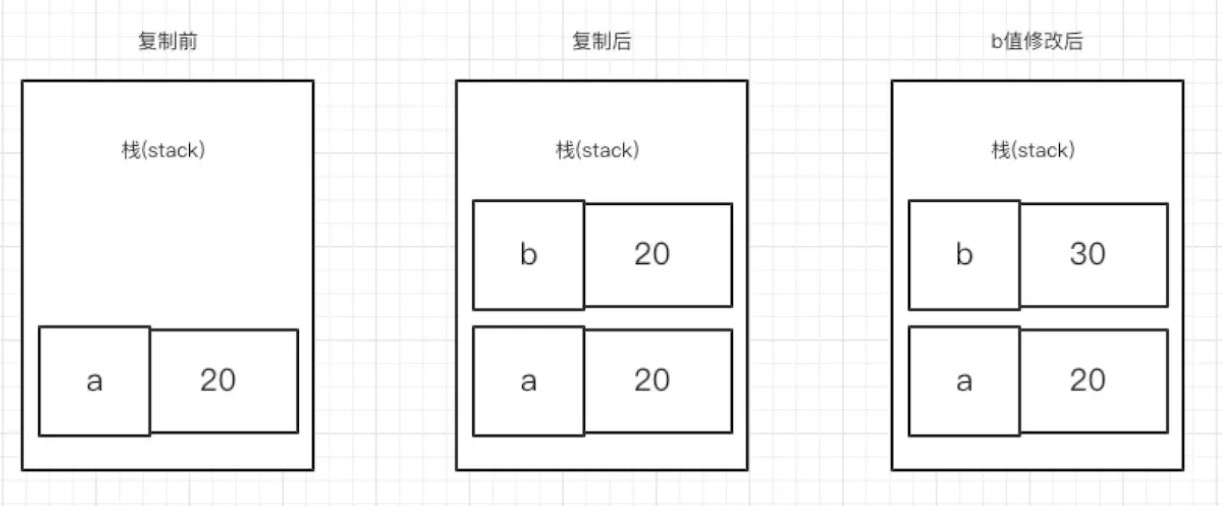
再来看看堆和栈复制操作存在的差异:
var a = 20;
var b = a;
b = 30;
console.log(a)
var m = { a: 10, b: 20 }
var n = m;
n.a = 15;
console.log(m.a)
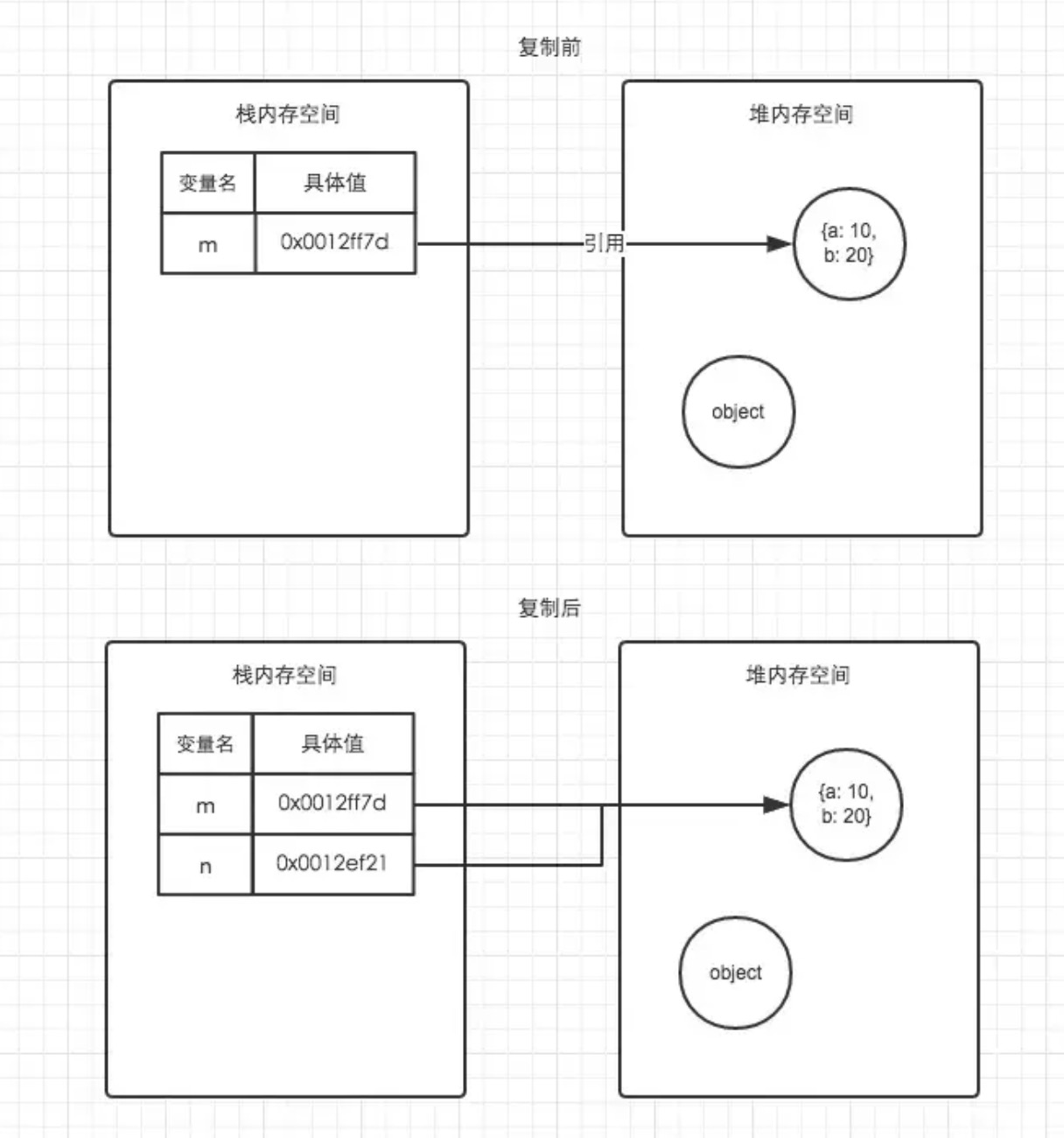
不难看出,基本数据类型的是复制的值,而引用数据类型是复制的值的引用。
内存机制我们了解了,又引出一个新的问题,栈里只能存基础数据类型吗,我们经常用的 function 存在哪里呢?
函数执行栈
对象放在 heap(堆)里,常见的基础类型和函数放在 stack(栈)里,函数执行的时候在栈里执行。
简单复习一下事件循环机制:
(1)所有同步任务都在主线程上执行,形成一个执行栈(execution context stack)。
(2)主线程之外,还存在一个”任务队列”(task queue)。只要异步任务有了运行结果,就在”任务队列”之中放置一个事件。
(3)一旦”执行栈”中的所有同步任务执行完毕,系统就会读取”任务队列”,看看里面有哪些事件。那些对应的异步任务,于是结束等待状态,进入执行栈,开始执行。
(4)主线程不断重复上面的第三步。
函数调用形成了一个栈帧:
function foo(b) {
var a = 10;
return a + b + 11;
}
function bar(x) {
var y = 3;
return foo(x * y);
}
console.log(bar(7));
当调用 bar 时,创建了第一个帧 ,帧中包含了 bar 的参数和局部变量。
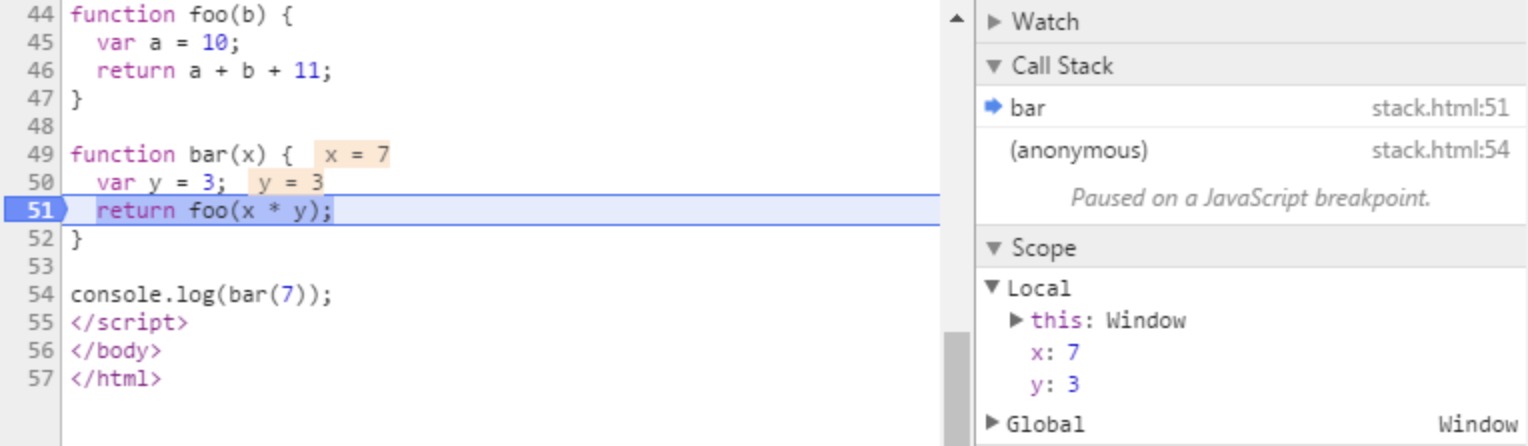
当 bar 调用 foo 时,第二个帧就被创建,并被压到第一个帧之上,帧中包含了 foo 的参数和局部变量。当 foo 返回时,最上层的帧就被弹出栈(剩下 bar 函数的调用帧 )。
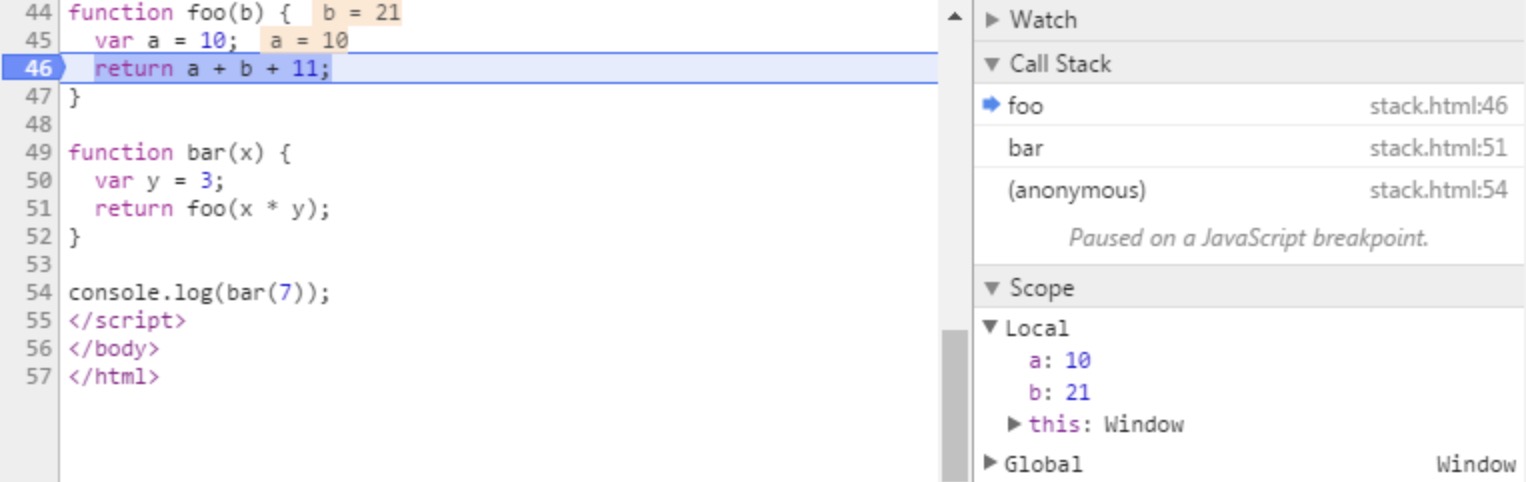
当 bar 返回的时候,栈就空了。
堆与栈的大小
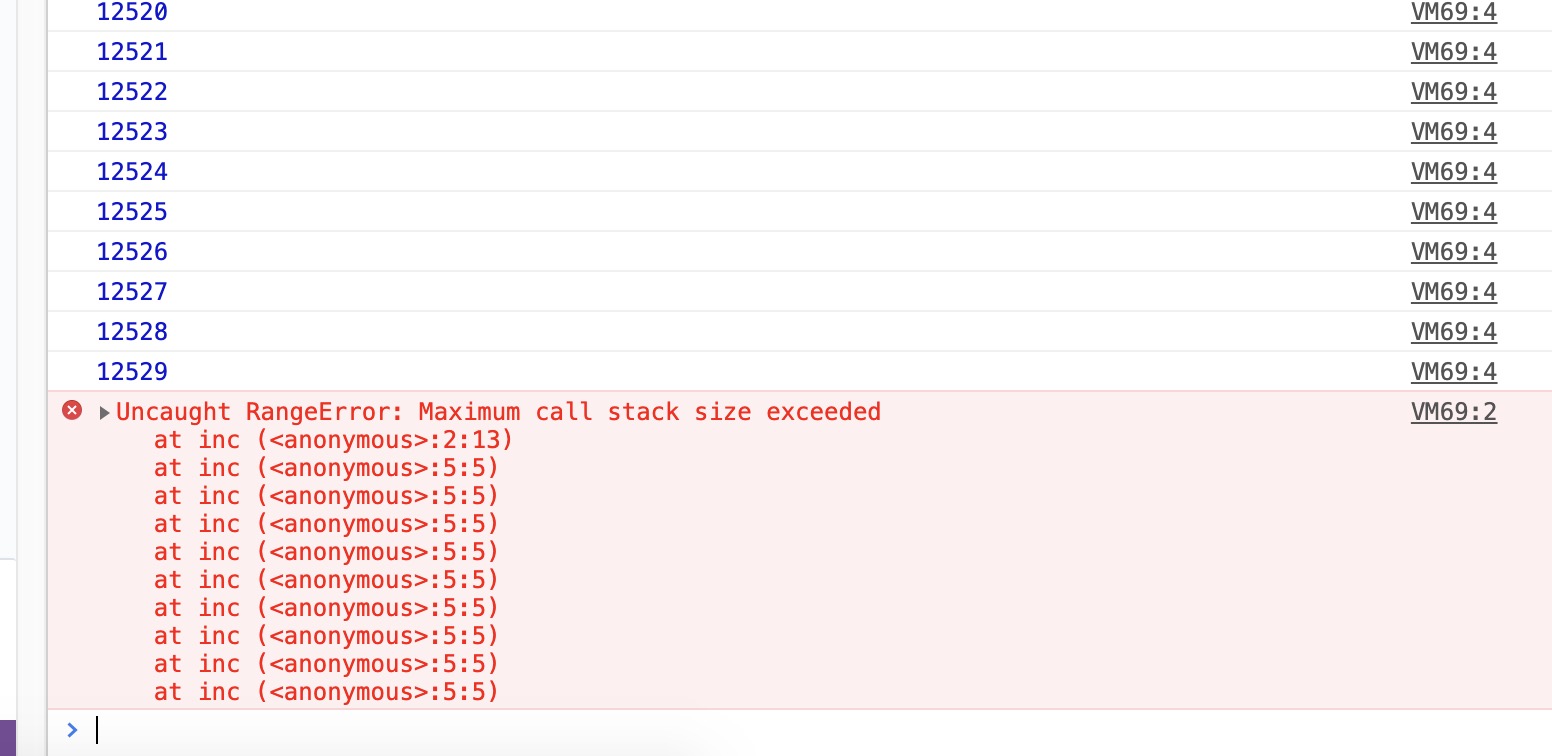
程序运行时,每个线程分配一个 stack,每个进程分配一个 heap,也就是说,stack 是线程独占的,heap 是线程共用的。此外,stack 创建的时候,大小是确定的,数据超过这个大小,就发生 stack overflow 错误,而 heap 的大小是不确定的,需要的话可以不断增加。所以这里只看 stack 的大小限制。下面是一个简单的测试:
var i=0;
function inc() {
i++;
console.log(i);
inc();
}
inc();
测试环境是 16G 内存的电脑,需要注意的是:根据栈的定义可以知道如果 inc 函数里有变量申明的话也是会有内存占用的。
垃圾回收机制策略简介
js 具有自动垃圾回收机制。虽然开发的时候不用过于关心内存,因为分配和回收都实现了自动管理。但是了解自己写的代码,在执行的过程中发生了什么,有助于我们写出更加优秀的代码。
引用概念
垃圾回收算法主要依赖于引用的概念。
在内存管理的环境中,一个对象如果有访问另一个对象的权限(隐式或者显式),叫做一个对象引用另一个对象。例如,一个 Javascript 对象具有对它原型的引用(隐式引用)和对它属性的引用(显式引用)。
“对象”的概念不仅特指 JavaScript 对象,还包括函数作用域(或者全局词法作用域)。
引用计数垃圾收集
这是最初级的垃圾收集算法。此算法把“对象是否不再需要”简化定义为“对象有没有其他对象引用到它”。
引用计数跟踪几个每个值被引用的次数,当声明一个引用类型值赋给该变量时,则这个值的引用次数就是 1,如果同一个值被赋给另外一个变量,则该值的引用次数加 1。
相反,如果包含对这个值引用的变量又取了另外一个值,则这个值的引用次数减 1。当这个值的引用次数变成 0 时,就可以将其内存空间回收。当垃圾回收器再次运行时,它就会释放哪些引用次数为 0 的值所占用的内存。
var o = {
a: {
b:2
}
};
// 两个对象被创建,一个作为另一个的属性被引用,另一个被分配给变量o
// 很显然,没有一个可以被垃圾收集
var o2 = o; // o2变量是第二个对“这个对象”的引用
o = 1; // 现在,“这个对象”的原始引用o被o2替换了
var oa = o2.a; // 引用“这个对象”的a属性
// 现在,“这个对象”有两个引用了,一个是o2,一个是oa
o2 = "yo"; // 最初的对象现在已经是零引用了
// 他可以被垃圾回收了
// 然而它的属性a的对象还在被oa引用,所以还不能回收
oa = null; // a属性的那个对象现在也是零引用了
// 它可以被垃圾回收了
引用计数缺陷
该算法有个限制:无法处理循环引用。在下面的例子中,两个对象被创建,并互相引用,形成了一个循环。它们被调用之后会离开函数作用域,所以它们已经没有用了,可以被回收了。然而,引用计数算法考虑到它们互相都有至少一次引用,所以它们不会被回收。
function f(){
var o = {};
var o2 = {};
o.a = o2; // o 引用 o2
o2.a = o; // o2 引用 o
return "azerty";
}
f();
IE 存在的问题
在 IE9 之前,IE 中有一部分对象并不是原生 JavaScript 对象。例如,BOM 和 DOM 中的对象就是 C++ 实现的 COM 对象,而 COM 对象的垃圾收集机制采用的是引用计数策略。因此,即使 IE 中的 JavaScript 引擎使用标记清除策略实现,但是 JS 访问的 COM 对象依然是基于引用计数策略的。可以在 IE 中涉及到 COM 对象,就会存在循环引用的问题。
var ele = document.getElementById('some_element')
var obj = new Object()
obj.ele = ele
ele.someObj = obj
在这个例子中一个 DOM 元素与一个原生 JS 对象之间创建了循环引用,由于 COM 的引用计数的垃圾回收策略,导致例子中的 DOM 从页面删除,也不会被垃圾回收。
解决办法:
obj.ele = null
ele.someObj = null
将变量设置为 null 意味着切断变量和它此前引用值之间的连接。当垃圾回收器下次运行时,就能删除这些值并回收它们占用的内存。
IE9 之后,DOM 和 BOM 对象都被转换成立真正的 JS 对象,这样就避免了两种垃圾回收算法并存导致的问题。
标记-清除算法
JavaScript 中最常用的垃圾回收方式就是标记清除(mark-and-sweep),当变量进入环境时,就将这个变量标记“进入环境”,当变量离开环境时,就将其标记为“离开环境”。
至于怎么标记有很多种方式,比如翻转某个特殊位来来记录一个变量何时进入环境、使用一个“进入环境”变量列表和一个“离开环境”列表等。
此算法可以分为两个阶段,一个是标记阶段(mark),一个是清除阶段(sweep)。
- 标记阶段,垃圾回收器会从根对象开始遍历。每一个可以从根对象访问到的对象都会被添加一个标识,于是这个对象就被标识为可到达对象。
- 清除阶段,垃圾回收器会对堆内存从头到尾进行线性遍历,如果发现有对象没有被标识为可到达对象,那么就将此对象占用的内存回收,并且将原来标记为可到达对象的标识清除,以便进行下一次垃圾回收操作。
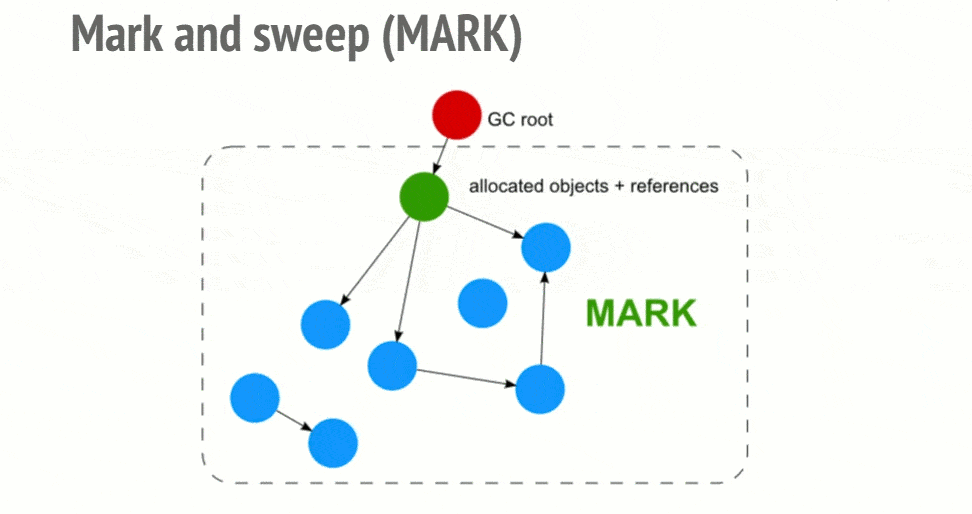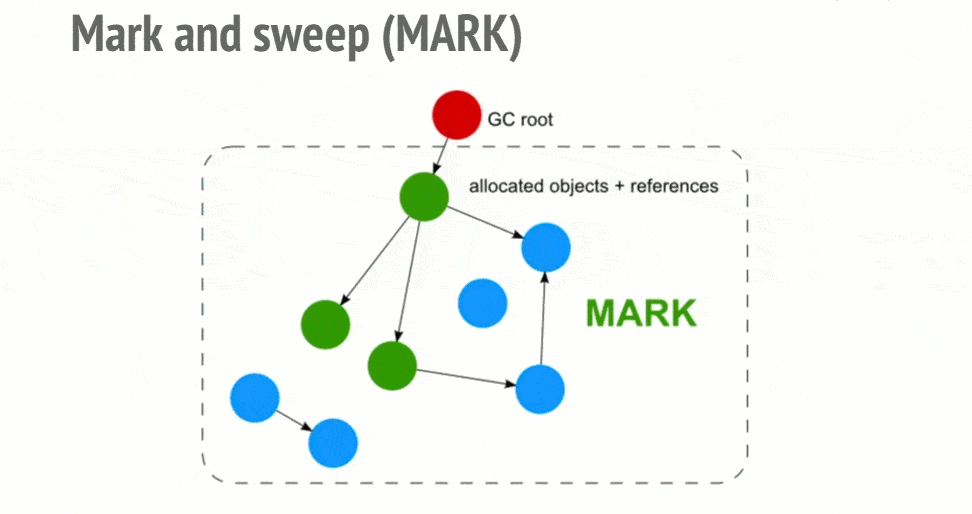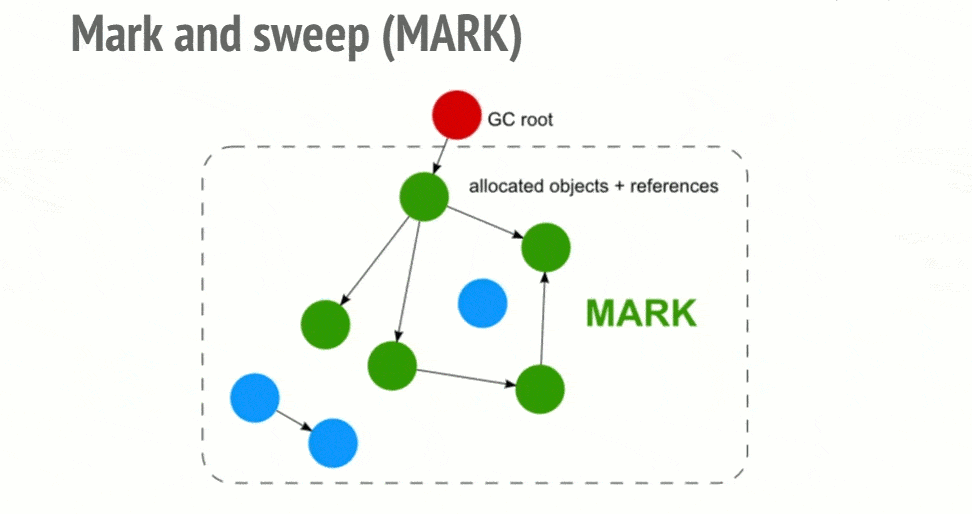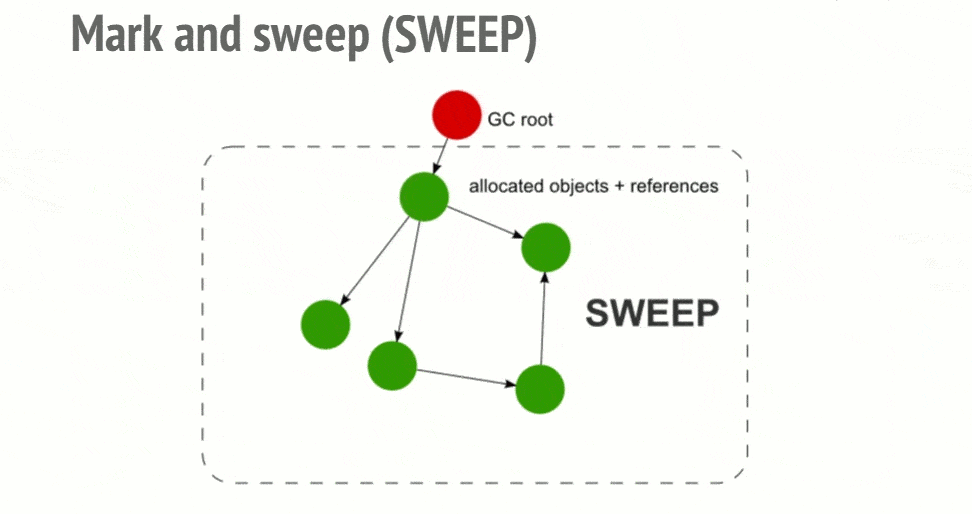
从 2012 年起,所有现代浏览器都使用了标记-清除垃圾回收算法。所有对 JavaScript 垃圾回收算法的改进都是基于标记-清除算法的改进,并没有改进标记-清除算法本身和它对“对象是否不再需要”的简化定义。
JavaScript 的根对象
GC 的时候,从根对象开始遍历。在浏览器,根对象是 window;在 Node.js 中,是 global(或称为 root).
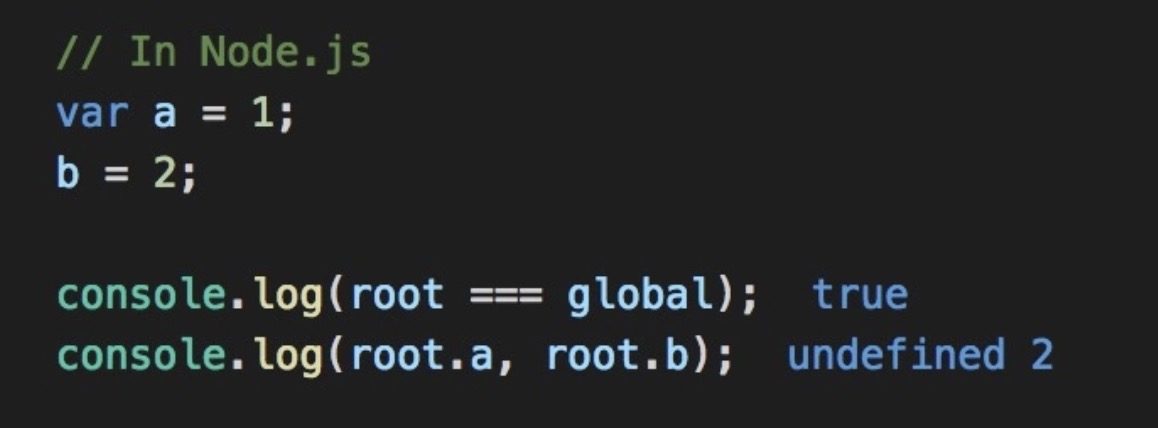
Node.js 中,每个文件被当做一个模块,所以,当你用 var/let/const 在文件的全局,声明变量的时候,作用域是当前文件(模块)。因此,图中 root.a 是 undefined。
标记-清除算法缺陷
- 那些无法从根对象查询到的对象都将被清除
- 垃圾收集后有可能会造成大量的内存碎片,如果一个对象由于需要占用较大内存单位而无法分配,那么就会导致 Mutator 一直处于暂停状态,而 Collector 一直在尝试进行垃圾收集,直到 Out of Memory。
V8 垃圾回收算法(分代回收)
概念
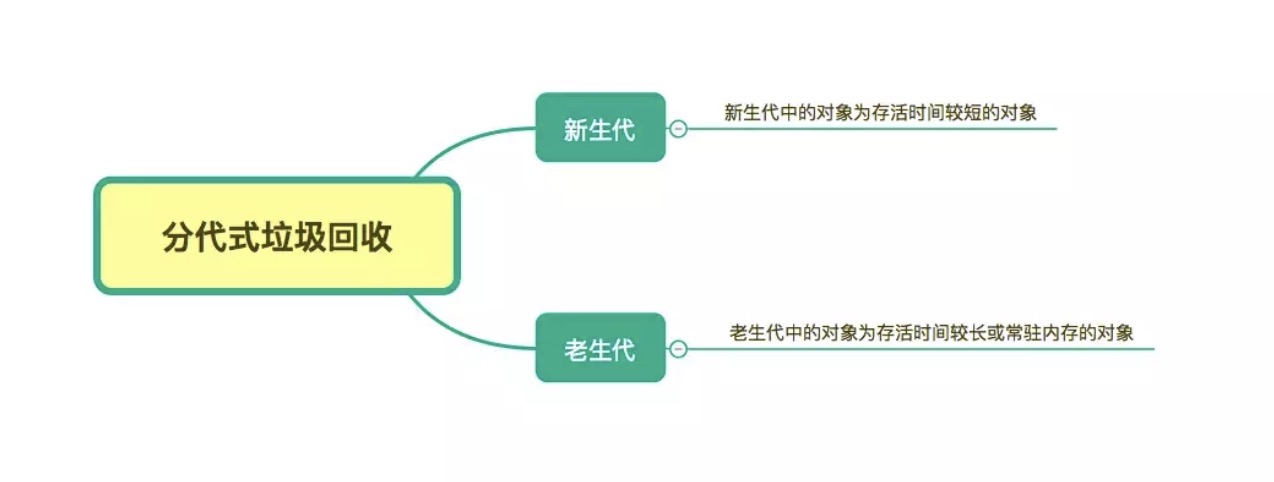
这个和 Java 回收策略思想是一致的。目的是通过区分「临时」与「持久」对象;多回收「临时对象区」(young generation),少回收「持久对象区」(tenured generation),减少每次需遍历的对象,从而减少每次 GC 的耗时。Chrome 浏览器所使用的 V8 引擎就是采用的分代回收策略。
「临时」与「持久」对象也被叫做作「新生代」与「老生代」对象。

V8 内存分代以及大小限制
在 V8 中,主要将内存分为新生代和老生代,新生代的对象为存活时间较短的对象,老生代的对象为存活时间较长或常驻内存的对象,如下图:

V8 堆的整体大小就是新生代所用内存空间加上老生代的内存空间。
在 node 中 javascript 能使用的内存是有限制的.
- 64 位系统下约为 1.4GB。
- 32 位系统下约为 0.7GB。
对应到分代内存中,默认情况下。
- 32 位系统新生代内存大小为 16MB,老生代内存大小为 700MB。
- 64 位系统新生代内存大小为 32MB,老生代内存大小为 1.4GB。
新生代平均分成两块相等的内存空间,叫做 semispace,每块内存大小 8MB(32 位)或 16MB(64 位)。
在这样限制下,将会导致 Node 无法直接操作大内存对象,比如无法将一个 2GB 的文件读入内存中进行字符串分析处理,即使物理内存有 32GB,这样在单个 Node 进程的情况下,计算机的内存资源无法得到充足的使用。
Node 提供 V8 内存使用量查看方式
$ node
$ process.memoryUsage();
{
rss: 18702336,
heapTotal: 10295296,
heapUsed:5409936
}
heapTotal:已申请到的堆内存;
heapUsed:当前使用的量。
V8 的堆示意图如下:
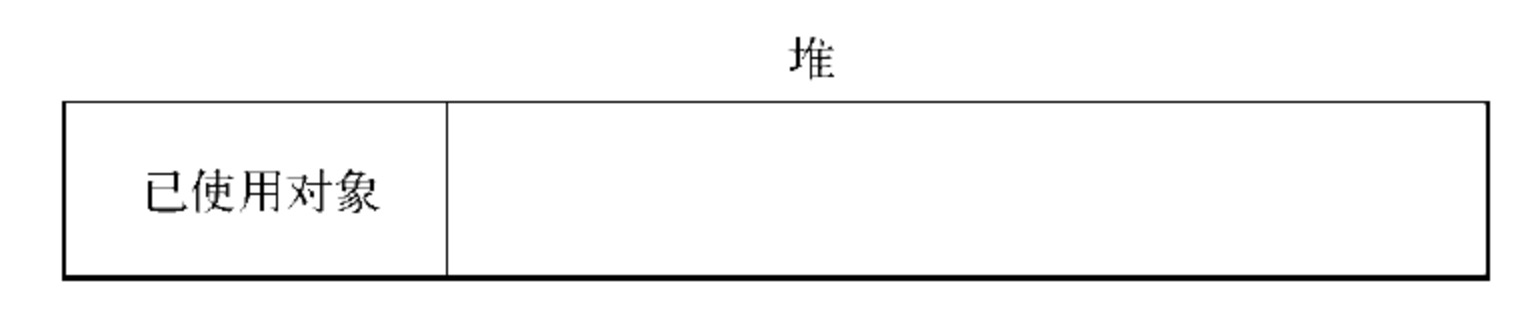
JS 声明变量并赋值时,所使用对象的内存就分配在堆中。如果已申请的堆空闲内存不够分配新的对象,将继续申请堆内存,直到对的大小超过 V8 的限制为止。
V8 提供选择来调整内存大小的配置,需要在初始化时候配置生效,遇到 Node 无法分配足够内存给 JS 对象的情况,可以用如下办法来放宽 V8 默认内存限制。避免执行过程内存用的过多导致崩溃
node --max-old-space-size=1700 app.js //单位为MB
node --max-new-space-size=1024 app.js //单位为MB
要知晓 V8 为何限制了内存的用量,则需要回归到 V8 在内存使用上的策略:
- 表面上的原因是 V8 最初是作为浏览器的 JavaScript 引擎而设计,不太可能遇到大量内存的场景。
- 而深层次的原因则是由于 V8 的垃圾回收机制的限制。由于 V8 需要保证 JavaScript 应用逻辑与垃圾回收器所看到的不一样,V8 在执行垃圾回收时会阻塞 JavaScript 应用逻辑,直到垃圾回收结束再重新执行 JavaScript 应用逻辑,这种行为被称为“全停顿”(stop-the-world)。
- 若 V8 的堆内存为 1.5GB,V8 做一次小的垃圾回收需要 50ms 以上,做一次非增量式的垃圾回收甚至要 1 秒以上。
- 这样浏览器将在 1s 内失去对用户的响应,造成假死现象。如果有动画效果的话,动画的展现也将显著受到影响。
Scavenge 算法
在分代基础上,新生代中的对象主要通过 Scavenge 算法进行垃圾回收。在 Scavenge 的具体实现中,主要采用了 Cheney 算法
-
Cheney 算法是一种采用复制的方式实现的垃圾回收算法。它将堆内存一分为二,每一部分空间称为 semispace。在这两个 semispace 空间中,只有一个处于使用中,另一个处于闲置状态。处于使用状态的 semispace 空间称为 From 空间,处于闲置状态的空间称为 To 空间。
-
当我们分配对象时,先是在 From 空间中进行分配。当开始进行垃圾回收时,会检查 From 空间中的存活对象,这些存活对象将被复制到 To 空间中,而非存活对象占用的空间将会被释放。
-
完成复制后,From 空间和 To 空间的角色发生兑换。简而言之,在垃圾回收过程中,就是通过将存活对象在两个 semispace 空间之间进行复制。
Scavenge 的缺点是只能使用堆内存中的一半,这是由划分空间和复制机制所决定的。但 Scavenge 由于只复制存活的对象,并且对于生命周期短的场景存活对象只占少部分,所以它在时间效率上有优异的表现。
新生代内存示意图:

由于 Scavenge 是典型的牺牲空间换取时间的算法,所以无法大规模地应用到所有的垃圾回收中。但可以发现,Scavenge 非常适合应用在新生代中,因为新生代中对象的生命周期较短,恰恰适合这个算法。
晋升
实际使用的堆内存是新生代的两个 semispace 空间大小和老生代所用内存大小之和。当一个对象经过多次复制依然存活时,它将会被认为是生命周期较长的对象。这种较长生命周期的对象随后会被移动到老生代中,采用新的算法进行管理。对象从新生代中移动到老生代中的过程称为晋升。
在单纯的 Scavenge 过程中,From 空间中的存活对象会被复制到 To 空间中去,然后对 From 空间和 To 空间进行角色对换(又称翻转)。但在分代式垃圾回收前提下,From 空间中的存活对象在复制到 To 空间之前需要进行检查。在一定条件下,需要将存活周期长的对象移动到老生代中,也就是完成对象晋升。
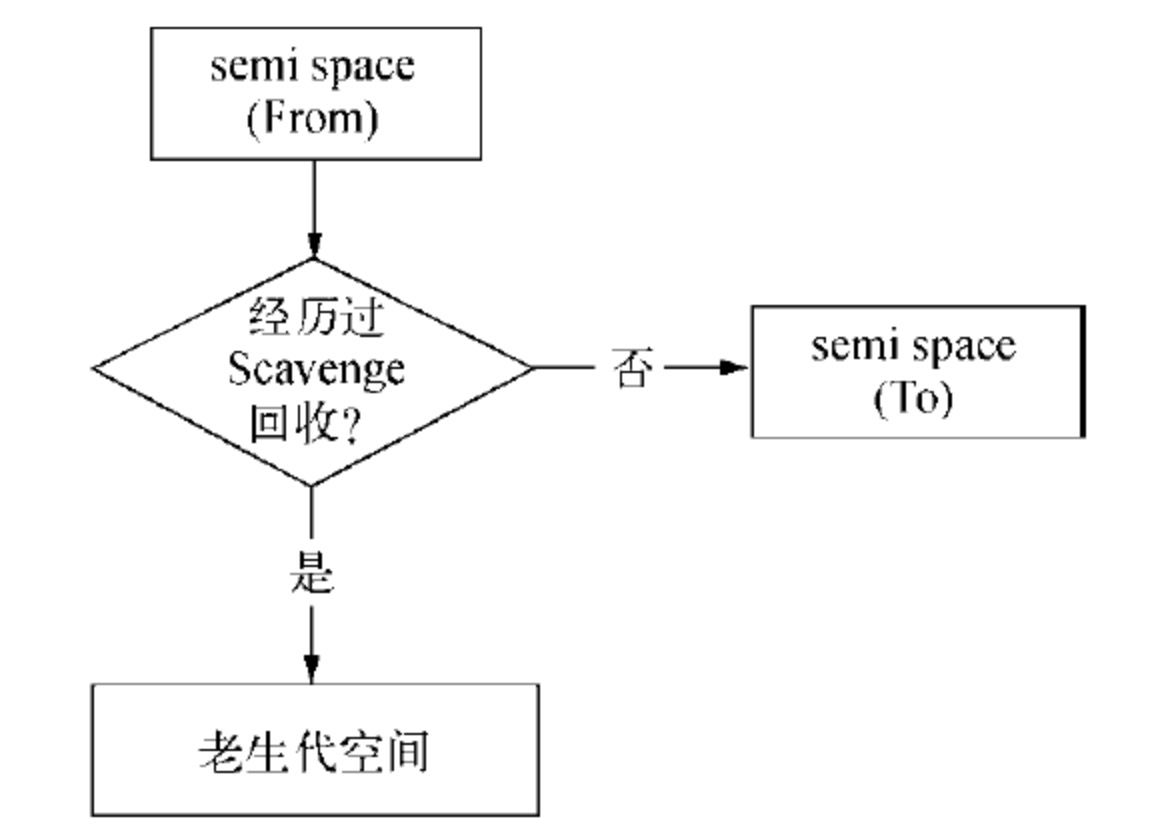
对象晋升的条件主要有两个:
- 一个是对象是否经历过 Scavenge 回收
- 一个是 To 空间的内存占用比超过限制
(一)在默认情况下,V8 的对象分配主要集中在 From 空间中。对象从 From 空间中复制到 To 空间时,会检查它的内存地址来判断这个对象是否已经经历过一次 Scavenge 回收。如果已经经历过了,会将该对象从 From 空间复制到老生代空间中,如果没有,则复制到 To 空间中。这个晋升流程如图所示:
(二)另一个判断条件是 To 空间的内存占用比。当要从 From 空间复制一个对象到 To 空间时,如果 To 空间已经使用了超过 25%,则这个对象直接晋升到老生代空间中,这个晋升的判断示意图如下图:
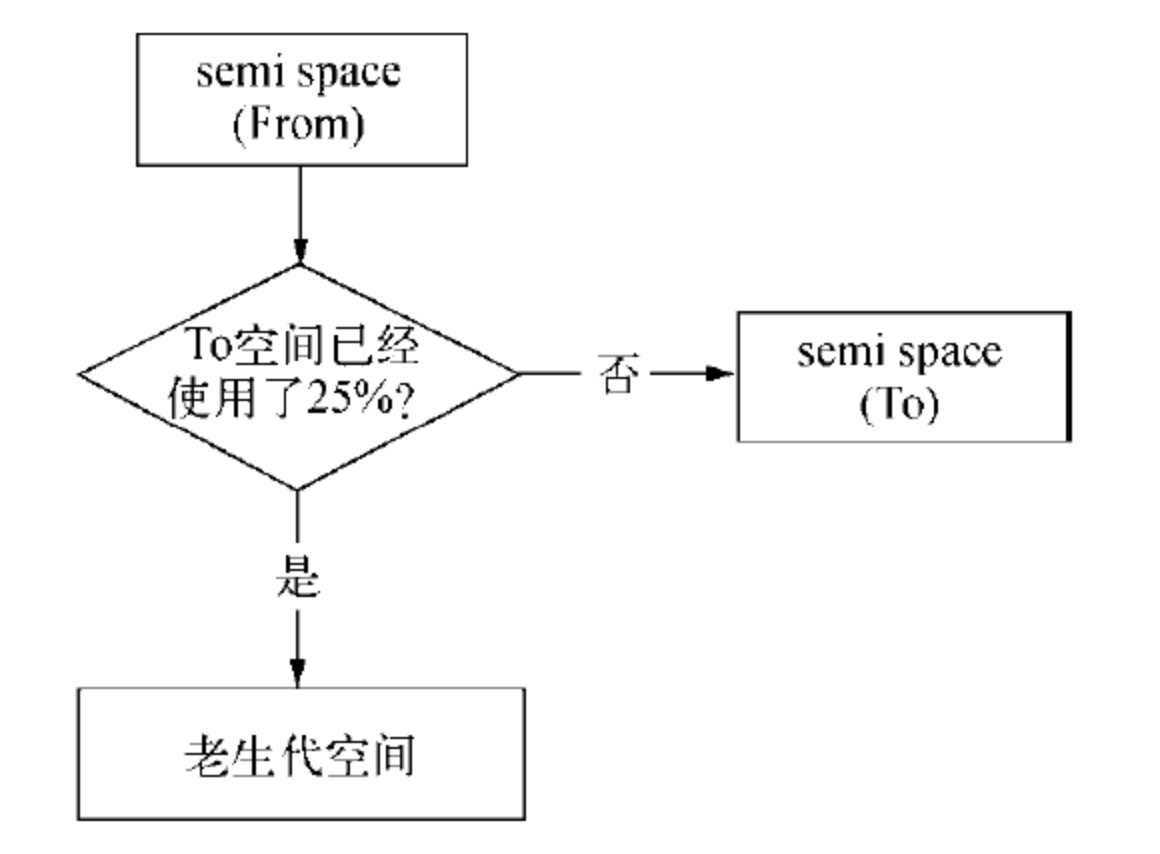
设置 25%这个限制值的原因是当这次 Scavenge 回收完成后,这个 To 空间将变成 From 空间,接下来的内存分配将在这个空间中进行。如果占比过高,会影响后续的内存分配。对象晋升后,将会在老生代空间中作为存活周期较长的对象来对待,接受新的回收算法处理。
Mark-Sweep & Mark-Compact
对于老生代中的对象,由于存活对象占较大比重,再采用 Scavenge 的方式会有两个问题:一个是存活对象较多,复制存活对象的效率将会很低;另一个问题依然是浪费一半空间的问题。为此,V8 在老生代中主要采用 Mark-Sweep 和 Mark-Compact 相结合的方式进行垃圾回收。
这里简单讲一下标记的过程,采用 3 色标记:黑、白、灰,步骤如下:
- GC 开始,所以对象标记为白色。
- 根对象标记为黑色,并开始遍历其子节点(引用的对象)。
- 当前被遍历的节点,标记为灰色,被放入一个叫 marking bitmap 的栈。在栈中,把当前被遍历的节点,标记为黑色,并出栈,同时,把它的子节点(如果有的话)标记为灰色,并压入栈。(大对象比较特殊,这里不展开)
- 当所有对象被遍历完后,就只剩下黑和白。通过 Sweeping 或 Compacting 的方式,清理掉白色,完成 GC。
Mark-Sweep
Mark-Sweep 是标记清除的意思,它分为标记和清除两个阶段。与 Scavenge 相比,Mark-Sweep 并不将内存空间划分为两半,所以不存在浪费一半空间的行为。与 Scavenge 复制活着的对象不同,Mark-Sweep 在标记阶段遍历堆中所有对象,并标记活着的对象,在随后的清除阶段中,只清除没有被标记的对象。可以看出,Scavenge 中只复制活着的对象,而 Mark-Sweep 只清理死亡对象。活对象在新生代中只占较小部分,死对象在老生代中只占较小部分,这是两种回收方式能高效处理的原因。
下图为 Mark-Sweep 在老生代空间中标记的示意图,黑色部分标记为死亡对象
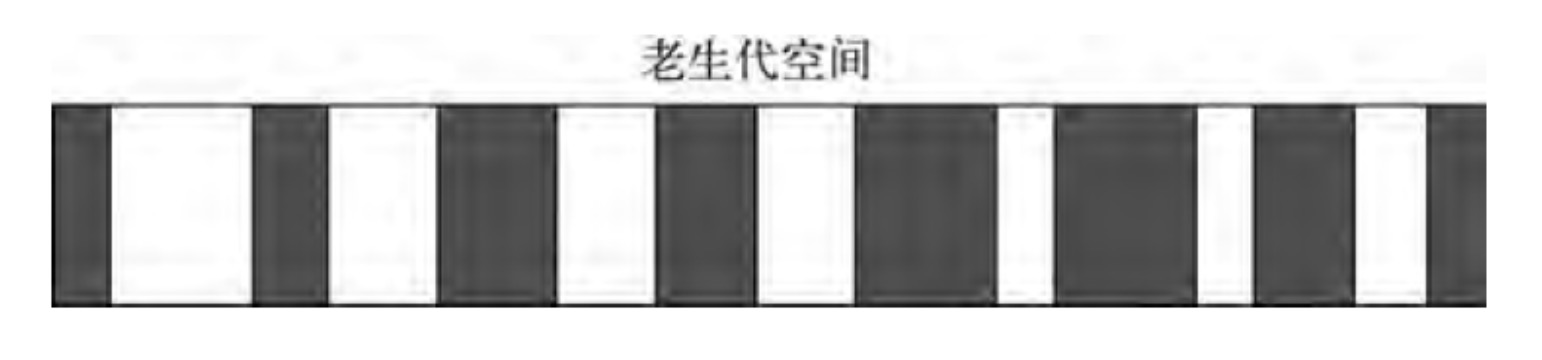
Mark-Sweep 最大的问题是在进行一次标记清除回收后,内存空间会出现不连续的状态。这种内存碎片会对后续的内存分配造成问题,因为很可能出现需要分配一个大对象的情况,这时所有的碎片空间都无法完成此次分配,就会提前触发垃圾回收,而这次回收是不必要的。
Mark-Compact
为了解决 Mark-Sweep 的内存碎片问题,Mark-Compact 被提出来。Mark-Compact 是标记整理的意思,是在 Mark-Sweep 的基础上演变而来的。它们的差别在于对象在标记为死亡后,在整理的过程中,将活着的对象往一端移动,移动完成后,直接清理掉边界外的内存。图为 Mark-Compact 完成标记并移动存活对象后的示意图,白色格子为存活对象,深色格子为死亡对象,浅色格子为存活对象移动后留下的空洞。
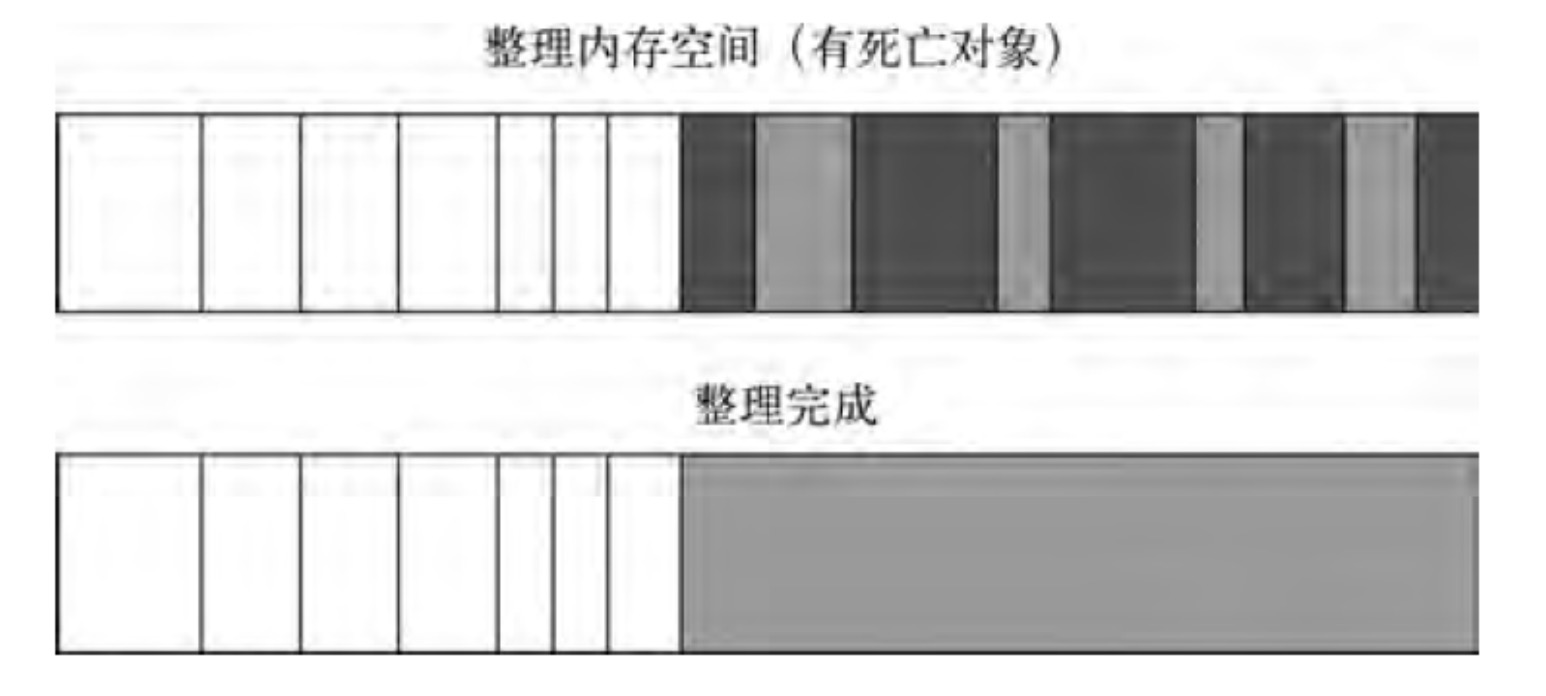
完成移动后,就可以直接清除最右边的存活对象后面的内存区域完成回收。
其他优化
Mark-Sweep、Mark-Compact、Scavenge 三种主要垃圾回收算法的简单对比:
| 回收算法 | Mark-Sweep | Mark-Compact | Scavenge |
|---|---|---|---|
| 速度 | 中等 | 最慢 | 最快 |
| 空间开销 | 少(有碎片) | 少(无碎片) | 双倍空间(无碎片) |
| 是否移动对象 | 否 | 是 | 是 |
从表格上看,Mark-Sweep 和 Mark-Compact 之间,由于 Mark-Compact 需要移动对象,所以它的执行速度不可能很快,所以在取舍上,V8 主要使用 Mark-Sweep,在空间不足以对从新生代中晋升过来的对象进行分配时才使用 Mark-Compact。
增量标记(incremental marking)
为了避免出现 js 应用逻辑与垃圾回收器看到的不一致的情况,垃圾回收的 3 种基本算法都需要将应用逻辑暂停下来,待执行完垃圾回收后再恢复执行应用逻辑,这种行为被称为“全停顿”(stop-the-world)。
在 V8 的分代式垃圾回收中,一次小垃圾回收只收集新生代,由于新生代默认配置得较小,且其中存活对象通常较少,所以即便它是全停顿的影响也不大。但 V8 的老生代通常配置得较大,且存活对象较多,全堆垃圾回收(full 垃圾回收)的标记、清理、整理等动作造成的停顿就会比较可怕,需要设法改善。
为了降低全堆垃圾回收带来的停顿时间,V8 先从标记阶段入手,将原本要一口气停顿完成的动作改为增量标记(incremental marking),也就是拆分为许多小“步进”,每做完一“步进”就让 js 应用逻辑执行一小会,垃圾回收与应用逻辑交替执行直到标记阶段完成。
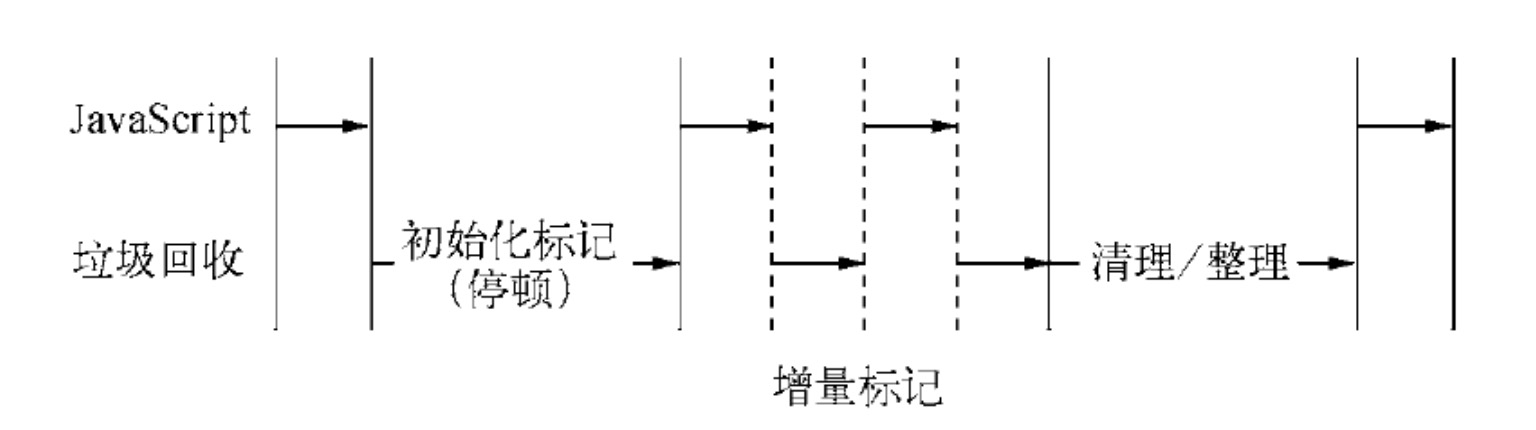
V8 在经过增量标记的改进后,垃圾回收的最大停顿时间可以减少到原本的 1/6 左右。
V8 后续还引入了延迟清理(lazy sweeping)与增量式整理(incremental compaction),让清理与整理动作也变成增量式的。同时还计划引入并行标记与并行清理,进一步利用多核性能降低每次停顿的时间。
小结
从 V8 的自动垃圾回收机制的设计角度可以看到,V8 对内存使用进行限制的缘由。新生代设计为一个较小的内存空间是合理的,而老生代空间过大对于垃圾回收并无特别意义。
V8 对内存限制的设置对于 Chrome 浏览器这种每个选项卡页面使用一个 V8 实例而言,内存的使用是绰绰有余,对于 Node 编写的服务器端来说,内存限制也并不影响正常场景下的使用。但是对于 V8 的垃圾回收特点和 js 在单线程上的执行情况,垃圾回收是影响性能的因素之一。想要高性能执行效率,需要注意让垃圾回收尽量少地进行,尤其是全堆垃圾回收。
以 Web 服务器中的会话实现为例,一般通过内存来存储,但在访问量大的时候会导致老生代中的存活对象骤增,不仅造成清理/整理过程费时,还会造成内存紧张,甚至溢出
JavaScript 内存泄漏
什么是内存泄漏
程序的运行需要内存。只要程序提出要求,操作系统或者运行时(runtime)就必须供给内存。
对于持续运行的服务进程(daemon),必须及时释放不再用到的内存。否则,内存占用越来越高,轻则影响系统性能,重则导致进程崩溃。
不再用到的内存,没有及时释放,就叫做内存泄漏(memory leak)。
常见的内存泄漏
1.意外的全局变量
JavaScript 处理未定义变量的方式比较宽松:未定义的变量会在全局对象创建一个新变量。在浏览器中,全局对象是 window 。
function foo(arg) {
bar = "this is a hidden global variable"; // 意外挂在在 window 全局变量,导致内存泄漏
}
2.被遗忘的计时器
计数器函数,一直占用内存
// 计数器一直存在会一直占用内存,计数器结束需要做释放处理
var someResource = getData();
setInterval(function() {
var node = document.getElementById('Node');
if(node) {
// 处理 node 和 someResource
node.innerHTML = JSON.stringify(someResource));
}
}, 1000);
3.闭包递归
let index = 0
function readData() {
let buf = new Buffer(1024 * 1024 * 100)
buf.fill('g')
return function fn() { // 此处会把 return 出来的函数挂在在 window 下,作用域无法清除
index++ // 引入局外变量,内存无法清除
if (index < buf.length) {
return buf[index-1] // buf 不会被清除,需要手动清除
} else {
return ''
}
}
}
const data = readData()
const next = data()
内存泄漏的识别方法
浏览器
Chrome 浏览器查看内存占用,按照以下步骤操作。
- 打开开发者工具,选择 Performance 面板
- 在顶部的字段里面勾选 Memory
- 点击左上角的录制按钮。
- 在页面上进行各种操作,模拟用户的使用情况。
- 一段时间后,点击对话框的 stop 按钮,面板上就会显示这段时间的内存占用情况。
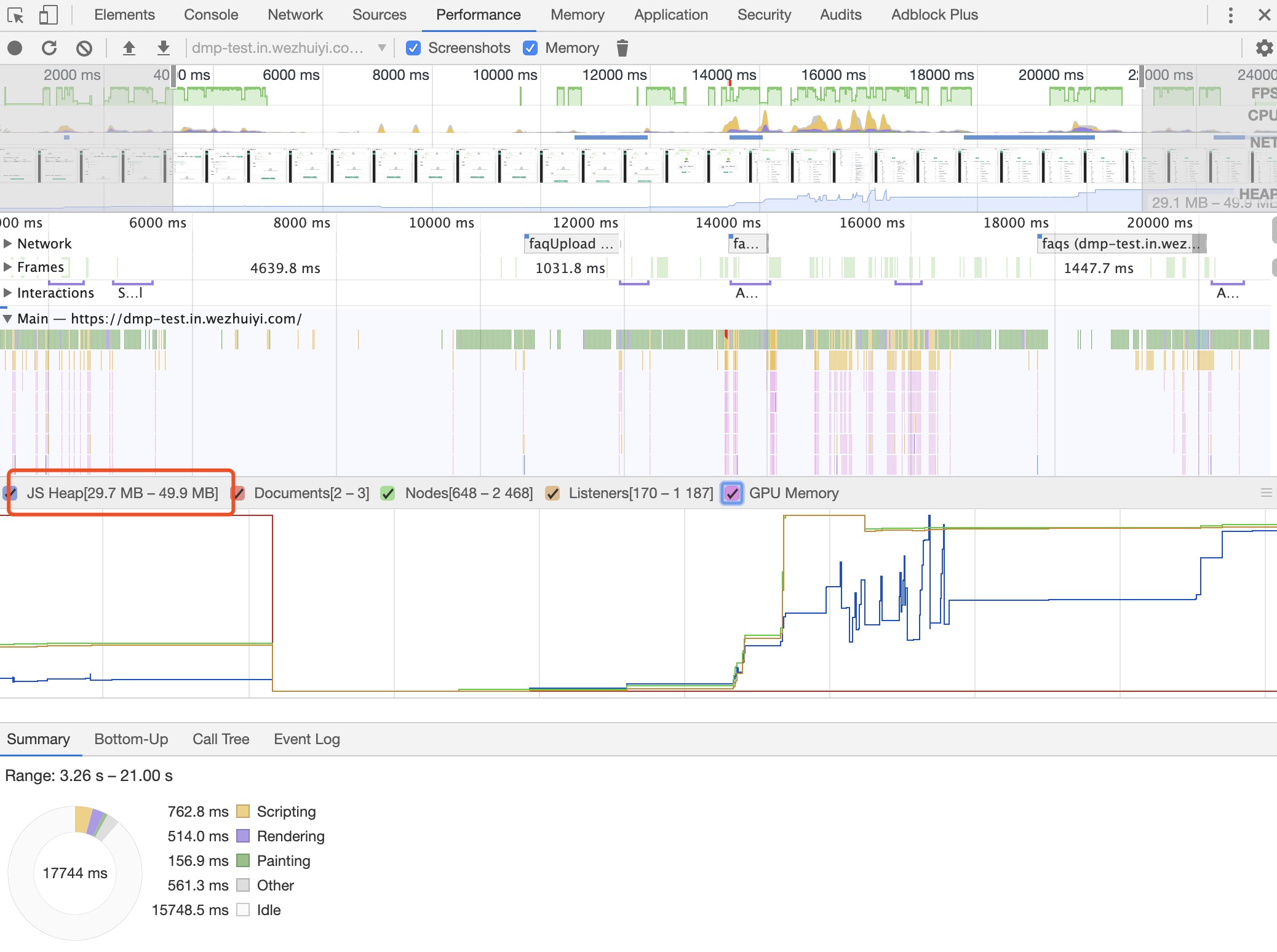
如果内存占用基本平稳,接近水平,就说明不存在内存泄漏。
反之,就是内存泄漏了。
命令行
命令行可以使用 Node 提供的 process.memoryUsage 方法。
process.memoryUsage();
// { rss: 27709440,
// heapTotal: 5685248,
// heapUsed: 3449392,
// external: 8772 }
process.memoryUsage 返回一个对象,包含了 Node 进程的内存占用信息。该对象包含四个字段,单位是字节,含义如下。

rss(resident set size):所有内存占用,包括指令区和堆栈。 heapTotal:”堆”占用的内存,包括用到的和没用到的。 heapUsed:用到的堆的部分。 external: V8 引擎内部的 C++ 对象占用的内存。
判断内存泄漏,以 heapUsed 字段为准。
查看内存使用情况
写一个方法用于不停地分配内存但不释放内存,相关代码如下:
var showMem = function() {
var mem = process.memoryUsage();
var format = function(bytes) {
return (bytes / 1024 / 1024).toFixed(2) + ' MB';
};
console.log('Process: heapTotal ' + format(mem.heapTotal) + ' heapUsed ' + format(mem.heapUsed) + ' rss ' + format(mem.rss));
console.log('---------------------------------------------------------------------------');
};
var useMem = function() {
var size = 20 * 1024 * 1024;
var arr = new Array(size);
for (var i = 0; i < size; i++) {
arr[i] = 0;
}
return arr;
};
var total = [];
for (var j = 0; j < 15; j++) {
showMem();
total.push(useMem());
}
showMem();
将以上代码存为 outofmemory.js 并执行它,得到的输出结果如下:
node outofmemory.js
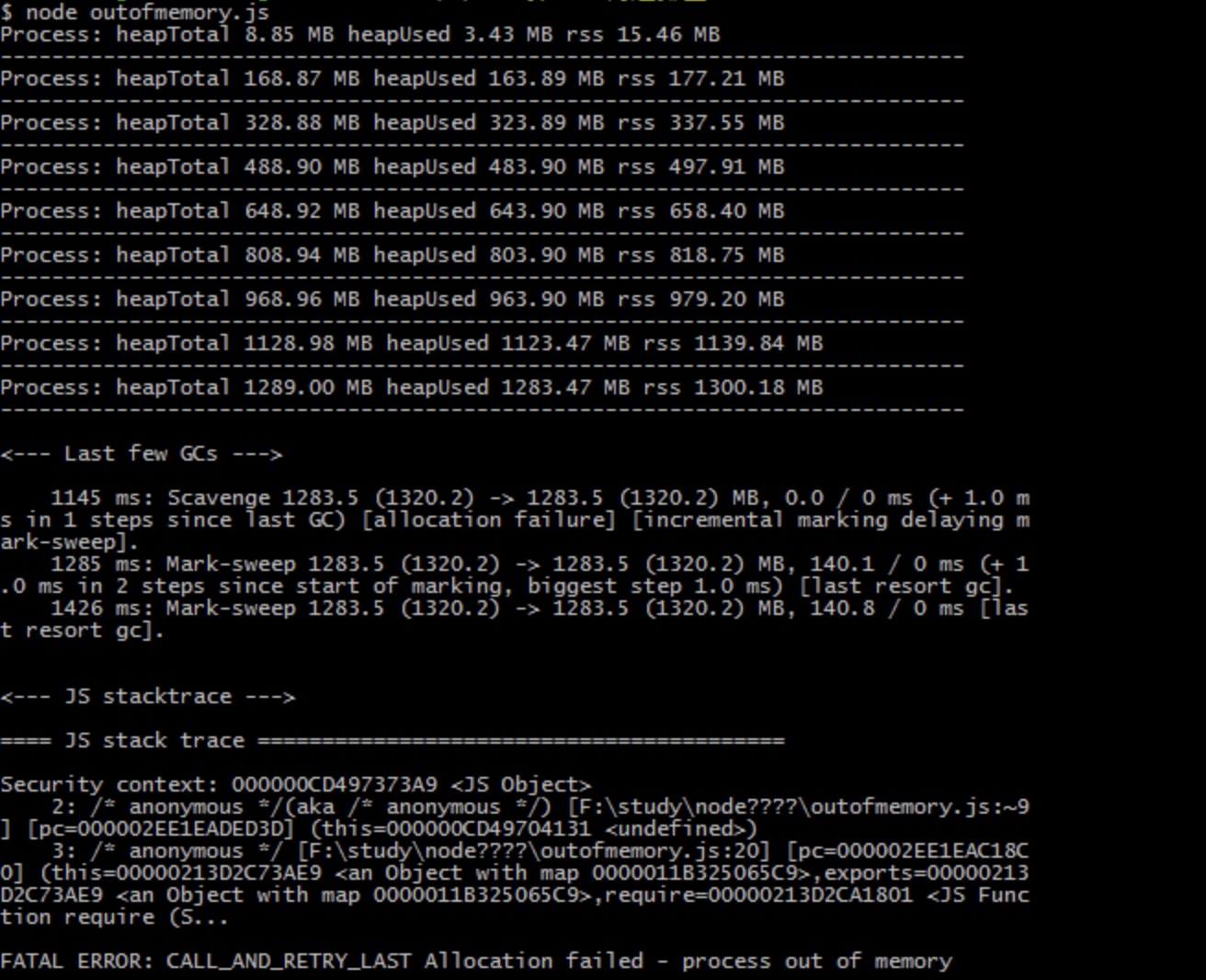
可以看到,每次调用 useMem 都导致了 3 个值的增长。在接近 1500MB 的时候,无法继续分配内存,然后进程内存溢出了,连循环体都无法执行完成,仅执行了 9 次。
堆外内存
通过 process.memoryUsage()的结果可以看到,堆中的内存用量总是小于进程的常驻内存用量。这意味着 Node 中的内存使用并非都是通过 V8 进行分配的。我们将那些不是通过 V8 分配的内存称为堆外内存。
这里将前面的 useMem()方法稍微改造一下,将 Array 变为 Buffer,将 size 变大,每一次构造 200MB 的对象,相关代码如下:
var useMem = function() {
var size = 200 * 1024 * 1024;
var buffer = new Buffer(size);
for (var i = 0; i < size; i++) {
buffer[i] = 0;
}
return buffer;
};
重新执行该代码,得到的输出结果如下所示:
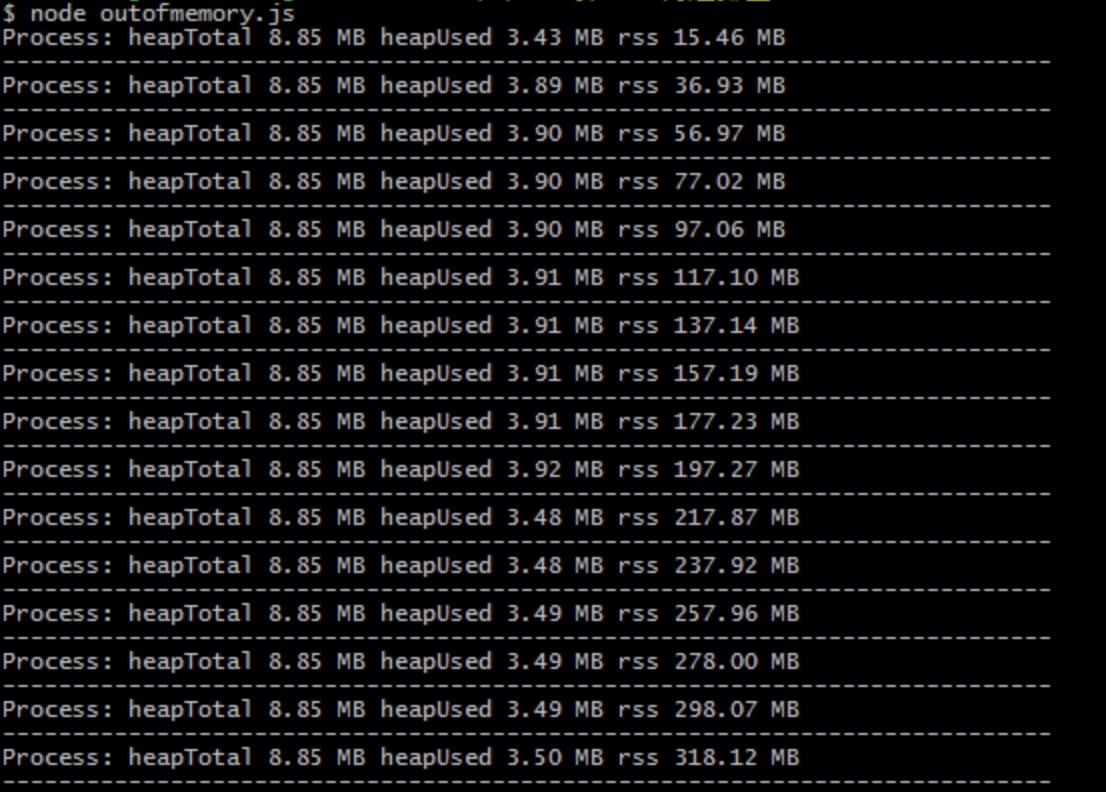
15 次循环都完整执行,并且三个内存占用值与前一个示例完全不同。在改造后的输出结果中,heapTotal 和 heapUsed 的变化极小,唯一变化的是 rss 的值,并且该值已经远远超过 V8 的限制值。这其中的原因是 Buffer 对象不同于其他对象,它不经过 V8 的内存分配机制,所以也不会有堆内存的大小限制。
这意味着利用堆外内存可以突破内存限制的问题。
为何 Buffer 对象并非通过 V8 分配?这在于 Node 并不同于浏览器的应用场景。在浏览器中,js 直接处理字符串即可满足绝大多数的业务需求,而 Node 则需要处理网络流和文件 I/O 流,操作字符串远远不能满足传输的性能需求。
从上面得知,Node 内存构成主要由通过 V8 进行分配的部分和 Node 自行分配的部分。受 V8 的垃圾回收限制的主要是 V8 的堆内存。
WeakSet 和 WeakMap
前面说过,及时清除引用非常重要。但是,你不可能记得那么多,有时候一疏忽就忘了,所以才有那么多内存泄漏。
最好能有一种方法,在新建引用的时候就声明,哪些引用必须手动清除,哪些引用可以忽略不计,当其他引用消失以后,垃圾回收机制就可以释放内存。这样就能大大减轻程序员的负担,你只要清除主要引用就可以了。
ES6 考虑到了这一点,推出了两种新的数据结构:WeakSet 和 WeakMap。它们对于值的引用都是不计入垃圾回收机制的,所以名字里面才会有一个”Weak”,表示这是弱引用。
下面以 WeakMap 为例,看看它是怎么解决内存泄漏的。
const wm = new WeakMap();
const element = document.getElementById('example');
wm.set(element, 'some information');
wm.get(element) // "some information"
上面代码中,先新建一个 Weakmap 实例。然后,将一个 DOM 节点作为键名存入该实例,并将一些附加信息作为键值,一起存放在 WeakMap 里面。这时,WeakMap 里面对 element 的引用就是弱引用,不会被计入垃圾回收机制。
也就是说,DOM 节点对象的引用计数是 1,而不是 2。这时,一旦消除对该节点的引用,它占用的内存就会被垃圾回收机制释放。Weakmap 保存的这个键值对,也会自动消失。
基本上,如果你要往对象上添加数据,又不想干扰垃圾回收机制,就可以使用 WeakMap。
示例
首先,打开 Node 命令行。
$ node --expose-gc
上面代码中,--expose-gc参数表示允许手动执行垃圾回收机制。
然后,执行下面的代码。
// 手动执行一次垃圾回收,保证获取的内存使用状态准确
> global.gc();
undefined
// 查看内存占用的初始状态,heapUsed 为 4M 左右
> process.memoryUsage();
{ rss: 21106688,
heapTotal: 7376896,
heapUsed: 4153936,
external: 9059 }
> let wm = new WeakMap();
undefined
> let b = new Object();
undefined
> global.gc();
undefined
// 此时,heapUsed 仍然为 4M 左右
> process.memoryUsage();
{ rss: 20537344,
heapTotal: 9474048,
heapUsed: 3967272,
external: 8993 }
// 在 WeakMap 中添加一个键值对,
// 键名为对象 b,键值为一个 5*1024*1024 的数组
> wm.set(b, new Array(5*1024*1024));
WeakMap {}
// 手动执行一次垃圾回收
> global.gc();
undefined
// 此时,heapUsed 为 45M 左右
> process.memoryUsage();
{ rss: 62652416,
heapTotal: 51437568,
heapUsed: 45911664,
external: 8951 }
// 解除对象 b 的引用
> b = null;
null
// 再次执行垃圾回收
> global.gc();
undefined
// 解除 b 的引用以后,heapUsed 变回 4M 左右
// 说明 WeakMap 中的那个长度为 5*1024*1024 的数组被销毁了
> process.memoryUsage();
{ rss: 20639744,
heapTotal: 8425472,
heapUsed: 3979792,
external: 8956 }
上面代码中,只要外部的引用消失,WeakMap 内部的引用,就会自动被垃圾回收清除。由此可见,有了它的帮助,解决内存泄漏就会简单很多。
内存泄漏排查
在 Node 中,由于 V8 的堆内存大小的限制,它对内存泄漏非常敏感。当在线服务的请求量变大时,哪怕是一个字节的泄漏都会导致内存占用过高。下面介绍一下遇到内存泄漏时的排查方案。
有一些常见的工具来定位 Node 应用的内存泄漏:
- v8-profiler:它可以用于对 V8 堆内存抓取快照和对 CPU 进行分析;
- node-heapdump:它允许对 V8 堆内存抓取快照,用于事后分析;
- node-mtrace:它使用 GCC 的 mtrace 工具来分析堆的使用;
- dtrace:有完善的 dtrace 工具用来分析内存泄漏;
- node-memwatch:来自 Mozilla 贡献的模块,采用 WTFPL 许可发布。
通过对这些工具的了解,发现排查内存泄漏主要通过对堆内存进行分析而找到。
大内存应用
stream 模块是 Node 的原生模块,直接引用即可。stream 继承自 EventEmitter,具备基本的自定义事件功能,同时抽象出标准的事件和方法。它分可读和可写两种。Node 中的大多数模块都有 stream 的应用,比如 fs 的 createReadStream()和 createWriteStream()方法可以分别用于创建文件的可读流与可写流,process 模块中的 stdin 和 stdout 则分别是可读流和可写流的示例。
由于 V8 的内存限制,我们无法通过 fs.readFile()和 fs.writeFile()直接进行大文件的操作,而改用 fs.createReadStream()和 fs.createWriteStream()方法通过流的方式实现对大文件的操作。下面的代码展示了如何读取一个文件,然后将数据写入到另一个文件的过程:
var reader = fs.createReadStream('in.txt');
var writer = fs.createWriteStream('out.txt');
reader.on('data', function (chunk) {
writer.write(chunk);
});
reader.on('end', function () {
writer.end();
});
可读流提供了管道方法 pipe(),封装了 data 事件和写入操作。通过流的方式,上述代码不会受到 V8 内存限制的影响,有效地提高了程序的健壮性。
如果不需要进行字符串层面的操作,则不需要借助 V8 来处理,可以尝试进行纯粹的 Buffer 操作,这不会受到 V8 堆内存的限制。但是这种大片使用内存的情况依然要小心,即使 V8 不限制堆内存的大小,物理内存依然有限制。
Node 将 JavaScript 的主要应用场景扩展到了服务器端,相应要考虑的细节也与浏览器端不同,需要更严谨地为每一份资源作出安排。总的来说,内存在 Node 中不能随心所欲地使用。